BLENDER is a companion program to the DISCOVER-Seq assay to identify off-target CRISPR/Cas editing sites from MRE11 ChIP-Seq experiments described in "Unbiased detection of CRISPR off-targets in vivo using DISCOVER-Seq." BLENDER takes aligned bamfiles from the MRE11 IP experiment and (optionally) a control bamfile and identifies locations with stacks of reads at putative cutsites. PAM sequences can be provided by the user as well as a guide sequence. BLENDER makes use of the ENCODE ChIP-Seq Blacklists for human and mouse which are lists of regions in the genome that have artifactual large numbers of reads. These lists and the control bam plus PAM sequences and the guide are used to filter out false positives. BLENDER runs on mouse mm10 and human hg38 genomes (blacklists coordinates are for these genomes).

As of March 2023, there are two versions of BLENDER.
- "New" BLENDER (aka "BLENDER2") uses the same logic as classic BLENDER, but has been rewritten to be much faster and easier to develop against. BLENDER2 will replace BLENDER for all future uses of DISCOVER-seq. Stay tuned for several updates to BLENDER2!
- "Classic" BLENDER (aka "BLENDER") is the original software reported in Wienert and Wyman et al Science 2019. It is battle-tested but is quite slow. A single run can take 1-2 days on a single CPU, depending on sequencing depth. It is also very hard to develop against, and so new features have lagged behind. BLENDER is provided so that one can compare to historical datasets/results.
BLENDER has a driver script run_blender.sh that takes several argmuments and runs identification of putative hits, filtering of those hits, and then creates an SVG of the aligned hits. Files are stored in the output directory given as a parameter to the bash script. Alternatively, each step can be run separately.
sh run_blender2.sh <path to reference genome> \
<path to IP bamfile> \
<path to control bamfile> \
<guide sequence> <output directory> ["options"]
sh run_blender.sh <path to reference genome> \
<path to IP bamfile> \
<path to control bamfile> \
<guide sequence> <output directory> ["options"]
These will run blender with option c set to 3 (details below), this means the program will run quickly, but may miss some very sparsely covered off target sites. I recommend running it initially with c set to 3 (the default) and then running again with c set to 2. Classic blender may take several days to run, but new blender should complete relatively quickly.
There are two major versions of blender:
- blender2.py: This uses the same logic as blender.pl, but is rewritten to be more flexible and have a much faster backend. It takes approximately one minute for a typical run to complete. It finds the same sites as blender.pl, but with very slight changes to the score. The Corn Lab has switched to using blender2.py, and this version will be the one developed against for all future versions.
- blender.pl: This version was originally published in Wienert & Wyman et al Science 2019. It is very slow, but has been extensively benchmarked. A single-CPU run can take as long as 1 day to complete and the newer multi-CPU mode can reduce this to 1 hour or so if you have many CPUs. It only works with blunt-cutting Cas enzymes that have a cutsite and PAM location identical to SpyCas9.
Faster, more flexible, less tested
pysam https://pysam.readthedocs.io/en/latest/installation.html (best installed via conda)
python blender.py -f <experimental bamfile> -c <control bamfile> -g <guide sequence> -r <reference genome> -b hg38.blacklist.bed > unfiltered_output.txt
python blender.py -f <experimental bamfile> -c <control bamfile> -g <guide sequence> -r <reference genome> -b hg38.blacklist.bed | perl filter.pl > output.txt
BLENDER can be run with or without being piped through the filtering script. There are two filtering scripts provided; the standard filter.pl script that implements the standard scoring scheme, and the filter_pool.pl script that implements the more stringent scoring scheme for pooled samples.

-f --file Experimental bamfile (required). This is the aligned bamfile for the MRE11 pulldown of ChIP-Seq of a Cas9 edited sample. BLENDER will extract the reference sequence fromthis file for use in the analysis. I typically use BWA for alignment, but bowtie2 can be used as well. BLENDER has not been tested with bamfiles from other aligners. Required.
-c --control Control bamfile. This is a ChIP-Seq for MRE11 pulldown from either unedited cells or cells that have been edited with a non-targeting gRNA. If there are greater than 10 reads in the control sample, the hit in the edited sample is filtered out.
-g --guide Guide sequence. Should be provided 5'-> 3' without the PAM sequence. Required.
-p --pams List of 2 nucleotide PAM sequences with spaces between them. The default is GG AG.
-r --reference Reference genome in FASTA format. Must be pre-indexed with faidx so that an accompanying *.fai is found in the same directory as the FASTA-formatted genome. Required.
-t --threshold Threshold for number of read ends exactly at a putative cut site. Default is 3. For maximum sensitivity, this can be set to 2 and the filtering scheme applied. Note that this was formerly option -c in blender.pl, but is now -t to avoid confusion with the control BAM file!
-s --score_min Minimum aggregated score across a 5-base window around the cutsite to consider a hit (default 3)
-m --max_mismatches Maximum number of mismatches to allow to the guide sequence (default 8)
-b --blacklist Blacklist to use for filtering hits, e.g. from ENCODE (BED format)
--verbose This flag will turn on output of filtered out candidates while running if filtered out for more than maximum mismatches (8) in the guide sequence, or the hit occurs in a blacklist region or it is in a very deep region and
thus likely an artifact.
Older, much slower, more tested
Parallel::ForkManager https://metacpan.org/pod/Parallel::ForkManager
sambamba https://lomereiter.github.io/sambamba/
samtools http://www.htslib.org/
perl blender.pl [options] <reference genome> <guide sequence> <IP bamfile> <control bamfile> > unfiltered_output.txt
perl blender.pl [options] <reference genome> <guide sequence> <IP bamfile> <control bamfile> | perl filter.pl > output.txt
perl blender.pl [options] <reference genome> <guide sequence> <IP bamfile> <control bamfile> | perl filter_pool.pl > pooled_output.txt
BLENDER can be run with or without being piped through the filtering script. There are two filtering scripts provided; the standard filter.pl script that implements the standard scoring scheme, and the filter_pool.pl script that implements the more stringent scoring scheme for pooled samples.
reference genome Path to reference genome. If reference has "mm10" in it, then the mouse blacklist coordinates will be used. Otherwise, human is assumed and the hg38 blacklist coordinates will be used.
guide sequence Guide sequence should be provided 5'-> 3' without the PAM sequence.
IP bamfile This is the aligned bamfile for the MRE11 pulldown of ChIP-Seq of a Cas9 edited sample. BLENDER will extract the reference sequence fromthis file for use in the analysis. I typically use BWA for alignment, but bowtie2 can be used as well. BLENDER has not been tested with bamfiles from other aligners.
control bamfile This is a ChIP-Seq for MRE11 pulldown from either unedited cells or cells that have been edited with a non-targeting gRNA. If there are greater than 10 reads in the control sample, the hit in the edited sample is filtered out.
output directory
-p List of 2 nucleotide PAM sequences, separated by commas, in quotes. The default is "GG,AG".
-c Cutoff threshold for number of read ends at a putative cut site. Default is 3. For maximum sensitivity, this can be set to 2 and the filtering scheme applied. BEWARE that this dramatically slows down running time. It can
increase runtime from ~30min to 24hrs, depending on the guide.
-j Number of threads to use (default 1, ideally equal to or higher than the number of chromosomes in the target genome))
--verbose This flag will turn on output of filtered out candidates while running if filtered out for more than maximum mismatches (8) in the guide sequence, or the hit occurs in a blacklist region or it is in a very deep region and
thus likely an artifact.
Both blender.pl and blender2.py have identical output formats.
The automated bash scripts output unfiltered_blender_hits.txt, filtered_blender_hits.txt and blender_hits.svg to the output directory provided by the user. This raw unfiltered output can be used for exploring bamfiles to assess whether adjustments might be needed for the scoring scheme. The output text files have the following columns:
Chr:Start-End Genomic coordinates of the putative guide
Cutsite Where the cutsite is within the guide
Disco score Score given to the hit. Essentially summing a window of read ends around the cut site
Cutsite Ends This is the number of read ends that pile up at the cutsite. When you set the 'c' parameter, it is this value that is set.
Strand/PAM
Guide sequence
Mismatches
The scripts also create an svg image of the hits something like this.
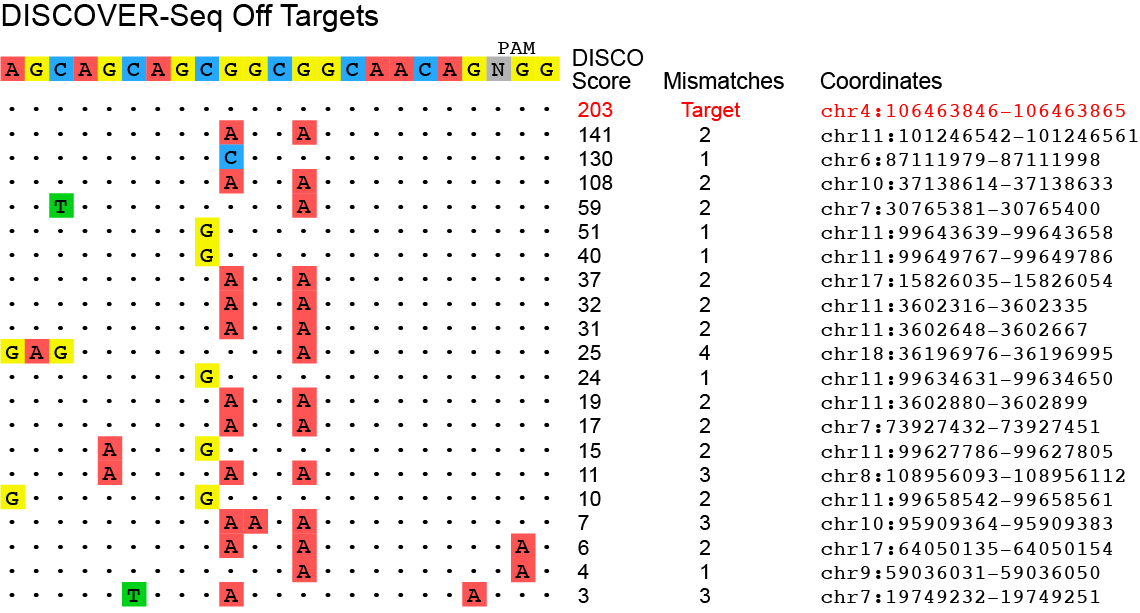
Demo data is included in the DEMO file. The DEMO directory contains data for running BLENDER on a single chromosome (chr19) for DISCOVER-Seq from MRE11 ChIP-Seq of the VEGFA site 2 guide in K562 cells.
Bam files for the IP file and the control file (BFP ChIP) are provided in the bwa directory and expected output can be found in the expected_output directory. Chromosome 19 has three off-target hits.
To run BLENDER on the demo data, use the following command in the main blender directory:
sh run_blender.sh <path/to/reference/genome> \
DEMO/bwa/BW43_VEFGA.chr19.bam \
DEMO/bwa/BW44_BFP_control.chr19.bam \
GACCCCCTCCACCCCGCCTC DEMO/blender
sh run_blender2.sh <path/to/reference/genome> \
DEMO/bwa/BW43_VEFGA.chr19.bam \
DEMO/bwa/BW44_BFP_control.chr19.bam \
GACCCCCTCCACCCCGCCTC DEMO/blender
For BLENDER, this will take approximately a minute or less to run. Runtime for BLENDER2 is about 2 seconds. The three output files can be found in the DEMO/blender directory. Because the bam file is just for chromosome 19, the output figure shows just the 3 hits found on chromosome 19 (image below is for BLENDER, with same sites but slightly different score for BLENDER2)

The fastq files to run this data on all chromosomes can be found in the NCBI Short Read Archive with BioProject Accession PRJNA509652. The links to the fastq files are (click on "Data Access" tab to get fastq download):
VEGFA IP Fastqs (BW43): https://trace.ncbi.nlm.nih.gov/Traces/sra/?run=SRR8550675
BFP control fastqs (BW44): https://trace.ncbi.nlm.nih.gov/Traces/sra/?run=SRR8550676
*Wienert, B., *Wyman, S. K., Richardson, C. D., Yeh, C. D., Akcakaya, P., Porritt, M. J., Morlock, M., Vu, J. T., Kazane, K. R., Watry, H. L., Judge, L. M., Conklin, B. R., Maresca, M. and Corn, J. E. (2019). Unbiased detection of CRISPR off-targets in vivo using DISCOVER-Seq. Science. *contributed equally


