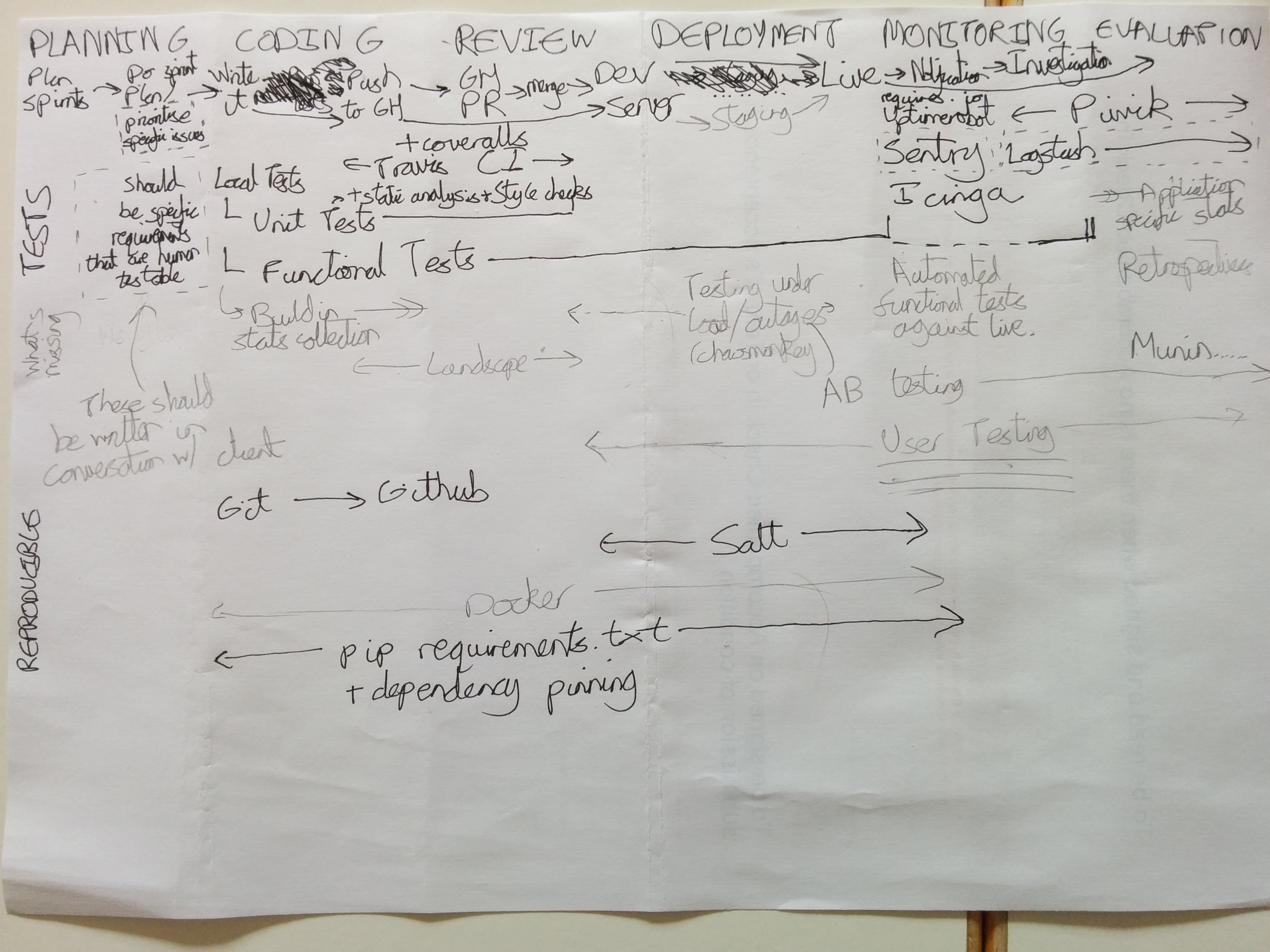
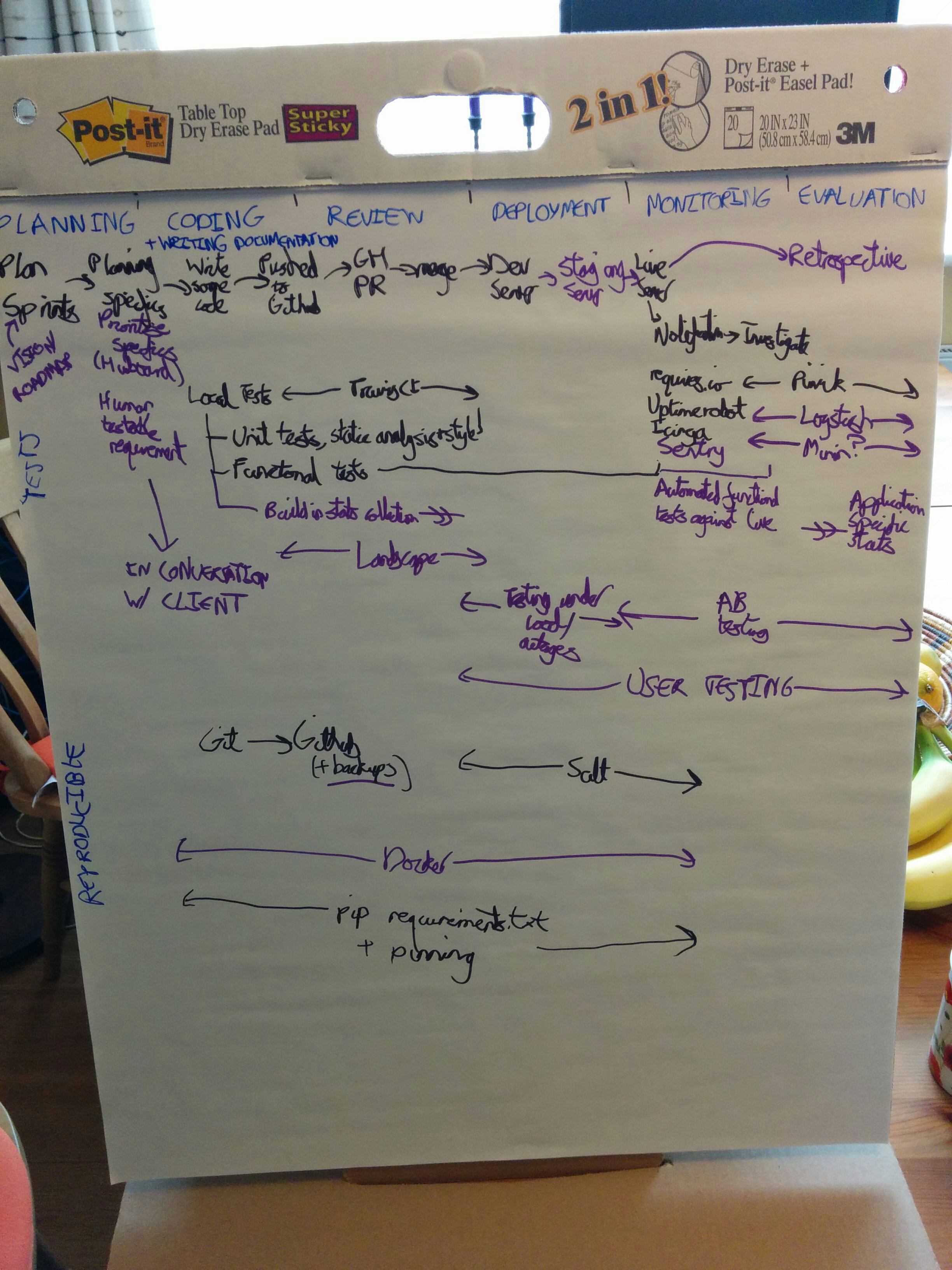
A repository of documentation about how we get our work done.
To read on GitHub (or locally), choose the files directly, or see the Table of Contents.
It's also available to read and download on GitBook at https://opendataservices.gitbook.io/developer-docs/
This is broken up into sections:
- How to guides - step by step guides on how to do certain tasks
- Reference - direct information on how we do our work
We try not to list basic instructions for common tools. Different developers will be at different levels for different tools, and in any case it's possible to look up these instructions online. Instead we list step by step guides for specific tasks we perform in a certain way at Open Data Services, and we make sure each how-to guide is focused on a specified user need. How to guides should be linked to relevant places in the reference, and vice versa.