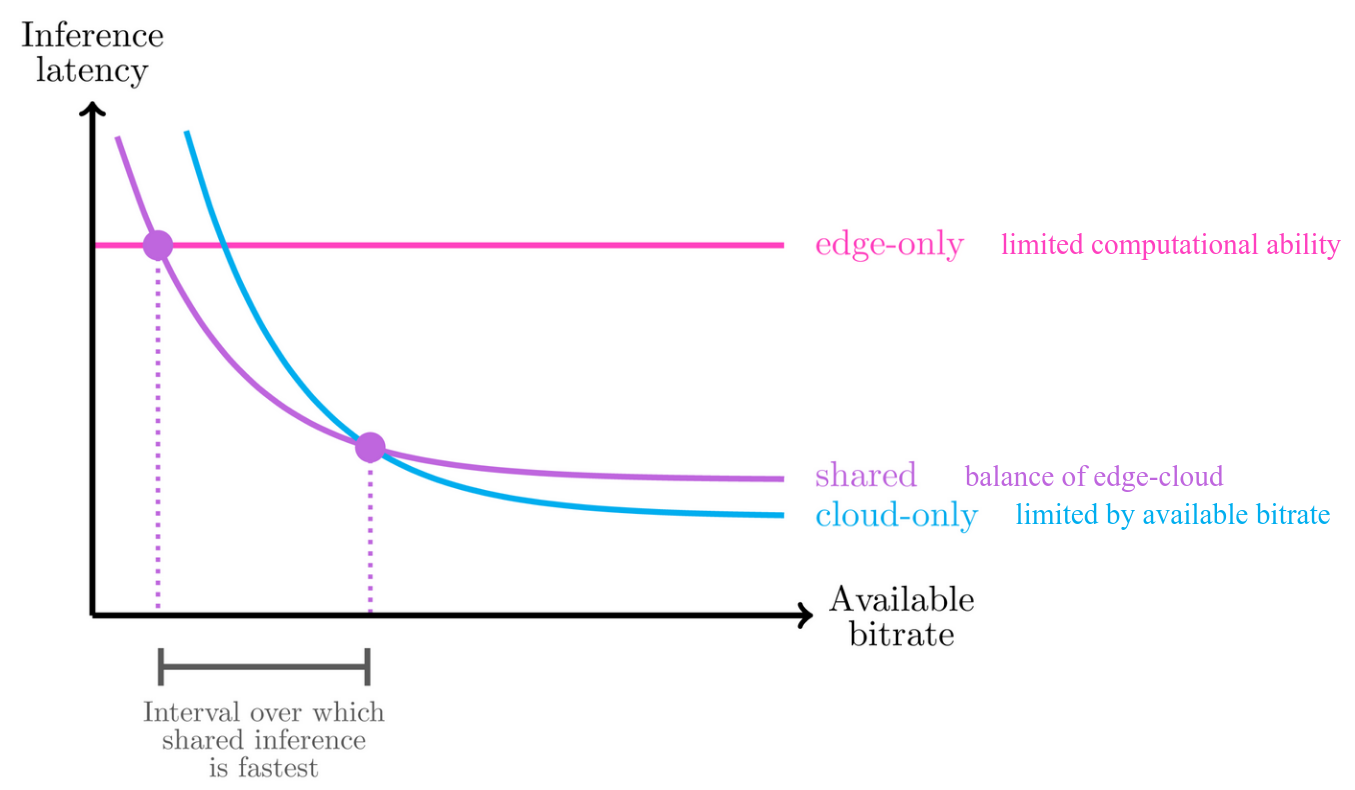
 Inference latency versus available bitrate. For certain ranges of bitrates, sharing the inference between the edge/mobile device and the cloud/server can have the lowest inference latency, along with other potential benefits. |
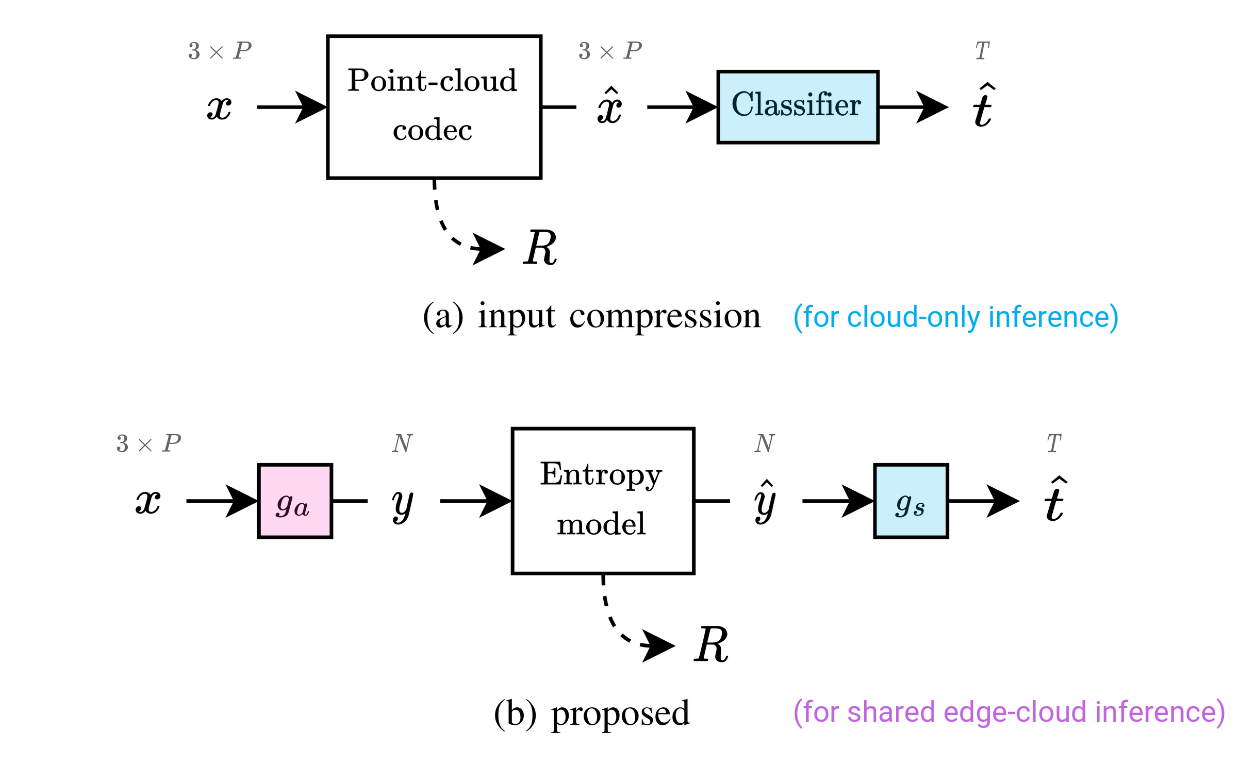 High-level comparison of codec architectures. (a) Conventional server-side inference where the input data is compressed, sent over to the server, and then decompressed before any processing begins. (b) Our proposed architecture where part of the inference is done on the edge, while being compressed, and then sent over to the server for decompression and further processing. |
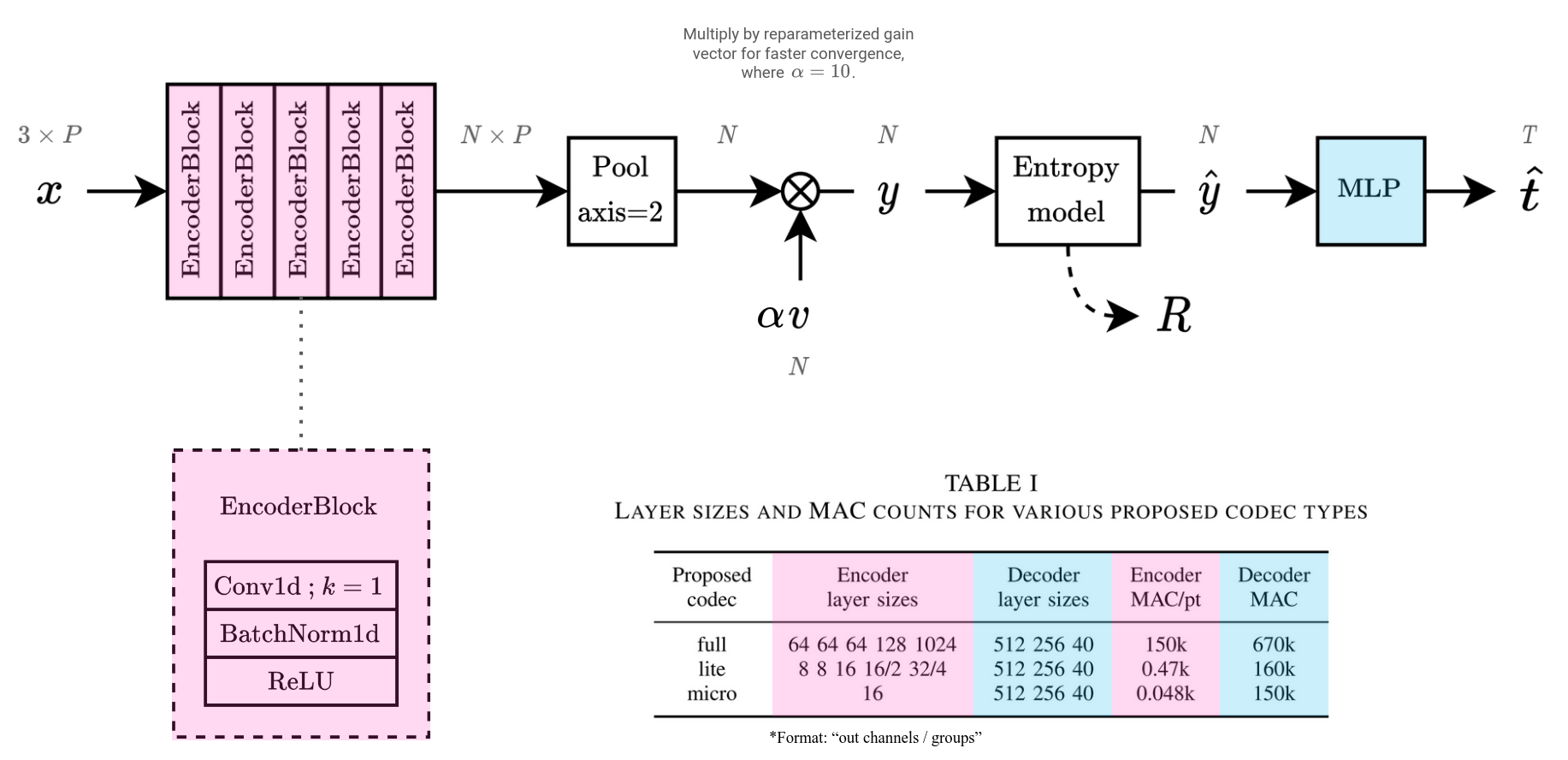 Our proposed architecture, based on PointNet, in full detail. Our proposed architecture, based on PointNet, in full detail. |
|
Abstract: Deep learning is increasingly being used to perform machine vision tasks such as classification, object detection, and segmentation on 3D point cloud data. However, deep learning inference is computationally expensive. The limited computational capabilities of end devices thus necessitate a codec for transmitting point cloud data over the network for server-side processing. Such a codec must be lightweight and capable of achieving high compression ratios without sacrificing accuracy. Motivated by this, we present a novel point cloud codec that is highly specialized for the machine task of classification. Our codec, based on PointNet, achieves a significantly better rate-accuracy trade-off in comparison to alternative methods. In particular, it achieves a 94% reduction in BD-bitrate over non-specialized codecs on the ModelNet40 dataset. For low-resource end devices, we also propose two lightweight configurations of our encoder that achieve similar BD-bitrate reductions of 93% and 92% with 3% and 5% drops in top-1 accuracy, while consuming only 0.470 and 0.048 encoder-side kMACs/point, respectively. Our codec demonstrates the potential of specialized codecs for machine analysis of point clouds, and provides a basis for extension to more complex tasks and datasets in the future.
- Authors: Mateen Ulhaq and Ivan V. Bajić
- Affiliation: Simon Fraser University
- Links: Published and presented at MMSP 2023. [Paper]. [Slides]. [BibTeX citation].
git clone https://github.com/multimedialabsfu/learned-point-cloud-compression-for-classification
git submodule update --init --recursiveUse either poetry or virtualenv to install python dependencies.
First, install poetry:
curl -sSL https://install.python-poetry.org | python3 -Then, install all python dependencies:
poetry env use python3.10
poetry install
poetry shell
pip install -e ./submodules/compressai
pip install -e ./submodules/compressai-trainer
pip install "git+https://github.com/facebookresearch/pytorch3d.git"virtualenv venv
source venv/bin/activate
pip install -e .
pip install -e ./submodules/compressai
pip install -e ./submodules/compressai-trainer
pip install "git+https://github.com/facebookresearch/pytorch3d.git"cd third_party/pc_error
make
# Install for user.
mkdir -p "$HOME/.local/bin/"
cp pc_error "$HOME/.local/bin/"git clone https://github.com/MPEGGroup/mpeg-pcc-tmc13
cd mpeg-pcc-tmc13
mkdir -p build
cd build
cmake ..
make
# Install for user.
mkdir -p "$HOME/.local/bin/"
cp tmc3/tmc3 "$HOME/.local/bin/"Ensure $PATH is set correctly:
echo "$PATH" | sed 's/:/\n/g' | grep -q "$HOME/.local/bin" || (
echo "Please add $HOME/.local/bin to PATH"
echo "For example, try running:"
echo 'echo '"'"'export PATH="$PATH:$HOME/.local/bin/"'"'"' >> "$HOME/.bashrc"'
)Download and repair the ModelNet40 dataset (it has incorrect OFF headers!) by running:
# Navigate to your desired root dataset directory.
cd "${paths.datasets}/modelnet"
# Download and extract the dataset.
wget 'http://modelnet.cs.princeton.edu/ModelNet40.zip'
unzip 'ModelNet40.zip'
python scripts/repair_modelnet.py --input_dir=ModelNet40
mv ModelNet40 dataset=modelnet40,format=off
# Another reasonable alternative:
# wget 'https://shapenet.cs.stanford.edu/media/modelnet40_normal_resampled.zip'During training, the torch_geometric.datasets.modelnet.ModelNet dataset class also downloads and processes its own format of the ModelNet40 dataset into the directory ${paths.datasets}/modelnet/dataset=modelnet40,format=pt. For compatibility with our scripts, we recommend that you also follow the same directory structure.
Our directory structure
${paths.datasets}/modelnet/
├── dataset=modelnet40,format=off <-- original dataset
├── dataset=modelnet40,format=pt <-- torch_geometric compatible dataset
├── by_n_ply
│ ├── 1024 <-- format=.ply, points=1024, flat
│ ├── 0512
│ └── ...
├── by_n_scale_ply_tmc3
│ ├── 1024
│ │ ├── 0256 <-- format=.ply, points=1024, scale=256, flat
│ │ ├── 0128
│ │ └── ...
│ └── ...
└── ModelNet40.zip
[OPTIONAL] For evaluating input compression codecs:
- To generate datasets for a specific number of points
N, usescripts/generate_datasets_by_n_points.py. - Many point-cloud codecs accept
*.plyfiles, but not*.off. To convert the dataset, install thectmconvutility and runscripts/convert_dataset.py:python convert_dataset.py \ --input_dir='dataset=modelnet40,format=off' \ --output_dir='dataset=modelnet40,format=ply' \ --convert_only=True
- To generate a normalized dataset for a specific number of points, run:
python convert_dataset.py \ --input_dir='dataset=modelnet40,format=off' \ --output_dir="dataset=modelnet40,format=ply,normalize=True,num_points=${NUM_POINTS}" \ --normalize=True \ --num_points_resample="${NUM_POINTS}" \ --num_points_subsample="${NUM_POINTS}"
We use CompressAI Trainer for training. See the walkthrough for more details.
To train a single-task classification compression model, use:
python -m src.run.train \
--config-path="$PWD/conf/" \
--config-name="example_pcc_singletask" \
++model.name="um-pcc-cls-only-pointnet-mmsp2023" \
++paths.datasets="$HOME/data/datasets" \
++hp.num_points=1024 \
++criterion.lmbda.cls=100To train a multi-task input reconstruction compression model, use:
python -m src.run.train \
--config-path="$PWD/conf/" \
--config-name="example_pcc_multitask" \
++model.name="um-pcc-multitask-cls-pointnet" \
++paths.datasets="$HOME/data/datasets" \
++hp.num_points=1024 \
++hp.detach_y1_hat=True \
++criterion.lmbda.rec=16000 \
++criterion.lmbda.cls=100To train vanilla PointNet (i.e. no compression), use:
python -m src.run.train \
--config-path="$PWD/conf/" \
--config-name="example_pc_task" \
++model.name="um-pc-cls-pointnet" \
++paths.datasets="$HOME/data/datasets" \
++hp.num_points=1024 \
++criterion.lmbda.cls=1.0Please see scripts/run.sh for more examples, including how to train different codec configurations/layer sizes.
CompressAI Trainer automatically evaluates models during training. To see the Aim experiment tracker/dashboard, please follow these instructions.
To save the results to JSON, modify scripts/save_json_from_aim_query.py to query your specific models. (By default, it is currently set up to generate all the trained codec curves shown in our paper.) Then, run:
python scripts/save_json_from_aim_query.py --aim-repo-path="/path/to/aim/repo" --output-dir="results/point-cloud-classification/modelnet40"- RD curves: Once the JSON results are saved, add the relevant files to the
CODECSlist inscripts/plot_rd_mpl.pyand run it to plot the RD curves. - Reconstructed point clouds: using
scripts/plot_point_cloud_mpl.py. - Critical point sets:
scripts/plot_critical_point_set.pycan be used to plot the critical point sets. Seescripts/run_plot.shfor example usage.
In our paper, we also evaluated "input compression codec" performance. To reproduce these results, please follow the procedure outlined in the paper, and make use of the following scripts:
-
NOTE: Please modify
RUN_HASHESto point to your own trained models.
Please cite this work as:
@inproceedings{ulhaq2023mmsp,
title = {Learned Point Cloud Compression for Classification},
author = {Ulhaq, Mateen and Baji\'{c}, Ivan V.},
booktitle = {Proc. IEEE MMSP},
year = {2023},
}