nielsbasjes / splittablegzip Goto Github PK
View Code? Open in Web Editor NEWSplittable Gzip codec for Hadoop
License: Apache License 2.0
Splittable Gzip codec for Hadoop
License: Apache License 2.0
If you have a file that is smaller than 4KB the codec will fail.
This is undesired behaviour.
I wonder if you could make suggestions on how to use this in an AWS glue job. My method does not involve using spark-submit but rather creating job definitions and run-job using boto3 tools.
When I try to use this in my script, i get:
pyspark.sql.utils.IllegalArgumentException: Compression codec nl.basjes.hadoop.io.compress.SplittableGzipCodec not found.
have tried passing --conf nl.basjes.hadoop.io.compress.SplittableGzipCodec, -packages nl.basjes.hadoop.io.compress.SplittableGzipCodec and other methods as args to job to no avail. I think I must need to put a copy of the codec on s3 and point to it with extra-files or other arg?
This issue lists Renovate updates and detected dependencies. Read the Dependency Dashboard docs to learn more.
This repository currently has no open or pending branches.
.github/workflows/build.yml
actions/checkout v4actions/cache v4actions/setup-java v4codecov/codecov-action v4.4.1
Benchmark/javamr/pom.xml
junit:junit 4.13.2org.apache.hadoop:hadoop-client 3.4.0Benchmark/pig/pom.xml
hadoop-codec/pom.xml
junit:junit 4.13.2org.slf4j:slf4j-api 2.0.13org.apache.maven.plugins:maven-gpg-plugin 3.2.4org.apache.maven.plugins:maven-source-plugin 3.3.1org.apache.maven.plugins:maven-deploy-plugin 3.1.2org.apache.maven.plugins:maven-javadoc-plugin 3.6.3org.apache.maven.plugins:maven-pmd-plugin 3.22.0org.codehaus.mojo:findbugs-maven-plugin 3.0.5pom.xml
org.apache.hadoop:hadoop-client 3.4.0
0a97faa is not released yet
Hi,
I get an exception trying to start session with spark.jars.packages='nl.basjes.hadoop:splittablegzip:1.3'
java.lang.ClassNotFoundException: java.lang.NoClassDefFoundError: Could not initialize class org.slf4j.LoggerFactory when creating Hive client using classpath
Anyone with experience in running on Spark 3+?
There is an error with this repository's Renovate configuration that needs to be fixed. As a precaution, Renovate will stop PRs until it is resolved.
Location: renovate.json
Error type: The renovate configuration file contains some invalid settings
Message: Invalid regExp for packageRules[0].allowedVersions: '!/^(?i).*[-_\.](Alpha|Beta|RC|M|EA|Snap|snapshot|jboss|atlassian)[-_\.]?[0-9]?.*$/'
I came across this project via a comment on a Spark Jira ticket where I was thinking about a way to split gzip files that is similar to what this project does. I was delighted to learn that someone had already thought through and implemented such a solution, and from the looks of it done a much better job at it than I could have.
So I just wanted to report here for the record, since gzipped files are a common stumbling block for Apache Spark users, that your solution works with Apache Spark without modification.
Here is an example, which I've tested against Apache Spark 2.4.4 using the Python DataFrame API:
# splittable-gzip.py
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = (
SparkSession.builder
# If you want to change the split size, you need to use this config
# instead of mapreduce.input.fileinputformat.split.maxsize.
# I don't think Spark DataFrames offer an equivalent setting for
# mapreduce.input.fileinputformat.split.minsize.
.config('spark.sql.files.maxPartitionBytes', 1000 * (1024 ** 2))
.getOrCreate()
)
print(
spark.read
# You can also specify this option against the SparkSession.
.option('io.compression.codecs', 'nl.basjes.hadoop.io.compress.SplittableGzipCodec')
.csv(...)
.count()
)Run this script as follows:
spark-submit --packages "nl.basjes.hadoop:splittablegzip:1.2" splittable-gzip.pyHere's what I see in the Spark UI when I run this script against a 20 GB gzip file on my laptop:
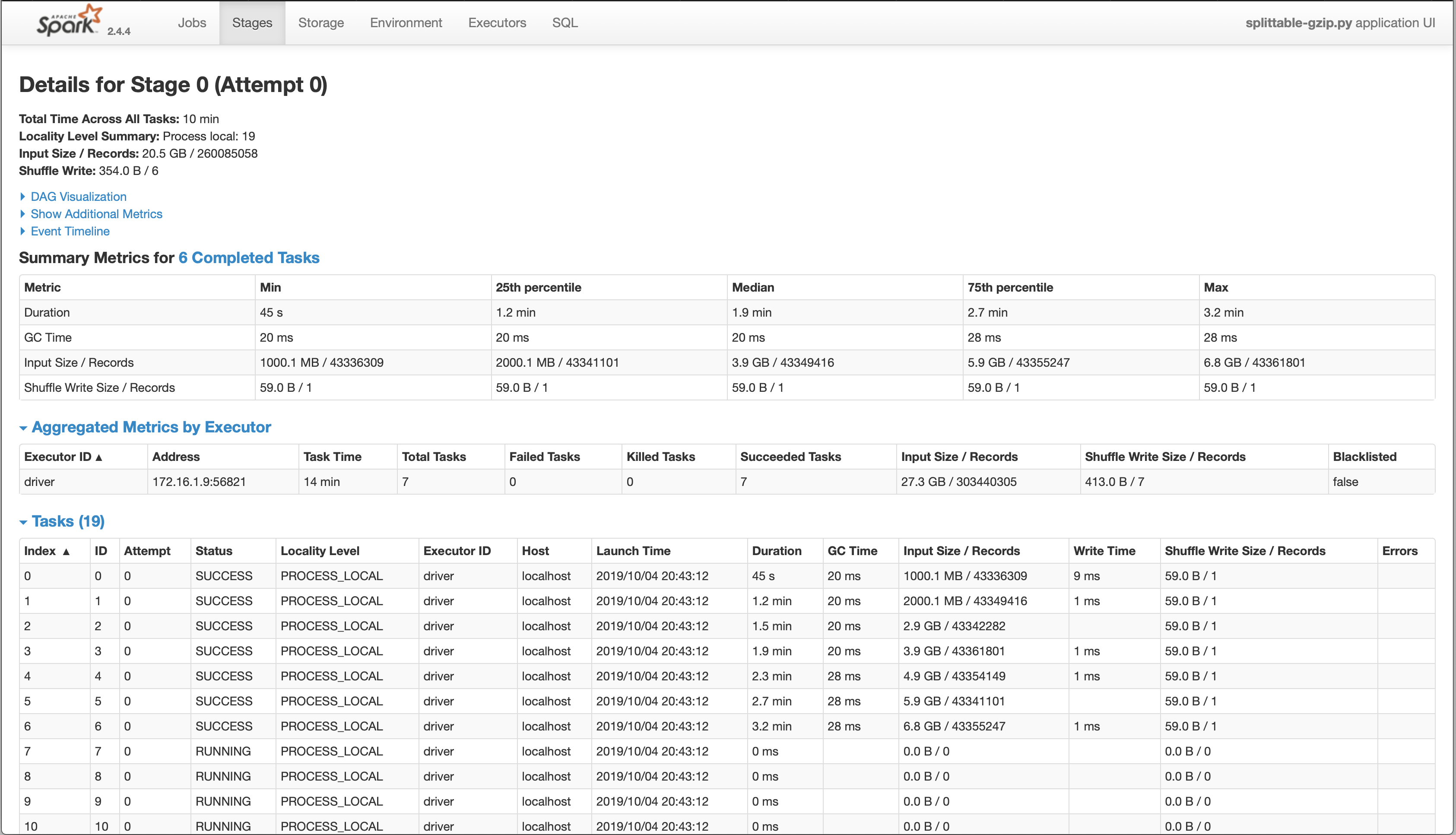
You can see in the task list the behavior described in the README, with each task reading from the start of the file to its target split.
And here is the Executor UI, which shows every available core running concurrently against this single file:
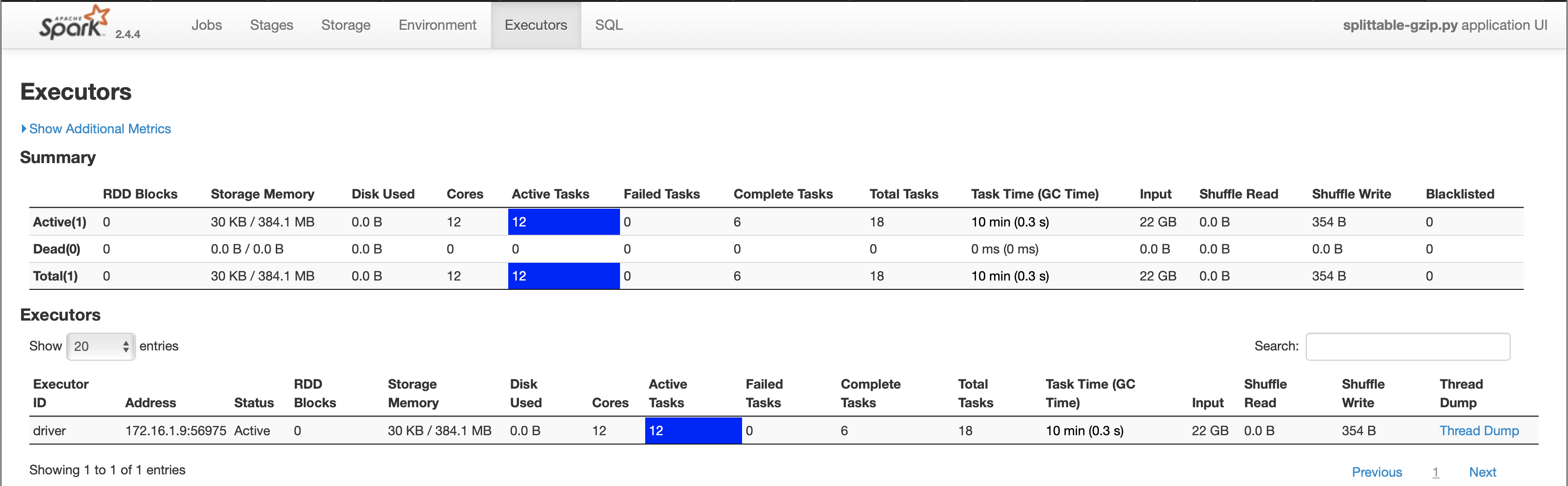
I will experiment some more with this project -- and perhaps ask some questions on here, if you don't mind -- and then promote it on Stack Overflow and in the Boston area.
Thank you for open sourcing this work!
The parallelly duplicated read will make the network in high throughput.
I think executors on same node or tasks on same executor should share the content of file , but make locality.wait longer could not solve the problem .
What can I do?
Hi! Thank you for this great library. We used it to process our large input gz files, but we faced with some problem.
java.lang.IllegalArgumentException: The provided InputSplit (786432000;786439029] is 7029 bytes which is too small. (Minimum is 65536)
In our company we use HDP 2.6 with spark 2.3.
I tried to find min split parameter for spark, but spark.hadoop.mapreduce.input.fileinputformat.split.minsize doesn't work. Only spark.sql.files.maxPartitionBytes setting realy works.
Give me some advice, please, what can I do? Or may be it's possible to fix problem in library?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.