輕量化、無後端的自建部落格系統。盡可能地提供舒適的寫作與閱讀體驗。
Home Page: https://blog.philip-huang.tech








https://blog.philip-huang.tech/?page=label-studio
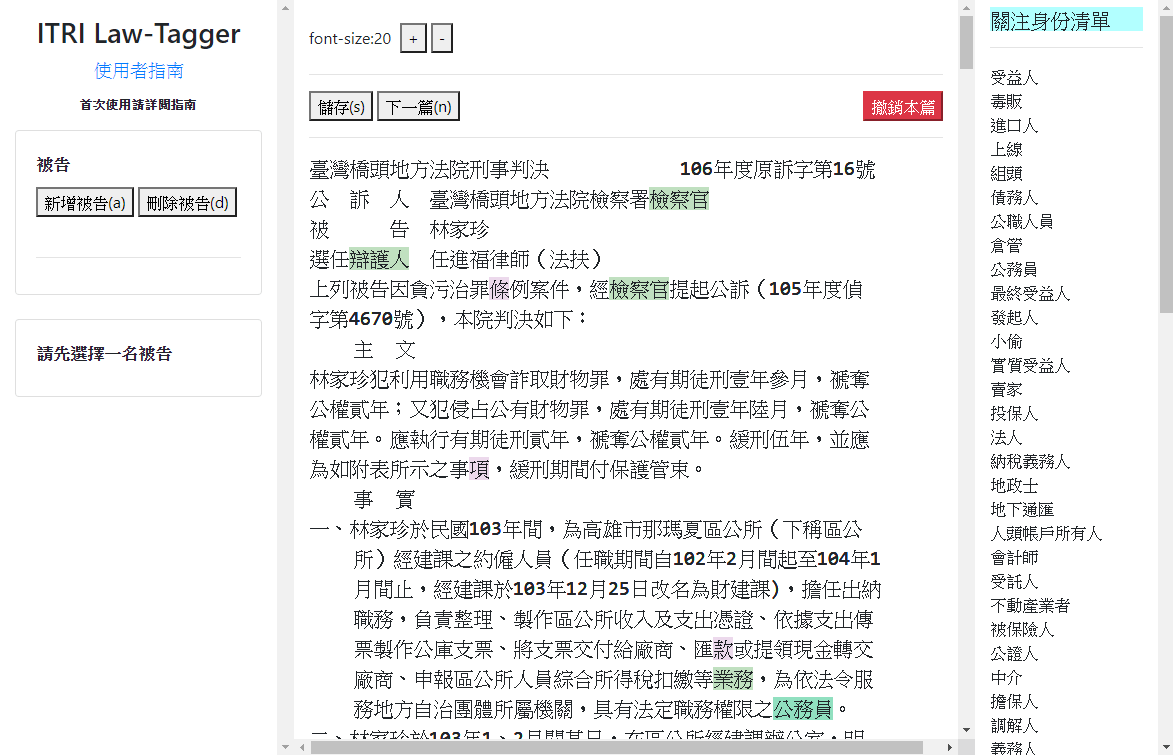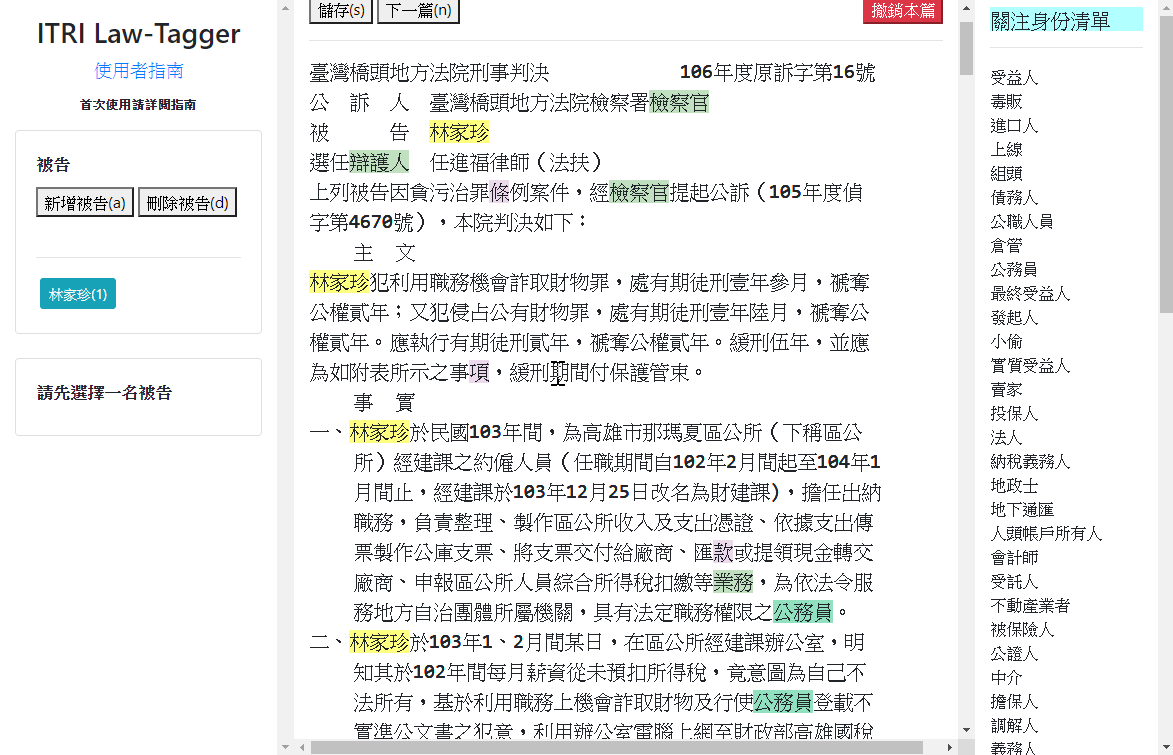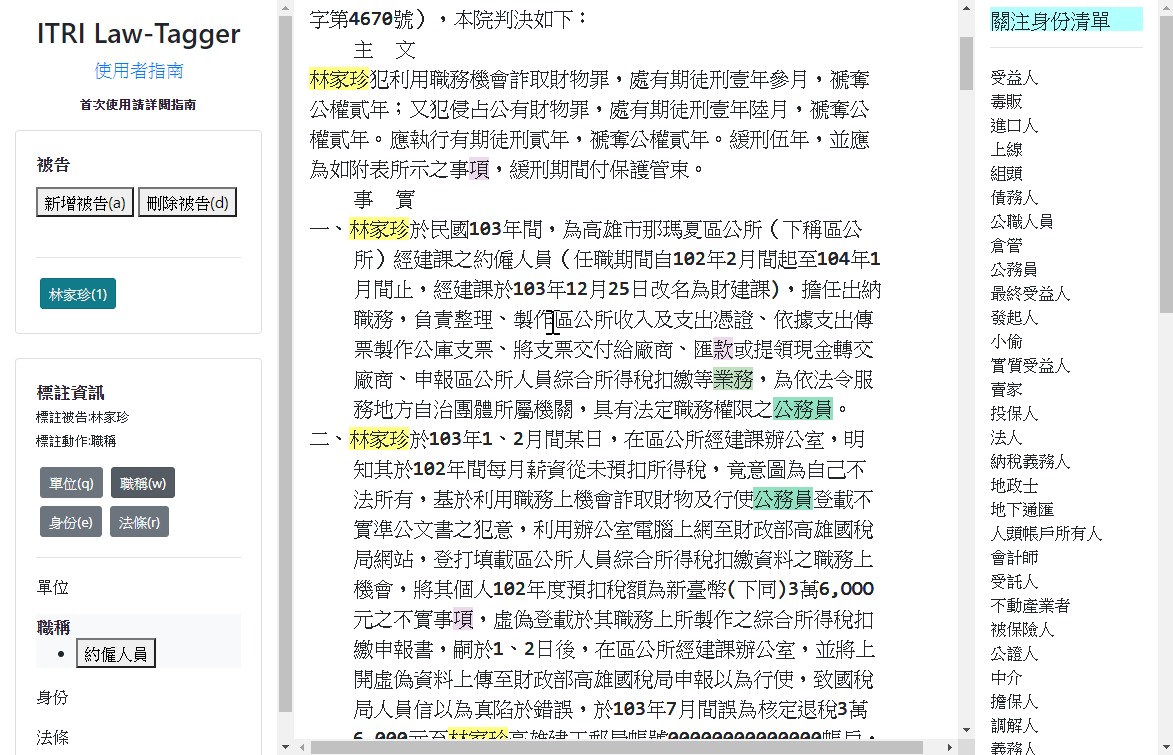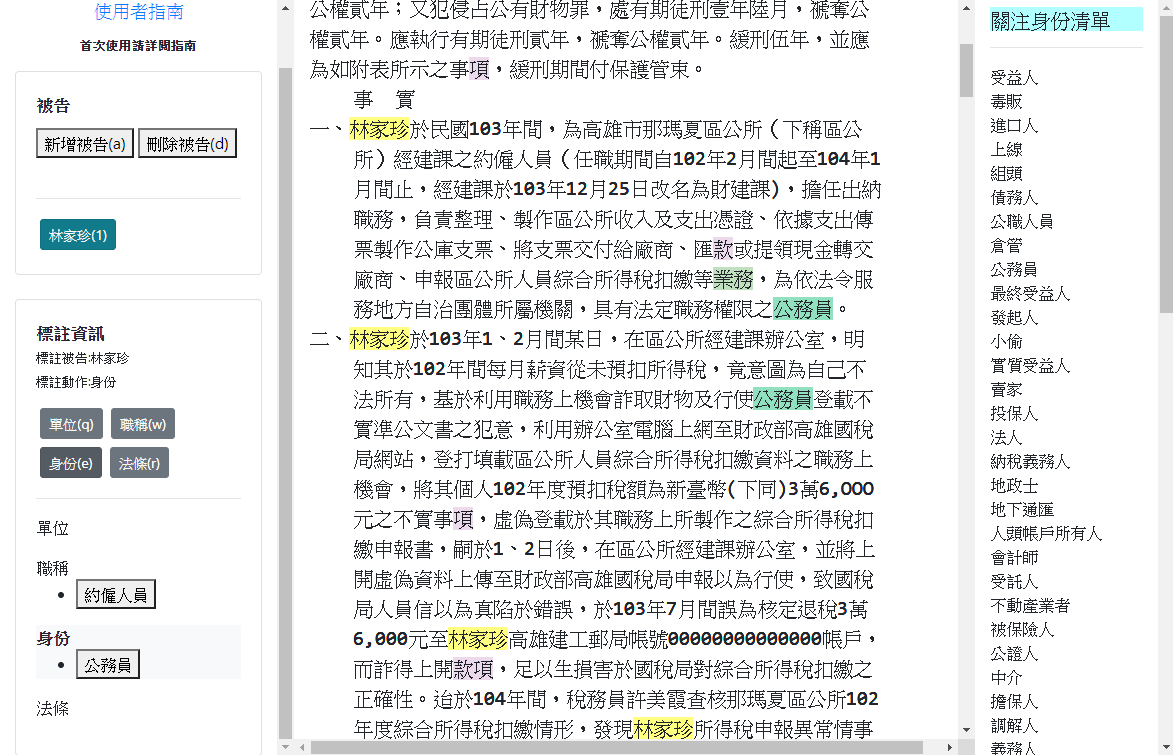
- tags: label-studo 資料標記 - date: 2023/02/04前陣子逛GitHub的時候偶然發現一個非常強大的資料標記工具 - Label Studio,號稱支援標記各式的資料類型
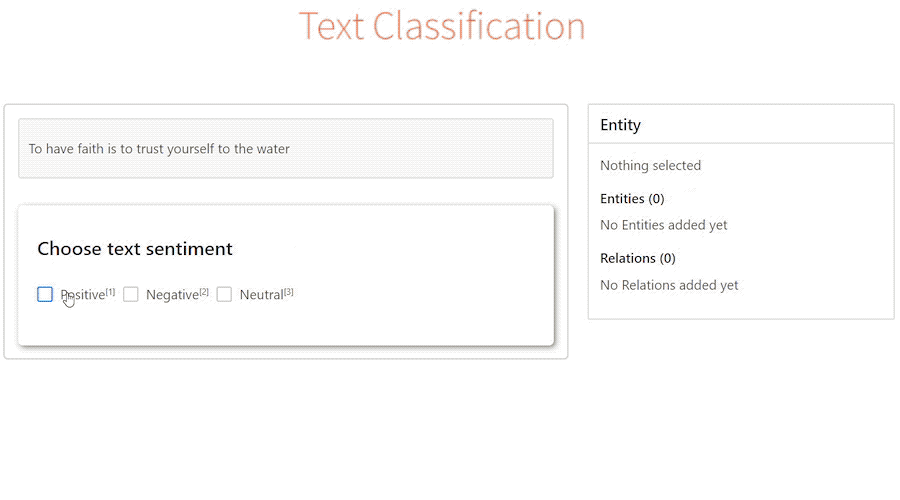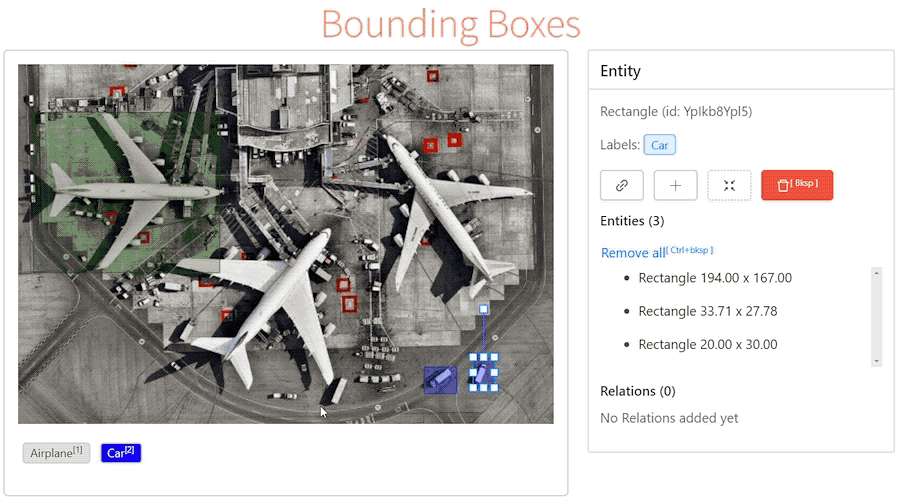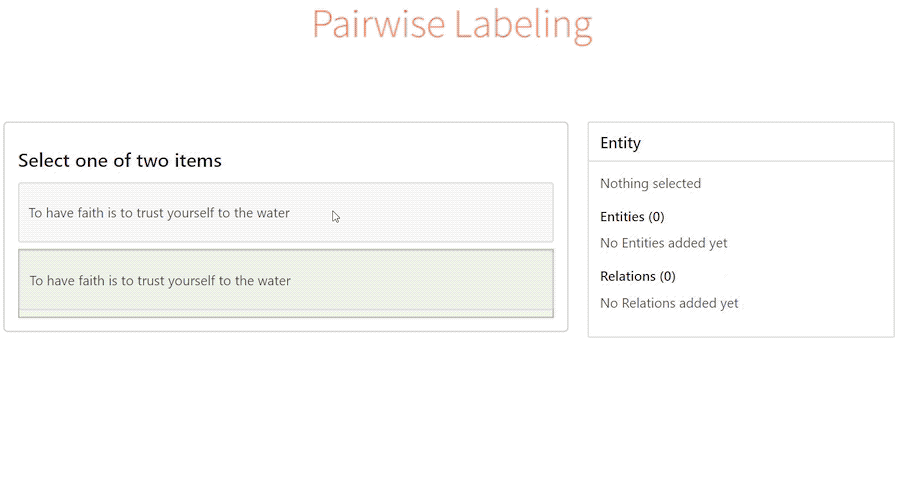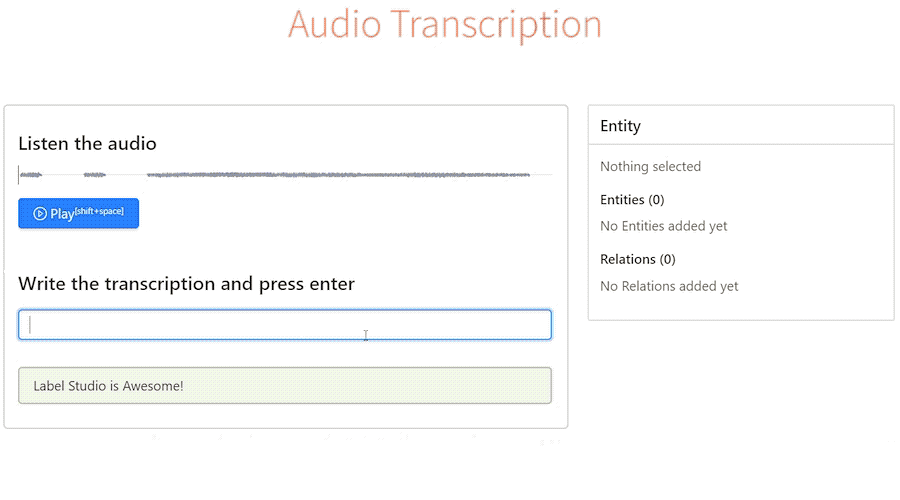
讓我想到之前實習的時候也曾經為了標注文字資料特別開發了一款標註工具
由於使用的資料需要儲存答案在文本中的位置(index),需要在標註工具上下點花點功夫才能讓標註者使用;畢竟讓人來計算答案位置實在太殘忍😆
當時還有一個想法是想要作成通用的文字標記工具,但最後因為技術與時間上的限制而作罷,只為了特定任務而設計:
https://blog.philip-huang.tech/?page=best-tools-at-2022
- tags: tools Tailwindcss Mobx Gradio Poetry Pytorch-Lightning - date: 2022/12/08Tailwindcss
一個非常靈活的css框架,過往我都使用 Bootstrap 較多,不過 Bootstrap 的美術風格比較不討我喜歡,雖較好上手但在小地方感覺不夠靈活。相比 tailwindcss 大量對css常用的屬性與設定進行封裝,在設計元件的時候就無須來回切換html與css非常能夠保持高校專注。缺點大概就是元件的class可讀性變差,但由於我多數時候配合使用 React 使用所以這點影響不大。
Mobx
React 很強大也很好用,除了元件資料共享:<。之前使用都使用 redux 作為狀態管理,但每一次設定都痛苦一次,然後回想使用方法再痛苦第二次,編寫模板痛苦第三次,實在是受不了啦。Mobx 簡單、直覺和
https://blog.philip-huang.tech/?page=az-multi-node-training
- tags: gpu-cluster multi-node-training LLM model-training - date: 2024/02/15LLM訓練非常吃資源,單節點多卡的配置還是會常常遇到算力或記憶體不足的問題。
GPU Cluster 使用上會涉及到許多額外的設定,並且通常會搭配排程系統、容器技術一起使用。
本篇簡單紀錄使用 Azure 平台進行多節點訓練的設定與流程。
重點環境:
ubuntu: 20.04
cuda: 12.2.2
python: 3.8
torch: 2.1.0
lightning: 2.1.4
deepspeed: 0.13.2
前置準備
建立 GPU Cluster
位置:ML Studio>管理>計算>計算叢集
可以設置最大節點與最小閒置節點(最小可以=0),閒置時不收費。
GPU叢集會根據任務需要自動拓展。
https://blog.philip-huang.tech/?page=peft-overview
- tags: peft overview LLM fine-tune LoRA Adapter - date: 2023/12/15語言模型(LM)技術已經實現一些重大突破,使得模型的規模更加龐大。然而,對大部份的人說,要微調如此巨大的模型所需的門檻太高。Parameter-efficient fine-tuning(PEFT)提供了一種新的訓練方法,即通過訓練一小組參數,使微調門檻降低,並且讓模型能夠適應和執行新的任務。
LM fine-tuning 演進
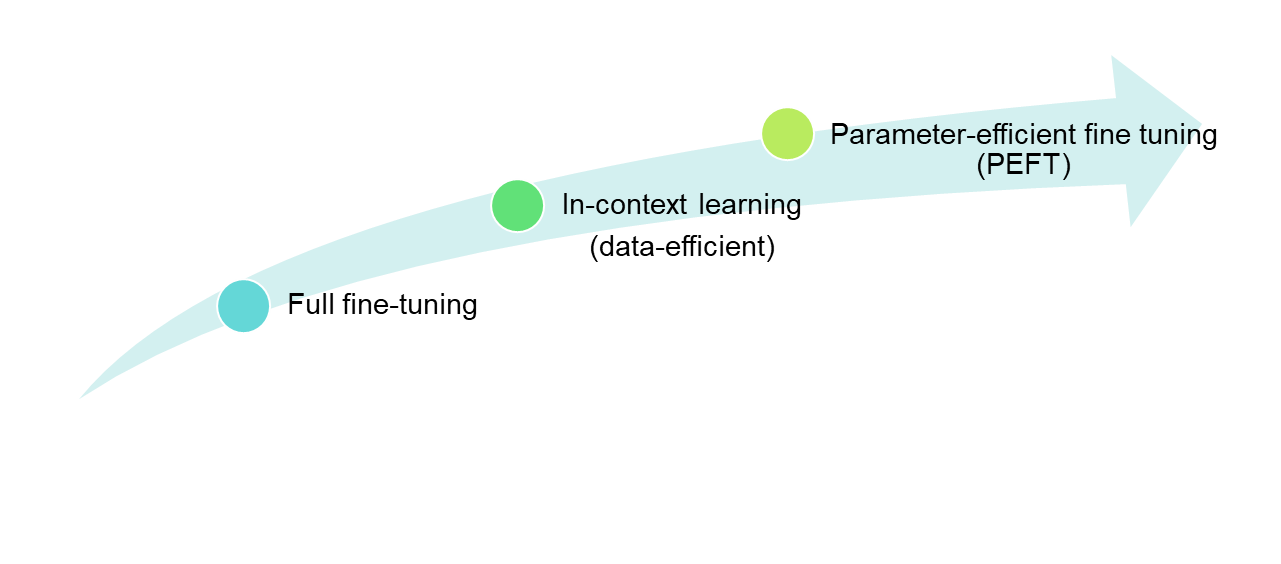
Full fine-tuning
Transformer 架構模型剛推出時(BERT,GPT, etc.),普遍模型大小落在500M~700M左右,這時候高端的消費級顯卡可以負擔微調所需的硬體門檻。
In-Context learni
https://blog.philip-huang.tech/?page=elasticsearch-chinese-search-optimize
- tags: Elasticserach 中文搜尋優化 簡繁轉換 同義詞 中文分詞 - date: 2022/07/28中文與英文的不同
中文與英文的結構不同,英文會使用空白分隔單字,但是中文卻是全部黏在一起
比如說 these is and apple 在預設的analyzer會被分割成
POST _analyze
{
"analyzer": "standard",
"text":"there is an apple"
}
而中文 那裡有一顆蘋果 則會被依照每一個字切開
POST _analyze
{
"analyzer": "standard",
"texthttps://blog.philip-huang.tech/?page=custom_bart_model
- tags: bart bert transformer-model pytorch nlp huggingface custom-transformer-model - date: 2022/08/10預訓練語言模型 Transformer Language Model (TLM) 非常強大,卻因為架構複雜而難以修改*1,今天示範如何在 BART Model 增加新的 Embedding Layer。
BART 是一個 Transformer Encoder-Decoder 架構模型。
*1 要適應下游任務僅須抽換最後一層 Linear Layer,這件事情非常容易達成,本次討論是如何增加新的輸入特徵
BERT Embedding 的實現
首先間借用一下經典的 BERT 輸入表示圖
BERT 是一個 Transformer Encoder 架構模型,與BART有所區別請注意不要混淆。
https://blog.philip-huang.tech/?page=IA3
- tags: 論文筆記 PEFT IA3 - date: 2023/12/05論文連結: Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
摘要
少樣本情境學習(ICL)使預先訓練的語言模型能夠在沒有基於梯度的訓練的情況下執行以前未見的任務,方法是將少量的訓練示例作為輸入的一部分。ICL 產生相當大的計算、記憶體和存儲成本,因為它涉及在每次進行預測時處理所有的訓練示例。參數高效微調(PEFT)(例如適配器模塊、提示微調、稀疏更新方法等)提供了一種替代範式,其中訓練一小組參數以使模型能夠執行新任務。
雖然 PEFT 的優勢解決了微調相對於 ICL 的一些不足,但相對於極少標記數據的情況下,對於 PEFT 方法是否能夠很好地工作,目前相對較少的關注。本文的主要目標是通過提出一種配方(即模型、PEFT
https://blog.philip-huang.tech/?page=blog_bart-model_nlp
- tags: bart-model nlp - date: 2020/01/01Import
! pip install transformers==4.5.1from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import torchtokenizer = AutoTokenizer.from_pretrained('facebook/bart-base')
model = AutoModelForSeq2SeqLM.from_pretrained('facebook/bart-base')Prepare data
context = 'Harry Potter is a series of'
label = 'seven fantasy novels' + tokenizer.eos_token
`https://blog.philip-huang.tech/?page=blog-update-230116
- tags: webassembley pyodide blog-update - date: 2023/01/16能夠直接在範例程式下方直接測試是一件很酷的事情
但是要達項功能,通常需要有一個後端來支持,除了安全性需要考慮外,對於像我這種Serverless類型的部落格或網頁可能就遺憾了。
不過現在可以藉由WebAssembly技術來達到在瀏覽器中運行Javasctipt以外的語言,例如下面是一段 Python script
WebAssembly或稱wasm是一個低階程式語言。WebAssembly是可攜式的抽象語法樹,被設計來提供比JavaScript更快速的編譯及執行。WebAssembly將讓開發者能運用自己熟悉的程式語言編譯,再藉虛擬機器引擎在瀏覽器內執行 - wikipedia.org
import sys
sys.version點選程式碼區塊
https://blog.philip-huang.tech/?page=1-bit_Adam
- tags: 論文筆記 1-bit Adam - date: 2023/05/24論文連結: https://arxiv.org/abs/2102.02888
從系統的角度來看,通信已成為主要瓶頸。1-bit Adam,最多可將通信量減少 5 倍,提供更好的可擴展性,並提供與未壓縮 Adam 相同的樣本收斂速度。
作者的主要發現是 Adam 的 variance(非線性項)在訓練期間變得穩定,因此我們可以在開始時(預熱階段)運行 Adam,並在其餘訓練(壓縮階段)中將其用作動量 SGD 的先決條件。
作者首先基於基於壓縮和誤差補償的的 SGD 方法為 Adam 實施了基本壓縮策略,並發現該方法在 Adam 上有效但是無法達到與原本 Adam 相同效果。
作者通過預熱階段找到穩定的 variance
最後實驗在多達 256 個 GPU 上進行的實驗表明,1-bit Adam 使 BERT-Large 預訓練的吞吐量提高了 3.3
https://blog.philip-huang.tech/?page=fill-in-middle
- tags: 論文筆記 FIM LM 預訓練 - date: 2023/12/13論文連結: https://arxiv.org/abs/2207.14255.pdf
Autoregressive (AR) 語言模型可以通過簡單的方式學習填充文字;作者簡單的將文章中間的段落移動到結尾來讓模型學習文字填充。
作者提供了大量的證據,表明以這種方式轉換了大部分數據的模型不會損害原始的從左到右生成能力,這主要是通過衡量困惑度和抽樣評估確認的。
Fill-in-the-middle(FIM)訓練模型的實用性、簡單性和效率,作者建議未來的 AR 語言模型應搭配FIM進行訓練。
LM架構差異
依照模型架構不同,模型在生成任務能捕捉的資訊會不一樣,這點可能會讓模型在執行任務時有不同的性能表現:
Encoder-decoder model 可以同時捕捉 prefix 和 suffix 來進行任務。
Left-to right models 只能使用 prefix 資訊進行任務。
重點貢獻
https://blog.philip-huang.tech/?page=chat-template
- tags: chat-template transformers LLM chat-model - date: 2023/12/19新版本的 transformers 已經增加 tokenizer.chat_template 屬性,有了這個 chat_template ,能確保我們在使用或訓練時遵循模型的需要的模板。
許多第三方的部屬框架 (如: vllm, openllm) 也已經開始支援這個屬性,但如果沒有設置 .chat_template 則會使用 .default_chat_template ,需要特別注意。
https://blog.philip-huang.tech/?page=blog_gpt_gpt2_nlp
Import
- tags: gpt gpt2 - date: 2020/01/01! pip install transformers==4.5.1from transformers import AutoModelWithLMHead,AutoTokenizer
import torchInit
model = AutoModelWithLMHead.from_pretrained('gpt2')
tokenizer = AutoTokenizer.from_pretrained('gpt2')
tokenizer.add_special_tokens({'pad_token': '[PAD]'})/user_data/.local/lib/python3.6/site-packages/transformers/models/auto/modeling_auto.py:970: Fu
https://blog.philip-huang.tech/?page=bpe-tokenization
- tags: 論文筆記 gpt2 bpe tokenizer tokenization - date: 2023/09/6論文連結: https://arxiv.org/abs/1508.07909
神經機器翻譯(NMT)模型通常使用固定的詞彙表,但翻譯是一個開放詞彙的問題。
先前的研究解決了 out-of-vocabulary(OOV)的單詞的翻譯問題,通常通過 back-off dictionary 來解決。在本文中,我們介紹了一種更簡單且更有效的方法,使NMT模型能夠通過將罕見和未知單詞編碼為 subwords 來進行開放詞彙的翻譯。這是基於一種直覺,即各種詞類可以通過比詞彙更小的單位進行翻譯。
我們討論了不同的詞彙分割技術的適用性,包括簡單的字符n-gram模型和基於字節對編碼壓縮算法的分割,並根據實驗結果顯示,subword model 在 WMT 15 的翻譯任務中相對於 baseline 分別提高了1.1和1.3個BLEU分數。
論文核心問題
Can we improve the
https://blog.philip-huang.tech/?page=blog_pytorch-lightning_pytorch
- tags: blog pytorch-lightning pytorch - date: 2021/06/20最近做DL實驗發現除了主要研究的核心,最花心力的就是維護的你training pipline
從資料處理、訓練、預測與算分到加入中斷點恢復,各種超參數與模型版本管理。
如果要一直驗證與處理這些問題,實在是很力不從心,好在大家都有同樣的困擾,於是PL出現了,根據官方說法
PyTorch Lightning is just organized PyTorch
You do the research. Lightning will do everything else.
就是這麼簡單!不過要體會第二點,我自己覺得是還有段距離,除了對框架本身要熟悉,目前PL也沒有到非常穩定(1.2.x),存在一些小BUG
基本上只要理解PL三大模組,就可以很快上手了,接下來看看我如何在我最近的研究案-QG(Question Generation)中使用PL
DataModule 從資料開始
對於使用p
https://blog.philip-huang.tech/?page=blog_nlp_pytorch_self-attention
- tags: nlp pytorch self-attention - date: 2021/03/24輸入準備
我們準備了兩個句子來進行這次實驗
sentences = ['helo attention','have a nice day']一開始先建立詞表與對應的單詞one-hot encoding
vocabs = ' '.join(sentences).split()
vocabs = list(set(vocabs))
one_hots = []
vocab_dict = {}
for i,vocab in enumerate(vocabs):
one_hots.append([0]*len(vocabs))
one_hots[i][i]=1
for i,(vocab,one_hot) in enumerate(zip(vocabs,one_hots)):
vocab_dict[vocab] = one_hot
prihttps://blog.philip-huang.tech/?page=blog_dockerfile_gh-action_ssh_pip-install-private
- tags: dockerfile gh-action ssh pip-install-private - date: 2021/10/6對Python有進階認識的可能會知道可以直接從github repo安裝套件,對public repo可以這樣做
pip install git+https://github.com/USERNAME/REPO.git那如果是一個private repo呢?這時候我們就必須使用ssh來進行身份認證
pip install [email protected]/username/private_repo.git本機環境操作
直接使用上面的指令會發生permission denied;我們需要先產生一組ssh-key,並且添加到GitHub帳號中
https://docs.github.com/en/github/authenticating-to-github/connecting-to-github-with-ssh/
https://blog.philip-huang.tech/?page=fast-api-gpu-inference
- tags: gpu fast-api inference optimize - date: 2023/09/12GPU 推論是計算密集型任務,一個推論往往是秒鐘起跳,而 Fast API 對多個請求的處理主要是基於異步(async),其本質是線程(threading),也就是說在 Fast API 中直接執行推論任務會卡住其他請求。
這時可以使用多進程處理(multi-processing)將推論任務丟到子進程中,這邊會有兩點需要注意:
由於pytorch的限制,建立子進程的方法無法使用預設的fork需要使用spawn。
為了避免 GPU OOM (out of memory) 需要使用一個全域的進程池,用來限制同時推論任務的最大處理數量。
實踐
以下是一段使用 Fast API+GPT2 做推論的最小化例子。
main.py
import asyncio
import concurrent.futures
from fastapi import https://blog.philip-huang.tech/?page=iterable-style-dataset-worker-setting
iterable-style dataset 可以處理巨量訓練資料迭代,但是當使用多個 worker 時,每個 worker 都會有一份相同的資料集副本,PyTorch 需要開發者自己去實現邏輯避免 worker 拿到重複資料。
資料通常是一個 generator 物件,所以就算多個 worker 手上都有一份副本也不會佔用許多記憶體。
根據 PyTorch 官方建議,我們可以使用 torch.utils.data.get_worker_info() 進行 worker 配置達到目的。
For iterable-style datasets, since each worker process gets a replica of the dataset object, naive multi-process loading will often result in duplicated data. Using torch.utils.data.get_worker_info() and/or worker_init_fn, users may configure
https://blog.philip-huang.tech/?page=blog_python3_uni2word_word2uni
- tags: blog python3 uni2word word2uni - date: 2022/07/01word2unicode
文字轉unicode較為簡單,用ord(x)即可
import re
def word2unicode(x):
uni = hex(ord(x))
uni = re.sub("^0x", "", uni).upper()
return uni
word2unicode("字") 5B57uni2word
我們在python shell中輸入unicode;python會直接幫我們進行轉換
>>> '\u5B57' 字但是若想使用變數組合將文字型態的unicode轉換為文字,如'\u' + var的方式
>>> uni_str = '5B57'
>>> word = '\u' + uni_str
File "<stdin>", line 1
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.