Here are some ideas to get you started:
- 🔭 I’m currently working on ByteDance
- 🌱 I’m currently learning Rust
- 📮 I’m currently writing a news letter FE News
- 🧱 I’m currently contributing on front-end-daily-question
- 📫 How to reach me: wx: pen1005
日常记录 blog,内容不限于前端,博文在 issue https://github.com/rottenpen/blog/issues
Here are some ideas to get you started:







我们在 Vue 开发的过程中,可能会用到 ES6 的 Set 数据类型。
常用的就是用它来去重。在我的理解当中,它就是一个不会重复的 Array ,但在实际开发中不然。
我们在浏览器里 log 一下,Set 是啥?
Set {_c: Set(134)}
_c :Set(134)
size:(...)
__proto__: Set
[[Entries]]: Array(134)
length: 134
__proto__: Object
size: (...)
__proto__: Set很明显,在 js 里,它压根就不是一个数组。(确实,它本来就不是。它的原型是 Set)
Vue 模版在检查 Set 的时候,自然会得出它为 Set 的结论,然后不会分析它里面的内容。
这就造成在我们:
<div v-for="(item, index) in Arr" :key="index">{{item}}</div> // =>只渲染出一个 div 而且 div 的内容是 {}
data ( ) {
return: {
Arr:new Set([1,2,3])
}
}这里,我们就需要对 Set 进行转化了,把它转化为一个普通的 Array 数组,这里用到了 ES6 的方法 Array.from() :
<div v-for="(item, index) in newArr" :key="index">{{item}}</div>
computed:{
newArr:{
return Array.from(this.Arr)
}
}给你一个整数数组 arr 。请你将数组中的元素按照其二进制表示中数字 1 的数目升序排序。
如果存在多个数字二进制中 1 的数目相同,则必须将它们按照数值大小升序排列。
请你返回排序后的数组。
链接:https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits
/**
* @param {number[]} arr
* @return {number[]}
*/
var sortByBits = function(arr) {
let countBit = (num) => {
let res = 0
let s = num
while(num) {
// console.log(s, num , num & 1)
if(num & 1) {
res++
}
num>>=1
}
// console.log(s, res)
return res
}
arr.sort((a, b) => {
let res = countBit(a) - countBit(b)
if (res === 0) return a - b
return res
})
return arr
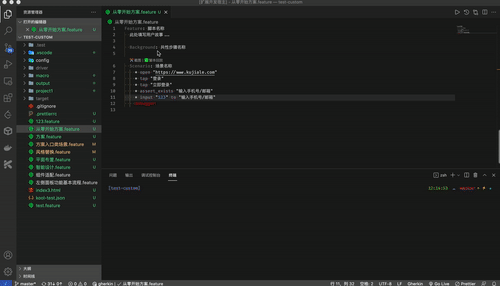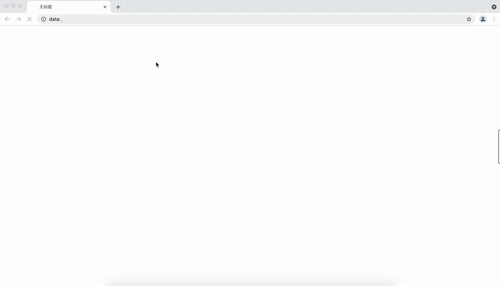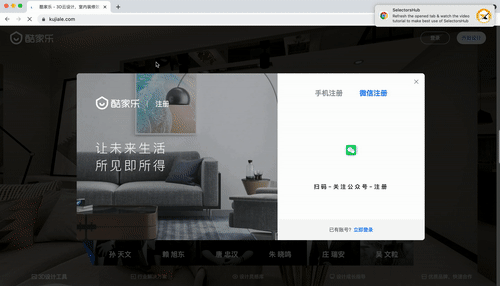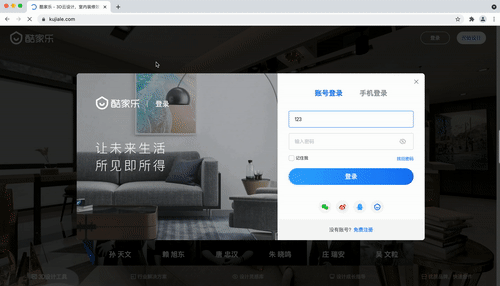
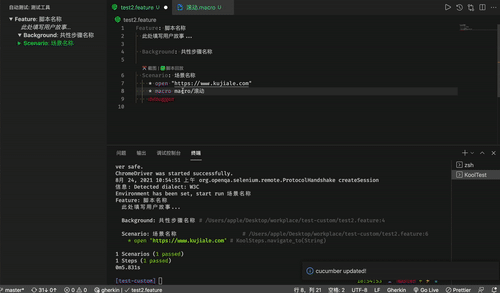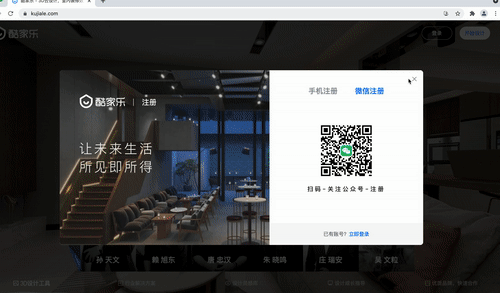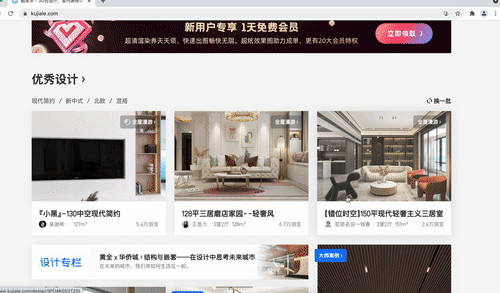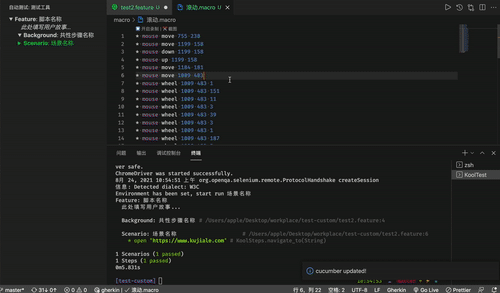
};Kooltest 是酷家乐研发的一个支持多终端的 UI 自动化测试框架。为了给用户提供更优质的产品体验,在产品上线前需要进行各项测试。其中回归测试多由测试人员手动执行,耗费了大量人力,并且还可能存在漏测问题。鉴于此,我们在跨端的 UI 自动化上面做了大量的优化和思考,实现了 KoolTest 的 跨端 UI 自动化测试方案,用以降低人力成本。目前本框架支持使用一套脚本规范来测试 Android、iOS、Web。
BDD 行为驱动开发(Behavior Driven Development)核心的是,开发人员、QA、非技术人员和用户都参与到项目的开发中,彼此协作。BDD 强调从用户的需求出发,最终的系统和用户的需求一致。BDD 验证代码是否真正符合用户需求,因此 BDD 是从一个较高的视角来对验证系统是否和用户需求相符。
直接上代码:
通过这种基于 cucumber 设计的语义化 DSL 语言轻松可以实现高开发效率,低阅读成本的目标。
有了测试框架和规范的 DSL 语言,我们还有什么事情要做呢?我们需要的是从编写开始的一整套 DevOps 体系。
而本文要介绍的是,我们是怎么通过 VsCode 插件来提高测试脚本开发体验的。
kool-test-script 提供的核心能力有:
VS Code 插件提供一些可以帮你更快开发脚本并且可以快速浏览,脚本运行的结果。
代码补全 (Code Completion) 提供即时类名、方法名和关键字等预测,辅助开发人员编写代码,大幅提升开发效率。
Kooltest 所使用的 DSL 语法是魔改自 Cucumber 提供 gherkin 语言,为了更好编写我们的 gherkin,我们需要对我们设计的关键字,方法名,文件路径等提供高亮和预测。
kool-test-script 增强了测试人员经常使用的 gherkin 及样式相关文件的代码补全体验。
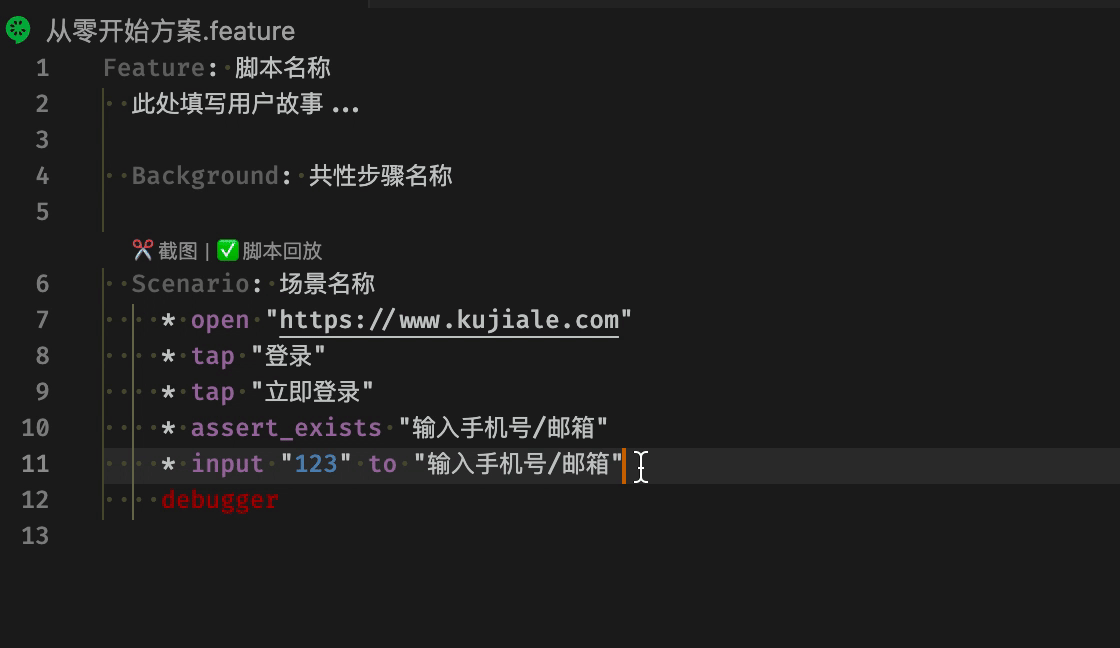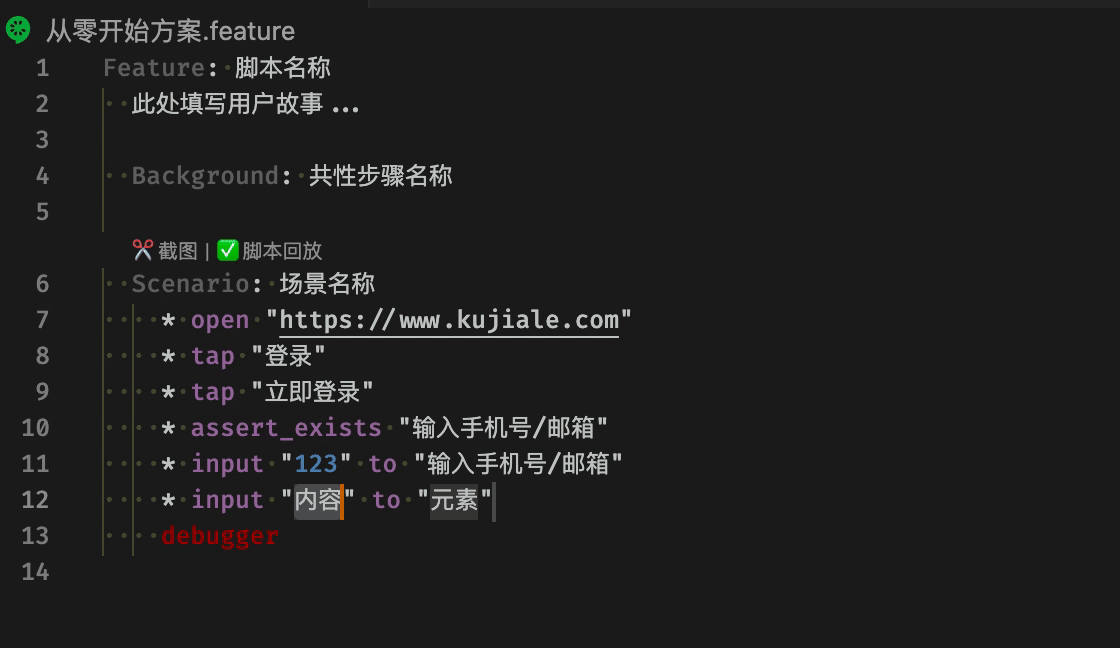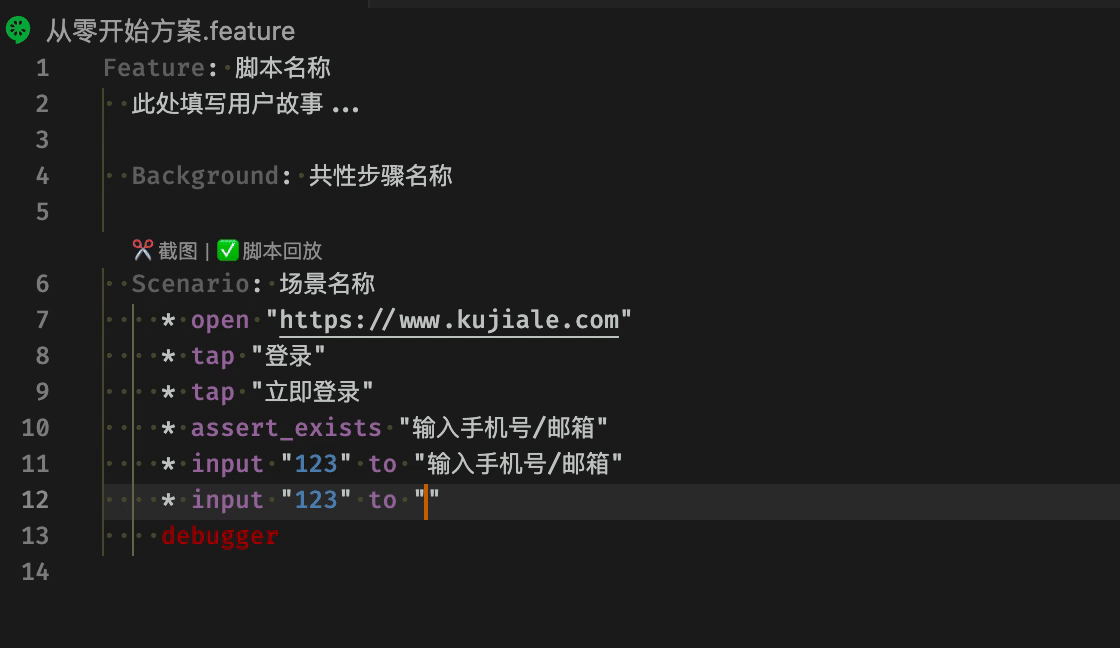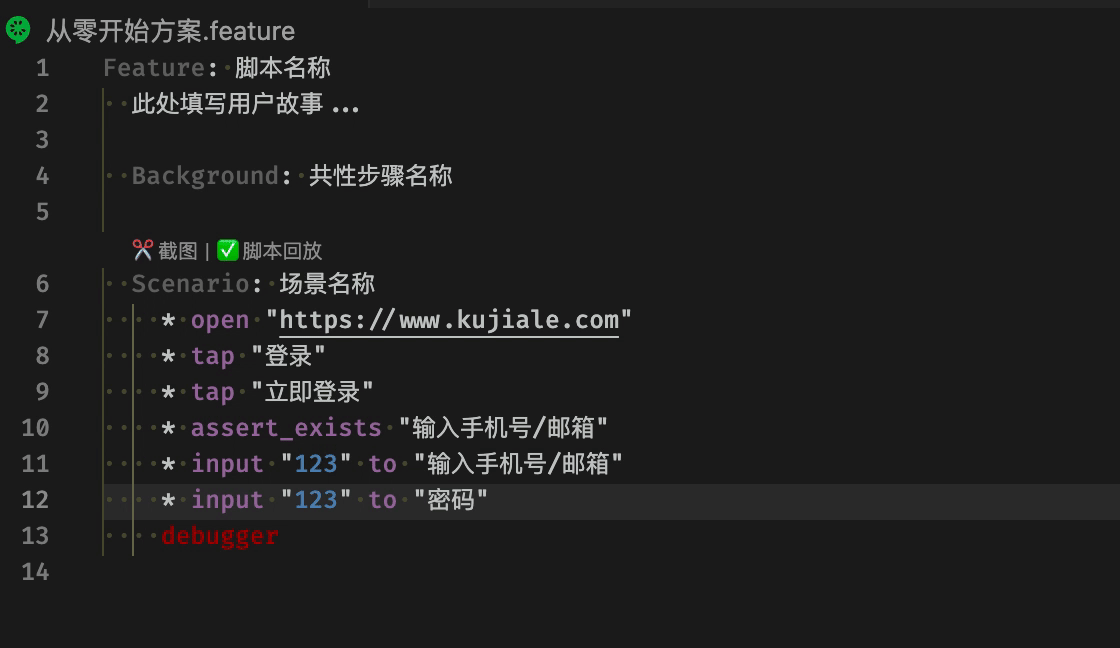
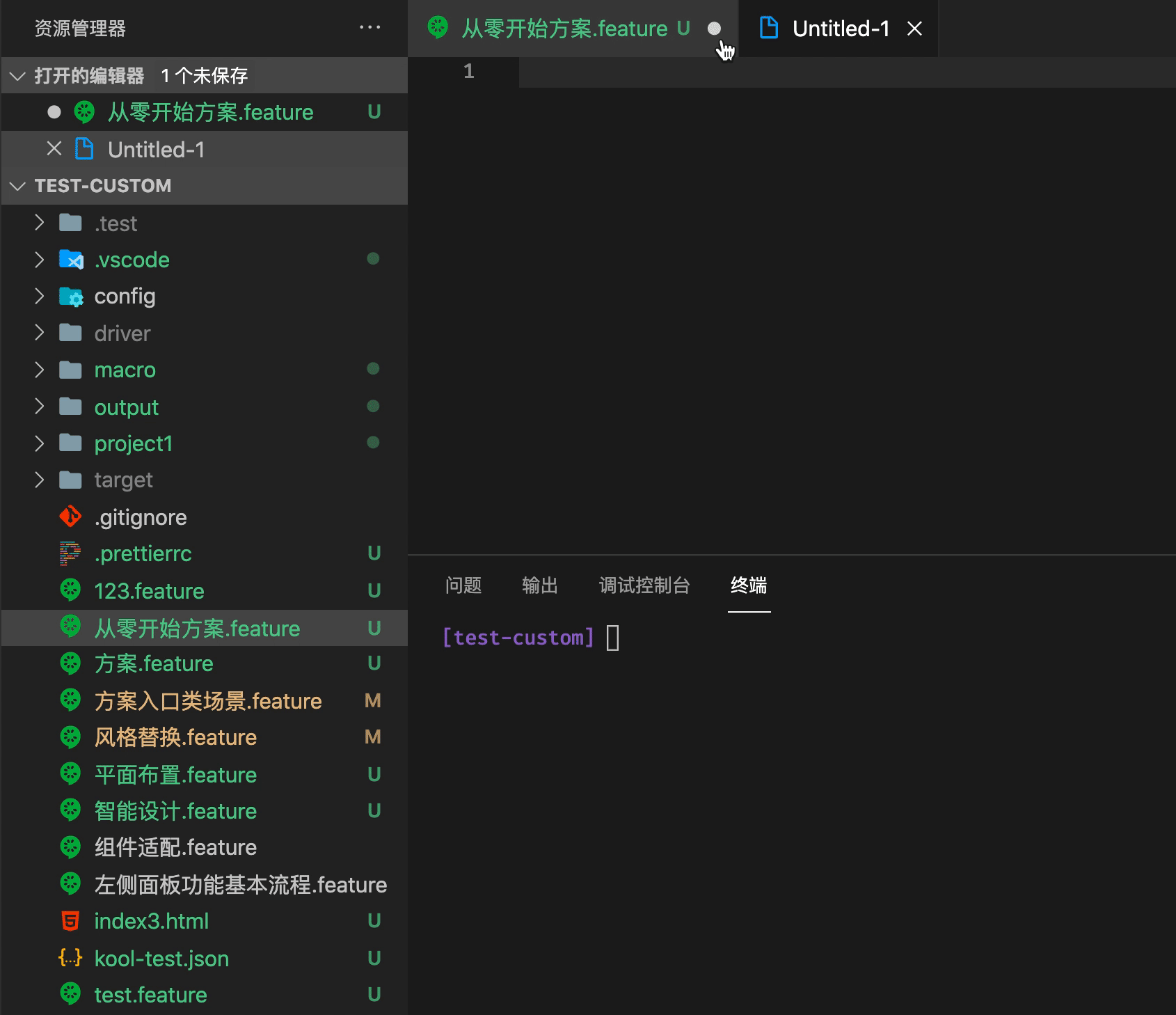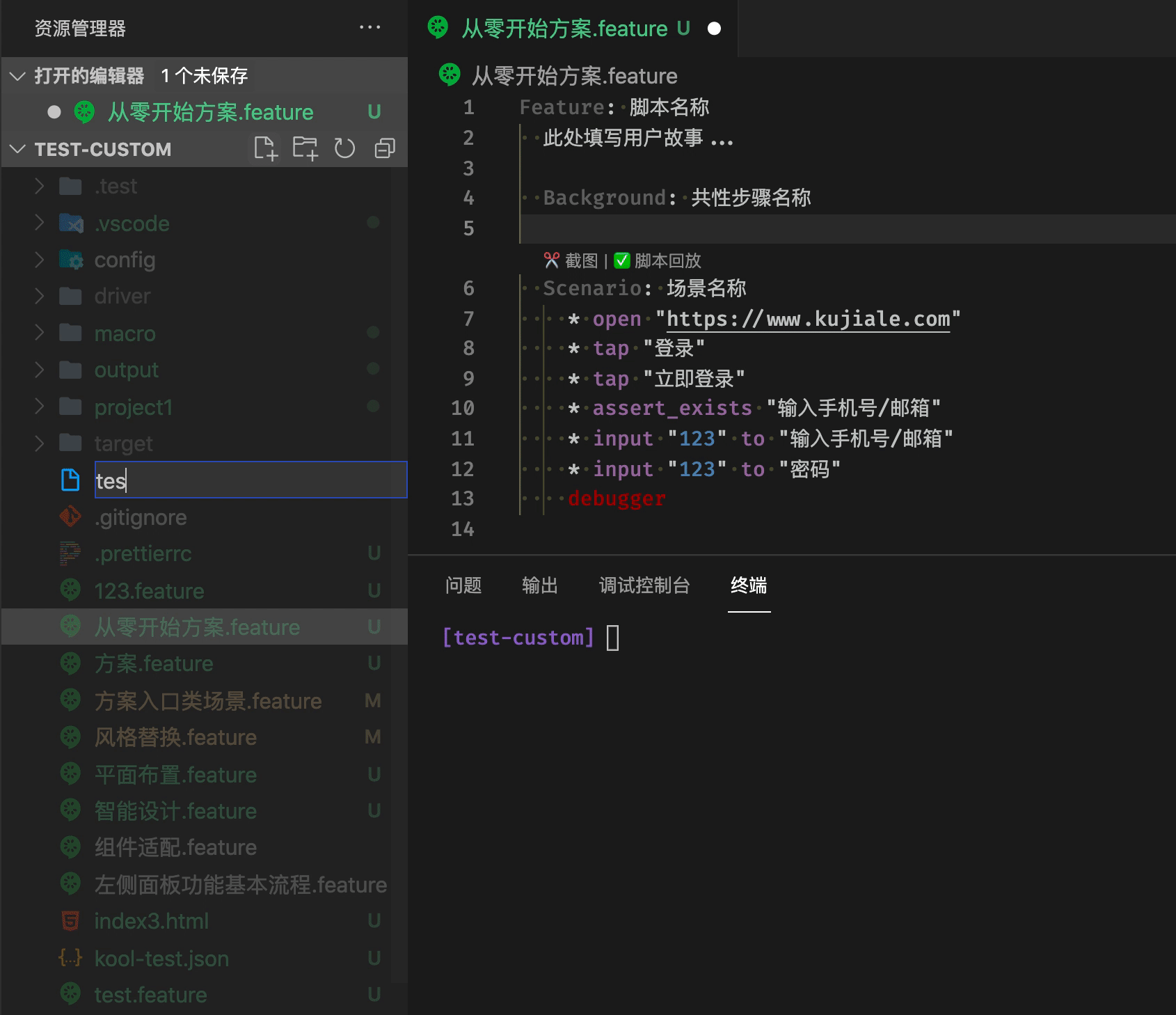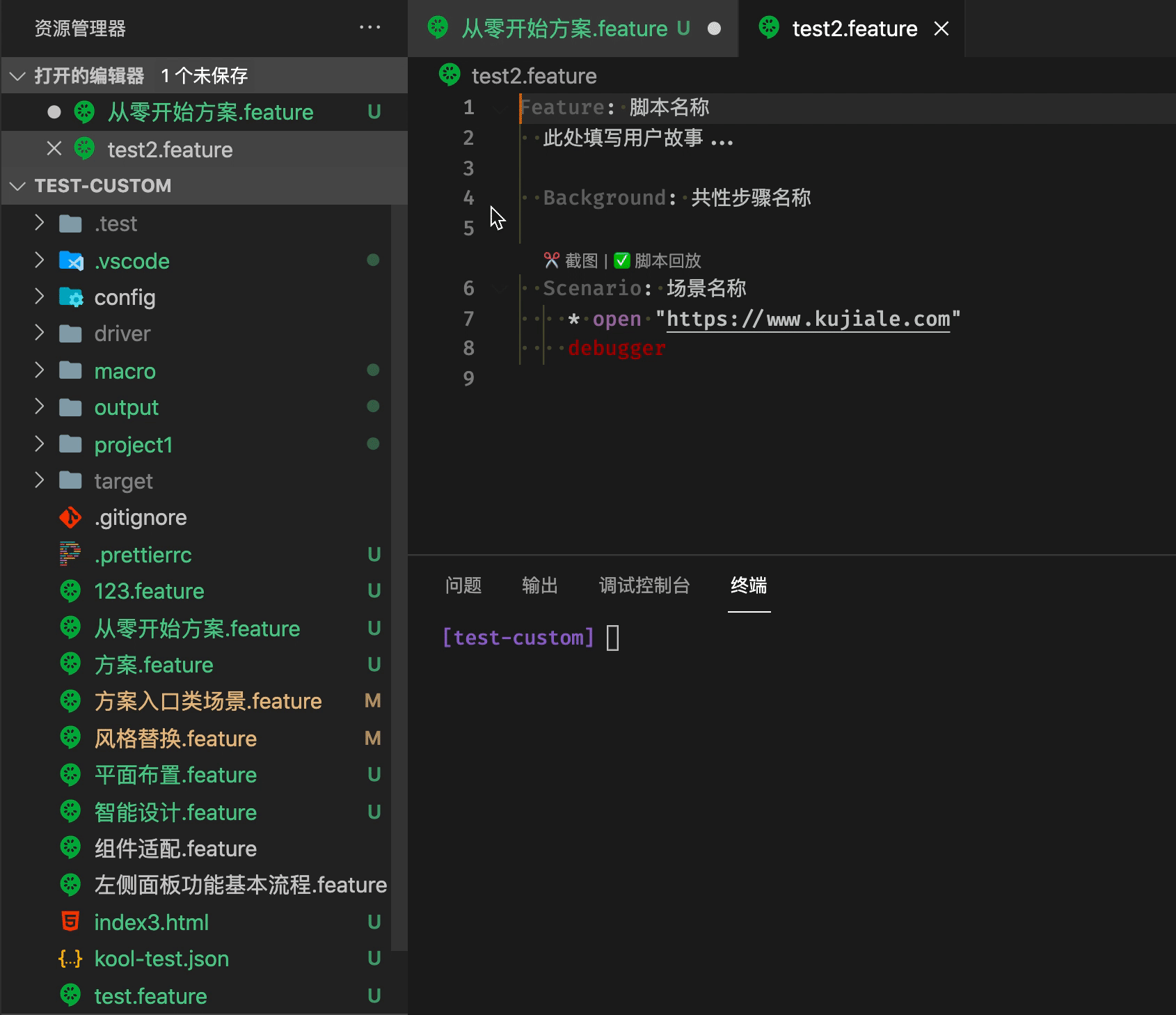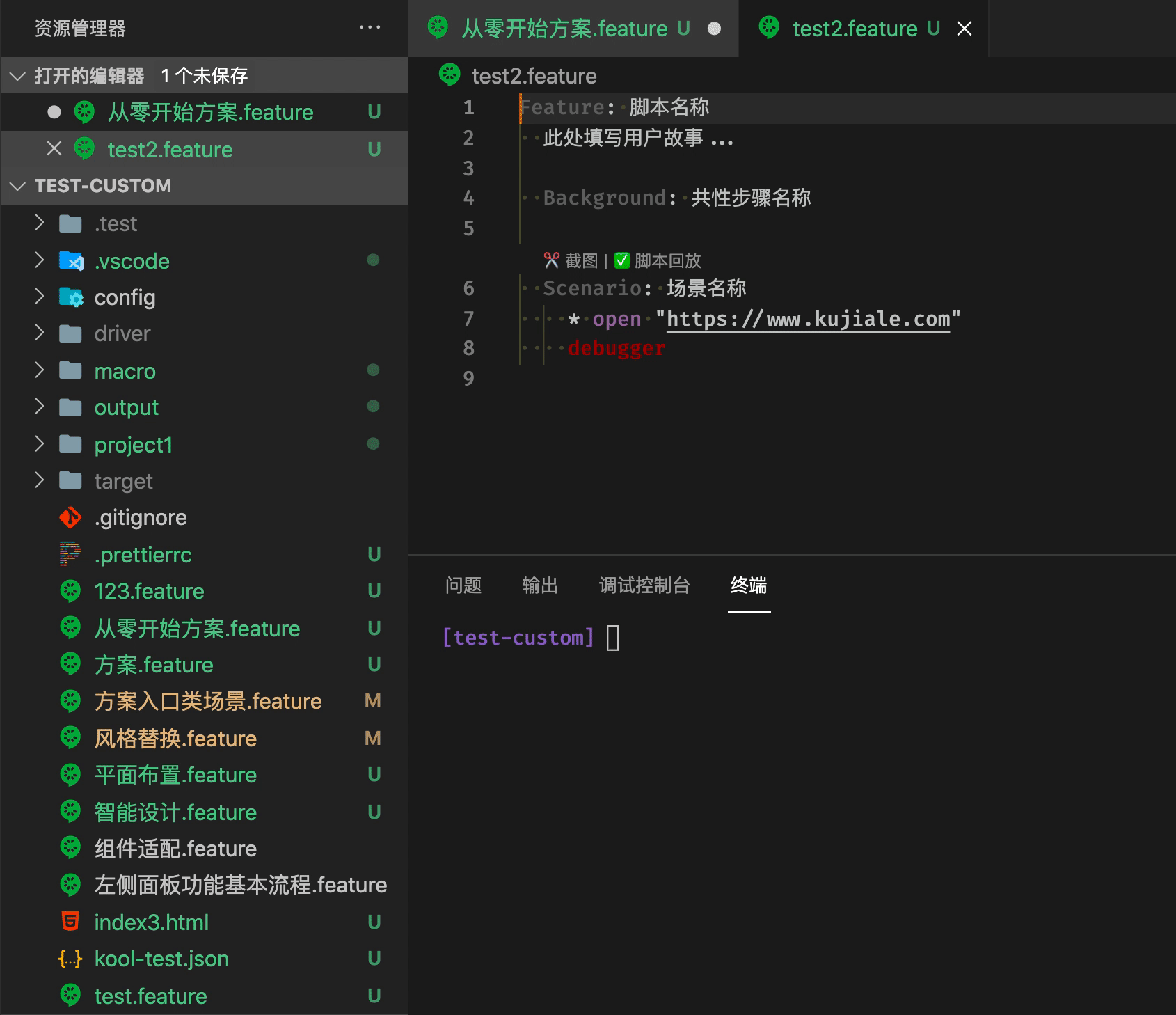
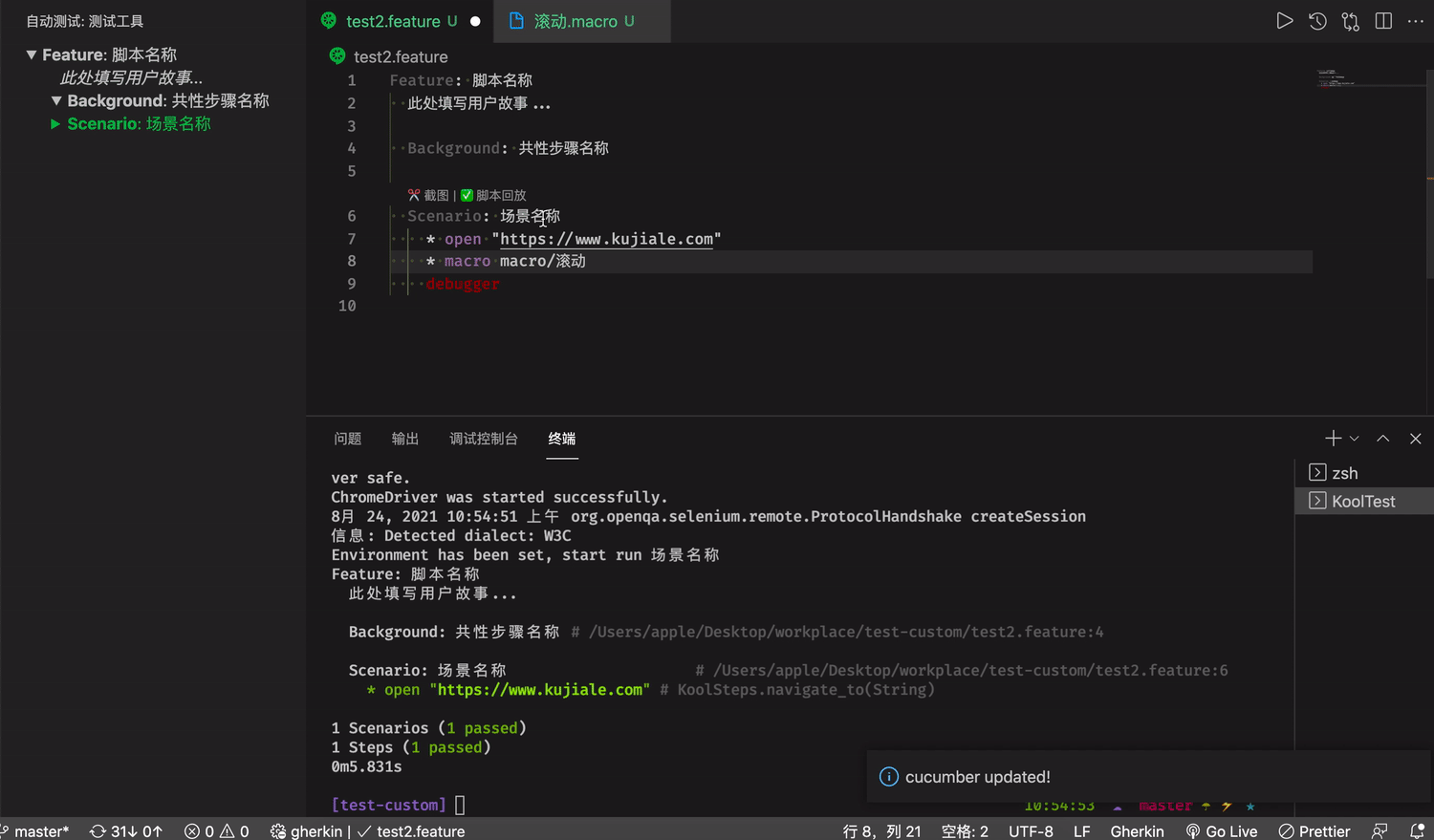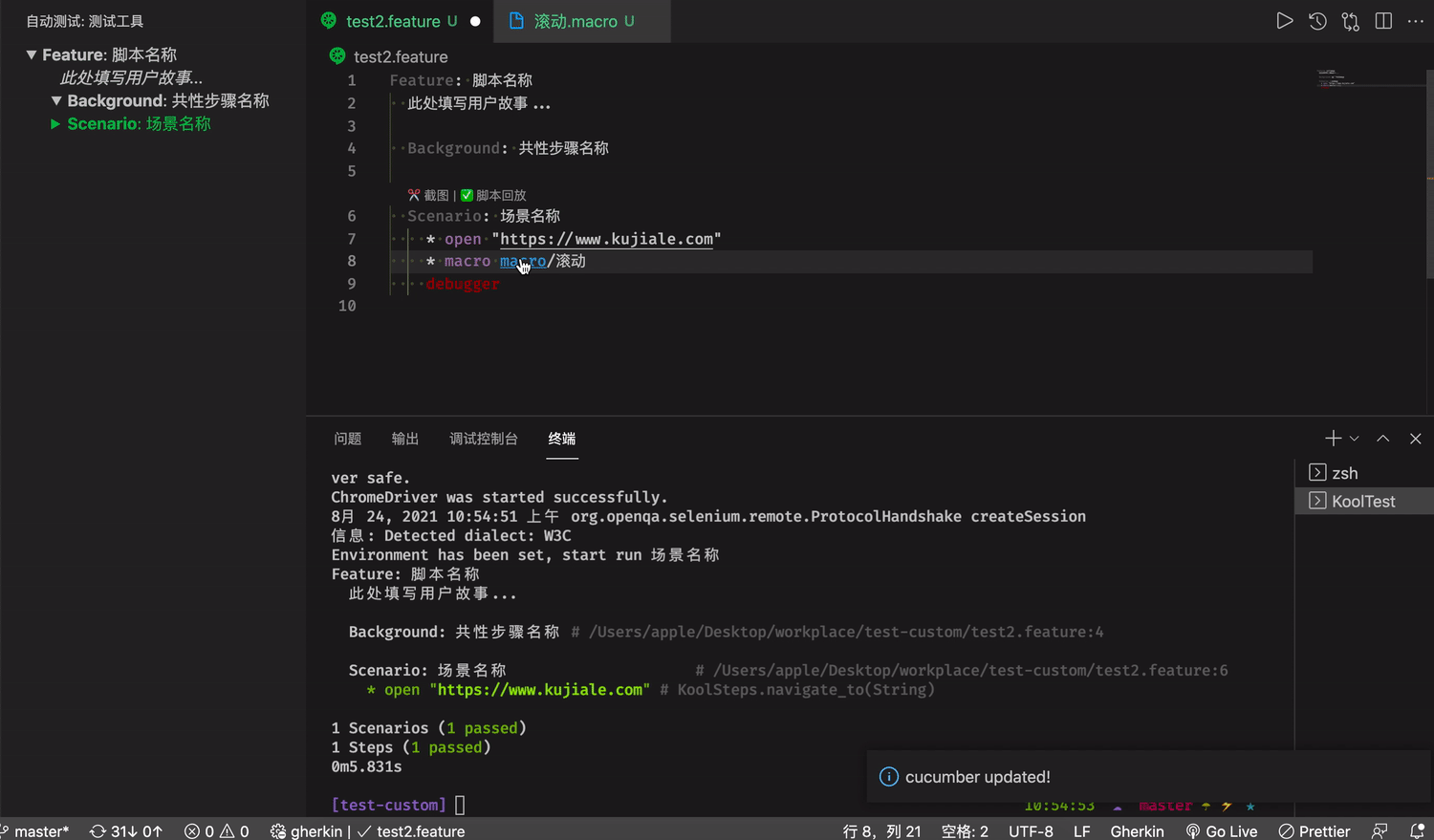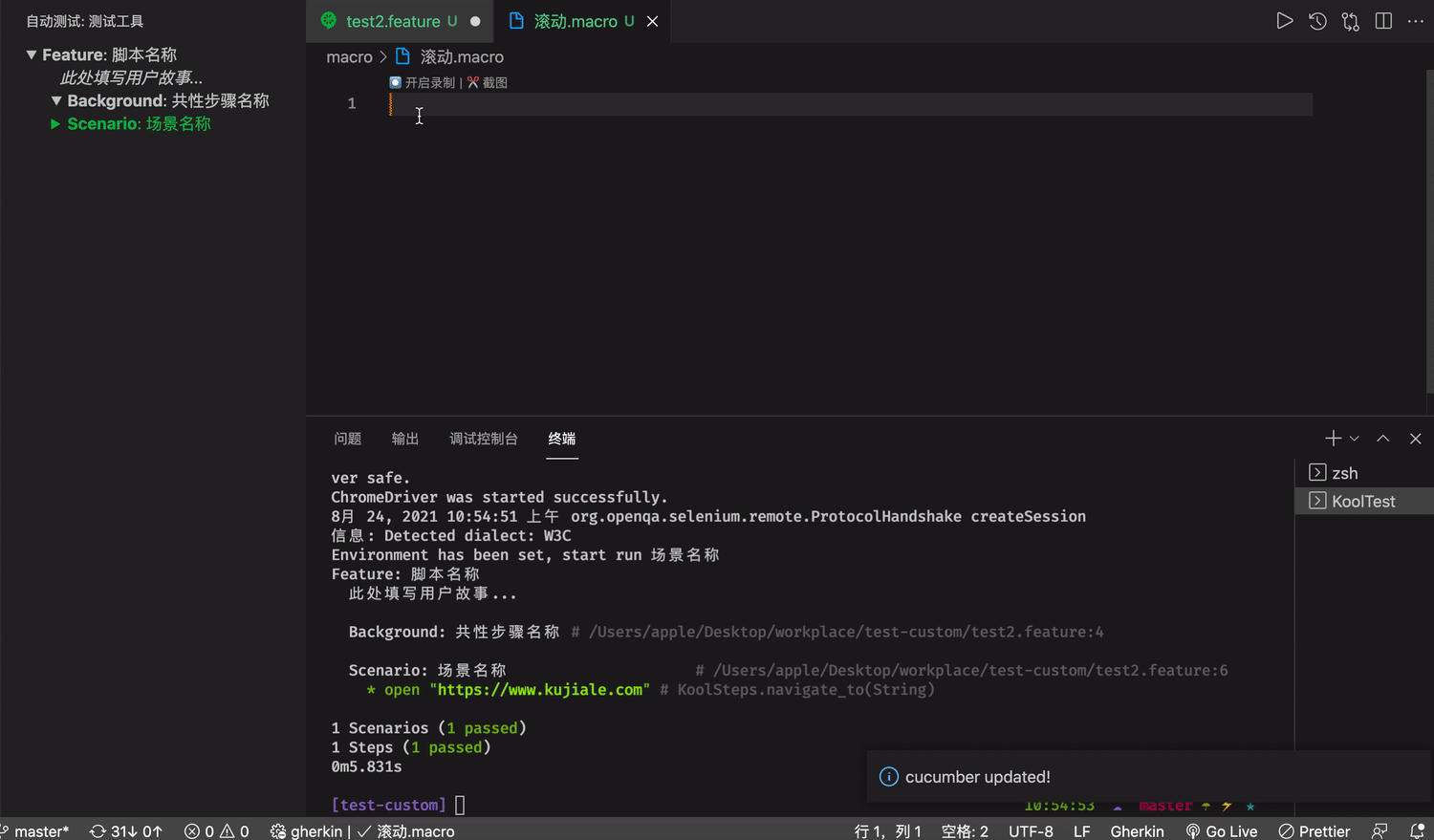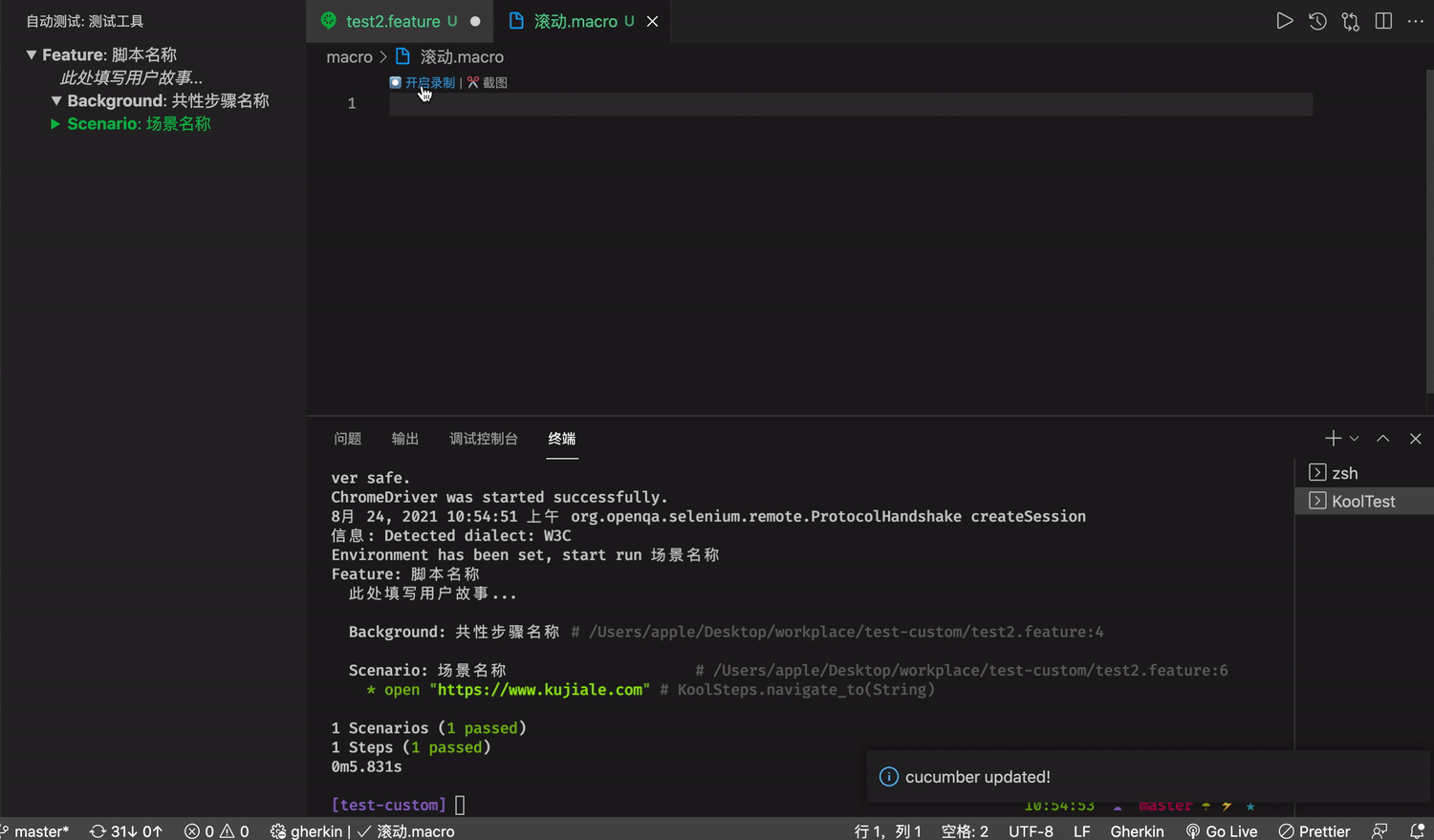
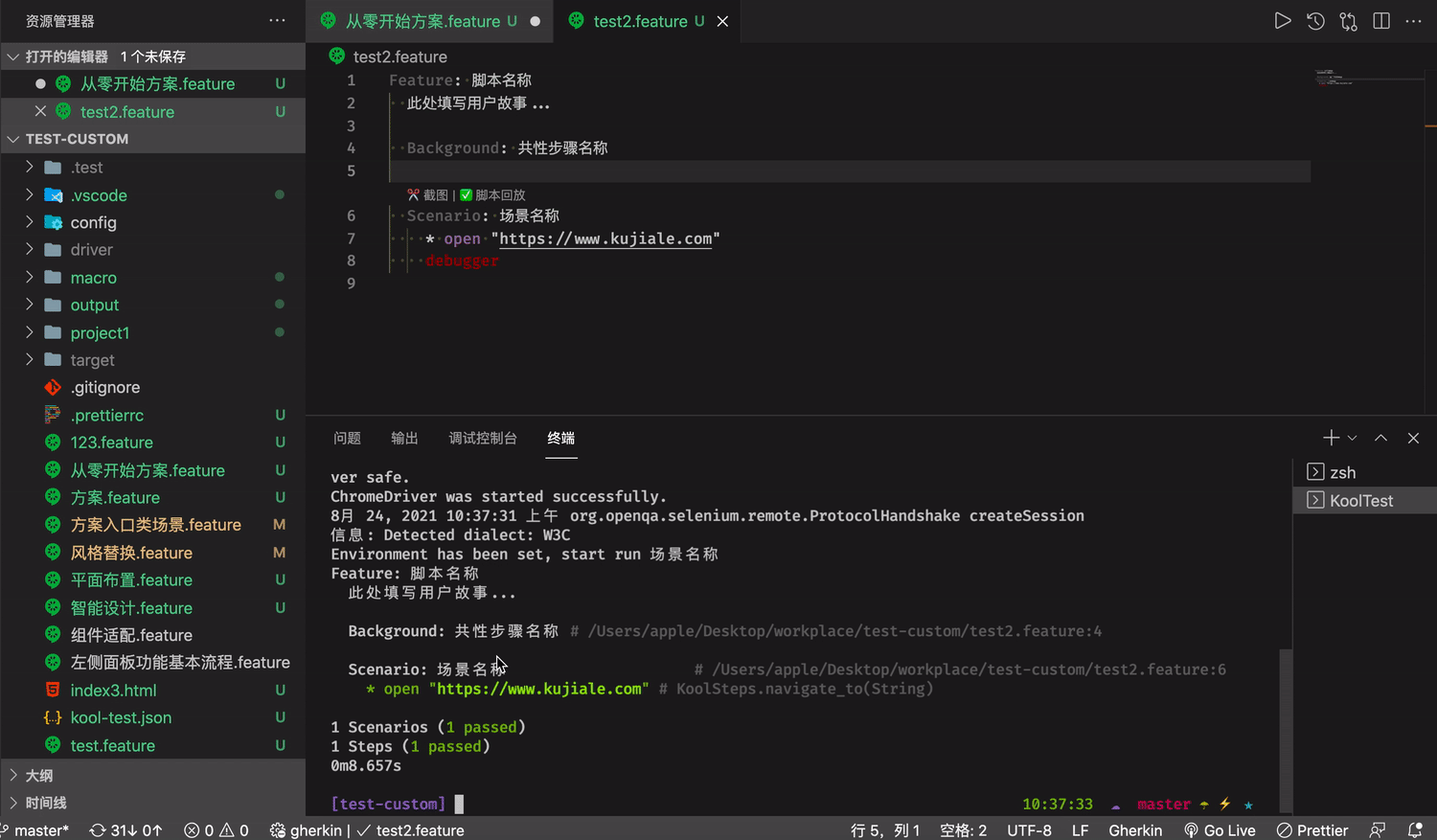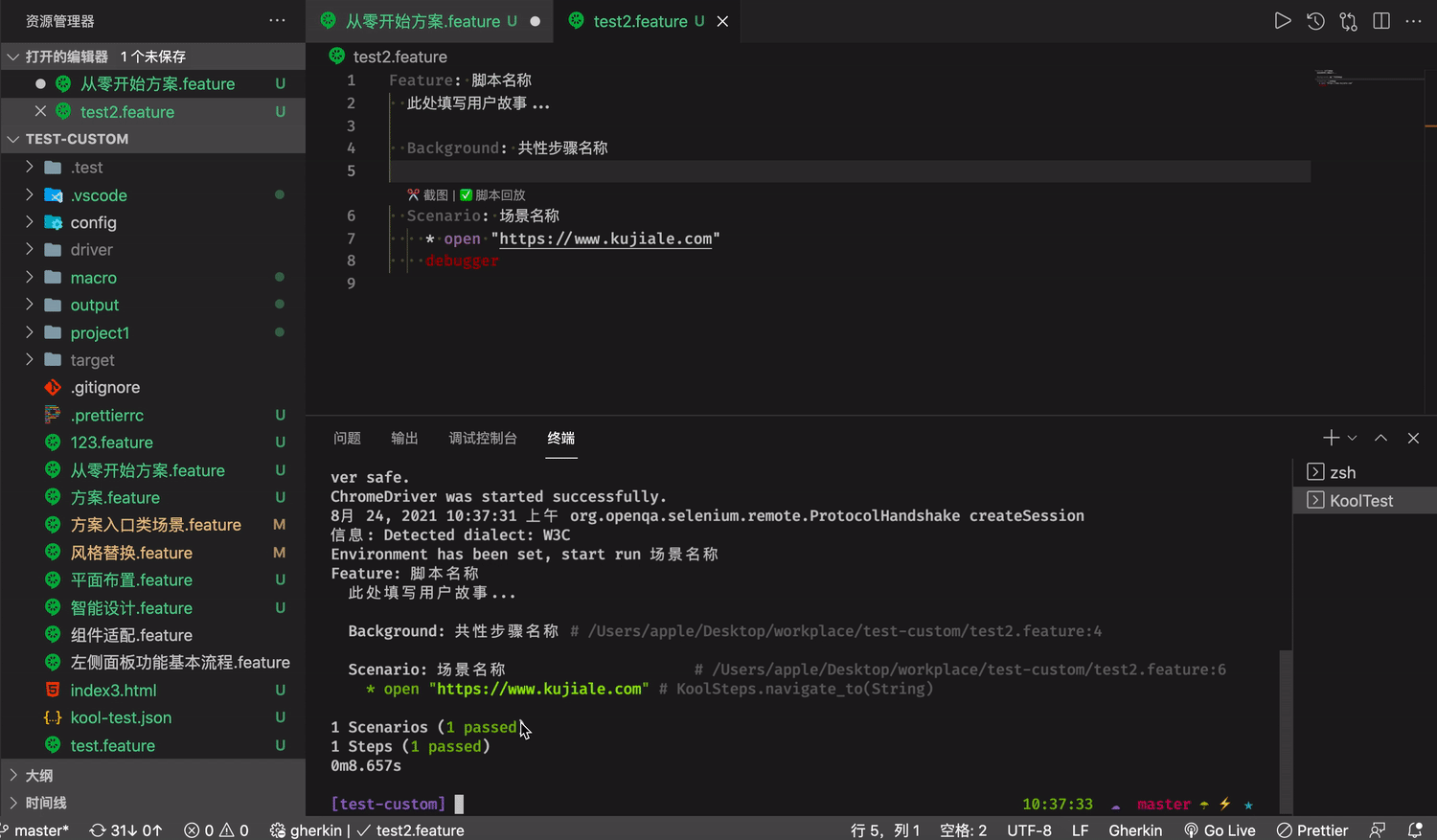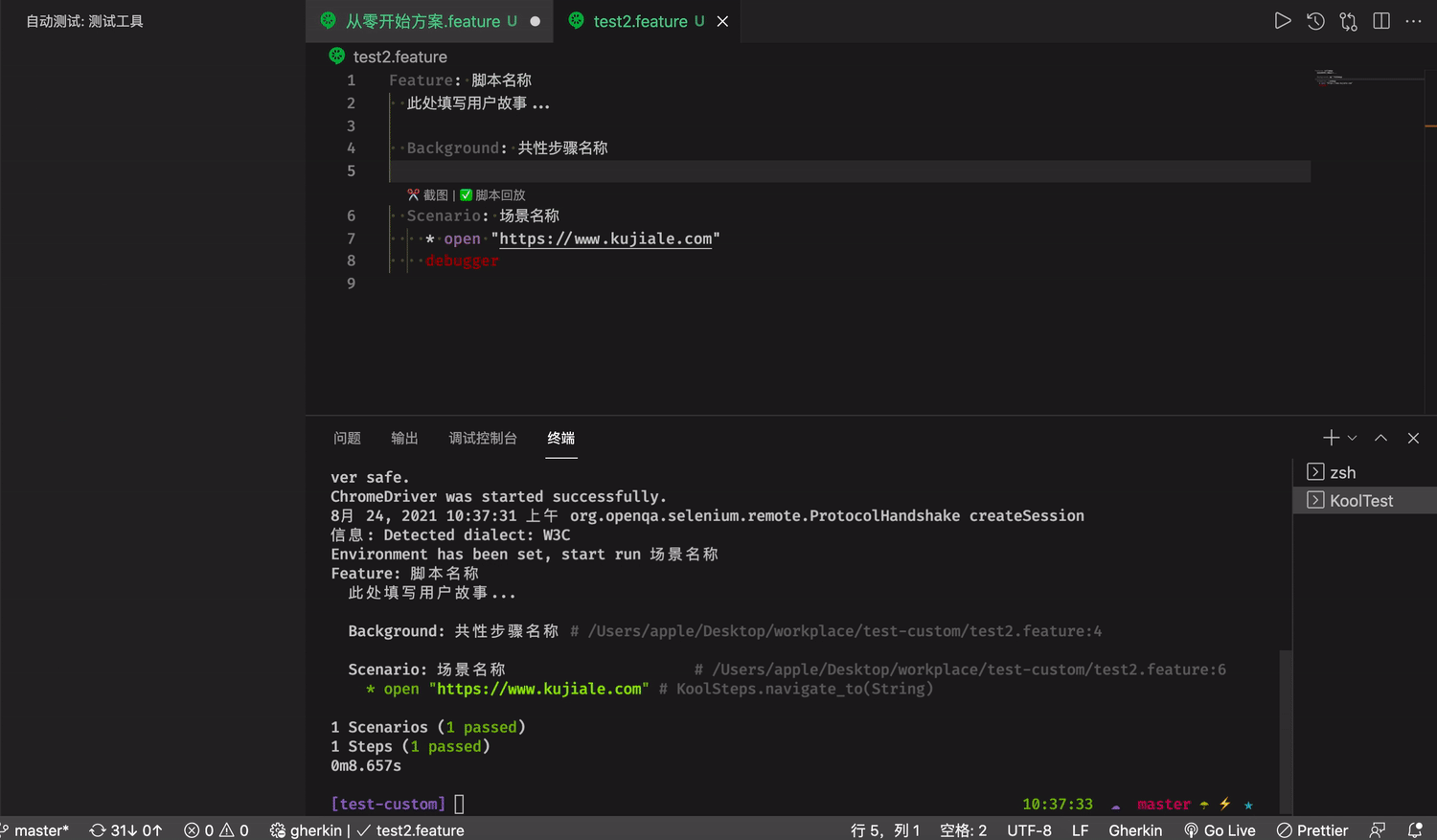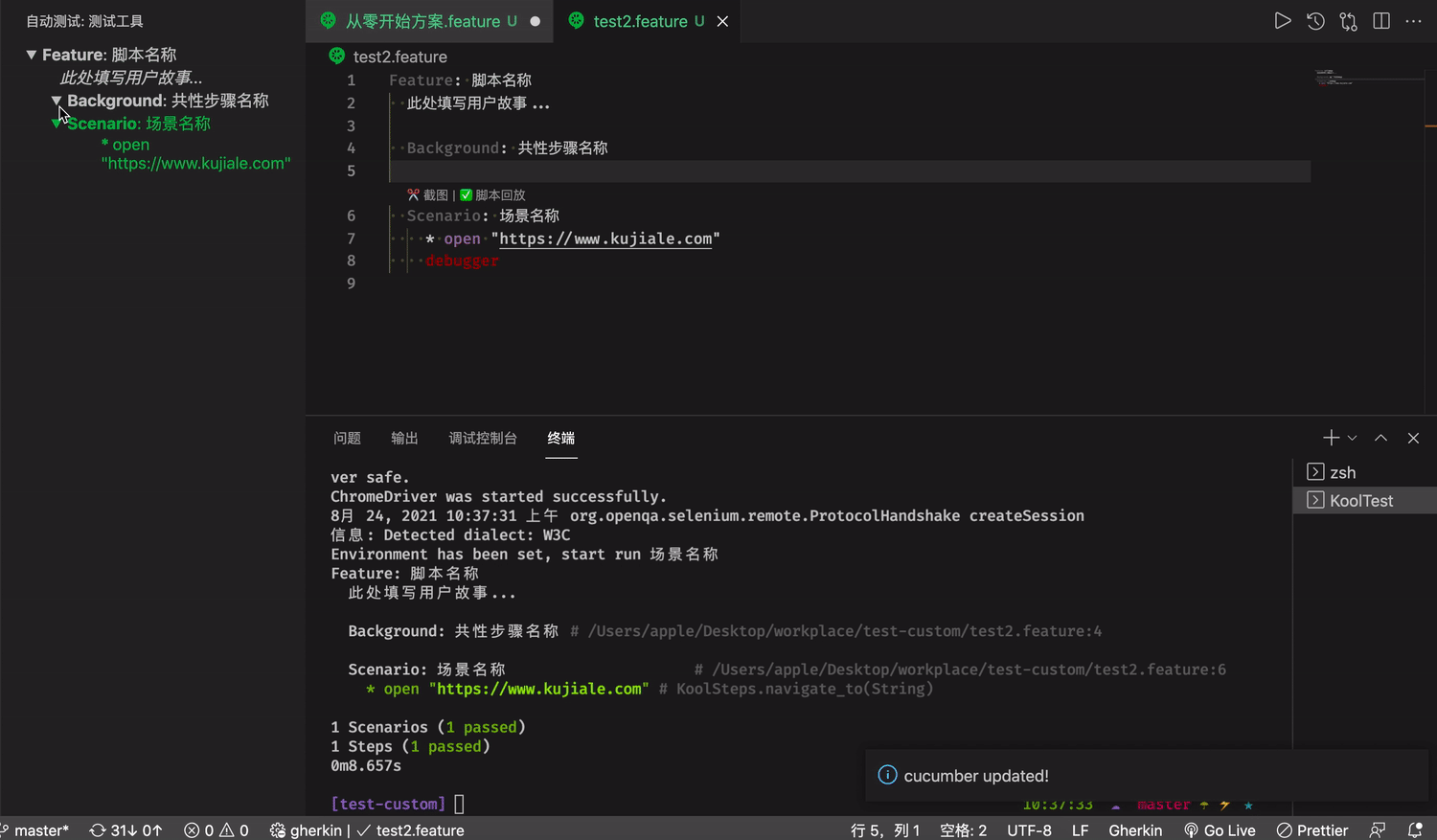
脚本核心文件 feature 可以在编辑器里直接运行脚本
自动填充模版
对于提供脚本复用能力的宏指令文件,我们提供了辅助录制键盘鼠标行为的能力。
Command + 鼠标点击自动跳转到对应 macro 文件
录制鼠标键盘的能力
运行脚本的时候,脚本会直接在 Terminal 上运行, 并记录如果脚本出错无法进行下去,代码会在哪个行为出错,定位到脚本具体的行为。
在结束进程之后,kooltest 脚本会自动生成对应日志文件。
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。
你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
var twoSum = function(nums, target) {
for(var i = 1;i<nums.length;i++){
if((nums[0] + nums[i])===target){
return [nums[0],nums[1]]
}
}
nums.shift()
if(nums.length === 1){
return false
}
return twoSum(nums,target)
};返回的是[2,7],觉得自己想到了递归还是挺好的,就记录下来了。
var twoSum = function(nums, target) {
for(var j = 0;j<=(nums.length-1);j++){
if(i===(nums.length-1)){
return false
}
for(var i = j + 1;i<nums.length;i++){ // 这里注意 i=j+1 否则会有索引相同的情况
if((nums[j] + nums[i])===target){
return [j,i]
}
}
}
};这个好理解,下一个。
function c(b, b) { return b }
c(1, 2) // 2
"use strict"
function cd(b, b) { return b } // 严格模式下报错
// Duplicate parameter name not allowed in this context实际上,使用 es6 函数语法的时候无论是否严格模式 ,这一条都成立。
let a = (b, b) => b // 箭头函数不管有没严格模式都是不允许同名属性得
// Uncaught SyntaxError: Duplicate parameter name not allowed in this context
// 使用默认参数的时候也会报错
// 不报错
function foo(x, x, y) {
// ...
}
// 报错
function foo(x, x, y = 1) {
// ...
}
// SyntaxError: Duplicate parameter name not allowed in this context我也没用过 with 语法:)
所以搜索了点资料。为什么不用 with 呢?主要是性能问题。发现在 vue2 里尤大也有用到它 with
// 示例代码:
var foo = 1;
var bar = {
foo : 2
}
with (bar) {
alert(foo);
foo = 3;
alert(foo);
var foo = 4;
alert(foo)
}
alert(bar.foo);
alert(foo);
if(true){
foo = 5;
}
alert(foo);
// 2, 3, 4, 4, 1, 5简单来说如果 foo 在 bar 里,就会对 bar 里的 foo 进行修改,而全局的 foo 不会发生修改。
如果 with 里的变量,在 with 定义的局部环境里没有,就会上升到高一层的环境寻找,而且会对其进行修改。
var foo = 1
var bar = {}
with(bar) {console.log(foo); var foo = 3 }
console.log(foo);
// 1, 3只读属性,包括 const,Object.defineProperty 的 writable: false。
另外,对一个使用 getter 方法读取的属性进行赋值,会报错。
"use strict"
var a = 0100
// Uncaught SyntaxError: Octal literals are not allowed in strict mode.如果想要使用八进制数字,可以使用 es6 的新语法。
二进制 0b,0B
八进制 0o,0O => 0o100
十六进制 0x,0X(不是 es6 的)
用来提醒宿主环境需要安装什么依赖,如果宿主环境有这个依赖,将会跟宿主公用对应依赖
会在这里记录我最近看到的好文章好blog
最近因为业务需要,为我们自己的 DSL 语言赋能,在 vscode 的插件开发上花了不少的精力。近期开发已告一段路了,因此小结一下开发中遇到的一些问题和解决方案。
下面我会介绍一些官方文档没有教但是我们在开发 vscode 插件可以实现的能力。
左侧栏开发,除了官方定制化提供的 TreeView 组件,我们其实还可以通过自己开发 webview Provider 来为左侧栏提供更灵活的功能。
export class SidebarProvider implements vscode.WebviewViewProvider {
_view?: vscode.WebviewView;
public async resolveWebviewView(webviewView?: vscode.WebviewView) {
this._view.webview.html = webviewView
return;
}
refresh() {
this._view.webview.html = fs.readFileSync('index.html')
}
}resolveWebviewView 会返回传入一个被劫持的 webview 对象,我们只需要在后续给这个 webview 对象赋值,即可完成刷新操作。
但是需要注意的问题是
let html = fs.readFileSync(path, "utf8");
html = html.replace(
/(<link.+?href="|<script.+?src="|<img.+?src=")(.+?)"/g,
(m, $1, $2) => {
return (
$1 +
vscode.Uri.file(
path.resolve(path.resolve(path1 || "", ".test", "cucumber"), $2)
)
.with({ scheme: "vscode-resource" })
.toString() +
'"'
);
}
);import * as puppeteer from "puppeteer-core";
const findChrome = require("carlo/lib/find_chrome");
let browser: puppeteer.Browser;
class Spider {
async buildPage({ url, timeout = 500 }: { url: string; timeout: number }) {
if(!browser) {
let findChromePath = await findChrome({});
let executablePath = findChromePath.executablePath;
browser = await puppeteer.launch({
executablePath,
headless: true,
});
}
const page = await browser.newPage();
await page.goto("file://" + url);
if (timeout) {
await page.waitFor(Number(timeout));
}
return page.content();
}
}
export default new Spider();除了直接提供具体的 html string,我们也可以通过跳转本地服务来实现 webview(ps. 这种重定向手段仅支持跳转 localhost 页面,外网域名并不被允许)
这里我们可以参考 slidev-vscode
<script>
window.addEventListener('load', () => {
location.replace(${JSON.stringify(url)})
})
</script>官方有提供 output channel 作为插件输出日志的地方。只需要维护一个channel 实例,往channel 中 push string,即可为你的插件打造一个输出日志的系统。
但是 Channel 相对来说会有不少坑,特别是在监听 child_process 的情况。所以个人建议使用的时候把它当做查看 console.log 的地方,而不是用它来监听子进程的使用情况。(可以参考 code runner 因为无法解决中文乱码问题,额外提供了 terminal 运行脚本的配置项)
this._outputChannel = vscode.window.createOutputChannel("myChannel");
this._outputChannel.appendLine('hello world');在需要运行子进程的业务场景,更合适的使用方法是,创建新的 termianl 直接在其之上运行。一方面可以解决上面中文乱码的,另一方面支持彩色输出,支持手动中断进程,也能提高用户的使用体验,而不是在无感知的情况下获取 output。
const command = 'node index.js'
let terminal = store.getTerminal();
if (!terminal) {
terminal = vscode.window.createTerminal("myTerminal");
store.setTerminal(terminal);
}
terminal.show();
terminal.sendText(command);我们可以通过 vscode.workspace.onDidCreateFiles 这个钩子监听在工作区中,新增了什么文件,这样我们就可以实现新建文件,自动填充模版的功能。例如 appworks 就实现了,生成 react 文件,自动填充 ice react 模版的能力。
vscode.workspace.onDidCreateFiles(async ({ files }) => {
await Promise.all(
files.map(async (file) => {
const { fsPath } = file;
const isValidateType = checkIsValidateType(fsPath);
if (isValidateType) {
await filContent(fsPath);
}
})
);
});没想到吧,微软出的产品在 windows 中坑巨多。
大部分 vscode 内置的路径在 windows 中都会有不同的问题,前缀可能会多一个 / 或者多一个 c://
在 windows 中 output channel 输出中文,经常会出现乱码。而且因为不支持彩色字体,如果记录 child_process 的输出信息,需要通过正则把代表颜色的字段去掉。
function stripcolorcodes(strWithColors){
return strWithColors.replace(/\x1B\[([0-9]{1,2}(;[0-9]{1,2})?)?[m|K]/g, '');
}ps. 想学怎么给字段加颜色 可以参考 https://github.com/marak/colors.js/
在 windows 中自动新建 terminal 会自动根据 vscode 配置的 [terminal.integrated.automationShell.windows](http://terminal.integrated.automationShell.windows) 来指定运行路径,但是由于 window 跟 osx 的路径分割符号不一致( mac 中开发是 '/' 和 windows 是 '' ),如果使用 cmd 或者 powerShell 运行没有问题,但如果使用 git bash 就会报错,所以要注意把 git bash 修改为其他运行方式。
失败方案1:
var trap = function(height) {
let sum = 0
let max = 0
let num = 0
let newList = [...new Set(height)].sort((a,b) => a - b)
let lastArr
let lastnum = 0
max = newList[newList.length - 1]
while (newList[num] <= max) {
lastArr = lastArr ? getNewArr(lastArr, newList[num]) : getNewArr(height, newList[num])
lastnum = num > 0 ? newList[num - 1] : 0
lastArr.forEach((ele) => {
let cut = ele - lastnum > 0 ? ele : lastnum
let add = newList[num] - ele > 0 ? newList[num] - cut : 0
// console.log(getNewArr(height, newList[num]), add)
sum = sum + add
})
num ++
}
return sum
};
var getNewArr = function(arr = [], height = 1,) {
let l = 0
let r = arr.length - 1
while (l <= r) {
if (arr[l] >= height && arr[r] >= height) { arr = arr.slice(l, r + 1); break}
if (arr[l] < height) { l++ }
if (arr[r] < height) { r-- }
}
return arr
}失败方案2:
var trap = function(height) {
if(height.length === 0){ return 0}
let sum = 0 // 结果
let newList = [...new Set(height)].sort((a,b) => a - b) // 升序的数组
max = newList[newList.length - 1]
let map = getNewArr(height, newList)
sum = getSum(newList, map, height)
return sum
};
function getSum(newList, map, arr, lastnum = 0) {
var len = newList.length;
let lr = map[newList[0]]
let sum = 0
lastArr = arr.slice(lr[0], lr[1] + 1) // 获取过滤后的数组
// lastnum = num > 0 ? newList[num - 1] : 0 // 上一轮的高度 如果等于num等于0 那么上一次的高度应该是 0
lastArr.forEach((ele) => {
let cut = ele - lastnum > 0 ? ele : lastnum
let add = newList[0] - ele > 0 ? newList[0] - cut : 0
sum = sum + add
})
if(len == 0){
return 0;
} else if (len == 1){
return sum;
} else {
return sum + getSum(newList.slice(1), map, arr, newList[0]);
}
}
var getNewArr = function(arr = [], sort) { //过滤掉左右不需要的值 获得一个高度的映射
let obj = {}
let l = 0
let r = arr.length - 1
let num = 0
while (l <= r) {
if (arr[l] >= sort[num] && arr[r] >= sort[num]) { obj[sort[num]] = [l, r] ; num++; if(num === sort.length) break }
if (arr[l] < sort[num]) { l++ }
if (arr[r] < sort[num]) { r-- }
}
return obj
}23种模式,慢慢看书,慢慢写。
书籍是JavaScript设计模式与开发实践
在亚马逊买了电子书,资源就不上传了,支持正版。
void是一个运算符,void 后面无论是接数字还是字符串最后都会返回 undefined。
在很多的源码,或者压缩后的代码中都能看到 void 0,这种代表 undefined 的写法。
居然是因为 void 0 比 undefined 短。能省很多个字节!所以为了让包更小,所以才有 void 0 代替 undefined。
openlayer 是一个比较小众的 gis 框架,这里要说的是,它集成的 heatmap 模块。
首先,我们可以从官网看到。新建一个 heatmap 图层,我们有很多配置项,通过这些配置项,我们可以配置出来的效果,如:redius , opacity , blur , source。通过 redius 我们可以调节热力图点扩散的范围,opacity 可以控制图层的透明度, blur 可以控制热力图热度深浅。本文我们来重点说一下,它的source。
module.exports = function stripcolorcodes(strWithColors){
return strWithColors.replace(/\x1B\[([0-9]{1,2}(;[0-9]{1,2})?)?[m|K]/g, '');
}这篇文章里,我们会通过一些简单的案例来说明 call(),apply() 和 bind() 三种方法的区别。函数也是JavaScript中的对象,所以就有了这3个方法来控制函数的调用。call() 和 apply() 是 ECMAScript 3的语法,而 bind() 则是 ECMAScript 5才加入到 js 的大家庭里。
//Demo with javascript .call()
var obj = {name:"rottenpen"};
var greeting = function(a,b,c){
return "welcome "+this.name+" to "+a+" "+b+" in "+c;
};
console.log(greeting.call(obj,"aaa","bbb","guangzhou"));
// 输出 welcome rottenpen to aaa bbb in guangzhou
先上模版代码
const dfs = () => {
if (到达终点) {
// something
return
}
if (越界or不合法){
return
}
if (剪枝) {
return
}
for (遍历) {
if (合法判断) {
// something
dfs() // 递归
}
}
}一开始这篇总结是打算在刚拿到 offer 的时候写的,然后拖着拖着3个月过去了,拖到现在。来抖开也快2个月了,而离我从广州来杭州工作也正好准备两年,就写一下关于我来杭漂这两年吧。
其实选择杭漂没啥浪漫的理由可讲,20 年的时候简历写的太烂,广州的中大厂都不要我,算法刷了 300 题,简历都没过。正好酷家乐要了我,我就选择来了杭州,如果说还有什么其他因素,顶多就是死党在杭州毕业后每年都会来杭州一次找他玩,正好 2020.5.20 来看他求婚,6月就拿到 offer 了。
在酷家乐这一年多,可以说是闲但折腾的一段时间,在酷家乐这种重 pc 应用的公司里,小程序是很难把蛋糕做大的。虽然说组的核心业务是给公司的微信生态做基建做中台,但为了能让我们组活下去,我们什么任务都可以做。短短的 21 年我写过自动化测试平台,写过后端,写过 sketch 插件,写过 vscode 插件。可以说是身在小程序基建部门,除了小程序什么都写。
前面这一段,听起来像是抱怨,但相对于百日如一的curd来说,酷家乐给了我很多把想法落地的土壤。无论是能力还是视野都有了十足的提升,这种视野不光是技术上的,还有业务上的。在资金流焦虑的公司,你开发的每个技术项目都应该提前作出预判,这个产品价值在哪里,有没有可能商业化,这时候你就要主动或者被动去研究竞品了。我理解这种技术外的积累,才有可能帮助开发摆脱头上头上那把 35 岁的达摩克斯之剑。
从酷家乐跳过来抖音的计划是在,21年年底萌生的,那时候其实想法比较简单,看到嘤嘤发招聘帖,正好上面写的东西我都 match,以前也对接过开平这边的接口,留在酷家乐22年也未必能晋升,赶紧润吧,就吭呲吭呲开始准备了。直到年初面拼多多,虽然面试是通过了,但其实收到的反馈是,技术广度不错,技术深度不够。也是这个阶段我才意识到,技术自嗨是不够的,需要更多的人去验证,需要有更多的人去 agure ,技术深度才能成长起来,这也更坚定了我要换坑的决心。
值得一提的是拼多多是我最开始用来练手的公司,但后面因为面试体验太好,面试官表现出来的职业素养太强,让我一度在抖音和拼多多之间纠结应该选哪个 offer,如果我不是 base 杭州,我应该会选择拼多多(然后现在就被关在上海了:( )。经历了拼多多地狱级别的面试难度,接下来的面试就比较轻松了,后面面小红书(面的部门正好最近裁员了),米哈游,抖音,相对来说都不是很困难。(还有一家外企,hr面完就没下文的,可能是嫌弃我英语渣渣吧)这段时间需要特别鸣谢的是我的好朋友 ljf,这段时间给了我很多技术答疑和精神上的鼓励。
整体来说,这一年多对我来说成长还是蛮大的吧,可能从做过的业务上没有得到公司的认可,但至少招聘市场对我的能力是认可的~
就跟前端的大部分框架/工具一样,给生活多留一点勾子,不是坏事。这两年断断续续有在开源社区输出一点自己的东西,不一定有很大作用,但从个人经历来说,一方面简历能好看一点,另一方面这个输出过程就是自己学习最佳的方法。
接下来的一年,我想给工作外的事情多留点 hook ,做一些自己的 side project,看看能不能产生一点被动收入。学一下 web3,如果哪天被毕业了,总得找个新方向继续折腾下去。当然开源社区我还是会继续做贡献的。
生活中多了一个对外来说非常非常重要的新成员(我对象)。在她出现之前,我在杭州的个人生活用孤儿形容不为过,没有社交,和好朋友见面起码有一个小时车程。以至于我对这个城市毫无认同感,交通稀烂,美食荒漠是这个城市的底色。我在遇到她之前更多的念想就是,把能力准备好赶紧再跳回广州。
她的出现改变了这一切。我们一起探店,一起旅行,一起爬山,一起看日落,看演出,看画展,我们开始经营我们的小出租屋,有了我们新的家庭成员小13——一只不太聪明的布偶猫。她是我的伴侣,是我的好朋友,是我的导师,是我的灯塔。慢慢地我对这个城市也有了点归属感,开始决定我要在这个城市驻扎下去。
也没啥展望的,就是升职加薪,side project 一切顺利,对象能拿到心仪的校招 offer 吧,以上。
这篇文章是我之前小程序使用 Taro 和原生混合开发方案的探索的后续。
主要要讲的是,在我们解决了旧的原生代码通过 Taro 和原生混合开发的方案,低成本把旧代码迁移到 Taro 环境后,我们遇到的问题以及我们的一些技术思路和开发方案,希望我们的经验能带给大家一点启发。特别是受困于原生小程序迁移 Taro 的小伙伴一点帮助。
主要内容分成几个部分:
1)当前的方案及其解决的问题。
2)我们中间运用到的一些不太优雅但无可奈何的小手段。
3)后续迭代的思路和想法。
如果说在 pc 端微前端的方案是为了解耦不同历史依赖,那么在内存有限性能有限的小程序开发中,我们要处理的第一件事情就是要统一不同技术栈之间的依赖。在我们设计的混合开发方案当中,旧包的依赖是直接复制到新包的,这就会造成有些依赖在新旧包之间重复引入,在寸土寸金的小程序中这种内存的浪费是致命的。
App.js 是一个很好的资源共享池,所以我们决定以原生代码的 getApp 作为共享资源的入口,让原生代码的依赖,都集中到 getApp 处引入,让原生代码能直接引入新代码依赖。
// 新包的 app.js 需要传入原生代码目录的名字。
require('./mixin')('sample');
// mixin.js
module.exports = nativeDirName => {
const oldApp = App;
let options;
App = option => {
options = option;
};
(function() {
require(`./${nativeDirName}/app.js`);
})();
App = oldApp;
const oldGetApp = getApp;
let res = Object.assign(options, oldGetApp(), {
...需要被新代码覆盖的资源
});
getApp = () => {
return res;
};
};
随后我们就遇到了下一个问题,我们需要确认哪些资源是可以共享的,哪些资源是要被覆盖的,哪些依赖已经被更新了,但用法不兼容的。
新版本的更新迭代,旧包还是不可避免要进行修改。在这个问题上只能去权衡,哪些页面需要继续使用旧代码,哪些页面适合重写。
一个好的方案不是一蹴而就的像混合方案的插件为了降低使用成本,也经历了好几次迭代,现在已经把原本的 webpack 转换成内置 copy 的 taro 插件了。好事多磨,我们的混合方案未必能满足大家混合开发的需求,不过希望能给大家一点启发。

最近给 appworks/tooltik 写 pr 顺便学一下怎么写 electron,发现官方并没有提供数据缓存的方案,就是大家自由发挥。
下面要说的 lowdb.js 是 一个基于 JSON 的非关系型数据库。它提供了一些很简单的 CURD 功能,只需要传入你希望存放的文件路径。与其说它是数据库,我更觉得它是一个提供类数据库操作方法的 file system。而且它在大部分情况下,不提供兜底能力,例如在 electron 打包安装后,在新环境里没有db文件,需要自己手动创建db文件。
import { join } from 'path'
import { Low, JSONFile } from 'lowdb'
// Use JSON file for storage
const file = join(__dirname, 'db.json')
const adapter = new JSONFile(file)
const db = new Low(adapter)
// Read data from JSON file, this will set db.data content
await db.read()
// If file.json doesn't exist, db.data will be null
// Set default data
db.data ||= { posts: [] }
// Create and query items using plain JS
db.data.posts.push('hello world')
db.data.posts[0]
// You can also use this syntax if you prefer
const { posts } = db.data
posts.push('hello world')
// Write db.data content to db.json
await db.write()一开始打算参考how-to-use-react-in-your-sketch-plugin的方案配,但是也许是 skpm 的版本不一致,遇到了多路径入口只读 default 的问题,在配置 TS 的时候遇到了不少问题。
最后放弃了一起构筑的方案,React webview 单独抽离打包,最后通过 shell 脚本打包。
VSCode 插件在 kooltest 自动化测试的开发实践
薅一手 Github Actions 自动发包 VSCode 插件
打卡了 23 天
看了一场话剧《伤心咖啡馆之歌》。
年度体检,毛病还是去年的毛病了,多了两个慢性病,希望能通过养成好习惯治好。

因为字体小于 12px 了,chrome 默认显示字体最小 12px
bookmark
飞书题库:https://bytedance.feishu.cn/base/app8Ok6k9qafpMkgyRbfgxeEnet?table=tblLUxZFqOA2vI2F&view=vewBdzCHZd
钉钉前端团队: https://juejin.cn/post/6986436944913924103
手写代码:https://gitee.com/zhufengpeixun/java-script_-test_1887/blob/master/README.md
每日一题插件(题库来源: 珠峰架构): https://github.com/everest-architecture/front-end-daily-question
京城一灯题库: https://lgwebdream.github.io/FE-Interview/daily/
木易杨题库: https://github.com/Advanced-Frontend/Daily-Interview-Question/issues
TypeScript 跳操: https://github.com/type-challenges/type-challenges
挖坑
这里要感谢一下 张仁阳老师 每天为我们提供的面试题。
上传接口需要上传 zip 文件的同时对 zip 文件进行解压上传。接下来我会介绍一下整个上传服务的优化过程。
首先我们来看一下,单文件上传,是怎么实现的(因为 sketch 插件的 formdata 是三方开发的,这篇指南中没有用到任何 formdata 的 request payload)。
const app = express();
app.post("/upload", (req, res) => {
// 因为 body 都用来放文件的 bufferArray
const fileName = req.query.fileName;
const TEMP_DIR = path.resolve(__dirname, "..", "tmp");
if (!fileName) {
res.status(400).json({ c: "-1", m: "query 缺少 fileName!" });
return;
}
const chunkDir = path.resolve(TEMP_DIR);
const prefix = +new Date();
const fn = `${chunkDir}/${prefix}/${fileName}`;
// fs-extra 提供的确认文件夹有没有生成
fs.ensureDirSync(chunkDir);
fs.ensureDirSync(`${chunkDir}/${prefix}`);
// 生成一个可写流 fn是可写流的写入路径
const stream = fs.createWriteStream(fn);
// 通过pipe 把整个 request body 写入可写流
const pipfile = req.pipe(stream).on("error", () => {
res.status(400).json({ c: "-1", m: "上传失败,接收文件失败" });
});
// close 的时候,可写流结束,文件成功生成了
pipfile.on("close", () => {
try {
// 上传到 cos,里面如果上传成功就通过
// res.send({ c: "0", d: response, m: "ok" }) 返回结果
upload(res);
} catch (error) {
res.status(400).json({ c: "-1", m: error });
}
});
});上面就是一个单文件上传接口的实现,简单总结一下它都做了什么:
这种实现有什么问题呢?
上传大文件时间太长,有可能造成超时。
然后我改成了分片上传,分片上传不是
即使我们使用了分片上传,我们依然没法解决接口阻塞问题,在上传过程中,有新的请求接入,需要等上传的 callback 完成之后。我一开始想到的是,难道网络请求的异步 I/O 也能阻塞整个进程吗?于是我把上传的部分放到 worker 上运行,效果显著,马上不阻塞了。
但是明明上传操作应该是异步请求,为什么会阻塞呢?
看了一下,原来是在读取文件信息的时候,我们封装的 cos sdk 用到了很多同步操作。

当文件数很多的时候就会阻塞我们的请求了。原来凶手在这⬆️ (ps. 除了同步 fs 还有很多打 log 的操作,console.log 也是一个同步阻塞的 io 操作,从下图可以看出,log 的性能不比 readfile 好多少)

上面我们分析了,一个上传接口怎么写,如何进行分片,如何处理 I/O 密集型任务。本来故事到这里应该就完,但是我在写这篇分享的时候,一时之间陷入了迷思,为什么异步 I/O 会阻塞请求新请求的回调呢?接收请求的回调是微任务还是宏任务呢?
先做一个小实验。
const { EventEmitter } = require("events");
let ee = new EventEmitter();
ee.on("log", console.log);
for (let i = 0; i < 1000; i++) {
Promise.resolve().then(() => console.log(i))
if ((i === 50)) {
ee.emit("log", `---------${i}`);
}
}这段代码的结果是, ——--50 比 console.log(i) 更早打印出来。其实如果有自己手写过 eventEmitter 的同学都知道,其实 emit 方法只是调用以下哈希表里对应的方法而已,这个方法是同步的,因为 node 的 http 模块是基于 event 的,express 的 listen 也是基于 event 的,我们是不是就可以得出他们的请求也是同步的结论呢。
OK,下面我们跳出日常浏览器宏任务微任务的八股。来看看 node 环境下的 Event loop (以下出自 node 官方文档: https://nodejs.org/zh-cn/docs/guides/event-loop-timers-and-nexttick/):
当Node.js启动时会初始化event loop, 每一个event loop都会包含按如下顺序六个循环阶段:

setTimeout() 和 setInterval() 的调度回调函数。setImmediate() 调度的之外),其余情况 node 将在适当的时候在此阻塞。setImmediate() 回调函数在这里执行。socket.on('close', ...)。我们通过两段异步操作的代码来深入我们对 node eventLoop 的理解。
setTimeout(() => {
console.log('timer1');
Promise.resolve().then(function() {
console.log('promise1');
});
}, 0);
setTimeout(() => {
console.log('timer2');
Promise.resolve().then(function() {
console.log('promise2');
});
}, 0);OK,我们再来看看下一段代码
const fs = require("fs");
setTimeout(() => {
console.log("timer1");
fs.readFile(__dirname + "/" + __filename, () => {
console.log("fs1");
});
}, 0);
setTimeout(() => {
console.log("timer2");
fs.readFile(__dirname + "/" + __filename, () => {
console.log("fs2");
});
}, 0);第一段代码在不同版本的表现是不一样的。
在 node 10 中,第一段代码的结果是
timer1 timer2 promise1 promise2
因为 node 会优先把 timer 队列清空再执行微任务的 nexttick 队列。
而在 node 11 后,我们得到的结果是。
timer1 promise1 timer2 promise2
仔细去翻node的修改日志,在node 11.0 的修改日志里面发现了这个:
也就是说 nextick 队列会在每一个 timer 和 immediate 后执行。也就是说微任务队列会在,每一次执行 settimeout , setImmediate , setInterval 的 callback 后执行。
下面我们来看看他是怎么实现的 ( 参考PR https://github.com/nodejs/node/pull/22842/files#diff-5a0457600721c223f1ed7184ef7d1d2617f4552a5341b53a49b284f808981724)

这是一个遍历 timer 队列的函数,当 while 循环执行了一次之后,ranAtLeastOneTimer 会变为 true ,然后执行 runNextTicks() 即立即执行微任务队列。
如果我们想在 node 10 中也能看到类似的效果,我们可以:
setTimeout(() => {
console.log('timer1');
Promise.resolve().then(function() {
console.log('promise1');
});
process._tickCallback(); // 这行是增加的!
}, 0);
setTimeout(() => {
console.log('timer2');
Promise.resolve().then(function() {
console.log('promise2');
});
process._tickCallback(); // 这行是增加的!
}, 0);OK,接下来就是垃圾时间了我们来看看第二段代码的结果。
timer1 timer2 fs1 fs2
fs1 fs2 是在 poll 阶段执行的,它们在执行完 timer 之后需要一段时间的异步 I / O 才能被执行。
所以回到上面我的迷思,网络请求的异步回调虽然是基于 event 机制实现的,但它其实是在 poll 阶段被异步执行。发送过来的请求被阻塞是因为我之前打太多 log 以及 fs 同步调用被阻塞。Worker 在一定程度上解决了同步阻塞的问题,但生成线程的开销也不容忽视,在非阻塞的情况下使用 Worker 并不是一个很好的方案。
当我们希望把云下的数据迁移到云上时,我们可以使用 pg_dump 导出希望迁移/备份的数据库数据,通过以下命令,pg_dump 将会在当前文件夹下生成对应备份的 sql 文件。
## pg_dump [数据库名] -f [文件名]
pg_dump kooltest -f backup.sql数据导入
## psql -d [数据库名] -U [用户名] -f [文件名]
psql -d kooltest -U root -f backup.sql虽然 SQL 被我们导出了,但是对接公司的数据库并不成功,因为 pg 跟 mysql 在 sql 格式上还是有不少区别的。
方案很快捷,不过只支持 windows 不支持 mac / linux: https://www.dbsofts.com/articles/postgresql_to_mysql/
需要在 window 安装应用,先填写旧数据库的基本信息和数据库类型,后填写新数据库的基本信息和类型,点击 submit 即可完成迁移。
JSON 格式的数据会被转化成 LONGTEXT。
而且每张表都会多一个前缀是 trial 的 column,不过因为它可以为 null,这个缺点基本可以忽略。
幸亏之前有使用 ORM 来连接 pg,抹平了不少底层的数据差异,只需要修改基本的 db 信息,以及数据库类型即可。
new Sequelize({
database: 'db',
username: 'dbuser',
password: 'xxx',
host: 'ip地址', // 从旧ip地址改到新ip地址
port: 端口号,
dialect: 'mysql', // 原本是postgresql
pool: {
max: 10,
min: 0,
idle: 10000,
acquire: 30000,
},
timezone: '+08:00',
define: {
timestamps: true,
createdAt: 'created',
updatedAt: 'updated',
charset: 'utf8',
},
});
DataTypes.JSON -> DataTypes.TEXT这是最近技术分享整理出来的话题,内容大部分摘自阿里云,腾讯云官方文档。
CDN 的全称是 Content Delivery Network,即内容分发网络。CDN 是构建在 现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的 负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞, 提高用户访问响应速度和命中率。CDN 的关键技术主要包括了节点调度、节点负载 均衡和内容存储、分发、管理技术。
使用 CDN 加速前,用户侧发起的请求通过用户侧 DNS 递归到网站 DNS 解析 以后,最终用户侧直接请求网站服务器。这里可能会造成以下几种情况: 1. 中心服务器负载过高,因为所有客户端发起的请求都会请求到服务器上 2. 终端用户内容获取延时高,比如服务器在北京,而用户在广州 3. 服务稳定性差

详细说明如下:
www.test.com 下的某图片资源(如:1.jpg)发起请求,会先向 Local DNS 发起域名解析请求。www.test.com 时,会发现已经配置了 CNAME www.test.com.cdn.dnsv1.com,解析请求会发送至 Tencent DNS(GSLB),GSLB 为腾讯云自主研发的调度体系,会为请求分配最佳节点 IP。CDN的层级划分
边缘计算是一种分散式运算的架构,将应用程序、数据资料与服务的运算,由⽹络中⼼节点移往⽹络逻辑上的边缘节点来处理。将原本完全由中心节点处理⼤型服务加以分解,切割成更⼩与更容易管理的部分,分散到边缘节点去处理。边缘节点更接近于⽤户终端装置,可以加快资料的处理与传送速度,减少延迟。
https://www.aliyun.com/product/ens
https://cloud.tencent.com/product/ecm



下面摘自 ENS 的文档:
开通服务:您需要根据实际业务需求填写开通ENS服务的各项资料。
(可选)创建自定义镜像:阿里云ENS控制台支持通过镜像构建机方式创建自定义镜像,您可以将自定义镜像用于创建边缘服务或升级边缘服务镜像。
创建边缘服务:根据业务需求,您可以在控制台创建边缘服务,明确边缘算力配置、分布,ENS智能选择节点进行批量下发算力。
上线运营:业务测试通过后,正式上线运营。您可以通过ENS控制台管理边缘服务、启停边缘服务、更新镜像、查看用量、进行数据监控等。
防止将某些 import 的包(package)打包到 bundle 中,而是在运行时(runtime)再去从外部获取这些扩展依赖(external dependencies)。
https://www.webpackjs.com/configuration/externals/
module.exports = {
externals: {
react: 'react' // '包名':'全局变量'
},
plugins: [
new HtmlWebpackPlugin(/** 手动植入cdn 地址 **/
{
cdn: {
js: ['cdn地址']
}
}
)
]
}https://juejin.cn/post/6952702774644015141
SSG:Static Site Generation,静态网站生成

这样做有很多好处:
SSG 的模式比较适用于个人博客/技术文档这种页面数量有限,更新频率有限的网站。但不适用于网页较多,更新频繁的网站。
ISR:Incremental Site Rendering,增量式的网站渲染
既然全量预渲染整个网站是不现实的,那么我们可以做一个切分:
1、关键性的页面(如网站首页、热点数据等)预渲染为静态页面,缓存至 CDN,保证最佳的访问性能;
2、非关键性的页面(如流量很少的老旧内容)先响应 fallback 内容,然后浏览器渲染(CSR)为实际数据;同时对页面进行异步预渲染,之后缓存至 CDN,提升后续用户访问的性能。

页面的更新遵循 stale-while-revalidate 的逻辑,即始终返回 CDN 的缓存数据(无论是否过期);如果数据已经过期,那么触发异步的预渲染,异步更新 CDN 的缓存。

在开发vscode插件的过程中,我做了两套日志系统,一套是通过监听进程 output 封装的 vscode channel,但是这套日志系统还要负责监听不少其他来源的信息。所以我们做了第二套日志系统,通过左侧栏的 webview 展示专门用来可视化记录自动化测试进程日志的。
问题来了,vscode 对植入webview 有很多限制,静态资源需要在 html 字符串的路径上加入 vscode-resouce 协议,即原本路径是src="1.png" 要转成 src="vscode-resouce:1.png"。
通过
html = html.replace(/(<link.+?href="|<script.+?src="|<img.+?src=")(.+?)"/g我们仿佛解决了问题。
这时候新的问题来了,html 的 img 元素,我们都是通过 js 来生成的,这就导致我们的正则,无法修改img部分的路径,而 vscode 只会根据 html 提供的路径进行特殊处理。
正菜来了,我们遇到的情况,就好像很多 spa 网页都会先通过预渲染生成页面来解决 seo 的问题(方法还有很多, 就不展开了)。
但是市面上大部分方案都是基于 webpack plugin 做的,我们并不需要用到,干脆没有轮子,自己来造吧。
spa-prerender 选了6k+赞的第一个 prerender-spa-plugin,看到源码用到了 puppeteer 字眼的依赖。好的,懂了,不用继续看下去了。puppeteer 我们还不擅长嘛。import * as puppeteer from "puppeteer-core";
const findChrome = require("carlo/lib/find_chrome");
let browser: puppeteer.Browser;
(async () => {
let findChromePath = await findChrome({});
let executablePath = findChromePath.executablePath;
browser = await puppeteer.launch({
executablePath,
headless: true,
});
})();
class Spider {
async buildPage({ url, timeout = 500 }: { url: string; timeout: number }) {
const page = await browser.newPage();
await page.goto("file://" + url);
if (timeout) {
await page.waitFor(Number(timeout));
}
return page.content();
}
}
export default new Spider();这里用到了两个库,通过 carlo 可以寻找 Chrome 的绝对路径供 puppeteer-core 使用,这样我们就不需要下载 Chormium 增大包体积了。调用一下 buildPage 我们就可以马上得到我们想要的 html 内容啦。
但生成的 html 文件会有一点小问题,html 渲染出来后 js 代码动态生成的代码会跟静态生成 dom 重复,我们后续把对应的那几行 js 给切掉,就完事了。
略
我们手上有一个很久没有维护的原生小程序项目需要重新开始迭代,但是我们团队早已开始使用 Taro 来开发小程序,有一些在其他项目中使用的Taro 业务模块也希望合并到旧代码中来。于是有了这篇文章。
令 2 年前的原生小程序代码和后续使用 Taro 写的小程序模块能够混合使用。
在这个方案中,计划用 webpack 插件通过分包的方法,把不同的小程序包,在 app.js 逻辑抽离的情况下合并成同一个小程序。希望能够让不同版本的 taro 代码,甚至是不同框架的小程序代码,可以在同一个小程序中运行。
可惜理想很丰满,现实很骨感。这个方案仅限于可以在 taro 1.x 版本中运行。从 taro 2.x 开始,taro 开始用 webpack 打包,会往 app.js 里面注入很多 Taro 相关的代码。对应的代码包,需要依赖 app.js 才能正常运行。更别说 Taro 3.x 开始,Taro 实现了一套运行时的方案,它是基于 React 和 React-Reconciler 实现的。必须往 app.js 里面注入相关 chunk 来实现 runtime。如果想自己实现一套这样的机制,难度不亚于自己实现一个 taro-runtime。开发成本以及维护成本过高。
Taro 官方为了方便原生用户加入 Taro 的大家庭当中,可以通过 Taro-cli 提供 taro convert 方法,实现原生代码向 Taro 代码的转换。但是这个方案也有很多弊端。
这个方法的原理是,通过 Taro with-weapp 这个装饰器把原生代码 App(options) / Page(options) / Component(options) 的 options 注入到 react 的 class component 内部。在这个过程中就会产生很多问题。class component 的 this 并不是指向原生的 App / Page / Component ,而是指向 class component 的实例。这样会导致原生很多 hack 的代码失效。
同时也因为,这个装饰器没有兼容 3.x 版本。会出现很多报错。为此我还提交了一个 PR 修复其中的 bug,这个 PR 将会在 3.0.8 版本合并。(除非原生代码不是很多,这个方案我大概是不敢用了,逃)
https://taro-docs.jd.com/taro/docs/2.2.11/hybrid Taro 提供了 Taro 和 native 的混写的方案。但是这个方案有很多弊端,经过这个方案打包后的原生代码,会出现很多路径不一致的问题。旧代码和新代码无法很好的解耦。不过这个方案是可行的,只是因为原生页面也作为 Entry 被打包进了 webpack 流程里,所以在这个方案的基础上,有了最后的终极方案。
既然 Taro 跟原生小程序代码是可以混写的,那我不如不让 Taro 打包我的原生代码,那样就能合理解耦新代码和旧代码了。
旧包独立抽出来,放进 src 目录。但在 app.js(taro)的 config 里不添加原生代码包的 pages。因为 taro 是通过 config 来把对应的 page 作为 Entry 添加进 webpack 里的,这样做是为了让 taro 只把 taro 相关代码打包进 dist。
旧包相关代码可以通过 https://taro-docs.jd.com/taro/docs/2.2.11/config-detail 提供的 copy 来实现静态输出。(注意,src 相关目录不要和旧包重名)
copy: {
patterns: [
{ from: 'src/native', to: 'dist' }, // 指定需要 copy 的目录
]
},由于在第一步,我们没有把旧包的 pages 添加到 config 里去,最后输出的 app.json 是不会把 copy 过来的 pages 添加进去的。所以另外实现了一个 webpack 插件changeAppJsonPlugin 来对最后输出文件的修改。让最终输出的 app.json 跟我们最终想要得到的一样。
// config/index.js
const changeAppJsonPlugin = require('./plugin/changeAppJsonPlugin')
config = {
// other....
mini: {
webpackChain (chain, webpack) {
chain.plugin('changeAppJsonPlugin')
.use(changeAppJsonPlugin)
},
}
}通过这个插件,我们可以实现在 app.js 的 config 里,增加一个 outputAppJson 的属性来修改最终出来的 app.json。
config = {
outputAppJson: {
// 需要添加进去的原生 pages
pages: [
{
path: 'pages/home/home',
homePage: true
},
'pages/mine/mine'
],
tabbar: {}
},
// taro 的 Entry
pages: []
}需要注意的是,output 里的 pages,是 push 进去最终输出的 pages 数组的,但是当我们需要把原生 pages,作为最终输出首页时,需要把这个页面写成 object 对象,如上面的格式,让 page unshift 进 pages 数组里去。
由于旧包把很多公共逻辑代码注入到 App 里。所以为了不影响旧代码的正常运行,对 getApp 这个函数进行了切片,把旧包里 App 里的 options 抽出来, 植入 getApp 。
// app.js
require('./global')// global.js
const oldGetApp = getApp;
class Opitons {
// ....
// 旧包 App option 里的逻辑
}
let res = Object.assign(new options(), oldGetApp());
getApp = () => {
return res;
};如此一来,在旧包里 page 通过 getApp 获得的公共逻辑也就能完美覆盖了。
通过以上的探索历程,总算很好地把 Taro 以及原生完美地跑起来了。虽然试了很多的错,但是通过这个过程,也让我对 Taro 有了重新的认识。作为一个 Taro 的新司机,以后 Taro 这车哪里有坑我也可以自己修了(误。
在后面开发过程中,发现实际工作中还需要通过一些额外的手段,来打通原生代码跟 Taro 代码之间的交互。所以额外写了以下内容。
在后续的开发中,我改造了上文的 global.js,重新命名为 mixin.js,同时做了两点改造:
一些工具函数的封装,如用来记录数据的 sessionStore,封装了业务逻辑的 Request 库。如果两端都引入相同依赖,会引起评论区有人提到依赖重复打包问题。所以建议旧包页面引用的一些依赖可以放到 app 里获取。
但是旧包有一些依赖,可能已经落后于现在的新代码。例如在旧包里,我们自己实现了一个 eventCenter,功能和 Taro 的 eventCenter 但是有一定差异。为了最少量的修改旧包代码逻辑,在 Taro eventCenter 的基础上进行兼容封装,让 Taro eventCenter 直接能在旧包上使用。
新版本的更新迭代,旧包还是不可避免要进行修改。在这个问题上只能去权衡,哪些页面需要继续使用旧代码,哪些页面适合重写。
分享一些我在开发过程中总结的小tips:
// 新包的 app.js
require('./mixin')('koolcard');
// mixin.js
module.exports = nativeDirName => {
const oldApp = App;
let options;
App = option => {
options = option;
};
(function() {
require(`./${nativeDirName}/app.js`);
})();
App = oldApp;
const oldGetApp = getApp;
let res = Object.assign(options, oldGetApp(), {
request: Request,
event: Event,
sessionData: Session,
service,
isIpx,
eventNames: EventNames,
globalData,
getPhoneNumber,
bystesLength,
iconStyle,
DEFAULT_AVATAR: DEFAULT_AVATAR,
newTip,
settings: new Setting(),
});
getApp = () => {
return res;
};
};usingComponent 会产生编译过程中会报错找不到组件的问题,虽然不影响编译打包。强迫症的我还是要想想办法解决....(虽然还没想到办法 hh

这个链接404了,可以提供源码吗?
找到自己的拉伸区 不要整天想着搞大新闻
专注度练习
建立个人认知体系,只接收对自己有用的触动点(确定自己需要什么不是盲目学习)


之前忙于开发(其实是懒)一直没有做过 VSCode 插件 CI 方面的工作,一直是手动发包的节奏,vsce package → VSCode 官网 → publish extension → 拖压缩包进来 → 上传。链路长,而且巨硬的网速出了名的烂,未免有点呆。最近正好 VSCode Kooltest 开源,干脆薅上 Github actions 的羊毛,集成一下。
Github 的 CI 规则与日常使用 gitlab 的规则大同小异这里就不赘述了,不过 Github Actions 有一个很好的地方是,它有一个 Github Marketplace 可以从上面直接复用别人写好的 YML 脚本(类似 docker hub)
在 Marketplace 上搜到了专门针对 VS Code 插件的 Publish VS Code Extension。
在你的github仓库根目录下创建好 .github/workflows/main.yml ,参考我写好的 YMI(直接复制粘贴即可)
# action 名
name: Deploy Extension
# 触发时机: 这里表示 push 或者 pr 合并到 main 上
on:
push:
branches:
- main
pull_request:
branches:
- main
jobs:
deploy:
# 运行的镜像和使用的 node 版本号
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v1
with:
node-version: 15
# 运行 npm ci 前,请保证现在 lock 相关文件无误
- run: npm ci
# 使用上述 github action
- name: Publish to Visual Studio Marketplace
uses: HaaLeo/publish-vscode-extension@v0
# 在 [https://dev.azure.com/](https://dev.azure.com/) 上生成的 marketplace 密钥
with:
pat: ${{ secrets.VS_MARKETPLACE_TOKEN }}
registryUrl: https://marketplace.visualstudio.com创建好文件之后,请在 https://dev.azure.com/ 生成密钥,**Organization 要选 All accessible organizations (此处划重点) ,**不然 deploy 的时候会报 401。
接下来要配置你的 github 仓库,注意 secret 名要叫VS_MARKETPLACE_TOKEN
到这,整个 CI 配置就基本完成,接下来就可以通过 push 或者 pr 来触发这套 deploy job 了。(版本号记得更新,不然也会发包失败)
npm ci 和 npm install 命令一样,是用来安装依赖的命令,但它可以比常规的 npm 安装快得多,也比常规安装更严格,它可以保证 npm 依赖安装的一致和稳定 (锁版本)。
所以这里有一个小前提,要保证 package-lock.json 文件存在并且无误。存在即是指要git push 的时候要把 package-lock.json 文件上传到仓库。无误指的是 lock 文件内的仓库地址可访问,如果这个 lock 文件是在内网私库环境生成的,在 github 上运行就会运行失败了。
import 的首字母大小写是会被 tsc 忽略的,以前有些模块引入路径我写错了,但没怎么留意。直至走 CI 流程的时候才被捕捉到,告诉我路径有问题。
最近在开发一套自动化测试使用的 DSL 语言,需要开发 vscode 插件做基建支持。基础的关键字高亮功能比较容易实现,脚手架模版一拉,关键字一加,就马上可以使用了。继续优化的过程中,遇到了新的问题,
DSL 里希望能够嵌套 js 代码来运行,但是我们知道,js 这种 GPL 语言的高亮,可不像 DSL 那么好做,而且我们重点是 DSL,可不能把时间浪费在 js 上。于是我想到了 vscode 的 markdown 是支持 js 代码高亮的。
根据 markdown-basics 所示,这个插件最上一层 patterns 包含了 #block,而
repository 里定义了 block 所包含的 #fenced_code_block,以及后续定义了 #fenced_code_block 包含了,#fenced_code_block_js.
那么我们的答案就找到了,只需要定义好 #fenced_code_block_js 的起点正则和终点正则,这部分代码就可以根据我们选择的 embeddedLanguages 映射出对应的样式
gherkin.tmLanguage.json{
"$schema": "https://raw.githubusercontent.com/martinring/tmlanguage/master/tmlanguage.json",
"name": "Gherkin",
"patterns": [{
"include": "#block"
}
],
"repository": {
"block": {
"patterns": [
{
"include": "#fenced_code_block"
},
{
"include": "#blockquote"
}
]
},
"fenced_code_block": {
"patterns": [
{
"include": "#fenced_code_block_js"
}
]
},
"fenced_code_block_js": {
"begin": "(^|\\G)(\\s*)(\"{3,}|~{3,})\\s*",
"name": "markup.fenced_code.block.gherkin",
"end": "(^|\\G)(\\2|\\s{0,3})(\\3)\\s*$",
"beginCaptures": {
"3": {
"name": "punctuation.definition.gherkin"
},
"4": {
"name": "fenced_code.block.language.gherkin"
},
"5": {
"name": "fenced_code.block.language.attributes.gherkin"
}
},
"endCaptures": {
"3": {
"name": "punctuation.definition.gherkin"
}
},
"patterns": [
{
"begin": "(^|\\G)(\\s*)(.*)",
"while": "(^|\\G)(?!\\s*([\"~]{3,})\\s*$)",
"contentName": "meta.embedded.block.javascript",
"patterns": [
{
"include": "source.js"
}
]
}
]
}
}代码到这就差不多搞定了,剩下的就是根据自己需要设置 block 的范围了。
Q1: 毒酒 一个恶毒的国王被告知他的 1000 桶酒中有一桶被下了毒。毒酒的毒性非常强,怎么稀释也能在整整30天时让一个人死掉,国王准备牺牲他的 10 个奴隶找出毒酒。
Q2: 议会和解 在一个议会当中,每个成员最多有三个对手(我们假设敌意总是相互的)。下面的论题是真还是假:能否将议会分成两部分以保证每个议员所在的那部分中的对手不多于1个?
Q3:
交了一个我好爱的女朋友!
健身 23 天,下个月开始准备加强训练强度,保持上班前练 10 分钟健身环。

看了肆囍乐队的演出

看了一次画展
之前一直以为 node 端,可以给不同字体加上颜色是因为 console.log 继承了某些功能,所以字体才会表现出不同功能。直到今天监听一个另外的进程,把进程 message 传来的文本 buffer 转为string。通过console.log 打印出来,依然能看到不同的颜色。
搜了一下 node console color, 找到了这个包
通过ansi码可以指令式修改后面文本的颜色。
var styles = {
'reset': '\x1B[0m',
'bright': '\x1B[1m',
'grey': '\x1B[2m',
'italic': '\x1B[3m',
'underline': '\x1B[4m',
'reverse': '\x1B[7m',
'hidden': '\x1B[8m',
'black': '\x1B[30m',
'red': '\x1B[31m',
'green': '\x1B[32m',
'yellow': '\x1B[33m',
'blue': '\x1B[34m',
'magenta': '\x1B[35m',
'cyan': '\x1B[36m',
'white': '\x1B[37m',
'blackBG': '\x1B[40m',
'redBG': '\x1B[41m',
'greenBG': '\x1B[42m',
'yellowBG': '\x1B[43m',
'blueBG': '\x1B[44m',
'magentaBG': '\x1B[45m',
'cyanBG': '\x1B[46m',
'whiteBG': '\x1B[47m'
}在面试中,面试官经常会没法听下你长篇大论,所以我们要先总结出一个结论再去细说。这样会大大为你的面试加分。
10月无总结
这个问题源于上一次面试拼多多被问到的一套组合拳,性能优化 -> 预渲染 -> 骨架屏 -> ssr -> 流式渲染,前面的几个点因为有所接触问题不大,但流式渲染因为很早已经被 ssr 框架们内置,我居然听都没听过👴🏿❓ 结合最近刚上线的 react 18 ,我们来聊聊流式渲染吧。
以 React 的 SSR 为例,React 提供了 renderToString 这个包,用于把 reactDOM 转化成 html 的静态代码。(为了让后面的测试效果明显一点,我写了一个渲染 4 万行 markdown 的 demo)
const tempString = fs.readFileSync(path.join(__dirname, './template.md'), 'utf8');
app.get('/react-ssr', (req, res) => {
// 由于量比较大,这一步会有明显的阻塞
const app = ReactDOMServer.renderToString(<App source={tempString}/>);
const html = `
<html lang="en">
<head>
</head>
<body>
<div id="root">${app}</div>
</body>
</html>
`
res.send(html);
});在浏览器获得这一整个超过4万行的 html 之前,浏览器是不做任何渲染的,这就代表用户会有很长的白屏时间,于是我们就有了下面的要说的流式渲染。
我们都知道浏览器接受到 html 之后的渲染流程:HTML 解析 -> DOM Tree / cssom tree -> 合成渲染树 -> layout + paint
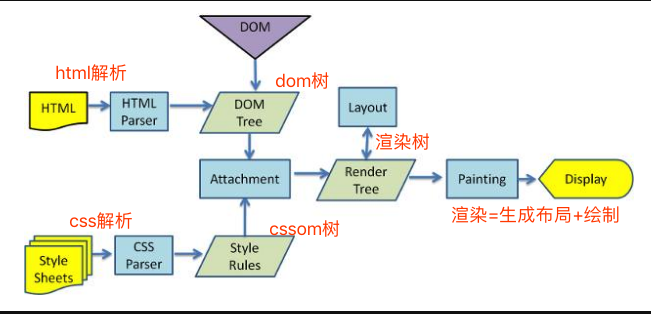
但比较幸运的是,浏览器不会等解析完完整的 html 文档后,才进行 layout 和 paint。
我们来跑一个简单的 demo 看看
实际上流式渲染的原理并不是很复杂, 为了让效果更直观我们来看看下面这个写了很多 setTimeout 的 demo:
app.get('/ssr-streaming', async (req, res) => {
res.write(`
<html lang="en">
<head>
</head>
<body>
`)
setTimeout(() => {
res.write(`<div style="background: #111222;width: 100vw;height: 100px;">321</div>`)
}, 100);
setTimeout(() => {
res.write(`<div style="background: #123222;width: 100vw;height: 100px;">321</div>`)
}, 500);
setTimeout(() => {
res.write(`<div style="background: #333112;width: 100vw;height: 100px;">321</div>`)
}, 1000);
setTimeout(() => {
res.write(`<div style="background: #332312;width: 100vw;height: 100px;">321</div>`)
}, 2000);
setTimeout(() => {
res.write(`<div style="background: #333432;width: 100vw;height: 100px;">321</div>`)
}, 3000);
setTimeout(() => {
res.write(`<div style="background: #335422;width: 100vw;height: 100px;">321</div>`)
}, 4000);
setTimeout(() => {
res.write(`<div style="background: #673211;width: 100vw;height: 100px;">321</div>`)
}, 5000);
setTimeout(() => {
res.end()
}, 6000);
});可以从浏览器的效果中看到,这些 div 是一段一段被渲染出来的。这归功于浏览器强大的兜底能力,就算我们没有提供闭合的 dom 结构,也能根据已经接收到的数据,进行补全和渲染。基于这一点,我们就可以选择更优的渲染方案,提前我们页面的 TTI 的时间了。
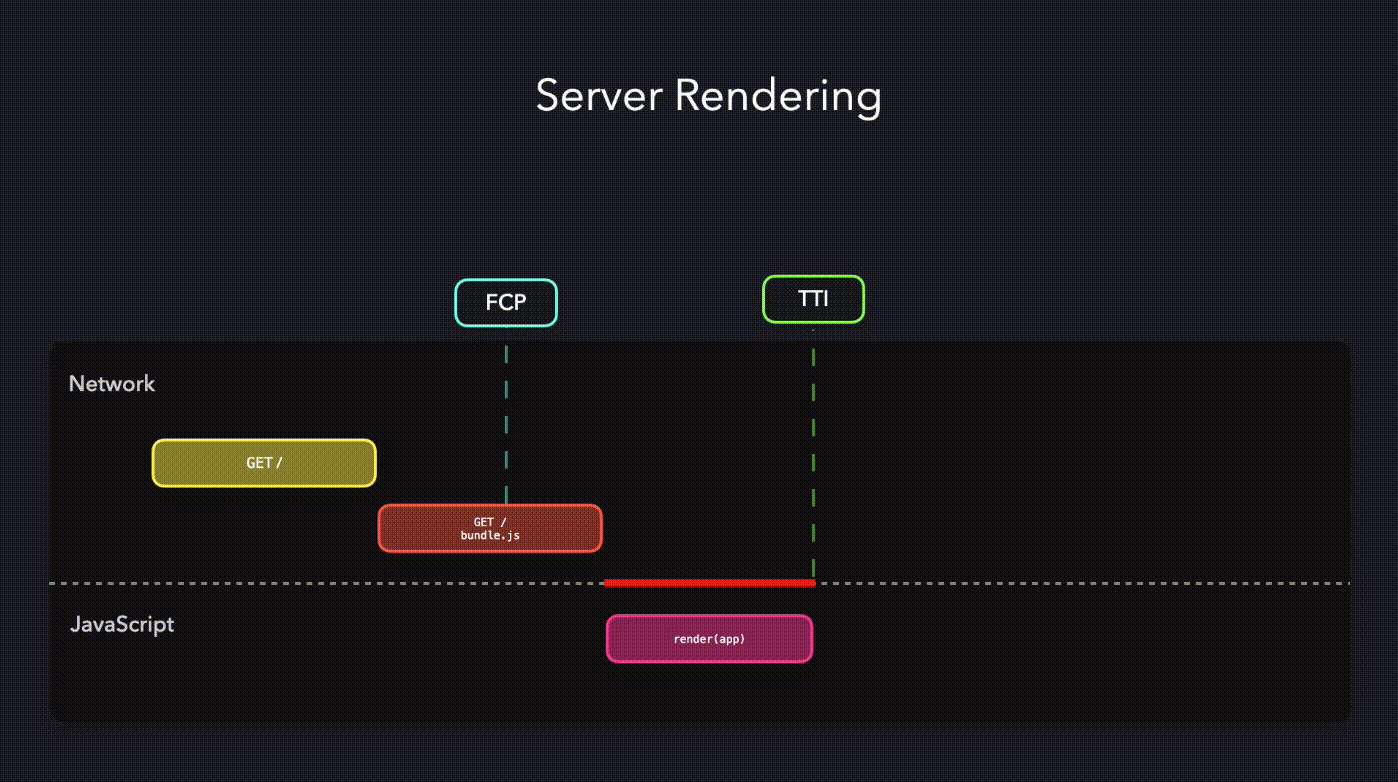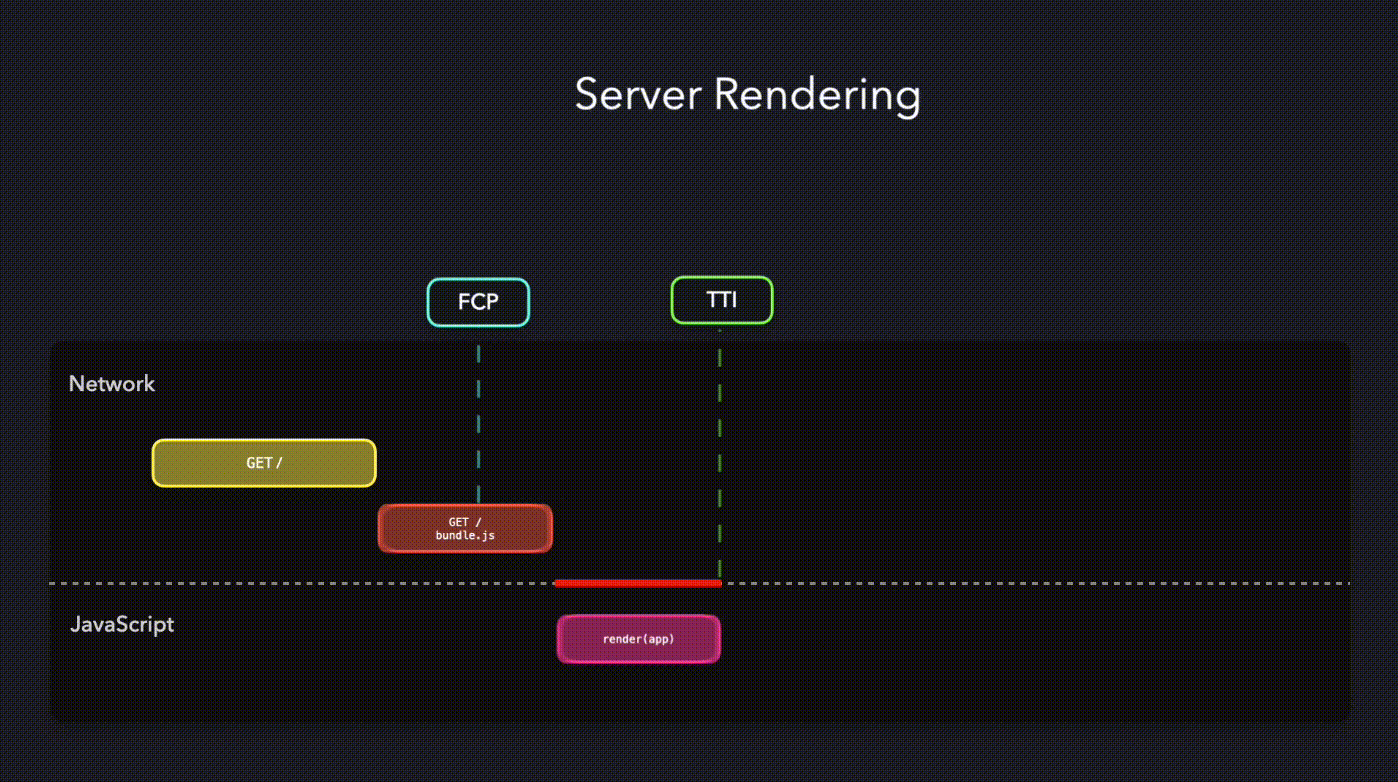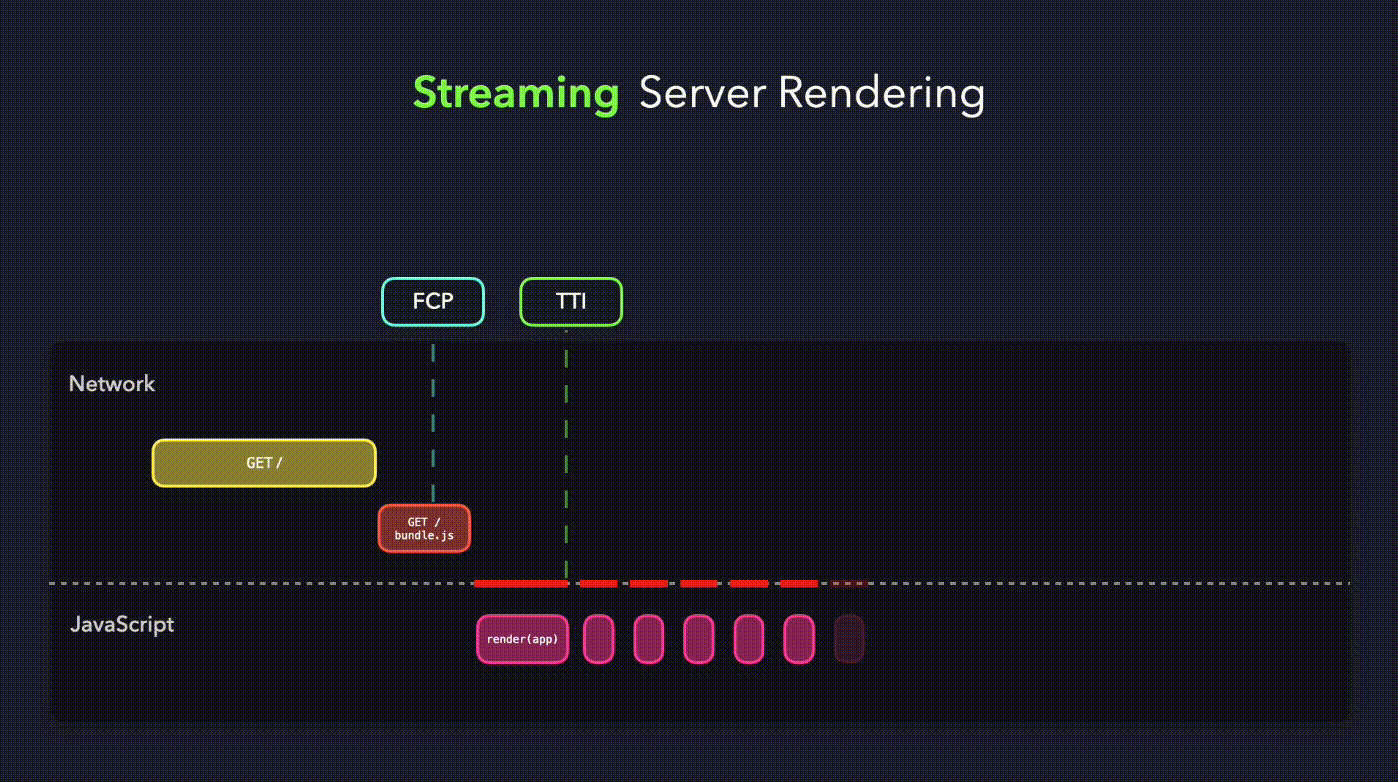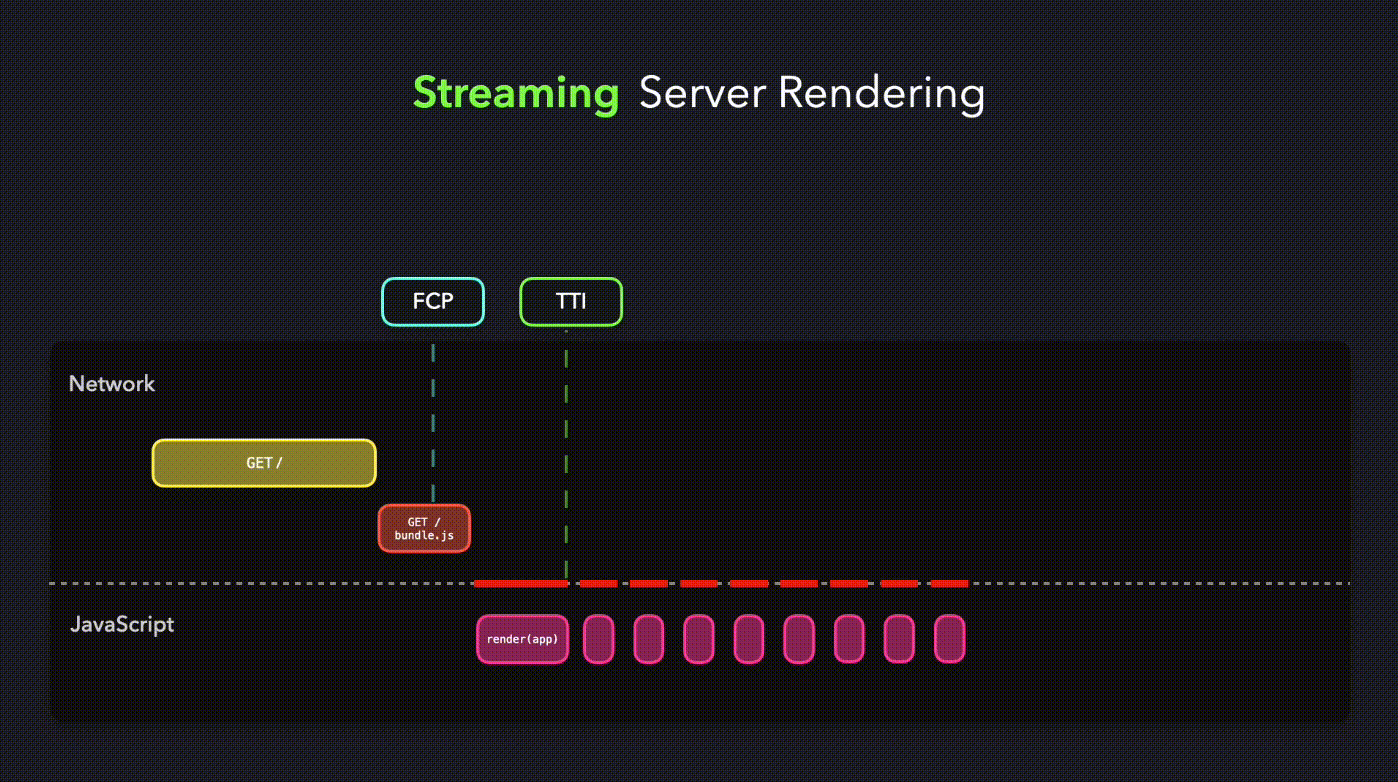
通过 react 的 renderToNodeStream 实现流式渲染(注,renderToNodeStream 是基于 dom 节点切片的,如果都写到一个 dom 里,无论这个节点的字符串多长,都是一次性返回的)
app.get('/react-streaming', (req, res) => {
res.write(`<html lang="en">
<head>
</head>
<body>`);
res.write(`<div id="root">`);
const stream = ReactDOMServer.renderToNodeStream(<App source={tempString} />)
stream.pipe(res, { end: false })
stream.on("end", () => {
res.write("</div></body></html>");
res.end();
})
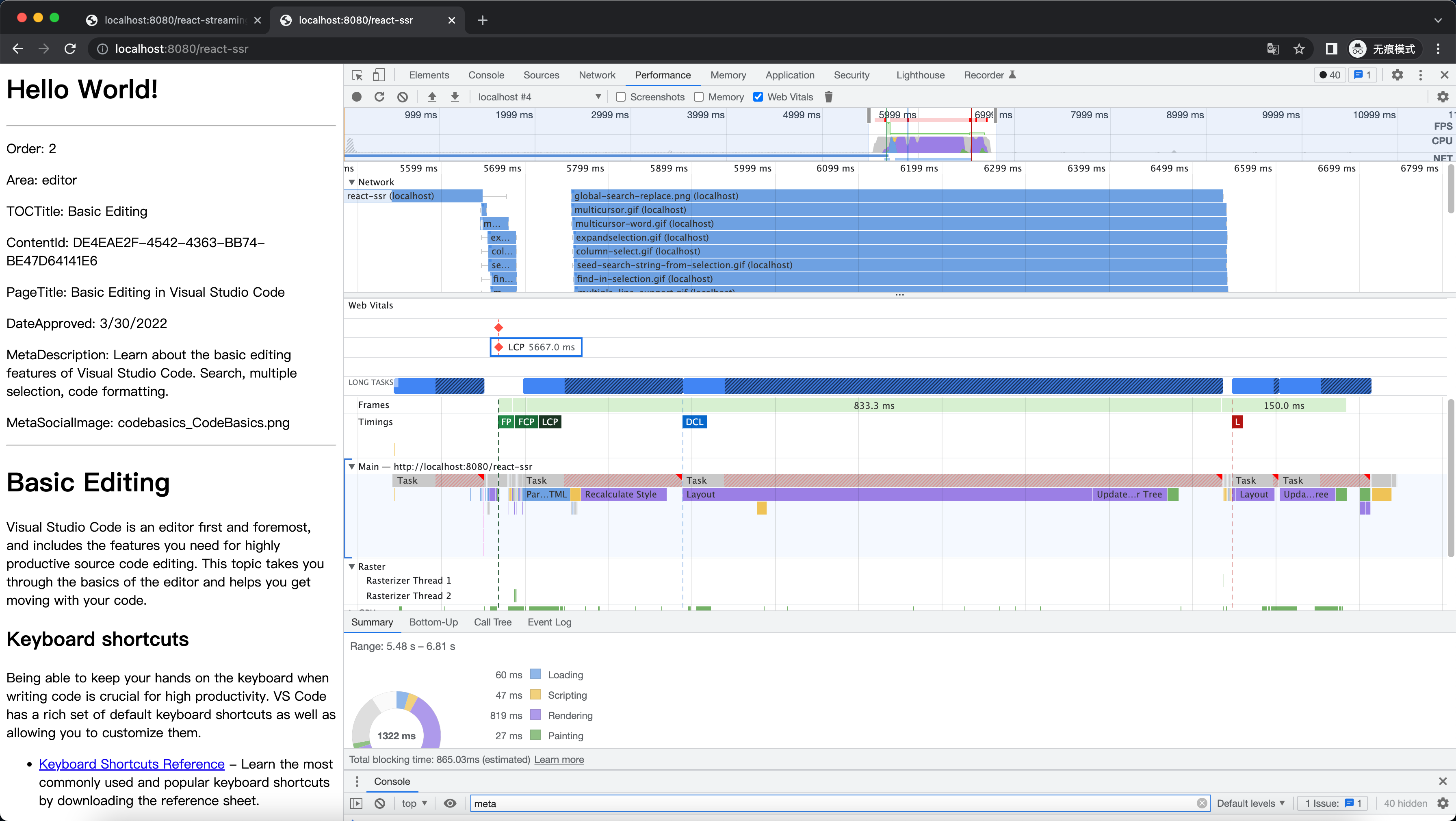
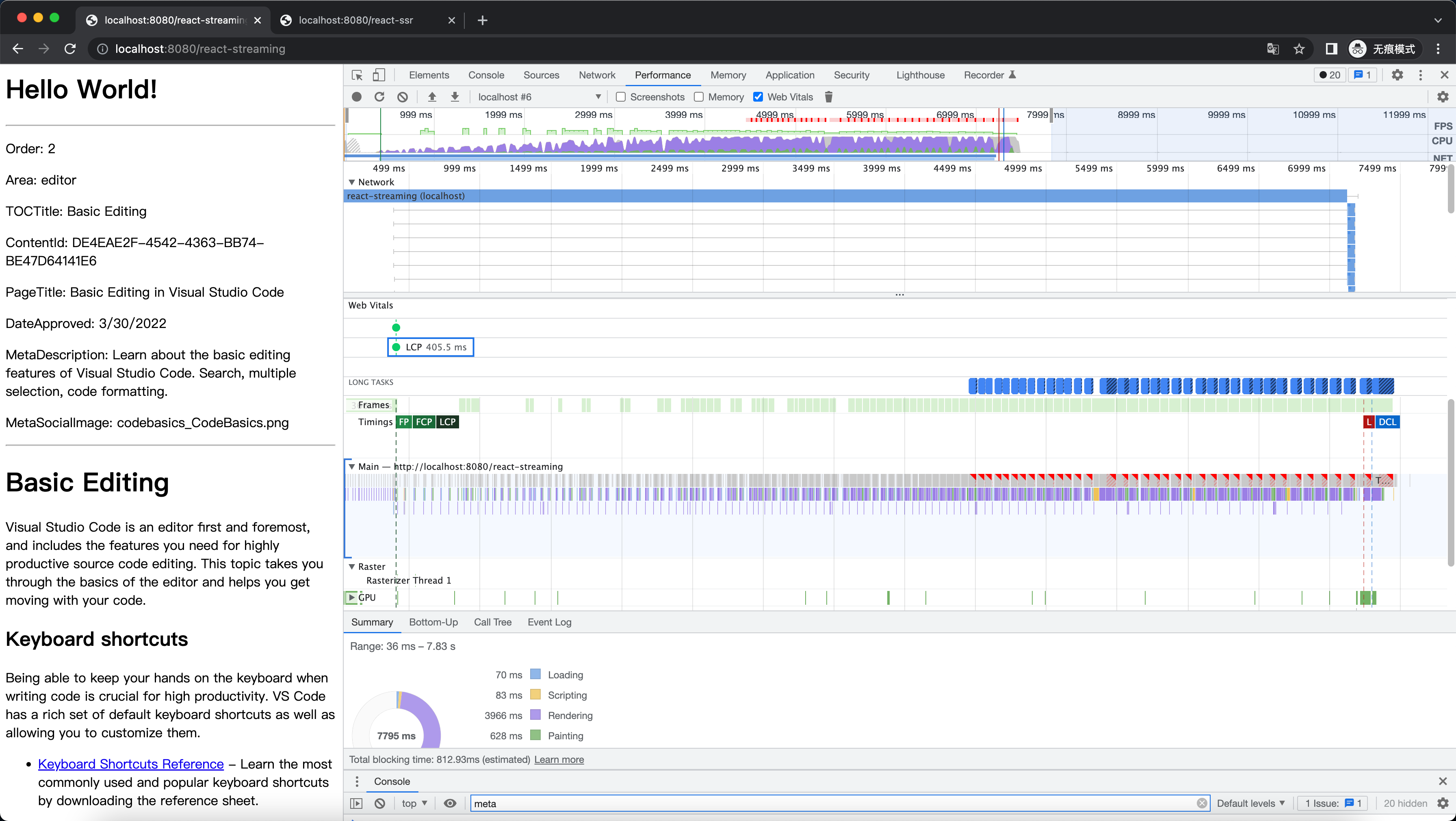
})我们可以看到在这个比较极端的 case 里 LCP 的时间明显提前了,这是因为当收到第一段 chunk 之后,浏览器马上进行渲染了。
优化前:
优化后:
lcp 提前了也不完全是好事,因为 react 的 ssr api 是纯文本的,逻辑层会被剥离(dehydrate)。
// 生成注水代码
import React from 'react';
import ReactDom from 'react-dom';
import { App } from './app';
ReactDom.hydrate(<App source="hydrate xxxxx" />, document.getElementById('root'))
// 用esbuild打包
"scripts": {
"build": "esbuild client/index.tsx --bundle --outfile=built/index.js",
}
// 在最后插入 index.js
app.get('/react-streaming', (req, res) => {
res.write(`<html lang="en">
<head>
</head>
<body>`);
res.write(`<div id="root">`);
const stream = ReactDOMServer.renderToNodeStream(<App source={tempString} />)
stream.pipe(res, { end: false })
stream.on("end", () => {
res.write(`</div></body>
<script src="index.js"></script> // 注水
</html>`);
res.end();
})
})这就意味着,在流式渲染中会先看到画面,但页面处于无法响应的阶段,对用户体验会有一定影响。

在React 18之前,如果应用程序的完整JavaScript代码没有加载进来,hydration就无法启动。对于较大的应用程序,这个过程可能需要一段时间。
但在React 18中,可以让你在子组件加载之前就对应用进行hydration。
通过用包装(warp)组件,你可以告诉React,它们不应该阻止页面的其他部分,甚至是hydration。这意味着你不再需要等待所有的代码加载,以便开始hydration。React可以在加载部分时进行hydration。
这2个Suspense的功能和React 18中引入的其他几个变化极大地加快了初始页面的加载。
刷题插件想要集成carbon.sh的功能,用来快速生成海报图方便用户分享题目和自己的答案,虽然官方代码是开源的,但都是基于web端实现,在node端实现开发成本很大。于是我找到了 node 端的 cli 源码。发现了一手蛮有意思的操作。
carbon-now-cli 集成了 puppeteer 直接打开 carbon 网站,通过 url 的方式把代码和需要的 language 注入到网页里,模拟点击下载时间,下载图片。同时还可以使用 clipboardy 把图片塞入粘贴板,直接粘贴生成图片。挺有趣的一个小技巧。
但是,chromium 的体积实在太大了,而且性能也极差。最后我放弃了这个方案。
In a small town the population is p0 = 1000 at the beginning of a year. The population regularly increases by 2 percent per year and moreover 50 new inhabitants per year come to live in the town. How many years does the town need to see its population greater or equal to p = 1200 inhabitants?
At the end of the first year there will be:
1000 + 1000 * 0.02 + 50 => 1070 inhabitants
At the end of the 2nd year there will be:
1070 + 1070 * 0.02 + 50 => 1141 inhabitants (number of inhabitants is an integer)
At the end of the 3rd year there will be:
1141 + 1141 * 0.02 + 50 => 1213
It will need 3 entire years.More generally given parameters:
p0, percent, aug (inhabitants coming or leaving each year), p (population to surpass)
the function nb_year should return n number of entire years needed to get a population greater or equal to p.
aug is an integer, percent a positive or null number, p0 and p are positive integers (> 0)
Examples:
nb_year(1500, 5, 100, 5000) -> 15
nb_year(1500000, 2.5, 10000, 2000000) -> 10Note: Don't forget to convert the percent parameter as a percentage in the body of your function: if the parameter percent is 2 you have to convert it to 0.02.
function nbYear(p0, percent, aug, p) {
// your code
var ny = 0
var sum = p0
while(sum < p){
sum = sum + sum*percent/100 + aug
ny = ny + 1
}
return ny
}刷 leetcode 的时候突发奇想,leetcode 是怎么算空间复杂度跟时间复杂度的(大概有想法,监听进程内存消耗变化就好)但是它是怎么定最后的百分比的呢。于是搜到了 ELO rating system 埃洛等级分系统。

以下复制粘贴自百度百科:
假设棋手A和B的当前等级分分别为RA和RB,则按Logistic distribution A对B的胜率期望值当为:

类似B对A的胜率为:

假如一位棋手在比赛中的真实得分(胜=1分,和=0.5分,负=0分)和他的胜率期望值不同,则他的等级分要作相应的调整。具体的数学公式为:

和分别为棋手调整前后的等级分。在大师级比赛中K通常为16。
例如,棋手A等级分为1613,与等级分为1573的棋手B战平。若K取32,则A的胜率期望值为

因而A的新等级分为。

甚至,我找到了这个数学模型的包。只需要传入,Ra Rb 以及胜负(true / false),它就能返回最后两者的得分。
var EloRating = require('elo-rating');
var playerWin = false;
var result = EloRating.calculate(1750, 1535, playerWin);
console.log(result.playerRating) // Output: 1735
console.log(result.opponentRating) // Output: 1550
result = EloRating.calculate(1750, 1535);
console.log(result.playerRating) // Output: 1754
console.log(result.opponentRating) // Output: 1531由此得出猜测,百分比是根据最后 rank 积分的百分比分布来判断。
而像周赛这种,直接返回 rank 积分。
最近公司的2D项目,3D项目的热力图都是由我来负责,2D 已经完满搞定了,3D刚开始弄,用到的框架是 cesium,找了个叫 Cesium-Heatmap 的插件,年代比较久远14年的代码。一开始没有集成到 vue 项目里,只用于普通的 html 上,没出什么问题。但集成到项目内,就蛋疼了。
A library to add heatmaps (using heatmap.js and Cesium.Entity.Rectangle or Cesium.SingleTileImageryProvider) to the Cesium framework.
export 出相应的 CesiumHeatmap 对象。源码的思路是,运行这个 js 文件时,通过立即执行函数定义 window.CesiumHeatmap 对象。(function (window) {
'use strict';
function define_CesiumHeatmap() {
var CesiumHeatmap = {
defaults: {
...... // 默认配置
},
}
};
CesiumHeatmap.create = function (cesium, bb, options) {
var instance = new CHInstance(cesium, bb, options);
return instance;
};
...... // 定义一堆 CesiumHeatmap 的方法
return CesiumHeatmap;
}
if (typeof(CesiumHeatmap) === 'undefined') {
window.CesiumHeatmap = define_CesiumHeatmap();
// 如果 CesiumHeatmap 不存在,window.CesiumHeatmap 就等于 define_CesiumHeatmap() 运行后,return 回来的 CesiumHeatmap
} else {
console.log("CesiumHeatmap already defined.");
}
})(window);
摘自 https://www.yuque.com/mdh/wama6c/zxdz34
做需求的时候发现 puppeteer 没有提供获得当前被选中页面的能力,返回的 page 实例也没有相关属性。那我们如何去得到真正被选中的实例呢
在浏览器里,当前页面是否可见是可以通过 document.visibilityState 获取的 hidden 为不可见,visible 为可见。我们完全可以对每个 page 实例运行 document.visibilityState 来获取页面状态。
const pages = await browser.pages();
let currentPages = await Promise.all(
pages.map(async (page) => {
const visible = await page.evaluate(
() => document["visibilityState"] === "visible"
);
page.visibilityState = visible;
return page;
})
);
currentPages = currentPages.filter((ele) => ele.visibilityState);
if (currentPages.length == 0) {
return ;
}
const currentPage = currentPages[0];A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.