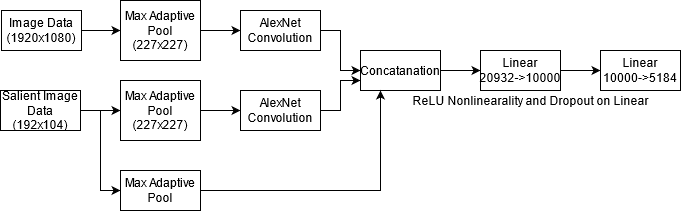
This model is a proof-of-concept for an algorithm to generate gaze cloud data based on images. It uses datasets from MIT's saliency benchmark to train the model, but it can be adapted for use for any images. The algorithm uses an image (3x1080x1920) and a salient map (1x192x104) as parameters and outputs a 1x54x96 gaze cloud image. The code in train.py uses MIT's premade salient images, however the model can be adopted to use salient image algorithms at runtime instead. The results generated from this experiment are promising, showing evidence of functional gaze generation. Weaknesses of the model are a center-image-biase even on images with salient object near the edges, a large amount of feedback noise, and inability to have multiple gaze clouds in one image with seperate salient objects. If I were to have a system with more power, I would have made the model deeper, as I feel the results are underfit.
Training Set Download: train.zip
Testing Set Download: test.zip
To use this dataset, put the trainSet and testSet folders in the same directory as train.py and test.py. To use this in your code, you may need to change the path in train.py and test.py. To create a pytorch set, you can create a EyeTrackingDataset object and pass in the path of your project, and a list of subfolders in trainSet to use.
If you want to use this code with a different dataset, you must change the EyeTrackingDataset.py to allow for it.