- Code for the paper
- Chainer 2+
- Python 2 or 3
run semi-supervised/regularize_z/train.py
We trained with a prior (a mixture of 10 2-D Gaussians or Swissroll distribution) on 10K labeled MNIST examples and 40K unlabeled MNIST examples.
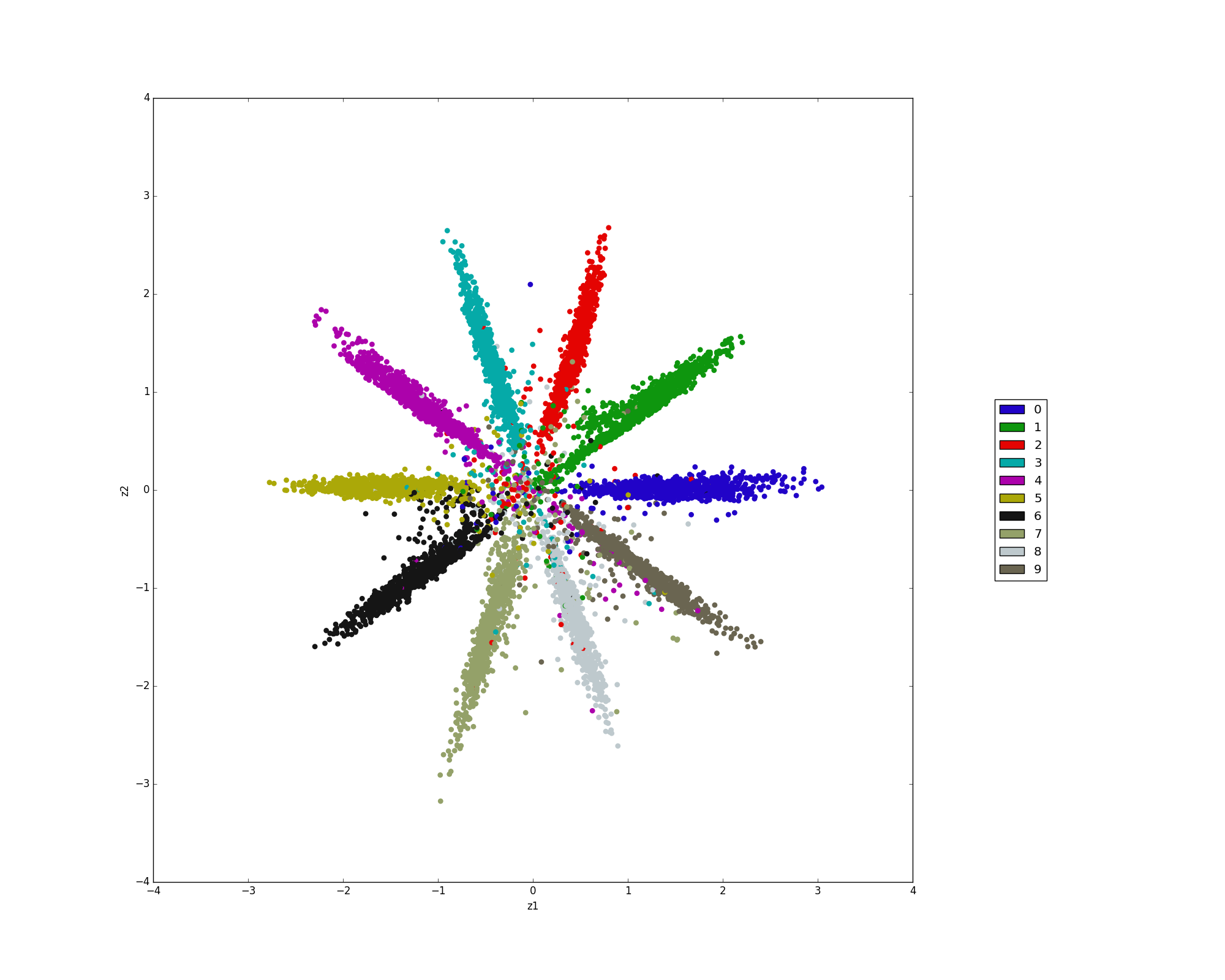
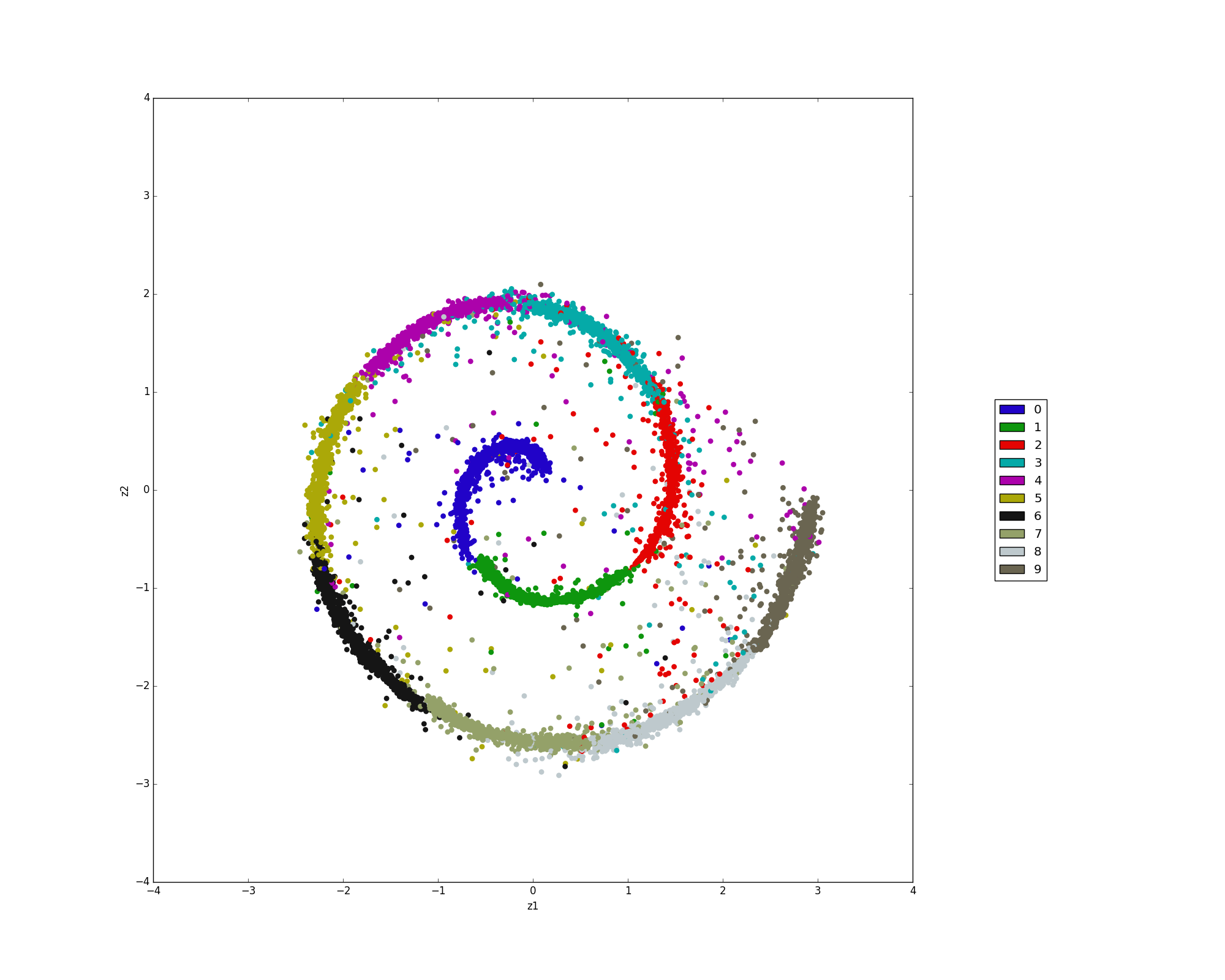
run supervised/learn_style/train.py

run semi-supervised/classification/train.py
| data | # |
|---|---|
| labeled | 100 |
| unlabeled | 49900 |
| validation | 10000 |


run unsupervised/clustering/train.py


run unsupervised/dim_reduction/train.py

run semi-supervised/dim_reduction/train.py




























































































































