I have built an AI Generated Text Detector with KerasNLP trained on LLM Text dataset sourced from kaggle using DistilBERT from KerasNLP Library.
Here, we delve into the task of identifying text generated by Large Language Models (LLMs). These models have become popular due to their ability to quickly produce high-quality text, making them useful for applications like chatbots, content creation, and automated writing. However, the increase in LLM-generated content has brought about the need to distinguish it from human-generated text due to concerns about misinformation, plagiarism, and ethical issues.
The necessity of detecting LLM-generated text stems from several factors:
Misinformation Control: LLMs can rapidly disseminate false information. Detection helps in identifying and reducing the impact of misinformation.
Plagiarism Prevention: Recognizing LLM-generated content helps prevent academic and content plagiarism, thereby maintaining integrity in research and publications.
Ethical Considerations: Knowing the origin of text content is essential for upholding ethical standards, particularly in sensitive areas like news reporting and legal documentation.
Trust and Transparency: Detection enhances trust by ensuring transparency about the source of text content, thereby improving credibility in communication channels.
It is a Library based on Keras that makes it easier to implement NLP applications by writing only a few lines of code. KerasNLP provides specialized layers and model components tailored for NLP tasks. Examples include layers for attention mechanisms, sequence-to-sequence models, and transformer-based architectures.
BERT stands for Bidirectional Encoder Representations from Transformers. BERT and other Transformer encoder architectures have been wildly successful on a variety of tasks in NLP (natural language processing). They compute vector-space representations of natural language that are suitable for use in deep learning models.
The BERT family of models uses the Transformer encoder architecture to process each token of input text in the full context of all tokens before and after, hence the name: Bidirectional Encoder Representations from Transformers.
BERT models are usually pre-trained on a large corpus of text, then fine-tuned for specific tasks.
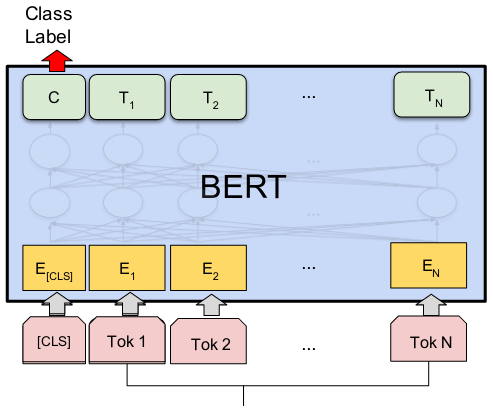
DistilBERT stands for "Distilled BERT". It is a distilled form of the BERT model. DistilBERT has fewer layers than BERT. Specifically, it has 6 layers compared to BERT-Base’s 12 layers. This reduction leads to a smaller model size and faster inference time. The size of a BERT model was reduced by 40% via knowledge distillation during the pre-training phase while retaining 97% of its language understanding abilities and being 60% faster.
Dataset Link: https://www.kaggle.com/datasets/thedrcat/daigt-v2-train-dataset
