Periscope is a powerful, fast, thick and top-to-bottom right-hander, eastward from Sumbawa's famous west-coast. Timing is critical, as needs a number of elements to align before it shows its true colors.
Periscope brings QoS and autoscaling to Hadoop YARN. Built on cloud resource management and YARN schedulers, allows to associate SLA policies to applications.
Periscope API documentation.
##Overview
The purpose of Periscope is to bring QoS to a multi-tenant Hadoop cluster, while allowing to apply SLA policies to individual applications. At SequenceIQ working with multi-tenant Hadoop clusters for quite a while we have always seen the same frustration and fight for resource between users. The FairScheduler was partially solving this problem - bringing in fairness based on the notion of Dominant Resource Fairness. With the emergence of Hadoop 2 YARN and the CapacityScheduler we had the option to maximize throughput and utilization for a multi-tenant cluster in an operator-friendly manner. The scheduler works around the concept of queues. These queues are typically setup by administrators to reflect the economics of the shared cluster. While this is a pretty good abstraction and brings some level of SLA for predictable workloads, it often needs proper design ahead. The queue hierarchy and resource allocation needs to be changed when new tenants and workloads are moved to the cluster.
Periscope was designed around the idea of autoscaling clusters - without any need to preconfigure queues, cluster nodes or apply capacity planning ahead.
##How it works
Periscope monitors the application progress, the number of YARN containers/resources and their allocation, queue depths, and the number of available cluster nodes and their health. Since we have switched to YARN a while ago (been among the first adopters) we have run an open source monitoring project, based on R. We have been collecting metrics from the YARN Timeline server, Hadoop Metrics2 and Ambari's Nagios/Ganglia - and profiling the applications and correlating with these metrics. One of the key findings was that while low level metrics are good to understand the cluster health - they might not necessarily help on making decisions when applying different SLA policies on a multi-tenant cluster. Focusing on higher level building blocks as queue depth, YARN containers, etc actually brings in the same quality of service, while not being lost in low level details.
Periscope works with two types of Hadoop clusters: static and dynamic. Periscope does not require any pre-installation - the only thing it requires is to be attached to an Ambari server's REST API.
##Technology
###Cloudbreak
Cloudbreak is SequenceIQ's RESTful Hadoop as a Service API. Once it is deployed in your favorite servlet container exposes a REST API allowing to span up Hadoop clusters of arbitrary sizes on your selected cloud provider. Provisioning Hadoop has never been easier. Cloudbreak is built on the foundation of cloud providers API (Amazon AWS, Microsoft Azure, Google Cloud Compute...), Apache Ambari, Docker containers, Serf and dnsmasq.
For further information please check the Cloudbreak documentation.
###Apache YARN
Since the emergence of Hadoop 2 and the YARN based architecture we have a platform where we can run multiple applications (of different types) not constrained only to MapReduce.
The idea of YARN is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). The ResourceManager and per-node slave, the NodeManager (NM), form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.
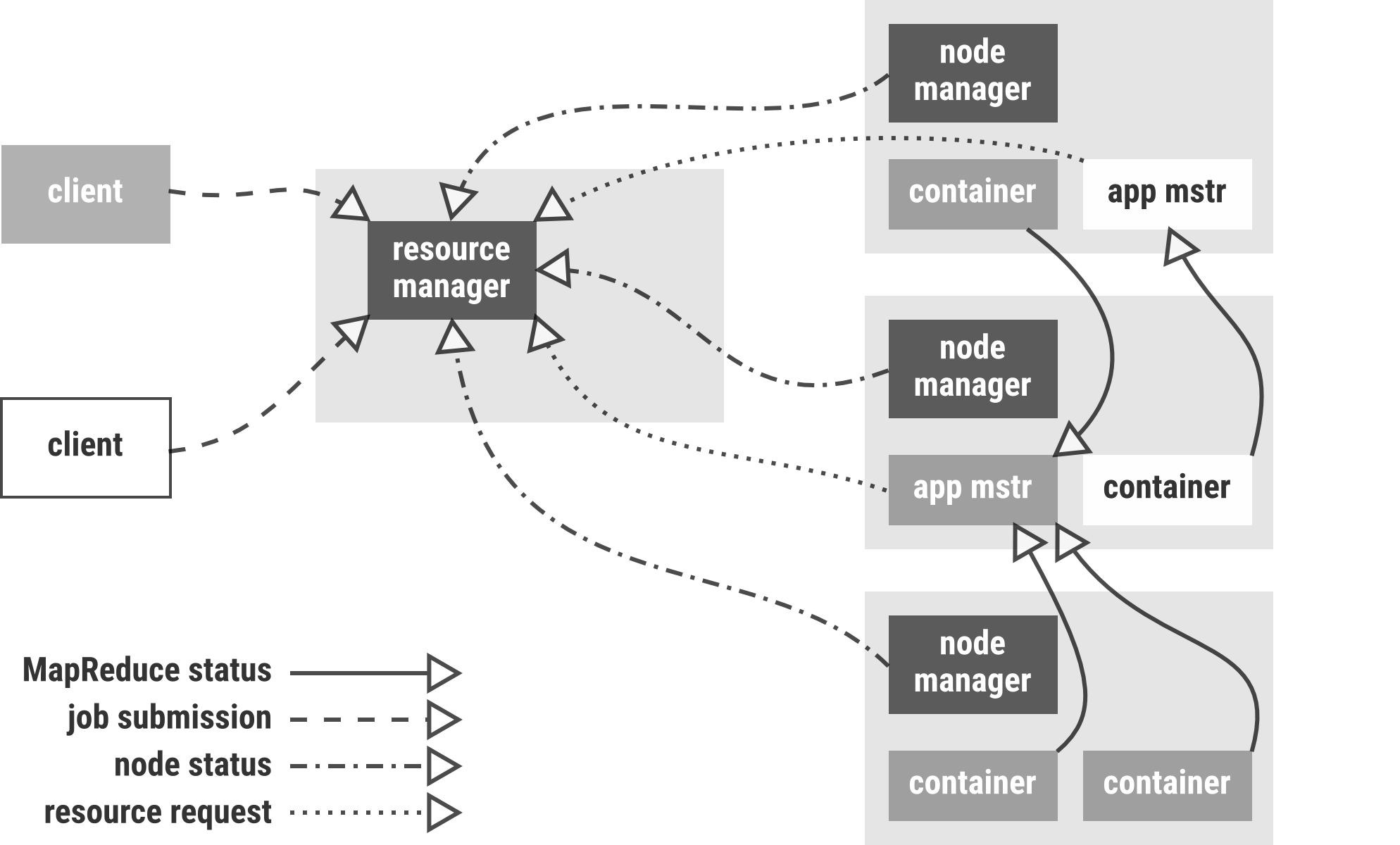
Different applications or different MapReduce job profiles have different resource needs, however since Hadoop 2 is a multi tenant platform the different users could have different access patterns or need for cluster capacity. In Hadoop 2.0 this is achieved through YARN schedulers — to allocate resources to various applications subject to constraints of capacities and queues. The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The Scheduler is pure scheduler in the sense that it performs no monitoring or tracking of status for the application.
Periscope is using the Capacity Scheduler to apply SLA policies to applications.
###Apache Ambari
The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
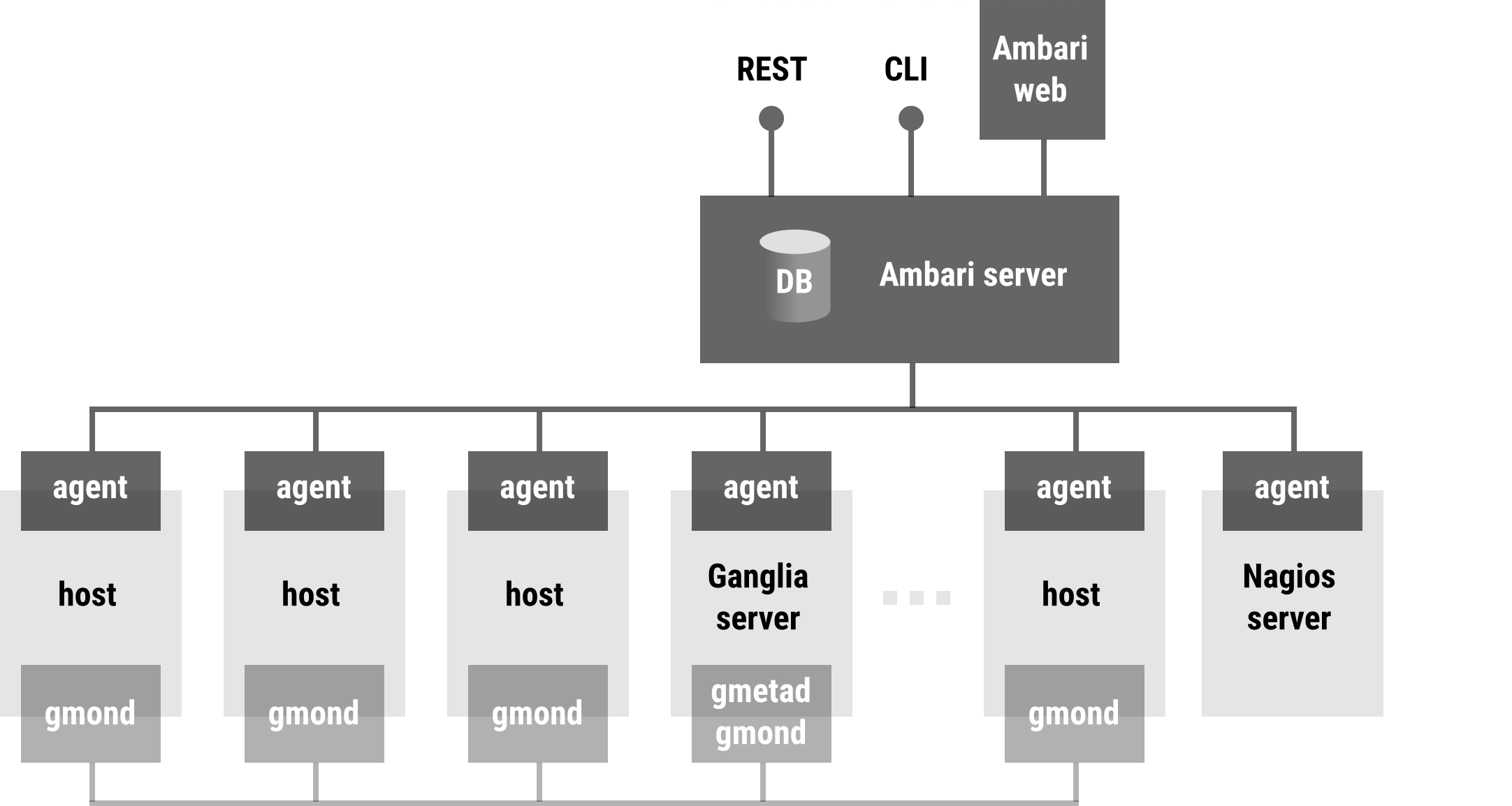
Ambari enables System Administrators to:
- Provision a Hadoop Cluster
- Ambari provides a step-by-step wizard for installing Hadoop services across any number of hosts.
- Ambari handles configuration of Hadoop services for the cluster.
- Manage a Hadoop Cluster
- Ambari provides central management for starting, stopping, and reconfiguring Hadoop services across the entire cluster.
- Monitor a Hadoop Cluster
- Ambari provides a dashboard for monitoring health and status of the Hadoop cluster.
- Ambari leverages Ganglia for metrics collection.
- Ambari leverages Nagios for system alerting and will send emails when your attention is needed (e.g. a node goes down, remaining disk space is low, etc).
Ambari enables to integrate Hadoop provisioning, management and monitoring capabilities into applications with the Ambari REST APIs. Ambari Blueprints are a declarative definition of a cluster. With a Blueprint, you can specify a Stack, the Component layout and the Configurations to materialize a Hadoop cluster instance (via a REST API) without having to use the Ambari Cluster Install Wizard.

###Docker
Docker is an open platform for developers and sysadmins to build, ship, and run distributed applications. Consisting of Docker Engine, a portable, lightweight runtime and packaging tool, and Docker Hub, a cloud service for sharing applications and automating workflows, Docker enables apps to be quickly assembled from components and eliminates the friction between development, QA, and production environments. As a result, IT can ship faster and run the same app, unchanged, on laptops, data center VMs, and any cloud.
The main features of Docker are:
- Lightweight, portable
- Build once, run anywhere
- VM - without the overhead of a VM
- Each virtualised application includes not only the application and the necessary binaries and libraries, but also an entire guest operating system
- The Docker Engine container comprises just the application and its dependencies. It runs as an isolated process in userspace on the host operating system, sharing the kernel with other containers.

- Containers are isolated
- It can be automated and scripted
###Serf
Serf is a tool for cluster membership, failure detection, and orchestration that is decentralised, fault-tolerant and highly available. Serf runs on every major platform: Linux, Mac OS X, and Windows. It is extremely lightweight. Serf uses an efficient gossip protocol to solve three major problems:
-
Membership: Serf maintains cluster membership lists and is able to execute custom handler scripts when that membership changes. For example, Serf can maintain the list of Hadoop servers of a cluster and notify the members when nodes come online or go offline.
-
Failure detection and recovery: Serf automatically detects failed nodes within seconds, notifies the rest of the cluster, and executes handler scripts allowing you to handle these events. Serf will attempt to recover failed nodes by reconnecting to them periodically.

-
Custom event propagation: Serf can broadcast custom events and queries to the cluster. These can be used to trigger deploys, propagate configuration, etc. Events are simple fire-and-forget broadcast, and Serf makes a best effort to deliver messages in the face of offline nodes or network partitions. Queries provide a simple realtime request/response mechanism.

##Building blocks
###Clusters
A Hadoop cluster is a set of components and services launched in order to store, analyze and process unstructured data. Periscope can work with any Hadoop 2/ YARN cluster provisioned with Apache Ambari, and supports any YARN application.
As highlighted before, Periscope can apply SLA policies to static and autoscaling clusters. Due to flexibility supported by cloud based Hadoop deployments, we suggest to link Periscope with Cloudbreak and apply policy based autoscaling to your cluster.
Static clusters
From Periscope point of view we consider a cluster static when the cluster capacity can't be increased horizontally.
This means that the hardware resources are already given - and the throughput can't be increased by adding new nodes.
Periscope introspects the job submission process, monitors the applications and applies the following SLAs:
- Application ordering - can guarantee that a higher priority application finishes before another one (supporting parallel or sequential execution)
- Moves running applications between priority queues
- Attempts to enforce time based SLA (execution time, finish by, finish between, recurring)
- Attempts to enforce guaranteed cluster capacity requests ( x % of the resources)
- Support for distributed (but not YARN ready) applications using Apache Slider
- Attach priorities to SLAs
Note: not all of the features above are supported in the first public beta version. There are dependencies we contributed to Hadoop, YARN and Ambari and they will be included in the next releases (2.6 and 1.7)
Autoscaling clusters
From Periscope point of view we consider a cluster dynamic when the cluster capacity can be increased horizontally.
This means that nodes can be added or removed on the fly - thus the cluster’s throughput can be increased or decreased based on the cluster load and scheduled applications.
Periscope works with Cloudbreak to add or remove nodes from the cluster based on the SLA policies and thus continuously provide a high quality of service for the multi-tenand Hadoop cluster.
Just to refresh memories - Cloudbreak is SequenceIQ's open source, cloud agnostic Hadoop as a Service API.
Given the option of provisioning or decommissioning cluster nodes on the fly, Periscope allows you to use the following set of SLAs:
- Application ordering - can guarantee that a higher priority application finishes before another one (supporting parallel or sequential execution)
- Moves running applications between priority queues
- Enforce time based SLA (execution time, finish by, finish between, recurring) by increasing cluster capacity and throughput
- Smart decommissioning - avoids HDFS storms, keeps
paidnodes alive till the last minute - Enforce guaranteed cluster capacity requests ( x % of the resources)
- Private cluster requests - supports provisioning of short lived private clusters with the possibility to merge
- Support for distributed (but not YARN ready) applications using Apache Slider
- Attach priorities to SLAs
Note: not all of the features above are supported in the first public beta version. There are dependencies we contributed to Hadoop, YARN and Ambari and they will be included in the next releases (2.6 and 1.7)
###Alarms
An alarm watches a metric over a specified time period, and used by one or more action or scaling policy based on the value of the metric relative to a given threshold over a number of time periods. In case Periscope raises an alarm an action (e.g. sending an email) or a scaling policy is triggered. Alarms are based on metrics. The current supported metrics are:
*PENDING_CONTAINERS- pending YARN containers
*PENDING_APPLICATIONS - pending/queued YARN applications
*LOST_NODES - cluster nodes lost
*UNHEALTHY_NODES - unhealthy cluster nodes
*GLOBAL_RESOURCES - global resources
Measured metrics are compared with pre-configured values using operators. The comparison operators are: LESS_THAN, GREATER_THAN, LESS_OR_EQUAL_THAN, GREATER_OR_EQUAL_THAN, EQUALS.
In order to avoid reacting for sudden spikes in the system and apply policies only in case of a sustained system stress, alarms have to be sustained over a period of time. The period specifies the time period in minutes during the alarm has to be sustained.
Also a threshold can be configured, which specifies the variance applied by the operator for the selected metric.
###SLA Scaling Policies
Scaling is the ability to increase or decrease the capacity of the Hadoop cluster or application.
When scaling policies are used, the capacity is automatically increased or decreased according to the conditions defined.
Periscope will do the heavy lifting and based on the alarms and the scaling policy linked to them it executes the associated policy.
By default a fully configured and running Cloudbreak cluster contains no SLA policies.
An SLA scaling policy can contain multiple alarms. As an alarm is triggered a scalingAdjustment is applied, however to keep the cluster size within boundaries a minSize and maxSize is attached to the cluster - thus a scaling policy can never over or undersize a cluster. Also in order to avoid stressing the cluster we have introduced a cooldown period (minutes) - though an alarm is raised and there is an associated scaling policy, the system will not apply the policy within the configured timeframe. In an SLA scaling policy the triggered rules are applied in order.
###Applications
A Hadoop YARN application is a packaged workload submitted to a cluster. An application requests resources from YARN Resource Manager. The resources are allocated as YARN containers. By default Periscope works with the Hadoop YARN Capacity Scheduler. Using the Capacity Scheduler applications are submitted in different priority queues. The queue configurations, their depth, associated resources, etc have to be designed ahead - and adapted in case of new tenants, applications or workloads are using the cluster.
At SequenceIQ, through our contributions to Apache YARN we facilitate moving applications between queues - and thus use the SLA policies attached to these queues. Even more, those SLA policies which were previously attached to Capacity Scheduler queues now can be attached to submitted jobs/applications.
Also we facilitate changing the resources allocated to a running application - even though they were submitted and already running.
Note: not all of the features above are supported in the first public beta version. There are dependencies we contributed to Hadoop, Ambari and YARN and they will be included in the next releases (1.7 and 2.6)
###Configuration
Periscope brings in the capability to reconfigure a running cluster - in particular resource properties heavily used. These properties currently are mostly related to the Capacity Scheduler configurations, but as we add functionality to Periscope this set of properties will constantly increase.
##QuickStart and installation
Periscope requires an Apache Ambari endpoint of your Hadoop cluster to start to apply your SLA policies. We suggest to start with Cloudbreak. Create a hosted free Cloudbreak account and start experimenting.
###Build and run The Periscope code is available at our GitHub repository.
git clone https://github.com/sequenceiq/periscope.git
cd periscope
In order to build Periscope you will need Gradle.
./gradlew clean build
You are almost done. In order to start using Periscope you will need to set or pass the following environment variables.
periscope.cloudbreak.url - URL of Cloudbreak, e.g: http://cloudbreak.sequenceiq.com:80
periscope.db.tcp.addr - Address of the Database, e.g: 172.17.0.2
periscope.db.tcp.port - Port of the Database, e.g: 5432
periscope.db.user - Username to the Database, default: postgres
periscope.db.pass - Password to the Database, default: <no_password>
periscope.db.name - Name of the Database, default: postgres
periscope.db.hbm2ddl.strategy - Strategy whether to create or update the DB scheme on start, default: update
periscope.smtp.host - SMTP host for sending emails
periscope.smtp.port - SMTP port
periscope.smtp.username - SMTP username
periscope.smtp.password - SMTP password
periscope.smtp.from - SMTP from address, e.g. [email protected]
periscope.identity.server.url - URL of the UAA identity server, e.g: http://uaa.sequenceiq.com:80
periscope.client.id - ID of the registered application in UAA
periscope.client.secret - Secret key of the registered application in UAA
Monitoring requests and actions are async which means they run in a different thread under a thread pool. You can configure this pool, or you can leave the default values. These properties are optional.
periscope.threadpool.core.size - default: 10 - Base pool size
periscope.threadpool.max.size - default: 100 - Maximum number of parallel requests
periscope.threadpool.queue.size - default: 10 - Requests queue size
Periscope is a Spring Boot based application. In order to start please run the following.
java -jar periscope.jar
##Monitoring
Part of Periscope we have a Hadoop cluster monitoring solution called Baywatch.
Although various solutions have been created in the software industry for monitoring of activities taking place in a cluster, but it turned out that only a very few of them satisfies most of our needs. When we made the decision about which monitoring libraries and components to integrate in our stack we kept in mind that it needs to be:
-
scalable to be able to efficiently monitor small Hadoop clusters which are consisting of only a few nodes and also clusters which containing thousands of nodes
-
flexible to be able to provide overview about the health of the whole cluster or about the health of individual nodes or even dive deeper into the internals of Hadoop, e.g. shall be able to visualize how our autoscaling solution for Hadoop YARN called Periscope moves running applications between queues
-
extensible to be able to use the gathered and stored data by extensions written by 3rd parties, e.g. a module which processes the stored (metrics) data and does real-time anomaly detection
-
zero-configuration to be able to plug into any existing Hadoop cluster without additional configuration, component installation
Based on the requirements above our choice were the followings:
- Logstash for log/metrics enrichment, parsing and transformation
- Elasticsearch for data storage, indexing
- Kibana for data visualization
###High Level Architecture
In our monitoring solution one of the design goal was to provide a generic, pluggable and isolated monitoring component to existing Hadoop deployments. We also wanted to make it non-invasive and avoid adding any monitoring related dependency to our Ambari, Hadoop or other Docker images. For that reason we have packaged the monitoring client component into its own Docker image which can be launched alongside with a Hadoop running in another container or even alongside a Hadoop which is not even containerized.
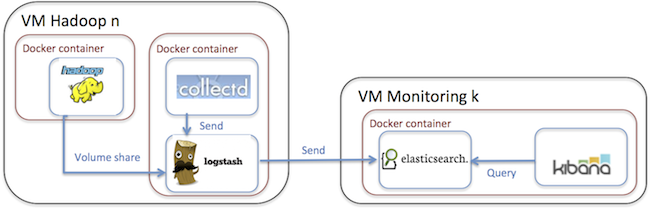
In a nutshell the monitoring solution consist of client and server containers. The server contains the Elasticsearch and the Kibana module. The server container is horizontally scalable and it can be clustered trough the clustering capabilities of Elasticsearch.
The client container - which is deployed on the machine what is needed to be monitored - contains the Logstash and the collectd module. The Logstash connects to Elasticsearch cluster as client and stores the processed and transformed metrics data there.
###Hadoop metrics The metrics data what we are collecting and visualizing are provided by Hadoop metrics, which is a collection of runtime information that are exposed by all Hadoop daemons. We have configured the Metrics subsystem in that way that it writes the valuable metrics information into the filesystem.
In order to be able to access the metrics data from the monitoring client component - which is running inside a different Docker container - we used the capability of Docker Volumes which basically let's you access a directory within one container form other container or even access directories from host systems.
For example if you would like mount the /var/log from the container named ambari-singlenode under the /amb/log in the monitoring client container then the following sequence of commands needs to be executed:
EXPOSED_LOG_DIR=$(docker inspect --format='{{index .Volumes "/var/log"}}' ambari-singlenode)
docker run -i -t -v $EXPOSED_LOG_DIR:/amb/log sequenceiq/baywatch-client /etc/bootstrap.sh -bashHundreds of different metrics are gathered form Hadoop metrics subsystem and all data is transformed by Logstash to JSON and stored in ElasticSearch to make it ready for querying or displaying it with Kibana.
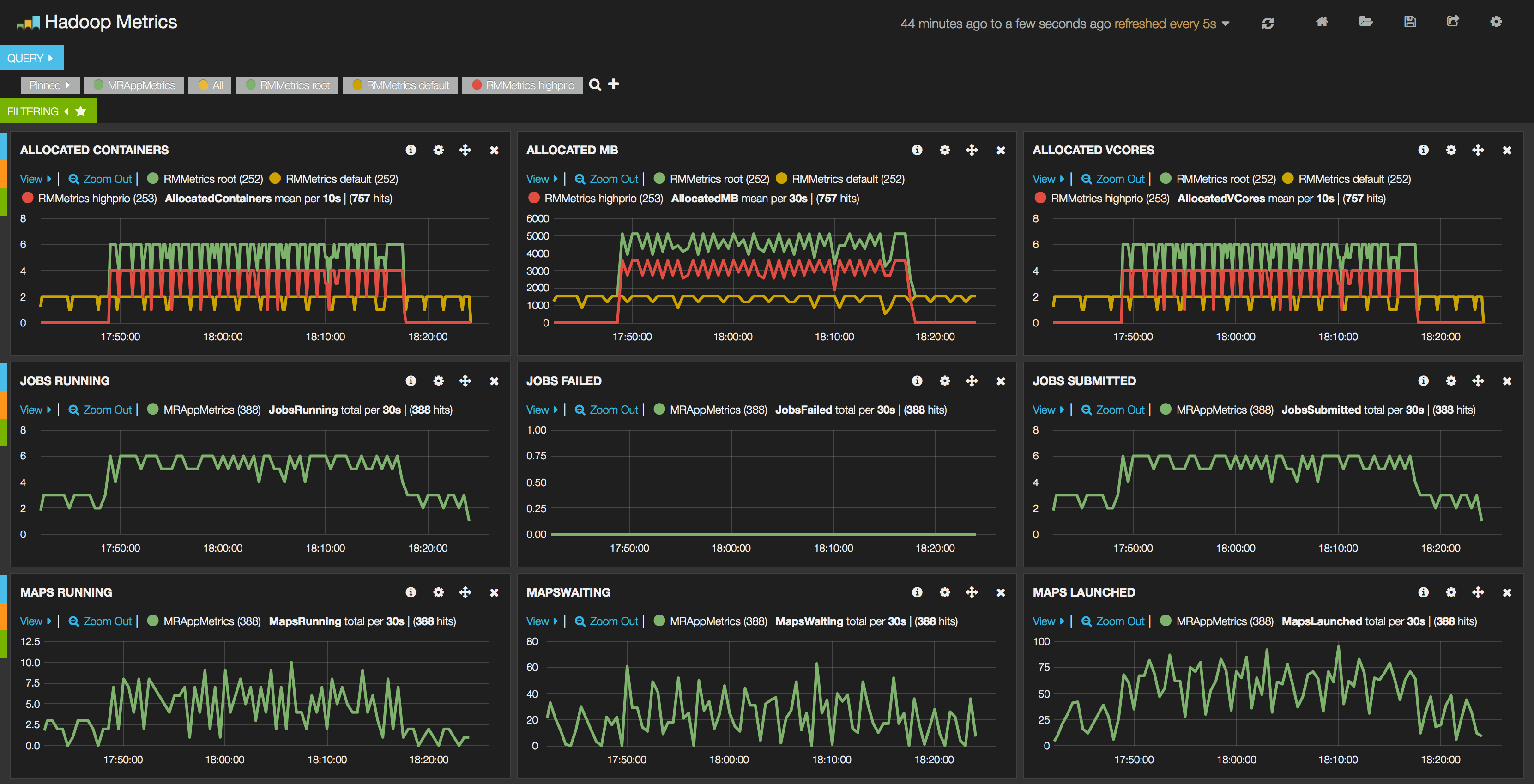
The screenshot below has been created from one of our sample dashboard which is displaying Hadoop metrics for a small cluster which was started on my notebook. In this cluster the Yarn's Capacity Scheduler is used and for demonstration purposes I have created a queue called highprio alongside the default queue. I have reduced the capacity of the default queue to 30 and defined the highprio queue with a capacity of 70.
The red line in the screenshot belongs to the highprio queue, the yellow line belongs to the default queue and the green line is the root queue which is the common ancestor both of them.
In the benchmark, the jobs were submitted to the default queue and a bit later (somewhere around 17:48) the same jobs were submitted to the highprio queue. As it is clearly observable for highprio queue the allocated Containers, Memory and VCores were higher and jobs were finished much more faster than those that were submitted to the default queue.
Such kind of dashboard is extremely useful when we are visualizing decisions made by Periscope and check e.g. how the applications are moved across queues, or additional nodes are added or removed dynamically from the cluster.
To see it in large, please click here.
Since all of the Hadoop metrics are stored in the Elasticsearch, therefore there are a lot of possibilities to create different dashboards using that particular parameter of the cluster which is interesting for the operator. The dashboards can be configured on the fly and the metrics are displayed in real-time.
###System resources
Beside Hadoop metrics, "traditional" system resource data (cpu, memory, io, network) are gathered with the aid of collectd. This can also run inside the monitoring client container since due to the resource management in Docker the containers can access and gather information about the whole system and a container can even "steal" the network of other container if you start with: --net=container:id-of-other-container which is very useful if cases when network traffic is monitored.
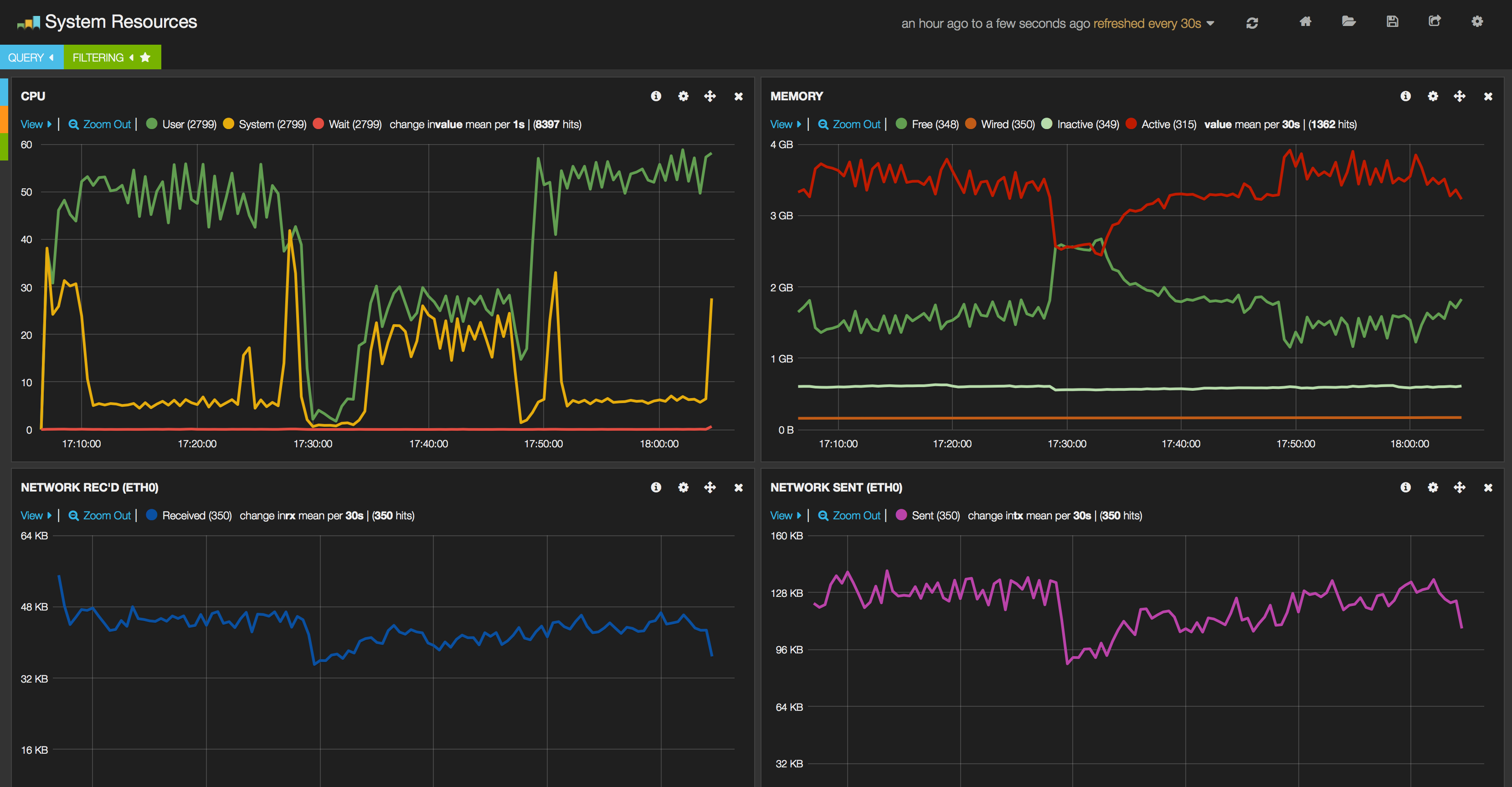
##Releases, future plans
Quite a while ago we have been thinking about autoscaling Hadoop clusters. First of all - being a cost aware young startup - we always had to manually manage our cloud based VM instances, doing what exactly Periscope does. Having short and long running Hadoop jobs on different clusters, and maintaining in parallel different clusters it was a very error prone and tedious job. While Amazon for instance gives a quite good API (remember we always use a CLI as an alternative for UI) but this still wasn’t easy when you have 10+ clusters of different sizes. On the other hand we have started to use different cloud providers as well - Microsoft’s Azure and Google’s Cloud Compute.
This diversity started to eat into too much DevOps time - and we decided to automate everything and create Periscope.
The first public beta does support autoscaling clusters on Amazon AWS and Microsoft Azure - and we will bring in the other Cloudbreak providers as we add them. Once our contributions in Apache Hadoop, YARN and Ambari will be released (patches are accepted and in trunk - target versions are 2.6.0 and 1.7.0 - Periscope will start supporting the static cluster features such as application SLA policies.
Also note that the current version supports only up-scaling.
The currently supported Hadoop is the Hortonworks Data Platform - the 100% open source Hadoop distribution and the respective component versions are:
CentOS - 6.5 Hortonworks Data Platform - 2.1 Apache Hadoop - 2.4.0 Apache Tez - 0.4 Apache Pig - 0.12.1 Apache Hive & HCatalog - 0.13.0 Apache HBase - 0.98.0 Apache Phoenix - 4.0.0 Apache Accumulo - 1.5.1 Apache Storm - 0.9.1 Apache Mahout - 0.9.0 Apache Solr - 4.7.2 Apache Falcon - 0.5.0 Apache Sqoop - 1.4.4 Apache Flume - 1.4.0 Apache Ambari - 1.6.1 Apache Oozie - 4.0.0 Apache Zookeeper - 3.4.5 Apache Knox - 0.4.0 Docker - 1.1 Serf - 0.5.0 dnsmasq - 2.7
###Future releases
While this is already a good achievement - bringing autoscaling to cloud based Hadoop clusters - we don’t stop here. Periscope will be a centralized place to manage your cluster through SLA policies, check your cluster metrics and logs and correlate them with events/cluster heath - built on the well proven ELK stack (Elasticsearch, Logstash, Kibana). The analytics and visualization capabilities will allow a deeper understanding of running jobs, the nature of resources consumed and ultimately leverage the features provided by cloud providers. For instance a CPU heavy job can always launch purpose built (compute optimized) instance types. The next release will bring in OAuth2 support - and will incorporate the new features from YARN, Hadoop and Ambari, thus you will be able to attach SLA policies to static clusters. As we have already mentioned we are running a YARN monitoring project based on R - based on the experience and what we have learnt the end goal is to built a high level heuristic model which maintains a healthy cluster, without the need of predefined SLA policy rules. ##Contribution
So you are about to contribute to Periscope? Awesome! There are many different ways in which you can contribute. We strongly value your feedback, questions, bug reports, and feature requests. Periscope consist of the following main projects:
###Periscope code
Available: https://github.com/sequenceiq/periscope
###Periscope API
Available: https://periscope-api.sequenceiq.com
GitHub: https://github.com/sequenceiq/periscope
###Periscope documentation
Product documentation: http://sequenceiq.com/periscope
GitHub: https://github.com/sequenceiq/periscope/blob/master/docs/index.md
API documentation: http://docs.periscope.apiary.io
GitHub: https://github.com/sequenceiq/periscope/blob/master/apiary.apib
###Ways to contribute
- Use Periscope and Cloudbreak
- Submit a GitHub issue to the appropriate GitHub repository.
- Submit a new feature request (as a GitHub issue).
- Submit a code fix for a bug.
- Submit a unit test.
- Code review pending pull requests and bug fixes.
- Tell others about these projects.
###Contributing code
We are always thrilled to receive pull requests, and do our best to process them as fast as possible. Not sure if that typo is worth a pull request? Do it! We will appreciate it. The Periscope projects are open source and developed/distributed under the Apache Software License, Version 2.0. If you wish to contribute to Periscope (which you're very welcome and encouraged to do so) then you must agree to release the rights of your source under this license.
####Creating issues
Any significant improvement should be documented as a GitHub issue before starting to work on it. Please use the appropriate labels - bug, enhancement, etc - this helps while creating the release notes for a version release. Before submitting issues please check for duplicate or similar issues. If you are unclear about an issue please feel free to contact us.
####Discuss your design
We recommend discussing your plans on the mailing list before starting to code - especially for more ambitious contributions. This gives other contributors a chance to point you in the right direction, give feedback on your design, and maybe point out if someone else is working on the same thing.
####Conventions
Please write clean code. Universally formatted code promotes ease of writing, reading, and maintenance.
-
Do not use @author tags.
-
New classes must match our dependency mechanism.
-
Code must be formatted according to our formatter.
-
Code must be checked with our checkstyle.
-
Contributions must pass existing unit tests.
-
The code changes must be accompanied by unit tests. In cases where unit tests are not possible or don’t make sense an explanation should be provided.
-
New unit tests should be provided to demonstrate bugs and fixes (use Mockito whenever possible).
-
The tests should be named *Test.java.
-
Use slf4j instead of commons logging as the logging facade.
###Thank you Huge thanks go to the contributors from the community who have been actively working with the SequenceIQ team. Kudos for that.
###Jobs Do you like what we are doing? We are looking for exceptional software engineers to join our development team. Would you like to work with others in the open source community? Please consider submitting your resume and applying for open positions at [email protected].
Brought to you courtesy of our legal counsel.
Use and transfer of Periscope may be subject to certain restrictions by the
United States and other governments.
It is your responsibility to ensure that your use and/or transfer does not
violate applicable laws.
Periscope is licensed under the Apache License, Version 2.0. See LICENSE for full license text.



