qianlei90 / blog Goto Github PK
View Code? Open in Web Editor NEW那些该死的文字呦
Home Page: https://qianlei.notion.site
那些该死的文字呦
Home Page: https://qianlei.notion.site

















































































































tags: 印象笔记
[toc]
Given an array of n integers where n > 1, nums, return an array output such that output[i] is equal to the product of all the elements of nums except nums[i].
Solve it without division and in O(n).
For example, given [1,2,3,4], return [24,12,8,6].
Follow up
Could you solve it with constant space complexity? (Note: The output array does not count as extra space for the purpose of space complexity analysis.)
值 = 所有左侧的数的乘积 * 所有右侧的数的乘积
可以用两个列表表示所有左侧数的乘积与右侧数的乘积。
给定数组[1, 2, 3, 4]
forward = [1, 1, 2, 6, 24]
backward = [1, 4, 12, 24, 24]
值 = forward[i] * backward[-(i+2)]
class Solution(object):
def productExceptSelf(self, nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
nums_length = len(nums)
forward, backward = [1], [1]
for i in range(nums_length):
forward.append(nums[i] * forward[i])
backward.append(nums[-(i+1)] * backward[i])
return [forward[x]*backward[-(x+2)] for x in range(nums_length)]一个更通俗易懂的写法:
class Solution(object):
def productExceptSelf(self, nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
nums.insert(0, 1)
nums.append(1)
left, right, result = [1], [1], []
for i in nums[1:-1]:
left.append(left[-1] * i)
for i in nums[-2:0:-1]:
right.append(right[-1] * i)
right.reverse()
for i in range(len(nums) - 2):
result.append(left[i] * right[i+1])
return result- 完 -
Tags: 印象笔记
[toc]
Given an array nums, write a function to move all 0's to the end of it while maintaining the relative order of the non-zero elements.
For example, given nums = `[0, 1, 0, 3, 12]`, after calling your function, nums should be `[1, 3, 12, 0, 0]`.
note
1. You must do this in-place without making a copy of the array.
2. Minimize the total number of operations.
列表操作题,利用python的list特性,很简单。直接把0删除,然后在末尾添加被删除的0就好。
class Solution(object):
def moveZeroes(self, nums):
"""
:type nums: List[int]
:rtype: void Do not return anything, modify nums in-place instead.
"""
original_len = len(nums)
while 0 in nums:
nums.remove(0)
nums.extend([0] * (original_len - len(nums)))利用list的sort方法,对元素进行排序。sort方法中有个参数是key,key用来为每个元素提取比较值.,默认为 None,,即直接比较每个元素。
可以构造一个lambda函数,如果元素的值为0,则返回True,True比False大,元素就排到了后面。
class Solution(object):
def moveZeroes(self, nums):
"""
:type nums: List[int]
:rtype: void Do not return anything, modify nums in-place instead.
"""
nums.sort(key=lambda x: x is 0)将lambda函数简化,简化为1个操作符即可。
class Solution(object):
def moveZeroes(self, nums):
"""
:type nums: List[int]
:rtype: void Do not return anything, modify nums in-place instead.
"""
nums.sort(key=operator.not_)- 完 -
Tags: 印象笔记 Docker
docker官方文档Manage data in containers的笔记。
[toc]
数据卷是容器内的一个特殊目录,该目录绕过UFS,不向顶层的可读写layer写入。数据卷用来保存、固化数据,独立于容器的生存周期,不会主动被回收。
数据卷有以下特性:
$ docker run -d -P --name web -v /webapp training/webapp python app.py-v /webapp: 在/webapp处创建数据卷
使用docker inspect web查看容器的信息时,有一段如下:
...
"Mounts": [
{
"Name": "fac362...80535",
"Source": "/var/lib/docker/volumes/fac362...80535/_data",
"Destination": "/webapp",
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
]
...表明在容器web中,挂载了一个数据卷,从host的/var/lib/docker/volumes/fac362...80535/_data挂载到容器的/webapp目录。因为并没有指定host中的目录,所以docker会默认在/var/lib/docker/volumes中新建一个目录用来保存数据。
$ docker run -d -P --name web -v /src/webapp:/webapp training/webapp python app.py-v from:to:attr: 将from挂载到to。
ro表示只读注意: 在Dockerfile里使用命名数据卷,不要直接挂载host目录,可能会导致其他人无法build镜像。
可以使用--volume-driver参数指定数据卷的驱动类型,如NFS、flocker等,只需安装相关插件即可。
$ docker run -i -t --volume-driver=nfs -v nfshost/path:/mount ubuntu /bin/bash将本机的nfs共享目录nfshost目录挂载到容器的/mount目录,指定驱动为nfs。
最好不要使用数据容器,直接使用命名卷,因为可能会误删容器,而命名卷需要手动删除。
参考:
数据容器是一个挂载了数据卷但是不执行任何命令的容器,其目的只是为其他容器提供数据卷,方便数据在多容器之间共享、复用。
$ docker create -v /dbdata --name dbstore training/postgres /bin/true上述命令创建了一个在/dbdata设为数据卷的容器,使用的基础镜像时trainging/postgres。然后我们就能把该数据容器挂载到别的容器中去。
$ docker run -d --volumes-from dbstore --name db1 training/postgres注意: 镜像优先使用需要挂载该数据容器的容器镜像,尽量不使用busybox等其他镜像,这样可以节约空间,不用再重新pull一个新的镜像。
两条命令解释得清楚。
$ docker run --rm --volumes-from dbstore -v $(pwd):/backup ubuntu tar cvf /backup/backup.tar /dbdata$ docker run -v /dbdata --name dbstore2 ubuntu /bin/bash
$ docker run --rm --volumes-from dbstore2 -v $(pwd):/backup ubuntu bash -c "cd /dbdata && tar xvf /backup/backup.tar --strip 1"$ docker run --rm -v /foo -v awesome:/bar busybox top该命令在删除容器时一起删除匿名数据卷/foo,但是不会删除命名数据卷awesome。
$ docker volume rm volume_name- 完 - 2017/03/07
Tags: 印象笔记
[toc]
Write a function to delete a node (except the tail) in a singly linked list, given only access to that node.
Supposed the linked list is `1 -> 2 -> 3 -> 4` and you are given the third node with value 3, the linked list should become `1 -> 2 -> 4` after calling your function.
最初的思路还在想,因为是单向链表,怎么去找之前的节点?单向链表是没法找到之前的节点的啊。想了很久,以为有什么技术是可以做到的,但回想了很久数据结构的课程,里面也没有提到一星半点。
当前节点是不能删除的,因为上一个节点会指向当前节点,但上一个节点没法修改。所以正确的思路应该是删除的是下一个节点。
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution(object):
def deleteNode(self, node):
"""
:type node: ListNode
:rtype: void Do not return anything, modify node in-place instead.
"""
node.val, node.next = node.next.val, node.next.next- 完 -
Tags: 印象笔记 Docker
docker官方文档Best practices for writing Dockerfiles的笔记。
[toc]
.gitignore。在大部分情况下,Dockerfile会和构建所需的文件放在同一个目录中,为了提高构建的性能,应该使用.gitignore来过滤掉不需要的文件和目录。Label、ENV等标签,参考1.2。apt-get install -y安装包的时候。--no-cache=true来强制重新生成中间镜像。关于缓存的寻找机制,可以参考之前的<Dockerfile语法指南>。针对单条指令的建议。
尽可能的使用官方镜像,推荐使用Debian Image。如果追求镜像的大小,可以考虑alpine或scratch。
在一个Label指令内添加多个标签。如:
LABEL vendor=ACME\ Incorporated \
com.example.is-beta= \
com.example.is-production="" \
com.example.version="0.0.1-beta" \
com.example.release-date="2015-02-12"为了增加Dockerfile的可读性和可维护性,将复杂的RUN指令分行写,不要全部写在一行。
apt-get upgrade或dist-upgrade,这会更新大量不必要的系统包,增加了镜像大小。如果需要更新包,简单的使用RUN apt-get update && apt-get install -y package就好。记得,如果package很多的话,分行并按字母表排序。apt-get upgrade和apt-get install -y package要在一个RUN指令内,如果在多个RUN指令内,docker会使用缓存,具体的参考之前的<Dockerfile语法指南>。apt-get clean语句。如果是其他镜像,手动执行该指令,或删除/var/lib/apt/lists下的文件。带管带的命令,其返回值是最后一条命令的返回值。所以如果管道前的命令出错而管道后的指令正常执行,则docker不会认为这条指令有问题。如果需要所有的管道命令都正常执行,可以增加set -o pipefail,如:
RUN set -o pipefail && wget -O - https://some.site | wc -l > /number部分shell不支持set -o pipefail,所以需要指定shell。如:
RUN ["/bin/bash", "-c", "set -o pipefail && wget -O - https://some.site | wc -l > /number"]使用exec格式,如CMD ["executable", "param1", "param2"]。 如果用户不清楚镜像的ENTRYPOINT是什么,不要和ENTRYPOINT配合使用,不要使用CMD ["param1", "param2"]。
如果你的镜像是个服务,如Apache这样的,使用正常的、通用的端口,如80端口。
可以修改PATH环境变量来优先使用自己的可执行文件。
可以当做变量来使用,控制Dockerfile中的其他指令,使Dockerfile更易维护。如:
ENV PG_MAJOR 9.3
ENV PG_VERSION 9.3.4
RUN curl -SL http://example.com/postgres-$PG_VERSION.tar.xz | tar -xJC /usr/src/postgress && …
ENV PATH /usr/local/postgres-$PG_MAJOR/bin:$PATH这两个指令类似,但如果只是复制文件到镜像内,仍然推荐使用COPY,因为COPY在功能上更单一,而ADD指令有更多的特性(如远程文件、自动解压等)。
ADD指令使用的最好时机是想镜像内添加压缩包,ADD会自动解压。强烈不建议使用ADD来添加远程文件。如果确实需要远程文件,应该使用RUN wget或RUN curl。
ENTRYPOINT指令的主要用途是把容器当做命令来用,此时CMD指令来指定默认参数。可以自己写脚本来当做ENTRYPOINT。
强烈建议使用该指令为用户数据创建数据卷,如数据的存储位置、配置文件的存储位置或用户自己创建的文件/目录等。
如果镜像的服务不用授权就能使用,那应该新增用户和组,以新用户来执行,如:
RUN groupadd -r postgres && useradd -r -g postgres postgres需要注意的是,UID/GID是顺着镜像中已存在的UID/GID创建的,如果对这个有严格要求,应该自己显式定义UID/GID。
不要在镜像内安装或使用sudo,如果需要类似的功能,可以使用gosu。
也不要来来回回的切换用户,这样会增加图层层数。
只使用绝对路径。切换工作目录只使用WORKDIR而不是RUN cd ... && do-something。
在运行docker build命令时,在执行任何指令前,先执行父Dockerfile中定义的ONBUILD指令。
在打标签时应该添加这些信息,如:ruby:1.9-onbuild。
谨慎使用COPY和ADD,因为有可能在子构建中并不存在对应的文件或目录。
两种方式:
debootstrap类似的工具来生成一个基础的OS,然后导入到docker中:$ sudo debootstrap raring raring > /dev/null
$ sudo tar -C raring -c . | docker import - raring
a29c15f1bf7a
$ docker run raring cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=13.04
DISTRIB_CODENAME=raring
DISTRIB_DESCRIPTION="Ubuntu 13.04"FROM scratch
ADD hello /
CMD ["/hello"]- 完 - 2017/03/10
Tags: 印象笔记
[toc]
C^d 删除当前字符
C^h 删除前一个字符
C^k 删除光标后的所有字符
C^u 删除光标前的所有字符
C^w 删除光标前的一个单词
A^d 删除光标后的一个单词
C^y 粘贴之前删除的内容
C^? 撤销前一次动作,同C^x u
C^f 右移一个字符
C^b 左移一个字符
A^f 跳跃到单词尾
A^b 跳跃到单词头
C^a 跳跃到行首
C^e 跳跃到行尾
C^x C^x 在当前位置与行首之间跳跃
C^t 将光标当前字符与前一个字符替换
A^t 将光标当前单词与前一个单词替换
A^h 将光标到单词尾的字符转变为大写
A^l 将光标到单词尾的字符转变为小写
A^c 将光标当前位置的字符变为大写,到单词尾的部分变为小写
^oldstr^newstr 替换上一条命令中的字符串
A^~ 用户名补全
A^$ 变量补全
A^@ 主机名补全
C^d 退出当前的登录
C^l 清屏
- 完 -
Tags: 印象笔记
[toc]
docker的yum源:
$ cat <<EOF > /etc/yum.repos.d/docker.repo
[dockerrepo]
name=Docker Repository
baseurl=https://yum.dockerproject.org/repo/main/centos/7/
enabled=1
gpgcheck=1
gpgkey=https://yum.dockerproject.org/gpg
EOFkubernetes的yum源:
$ cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://yum.kubernetes.io/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOFyum使用代理,修改/etc/yum.conf文件,增加如下内容:
proxy=http://<proxy ip>:<proxy port>有些repo是不希望启用代理的,比如本地或者国内直连比较快的,在对应的repo配置下面增加一行:
proxy=_none_docker使用代理:
mkdir /etc/systemd/system/docker.service.d
echo '[Service]' > /etc/systemd/system/docker.service.d/http-proxy.conf
echo 'Environment="HTTP_PROXY=http://<proxy ip>:<proxy port>/" "NO_PROXY=localhost,127.0.0.1,docker.jcing.com"' >> /etc/systemd/system/docker.service.d/http-proxy.conf
systemctl daemon-reload
# 检查输出
systemctl show --property=Environment docker
systemctl restart docker安装docker:
$ yum install -y docker-engine
$ systemctl enable docker && systemctl start docker安装kubernetes:
# 关闭SELinux
$ setenforce 0
$ yum install -y kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable kubelet && systemctl start kubelet确保shell中没有设置http_proxy和https_proxy环境变量,然后执行下面的初始化命令:
$ kubeadm initkubernetes会自动从google服务器中下载相关的docker镜像,大致输出如下:
<master/tokens> generated token: "f0c861.753c505740ecde4c"
<master/pki> created keys and certificates in "/etc/kubernetes/pki"
<util/kubeconfig> created "/etc/kubernetes/kubelet.conf"
<util/kubeconfig> created "/etc/kubernetes/admin.conf"
<master/apiclient> created API client configuration
<master/apiclient> created API client, waiting for the control plane to become ready
<master/apiclient> all control plane components are healthy after 61.346626 seconds
<master/apiclient> waiting for at least one node to register and become ready
<master/apiclient> first node is ready after 4.506807 seconds
<master/discovery> created essential addon: kube-discovery
<master/addons> created essential addon: kube-proxy
<master/addons> created essential addon: kube-dns
Kubernetes master initialised successfully!
You can connect any number of nodes by running:
kubeadm join --token <token> <master-ip>如果卡在<master/apiclient> created API client, waiting for the control plane to become ready这一步,请检查网络,很有可能是无法从服务器拉取镜像所导致的。
一个简单的测试代理是否可用的方法:
# 下面这一步会卡死
$ curl www.google.com
# 下面的会有返回
$ http_proxy=http://<proxy ip>:<proxy port> curl www.google.com如果卡在<master/apiclient> waiting for at least one node to register and become ready或者<master/discovery> created essential addon: kube-discovery,可以通过systemctl status kubelet查看信息,也许能发现卡住的原因。
输出的最后一行很重要,kubeadm join --token <token> <master-ip>,请记录。
如果集群的master上也可以部署pod,执行下面的命令:
$ kubectl taint nodes --all dedicated-
node "test-01" tainted
taint key="dedicated" and effect="" not found.
taint key="dedicated" and effect="" not found.如果某部配置失败,需要清理环境重新执行:
# 查看已经存在的的namespace并删除
$ kubectl get namespace
$ kubectl delete namespace sock-shop
# 清理环境
$ kubeadm reset
# 重新执行
$ systemctl start kubelet.service
$ kubeadm init$ kubectl apply -f https://git.io/weave-kube节点也需要能够正常访问google服务的,按照0、1、2步做好准备工作后,执行命令:
# 这一行就是kubeadm init命令的最后一行输出,token是加入秘钥,master-ip是集群master的IP
$ kubeadm join --token <token> <master-ip>
<util/tokens> validating provided token
<node/discovery> created cluster info discovery client, requesting info from "http://138.68.156.129:9898/cluster-info/v1/?token-id=0f8588"
<node/discovery> cluster info object received, verifying signature using given token
<node/discovery> cluster info signature and contents are valid, will use API endpoints [https://138.68.156.129:443]
<node/csr> created API client to obtain unique certificate for this node, generating keys and certificate signing request
<node/csr> received signed certificate from the API server, generating kubelet configuration
<util/kubeconfig> created "/etc/kubernetes/kubelet.conf"
Node join complete:
* Certificate signing request sent to master and response
received.
* Kubelet informed of new secure connection details.
Run 'kubectl get nodes' on the master to see this machine join.
# 检查集群中的节点
$ kubectl get nodes装完没什么用,可以不装,跳过这一步。
# 新建namespace
$ kubectl create namespace sock-shop
# 安装应用
$ kubectl apply -n sock-shop -f "https://github.com/microservices-demo/microservices-demo/blob/master/deploy/kubernetes/complete-demo.yaml?raw=true"
# 查看应用
$ kubectl describe svc front-end -n sock-shop
Name: front-end
Namespace: sock-shop
Labels: name=front-end
Selector: name=front-end
Type: NodePort
IP: 100.66.88.176
Port: <unset> 80/TCP
NodePort: <unset> 31869/TCP
Endpoints: <none>
Session Affinity: None
$ kubectl get pods -n sock-shop
NAME READY STATUS RESTARTS AGE
cart-2013512370-0ii5d 1/1 Running 2 4d
cart-db-1445314776-1opbe 1/1 Running 0 1h
catalogue-3777349842-ko0ps 1/1 Running 2 4d
catalogue-db-2196966982-jihxd 1/1 Running 0 1h
front-end-697319832-7mlos 1/1 Running 2 4d
orders-3580282209-urdkx 1/1 Running 0 1h
orders-db-1215677090-9g5ui 1/1 Running 2 4d
payment-1376044718-1lej0 1/1 Running 0 1h
queue-master-1190579278-yvm1a 1/1 Running 2 4d
rabbitmq-1897447621-wymmw 1/1 Running 0 1h
shipping-589875162-30gg9 1/1 Running 2 4d
user-3338781425-bsyc0 1/1 Running 2 4d
user-db-710789251-32e0j 1/1 Running 0 1hDashboard是kubernetes的网页端可视化界面,配置的前提是kube-dns和weave网络启动正常。
# 安装dashboard
$ kubectl create -f https://rawgit.com/kubernetes/dashboard/master/src/deploy/kubernetes-dashboard.yaml因为使用kubeadm安装的集群是不带认证的,所以无法直接从https://<master ip>/ui访问。
但是可以找到暴露的本机IP:
$ kubectl describe services kubernetes-dashboard -n kube-system
Name: kubernetes-dashboard
Namespace: kube-system
Labels: app=kubernetes-dashboard
Selector: app=kubernetes-dashboard
Type: NodePort
IP: 10.107.143.60
Port: <unset> 80/TCP
NodePort: <unset> 30353/TCP
Endpoints: 10.32.0.24:9090
Session Affinity: None
No events.#找到NodePort,然后直接访问http://<master ip>:30353就能够进入dashboard。参考这个Issue。

Dashboard的github README上介绍说,要启用图形化监控cpu和内存,需要在集群上运行heapster。
git clone https://github.com/kubernetes/heapster.git ~/heapster
cd ~/heapster
kubectl apply -f deploy/kube-config/influxdb/文档上说也要安装deploy/kube-config/google下的东西,我们是不需要的,只要安装了influxdb就可以了。
ps: 如果需要卸载,运行kubectl delete -f deploy/kube-config/influxdb就行。其他按照文件安装的pod也可以使用“delete -f”参数来删除。

使用kubeadm安装 #kubernetes #官方文档
Dashboard #kubernetes #官方文档 #dashboard
在centos上安装docker #docker #官方文档
为docker配置http代理 #docker #官方文档
Dashboard #kubernetes #github #dashboard
Dashboard关于“Unauthorized”的Issue #kubernetes #github #dashboard
Heapster # kubernetes #github #dashboard
Tags: 印象笔记
[toc]
如果文件名是中文,会显示形如274\232\350\256\256\346\200\273\347\273\223.png的乱码。
在bash提示符下输入:
git config --global core.quotepath falsecore.quotepath 设为false的话,就不会对0×80以上的字符进行quote。中文显示正常。
- 完 -
Tags: 印象笔记 Docker
docker官方文档Docker container networking的笔记。
[toc]
docker network ls:列出当前docker中已有的网络docker network inspect:查看网络详情,比如查看网络中有哪些容器docker run --network=<NETWORK>:指定运行容器时使用哪个网络docker默认提供了3种网络:bridge、host、none。
host网络容器的网络接口跟主机一样。
none网络除了lo接口外,容器没有任何其他网络接口。
bridge网络这是新建容器时默认使用的网络,也是使用得最多的网络。网络中的所有容器可以通过IP互相访问。
bridge网络通过网络接口docker0跟主机桥接,可以在主机上通过ifconfig docker0查看到该网络接口的信息。
bridge这是自定义网络中最简单的,跟docker提供的默认bridge相差无几。
$ docker network create --driver bridge isolated_nw
1196a4c5af43a21ae38ef34515b6af19236a3fc48122cf585e3f3054d509679b
$ docker network inspect isolated_nw
[
{
"Name": "isolated_nw",
"Id": "1196a4c5af43a21ae38ef34515b6af19236a3fc48122cf585e3f3054d509679b",
"Scope": "local",
"Driver": "bridge",
"IPAM": {
"Driver": "default",
"Config": [
{
"Subnet": "172.21.0.0/16",
"Gateway": "172.21.0.1/16"
}
]
},
"Containers": {},
"Options": {},
"Labels": {}
}
]
$ docker network ls
NETWORK ID NAME DRIVER
9f904ee27bf5 none null
cf03ee007fb4 host host
7fca4eb8c647 bridge bridge
c5ee82f76de3 isolated_nw bridge
$ docker run --network=isolated_nw -itd --name=container3 busybox
8c1a0a5be480921d669a073393ade66a3fc49933f08bcc5515b37b8144f6d47c
$ docker network inspect isolated_nw
[
{
"Name": "isolated_nw",
"Id": "1196a4c5af43a21ae38ef34515b6af19236a3fc48122cf585e3f3054d509679b",
"Scope": "local",
"Driver": "bridge",
"IPAM": {
"Driver": "default",
"Config": [
{}
]
},
# 注意"Containers"字段,跟之前相比,多了我们加进去的容器。
"Containers": {
"8c1a0a5be480921d669a073393ade66a3fc49933f08bcc5515b37b8144f6d47c": {
"EndpointID": "93b2db4a9b9a997beb912d28bcfc117f7b0eb924ff91d48cfa251d473e6a9b08",
"MacAddress": "02:42:ac:15:00:02",
"IPv4Address": "172.21.0.2/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]两点限制:
link,可以通过暴露容器端口使外部网络来访问容器(?????)docker_gwbridge在下列两种情况下,docker_gwbridge网络会自动被docker创建
可以提前自己创建docker_gwbridge网络,否则docker会按默认的创建:
$ docker network create --subnet 172.30.0.0/16 \
--opt com.docker.network.bridge.name=docker_gwbridge \
--opt com.docker.network.bridge.enable_icc=false \
docker_gwbridgeoverlay可以在swarm的节点中创建overlay网络,该网络只对swarm集群的服务有效,在节点上不属于swarm集群的容器,运行docker run指令是无法使用该网络的。
# Create an overlay network `my-multi-host-network`.
$ docker network create \
--driver overlay \
--subnet 10.0.9.0/24 \
my-multi-host-network
400g6bwzd68jizzdx5pgyoe95
# Create an nginx service and extend the my-multi-host-network to nodes where
# the service's tasks run.
$ docker service create --replicas 2 --network my-multi-host-network --name my-web nginx
716thylsndqma81j6kkkb5ausoverlay如果overlay网络不是运行在swarm集群中,则需要一个KV存储,如Consul、Etcd、Zookeeper等。
# 创建overlay网络
docker network create --driver overlay my-multi-host-network网络中的容器互相连通,不管是在哪台主机上。
docker运行了一个内置的DNS服务器,容器在做域名解析时先访问内置的DNS,失败后再去访问外网的DNS。
- 完 - 2017/03/13
=最基本的赋值。make会将整个makefile展开后,再决定变量的值。也就是说,变量的值将会是整个makefile中最后被指定的值。
x = foo
y = $(x) bar
x = xyz
y的值将会是xyz bar,而不是foo bar.
:=覆盖之前的值,变量的值决定于它在makefile中的位置,而不是整个makefile展开后的最终值。
x := foo
y := $(x) bar
x := xyz
y的值将会是foo bar,而不是xyz bar.
?=如果没有被赋值过就赋予等号后面的值
+=添加等号后面的值
- 完 -
Tags: 印象笔记
[toc]
Given an array of numbers nums, in which exactly two elements appear only once and all the other elements appear exactly twice. Find the two elements that appear only once.
For example:
Given nums = [1, 2, 1, 3, 2, 5], return [3, 5].
note
1. The order of the result is not important. So in the above example, [5, 3] is also correct.
2. Your algorithm should run in linear runtime complexity. Could you implement it using only constant space complexity?
class Solution(object):
def singleNumber(self, nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
from operator import xor
all_xor = reduce(xor, nums) # 这两个数字的异或值
last_bit = all_xor & -all_xor # 取到最右边的那个1,具体百度"x & -x"
# last_bit只有1位为1,其他位都为0
list1 = [x for x in nums if not (x & last_bit)]
list2 = [x for x in nums if (x & last_bit)]
return [reduce(xor, list1), reduce(xor, list2)]- 完 -
Tags: 印象笔记 Docker
docker官方文档Understand images, containers, and storage drivers的笔记。
[toc]
镜像是由一组只读的图层组成,这些图层自下而上以栈(stack)的形式互相关联,每层图层中都存储了文件系统级别上与下一层图层的差异。如图所示。
docker的存储驱动用来管理这些图层,在逻辑上(非存储上)提供一个单一的扁平的视图,就好像在上图最上面提供了一个平面视图,当我们从上往下看时,看到了这个镜像完整的文件系统。
当我们根据镜像来创建容器时,docker会在镜像的图层(所有只读的图层)之上,再添加一层可读写的图层,被称为"容器图层"。所有对容器的改动都只会写到容器图层中去,而不会影响到下面只读的镜像图层。如图所示。
docker在1.10版本中引入了新的存储模型:内容寻址存储。
之前的版本中,镜像和图层的UUID只是一个随机值,但是在新模型中,这个UUID是镜像和图层的内容哈希值。
这种新的计算方式在避免UUID冲突(因为之前是随机生成的)的同时,也保证了数据在一些操作(push、pull、load等)之后的完整性。在不同的构建过程中,也可以更好的复用图层,因为有一样的基于内容的哈希值。
注意,这只限于镜像图层,容器图层还是随机的UUID。如图所示。
从老版本的docker迁移到新版本的docker时,会自动将镜像的存储模型迁移到新的内容寻址存储。在更新后的docker服务启动时,docker会自动的去计算内容哈希值,但是如果镜像数据量特别大的话,还是会消耗很多时间,而在这段时间内,docker服务是不可用的,而这对很多用户来说是不可接受的。
docker提供了一个迁移工具,可以在升级docker服务之前就开始迁移数据。具体的可以查看github上的v1.10-migrator。
容器与镜像的区别在于,容器是在镜像图层之上新增了一层可读写的图层,所以一个镜像可以生成多个容器,而每个容器又可以有自己的数据。如图所示。
当容器被删除时,其新增的可读写层也一起被删除。
docker的存储驱动负责管理镜像图层和容器图层,但背后的逻辑却因不同的存储驱动而不同,而其中的两个关键技术就是:镜像图层的可栈化(stackable)和写时拷贝技术(copy-on-write, CoW)。
简单来说,就是多个系统应用需要使用同一块数据时,如果是读取数据,那大家就一起读取,如果有应用要写入数据时,系统为这个应用单独的复制这一块数据,应用只往数据副本中写入,等写完了,操作系统再把副本合并到原数据中去。
CoW技术对性能会有一定的影响,不同的存储驱动实现CoW的操作不一样,受CoW的性能影响也不同。
当容器被删除时,所有不在数据卷中的数据都会被删除,这是因为数据卷不在容器图层中。删除容器时容器图层会被删除,但数据卷不会。
数据卷绕过了存储驱动,也被排除在本地的文件系统之外。下图显示了容器和数据卷的使用。
- 完 - 2016/03/10
Tags: Docker 印象笔记
docker官方文档Select a storage driver的笔记。
[toc]
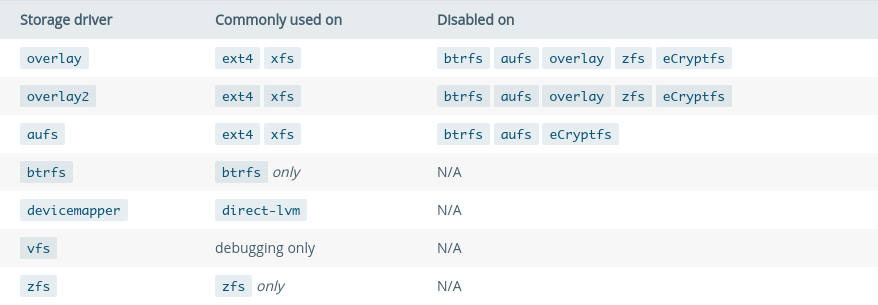
docker的存储驱动是基于Linux的文件系统的,在此之上,每一种存储驱动都有一套自己的管理镜像图层和容器图层的实现。可以用docker info来查看当前所使用的存储驱动。
$ docker info
Containers: 0
Images: 0
Storage Driver: overlay
Backing Filesystem: extfs
Execution Driver: native-0.2
Logging Driver: json-file
Kernel Version: 3.19.0-15-generic
Operating System: Ubuntu 15.04
... output truncated ...
上面的输出指明docker正在使用overlay存储驱动,而其背后的文件系统是extfs。能否使用某种存储驱动,是跟主机的文件系统有关的,下图显示了这种依赖关系:
可以使用docked --storage-driver=<name>来指定存储驱动。
overlay和overlay2都是OverlayFS,但是是不同的实现,并且不兼容,这意味着在这两种存储驱动间切换,会重现构建所有的镜像内容。overlay是早期的实现,在docker 1.11之前这是唯一的选择。overlay有inode限制,commit时有性能问题。overlay2解决了这些问题,但是只在Linux内核版本4.0之后才能使用。
- 完 - 2017/03/20

Pod无法通过Service访问自己的端口,但是其他Pod可以通过该Service访问到该Pod的端口
解决方法:
ip link set docker0 promisc on参考: github issue
- 完 -
在阅读为数不多的计算机类书籍时,我总是想方设法的套用《如何阅读一本书》中的方法,先看封面目录前言,然后针对每一个章节细啃。往往一本中等厚度的书,我可以翻来覆去看上好几个月。一来是因为自己懒,看书频率低,二来是因为在每次看书之前想不起来之前说了什么,害怕无法接受接下来的知识,又会回过头去翻一翻前面的内容。好不容易整本书看完了,又感觉看完之后感觉不扎实,脑子有点空,害怕睡一觉就会全部忘记,就后悔没记笔记,好像浪费了阅读的时间。等开始看第二遍准备记笔记的时候,又炸毛了:唉这点我上次看怎么一点印象都没有,唉这里有个大坑我要把这一大段话全部记下来别以后往坑里跳了,唉这章内容我现在根本用不上要不要记啊...?就这样又纠结又费力的过了几个月,终于自我感觉稳妥了,可以把书扔了以后靠笔记过活,然后笔记一存档,再也没回顾过。坑依然踩,踩了坑就google,顺手又把别人的解决方案机械化的记录一下,看起来是又学习到了新东西。
总结一下上面出现的问题。
列了这么多,其实几个字就能完全概括:缺乏主动阅读,这是《如何阅读一本书》中一再强调的方法,我却从来没有应用到自己身上。
哈佛公开课《幸福课》中对积极心理学也提到了类似的问题:概念,或者说解决方法,简而概之就是如此,道理大家都懂,但是真正能应用到自己的生活中去的人,却寥寥无几。
实践,实践,实践。
是的,我需要重新安排自己的学习方式了。当然我不会按照分析阅读的方式去阅读技术书籍,一来章节太多问题太多规则也太多,没有精力,二来计算机类的书籍如果不写代码等于荒废一半。
对于不需要详读的书,我会利用思维导图梳理书中的内容结构,加上自己阅读时出现的疑点和答案,记录下来,作为读书笔记回顾。
对于需要详读的书,我会利用问题来引导阅读,详细解答自己的问题并记录。减少技术上的细枝末节,简要记录流程、原理,不记录操作、命令、基础代码。
- 完 -
跳过
将网络层的IP数据包拆分,加上帧首部和帧尾部封装成帧后,再发送出去,一般使用控制字符来表示帧定界符:
链路层应该对网络层透明,即网络层不管给什么数据,链路层都是可以发送过去的。但是有这样的情况:网络层给的数据中,也包含了跟帧定界符一样的字符,该怎么判定这个字符是要传输的数据,还是帧定界符呢?
下图中出现帧判定错误:
答案是使用转义字符,通过字节填充的方式,转义掉数据中的控制字符。如果数据中也包括转义字符,则再在前面加一个转义字符:
链路层在传输数据时,可能会出现两种错误:
0变1,1变0OSI要求链路层是可靠的,但实际上链路层出错的概率很低,当前实现上都已经不再使用帧确认、重传了,这部的处理交给了上层协议,所以链路层实际上是不可靠的。
将数据分组,通过CRC校验计算帧校验序列,附加到在每组数据的后面,再封装成帧后发送出。接收端进行校验,丢弃出错的帧。可以认为“凡是接收端的链路层所接受的帧均无差错”。
交换机是多接口网桥,通过自学习完善转发表。
IPV4或IPV6。20字节~60字节,必须是4字节的整数倍,不足4字节时填充。链路层的MTU时,需要对IP数据报进行分片,这时总长度指的是分片后每个分片的首部长度和数据长度的总和。后面是否还有分片和能否分片。
1,为0时则丢弃数据报,最大值255。若设为1,表示只在本局域网中传送。在一个网络中,将IP地址中的主机号部分,取前几位作为子网编号,对网络进行划分。子网划分增加了网络的灵活性,却减少了网络中的主机总数。
IP地址与子网掩码进行与运算,得到网络地址。
CIDR其实就是将IP地址分成可变长度的两部分,前面是网络前缀,后面是主机号。用<IP地址>/<前缀长度>这样的记法。
在路由表中进行匹配时,从匹配结果中选择具有最长网络前缀的路由,使用二叉线索树来查找:
由于上面用的是“唯一前缀”,并非“网络前缀”,所以找到叶子节点后,再将目的地址和叶子节点的子网掩码进行与运算,看是否匹配。至于如何从路由表的IP地址中,计算出所有的唯一前缀,是一道算法题:trie树,关键字“字符串最短唯一前缀”。
无连接、不可靠,面向报文,即应用层下来的数据,直接添加头部就交给网络层,没有合并和拆分。
UDP校验时,把首部和数据部分一起校验,IP数据报是只校验首部的。
面向连接、可靠,点对点,全双工通信,字节流。
这种可靠传输协议也叫自动重传请求ARQ(Automatic Repeat-reQuest)。停止等待协议很慢,信道利用率也很低,所以使用流水线传输,即连续ARQ协议和滑动窗口协议。
几个重要字段:
由于对网络负荷的情况不清楚,先探测一下,由小到大逐渐增大发送窗口,每经过一次传输轮训,拥塞窗口cwnd就加倍。
让cwnd缓慢增大,每次加1,线性增长,而不是加倍
接收方每收到一个失序的报文,就立即发出重复确认,而不用等待自己发送数据时才进行捎带确认。
发送方一连收到三个重复确认就立即重传对方尚未收到的报文。
发送方一连收到三个重复确认时,就“乘法减小”,把ssthresh减半,然后执行拥塞避免算法,“加法增大”
建立连接:
释放连接:
为什么连接的时候是三次握手,关闭的时候是四次挥手呢?因为发送FIN时,只是表示自己这一方不再有数据要发送,但是对方发送的数据,还是需要继续接收,直到对方也发送FIN后才可以断开连接。
Tags: 印象笔记
[toc]
You are playing the following Nim Game with your friend: There is a heap of stones on the table, each time one of you take turns to remove 1 to 3 stones. The one who removes the last stone will be the winner. You will take the first turn to remove the stones.
Both of you are very clever and have optimal strategies for the game. Write a function to determine whether you can win the game given the number of stones in the heap.
For example, if there are 4 stones in the heap, then you will never win the game: no matter 1, 2, or 3 stones you remove, the last stone will always be removed by your friend.
hint
If there are 5 stones in the heap, could you figure out a way to remove the stones such that you will always be the winner?
其实就是找规律.
| 石子数 | 先手者赢 | 说明 |
|---|---|---|
| 1 | True | |
| 2 | True | |
| 3 | True | |
| 4 | False | 不管A取几个, B总是[1, 2, 3], 相当于在[1, 2, 3]时B先手 |
| 5 | True | A取1, B会到4, 相当于在4时B先手, 会输 |
| 6 | True | A取2, 同上 |
| 7 | True | A取3, 同上 |
| 8 | False | 不管A取几个, B总是[5, 6, 7], 相当于在[5, 6, 7]时B先手 |
| 9 | True | A取1, B会到8, 相当于在8时B先手, 会输 |
| ... | ... | ... |
class Solution(object):
def canWinNim(self, n):
"""
:type n: int
:rtype: bool
"""
return not n % 4 == 0- 完 -
Tags: 印象笔记
[TOC]
如果apt、yum、brew中有已编译好的,可以直接用。
自用系统是Centos7,只启用了163的源,所以都需要自己编译安装。
shadowsocks与privoxy都安装到/opt,为了卸载方便我也保留了源码目录。
mkdir /opt/shadowsocks-libev
mkdir /opt/privoxyyum install gcc autoconf libtool automake make zlib-devel openssl-devel asciidoc xmlto
git clone https://github.com/shadowsocks/shadowsocks-libev /opt/shadowsocks-libev/src
cd /opt/shadowsocks-libev/src
./configure —prefix=/opt/shadowsocks-libev/
make && make install# 这只是测试命令,无法直接使用
/opt/shadowsocks-libev/bin/ss-local -s test.ssv7.net -p 29354 -b 127.0.0.1 -l 1080 -k 111111 -m aes-256-cfb > /opt/shadowsocks-libev/ss.log 2>&1 &自己去privoxy的官网下载源码压缩包。
tar -zxvf privoxy.tar.gz
mv privoxy /opt/privoxy/src
cd /opt/privoxy/src
./configure —prefix=/opt/privoxy/
make && make install修正/opt/privoxy/etc/config文件,在最后增加一行:forward-socks5 / 127.0.0.1:1080 .
/opt/privoxy/sbin/privoxy /opt/privoxy/etc/config > /opt/privoxy/privoxy.log 2>&1反正加到开机启动项里就能直接用......
#!/usr/bin/env sh
/opt/shadowsocks-libev/bin/ss-local -s test.ssv7.net -p 29354 -b 127.0.0.1 -l 1080 -k 111111 -m aes-256-cfb > ss.log 2>&1 &
/opt/privoxy/sbin/privoxy --no-daemon /opt/privoxy/etc/config > privoxy.log 2>&1 &Tags: 印象笔记 Docker
[toc]
Docker Machine启动后会执行/var/lib/boot2docker/bootlocal.sh文件中的命令。
/var/lib/boot2docker/bootlocal.sh文件,内容如下:mkdir -p /work
mount -t vboxsf -o defaults,uid=`id -u docker`,gid=`id -g docker` work /work/var/lib/boot2docker/bootlocal.sh文件,内容如下:ifconfig eth2 192.168.2.171 netmask 255.255.255.0 broadcast 192.168.2.255 upDocker Machine中,/var是/mnt/sda1/var的软链接,根据df -h查看到/dev/sda1挂载在/mnt/sda1/下,这部分的内容是保存在硬盘中的,重启后仍然存在。所以如果需要在Docker Machine中保存数据,不至于重启之后就不见,可以将数据保存在/mnt/sda1/目录下,然后在/var/lib/boot2docker/bootlocal.sh中软链接到所需的位置。
mkdir /etc/systemd/system/docker.service.d
echo '[Service]' > /etc/systemd/system/docker.service.d/http-proxy.conf
echo 'Environment="HTTP_PROXY=http://127.0.0.1:8118/" "NO_PROXY=localhost,127.0.0.1,docker.jcing.com"' >> /etc/systemd/system/docker.service.d/http-proxy.conf
systemctl daemon-reload
systemctl show --property=Environment docker # Environment=HTTP_PROXY=http://proxy.example.com:80/
systemctl restart docker参考资料:docker proxy
curl -X GET http://docker.jcing.com:5000/v1/search?q=infopub_base2017/03/22 更新
根据官方文档定义,可以在/etc/docker/daemon.json中配置除http_proxy以外的所有dockerd的配置,这是最标准的做法。参见dockerd
原方案
需要启用--insecure-registry参数,修改其中一个配置文件就好:
/etc/sysconfig/docker,在OPTIONS后增加--insecure-registry your.dock.registry/usr/lib/systemd/system/docker.service中的ExecStart变量中增加--insecure-registry your.dock.registry如果宿主机的网络调整过,网络服务被重启,那docker服务也需要重启,不然可能会影响到docker容器。踩了一回大坑。
- 完 - 2017/03/14
Tags: 印象笔记
[toc]
如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure)。
>>>def addx(x):
>>> def adder(y): return x + y
>>> return adder
>>> c = addx(8)
>>> type(c)
<type 'function'>
>>> c.__name__
'adder'
>>> c(10)
18在函数addx()的中,内部函数adder()是闭包,因为它除了调用了自身的参数y以外,也引用了外部函数addx()的参数x。
注意点
闭包不能修改外部作用域的局部变量。
>>> def foo():
m = 0
def foo1():
m = 1
print m
print m
foo1()
print m
>>> foo()
0
1
0一种典型的错误:
# 错误的用法
def foo():
a = 1
def bar():
a = a + 1 # a被解析为bar中的局部变量,但是右侧的a会找不到值
return a
return bar# 正确的用法
def foo():
a = 1
def bar():
nonlocal a #指明a不是bar()的局部变量,这样a就被解析为foo中的变量
a = a + 1
return a
return barpython的函数只有在执行时,才会去找函数体里的变量的值。
前提:当循环结束以后,循环体中的临时变量i不会销毁,而是继续存在于执行环境中。
for i in range(3):
print i错误的用法:输出为4,4,4
flist = []
for i in range(3):
def foo(x): print x + i
flist.append(foo)
for f in flist: #此时i的值为2
f(2) #执行 print 2 + 2正确的用法:输出为2,3,4
flist = []
for i in range(3):
def foo(x, y=i): print x + y
flist.append(foo) #被添加到flist的是foo(x, 0), foo(x, 1), foo(x, 2)
for f in flist:
f(2)origin = [0, 0] # 坐标系统原点
legal_x = [0, 50] # x轴方向的合法坐标
legal_y = [0, 50] # y轴方向的合法坐标
def create(pos=origin):
def player(direction,step):
# 这里应该首先判断参数direction,step的合法性,比如direction不能斜着走,step不能为负等
# 然后还要对新生成的x,y坐标的合法性进行判断处理,这里主要是想介绍闭包,就不详细写了。
new_x = pos[0] + direction[0]*step
new_y = pos[1] + direction[1]*step
pos[0] = new_x
pos[1] = new_y
#注意!此处不能写成 pos = [new_x, new_y],原因在上文有说过
return pos
return player
player = create() # 创建棋子player,起点为原点
print player([1,0],10) # 向x轴正方向移动10步
print player([0,1],20) # 向y轴正方向移动20步
print player([-1,0],10) # 向x轴负方向移动10步输出为
[10, 0]
[10, 20]
[0, 20]def make_filter(keep):
def the_filter(file_name):
file = open(file_name)
lines = file.readlines()
file.close()
filter_doc = [i for i in lines if keep in i]
return filter_doc
return the_filter如果我们需要取得文件"result.txt"中含有"pass"关键字的行,则可以这样使用例子程序
filter = make_filter("pass")
filter_result = filter("result.txt")- 完 -
Tags: 印象笔记
[toc]
有系统的略读或粗读
粗浅的阅读
待补充
待补充
- 完(废弃) -
Tags: 印象笔记
[toc]
Given a binary tree, find its maximum depth.
The maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.
因为给的是二叉树,所以直接利用递归依次遍历两个子节点来计算深度就好。第一次做这样的题,如果不看讨论区里的答案,还真不知道怎么去写。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def maxDepth(self, root):
"""
:type root: TreeNode
:rtype: int
"""
return 1 + max(self.maxDepth(root.left), self.maxDepth(root.right)) if root else 0- 完 -
Tags: 印象笔记
[toc]
Given two binary trees, write a function to check if they are equal or not.
Two binary trees are considered equal if they are structurally identical and the nodes have the same value.
又是二叉树,想到第104题求树的深度的问题,自然而然的又想起用递归去做。
但是需要考虑到节点为None的情况是需要另作处理的。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def isSameTree(self, p, q):
"""
:type p: TreeNode
:type q: TreeNode
:rtype: bool
"""
if p is None and q is None:
return True
elif p is None and q is not None:
return False
elif p is not None and q is None:
return False
else:
if p.val == q.val:
return True and self.isSameTree(p.left, q.left) and self.isSameTree(p.right, q.right)
else:
return False精简代码,上面的代码分段太多
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def isSameTree(self, p, q):
"""
:type p: TreeNode
:type q: TreeNode
:rtype: bool
"""
if not p and not q:
return True
elif not p or not q:
return False
else:
return (True and self.isSameTree(p.left, q.left) and self.isSameTree(p.right, q.right)) if p.val == q.val else False看了讨论区的答案,最终有了一行代码的解答,真的是太精简了...
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def isSameTree(self, p, q):
"""
:type p: TreeNode
:type q: TreeNode
:rtype: bool
"""
return (p.val == q.val and self.isSameTree(p.left, q.left) and self.isSameTree(p.right, q.right)) if (p and q) else (p == q)- 完 -
Tags: 印象笔记
昨天碰到一个很有趣的问题,我使用第三方库python-docx对docx文档进行操作,本地代码一切顺利,docker push到仓库,然后部署到105上时,却出错了:
Traceback (most recent call last):
File "/work/nav_biz/nav_biz_portal/src/infopub/apis/apply_records.py", line 22, in <module>
from docx import Document
File "/opt/python/lib/python2.7/site-packages/docx/__init__.py", line 3, in <module>
from docx.api import Document # noqa
...
...
...
File "/opt/python/lib/python2.7/site-packages/docx/enum/base.py", line 63, in _intro_text
return textwrap.dedent(cls_docstring).strip()
File "/usr/lib64/python2.7/textwrap.py", line 390, in dedent
text = _whitespace_only_re.sub('', text)
TypeError: expected string or buffer可以看到,我的代码里什么都没做,只是从第三方库里import就出错了,出错流程为:
奇怪,在容器镜像的hash值、git最后提交的hash值、没有多余pyc、pyo文件的情况下,为什么会出现不一样的结果。两边代码唯一的不同点在于:
我本地代码的uwsgi.ini配置中,为了能打印debug信息,将
optimize参数配置为0,而105上该参数的值为默认值9。
uwsgi文档中写道:
optimize
argument: required_argument
shortcut: -O
parser: uwsgi_opt_set_int
help: set python optimization level
set python optimization level。据我所知,该参数跟python解释器的-O和-OO参数有关。
-O参数的作用为:
.pyc修改到.pyo__debug__变量为False-OO参数除了上述作用以外,还有:
Python官方文档中对PYTHONOPTIMIZE环境变量的解释是,相当于执行多少次的-O。正常情况下,PYTHONOPTIMIZE的取值为0、1和2,分别对应不优化、-O、-OO。如果取值9,相当于执行:python -OOOOOOOOO,此时sys.flags.optimize的值为9。
根据上述的解释,我重新调整了uwsgi的optimize值,设置为0、1都可以正常执行代码,>=2的情况下就会出错。
遗留问题:PYTHONOPTIMIZE取值>2时,跟PYTHONOPTIMIZE=2有什么不同?
【完】 2017/02/07
Tags: 印象笔记 Python
[toc]
在pip install或者pip search时出现如下提示:
/home/hoh0/.pyenv/versions/2.7/envs/yihe.io/lib/python2.7/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:315: SNIMissingWarning: An HTTPS request has been made, but the SNI (Subject Name Indication) extension to TLS is not available on this platform. This may cause the server to present an incorrect TLS certificate, which can cause validation failures. For more information, see https://urllib3.readthedocs.org/en/latest/security.html#snimissingwarning.
SNIMissingWarning
/home/hoh0/.pyenv/versions/2.7/envs/yihe.io/lib/python2.7/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:120: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. For more information, see https://urllib3.readthedocs.org/en/latest/security.html#insecureplatformwarning.
InsecurePlatformWarning
需要在当前的虚拟环境中安装以下包:
pip install pyopenssl ndg-httpsclient pyasn1可能需要在系统中安装以下包(未测试):
sudo yum install libffi-dev libssl-dev
pip install flask --trusted-host pypi.jcing.com --index http://username:[email protected]/simple--trusted-host: 信任该url,即使不使用https协议
--index: 安装包时使用的源,如果是公开的pip源,可以不用加username:password
pip会把以PIP_开头的环境变量当做配置,所以如果有自定义的环境变量要和pip组合使用,不要以PIP_来命名自己的环境变量。如pip的用户名、密码要从环境变量读取,环境变量取名为PYTHON_PIP_USER和PYTHON_USER_PASSWORD,不要取名PIP_USER和PIP_PASSWORD,会提示ValueError: invalid truth value ...。
- 完 - 2017/03/14
Tags: 印象笔记
[toc]
EXTRA_DOCKER_OPTS="--insecure-registry=10.0.0.0/8。参考:官方文档$ curl -sSL http://deis.io/deis-cli/install-v2.sh | bash
$ curl -sSL https://get.helm.sh | bash这两个命令会在当前目录下下载deis和helmc两个可执行文件。移动到/usr/local/bin目录下。
$ mv deis helmc /usr/local/bin$ helmc repo add deis https://github.com/deis/charts$ helmc fetch deis/workflow-v2.8.0
$ helmc generate -x manifests workflow-v2.8.0
$ helmc install workflow-v2.8.0 成功安装后,可以通过kubernetes查看到有新的namespace和新的pod:
$ kubectl get namespace
$ kubectl --namespace=deis get pods等pod全部启动后,workflow就安装好了。
找到deis router的ip:
$ kubectl --namespace=deis describe svc deis-router然后注册用户:
$ deis register http://deis.104.197.125.75.nip.io这个nip.io暂时无法理解,参考官方文档。
$ deis create test-app --no-remotetest-app是我们的测试app,如果不指定,会自动生成一个。每个app都对应kubernetes中的一个namespace。
$ deis pull deis/example-go -a proper-barbecue向app中添加容器。在这一步卡住报错。参考这个Issue
注意:默认的storage使用的是minio,minio会在重启后丢失所有数据,所以如果重启了docker服务或者kubernetes,需要重新注册用户。
Tags: 印象笔记
[toc]
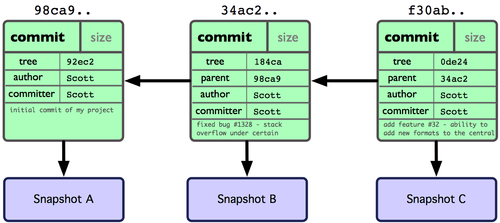
*:零个或多个任意字符 [abc]:a或b或c?:一个任意字符 [0-9]:0~9git diff:修改后未暂存起来的变化git diff --cached:已暂存未提交的变化git commit -a:所有跟踪的文件都提交git rm --cached:不再追踪文件git rm \*~:删除当前及子目录下以*~*结尾的文件,加""是为了不然shell进行转义git log -p -2:-p显示内容差异,-2显示最近两次git log -U1 --word-diff:-U1指定上下文为1行,--word-diff指定单词层面的对比git log --stat:显示增改行数统计git log --pretty=short|full|fuller|oneline:指定显示格式git log --pretty=format:"%h - %an, %ar : %s":format指定显示的内容
%H:提交对象(commit)的完整哈希字串%h:提交对象的简短哈希字串%T:树对象(tree)的完整哈希字串%t:树对象的简短哈希字串%P:父对象(parent)的完整哈希字串%p:父对象的简短哈希字串%an:作者(author)的名字%ae:作者的电子邮件地址%ad:作者修订日期(可以用 -date= 选项定制格式)%ar:作者修订日期,按多久以前的方式显示%cn:提交者(committer)的名字%ce:提交者的电子邮件地址%cd:提交日期%cr:提交日期,按多久以前的方式显示%s:提交说明git log --pretty=format:"%h %s" --graph:--graphSCII 字符串表示的简单图形-(n) 仅显示最近的 n 条提交--since, --after 仅显示指定时间之后的提交。--until, --before 仅显示指定时间之前的提交。--author 仅显示指定作者相关的提交。--committer 仅显示指定提交者相关的提交。--name-only 仅在提交信息后显示已修改的文件清单。--name-status 显示新增、修改、删除的文件清单。--abbrev-commit 仅显示 SHA-1 的前几个字符,而非所有的 40 个字符。--relative-date 使用较短的相对时间显示(比如,“2 weeks ago”)。--oneline --pretty=oneline --abbrev-commit 的简化用法。git commit --amend:修改最后一次提交git remote -v:显示远程仓库的地址git remote add [shortname] [url]:添加一个远程仓库,名字为shortname,地址为urlgit fetch [remote-name]:从远程仓库remote-name中拉取数据到本地,并不进行合并git push origin master:推送本地的master分支到远程仓库origingit remote show [remote-name]:显示远程仓库remote-name的详细信息git remote rename [old-name] [new-name]:重命名远程仓库在本地的简称git remote rm [shortname]:删除远程仓库git tag -l [pattern]:搜索tag,显示匹配pattern的taggit tag -a [tag-name] -m string obj:创建一个附注标签,并添加说明,若-a改为-s,则表示用GPG来签署标签(-a:annotated -s:signed -v:verify)git push origin [tagname]或git push origin --tags:推送标签到远程仓库git config --global alias.co checkout:别名,git co==git checkoutgit config --global alias.visual '!gitk':别名,git visual启动外部命令gitk
git checkout -b iss53==git branch iss53+git checkout iss53
git branch -d [branch-name]:删除分支
git merge [branch-name]:合并当前分支和branch-name指定的分支
git branch -v:查看各个分支最后一次提交的信息
git branch --merged|no-merged:查看哪些分支已经合并/未合并到当前分支(当前分支的直接上游)
git branch -D:强制删除未合并的分支(可能会丢失数据)
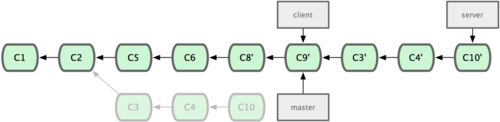
git push origin serverfix:awesomebranch:推送本地的serverfix分支到远程仓库origin,并命名为awesomebranchgit checkout -b serverfix origin/serverfix:origin/serverfix是远程仓库origin的分支serverfix在本地的克隆,这条语句是新建并转到一个分支,该分支以origin/serverfix为基础git checkout --track origin/serverfix:新建同名分支,来追踪远程分支origin/serverfixgit push origin :serverfix:删除远程分支(推送本地的空分支到远程的serverfix分支,即删除)git rebase --onto master server client:取出client分支,找出client分支和server分支的共同祖先之后的变化,然后把它们在master上重演一遍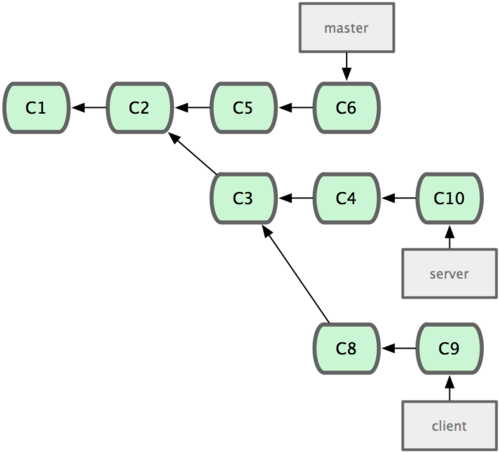
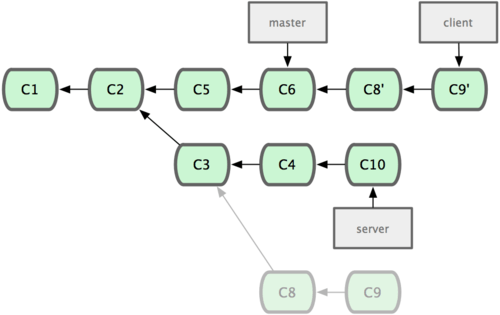
git rebase master server:把server分支rebase到master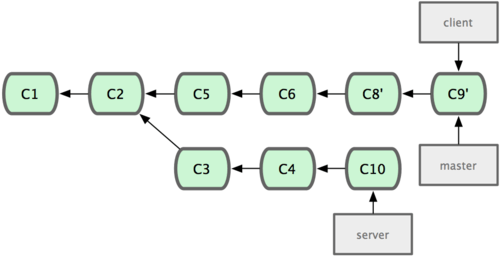
git clone file:///path/project.git
git clone /path/project.git
git clone ssh://user@server/path/project.git
git clone user@server:/path/project.git
缺少授权机制,所有人的权限相同,可以所有人都有clone权限,也可以所有人都有推送权限
git clone git://url/project.git
git clone http://url/project.git
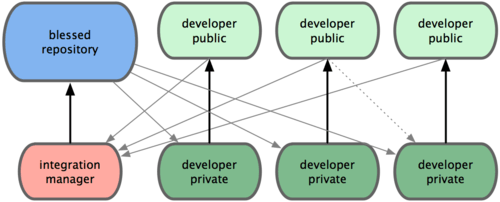
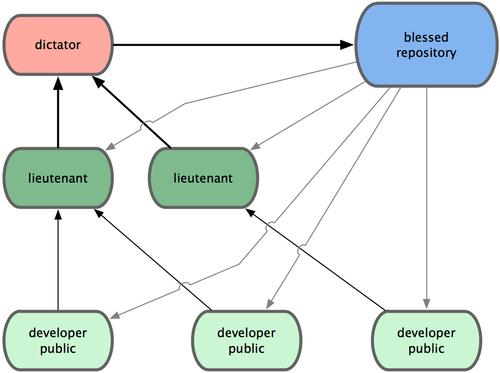
git diff --check:检查多余的空白字符
本次更新的简要描述(50 个字符以内)
如果必要,此处展开详尽阐述。段落宽度限定在 72 个字符以内。
某些情况下,第一行的简要描述将用作邮件标题,其余部分作为邮件正文。
其间的空行是必要的,以区分两者(当然没有正文另当别论)。
如果并在一起,rebase 这样的工具就可能会迷惑。另起空行后,再进一步补充其他说明。
可以使用这样的条目列举式。
一般以单个空格紧跟短划线或者星号作为每项条目的起始符。每个条目间用一空行隔开。
不过这里按自己项目的约定,可以略作变化。
sc/ruby_clientgit apply patch、git apply --check patch。事务性操作,要么全部打上要么全部放弃不会存在补丁打一半的情况git am patch、git am -3 patchgit log a -not master:查看a分支上但不在master分支上的提交git diff master...a:master到分支a的差别git cherry-pick e43a6fd3e94888d76:提取某次提交的补丁,应用在当前分支上git describe master:生成git版本号git archive master --prefix='project/' | gzip > `git describe master`.tar.gz
git archive master --prefix='project/' --format=zip > `git describe master`.zipgit shortlog --no-merges master --not v1.0.1:生成修改日志,自从v1.0.1版本以来的所有提交的简介git reflog:引用日志,只在本地有效,从仓库被clone时开始记录git show HEAD@{5}:查看仓库中* HEAD *在五次前的值git show master@{yesterday}:查看master分支昨天的情况git log master..experiment:所有可从experiment分支中获得而不能从master分支中获得的提交git log origin/master..HEAD:显示任何在当前分支上而不在远程origin上的提交git log refA refB ^refC、git log refA refB --not refC:查找所有从refA或refB包含的但是不被refC包含的提交git log master...experiment:查看master或者experiment中包含的但不是两者共有的引用git log --left-right master...experiment:显示每个提交到底处于哪一侧的分支git stash list:查看现有的储藏git stash apply stash@{2}:应用储藏,如果不指定名字,默认使用最近的储藏git stash drop:删除某次储藏git stash show -p stash@{0} | git apply -R:取消之前所应用储藏的修改git stash branch testchanges:从储藏中创建一个新的分支testchanges,并删除储藏git commit --amend:修改上一次的提交,会修改SHA-1的值,不要在推送到远程仓库后使用git rebase -i HEAD~3:修改最近3次的提交,修改pick为edit,修改完成后git rebase --continuegit filter-branch --tree-filter 'rm -f passwords.txt' HEAD:在所有提交中删除文件passwords.txt,--tree-filter会在每次检出项目时先执行指定的命令然后重新提交结果git blame -C -L 12,22 simplegit.rb:查看文件simplegit.rb中第12到22行的修改日志,-C显示代码的原始出处git bisect start
git bisect bad
git bisect good v1.0
...
git bisect reset或者有脚本在正常时返回0,错误时返回非0的话,可以完全自动地执行git bisect
git bisect start HEAD v1.0
git bisect run test-error.shgit submodule add url:添加子模块git submodule init、git submodule update:拉取、更新子模块$ git remote add rack_remote [email protected]:schacon/rack.git
$ git fetch rack_remote
$ git checkout -b rack_branch rack_remote/master
$ git checkout master
$ git read-tree --prefix=rack/ -u rack_branch当上游项目更新后,切换到rack_branch分支后pull后再归并
$ git checkout master
$ git merge --squash -s subtree --no-commit rack_branch获取rack_branch和和rack目录的区别,或者比较rack子目录和服务器上拉取时master分支的差别
$ git diff-tree -p rack_branch
$ git diff-tree -p rack_remote/mastergit config --global *** --> ~/.gitconfig,git config --system *** --> /etc/gitconfigcore.editor:文本编辑器commit.template:提交时的模版文件core.pager:分页器,默认为lesscore.excludesfile:类似*.gitignore*,不过在项目外不被git追踪help.autocorrect:自动校正color.ui:颜色merge.tool:合并工具core.autocrlf:行结束符CRLF转换成LF*.doc diff=wordgit config diff.word .textconv catdoc*.png diff=exifgit config diff.exif.textconv exiftoolgit archive创建压缩包时不包含该目录,在*.gitattributes*中追加test/ export-ignoredatabase.xml merge=ours- 完 -
Tags: 印象笔记
[toc]
Macbook开启vnc访问open vnc://centos-ip后提示不兼容此版本。
解决方法: Centos7设置VNC不加密:gsettings set org.gnome.Vino require-encryption false
- 完 -
指定容器运行时的默认参数,如果出现多次以最后依次为准。 依次应为一次
Tags: 印象笔记
[toc]
nginx有一个master进程和若干worker进程。worker进程的数量在配置文件中定义,可固定值也可根据cpu核心数来自动调整。
nginx -s 信号,其中信号可选值与意义如下:
| 信号 | 意义 |
|---|---|
| stop | 快速退出 |
| quit | 安全退出 |
| reload | 重载配置文件 |
| reopen | 重新打开日志文件 |
注:
reload信号会先检查配置文件合法性,如果配置无误会开启新的worker进程接收新到的请求,并发信号给老的worker进程,老的worker进程处理完当前的请求后会自动安全退出。
也可以使用kill命令,如kill -s QUIT 1628(1628为master进程号),另一个常用的kill -HUP 1628效果同reload信号。
配置文件由指令(simple directive)和指令块(block directive)组成,指令由;结束,指令块由{}组成,指令块可嵌套。不在指令块中的指令为主上下文(main context)。
以#开头的行是注释。
如event和http指令块在主上下面中,server指令块在http指令块中,location指令块在server指令块中。
http {
server {
location / {
root /data/wwww;
}
location /images/ {
root /data;
}
}
}
以*/images/开头的请求会加上/data形成本地的路径(/data/images/*)来获取资源,其他请求会直接到/data/www/目录下获取。
root指令的意思是指在完整的url前加上参数,形成本地的资源路径。location匹配规则:最早正则匹配>其他正则匹配>最长准确匹配>其他准确匹配server {
listen 8080;
root /data/up1;
location / {
}
}
监听8080端口,过来的所有请求去/data/up1获取资源。
server {
location / {
proxy_pass http://localhost:8080;
}
location /images/ {
root /data;
}
}
所有以*/images/开头的请求去/data/iamges*下获取资源,其他请求转发到本地的8080端口。
server {
location / {
proxy_pass http://localhost:8080/;
}
location ~ \.(gif|jpg|png)$ {
root /data/images;
}
}
以.gif、.jpg、.png结尾的url去*/data/images*下获取资源,其他请求转发到本地的8080端口。
~表示后面跟随的是正则。server {
location / {
fastcgi_pass localhost:9000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param QUERY_STRING $query_string;
}
location ~ \.(gif|jpg|png)$ {
root /data/images;
}
}
使用fastcgi_pass指令代替proxy_pass来表明使用的是FastCGI,fastcgi_param指令设置传递给FastCGI服务器的参数
- 完 -
Tags: 印象笔记
[toc]
HAWAII + IDAHO + IOWA + OHIO == STATES
每个字母对应一个数字,求解使等式成立时各个字母所代表的数字。
import re
import itertools
def solve(puzzle):
# re.findall返回puzzle中所有单词的列表
words = re.findall('[A-Z]+', puzzle.upper())
# 利用集和获取单词中不同的字母
unique_characters = set(''.join(words))
# 利用断言判断字母的个数,如果超过10个则触发异常(因为数字是0~9只有10个)
assert len(unique_characters) <= 10, 'Too many letters'
# 利用列表解析返回一个包含这些单词中不同的首字母的集和
first_letters = {word[0] for word in words}
# 获取不同的首字母的个数
n = len(first_letters)
# 对字母进行排序,将单词首字母放在字符串的前面
sorted_characters = ''.join(first_letters) + \
''.join(unique_characters - first_letters)
# 获取字母的ASCII值,并以元组的形式返回给characters
characters = tuple(ord(c) for c in sorted_characters)
# 获取数字的ASCII值,并以元组的形式返回给digits
digits = tuple(ord(c) for c in '0123456789')
zero = digits[0]
# 对[0-9]进行排列,排列中数字的长度为len(characters)
for guess in itertools.permutations(digits, len(characters)):
# 因为数值的第一个数字不可能是0,所以要排除掉这种情况
if zero not in guess[:n]:
# zip制造一个一一对应的元组,然后通过dict显示转换为字典,字典的键为字母,值为数字
# 通过translate将puzzle中相应的字母转换为数字,这样字母等式就全部变成了数字等式
equation = puzzle.translate(dict(zip(characters, guess)))
# 如果数字等式确实成立,则返回这个数字等式(字符串)
# eval原来判断数字等式是否成立,eval的参数可以是任何python表达式并且返回任何数据类型
if eval(equation):
return equation
if __name__ == '__main__':
import sys
# sys.argv表示命令行参数,其中argv[0]表示当前的python文件名
# 例如:python3 alphametics.py "HAWAII + IDAHO + IOWA + OHIO == STATES"
# 其中sys.argv[0]是"alphametics.py",sys.argv[1]是"HAWAII + IDAHO + IOWA + OHIO == STATES"
for puzzle in sys.argv[1:]:
print(puzzle)
# 根据函数solve来看,solution是等式成立时的数字字符串
solution = solve(puzzle)
if solution:
print(solution)$ python3 alphametics.py "HAWAII + IDAHO + IOWA + OHIO == STATES"
HAWAII + IDAHO + IOWA + OHIO = STATES
510199 + 98153 + 9301 + 3593 == 621246
$ python3 alphametics.py "I + LOVE + YOU == DORA"
I + LOVE + YOU == DORA
1 + 2784 + 975 == 3760
$ python3 alphametics.py "SEND + MORE == MONEY"
SEND + MORE == MONEY
9567 + 1085 == 10652- 完 -
Tags: 印象笔记 Linux
[toc]
:w !sudo tee%
w:vim中的保存!sudo:执行外部命令sudotee:从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件%:在vim中表示当前文件的文件名:r ! date
r:read的缩写,读取文件或者命令的输出! date:执行命令date:argdo %s/a_value/b_value/ge | update
argdo:arg中包含了vim所编辑的文件列表,命令:args可以显示当前的列表,:argadd file增加文件file到arg列表中,argdo可以对args中的所有文件执行操作%s/a_value/b_value/ge:全局替换,e的作用是不提示错误消息,使命令继续执行下去,具体参见:h s_flagsupdate:修改缓冲区后写入"+y, "+p, "+dset clipboard+=unnamed:execute '%!python -m json.tool' | w
Ctrl-W T
[I来显示搜索结果列表/中),按Ctrl-r Ctrl-w来快速输入当前光标所在的单词- 完 - 2016/03/15
Tags: 印象笔记
[toc]
git remote add -f <子仓库名> <子仓库地址>
git subtree add --prefix=<子目录名> <子仓库名> <分支> --squash
--squash意思是把subtree的改动合并成一次commit,这样就不用拉取子项目完整的历史记录。
--prefix之后的=等号也可以用空格。
git subtree pull --prefix=<子目录名> <远程分支> <分支> --squash
git subtree push --prefix=<子目录名> <远程分支名> 分支
- 完 -
需要启用--insecure-registry参数,修改其中一个配置文件就好:
/etc/sysconfig/docker,在OPTIONS后增加--insecure-registry your.dock.registry/usr/lib/systemd/system/docker.service中的ExecStart变量中增加--insecure-registry your.dock.registry如果宿主机的网络调整过,网络服务被重启,那docker服务也需要重启,不然可能会影响到docker容器。踩了一回大坑。
- 完 -
tags: 印象笔记
[toc]
Given an array of integers, every element appears twice except for one. Find that single one.
note
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
原来的想法是list(set(list_a)) * 2 - list_a,但是这样的空间复杂度好象不是O(1)的,好象用到set的地方就会产生额外的空间(并不确定)。
正确的解法应该是使用异或,异或的特点就是两个值如果相同就是Flase,不相同就是True。
class Solution(object):
def singleNumber(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
return reduce(lambda x, y: x ^ y, nums)- 完 -
自己太懒,搭建个人博客的事情被一拖再拖,直到最近愈发觉得读书无味,看过一遍之后脑中还是茫然一片,才意识到输出对于知识巩固的重要性。
不过也好,Better late than never,希望自己能坚持写一些文字,记录读书、生活和技术成长道路上的点点滴滴。
欢迎来到我的个人博客。
- 完 -
Tags: 印象笔记
[toc]
mysql -u ben -p -h myserver -P 9999-u:user
-p:need password
-h:host
-P:port,默认3306
USE yourdb;使用某个数据库
SHOW DATABASES/TABLES;
SHOW COLUMNS FROM yourtable; == DESCRIBE yourtable;显示已经存在的数据库/表/某表中的列
SHOW STATUS:显示服务器状态信息
SHOW CREATE DATABASE/TABLE:显示创建数据库/表的SQL语句
SHOW GRANTS:显示授权用户的安全权限
SHOW ERRORS/WARNINGS:显示服务器错误或警告信息
SELECT * FROM yourtable;
SELECT columnA, columnB, columnC FROM yourtable;SQL语句不区分大小写,忽略空格,以分号结尾
SELECT DISTINCT colunmA FROM yourtable;返回结果去重
SELECT columnA FROM yourtable LIMIT 5;
SELECT colunmA FROM yourtable LIMIT 5,6/LIMIT 4 OFFSET 6;限制返回结果为5行/5~5+6行
SELECT tableA.colunmA FROM dbA.tableASELECT colunmA, colunmB, columnC FROM tableA ORDER BY colunmA DESC, colunmC;从表tableA中选取colunmA,colunmB,colunmC列并按colunmA降序,colunmC升序的顺序排列
如果需要在多个列降序,需要在每个列中指定DESC
WHERE子句的操作符:=,!=,<>,<,<=,>,>=,BETWEEN
SELECT colunmA FROM tableA WHERE colunmA BETWEEN num1 AND num2;
SELECT colunmA FROM tableA WHERE colunmA IS NULL;SELECT colunmA, colunmB FROM tableA
WHERE colunmA = num1 OR colunmA =num2 AND colunmB >= num3;AND比OR有更高的优先级,所以应该用括号
SELECT colunmA, colunmB FROM tableA
WHERE (colunmA = num1 OR colunmA =num2) AND colunmB >= num3;SELECT colunmA, colunmB FROM tableA
WHERE colunmA IN/NOT IN (num1, num2)
ORDER BY colunmBIN与OR的功能相同,NOT用来取反
使用LIKE关键字,区分大小写,影响性能少用
%:任何字符出现任意次数
_:任何字符出现1次
SELECT colunmA FROM tableA WHERE colunmA LIKE '%char1_char2';LIKE匹配整个列,REGEXP匹配部分
MySQL中,正则表达式的前导为\\,用来匹配特殊字符,如\\\用来匹配\
Concat():字符串拼接
RTrim():去掉右侧空格
AS:使用别名
SELECT Concat(RTrim(colunmA), ' (', RTrim(colunmB), ' )') AS colunmC
FROM tableA ORDER BY colunmAMySQL的日期格式为yyyy-mm-dd
字符串函数:
Upper():转换为大写
Left():返回串左边的字符
Length():返回串的长度
Locate():找出一个串的子串
Lower():将串转换为小写
LTrim():去掉串左边的空格
Right():返回串右边的字符
RTrim():去掉串右边的空格
Soundex():返回串的SOUNDEX值
SubString():返回子串的字符
Upper():将串转换为大写
SELECT colunmA, colunmB FROM tableA
WHERE Soundex(colunmA) = Soundex(colunmB)时间函数:
AddDate():增加一个日期(天、周等)
AddTime():增加一个时间(时、分等)
CurDate():返回当前日期
CurTime():返回当前时间
Date():返回日期时间的日期部分
DateDiff():计算两个日期之差
Date_Add():高度灵活的日期运算函数
Date_Format():返回一个格式化的日期或时间串
Day():返回一个日期的天数部分
DayOfWeek():对于一个日期,返回对应的星期几
Hour():返回一个时间的小时部分
Minute():返回一个时间的分钟部分
Month():返回一个日期的月份部分
Now():返回当前日期和时间
Second():返回一个时间的秒部分
Time():返回一个日期时间的时间部分
Year():返回一个日期的年份部分
SELECT colunmA, colunmB FROM tableA
WHERE Data(colunmA) BETWEEN '2005-09-01' AND '2005-09-30'数值函数:
Abs():返回一个数的绝对值
Cos():返回一个角度的余弦
Exp():返回一个数的指数值
Mod():返回除操作的余数
Pi():返回圆周率
Rand():返回一个随机数
聚集函数:
AVG():返回某列的平均值,忽略NULL行
COUNT():返回某列的行数
MAX():返回某列的最大值
MIN():返回某列的最小值
SUM():返回某列值之和
SELECT AVG(DISTINCT colunmA) AS name1 FROM tableA
WHERE colunmB = numB从tableA中选取colunmB列的值为numB的行,并计算这些行中不同colunmA的平均值
分组:把数据分为多个逻辑组,对每个组进行聚集计算
一般在使用GROUP BY时也使用ORDER BY,保证数据排序的唯一性,不依赖GROUP BY的排序
SELECT colunmA, COUNT(*) AS name1 FROM tableA
WHERE colunmB >= numB
GROUP BY colunmA
HAVING COUNT(*) >= numC
ORDER BY colunmAWHERE在分组前进行,约束来之数据库的数据,在结果返回前起作用,不能使用聚集函数
HAVING在分组后进行,在查询返回结果集以后对结果进行过滤,可以使用聚集函数
SELECT cust_name,
cust_state,
(SELECT COUNT(*) FROM orders WHERE orders.cust_id = customers.cust_id) AS orders
FROM customers
ORDER BY cust_name;SELECT cust_name, cust_contact
FROM customers
WHERE cust_id IN (SELECT cust_id
FROM orders
WHERE order_num IN (SELECT order_num
FROM orderitems
WHERE prod_id = 'TNT2'));2个表:
SELECT A.name, B.name, B.price FROM A INNER JOIN B ON A.id = B.id;多个表:
SELECT A.name, A.contact FROM A, B, C
WHERE A.id = B.id AND B.num = C.num AND C.id = '102';不要联接太多的表,影响数据库性能
自联接:
SELECT A.id, A.name FROM A AS a, A AS b
WHERE a.id = b.id AND b.id = 'DTNTR';自然联接:
排除多次出现的列,使每个列只返回一次
外部联接:
包括那些没有关联的行,LEFT OUTER JOIN左边的表中所有的行都联接右边表中的行
SELECT A.id, B.num FROM A LEFT OUTER JOIN B ON A.id = B.id;SELECT id, num, price FROM A WHERE price <=5
UNION
SELECT id, num, price FROM B WHERE id IN (1001, 1002);UNION中每个查询必须包含相同的列,表达式或聚集函数,列的数据类型必须兼容
UNION自动去除重复的行,如果想返回所有匹配的行,使用UNION ALL
ORDER BY只能放在最后,只能对整体结果排序
启用:在建表时加入FULLTEXT子句,仅在MyISAM中支持
CREATE TABLE A
(
id int NOT NULL AUTO_INCREMENT,
data datetime NOT NULL,
text text NULL,
PRIMARY KEY(id),
FULLTEXT(text)
)ENGINE = MyISAM;全文本搜索:
SELECT text FROM A WHERE Match(text) Against('keywords');MySql对所有行计算一个等级值,返回等级值非0的行
查询扩展
SELECT text FROM A
WHERE Match(text) Against('keywords' WITH QUERY EXPANSION);对关键字所在行的所有单词再进行一次全文本搜索
布尔文本搜索
SELECT text FROM A
WHERE Match(text) Against('keywords -rope*' IN BOOLEAN MODE);搜索包含keywords但不包含任意以rope开始的行
插入多条数据:
INSERT INTO table(colA, colB, colC)
VALUES(1, 'TEXT1', NULL), (2, 'TEXT2', default_value);VALUE与表中的列一一对应
对于省略的某些列,有如下条件:
插入检索出的数据:
INSERT INTO tableA(colA, colB, colC) SELECT A, B, C FROM tableB;从tableB中检索A,B,C列的数据,插入到表tableA中去
更新某行的制定列,不要省略WHERE子句,若省略表示更新所有行
UPDATE customers SET cust_name = 'A', cust_email = '[email protected]' WHERE cust_id = 1005;删除某行,类似UPDATE
DELETE FROM tableA WHERE id = 1005;创建一个表
CREATE TABLE A IF NOT EXISTS
(
id int NOT NULL AUTO_INCREMENT=1,
name char(50) NOT NULL,
address char(50) NULL DEFAULT "default value",
PRIMARY KEY (id, name)
)ENGINE=InnoDB;增加一列
ALTER TABLE A ADD phone char(20);删除一列
ALTER TABLE A DROP COLUMN phone;重命名表名
RENAME TABLE A TO B;- 完(废弃) -
Tags: 印象笔记 Docker
docker官方文档Dockerfile reference的笔记。
[toc]
docker构建一个镜像,需要:
$ docker build .这条命令中,docker CLI会:
当然也可以用远程git仓库来代替本地路径,docker服务会把整个git仓库(包括git子模块)当做上下文,在仓库的根目录中寻找Dockerfile。
注意
为了加快构建速度,减少传递给docker服务的文件数量,最好将Dockerfile放在单独的空目录中。如果目录中含有大量文件,可以使用**.dockerignore**来忽略构建时用不到的文件。
另一个例子:
$ docker build --no-cache=true -f /path/to/Dockerfile -t some_tag -t image_name:image_version /path/to/build--no-cache:不使用缓存,每条指令都重新生成镜像(速度会很慢)
-f:明确指定Dockerfile
-t:给生成的镜像打上标签
docker寻找缓存的逻辑其实就是树型结构根据Dockerfile指令遍历子节点的过程。下图可以说明这个逻辑。
FROM base_image:version Dockerfile:
+----------+ FROM base_image:version
|base image| RUN cmd1 --> use cache because we found base image
+-----X----+ RUN cmd11 --> use cache because we found cmd1
/ \
/ \
RUN cmd1 RUN cmd2 Dockerfile:
+------+ +------+ FROM base_image:version
|image1| |image2| RUN cmd2 --> use cache because we found base image
+---X--+ +------+ RUN cmd21 --> not use cache because there's no child node
/ \ running cmd21, so we build a new image here
/ \
RUN cmd11 RUN cmd12
+-------+ +-------+
|image11| |image12|
+-------+ +-------+
大部分指令可以根据上述逻辑去寻找缓存,除了ADD和COPY。
这两个指令会复制文件内容到镜像内,除了指令相同以外,docker还会检查每个文件内容校验和(不包括最后修改时间和最后访问时间),如果校验和不一致,则不会使用缓存。
注意
除了这两个命令,docker并不会去检查容器内的文件内容,比如RUN apt-get -y update,每次执行时文件可能都不一样,但是docker认为命令一致,会继续使用缓存。这样一来,以后构建时都不会再重新运行apt-get -y update。
如果docker没有找到当前指令的缓存,则会构建一个新的镜像,并且之后的所有指令都不会再去寻找缓存。
在docker构建镜像的第一步,docker CLI会先在上下文目录中寻找.dockerignore文件,根据.dockerignore文件排除上下文目录中的部分文件和目录,,然后把剩下的文件和目录传递给docker 服务。
.dockerignore语法同.gitignore,具体不表,可以参考官方文档。
虽然Dockerfile并不区分大小写,但还是约定指令使用大写。
Dockerfile的第一条可执行指令必须是FROM。
以#开头的是注释,行内的#都被当做参数,并且不支持续行。
解析指令也以#开头,形式如下:
# directive=value1
# directive=value2
FROM ImageName解析指令是可选的,虽然不区分大小写,但还是约定使用小写。
解析指令会影响到Dockerfile的解析逻辑,并且不会生成图层,也不会在构建时显示。解析指令只能出现在Dockerfile头部,并且一条解析指令只能出现一次。如果碰到注释、Dockerfile指令或空行,接下来出现的解析指令都无效,被当做注释处理。不支持续行。
根据文档当前只有一个解析指令:escape。(我猜如果有必要可能会在之后的版本中增加新的解析指令吧)
escape用来设置转义或续行字符,这在Windows中很有用:
COPY testfile.txt c:\\
RUN dir c:\会被docker解析成: COPY teestfile.txt c:\RUN dir c:,下面的例子就可以正常执行。
# escape=`
COPY testfile.txt c:\
RUN dir c:\在Dockerfile中,使用env指令来定义环境变量。环境变量有两种形式:$variable_name和${variable_name},推荐使用后者,因为:
${foo}_bar,前者就无法做到word除了字符串外也支持环境变量,进行递归替换
${variable:-word}:如果variable不存在,则使用word${varialbe:+word}:如果variable存在,则使用word,如果variable不存在,则使用空字符串支持这些指令:ADD,COPY,ENV,EXPOSE,LABEL,USER,WORKDIR,VOLUME,STOPSIGNAL和1.4版本之后的ONBUILD
注意
在整个指令行中只使用一个值,参考下面这个例子:
ENV abc=hello
ENV abc=bye def=$abc
ENV ghi=$abc最后abc=bye, def=hello, ghi=bye
几个注意点:
/bin/sh -c)运行可执行文件,exec格式的是直接执行可执行文件。如果exec格式的要在某个shell中执行,要这么写:["/bin/bash", "-c", "echo hello"]。shell可以使用SHELL指令来更改。\\)来换行。"而不是单引号'。RUN ["echo", "$HOME"]不会将$HOME展开,如果需要展开变量,可以这样使用:RUN ["sh", "-c", "echo $HOME"]docker build - < somefile这种方式来构建镜像的,则没有上下文,ADD只能使用远程文件URL而COPY不能使用。如果以docker build - < archive.tar.gz,则会在压缩包的根目录中寻找Dockerfile,压缩包的根目录当做上下文。RUN wget或RUN curl,而不是直接使用ADD或COPY。ADD或COPY远程文件的,会赋予文件600权限,并且HTTP Last-Modified时间就是文件的最后修改时间。最后修改时间被改变,docker不会认为文件被改变,docker只会检查文件内容。构建的镜像继承自某个base image。格式:
FROM <image>
FROM <image>:<tag>
FROM <image>@<digest>FROM指令必须是Dockerfile的第一个指令,可以使用多次来构建多个镜像,以最后一个镜像的ID为输出值。
tag和digest是可选的,如果不提供则使用latest。
在镜像的构建过程中执行特定的命令,并生成一个中间镜像。格式:
RUN <command>:shell格式RUN ["executable", "param1", "param2"]:exec格式指定容器运行时的默认参数,如果出现多次以最后一次为准。格式:
CMD ["executable", "param1", "param2"]:exec格式CMD command param1 param2:shell格式CMD ["param1", "param2"]:省略可执行文件的exec格式,这种写法使CMD中的参数当做ENTRYPOINT的默认参数,此时ENTRYPOINT也应该是exec格式具体与ENTRYPOINT的组合使用,参考ENTRYPOINT。
注意
与RUN指令的区别:RUN在构建的时候执行,并生成一个新的镜像,CMD在容器运行的时候执行,在构建时不进行任何操作。
给构建的镜像打标签。格式:
LABEL <key>=<value> <key>=<value> <key>=<value> ...如果base image中也有标签,则继承,如果是同名标签,则覆盖。
为了减少图层数量,尽量将标签写在一个LABEL指令中去,如:
LABEL multi.label1="value1" \
multi.label2="value2" \
other="value3"为构建的镜像设置作者信息。格式:
MAINTAINER <name>LABEL比MAINTAINER更灵活,推荐使用LABEL,弃用MAINTAINER。
为构建的镜像设置监听端口,使容器在运行时监听。格式:
EXPOSE <port> [<port>...]EXPOSE指令并不会让容器监听host的端口,如果需要,需要在docker run时使用-p、-P参数来发布容器端口到host的某个端口上。
在构建的镜像中设置环境变量,在后续的Dockerfile指令中可以直接使用,也可以固化在镜像里,在容器运行时仍然有效。格式:
ENV <key> <value>:把第一个空格之后的所有值都当做<key>的值,无法在一行内设定多个环境变量。ENV <key>=<value> ...:可以设置多个环境变量,如果<value>中存在空格,需要转义或用引号"括起来。docker推荐使用第二种,因为可以在一行中写多个环境变量,减少图层。如下:
ENV myName="John Doe" \
myDog=Rex\ The\ Dog \
myCat=fluffy注意
docker run --env <key>=<value>。ENV可能会对后续的Dockerfile指令造成影响,如果只需要对一条指令设置环境变量,可以使用这种方式:RUN <key>=<value> <command>在构建镜像时,复制上下文中的文件到镜像内,格式:
ADD <src>... <dest>ADD ["<src>",... "<dest>"]<src>可以是文件、目录,也可以是文件URL。可以使用模糊匹配(wildcards,类似shell的匹配),可以指定多个<src>,必须是在上下文目录和子目录中,无法添加../a.txt这样的文件。如果<src>是个目录,则复制的是目录下的所有内容,但不包括该目录。如果<src>是个可被docker识别的压缩包,docker会以tar -x的方式解压后将内容复制到<desct>。
<dest>可以是绝对路径,也可以是相对WORKDIR目录的相对路径。
所有文件的UID和GID都是0。
注意
如果docker发现文件内容被改变,则接下来的指令都不会再使用缓存。
关于复制文件时需要处理的/,基本跟正常的copy一致,具体参考ADD指令。
与ADD类似,只不过ADD是将上下文内的文件复制到镜像内,COPY是在镜像内的复制。格式与ADD一致。
注意
如果<dest>不存在,COPY指令会自动创建所有目录,包括子目录
指定镜像的执行程序,只有最后一条ENTRYPOINT指令有效。格式:
ENTRYPOINT <command> <param1> <param2>:shell格式,因为嵌套在shell中,PID不再为1,也接受不到Unix信号,即在docker stop <container>时收不到SIGTERM信号,需要手动写脚本使用exec或gosu命令处理。ENTRYPOINT ["<executable>", "<param1>", "<param2>"]:exec格式,PID为1官方文档有两个例子:Exec form ENTRYPOINT example和Shell form ENTRYPOINT example。
CMD和ENTRYPOINT至少得使用一个。ENTRYPOINT应该被当做docker的可执行程序,CMD应该被当做ENTRYPOINT的默认参数。
docker run <image> <arg1> <arg2> ...会把之后的参数传递给ENTRYPOINT,覆盖CMD指定的参数。可以用docker run --entrypoint来重置默认的ENTRYPOINT。
关于ENTRYPOINT和CMD的交互,用一个官方表格可以说明:
| No ENTRYPOINT | ENTRYPOINT exec_entry p1_entry | ENTRYPOINT ["exec_entry", "p1_entry"] | |
|---|---|---|---|
| No CMD | error, not allowed | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry |
| CMD ["exec_cmd", "p1_cmd"] | exec_cmd p1_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry exec_cmd p1_cmd |
| CMD ["p1_cmd", "p2_cmd"] | p1_cmd p2_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry p1_cmd p2_cmd |
| CMD exec_cmd p1_cmd | CMD exec_cmd p1_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry /bin/sh -c exec_cmd p1_cmd |
指定镜像内的目录为数据卷。格式:
VOLUME ["/var/log"]
VOLUME /var/log /var/db在容器运行的时候,docker会把镜像中的数据卷的内容复制到容器的数据卷中去。
如果在接下来的Dockerfile指令中,修改了数据卷中的内容,则修改无效。
为接下来的Dockerfile指令指定用户。格式:
USER daemon收影响的指令有:RUN、CMD、ENTRYPOINT。
为接下来的Dockerfile指令指定当前工作目录,可多次使用,如果使用的是相对路径,则相对的是上一个工作目录,类似shell中的cd命令。格式:
WORKDIR /path/to/workdir收影响的指令有:RUN、CMD、ENTRYPOINT、COPY和ADD。
指定了用户在docker build --build-arg <varname>=<value>时可以使用的参数。格式:
ARG <name>[=<default value>]构建参数在定义的时候生效而不是在使用的时候。如下面第三行开始的user才是用户构建参数传递过来的user:
FROM busybox
USER ${user:-some_user}
ARG user
USER $user后续的ENV指令会覆盖同名的构建参数,正常用法如下:
FROM ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER ${CONT_IMG_VER:-v1.0.0}
RUN echo $CONT_IMG_VERdocker内置了一批构建参数,可以不用在Dockerfile中声明:HTTP_PROXY、http_proxy、HTTPS_PROXY、https_proxy、FTP_PROXY、ftp_proxy、NO_PROXY、no_proxy
注意
在使用构建参数(而不是在构建参数定义的时候)的指令中,如果构建参数的值发生了变化,会导致该指令发生变化,会重新寻找缓存。
向镜像中添加一个触发器,当以该镜像为base image再次构建新的镜像时,会触发执行其中的指令。格式:
ONBUILD [INSTRUCTION]比如我们生成的镜像是用来部署Python代码的,但是因为有多个项目可能会复用该镜像。所以一个合适的方式是:
[...]
# 在下一次以此镜像为base image的构建中,执行ADD . /app/src,将项目代目添加到新镜像中去
ONBUILD ADD . /app/src
# 并且build Python代码
ONBUILD RUN /usr/local/bin/python-build --dir /app/src
[...]注意
ONBUILD只会继承给子节点的镜像,不会再继承给孙子节点。
ONBUILD ONBUILD或者ONBUILD FROM或者ONBUILD MAINTAINER是不允许的。
触发系统信号。格式:
STOPSIGNAL signal增加自定义的心跳检测功能,多次使用只有最后一次有效。格式:
HEALTHCHECK [OPTION] CMD <command>:通过在容器内运行command来检查心跳HEALTHCHECK NONE:取消从base image继承来的心跳检测可选的OPTION:
--interval=DURATION:检测间隔,默认30秒--timeout=DURATION:命令超时时间,默认30秒--retries=N:连续N次失败后标记为不健康,默认3次<command>可以是shell脚本,也可以是exec格式的json数组。
docker以<command>的退出状态码来区分容器是否健康,这一点同shell一致:
举例:每5分钟检测本地网页是否可访问,超时设为3秒:
HEALTHCHECK --interval=5m --timeout=3s \
CMD curl -f http://localhost/ || exit 1可以使用docker inspect命令来查看健康状态。
注意
docker版本1.12
更改后续的Dockerfile指令中所使用的shell。默认的shell是["bin/sh", "-c"]。可多次使用,每次都只改变后续指令。格式:
SHELL ["executable", "parameters"]注意
docker版本1.12
-\ 完 -\ 2017/03/09
Tags: 印象笔记
[toc]
Given a non-negative integer num, repeatedly add all its digits until the result has only one digit.
For example:
Given num = 38, the process is like: 3 + 8 = 11, 1 + 1 = 2. Since 2 has only one digit, return it.
hint
A naive implementation of the above process is trivial. Could you come up with other methods?
follow up
Could you do it without any loop/recursion in O(1) runtime?
按照定义来写就能算出来. 先把数字转成字符串, 然后对每一位相加,重复执行.
class Solution(object):
def addDigits(self, num):
"""
:type num: int
:rtype: int
"""
def calculate(n):
if len(str(n)) <= 1:
return n
return calculate(reduce(lambda x, y: int(x) + int(y), str(n)))
return calculate(num)n进制数abc...
= a * n^m + b * n^(m-1) + c * n^(m-2) + ...
= a * (n^m - 1) + b * (n^(m - 1) - 1) + c * (n^(m-2) - 1) + ... + (a +b +c + ...)
= a * (n - 1) * (...) + b * (n - 1) * (...) + c * (n - 1) * (...) + ... + (a + b + c + ...)
= (...) * (n - 1) + ... + (a +b +c + ...)
所以对于10进制数来说, root(x) = y * 9 +r, 即 root(x) = x % 9.
再考虑题目中的非负, 还有可能出现0, root(0) = 0
class Solution(object):
def addDigits(self, num):
"""
:type num: int
:rtype: int
"""
if num == 0:
return 0
return num % 9 if num % 9 != 0 else 9对上面的代码简化为1行:
class Solution(object):
def addDigits(self, num):
"""
:type num: int
:rtype: int
"""
return 0 if not num else 1 + (num - 1) % 9- 完 -
Tags: 印象笔记
[toc]
Invert a binary tree.
4
/ \
2 7
/ \ / \
1 3 6 9
to
4
/ \
7 2
/ \ / \
9 6 3 1
又是二叉树又是二叉树,还是用递归啊。正确的思路是交换左右孩子节点,再利用递归重复操作。
第一次WA,思路错误,贴出思路错误的代码。
这个想法是交换两个子节点的值,然后对子节点进行同样的操作。下面的是转换后的结果,这个结果是错误的。
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def invertTree(self, root):
"""
:type root: TreeNode
:rtype: TreeNode
"""
if root and root.left and root.right:
left, right = root.left, root.right
root.left = self.invertTree(right)
root.right = self.invertTree(left)
return root 4
/ \
2 7
/ \ / \
1 3 6 9
to
4
/ \
7 2
/ \ / \
6 9 1 3
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def invertTree(self, root):
"""
:type root: TreeNode
:rtype: TreeNode
"""
if root:
root.left, root.right = root.right, root.left
self.invertTree(root.left)
self.invertTree(root.right)
return root对上面的代码进行精简,精简到3行
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def invertTree(self, root):
"""
:type root: TreeNode
:rtype: TreeNode
"""
if root:
root.left, root.right = self.invertTree(root.right), self.invertTree(root.left)
return root- 完 -
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.