



By using Tripadvisor Scraper, you agree to comply with all applicable local and international laws related to data scraping, copyright, and privacy. The developers of Tripadvisor Scraper will not be held liable for any misuse of this software. It is the user's sole responsibility to ensure adherence to all relevant laws regarding data scraping, copyright, and privacy, and to use Tripadvisor Scraper in an ethical and legal manner, in line with both local and international regulations.
We take concerns related to the Tripadvisor Scraper Project very seriously. If you have any inquiries or issues, please contact Chetan Jain at [email protected]. We will take prompt and necessary action in response to your emails.
- ✅ Botasaurus: The All-in-One Web Scraping Framework with Anti-Detection, Parallelization, Asynchronous, and Caching Superpowers.
Tripadvisor Scraper helps you scrape Tripadvisor Hotels and Restaurants. 🚀
-
Easily access Tripadvisor Hotels and Restaurants through our user-friendly dashboard.
-
Get 101% accurate, fresh results in realtime, allowing you to use the results to their full potential.
-
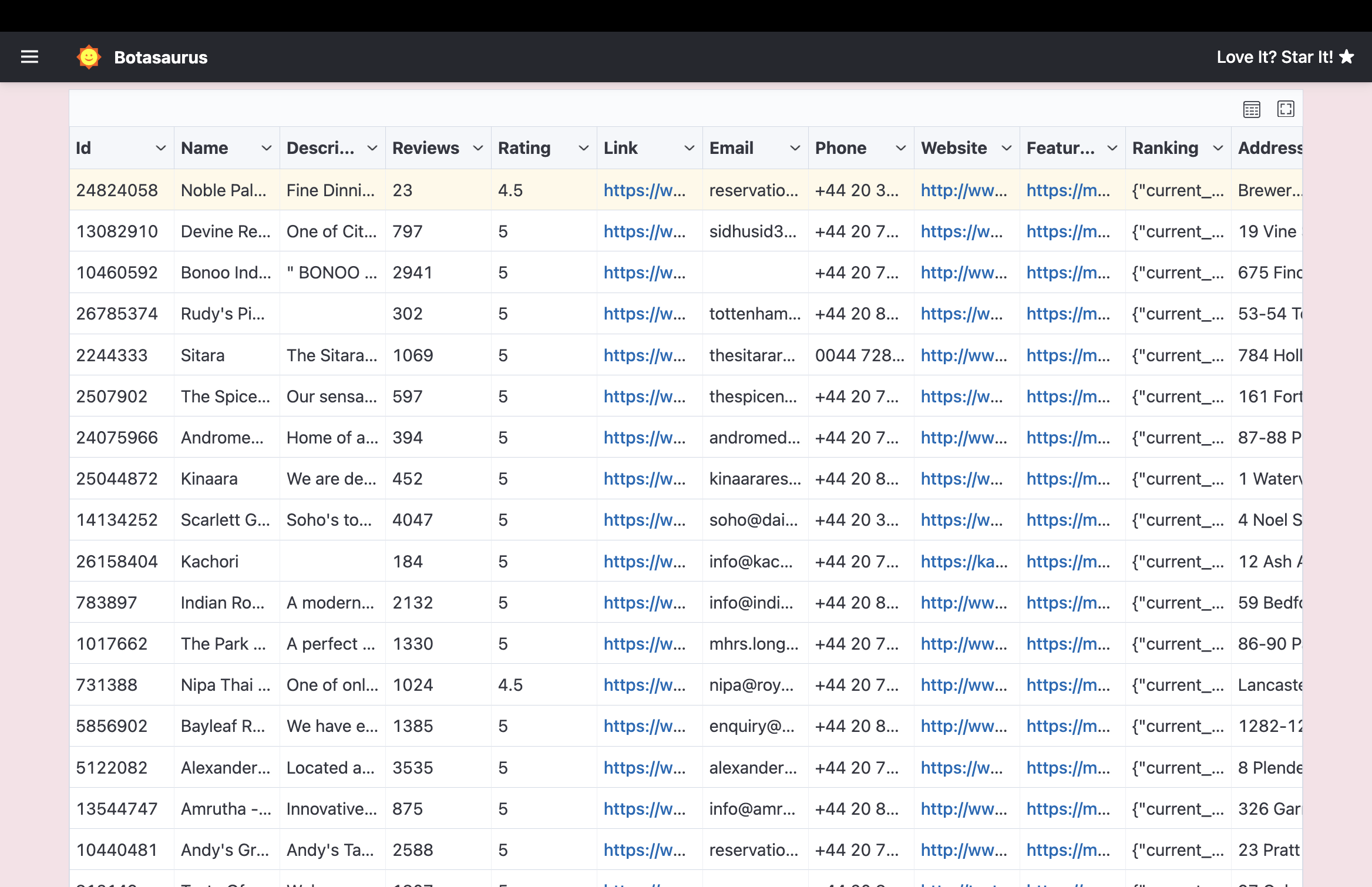
Get Website, Email, Phone, Address, and other details of Hotels and Restaurants.
In next 5 minutes, you'll extract New York Hotels's from Tripadvisor.
To use this tool, you'll need:
- Node.js version 16 or later to run the UI Dashboard (please check your Node.js version by running
node -v) - Python for running the scraper
Don't have Node.js or Python? No problem!
You can easily run this tool within Gitpod, a cloud-based development environment, by following these steps.
Let's get started by following these super simple steps:
1️⃣ Clone the Magic 🧙♀️:
git clone https://github.com/omkarcloud/tripadvisor-scraper
cd tripadvisor-scraper2️⃣ Install Dependencies 📦:
python -m pip install -r requirements.txt
python run.py install3️⃣ Launch the UI Dashboard 🚀:
python run.py4️⃣ Open your browser and go to http://localhost:3000, then press the Run button to see Tripadvisor Products. 😎
Note: If you don't have Node.js 16+ and Python installed or you are facing errors, follow this Simple FAQ here, and you will have your search results in the next 5 Minutes
- Visit http://localhost:3000 and enter your queries
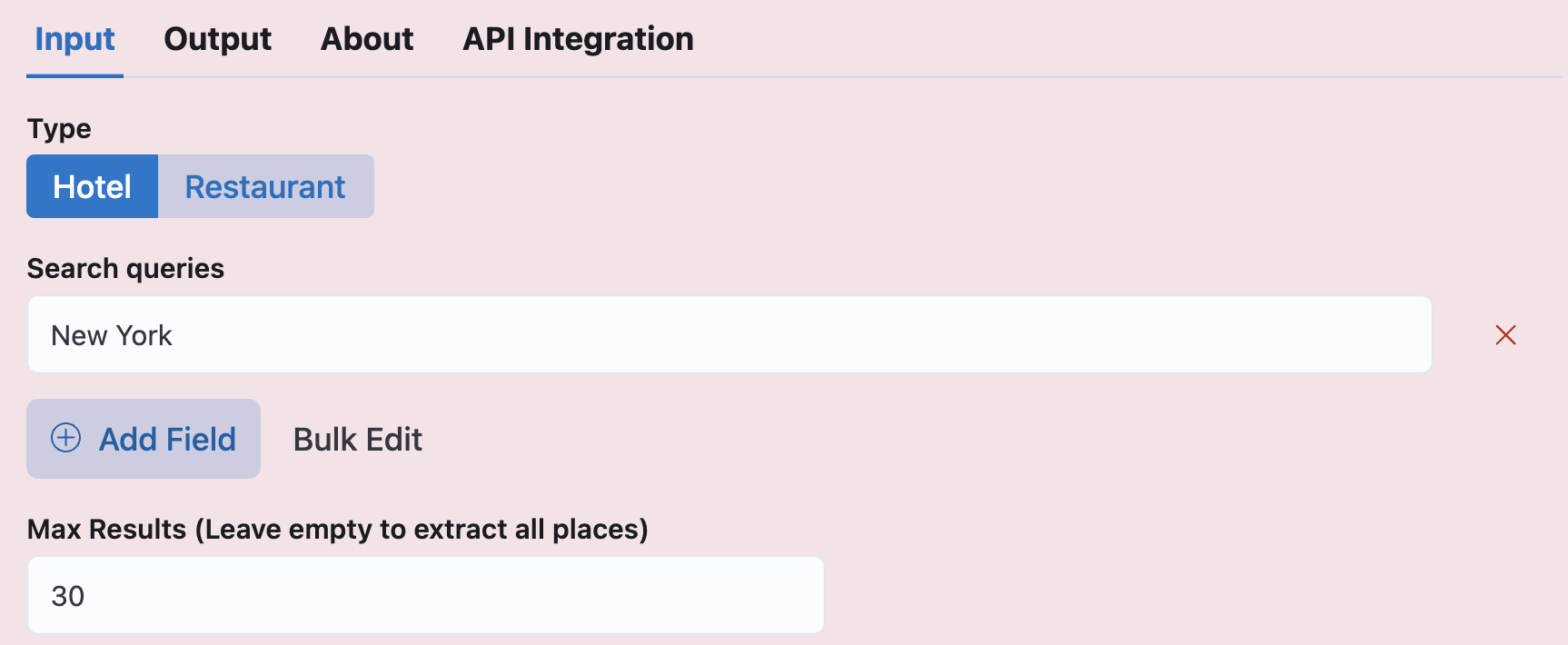
- Now, simply press the Run button.

We scrape over 45+ data points, important among them are:
- Name
- Reviews
- Rating
- Website
- Phone
- Address
- And many more...
Kindly follow these steps to use our Rapid API and easily get the tripadvisor product details:
- Sign up on RapidAPI by visiting this link.
- Subscribe to the Free Plan by visiting this link.
-
Copy the API key.
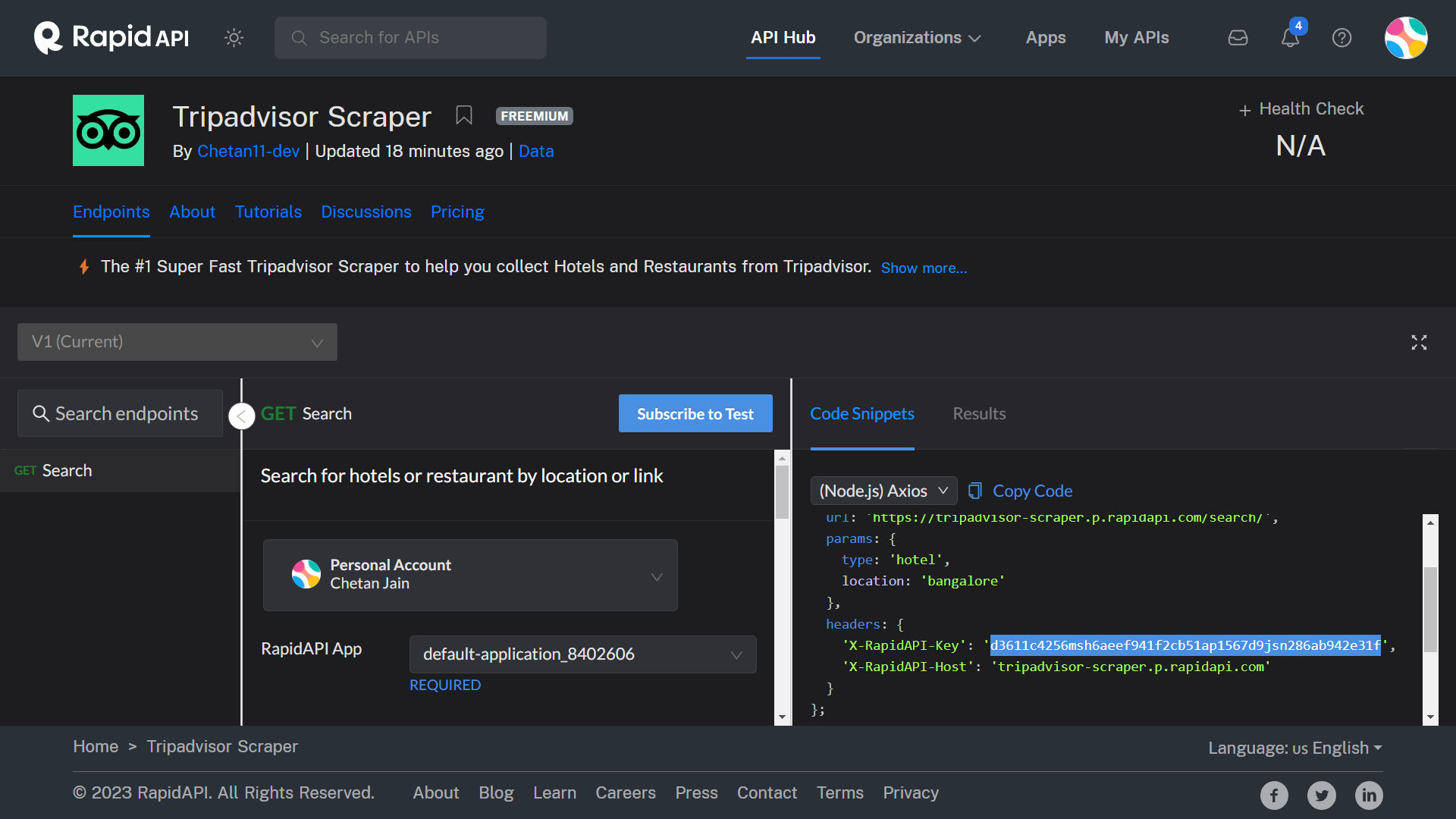
-
Put the Key in the "Rapid API Key" textbox and simply run it:

The first 200 requests are free with the API. After that, you can upgrade to the Pro Plan to scrape 10000 listings for $16, which is a really great price, considering that the data is 101% accurate, fresh, and comprehensive with 45+ fields.
We wholeheartedly ❤️ believe in the value our product brings for you, especially since it has successfully worked for hundreds of people like you.
But, we also understand the reservations you might have.
That's why we've put the ball in your court: If, within the next 90 days, you feel that our product hasn't met your expectations, don't hesitate. Reach out to us, and within 24 hours, we will gladly refund your money, no questions and no hassles.
The risk is entirely on us! because we're that confident in what we've created!
We are ethical and honest, and we will not keep your money if you are not satisfied with our product. Requesting a refund is a simple process that should only take about 5 minutes.
To do so, you need to submit a support request here, and we will issue the refund.
Thank you! We used Botasaurus, which is the secret behind our awesome Tripadvisor Scraper.
Botasaurus is a web scraping framework that makes life a lot easier for web scrapers.
It handled the hardest parts of our scraper, such as:
- Creating a gorgeous UI dashboard with task management features
- Sorting, filtering, and exporting data as CSV, JSON, Excel, etc.
- Caching, parallel and asynchronous scraping
If you're a web scraper, I really recommend learning about Botasaurus here 🚀.
Trust me, learning Botasaurus will only take 20 minutes, but I guarantee it will definitely save you thousands of hours in your life as a web scraper.

Having read this page, you have all the knowledge needed to effectively use the tool.
You may choose to read the following questions based on your interests:
- I Don't Have Python, or I'm Facing Errors When Setting Up the Scraper on My PC. How to Solve It?
- How to Update the Scraper to the Latest Version?
For further help, feel free to reach out to us through:
-
WhatsApp: If you prefer WhatsApp, simply send a message here. Also, to help me provide the best possible answer, please include as much detail as possible.

-
Email: If you prefer email, kindly send your queries to [email protected]. Also, to help me provide the best possible answer, please include as much detail as possible.

We look forward to helping you and will respond to emails and WhatsApp messages within 24 hours.
Good Luck!
Love It? Star It ⭐!
Become one of our amazing stargazers by giving us a star ⭐ on GitHub!
It's just one click, but it means the world to me.






































































































