This repo contains the code for our NIPS17 paper, Structured Bayesian Pruning via Log-Normal Multiplicative Noise (poster). In the paper, we propose a new Bayesian model that takes into account the computational structure of neural networks and provides structured sparsity, e.g. removes neurons and/or convolutional channels in CNNs. To do this we inject noise to the neurons outputs while keeping the weights unregularized.

Example for launching LeNet5 experiment.
python ./scripts/lenet5-sbp.py
Example for launching VGG-like experiment. To obtain sparse VGG-like architecture we use pretrained network, so you can use your own weights, or train the network from scratch using the following command.
python ./scripts/vgglike.py --num_gpus <num GPUs>
Don't forget to adjust batch size to obtain the same number of iterations. For instance, for one GPU we use batch_size=100, for 2 GPUs we use batch_size=50.
Finally, use the following command to launch SBP model for VGG-like architecture.
python ./scripts/vgglike-sbp.py --num_gpus <num GPUs> --checkpoint <path to pretrained checkpoint>
Results for LeNet architectures on MNIST
| Network | Method | Error | Neurons per Layer | CPU | GPU | FLOPs |
|---|---|---|---|---|---|---|
| Lenet-fc | Original | 1.54 | 784 - 500 - 300 - 10 | 1.00 X | 1.00 X | 1.00 X |
| SparseVD | 1.57 | 537 - 217 - 130 - 10 | 1.19 X | 1.03 X | 3.73 X | |
| SSL | 1.49 | 434 - 174 - 78 - 10 | 2.21 X | 1.04 X | 6.06 X | |
| StructuredBP | 1.55 | 245 - 160 - 55 - 10 | 2.33 X | 1.08 X | 11.23 X | |
| LeNet5 | Original | 0.80 | 20 - 50 - 800 - 500 | 1.00 X | 1.00 X | 1.00 X |
| SparseVD | 0.75 | 17 - 32 - 329 - 75 | 1.48 X | 1.41 X | 2.19 X | |
| SSL | 1.00 | 3 - 12 - 800 - 500 | 5.17 X | 1.80 X | 3.90 X | |
| StructuredBP | 0.86 | 3 - 18 - 284 - 283 | 5.41 X | 1.91 X | 10.49 X |
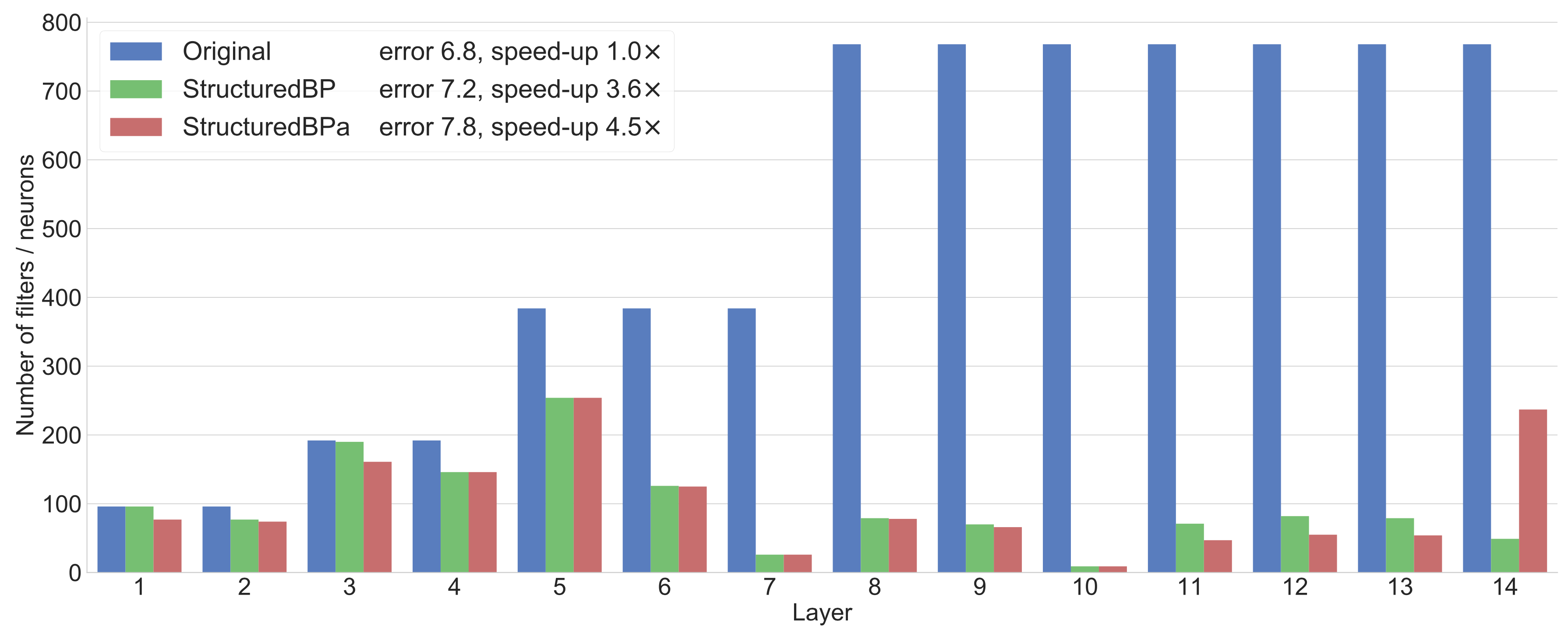
Results for VGG-like architecture on CIFAR-10 dataset. Here speed-up is reported for CPU. More detailed results are provided in the paper.
If you found this code useful please cite our paper
@incollection{
neklyudov2018structured,
title = {Structured Bayesian Pruning via Log-Normal Multiplicative Noise},
author = {Neklyudov, Kirill and Molchanov, Dmitry and Ashukha, Arsenii and Vetrov, Dmitry P},
booktitle = {Advances in Neural Information Processing Systems 30},
editor = {I. Guyon and U. V. Luxburg and S. Bengio and H. Wallach and R. Fergus and S. Vishwanathan and R. Garnett},
pages = {6778--6787},
year = {2017},
publisher = {Curran Associates, Inc.},
url = {http://papers.nips.cc/paper/7254-structured-bayesian-pruning-via-log-normal-multiplicative-noise.pdf}
}















































































