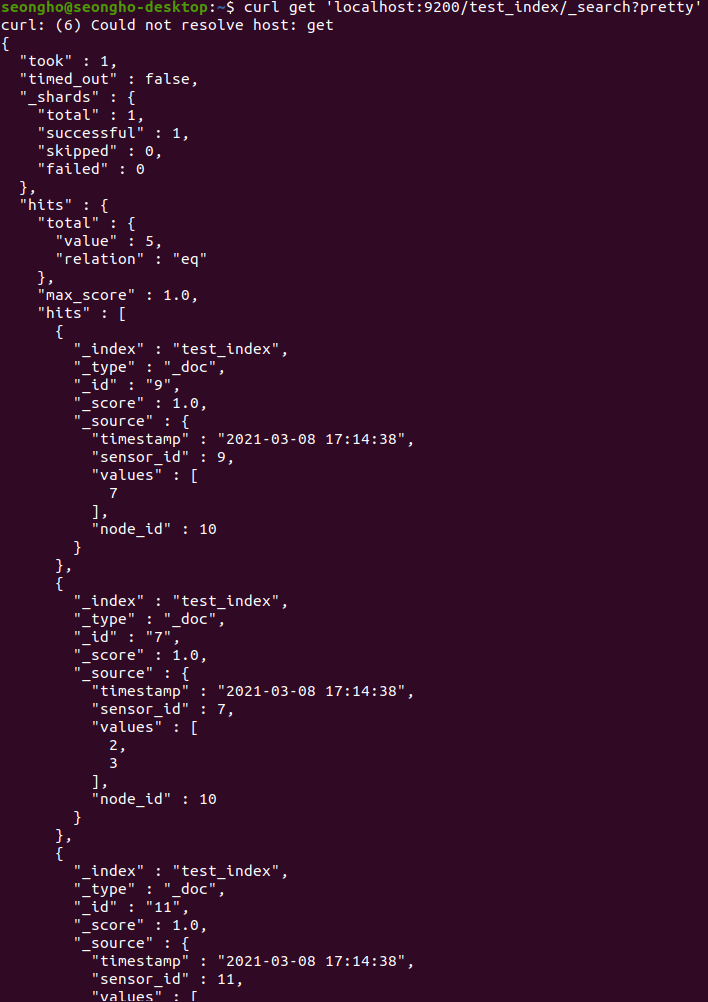
Save the data produced to Kafka in ES through PySpark streaming
Python: 3.8.0
Spark: spark-2.4.7-bin-hadoop2.7
Pyspark: 2.4.7
ElasticSearch: 7.6.1
Kafka: 2.5.0
Zookeeper: 3.6.1
- Spark Streaming(Dstreams)
$ spark-submit \
--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.0 \
--jars jar/elasticsearch-spark-20_2.11-7.6.1.jar \
Dstream/run.py
- Structured Streaming
$ spark-submit \
--packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0 \
--jars jar/elasticsearch-spark-20_2.11-7.6.1.jar \
--conf spark.cores.max=2 Structured/structerd.py
-
Consumed data from Kafka

-
Data stored in ES