pschachte / wybe Goto Github PK
View Code? Open in Web Editor NEWA programming language supporting most of both declarative and imperative programming
License: MIT License
A programming language supporting most of both declarative and imperative programming
License: MIT License













































The current Wybe string type is just a C string, which is convenient for character constants and to use C I/O, and that's about it. The string type should support efficient concatenation and substring. Ideally, when a string is not aliased, it should be able to act like a buffer by supporting destructive update.
What I tried to do:
% cat hello_world.wybe
!println("Hello, World!")
% wybemk hello_world
Internal error: Invalid Wybe object file /usr/local/lib/wybe/wybe.o: module data missing
CallStack (from HasCallStack):
error, called at src/AST.hs:2784:17 in main:AST
Seems like the function loadModuleFromObjFile failed when loading the standard library:
Line 492 in 6350c56
All of the above is done under Ubuntu 18.04.2
every print and println start from here should have an exclamation marks in front of of it
For example, we store LPVM instructions using this data structure which is very error-prone.
Line 1948 in f68d0f5
If we add an incompatible change to the LPVM instructions. It won't case a compile error and in some cases it won't even cause a runtime error.
Most of the current codes just match on the strings and make assumptions about the length of list etc, and the compiler can't verify it.
This is a bit odd. The same program can become slower when there are more cpu cores in the system.
I used the same physical machine to run vm and allocate a different number of cpu cores to it. Then I ran the same wybe program on it and here are the results:
| number of cores | time used |
|---|---|
| 1 | 54s |
| 2 | 58s |
| 6 | 128s |
| 12 | 220s |
I suspect that the issue is caused by the gc, because:
After a quick look at the doc of the BDW GC, it seems that the gc should be single-threaded with incremental mode disabled by default. Not sure why and I will keep investigating this.
test.wybe
?x = 1
?x = 1.0
output
Error detected during type checking of module(s) test
Internal error: type error in move: {foreign llvm move(1.0 @test:2:9, ?x @test:2:1)}
CallStack (from HasCallStack):
error, called at src/AST.hs:2786:17 in main:AST
main.wybe
use lib
!foo()
lib.wybe
pub def foo() use !io {
!println("test message A")
}
Reproduce steps:
main.foo() in lib.wybe (eg. change the string in println).main again and this new main will behave the same as the previous one.The current incremental build works as follows:
Lines 327 to 343 in 5cb70a8
Lines 949 to 959 in 5cb70a8
The main issue is that incremental build only considers each module itself and ignores the changes of its dependencies. Inlining and alias analysis that cross multiple modules will break.
Supporting incremental build during the top-down pass requires this issue to be fixed first. I'm planning to discuss this in the coming meeting.
The diagram below shows the target main and its dependencies.

The problem is related to the circular dependency of ca and cb.
If there isn't any object file that can be reused, then compileModSCC [ca, cb] will be executed, which is correct.
If there are up-to-date object files for ca and cb, then compileModSCC won't be executed, which is correct.
If only the object file of ca is missing (or outdated), then compileModSCC [ca] will be executed, which is wrong.
if only the object file of cb is missing (or outdated), then compileModSCC won't be executed and left cb uncompiled, which is wrong.
The cause is that loadModuleFromObjFile inserts modules directly into the Compiler State and doesn't call things like exitModule, so the topological sort is kind of broken. In the example above, cb is deferred first. Then compiler visits ca and realize that ca and cb is in an SCC. But if cb is loaded directly then it won't be marked as deferred and if ca is loaded directly then the deferred cb won't be picked.
Overall, I feel that the builder part is a bit messy and we need to fix this before working on #66
In my opinion, a module has two stages while building (shown in the diagram below).
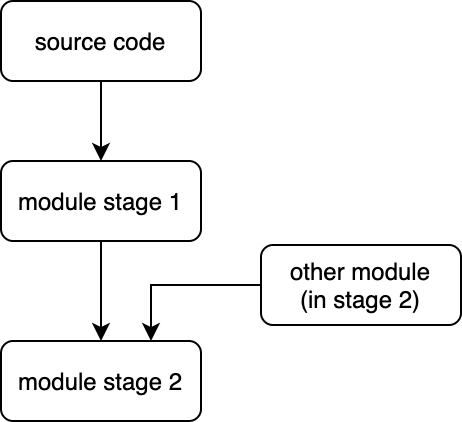
Currently, the builder handles the first part correctly. A stage 1 module only depends on its source code, so using the lastModifiedTime is correct.
However, a stage 2 module (generated by the compileModSCC) also depends on other stage 2 modules and its stage 1 module, so we can't let the decision from the first part affects this part. So we need to visit all SCCs no matter if it's loaded from an object file or not. And for each SCC, we need to check whether anything changes (like the one that will be added to fix #66 ), if so, then compileModSCC should be executed with the whole SCC.
Then there is another problem, currently, we only store the stage 2 modules in the object file, we need a way to get the stage 1 module if we need to rebuild it. I don't like the idea of getting it from the source code since it basically makes the object file not portable at all. Maybe storing the list of tokens?
Also support anonymous procs/functions using notation like @ to refer to the next lambda argument and @2 to refer to the second lambda argument. This covers both lambda and partial application.
We added the support of linktime dead code elimination in #4 when wybe only works on macOS.
It turns out that the -dead_strip only exists in the system linker on macOS so it doesn't work on ubuntu.
I tried -Wl,--gc-sections and it doesn't work, I believe it requires that every function in its own ELF section.
There is a case where
Lines 198 to 201 in 47a01b2
procImpln def is ProcDefSrc instead of ProcDefPrim.
A sample csae is test-cases/final-dump/multi_specz_cyclic_lib2.wybe.
Actually it belongs to a test case with 3 files.
test-cases/final-dump/multi_specz_cyclic_exe.wybe
test-cases/final-dump/multi_specz_cyclic_lib.wybe
test-cases/final-dump/multi_specz_cyclic_lib2.wybe
Compiling them as a whole succeeds without any error but compiling multi_specz_cyclic_lib2.o individually causes this problem.
The for loop should allow iteration over integer sequences, lists, and arrays. It should allow iteration over more than one sequence in lock step.
... so if a break appears in one branch of a conditional, then variables assigned in the other branch(es) will be assigned in subsequent statements.
Example:
> cat helloworld.wybe
!println("Hello World!")
> wybemk helloworld
> ./helloworld
zsh: no such file or directory: ./helloworld
Using bigloop.wybe as an example, output executable using command:
wybemk bigloop
will get an executable doing exactly what the code say: looping over i and add 2 to sum each time.
wybemk bigloop.ll
will get a LLVM IR output with fully optimized code without any looping.
As a side note, when disassembling the bigloop executable I also noticed the fact that the final executable will include all standard types and functions, including those it never used during runtime.
$ wybemk --version
wybemk 0.1 (git 40f3b16)
Arrays are always tricky in a declarative language, because copying the whole array to change one element is impractical. CTGC make make it workable locally, but we need interprocedural CTGC for it to really be practical.
In the following code:
def main use io {
!println("hello world!")
}
!main
the compiler allows changes to the io state to be thrown away. This happens because the use clause says use io instead of use !io. Then the compiler sees that the main proc does not produce any output, so it optimises it away.
To fix this, we must introduce a restriction that io states cannot be copied -- we need linear types of some sort, which will be a significant effort.
This allows generation of specialised versions of procedures based on how it will be called, and allows the compiler to select the best available version of a procedure for each call.
That means overloading based on arity will not be supported.
Code:
pub type intlist { pub [] | [|](head:int, tail:intlist) }
pub def list_print(x:intlist) use !io {
if { x = [ ?h | ?t] ::
!print(h)
!print(" ")
!list_print(t)
}
}
pub def list_println(x:intlist) use !io {
!list_print(x)
!println("")
}
?x = [1,2,3,4,5,6]
?y = [999]
!list_println(x)
!list_println(y)
if { x = [ ?h | ?t] ::
if { tail(!t, y) ::
!print("t: ")
!list_println(t)
}
}
!list_println(x)
Ouput:
1 2 3 4 5 6
999
t: 2 999
1 2 999
Expect Output:
1 2 3 4 5 6
999
t: 2 999
1 2 3 4 5 6
The LPVM code is wrong:
*main* > public (0 calls)
0: (argc#0:wybe.int, [?argc#0:wybe.int], argv#0:wybe.int, [?argv#0:wybe.int], exit_code#0:wybe.int, [?exit_code#0:wybe.int], io#0:wybe.phantom, ?io#5:wybe.phantom): AliasPairs: []
foreign lpvm alloc(16:wybe.int, ?tmp$13#0:error_case.intlist)
foreign lpvm mutate(~tmp$13#0:error_case.intlist, ?tmp$14#0:error_case.intlist, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 6:wybe.int)
foreign lpvm mutate(~tmp$14#0:error_case.intlist, ?tmp$15#0:error_case.intlist, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 0:error_case.intlist)
foreign lpvm alloc(16:wybe.int, ?tmp$18#0:error_case.intlist)
foreign lpvm mutate(~tmp$18#0:error_case.intlist, ?tmp$19#0:error_case.intlist, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 5:wybe.int)
foreign lpvm mutate(~tmp$19#0:error_case.intlist, ?tmp$20#0:error_case.intlist, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, ~tmp$15#0:error_case.intlist)
foreign lpvm alloc(16:wybe.int, ?tmp$23#0:error_case.intlist)
foreign lpvm mutate(~tmp$23#0:error_case.intlist, ?tmp$24#0:error_case.intlist, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 4:wybe.int)
foreign lpvm mutate(~tmp$24#0:error_case.intlist, ?tmp$25#0:error_case.intlist, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, ~tmp$20#0:error_case.intlist)
foreign lpvm alloc(16:wybe.int, ?tmp$28#0:error_case.intlist)
foreign lpvm mutate(~tmp$28#0:error_case.intlist, ?tmp$29#0:error_case.intlist, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 3:wybe.int)
foreign lpvm mutate(~tmp$29#0:error_case.intlist, ?tmp$30#0:error_case.intlist, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, ~tmp$25#0:error_case.intlist)
foreign lpvm alloc(16:wybe.int, ?tmp$33#0:error_case.intlist)
foreign lpvm mutate(~tmp$33#0:error_case.intlist, ?tmp$34#0:error_case.intlist, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 2:wybe.int)
foreign lpvm mutate(~tmp$34#0:error_case.intlist, ?tmp$35#0:error_case.intlist, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, ~tmp$30#0:error_case.intlist)
foreign lpvm alloc(16:wybe.int, ?tmp$38#0:error_case.intlist)
foreign lpvm mutate(~tmp$38#0:error_case.intlist, ?tmp$39#0:error_case.intlist, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 1:wybe.int)
foreign lpvm mutate(~tmp$39#0:error_case.intlist, ?tmp$40#0:error_case.intlist, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, tmp$35#0:error_case.intlist)
foreign lpvm alloc(16:wybe.int, ?tmp$43#0:error_case.intlist)
foreign lpvm mutate(~tmp$43#0:error_case.intlist, ?tmp$44#0:error_case.intlist, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 999:wybe.int)
foreign lpvm mutate(~tmp$44#0:error_case.intlist, ?tmp$45#0:error_case.intlist, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 0:error_case.intlist)
error_case.list_print<0>(tmp$40#0:error_case.intlist, ~#io#0:wybe.phantom, ?tmp$48#0:wybe.phantom) @error_case:12:6
foreign c print_string("":wybe.string, ~tmp$48#0:wybe.phantom, ?tmp$49#0:wybe.phantom) @wybe:100:39
foreign c putchar('\n':wybe.char, ~tmp$49#0:wybe.phantom, ?#io#1:wybe.phantom) @wybe:86:26
error_case.list_print<0>(tmp$45#0:error_case.intlist, ~#io#1:wybe.phantom, ?tmp$52#0:wybe.phantom) @error_case:12:6
foreign c print_string("":wybe.string, ~tmp$52#0:wybe.phantom, ?tmp$53#0:wybe.phantom) @wybe:100:39
foreign c putchar('\n':wybe.char, ~tmp$53#0:wybe.phantom, ?#io#2:wybe.phantom) @wybe:86:26
foreign llvm icmp ne(tmp$40#0:error_case.intlist, 0:wybe.int, ?tmp$55#0:wybe.bool)
case ~tmp$55#0:wybe.bool of
0:
error_case.list_print<0>(~tmp$40#0:error_case.intlist, ~#io#2:wybe.phantom, ?tmp$58#0:wybe.phantom) @error_case:12:6
foreign c print_string("":wybe.string, ~tmp$58#0:wybe.phantom, ?tmp$59#0:wybe.phantom) @wybe:100:39
foreign c putchar('\n':wybe.char, ~tmp$59#0:wybe.phantom, ?#io#5:wybe.phantom) @wybe:86:26
1:
foreign llvm move(~tmp$35#0:error_case.intlist, ?t#0:error_case.intlist)
foreign llvm icmp ne(%t#0:error_case.intlist, 0:wybe.int, ?tmp$58#0:wybe.bool)
case ~tmp$58#0:wybe.bool of
0:
foreign llvm move(~%t#0:error_case.intlist, ?%t#1:error_case.intlist)
error_case.list_print<0>(~tmp$40#0:error_case.intlist, ~#io#2:wybe.phantom, ?tmp$61#0:wybe.phantom) @error_case:12:6
foreign c print_string("":wybe.string, ~tmp$61#0:wybe.phantom, ?tmp$62#0:wybe.phantom) @wybe:100:39
foreign c putchar('\n':wybe.char, ~tmp$62#0:wybe.phantom, ?#io#5:wybe.phantom) @wybe:86:26
1:
# !!!! It should be non-destructive here.
foreign lpvm mutate noalias(~%t#0:error_case.intlist, ?%t#1:error_case.intlist, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, ~tmp$45#0:error_case.intlist)
foreign c print_string("t: ":wybe.string, ~#io#2:wybe.phantom, ?#io#3:wybe.phantom) @wybe:100:39
error_case.list_print<0>(~t#1:error_case.intlist, ~#io#3:wybe.phantom, ?tmp$63#0:wybe.phantom) @error_case:12:6
foreign c print_string("":wybe.string, ~tmp$63#0:wybe.phantom, ?tmp$64#0:wybe.phantom) @wybe:100:39
foreign c putchar('\n':wybe.char, ~tmp$64#0:wybe.phantom, ?#io#4:wybe.phantom) @wybe:86:26
error_case.list_print<0>(~tmp$40#0:error_case.intlist, ~#io#4:wybe.phantom, ?tmp$67#0:wybe.phantom) @error_case:12:6
foreign c print_string("":wybe.string, ~tmp$67#0:wybe.phantom, ?tmp$68#0:wybe.phantom) @wybe:100:39
foreign c putchar('\n':wybe.char, ~tmp$68#0:wybe.phantom, ?#io#5:wybe.phantom) @wybe:86:26
Code:
pub type intlist { pub [] | [|](head:int, tail:intlist) }
pub def list_print(x:intlist) use !io {
if { x = [ ?h | ?t] ::
!print(h)
!print(" ")
!list_print(t)
}
}
pub def list_println(x:intlist) use !io {
!list_print(x)
!println("")
}
?x = [1,2,3]
?y = [0]
!println("----------")
!list_println(x)
!list_println(y)
if { tail(!y, x) ::
!println("----------")
!print("x: ")
!list_println(x)
!print("y: ")
!list_println(y)
}
if { head(!x, 999) ::
!println("----------")
!print("x: ")
!list_println(x)
!print("y: ")
!list_println(y)
}
Output:
----------
1 2 3
0
----------
x: 1 2 3
y: 0 1 2 3
----------
x: 999 2 3
y: 0 999 2 3
Expect Output:
----------
1 2 3
0
----------
x: 1 2 3
y: 0 1 2 3
----------
x: 999 2 3
y: 0 1 2 3
The problem is that the output of mutate is always considered as unalised.
Currently, LLVM code gen uses CCC for everything, which means it does not perform tail call/last call optimisation. We need to use CCC for foreign calls, but should use FastCC for Wybe code. Or perhaps TailCC, which is like FastCC, except for guarantees tail calling if it's possible.
I am working on another test case for gloabl CTGC (using explicit setter).
Here is the program:
type drone_info { pub drone_info(x:int, y:int, z:int, count:int) }
def drone_init():drone_info = drone_info(0, 0, 0, 0)
def print_info(d:drone_info) use !io {
!print("(")
!print(x(d))
!print(", ")
!print(y(d))
!print(", ")
!print(z(d))
!print(") #")
!print(count(d))
!nl
}
def do_action(!d:drone_info, action:char, ?success:bool) {
?success = true
if { action = 'n' ::
y(!d, y(d)-1)
| action = 's' ::
y(!d, y(d)+1)
| action = 'w' ::
x(!d, x(d)-1)
| action = 'e' ::
x(!d, x(d)+1)
| action = 'u' ::
z(!d, z(d)+1)
| action = 'd' ::
z(!d, z(d)-1)
| otherwise ::
?success = false
}
if { success ::
count(!d, count(d)+1)
}
}
?d = drone_init()
do {
!read(?ch:char)
until ch = eof
if { ch /= ' ' && ch /= '\n' ::
if { ch = 'p' ::
!print_info(d)
| otherwise ::
do_action(!d, ch, ?success)
if { success = false ::
!println("invalid action!")
}
}
}
}
!malloc_count(?mc)
!println(mc)
Note that the variable d should be unaliased. However, the prototype of the generated procedure for the loop is like this:
0: gen$1(argc#0:wybe.int, argv#0:wybe.int, d#0:drone.drone_info, exit_code#0:wybe.int, io#0:wybe.phantom, tmp$0#0:drone.drone_info, ?argc#1:wybe.int, ?argv#1:wybe.int, ?exit_code#1:wybe.int, ?io#3:wybe.phantom):
The d#0 and tmp$0#0 in it are the same thing, according to the call site:
foreign lpvm alloc(32:wybe.int, ?tmp$13#0:drone.drone_info)
foreign lpvm mutate(~tmp$13#0:drone.drone_info, ?tmp$14#0:drone.drone_info, 0:wybe.int, 1:wybe.int, 32:wybe.int, 0:wybe.int, 0:wybe.int)
foreign lpvm mutate(~tmp$14#0:drone.drone_info, ?tmp$15#0:drone.drone_info, 8:wybe.int, 1:wybe.int, 32:wybe.int, 0:wybe.int, 0:wybe.int)
foreign lpvm mutate(~tmp$15#0:drone.drone_info, ?tmp$16#0:drone.drone_info, 16:wybe.int, 1:wybe.int, 32:wybe.int, 0:wybe.int, 0:wybe.int)
foreign lpvm mutate(~tmp$16#0:drone.drone_info, ?tmp$0#0:drone.drone_info, 24:wybe.int, 1:wybe.int, 32:wybe.int, 0:wybe.int, 0:wybe.int)
drone.gen$1<0>(~argc#0:wybe.int, ~argv#0:wybe.int, ~tmp$0#0:drone.drone_info, ~exit_code#0:wybe.int, ~io#0:wybe.phantom, ~tmp$0#0:drone.drone_info, ?argc#1:wybe.int, ?argv#1:wybe.int, ?exit_code#1:wybe.int, ?io#1:wybe.phantom) #1 @drone:42:1
It stops the specialized version of gen$1<0> to be used.
int_list.wybe
pub type int_list { pub [] | [|](head:int, tail:int_list) }
pub def print(x:int_list) use !io {
if { x = [ ?h | ?t] ::
!print(h)
!print(" ") # the problem seems related to this one.
!print(t)
}
}
pub def println(x:int_list) use !io {
!print(x)
!nl
}
?x = [1,2,3]
!println(x)
> wybemk int_list
adjustNth refers beyond list end
CallStack (from HasCallStack):
error, called at src/Callers.hs:79:20 in main:Callers
Program:
position.wybe
pub type position { pub position(x:int, y:int) }
pub def printPosition(pos:position) use !io {
!print(" (")
!print(pos.x)
!print(",")
!print(pos.y)
!println(")")
}
main.wybe
use position
?pos = position(100,150)
?pos2 = pos
!println("-------")
x(!pos, 200)
!printPosition(pos)
!printPosition(pos2)
!println("-------")
x(!pos2, 90)
!printPosition(pos)
!printPosition(pos2)
Expected output:
-------
(200,150)
(100,150)
-------
(200,150)
(90,150)
Actual output:
-------
(200,150)
(200,150)
-------
(90,150)
(90,150)
Final dump:
foreign lpvm alloc(16:wybe.int, ?tmp$3#0:position.position)
foreign lpvm mutate(~tmp$3#0:position.position, ?tmp$4#0:position.position, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 100:wybe.int)
foreign lpvm mutate(~tmp$4#0:position.position, ?tmp$0#0:position.position, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 150:wybe.int)
foreign c print_string("-------":wybe.string, ~#io#0:wybe.phantom, ?tmp$7#0:wybe.phantom) @wybe:100:39
foreign c putchar('\n':wybe.char, ~tmp$7#0:wybe.phantom, ?#io#1:wybe.phantom) @wybe:86:26
foreign lpvm mutate noalias(tmp$0#0:position.position, ?%pos#1:position.position, 0:wybe.int, 0:wybe.int, 16:wybe.int, 0:wybe.int, 200:wybe.int)
position.printPosition<0>(pos#1:position.position, ~#io#1:wybe.phantom, ?#io#2:wybe.phantom) @alias_des2:7:2
position.printPosition<0>(tmp$0#0:position.position, ~#io#2:wybe.phantom, ?#io#3:wybe.phantom) @alias_des2:8:2
foreign c print_string("-------":wybe.string, ~#io#3:wybe.phantom, ?tmp$12#0:wybe.phantom) @wybe:100:39
foreign c putchar('\n':wybe.char, ~tmp$12#0:wybe.phantom, ?#io#4:wybe.phantom) @wybe:86:26
foreign lpvm mutate noalias(~tmp$0#0:position.position, ?%pos2#1:position.position, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, 90:wybe.int)
position.printPosition<0>(~pos#1:position.position, ~#io#4:wybe.phantom, ?#io#5:wybe.phantom) @alias_des2:11:2
position.printPosition<0>(~pos2#1:position.position, ~#io#5:wybe.phantom, ?#io#6:wybe.phantom) @alias_des2:12:2
See test-cases/use_resource.wybe. Compiling to .o works fine, but generating an executable gets this error:
Error detected during resource checking of module(s)
Unknown resource use_resource.count
Wybe code:
!println("hello world!")
correctly print out hello world!
while:
#test.wybe
def main() use io {
!println("hello world!")
}
!main()
print out nothing.
wybemk test.ll give an almost empty text file:
; ModuleID = 'test'
source_filename = "....../test.wybe"
wybemk -V:
wybemk 0.1 (git 40f3b16)
Built Wed Apr 22 13:37:07 AEST 2020
Using library directories:
/usr/local/lib/wybe
For example, this code compiles when it shouldn't, because it should not be able to verify that the C exit is terminal:
def terminal my_exit(code:int) {
foreign c exit(code)
}
A single do loop like the one in the above attached file executes as expected.
However, using a nested do or for loop optimizes the inner loop away and inlines only a single iteration of the outer loop.
Expected output:
Outer
Inner
Inner
...
Actual output:
Outer
The inner loop is optimized away somewhere between Clause.hs and Expansion.hs.
In the current makefile, it will build the wybemk and copy it to "~/.local/bin". However, the cbits.so is built and put in the wybe project folder.
When using wybemk to compile a program, it seems that the wybemk will try to locate the cbits.so in the work directory and throw an internal error "clang: error: no such file or directory: 'cbits.so'".
The compiler is also trying to use the "./wybelibs/wybe.wybe" in the current work directory.
?res = 10 > 5
!println(res)
?res = 10 < 5
!println(res)
gives output:
false
false
and for this program
!read(?a:int)
!read(?b:int)
if { a > b ::
!println("a > b")
| otherwise ::
!println("a <= b")
}
we have:
> ./test
5 10
a <= b
> ./test
10 5
a > b
> ./test
5 -10
a <= b
> ./test
-10 5
a > b
f1.wybe
use f2
pub def xxx(v:int, n:int) use !io {
?n = n - 1
if { n < 0 ::
!println(v)
| otherwise ::
!yyy(v, n)
}
}
!xxx(99, 10)
f2.wybe
use f1
pub def yyy(v:int, n:int) use !io {
?n = n - 1
if { n < 0 ::
!println(v)
| otherwise ::
!xxx(v, n)
}
}
Then:
wybemk f1
I suspect the problem is in orderedDependencies called from
Line 776 in d7fcff1
Wybe issues an error message if you call a test procedure or function outside of a test context. So code like
if { lst = [] :: ?z = y
| else :: ?z = [head(lst) | append(tail(lst), y)]
}
causes an error, because the calls to head and tailare tests. However, because they appear in a context in which we know lst is not [], they actually can be guaranteed to succeed.
Because determinism errors are detected and reported during type/mode analysis, this must be addressed prior to transformation to LPVM, and since LPVM code is strictly deterministic, determinism errors need to be handled at the AST state, which makes the analysis messier.
I believe the easiest way to handle this would be to maintain sets of mutually exclusive calls, and sets of exhaustive tests. Initially, all the constructors of each type would be recorded as both mutually exclusive and exhaustive. Additionally, we should allow users to declare these sets. For example, the int type would include declarations that <= and > are mutually exclusive and exhaustive, likewise <, =, and >.
Given this information, when compiling code that follows success of a test, we can know that none of the calls that are mutually exclusive with it can succeed. When compiling code that follows failure of a test, we can know that one of the calls it is exhaustive with must succeed. When that set is a singleton, we can record that it must succeed. Thus in the example code above, because we know that and head(lst,?tmp) are exhaustive, in the else branch in that example, because has failed, then the call to head must succeed, and similarly for tail.
test.wybe
?x = -1.3
!println(x)
output:
Error detected during type checking of module(s) test
./test.wybe:1:7: Type error in call to -, argument 1
./test.wybe:1:7: Type error in call to -, argument 1
./test.wybe:1:7: Toplevel call to - with 2 arguments, expected 3
./test.wybe:1:7: Toplevel call to - with 2 arguments, expected 3
./test.wybe:1:7: Toplevel call to - with 2 arguments, expected 3
./test.wybe:1:7: Toplevel call to - with 2 arguments, expected 3
./test.wybe:1:7: Toplevel call to - with 2 arguments, expected 3
./test.wybe:1:7: Toplevel call to - with 2 arguments, expected 3
Compilation aborts with this message for any source file that defines a new data structure
There is a performance degradation in procedure range in the complex test case testcase_multi_specz-int_list caused by #87 .
The original procedure:
pub def range(start:int, stop:int, step:int, ?result:int_list) {
?result = []
do {
while start < stop
?result = [start | result]
?start = start + step
}
reverse(!result)
}
I rewrite it as below to avoid that issue.
pub def range(start:int, stop:int, step:int, ?result:int_list) {
?result = []
range_loop(start, stop, step, !result)
reverse(!result)
}
pub def range_loop(start:int, stop:int, step:int, !result:int_list) {
if { start < stop ::
?result = [start | result]
range_loop(start+step, stop, step, !result)
}
}
and get LPVM code as below:
range > public (0 calls)
0: range(start#0:wybe.int, stop#0:wybe.int, step#0:wybe.int, ?result#2:int_list.int_list):
AliasPairs: []
InterestingCallProperties: []
int_list.range_loop<0>(~start#0:wybe.int, ~stop#0:wybe.int, ~step#0:wybe.int, 0:int_list.int_list, ?%result#1:int_list.int_list) #1 @int_list:26:5
int_list.reverse_helper<0>(~%result#1:int_list.int_list, 0:int_list.int_list, ?%result#2:int_list.int_list) #3 @int_list:155:42
range_loop > public (2 calls)
0: range_loop(start#0:wybe.int, stop#0:wybe.int, step#0:wybe.int, result#0:int_list.int_list, ?result#2:int_list.int_list):
AliasPairs: [(result#0,result#2)]
InterestingCallProperties: []
foreign llvm icmp slt(start#0:wybe.int, stop#0:wybe.int, ?tmp$2#0:wybe.bool) @wybe:31:35
case ~tmp$2#0:wybe.bool of
0:
foreign llvm move(~result#0:int_list.int_list, ?result#2:int_list.int_list)
1:
foreign lpvm alloc(16:wybe.int, ?tmp$7#0:int_list.int_list)
foreign lpvm mutate(~tmp$7#0:int_list.int_list, ?tmp$8#0:int_list.int_list, 0:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, start#0:wybe.int)
foreign lpvm mutate(~tmp$8#0:int_list.int_list, ?tmp$9#0:int_list.int_list, 8:wybe.int, 1:wybe.int, 16:wybe.int, 0:wybe.int, ~result#0:int_list.int_list)
foreign llvm add(~start#0:wybe.int, step#0:wybe.int, ?tmp$1#0:wybe.int) @wybe:20:34
int_list.range_loop<0>(~tmp$1#0:wybe.int, ~stop#0:wybe.int, ~step#0:wybe.int, ~tmp$9#0:int_list.int_list, ?%result#2:int_list.int_list) #3 @int_list:33:9
The alias analysis failed to handle this case that the first int_list arg in the call to range_loop in range is a constant.
So it will think the return value result#1 is aliased.
While trying to fix it, I found something odd.
The aliasmap after the call to range_loop is like this:
current aliasMap: fromList [fromList [LiveVar lst#0,LiveVar result#1],fromList [LiveVar result#2,MaybeAliasByParam result#2],fromList [MaybeAliasByParam start#0],fromList [MaybeAliasByParam step#0],fromList [MaybeAliasByParam stop#0]]
The lst#0 isn't even a variable in the procedure range. It seems the alias analysis mixed up the parameters of the callee and the arguments of the caller.
This was tested in a Ubuntu environment.
For example, when the path of the wybe compiler's git repo is something like:
/home/wybe compiler/
make all will failed to copy the wybemk file from stack's tmp directory to the wybe compiler's root directory
The exact command causing the above issue is cp `stack path --local-install-root`/bin/$@ $@ in line 43 of Makefile
A simple fix would be adding quote to the command:
cp "`stack path --local-install-root`/bin/$@" $@
I am not familiar with MacOS enough to know will this break though
This same issue also occur if INSTALLBIN or INSTALLLIB contain spaces for some reason.
I belive the cause is here:
Lines 435 to 460 in 9bfffb1
loadImports only handles the imports of the root module.
If #71 is merged, then we also need to fix the corresponding part for loading from an object file.
I belive the builder needs a large refactor, for more detail, please find XXXs added by PR #71 .
err.wybe
?x = 0.01
!println(x)
output:
Syntax Error: "./err.wybe" (line 1, column 7):
unexpected TokSymbol "." "./err.wybe" (line 1, column 7)
expecting simple expression terms, relational expressions or end of input
I believe the wrong part is here, a number that stars with 0 is considered to be octal.
Lines 113 to 115 in db7242e
Also, based on the current document. For the scientific notation of a float, the "order of magnitude" part can't be negative. That's a bit odd.
When compiling cbits.c, I get these warning messages:
wybelibs/cbits.c:16:35: warning: format specifies type 'long' but the argument
has type 'int64_t' (aka 'long long') [-Wformat]
return (int64_t)printf("%ld", x);
~~~ ^
%lld
wybelibs/cbits.c:28:42: warning: format specifies type 'long' but the argument
has type 'int64_t' (aka 'long long') [-Wformat]
return (int64_t)fprintf(stderr, "%ld", x);
~~~ ^
%lld
wybelibs/cbits.c:51:18: warning: format specifies type 'long *' but the argument
has type 'int64_t *' (aka 'long long *') [-Wformat]
scanf("%ld", &x);
~~~ ^~
%lld
Allow a type to be a subtype of another type. For a type a to be a subtype of b, it would be required for there to be a total function named b from a to b. Then it would be allowed to pass a value x:a anywhere a b was expected; the compiler would automatically pass b(x) instead.
This permits multiple inheritance. It also permits bi-directional conversion, in cases where two types are effectively semantically equivalent, though perhaps implemented differently.
For now, don't search for a conversion route between types: do the conversion from a to b if there's a function named b from a to b; otherwise, the conversion is not supported.
Allow the conversion function to be defined in any module. E.g., module c can import both a and b, which are not related, but if c defines or imports a function b from a to b, then a is a subtype of b and c can pass an a anywhere a b is expected.
trying to compile test cases inside /test-cases/final-dump/, use_resource.wybe gives error related to the use of resources
$wybemk use_resource
gives the following error:
Unknown resource use_resource.count
while
$wybemk use_resource.o
gives no error
I was trying to fix #21 which requires merging multiple alias maps and I found a case where the result is wrong.
Util.combineUf (fromList [(a#0,a#0),(b#0,b#0),(r#0,a#0)]) (fromList [(a#0,a#0),(b#0,b#0),(r#0,b#0)]) returns fromList [(a#0,a#0),(b#0,b#0),(r#0,a#0)]
Util.uniteUf (fromList [(a#0,a#0),(b#0,b#0),(r#0,b#0)]) (r#0) (a#0) returns fromList [(a#0,a#0),(b#0,b#0),(r#0,a#0)].
I don't know how to fix it due to the current implementation doesn't make sense to me.
My questions are:
Line 162 in f5cae83
Lines 273 to 282 in f5cae83
Lines 334 to 339 in f5cae83
Using some suitable heuristic, automatically pass some procedure input and output arguments in global variables. This will be beneficial for arguments passed around widely through the program, and probably detrimental for arguments that change frequently.
It would probably be best to actually store all these in allocated heap memory, so that each thread can have its own set, when we support multithreading.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.