![]()

- Introduction
- Downloading Coherence Community Edition
- Coherence Overview
- Getting Started
- Building
- Documentation
- Examples
- Contributing
- License
Coherence is a scalable, fault-tolerant, cloud-ready, distributed platform for building grid-based applications and reliably storing data. The product is used at scale, for both compute and raw storage, in a vast array of industries such as critical financial trading systems, high performance telecommunication products and eCommerce applications.
Typically these deployments do not tolerate any downtime and Coherence is chosen due to its novel features in death detection, application data evolvability, and the robust, battle-hardened core of the product that enables it to be seamlessly deployed and adapted within any ecosystem.
At a high level, Coherence provides an implementation of the familiar Map<K,V>
interface but rather than storing the associated data in the local process it is partitioned
(or sharded) across a number of designated remote nodes. This partitioning enables
applications to not only distribute (and therefore scale) their storage across multiple
processes, machines, racks, and data centers but also to perform grid-based processing
to truly harness the CPU resources of the machines.
The Coherence interface NamedMap<K,V> (an extension of Map<K,V>) provides methods
to query, aggregate (map/reduce style) and compute (send functions to storage nodes
for locally executed mutations) the data set. These capabilities, in addition to
numerous other features, enable Coherence to be used as a framework for writing robust,
distributed applications.
As Coherence is generally embedded into an application by using Coherence APIs, the natural place to consume this dependency is from Maven:
<dependencies>
<dependency>
<groupId>com.oracle.coherence.ce</groupId>
<artifactId>coherence</artifactId>
<version>22.06.7</version>
</dependency>
</dependencies>You can also get Coherence container images from the official GitHub Packages site. For other language clients, follow the links to C++, .NET, JavaScript, Go and Python. For commercial offerings, go to Oracle Technology Network.
First and foremost, Coherence provides a fundamental service that is responsible for all facets of clustering and is a common denominator / building block for all other Coherence services. This service, referred to as 'service 0' internally, ensures that the mesh of members is maintained and responsive, taking action to collaboratively evict, shun, or in some cases, voluntarily depart the cluster when deemed necessary. As members join and leave the cluster, other Coherence services are notified, thus enabling those services to react accordingly.
Note: This part of the Coherence product has been in production for more that 10 years, being the subject of some extensive and imaginative testing. While this feature has been discussed here, it certainly is not something that customers, generally, interact with directly, but is important to be aware of.
Coherence services build on top of the cluster service. The key implementations to be aware of are PartitionedService, InvocationService, and ProxyService.
In the majority of cases, customers deal with maps. A map is represented
by an implementation of NamedMap<K,V>. A NamedMap is hosted by a service,
generally the PartitionedService, and is the entry point to store, retrieve,
aggregate, query, and stream data.
Coherence Maps provide a number of features:
- Fundamental key-based access: get/put getAll/putAll.
- Client-side and storage-side events:
- MapListeners to asynchronously notify clients of changes to data.
- EventInterceptors (either sync or async) to be notified storage level events, including mutations, partition transfer, failover, and so on.
- NearCaches - Locally cached data based on previous requests with local content invalidated upon changes in the storage tier.
- ViewCaches - Locally stored view of remote data that can be a subset based on a predicate and is kept in sync, real time.
- Queries - Distributed, parallel query evaluation to return matching key, values, or entries with potential to optimize performance with indices.
- Aggregations - A map/reduce style aggregation where data is aggregated in parallel on all storage nodes, and results streamed back to the client for aggregation of those results to produce a final result.
- Data local processing - Ability to send a function to the relevant storage node to execute processing logic for the appropriate entries with exclusive access.
- Partition local transactions - Ability to perform scalable transactions by associating data (thus being on the same partition) and manipulating other entries on the same partition, potentially across different maps.
- Non-blocking / async NamedMap API
- C++ and .NET clients - Access the same NamedMap API from either C++ or .NET.
- Portable Object Format - Optimized serialization format, with the ability to navigate the serialized form for optimized queries, aggregations, or data processing.
- Integration with Databases - Database and third party data integration with CacheStores, including both synchronous or asynchronous writes.
- CohQL - Ansi-style query language with a console for adhoc queries.
- Topics - Distributed topics implementation that offers pub/sub messaging with the storage capacity, the cluster, and parallelizable subscribers.
Coherence also provides a number of non-functional features:
- Rock solid clustering - Highly tuned and robust clustering stack that enables Coherence to scale to thousands of members in a cluster with thousands of partitions and terabytes of data being accessed, mutated, queried, and aggregated concurrently.
- Safety first - Resilient data management that ensures backup copies are on distinct machines, racks, or sites, and the ability to maintain multiple backups.
- 24/7 Availability - Zero downtime with rolling redeployment of cluster members
to upgrade application or product versions.
- Backward and forward compatibility of product upgrades, including major versions.
- Persistent Maps - Ability to use local file system persistence (thus avoid extra network hops) and leverage Coherence consensus protocols to perform distributed disk recovery when appropriate.
- Distributed State Snapshot - Ability to perform distributed point-in-time snapshot of cluster state, and recover snapshot in this or a different cluster (leverages persistence feature).
- Lossy redundancy - Ability to reduce the redundancy guarantee by making backups and/or persistence asynchronous from a client perspective.
- Single Mangement View - Provides insight into the cluster with a single JMX server that provides a view of all members of the cluster.
- Management over REST - All JMX data and operations can be performed over REST, including cluster wide thread dumps and heapdumps.
- Non-cluster Access - Provides access to the cluster from the outside via proxies, for distant (high latency) clients and for non-java languages such as C++ and .NET.
- Kubernetes friendly - Enables seamless and safe deployment of applications to k8s with our own operator.
You must have the following installed and available on your PATH.
- Java - JDK 17 or higher
- Maven - 3.8.5 or higher
- Cohrence CLI Installed (see below)
The following example shows you how to quickly get started with Coherence using the Coherence CLI to create a 3 node Coherence cluster scoped to you local machine. You will then access data using the CohQL and Coherence consoles.
For macOS or Linux platforms, use the following to install the latest version of the CLI:
curl -sL https://raw.githubusercontent.com/oracle/coherence-cli/main/scripts/install.sh | bashWhen you install the CLI, administrative privileges are required as the
cohctlexecutable is moved to the /usr/local/bin directory.
For Windows, see here for installation guide.
Use the following command to create a 3 node Coherence cluster called my-cluster, scoped to your local machine using the default of Coherence CE 22.06.7.
$ cohctl create cluster my-cluster
Cluster name: my-cluster
Cluster version: 22.06.7
Cluster port: 7574
Management port: 30000
Replica count: 3
Initial memory: 128m
Persistence mode: on-demand
Group ID: com.oracle.coherence.ce
Additional artifacts:
Startup Profile:
Dependency Tool: mvn
Are you sure you want to create the cluster with the above details? (y/n) y
Checking 3 Maven dependencies...
- com.oracle.coherence.ce:coherence:22.06.7
- com.oracle.coherence.ce:coherence-json:22.06.7
- org.jline:jline:3.20.0
Starting 3 cluster members for cluster my-cluster
Starting cluster member storage-0...
Starting cluster member storage-1...
Starting cluster member storage-2...
Current context is now my-cluster
Cluster added and startedNote: If you do not have the Maven artefacts locally, it may take a short while to download them from Maven central.
Once the cluster is created, wait it a couple of seconds, and use the following command to see the members.
$ cohctl get members
Using cluster connection 'my-cluster' from current context.
Total cluster members: 3
Cluster Heap - Total: 384 MB Used: 114 MB Available: 270 MB (70.3%)
Storage Heap - Total: 128 MB Used: 16 MB Available: 112 MB (87.5%)
NODE ID ADDRESS PORT PROCESS MEMBER ROLE STORAGE MAX HEAP USED HEAP AVAIL HEAP
1 /127.0.0.1 55654 58270 storage-1 CoherenceServer true 128 MB 16 MB 112 MB
2 /127.0.0.1 55655 58271 storage-2 CoherenceServer true 128 MB 74 MB 54 MB
3 /127.0.0.1 55656 58269 storage-0 CoherenceServer true 128 MB 24 MB 104 MBNote: If you do not see the above, then ensure the java executable is on your PATH, you are using JDK17, and then issue cohctl start cluster my-cluster to start the cluster.
Start the CohQL Console using the CLI, and run the statements at the CohQL> prompt to insert data into your cache.
$ cohctl start cohql
CohQL> select * from welcomes
CohQL> insert into welcomes key 'english' value 'Hello'
CohQL> insert into welcomes key 'spanish' value 'Hola'
CohQL> insert into welcomes key 'french' value 'Bonjour'
CohQL> select key(), value() from welcomes
Results
["french", "Bonjour"]
["english", "Hello"]
["spanish", "Hola"]
CohQL> bye
# Restart to CohQL to show that the data is still present in the Coherence cluster.
$ cohctl start cohql
CohQL> select key(), value() from welcomes
Results
["french", "Bonjour"]
["english", "Hello"]
["spanish", "Hola"]
CohQL> byeUse the following command to start the Coherence console, which is a different way to interact with the data in a Cache.
$ cohctl start console
Map (?): cache welcomes
Map (welcomes): get english
Hello
Map (welcomes): list
french = Bonjour
spanish = Hola
english = Hello
Map (welcomes): put australian Gudday
null
Map (welcomes): list
spanish = Hola
english = Hello
australian = Gudday
french = Bonjour
Map (welcomes): byeNote: Ensure you shutdown your Coherence cluster using the following:
cohctl stop cluster my-cluster
The following example illustrates starting a storage enabled Coherence server,
followed by running the HelloCoherence application. The HelloCoherence application
inserts and retrieves data from the Coherence server.
- Create a maven project either manually or by using an archetype such as maven-archetype-quickstart
- Add a dependency to the pom file:
<dependency>
<groupId>com.oracle.coherence.ce</groupId>
<artifactId>coherence</artifactId>
<version>22.06.7</version>
</dependency>- Copy and paste the following source to a file named src/main/java/HelloCoherence.java:
import com.tangosol.net.CacheFactory;
import com.tangosol.net.NamedMap;
public class HelloCoherence
{
// ----- static methods -------------------------------------------------
public static void main(String[] asArgs)
{
NamedMap<String, String> map = CacheFactory.getCache("welcomes");
System.out.printf("Accessing map \"%s\" containing %d entries\n",
map.getName(),
map.size());
map.put("english", "Hello");
map.put("spanish", "Hola");
map.put("french" , "Bonjour");
// list
map.entrySet().forEach(System.out::println);
}
}- Compile the maven project:
mvn package- Start a Storage Server
mvn exec:java -Dexec.mainClass="com.tangosol.net.DefaultCacheServer" &- Run
HelloCoherence
mvn exec:java -Dexec.mainClass="HelloCoherence"- Confirm you see output including the following:
Accessing map "welcomes" containing 3 entries
ConverterEntry{Key="french", Value="Bonjour"}
ConverterEntry{Key="spanish", Value="Hola"}
ConverterEntry{Key="english", Value="Hello"}- Kill the storage server started previously:
kill %1$> git clone [email protected]:oracle/coherence.git
$> cd coherence/prj
# build Coherence module
$> mvn clean install
# build Coherence module skipping tests
$> mvn clean install -DskipTests
# build all other modules skipping tests
$> mvn -Pmodules clean install -DskipTests
# build specific module, including all dependent modules and run tests
$> mvn -Pmodules -am -pl test/functional/persistence clean verify
# only build coherence.jar without running tests
$> mvn -am -pl coherence clean install -DskipTests
# only build coherence.jar and skip compilation of CDBs and tests
$> mvn -am -pl coherence clean install -DskipTests -Dtde.compile.not.requiredOracle Coherence product documentation is available here.
The following Oracle Coherence features are not included in Coherence Community Edition:
- Management of Coherence via the Oracle WebLogic Management Framework
- Deployment of Grid Archives (GARs)
- HTTP Session Management for Application Servers (Coherence*Web)
- GoldenGate HotCache
- TopLink-based CacheLoaders and CacheStores
- Elastic Data
- Federation and WAN (wide area network) Support
- Transaction Framework
- CommonJ Work Manager
Below is an overview of features supported in each Coherence edition for comparison purposes:
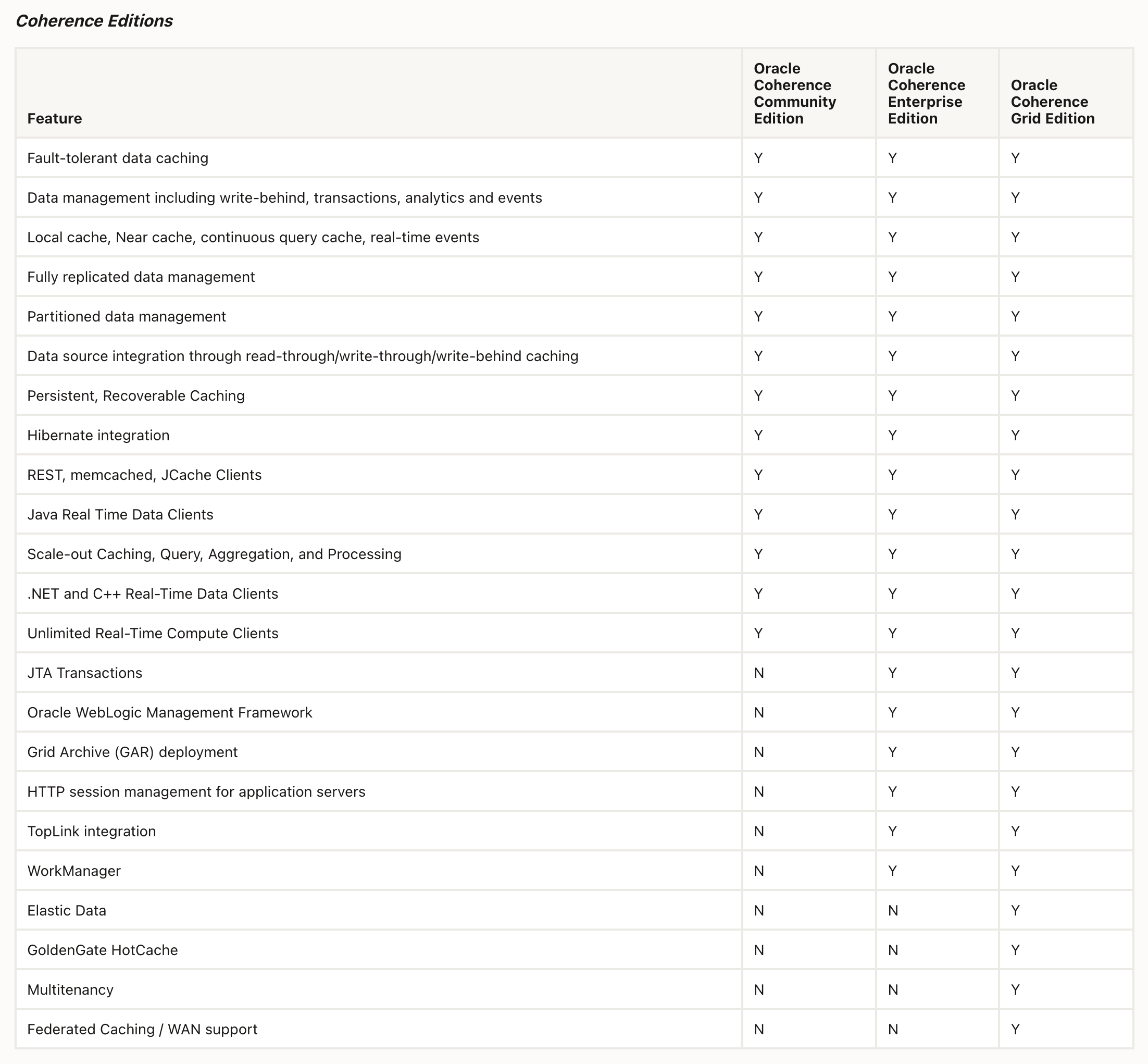
Please refer to Oracle Fusion Middleware Licensing Documentation for official documentation of Oracle Coherence commercial editions and licensing details.
Examples related to Coherence features are located under examples directory of this repository.
This project welcomes contributions from the community. Before submitting a pull request, please review our contribution guide
Please consult the security guide for our responsible security vulnerability disclosure process
Copyright (c) 2000, 2024 Oracle and/or its affiliates.
Released under the Universal Permissive License v1.0 as shown at https://oss.oracle.com/licenses/upl/.




























































































































