Package implementing additional infix operators for R.
Implemented operators work with 4 different value types: sets,
intervals, regular expressions, and counts.
And provide 3 distinct functionalities: detection, subsetting,
and replacement.
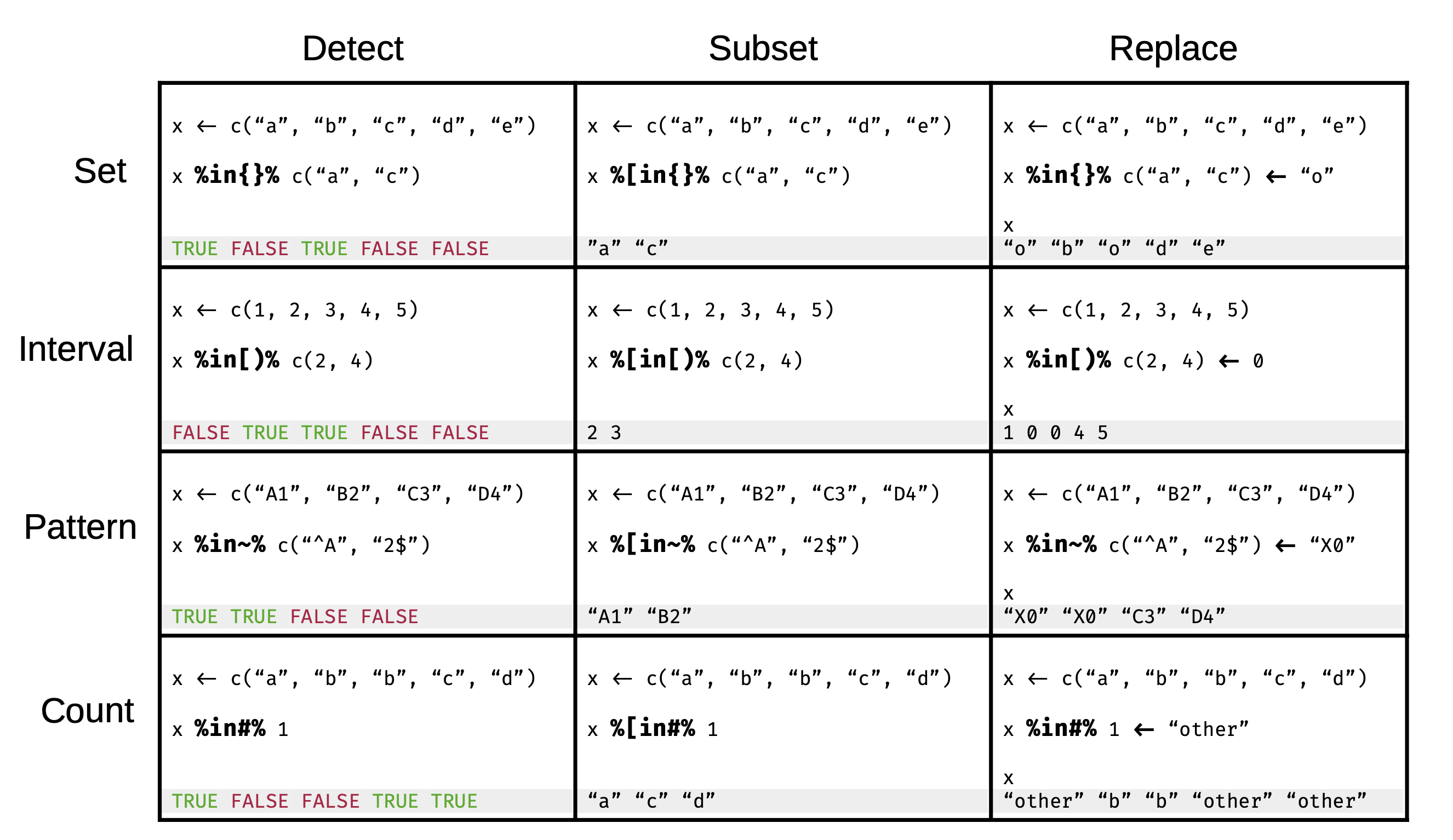
For more examples please see the vignette.
For a complete list of available operators consult the tables below.
All operators have the same form composed of two distinct parts:
%<operation><type>%.
[operation]specifies the performed functionality and can be one ofin,out,[in,[out.[type]specifies the type of operation and can be one of{},[],(),[),(],~,~p,~f,#.
| Form | Description | Call |
|---|---|---|
%in{}% |
which elements are inside a set | x %in{}% set |
%in[]% |
which elements are inside a closed interval | x %in[]% interval |
%in()% |
which elements are inside an open interval | x %in()% interval |
%in[)% |
which elements are inside an interval open on the right | x %in[)% interval |
%in(]% |
which elements are inside an interval open on the left | x %in(]% interval |
%in~% |
which elements match a regular expression | x %in~% pattern |
%in~p% |
which elements match a regular perl expression | x %in~p% pattern |
%in~f% |
which elements match a regular fixed expression | x %in~f% pattern |
%in#% |
which elements occur a specified number of times | x %in#% count |
%out% |
which elements are outside a set (same as ! x %in% y) | x %out% set |
%out{}% |
which elements are outside a set | x %out{}% set |
%out[]% |
which elements are outside a closed interval | x %out[]% interval |
%out()% |
which elements are outside an open interval | x %out()% interval |
%out[)% |
which elements are outside an interval open on the right | x %out[)% interval |
%out(]% |
which elements are outside an interval open on the left | x %out(]% interval |
%out~% |
which elements do not match a regular expression | x %out~% pattern |
%out~p% |
which elements do not match a regular perl expression | x %out~p% pattern |
%out~f% |
which elements do not match a regular fixed expression | x %out~f% pattern |
%out#% |
which elements occur other than a specified number of times | x %out#% count |
| Form | Description | Call |
|---|---|---|
%[==% |
select elements equal to the provided value | x %[==% element |
%[!=% |
select elements not equal to the provided value | x %[!=% element |
%[>% |
select elements greater than the provided value | x %[>% number |
%[<% |
select elements lower than the provided value | x %[<% number |
%[>=% |
select elements greater or equal to the provided value | x %[>=% number |
%[<=% |
select elements lower or equal to the provided value | x %[<=% number |
%[in% |
select elements inside a set | x %[in% set |
%[in{}% |
select elements inside a set | x %[in{}% set |
%[in[]% |
select elements inside a closed interval | x %[in[]% interval |
%[in()% |
select elements inside an open interval | x %[in()% interval |
%[in[)% |
select elements inside an interval open on the right | x %[in[)% interval |
%[in(]% |
select elements inside an interval open on the left | x %[in(]% interval |
%[in~% |
select elements matching a regular expression | x %[in~% pattern |
%[in~p% |
select elements matching a regular perl expression | x %[in~p% pattern |
%[in~f% |
select elements matching a regular fixed expression | x %[in~f% pattern |
%[in#% |
select elements that occur a specified number of times | x %[in#% count |
%[out% |
select elements outside a set | x %[out% set |
%[out{}% |
select elements outside a set | x %[out{}% set |
%[out[]% |
select elements outside a closed interval | x %[out[]% interval |
%[out()% |
select elements outside an open interval | x %[out()% interval |
%[out[)% |
select elements outside an interval open on the right | x %[out[)% interval |
%[out(]% |
select elements outside an interval open on the left | x %[out(]% interval |
%[out~% |
select elements not matching a regular expression | x %[out~% pattern |
%[out~p% |
select elements not matching a regular perl expression | x %[out~p% pattern |
%[out~f% |
select elements not matching a regular fixed expression | x %[out~f% pattern |
%[out#% |
select elements that occur other than specified number of times | x %[out% count |
| Form | Description | Call |
|---|---|---|
==<- |
change elements equal to the provided value | x == element <- value |
!=<- |
change elements not equal to the provided value | x != element <- value |
><- |
change elements greater than the provided value | x > number <- value |
<<- |
change elements lower than the provided value | x < number <- value |
>=<- |
change elements greater or equal to the provided value | x >= number <- value |
<=<- |
change elements lower or equal to the provided value | x <= number <- value |
%in%<- |
change elements inside a set | x %in% set <- value |
%in{}%<- |
change elements inside a set | x %in{}% set <- value |
%in[]%<- |
change elements inside a closed interval | x %in[]% interval <- value |
%in()%<- |
change elements inside an open interval | x %in()% interval <- value |
%in[)%<- |
change elements inside an interval open on the right | x %in[)% interval <- value |
%in(]%<- |
change elements inside an interval open on the left | x %in(]% interval <- value |
%in~%<- |
change elements matching a regular expression | x %in~% pattern <- value |
%in~p%<- |
change elements matching a regular perl expression | x %in~p% pattern <- value |
%in~f%<- |
change elements matching a regular fixed expression | x %in~f% pattern <- value |
%in#%<- |
change elements that occur specified number of times | x %in#% count <- value |
%out%<- |
change elements outside a set | x %out% set <- value |
%out{}%<- |
change elements outside a set | x %out{}% set <- value |
%out[]%<- |
change elements outside a closed interval | x %out[]% interval <- value |
%out()%<- |
change elements outside an open interval | x %out()% interval <- value |
%out[)%<- |
change elements outside an interval open on the right | x %out[)% interval <- value |
%out(]%<- |
change elements outside an interval open on the left | x %out(]% interval <- value |
%out~%<- |
change elements not matching a regular expression | x %out~% pattern <- value |
%out~p%<- |
change elements not matching a regular perl expression | x %out~p% pattern <- value |
%out~f%<- |
change elements not matching a regular fixed expression | x %out~f% pattern <- value |
%out#%<- |
change elements that occur other than specified number of times | x %out#% count <- value |
- Overloading
To give an assignment counterpart to < we had to overload the <<-
operator, which explains the message when attaching the package. This
doesn’t affect the behavior of the <<- assignments.
- Behaviour
Detection operators should be seen as an extension of the standard infix
operators implemented in R (i.e. ==, >, etc). For this reason the
implemented operators differ from standard %in% and behave more like
== on data.frames and objects with NA values.
Subsetting and replacement operators are wrappers around detection
operators.
Subsetting: x[ x %in{}% set].
Replacement: replace(x, x %in{}% set, value).
Other similar packages you might be interested in.










































