




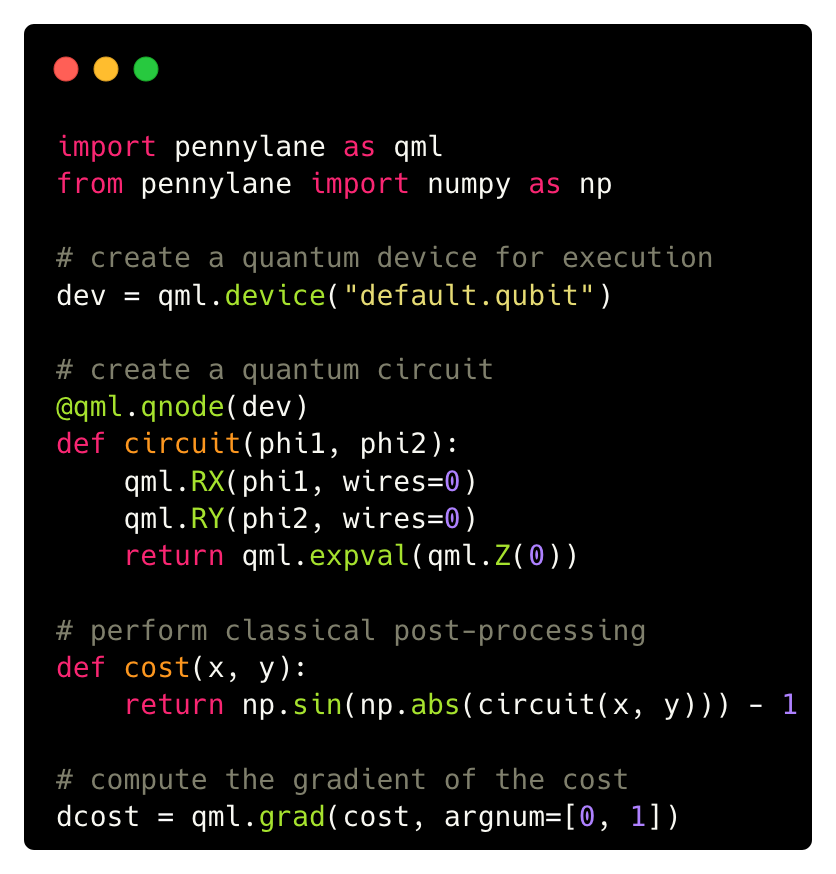
PennyLane is a cross-platform Python library for differentiable programming of quantum computers.
Train a quantum computer the same way as a neural network.


-
Machine learning on quantum hardware. Connect to quantum hardware using PyTorch, TensorFlow, JAX, Keras, or NumPy. Build rich and flexible hybrid quantum-classical models.
-
Just in time compilation. Experimental support for just-in-time compilation. Compile your entire hybrid workflow, with support for advanced features such as adaptive circuits, real-time measurement feedback, and unbounded loops. See Catalyst for more details.
-
Device-independent. Run the same quantum circuit on different quantum backends. Install plugins to access even more devices, including Strawberry Fields, Amazon Braket, IBM Q, Google Cirq, Rigetti Forest, Qulacs, Pasqal, Honeywell, and more.
-
Follow the gradient. Hardware-friendly automatic differentiation of quantum circuits.
-
Batteries included. Built-in tools for quantum machine learning, optimization, and quantum chemistry. Rapidly prototype using built-in quantum simulators with backpropagation support.
PennyLane requires Python version 3.9 and above. Installation of PennyLane, as well as all dependencies, can be done using pip:
python -m pip install pennylaneDocker support exists for building using CPU and GPU (Nvidia CUDA 11.1+) images. See a more detailed description here.
For an introduction to quantum machine learning, guides and resources are available on PennyLane's quantum machine learning hub:
- What is quantum machine learning?
- QML tutorials and demos
- Frequently asked questions
- Key concepts of QML
- QML videos
You can also check out our documentation for quickstart guides to using PennyLane, and detailed developer guides on how to write your own PennyLane-compatible quantum device.
Take a deeper dive into quantum machine learning by exploring cutting-edge algorithms on our demonstrations page.
All demonstrations are fully executable, and can be downloaded as Jupyter notebooks and Python scripts.
If you would like to contribute your own demo, see our demo submission guide.
Seeing is believing! Check out our videos to learn about PennyLane, quantum computing concepts, and more.
We welcome contributions—simply fork the PennyLane repository, and then make a pull request containing your contribution. All contributors to PennyLane will be listed as authors on the releases. All users who contribute significantly to the code (new plugins, new functionality, etc.) will be listed on the PennyLane arXiv paper.
We also encourage bug reports, suggestions for new features and enhancements, and even links to cool projects or applications built on PennyLane.
See our contributions page and our developer hub for more details.
- Source Code: https://github.com/PennyLaneAI/pennylane
- Issue Tracker: https://github.com/PennyLaneAI/pennylane/issues
If you are having issues, please let us know by posting the issue on our GitHub issue tracker.
We also have a PennyLane discussion forum—come join the community and chat with the PennyLane team.
Note that we are committed to providing a friendly, safe, and welcoming environment for all. Please read and respect the Code of Conduct.
PennyLane is the work of many contributors.
If you are doing research using PennyLane, please cite our paper:
Ville Bergholm et al. PennyLane: Automatic differentiation of hybrid quantum-classical computations. 2018. arXiv:1811.04968
PennyLane is free and open source, released under the Apache License, Version 2.0.












![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")




























































































































































