
A graph neural network framework for multi-agent reinforcement learning with limited local observability for each agent. This is an official implementation of the model described in:
"Scalable Multi-Agent Reinforcement Learning through Intelligent Information Aggregation",
Siddharth Nayak, Kenneth Choi, Wenqi Ding, Sydney Dolan, Karthik Gopalakrishnan, Hamsa Balakrishnan
April 2023 - The paper was accepted to ICML'2023! See you in Honolulu in July 2023
Dec 2022 - Presented a short version of this paper at the Strategic Multi-Agent Interactions: Game Theory for Robot Learning and Decision Making Workshop at CoRL in Auckland. You can find the recording here.
Please let us know if anything here is not working as expected, and feel free to create new issues with any questions.
We consider the problem of multi-agent navigation and collision avoidance when observations are limited to the local neighborhood of each agent. We propose InforMARL, a novel architecture for multi-agent reinforcement learning (MARL) which uses local information intelligently to compute paths for all the agents in a decentralized manner. Specifically, InforMARL aggregates information about the local neighborhood of agents for both the actor and the critic using a graph neural network and can be used in conjunction with any standard MARL algorithm. We show that (1) in training, InforMARL has better sample efficiency and performance than baseline approaches, despite using less information, and (2) in testing, it scales well to environments with arbitrary numbers of agents and obstacles.
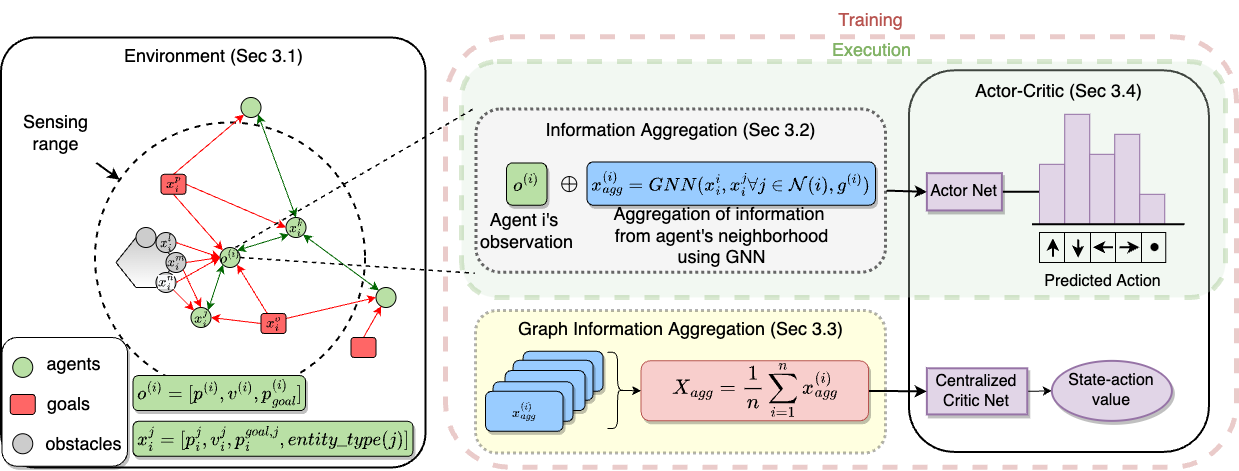
Overview of InforMARL: (i) Environment: The agents are depicted by green circles, the goals are depicted by red rectangles, and the unknown obstacles are depicted by gray circles. $x^{i}{agg}$ represents the aggregated information from the neighborhood, which is the output of the GNN. A graph is created by connecting entities within the sensing-radius of the agents. (ii) Information Aggregation: Each agent's observation is concatenated with $x^{i}{\mathrm{agg}}$. The inter-agent edges are bidirectional, while the edges between agents and non-agent entities are unidirectional. (iii) Graph Information Aggregation: The aggregated vector from all the agents is averaged to get
To train InforMARL:
python -u onpolicy/scripts/train_mpe.py --use_valuenorm --use_popart \
--project_name "informarl" \
--env_name "GraphMPE" \
--algorithm_name "rmappo" \
--seed 0 \
--experiment_name "informarl" \
--scenario_name "navigation_graph" \
--num_agents 3 \
--collision_rew 5 \
--n_training_threads 1 --n_rollout_threads 128 \
--num_mini_batch 1 \
--episode_length 25 \
--num_env_steps 2000000 \
--ppo_epoch 10 --use_ReLU --gain 0.01 --lr 7e-4 --critic_lr 7e-4 \
--user_name "marl" \
--use_cent_obs "False" \
--graph_feat_type "relative" \
--auto_mini_batch_size --target_mini_batch_size 128We also provide with code for the navigation environment which is compatible to be used with graph neural networks.
Note: A more thorough documentation will be up soon.
python multiagent/custom_scenarios/navigation_graph.py
from multiagent.environment import MultiAgentGraphEnv
from multiagent.policy import InteractivePolicy
# makeshift argparser
class Args:
def __init__(self):
self.num_agents:int=3
self.world_size=2
self.num_scripted_agents=0
self.num_obstacles:int=3
self.collaborative:bool=False
self.max_speed:Optional[float]=2
self.collision_rew:float=5
self.goal_rew:float=5
self.min_dist_thresh:float=0.1
self.use_dones:bool=False
self.episode_length:int=25
self.max_edge_dist:float=1
self.graph_feat_type:str='global'
args = Args()
scenario = Scenario()
# create world
world = scenario.make_world(args)
# create multiagent environment
env = MultiAgentGraphEnv(world=world, reset_callback=scenario.reset_world,
reward_callback=scenario.reward,
observation_callback=scenario.observation,
graph_observation_callback=scenario.graph_observation,
info_callback=scenario.info_callback,
done_callback=scenario.done,
id_callback=scenario.get_id,
update_graph=scenario.update_graph,
shared_viewer=False)
# render call to create viewer window
env.render()
# create interactive policies for each agent
policies = [InteractivePolicy(env,i) for i in range(env.n)]
# execution loop
obs_n, agent_id_n, node_obs_n, adj_n = env.reset()
stp=0
while True:
# query for action from each agent's policy
act_n = []
for i, policy in enumerate(policies):
act_n.append(policy.action(obs_n[i]))
# step environment
obs_n, agent_id_n, node_obs_n, adj_n, reward_n, done_n, info_n = env.step(act_n)
# render all agent views
env.render()Here env.reset() returns obs_n, agent_id_n, node_obs_n, adj_n where:
-
obs_n: Includes local observations (position, velocity, relative goal position) of each agent. -
agent_id_n: Includes the 'ID' for each agent. This can be used to query any agent specific features in the replay buffer -
node_obs_n: Includes node observations for graphs formed wrt each agent$i$ . Here each node can be any entity in the environment namely: agent, goal or obstacle. The node features include relative position, relative velocity of the entity and the relative position of the goal on the entity. -
adj_n: Includes the adjacency matrix of the graphs formed.
This can also be used with an environment wrapper:
from multiagent.MPE_env import GraphMPEEnv
# all_args can be pulled config.py or refer to `onpolicy/scripts/train_mpe.py`
env = MPEEnv(all_args)
obs_n, agent_id_n, node_obs_n, adj_n = env.reset()- Multiagent-particle-envs: We have pulled the relevant folder from the repo to modify it.
pip install gym==0.10.5(newer versions also seem to work)pip install numpy-stl- torch==1.11.0
- torch-geometric==2.0.4
- torch-scatter==2.0.8
- torch-sparse==0.6.12
We compare our methods with other MARL baselines:
- Pulled the MAPPO code from here which was used in this paper. Also worth taking a look at this branch for their benchmarked code.
- MADDPG, MATD3, QMIX, VDN
- Graph Policy Gradients (GPG); Paper
- Graph Convolutional Reinforcement Learning (DGN); Paper
- Entity Message Passing Network (EMP); Paper
-
OMP: Error #15: Initializing libiomp5.dylib, but found libomp.dylib already initialized.: Install nomkl by runningconda install nomkl -
AttributeError: dlsym(RTLD_DEFAULT, CFStringCreateWithCString): symbol not found: This issue arises with MacOS Big Sur. A hacky fix for this is to revert change thepygletversion to maintenance version usingpip install --user --upgrade git+http://github.com/pyglet/[email protected] -
AttributeError: 'NoneType' object has no attribute 'origin': This error arises whilst usingtorch-geometricwith CUDA. Uninstalltorch_geometric,torch-cluster,torch-scatter,torch-sparse, andtorch-spline-conv. Then re-install using:TORCH="1.8.0" CUDA="cu102" pip install --no-index torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}+${CUDA}.html --user pip install --no-index torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}+${CUDA}.html --user pip install torch-geometric --user
Please file an issue if you have any questions or requests about the code or the paper. If you prefer your question to be private, you can alternatively email me at [email protected]
If you found this codebase useful in your research, please consider citing
@article{nayak22informarl,
doi = {10.48550/ARXIV.2211.02127},
url = {https://arxiv.org/abs/2211.02127},
author = {Nayak, Siddharth and Choi, Kenneth and Ding, Wenqi and Dolan, Sydney and Gopalakrishnan, Karthik and Balakrishnan, Hamsa},
keywords = {Multiagent Systems (cs.MA), Artificial Intelligence (cs.AI), Robotics (cs.RO), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scalable Multi-Agent Reinforcement Learning through Intelligent Information Aggregation},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}We would love to include more scenarios from the multi-agent particle environment to be compatible with graph neural networks and would be happy to accept PRs.
MIT License


































































