The Koster Seafloor Observatory is an open-source, citizen science and machine learning approach to analyse subsea movies.
The KSO system has been developed to:
- move and process underwater footage and its associated data (e.g. location, date, sampling device).
- make this data available to citizen scientists in Zooniverse to annotate the data.
- train and evaluate machine learning models (customise Yolov5 or Yolov8 models).
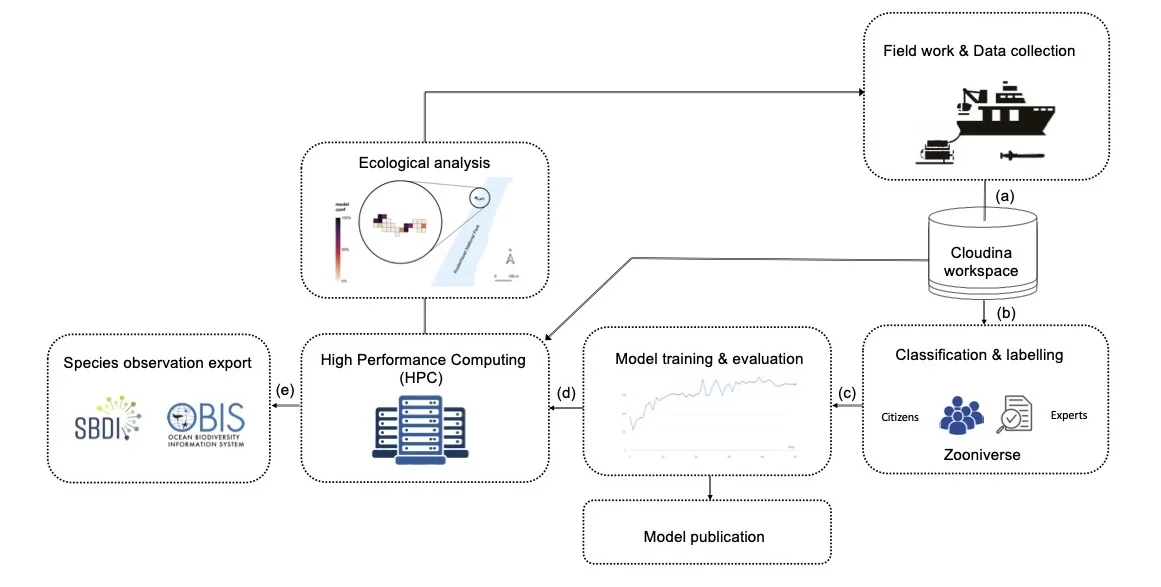
The system is built around a series of easy-to-use Jupyter Notebooks. Each notebook allows users to perform a specific task of the system (e.g. upload footage to the citizen science platform or analyse the classified data).
Users can run these notebooks via Google Colab (by clicking on the Colab links in the table below), locally or on a high-performance computing (HPC) environment.
Our notebooks are modular and grouped into four main task categories; Set up, Classify, Analyse and Publish.
| Task | Notebook | Description | Try it! |
|---|---|---|---|
| Set up | Check_metadata | Check format and contents of footage and sites, media and species csv files | |
| Classify | Upload_subjects_to_Zooniverse | Prepare original footage and upload short clips to Zooniverse, extract frames of interest from the original footage and upload them to Zooniverse | |
| Classify | Process_classifications | Pull and process up-to-date classifications from Zooniverse | |
| Analyse | Train_models | Prepare the training and test data, set model parameters and train models | |
| Analyse | Evaluate_models | Use ecologically relevant metrics to test the models | |
| Publish | Publish_models | Publish the model to a public repository | |
| Publish | Publish_observations | Automatically classify new footage and export observations to GBIF |
Bash
docker pull ghcr.io/ocean-data-factory-sweden/kso:dev
Clone this repository using
git clone https://github.com/ocean-data-factory-sweden/kso.gitDepending on your system (Windows/Linux/MacOS), you might need to install some extra tools. If this is the case, you will get a message about what you need to install in the next steps. For example, Microsoft Build Tools C++ with a version higher than 14.0 is required for Windows systems.
- Open the Anaconda Prompt
- Navigate to the folder where you have cloned the repository or unzipped the manually downloaded repository. Then go into the kso folder.
cd kso
- Create an Anaconda environment with Python 3.8. Remember to change the name env.
conda create -n <name env> python=3.8
- Enter the environment:
conda activate <name env>
- Specify your GPU details.
5a. Find out the pytorch installation you need. Navigate to the system options (example below) and select your device/platform details.

5b. Add the recommended command to the KSO's gpu_requirements_user.txt file.
- Install all the requirements:
pip install -r requirements.txt -r gpu_requirements_user.txt
Cloudina is a hosted version of KSO (powered by JupyterHub) on NAISS Science Cloud. It allows users to scale and automate larger workflows using a powerful processing backend. This is currently an invitation-only service. To access the platform, please contact jurie.germishuys[at]combine.se.
The current portals are accessible as:
To start a new project you will need to:
- Create initial information for the database: Input the information about the underwater footage files, sites and species of interest. You can use a template of the csv files and move the directory to the "db_starter" folder.
- Link your footage to the database: You will need files of underwater footage to run this system. You can download some samples and move them to
db_starter. You can also store your own files and specify their directory in the notebooks.
Please remember the format of the underwater media is standardised (typically .mp4 or .jpg) and the associated metadata captured in three CSV files (“movies”, “sites” and “species”) should follow the Darwin Core standards (DwC).
If you would like to expand and improve the KSO capabilities, please follow the instructions above to set the project up on your local computer.
When you add any changes, please create your branch on top of the current 'dev' branch. Before submitting a Merge Request, please:
- Run Black on the code you have edited
black filename - Clean up your commit history on your branch, so that every commit represents a logical change. (so squash and edit commits so that it is understandable for others)
- For the commit messages, we ask that you please follow the conventional commits guidelines (table below) to facilitate code sharing. Also, please describe the logic behind the commit in the body of the message.
| Commit Type | Title | Description | Emoji |
|---|---|---|---|
feat |
Features | A new feature | ✨ |
fix |
Bug Fixes | A bug Fix | 🐛 |
docs |
Documentation | Documentation only changes | 📚 |
style |
Styles | Changes that do not affect the meaning of the code (white-space, formatting, missing semi-colons, etc) | 💎 |
refactor |
Code Refactoring | A code change that neither fixes a bug nor adds a feature | 📦 |
perf |
Performance Improvements | A code change that improves performance | 🚀 |
test |
Tests | Adding missing tests or correcting existing tests | 🚨 |
build |
Builds | Changes that affect the build system or external dependencies (example scopes: gulp, broccoli, npm) | 🛠 |
ci |
Continuous Integrations | Changes to our CI configuration files and scripts (example scopes: Travis, Circle, BrowserStack, SauceLabs) | ⚙️ |
chore |
Chores | Other changes that don't modify src or test files | ♻️ |
revert |
Reverts | Reverts a previous commit | 🗑 |
- Rebase on top of dev. (never merge, only use rebase)
- Submit a Pull Request and link at least 2 reviewers
If you use this code or its models in your research, please cite:
Anton V, Germishuys J, Bergström P, Lindegarth M, Obst M (2021) An open-source, citizen science and machine learning approach to analyse subsea movies. Biodiversity Data Journal 9: e60548. https://doi.org/10.3897/BDJ.9.e60548
You can find out more about the project at https://subsim.se.
We are always excited to collaborate and help other marine scientists. Please feel free to contact us (matthias.obst(at)marine.gu.se) with your questions.
If you experience issues importing panoptes_client in Windows, it is a known issue with the libmagic package. Pmason's suggestions in the Talk board of Zooniverse can be useful for troubleshooting it.
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

























