

This is a library for comparing tables, producing a summary of their differences, and using such a summary as a patch file. It is optimized for comparing tables that share a common origin, in other words multiple versions of the "same" table.
For a live demo, see:
Install the library for your favorite language:
npm install daff -g # node/javascript
pip install daff # python
gem install daff # ruby
composer require paulfitz/daff-php # php
install.packages('daff') # R wrapper by Edwin de Jonge
bower install daff # web/javascriptOther translations are available here:
Or use the library to view csv diffs on github via a chrome extension:
The diff format used by daff is specified here:
This library is a stripped down version of the coopy toolbox (see http://share.find.coop). To compare tables from different origins, or with automatically generated IDs, or other complications, check out the coopy toolbox.
You can run daff/daff.py/daff.rb as a utility program:
$ daff
daff can produce and apply tabular diffs.
Call as:
daff a.csv b.csv
daff [--color] [--no-color] [--output OUTPUT.csv] a.csv b.csv
daff [--output OUTPUT.html] a.csv b.csv
daff [--www] a.csv b.csv
daff parent.csv a.csv b.csv
daff --input-format sqlite a.db b.db
daff patch [--inplace] a.csv patch.csv
daff merge [--inplace] parent.csv a.csv b.csv
daff trim [--output OUTPUT.csv] source.csv
daff render [--output OUTPUT.html] diff.csv
daff copy in.csv out.tsv
daff in.csv
daff git
daff version
The --inplace option to patch and merge will result in modification of a.csv.
If you need more control, here is the full list of flags:
daff diff [--output OUTPUT.csv] [--context NUM] [--all] [--act ACT] a.csv b.csv
--act ACT: show only a certain kind of change (update, insert, delete, column)
--all: do not prune unchanged rows or columns
--all-rows: do not prune unchanged rows
--all-columns: do not prune unchanged columns
--color: highlight changes with terminal colors (default in terminals)
--context NUM: show NUM rows of context (0=none)
--context-columns NUM: show NUM columns of context (0=none)
--fail-if-diff: return status is 0 if equal, 1 if different, 2 if problem
--id: specify column to use as primary key (repeat for multi-column key)
--ignore: specify column to ignore completely (can repeat)
--index: include row/columns numbers from original tables
--input-format [csv|tsv|ssv|psv|json|sqlite]: set format to expect for input
--eol [crlf|lf|cr|auto]: separator between rows of csv output.
--no-color: make sure terminal colors are not used
--ordered: assume row order is meaningful (default for CSV)
--output-format [csv|tsv|ssv|psv|json|copy|html]: set format for output
--padding [dense|sparse|smart]: set padding method for aligning columns
--table NAME: compare the named table, used with SQL sources. If name changes, use 'n1:n2'
--unordered: assume row order is meaningless (default for json formats)
-w / --ignore-whitespace: ignore changes in leading/trailing whitespace
-i / --ignore-case: ignore differences in case
daff render [--output OUTPUT.html] [--css CSS.css] [--fragment] [--plain] diff.csv
--css CSS.css: generate a suitable css file to go with the html
--fragment: generate just a html fragment rather than a page
--plain: do not use fancy utf8 characters to make arrows prettier
--unquote: do not quote html characters in html diffs
--www: send output to a browser
Formats supported are CSV, TSV, Sqlite (with --input-format sqlite or
the .sqlite extension), and ndjson.
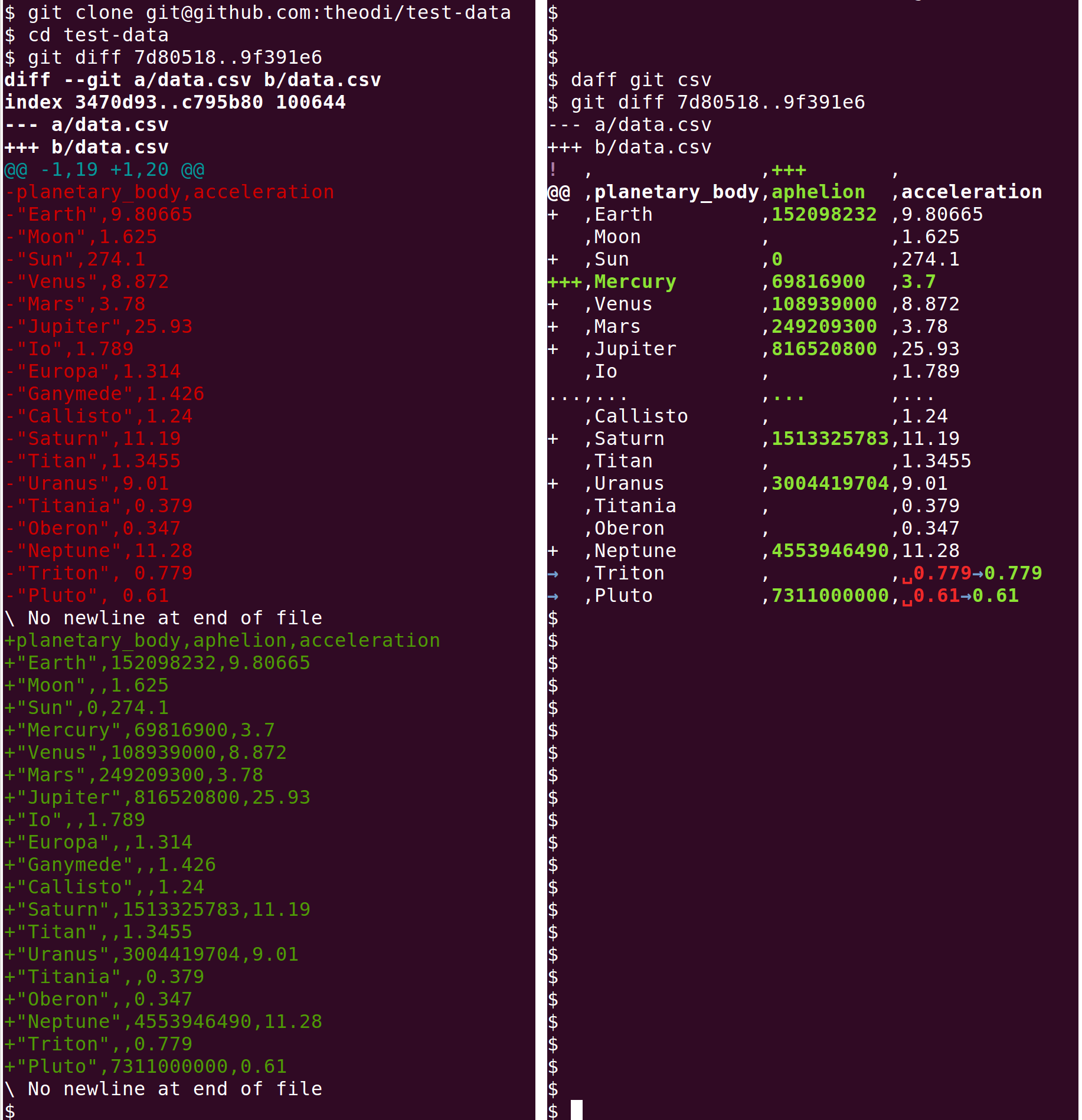
Run daff git csv to install daff as a diff and merge handler
for *.csv files in your repository. Run daff git for instructions
on doing this manually. Your CSV diffs and merges will get smarter,
since git will suddenly understand about rows and columns, not just lines:
You can use daff as a library from any supported language. We take
here the example of Javascript. To use daff on a webpage,
first include daff.js:
<script src="daff.js"></script>Or if using node outside the browser:
var daff = require('daff');For concreteness, assume we have two versions of a table,
data1 and data2:
var data1 = [
['Country','Capital'],
['Ireland','Dublin'],
['France','Paris'],
['Spain','Barcelona']
];
var data2 = [
['Country','Code','Capital'],
['Ireland','ie','Dublin'],
['France','fr','Paris'],
['Spain','es','Madrid'],
['Germany','de','Berlin']
];To make those tables accessible to the library, we wrap them
in daff.TableView:
var table1 = new daff.TableView(data1);
var table2 = new daff.TableView(data2);We can now compute the alignment between the rows and columns in the two tables:
var alignment = daff.compareTables(table1,table2).align();To produce a diff from the alignment, we first need a table for the output:
var data_diff = [];
var table_diff = new daff.TableView(data_diff);Using default options for the diff:
var flags = new daff.CompareFlags();
var highlighter = new daff.TableDiff(alignment,flags);
highlighter.hilite(table_diff);The diff is now in data_diff in highlighter format, see
specification here:
[ [ '!', '', '+++', '' ],
[ '@@', 'Country', 'Code', 'Capital' ],
[ '+', 'Ireland', 'ie', 'Dublin' ],
[ '+', 'France', 'fr', 'Paris' ],
[ '->', 'Spain', 'es', 'Barcelona->Madrid' ],
[ '+++', 'Germany', 'de', 'Berlin' ] ]For visualization, you may want to convert this to a HTML table with appropriate classes on cells so you can color-code inserts, deletes, updates, etc. You can do this with:
var diff2html = new daff.DiffRender();
diff2html.render(table_diff);
var table_diff_html = diff2html.html();For 3-way differences (that is, comparing two tables given knowledge
of a common ancestor) use daff.compareTables3 (give ancestor
table as the first argument).
Here is how to apply that difference as a patch:
var patcher = new daff.HighlightPatch(table1,table_diff);
patcher.apply();
// table1 should now equal table2For other languages, you should find sample code in the packages on the Releases page.
The daff library is written in Haxe, which
can be translated reasonably well into at least the following languages:
- Javascript
- Python
- Java
- C#
- C++
- Ruby (using an unofficial haxe target developed for
daff) - PHP
Some translations are done for you on the
Releases page.
To make another translation, or to compile from source
first follow the Haxe language introduction for the
language you care about. At the time of writing, if you are on OSX, you should
install haxe using brew install haxe. Then do one of:
make js
make php
make py
make java
make cs
make cpp
For each language, the daff library expects to be handed an interface to tables you create, rather than creating them
itself. This is to avoid inefficient copies from one format to another. You'll find a SimpleTable class you can use if
you find this awkward.
Other possibilities:
- There's a daff wrapper for R written by Edwin de Jonge, see https://github.com/edwindj/daff and http://cran.r-project.org/web/packages/daff
- There's a hand-written ruby port by James Smith, see https://github.com/theodi/coopy-ruby
- You can browse the
daffclasses at http://paulfitz.github.io/daff-doc/

- https://specs.frictionlessdata.io/tabular-diff : a specification of the diff format we use.
- http://theodi.org/blog/csvhub-github-diffs-for-csv-files : using this library with github.
- ropensci/unconf15#19 : a thread about diffing data in which daff shows up in at least four guises (see if you can spot them all).
- http://theodi.org/blog/adapting-git-simple-data : using this library with gitlab.
- http://okfnlabs.org/blog/2013/08/08/diffing-and-patching-data.html : a summary of where the library came from.
- http://blog.okfn.org/2013/07/02/git-and-github-for-data/ : a post about storing small data in git/github.
- http://blog.ouseful.info/2013/08/27/diff-or-chop-github-csv-data-files-and-openrefine/ : counterpoint - a post discussing tracked-changes rather than diffs.
- http://blog.byronjsmith.com/makefile-shortcuts.html : a tutorial on using
makefor data, with daff in the mix. "Since git considers changes on a per-line basis, looking at diffs of comma-delimited and tab-delimited files can get obnoxious. The program daff fixes this problem."
daff is distributed under the MIT License.




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")







































































































































