monero-project / research-lab Goto Github PK
View Code? Open in Web Editor NEWA general repo for Monero Research Lab work in progress and completed work
A general repo for Monero Research Lab work in progress and completed work























































































































































Started here, a simulation of a coin-agnostic cryptocurrency network can be used as a sandbox/playground for testing new approaches to consensus or difficulty. These simulations should be fleshed out more, better commented, made visually appealing, but more importantly: useful information needs to be extractable from the transcripts of the simulations.
I'm going to leave notes on various papers on things like accumulators, verifiable constructions, etc, as I read through them here.
Request for Comments: MRL Conflict of Interest and Financial Disclosure Guidelines
Sarang Noether and Brandon Goodell
Many people contribute to the Monero Project and its workgroups like the Monero Research Lab (MRL). We want to ensure that contributions to MRL are done honestly and in good faith.
It is far too common for contributors to other projects and the literature not to disclose associations, funding, and other conflicts of interest, or to engage in bad faith discussion/debates that may lead a reasonable person to question the motives for their work or the results of their efforts. Community trust in the MRL research process and the credibility of MRL research partly depends on the transparent disclosure of conflicts of interest and clear compliance with ethical standards, which includes how these conflicts are handled at every stage of our research. This helps readers understand where our work comes from and what may influence it.
We have written the following sample guidelines on how to contribute to MRL honestly and with good faith. These are certainly non-binding, as we are a headless organization involving disparate contributors, but these are the standards by which we would like to hold ourselves. We hope that members of the community can provide comments, so that we can structure this in a way that satisfies both scientists at MRL and the Monero community at large.
Sample Guidelines
Disclose financial conflicts. If you have any financial relationship that is affected by work at MRL, or if your work at MRL may be affected by such a financial relationship, clearly disclose this relationshiop. This does not forbid conflicting individuals from contributing. After all, anyone paid by the community to research Monero technically has a financial conflict, and should disclose it.
Disclose relevant competition. If you do outside work that competes with MRL, clearly disclose these activities. This does not forbid contributors from contributing to other projects. After all, most members of the Monero community contribute to many projects and/or have careers outside of the Monero workgroups.
Report vulnerabilities responsibly. If you find a vulnerability in any project (including Monero), clearly disclose that vulnerability responsibly in a way that minimizes the risk to the users of that project, and ensure that the folks who are responsible for fixing the vulnerability gain enough information to do so.
Discourse in good faith. If you hold events or discussions about Monero, do not provide observers with reasons to question your intellectual honesty or your motives for contributing at MRL. This means to not troll, scam, refuse to admit mistakes, demand unreasonable standards of evidence, and so on. If you have to ask if you're contributing in good faith, you might not be.
How to Responsibly Disclose Conflicts
Publications and Code. If you have a conflict of interest and your contributions become part of some MRL document or codebase, disclose your conflicts to other MRL contributors and ensure that the document or code makes a clear note of your conflict. This may mean inserting a statement/comment declaring that the supporting source had no involvement. Otherwise, it means inserting descriptions of all sources of financial support for the work along with explanations of the role of those sources if any in study design, analysis and interpretation of data, writing of the document/code, or the decision to submit the report for publication.
Media and interviews. Contributors to MRL are sometimes asked to participate in interviews or other media appearances to discuss MRL research or the Monero Project. You should always disclose conflicts of interest to the interviewer or journalist. Since MRL is not a formal organization, you should also make it clear that the things you say or write in the interview are your own views, and don't necessarily represent those of the Monero Project, the Monero community, or other MRL contributors. We all speak for ourselves, and the public should never assume that you formally represent others.
Privately. If you want to participate in MRL research but are concerned that revealing details about your conflict poses a threat to your privacy or personal safety, you should disclose to your MRL collaborators the fact that a conflict exists (although certainly details are left up to you). Your collaborators can decide if they need to approach your contributions with greater scrutiny or how to otherwise proceed.
Summary
Our proposed policy can be easily boiled down: be honest and participate in good faith. Nothing here is set in stone. Our work should be judged on its own merits, and concerns about our integrity should never stand in the way of progress at the Monero Project. Or, think about it as a deeper version of Wheaton's law: DON'T BE AN ASSHOLE.
If you have questions, comments, etc., please open an issue so that the community at large can discuss it.
From the abstract: "elaborates upon exactly what the offending blcok did to the network."
blcok -> block
(OUTDATED, see this comment down below)
Monero addresses are (K_v,K_s), with private keys (k_v,k_s) corresponding to 'view' and 'spend'. One time addresses are constructed based on the 'transaction public key' rG (for the simple non-subaddress case). A one-time address (aka stealth) is K^o = H_n(r*K_v,t)*G + K_s, where H_n() is a hash to scalar function, and t is the index of the output to which the address-holder is being given spend-rights.
An address holder can use his view key to search for owned outputs. He finds rG and K^o in a transaction's data, then calculates k_v*rG, and K'_s = K^o - H_n(k_v*rG)*G, and checks K'_s ?= K_s. If they match, then he owns the output and may spend it by signing an MLSAG with the private key k^o = H_n(k_v*rG,t) + k_s.
Currently the only way to know if an output has been spent is to calculate the key images of all owned outputs, then check if any of those images have appeared in the blockchain before. Calculating a key image KI requires the private spend key k_s, since KI = k^o*H_p(K^o) (where H_p is Monero's unique hash-to-point algorithm), and since k^o is partly composed of k_s.
This reality is somewhat confusing, since a 'view' key can't actually be used to view an address' balance (sum of unspent owned outputs)!
My proposal is a new 'viewspent' public key for every input to a transaction. This public key will be stored in the transaction extra field, and not verified as part of the protocol. It will exist merely as a convenience that transaction authors create for themselves, so their view-only wallets may easily and safely recognize an address' balance. It may not be rigorous enough for an audit environment, where all key images of known owned outputs are required (even though this will leak future spends of those outputs), since transaction authors are free to create fake viewspent keys. Since one-time addresses themselves, and view keys by extension, are not part of the protocol (someone may do like Bitcoin, and assign output ownership by including an address directly in transaction data, though all other wallets would not be able to interact with those outputs), I do not view this audit-related drawback as a real detriment to the proposal. View keys and one-time addresses are essentially conveniences to begin with, so viewspent keys are on a similar level to the transaction public key.
Viewspent key: K_vs = (k_s/k_v)*H_p(K^o)
Check for spent: KI - k_v*K_vs ?= H_n(k_v*rG,t)*H_p(K^o)
Users only need to check for spent when one of their owned outputs is referenced in the input ring of a transaction (and only when not already identified as spent), which should only require per-owned-output checks on the order of the ring sizes themselves (11 currently), an insignificant amount of scanning compared to finding owned outputs in the first place.
The view key's inverse (1/k_v) is included to prevent the person who originally created an output from using the sender-receiver shared secret rKv to realize the recipient spent that output.
Bonus: I recommend deprecating the extra field's 0x01 tag, and using 0x04 exclusively (extra pub keys) since the keys from this proposition can be randomly shuffled amongst the transaction public keys. Randomly shuffled pub keys is beneficial to tx join protocols that want to use a promising in-consideration mitigation for the Janus attack.
UPDATE1: within the extra field, separate viewspent keys into its own type sub-field, to reduce unnecessary scanning for owned outputs.
Sublinear ring signatures have been proposed before in multiple contexts and settings, including bilinear pairings and LWE approaches, and so on. For implementation, we must look at the total time to download and verify the blockchain, assuming that these two processes (downloading and verifying) must occur in disjoint intervals of time. For a sublinearly sized blockchain, download time is sublinear, but ring signatures always require at least a linear amount of time for verification for the first time they are verified; batching and other optimizations may bring this to be sublinear after the first verification. SNARKs and STARKs avoid this, essentially, by verifying only once (although this is a mischaracterization, it isn't relevant to our desired tech note).
If the ring sigs are logarithmically sized, this introduces an exponential space-time tradeoff: worsening verification time by a small percentage can only be "made up" by making total space very very much smaller. Or, to think of it another way: saving a tiny bit of space in exchange for a tiny bit of verification time is not a good trade.
We would like a technical note that details this trade-off and establishes some standard or rule by which future Monero contributors can judge whether to trade-off between space and time. For example, with the improvements made by bulletproofs, transactions have been made both smaller and faster to verify, allowing us some extra room in spacetime for increased ring sizes.
Monero transactions have an extra field that is not verified (see this stackexchange question for all the details I could figure out about how it is actually used). So long as it's in the right part of the transaction structure, and does not force a tx outside the maximum tx weight, any kind of data may reside inside it. Moreover, there are no clear standards about how to implement those fields for tx construction.
A heuristics-based analysis of transactions' extra fields reveals a lot of so-called 'anonymity puddles', which are essentially fingerprints of different implementation methods. Pools which use different size extra nonces to keep track of miners, and the sub-field sorting method (1 vs 2; standard implementation sorts using sort_tx_extra()), are clear examples. Thanks to Noncesense Research Lab researchers Isthmus and N3ptune for their work investigating this problem.
It's important that the extra field remain open ended to maintain flexibility in the face of an unknown future. It's also important, in line with the Monero Project's interest in fungibility and privacy, that users only lose privacy because they choose to (opt-out privacy), and not because there is no clear anonymity pool. This proposal aims to retain the extra field's flexibility while also creating an environment for straightforward implementation consensus.
The Electric Coin Company just published a new zero-knowledge proof scheme that allows for recursive composition without the need for a trusted setup. There's a reference implementation Rust by Sean Bowe: https://github.com/ebfull/halo.
I'm posting this here since it could tie into the research that @b-g-goodell , @RandomRun and @SarangNoether are doing.
Here's the paper: https://electriccoin.co/wp-content/uploads/2019/09/Halo.pdf
For easy checking of recipient addresses before sending, a utility for visualizing an address as a unique seashell can be found here; when displaying a public key for receiving Monero, a recipient should also display the corresponding seashell, and a sender ought to be able to generate that seashell locally on their own device (or several) to verify that the recipient address is correct.
Simple utility, can save a lot of headaches, but requires some nontrivial security precautions to avoid a MITM attack, requires the attention of a designer or someone good with 3d rendering, and so on. Lots of work to be done; the math part is easy (and mostly finished, color and texture maps notwithstanding).
The difficulty research that Surae was working on is quite extensive, but incomplete.
Someone would have to pick it up and run with it, as Surae is basically burnt out on difficulty and has moved on to other challenges:)
The DLSAG preprint specifies a method for applying hidden timelocks to its dual-key output construction.
Even without DLSAG or its intended non-interactive refund mechanism, it's possible to integrate hidden timelocks into the Monero protocol. Outputs come equipped with a separate Pedersen commitment to a lock time (using a standardized time format, either blocks or timestamps). Ring signatures are extended to include another key vector dimension. Signers produce an auxiliary commitment to the same time, but with a random mask, and include this offset as part of each ring member in signatures. Then, the signer chooses a random (not necessarily uniform) auxiliary time value between the lock time and the current time, and includes this in the clear; it generates a particular range proof demonstrating that the difference between the auxiliary time value and the (hidden) time value in the auxiliary commitment is positive and range-limited.
It's not feasible to include this functionality using MLSAG signatures, since this would require the addition of a separate set of scalars that scales with the ring size. However, including it with CLSAG signatures adds only a single group element. Adding them to Triptych would also add a single group element. There is an added computational complexity for the verifier (and prover) that, at first estimate, would negate the time savings from an MLSAG-CLSAG migration.
This functionality could be mandatory or optional, depending on the risk assessment.
Hi all.
I was reading the Lelantus paper to try to figure out a way to mitigate the sender detection problem with its key image format while retaining the good scaling properties, and ended up reading the One-Out-of-Many Proofs paper, which is one of its main components. I think that maybe the 1ofMnay construction could be used to yield another linkable ring signature using linking tags similar to current Monero key images, and that, due to their use of Hp(.), cannot be detected by the sender.
Here is my summarized understanding of what the One-Out-of-Many Proofs do, based on this version of the paper (mostly pages 11 through 14):
The proof takes in a collection of 2^n points, such that, at a position l, is of the form c_l = g^r (for some secret r known only to the prover), and allows the prover to convince the verifier of his knowledge of r by producing a point whose discrete log wrt the base point g is:
z_d := r*x^n + sum(\rho_k*x^k for k in [0,n-1]).
Notice that the value of the other commitments c_i do not affect the value of z_d. It only depends on r and the \rho_k's which were chosen randomly by the prover. Any contribution from the other c_i's only seem to affect only the c_dk values, and those contributions are removed during the proof.
As the paper mentions, producing such z_d in this manner can already be viewed as a (non-linkable) ring signature.
Modified linkable scheme:
Now consider what would happen if we formed the auxiliary ring (Hp(c_i)), for i in [0,2^n]. At position l we have Hp(c_l), and if we could prove that the discrete log of that point with respect to some other point is also r using the same parameters as the first proof, then they both would output the same z_d! And indeed, the point J that satisfies DL(Hp(c_l), J) = DL(c_l, g) = r is J := Hp(c_l)^(1/r), which is unlinkable to c_l. J will be the linking tag which, in the context of transactions, will be used to prevent double spend.
At the beginning of the proof the prover provides J to the verifier, so they know to run the first part of the protocol wrt to g (and stop right before the verifier would select x) and then repeat the procedure, replacing g by J everywhere it occurs, but keeping the same parameters r_j, a_j, s_j, t_j and \rho_k. (In fact, the values r_j, a_j, s_j and t_j are only used to show that the index l committed is indeed a sequence of zeros and ones of size n and therefore this may be run only once to compute the f_j's, which are just numbers. Indeed, it looks like the only thing that will incur an extra cost is computing the new c_dk's.)
Once once that is done, the random oracle picks a single random challenge value x that should be used in the two proofs. And if the prover has acted honestly, then the two values of z_d will match. (Correctness)
If the prover messes with the \rho_k's or r (when defining J) then, since the z_d's will be different polynomials in x, the chance of the z_d values coinciding will be negligible. Also the index l will be the same, provided that the same f_i's are used in both proofs (otherwise the same signer could produce multiple linking tags), so making sure that this happens is an important part of the verification. (So it seems plausible to me that this scheme will be unforgeable too, but it still requires proving, of course)
Please let me know what you think.
It's possible to generate proofs for incoming and outgoing transactions of knowledge of either the transaction private key or the recipient private view key, using two-component Schnorr proofs. However, the challenge used in the proof generation and verification functions does not include all public proof parameters.
Disclaimer
What follows is not a proposal but rather just me wondering about what seems to be a natural idea for improving usability while waiting for a full node to synch. I don't understand the security implications of enabling these changes and I am half expecting there to be some clear problems about it, so I am posting this here is the hopes of understanding the possible drawbacks.
TL;DR: Include key image set (KIS) commitment in block headers to allow for transaction validation while full node is still synching, and optionally add also a commitment to the one-time address set (OTAS) to headers so that new nodes can get their wallet balances fast. That is, as a regular validator validates the chain, he should include or expect to see in each block header a commitment for the state at that height. In something like Bitcoin that would roughly correspond to the UTXO, and in Monero that would be the KIS and OTAS.
Brief overview of the issue
From what I understand, once a new node joins the network it will roughly ask its peers for the current height and accumulated difficulty, and following that it will receive batches of 10 thousand block header hashes, and then batches of 20 blocks at a time that match those hashes. It will verify the contents of those blocks for proper signatures, possible double spends etc. As it goes it builds the key image set (KIS) that it uses to prevent double spending of funds going forward.
This process can take up to a few days, which is a very long time in any case, but it can be especially frustrating for new users.
Redundant verification and immutability
The verification of the blocks contents is an expensive process that is repeated by every full node, and the further deep a block is buried in the blockchain, the harder it is for an attacker to change its contents.
What I am wondering is: can we rely on this immutability through PoW to start operating as a validating node after verifying the PoW, but before completely validating all the blocks contents?
The goal is for a fresh new node to know, with high probability:
(i) that it is in possession of the right block-headers chain; and
(ii) its own wallet balance.
Intuitively, if we know that we are looking at the longest PoW chain, then we may be content to verify that a properly signed transaction references only coins created in blocks that are buried at least N blocks deep, and that there is no double spend happening.
So, if a ring contains a coin C1 that was created by a transaction T1 that is buried at depth N1 >= N, then we are satisfied; if it also contains a coin C2 created in a transaction T2 buried at depth N2 < N, then repeat this process until verifying each coin's genealogy up to depth N. If all the coins involved can have their genealogy established in this way, and there is no double spend detected, then the transaction is deemed valid and is relayed to other peers.
Here imagine that N is big enough that there has been enough time for all the full nodes on the network to have validated the entire contents of the blockchain, its PoW etc, and resolved any crisis situation from an attack or big reorg.
How to check for double spend attempts?
In the process described above, the new node would have to somehow know what the KIS was at present height. One way to do that would be to have other nodes provide it to him. But how does he know that the reported KIS is the right one?
If he could check the KIS commitment (say its hash) somewhere authoritative, then it would just be a matter of checking that for the reported KIS he is getting from his peers. So a natural way to solve this would be to include, in each block header a field where the block producer would record the KIS commitment at that height. And of course requiring by consensus rule that the validators check that that is correct.
So if the fresh new node wants to start the "fast synch" from depth N, it would (momentarily) trust immutability of the chain and not check the coins genealogy beyond depth N (at first), and also, it would ask for the KIS at depth N. Then he would ask for all the blocks from depth N up to current height (and validate its contents) to get the new key images.
It will still work as a full node
The process described is only meant to give the new node some functionality while it is getting fully synched. That is, while it is doing its validation up to depth N, it will also be querying for the remaining blocks like it would normally, it is just that in the normal setup it would be unusable during the synching stage.
Note that it doesn't matter the order in which it validates the blockchain, although starting from most recent blocks makes more sense since that is where most of the ring members are sampled from, and presumably most users will be looking for coins recently received more often than scanning for really old coins.
Getting the balance
During synching, the new node can already start looking for coins belonging to its wallet, and being in possession of the KIS from the beginning at least guarantees to the user that whatever coins the wallet finds, its provisional balance can only increase, since the wallet can know immediately if a newly found coin has already been spent.
In fact here, if the goal is to make it possible for the user to find its balance right away, then another piece of information that could be added to the block header is the commitment to the one-time address set (OTAS), that is the list of all public keys, and transaction or output key, (P,R) associated with each coin in existence up to that block's height.
If the new node can query for the OTAS at depth N, then it can know even before start validating the chain where its coins are, and whether they are spent (from KIS). It may not be good practice from a privacy point of view to ask directly for the specific blocks containing those coins only, but at least the node knows what information it is most interested in and may get those coins blocks sooner.
Some notes:
(i) I use the term commitment, as opposed to hashing, because I am not sure that simply hashing a big piece of data at every block is necessarily the best way to do it. There may be other ways to structure this commitment that may be more efficient, given that the KIS and OTAS may just increase a tiny bit from one block to another.
(ii) If this idea happens to be sound, a similar approach could work in Bitcoin by committing the UTXO in each block instead. The question of how to commit the UTXO may be more interesting since the UTXO constantly has elements added as well as removed from it.
(iii) There is still the matter of simply validating the PoW on the purported longest chain. In my experience (~80 hps), it might take more than 6 hours just to completely validate the hashes. I am not sure what can be done about this, short of checkpointing (which I believe is already done) and using a higher hash rate PoW algorithm going forward.
I believe it's time to seriously review the proof of work algorithm used in Monero in light of the very serious consequences we have all witness with mining centralization in the Bitcoin community.
Mining centralization takes some obvious and non obvious forms. Miners can centralize the network simply by accumulating a majority of hashrate which may be easier to do when there is only specialized hardware from limited sources.
The second form of centralization is more insidious, which is also currently observed in the Bitcoin mining ecosystem where one company commands the monopoly on ASIC hardware supply. This is detrimental to decentralization because the company is able to exert economic force against both competitors and it's own customers. Because they are the major supplier, new players can be quickly starved out of the market through anti-competitive pricing designed to suffocate a new company. In the case of customers, since there is an unlimited demand for mining, and a scarcity of equipment, mining equipment customers can be coerced economically with threats of ceasing new sales. All these things encourage and enforce a cartel that is both difficult to see, and difficult to tame.
It is unclear if the Monero proof of work can be optimized by specialized hardware.
Clearly the best defense against mining hardware monopoly is to make it uneconomical or impossible for specialist hardware to be created for Monero. If the proof of work is only viable on commodity hardware, such as GPU, it's much harder for a manufacture to dominate because GPUs have a wide range of applications and thus plenty GPUs available in the world from a diverse set. CPU only algos are obviously problematic due to botnets from hacked computers. GPUs don't suffer this problem since GPU hijack would be very obvious on PCs.
In any case, I believe Monero is in a precarious situation and given the clear lessons from Bitcoin, we should take proactive action to ensure Monero does not become the center of a similar situation.
Linkability in Monero is one of the older topics at MRL. It has been studied before (see here, here and here); recent set-theoretic results (see here) and the start of some graph-theoretic results (see here, in progress) have added to our body of knowledge.
We would like a technical note or an MRL bulletin compiling these results in a convenient location. MRL is aware of at least one paper in preparation by outside researchers studying this problem, with results including, in part, the difficulty of finding a complete list of all "provably spent" outputs (previously called blackballed outputs, we now refer to these as dead outputs) as belonging to a class harder than NP (see here).
With @SarangNoether finishing the DLSAG technical note and the completion of thring signatures, we are now capable of most payment channel infrastructures in Monero (a fulmo network, if you will).
MRL is aware of at least one paper in preparation by external researchers describing variations on hashed timelock contracts for Monero; we need to get these descriptions compiled in a convenient place for eventual implementation.
Hi all,
I'm just wondering what is the current state of the Mininero source code. It seems to have plenty of useful code implemented in python 2 but at the same time it seems to be slightly outdated in comparison with what is implemented in C++ project [ https://github.com/monero-project/monero ]. The updated and well documented python implementation like that could be useful for research and education of people trying to understand complexities of C++ code in main monero project.
Can anyone find useful to get updated version of this project (also ported in python3)?
The threshold ring signature paper by @b-g-goodell and I describes a provably-secure construction requiring a commit-and-reveal phase. The current multisignature implementation should be updated to reflect this construction properly.
A swap proposal from h4sh3d was introduced a while back, using XMR and BTC in particular: https://github.com/h4sh3d/xmr-btc-atomic-swap
The proposal assumes, among other things, a zero-knowledge proof of equality of the preimge of a given SHA-256 hash and the discrete log preimage of a given ed25519 group element. The original Bulletproofs paper provides timing examples for a circuit with this capability.
It would be useful to examine the entire swap protocol in more detail, as well as determine the feasibility of such a preimage equality zero-knowledge proof.
After asking this question on SE and getting answer from Luigi pointing me to the code, I think I finally figured out how the simplified version of RingCT works, as in the note below (which is a modification to MRL-005):
https://www.overleaf.com/read/xyhymkfjfqmn
If my understanding is correct, shouldn't this be formally published under MRL?
My second question:
As I see it, each ring has a 2x(q+1) matrix containing pairs of (P,C), and also has 2 key images. I think the second key image corresponds to the commitment to zero, which seems unnecessary (we've already checked the double-spend with the first key image). Can't we skip the second key image to make the signature size even smaller?
With the completion of Zero to Monero (see here), the urgency of this has decreased. Having said that, we should like to provide a series of short standards (see the CryptoNote standards as an example) explaining the usage of each individual element in Monero and how it all comes together.
This is a very descriptive project, all about documentation, rather than a research project.
Currently, the number of transaction public keys included in a transaction can, in some cases, reveal that one or more outputs are directed to subaddresses. A mitigation is to uniformly include a separate transaction public key for each output.
It is my understanding that right now the Monero MLSAG signature contains two sequences of scalars. Their use is to separately and respectively ensure linkability and that the commitments for the amounts add up to zero. (I am basing my understanding from posts about ringCT (e.g. here), and although I am aware that Monero now uses Bulletproofs, I believe that the MLSAG part should still be the same, since, to my knowledge, bulletproofs integration only affected the range proofs.)
So, to recap and make sure that I got the right picture, this is what I think goes on now:
Signing:
Signer picks a ring of outputs that includes his own output, plus decoys. The simplified ring information needed for signing looks like this:
Ring = (P_i, C_i) for i in [1,n+1],
where C_i is already denoting the committed amounts for each P_i, subtracted the commitments for the new output amounts being created in the transaction being signed.
(WLOG and to simplify the exposition, we assume that his output is at position n. I.e., the signer knows scalars p_n, c_n such that (P_n, C_n) = (p_n*G, c_n*G). Also, in what follows I will omit the transaction message from the hashes Hs just to simplify notation but in reality they should be there, of course.)
Next, he picks two sequences of random scalars: s'_0, s_1, ..., s_{n-1} and r'_0, r_1, ..., r_{n-1}. He computes:
L_0 := s'_0*G
R_0 := s'_0*Hp(P_n)
S_0 := r'_0*G
h_0 := Hs(L_0||R_0||S_0),
and, for i in [1,n], computes:
L_i := s_i*G + h_{i-1}*P_i
R_i := s_i*Hp(P_i) + h_{i-1}*I
S_i := r_i*G + h_{i-1}*C_i
h_i := Hs(L_i||R_i||S_i).
Finally, he sets:
s_0 := s'_0 - h_{n-1}*p_n, r_0 := r'_0 - h_{n-1}*c_n, and
sig := (h_0, s_0,..., s_{n-1}, r_0,..., r_{n-1}, I).
Verification:
Verifier parses the signature information and computes, for i in [1,n+1]:
L_i := s_i*G + h_{i-1}*P_i
R_i := s_i*Hp(P_i) + h_{i-1}*I
S_i := r_i*G + h_{i-1}*C_i
h_i := Hs(L_i||R_i||S_i).
If h_0 = h_n, then it passes verification.
If that understanding is correct, I am wondering if that signature cannot be made shorter by completely eliminating the S_i component and the r_i's from the signature.
That would entail redefining L_i and R_i to aggregate, respectively, C_i and C' := c_n*Hp(P_n).
The Naive Approach and the problem with it:
The naive approach would be to just add C_i and C' to P_i and I, respectively, and redefine:
L_0 := s'_0*G
R_0 := s'_0*Hp(P_n)
h_0 := Hs(L_0||R_0),
for i in [1,n]:
L_i := s_i*G + h_{i-1}*(P_i + C_i)
R_i := s_i*Hp(P_i) + h_{i-1}*(I + C')
h_i := Hs(L_i||R_i)
Finally, redefine:
s_0 := s'_0 - h_{n-1}*(p_n + c_n)
sig := (h_0, s_0,..., s_{n-1}, I, C').
This naive approach already has the advantage of passing the corresponding verification for an honest signer and having a shorter signature. However, it also has a big problem: since the verifier has no way to check that I and C' were produced honestly, a malicious signer could easily provide random points I' and C'' such that I + C' = I' + C'', thus allowing him to create new coins undetected.
Solution: Use a Linear Combination with Hashed Coefficients:
To fix that, before redefining L_i and R_i, the signer computes:
mu_P = Hs("points", Ring, I, C')
mu_C = Hs("amounts",Ring, I, C').
Then he proceeds to define:
L_0 := s'_0*G
R_0 := s'_0*Hp(P_n)
h_0 := Hs(L_0||R_0),
and, for each i in [1,n]:
L_i := s_i*G + h_{i-1}*(mu_P*P_i + mu_C*C_i) = s_i*G + (h_{i-1}*mu_P)*P_i + (h_{i-1}*mu_C)*C_i
R_i := s_i*Hp(P_i) + h_{i-1}*(mu_P*I + mu_C*C') = s_i*Hp(P_i) + (h_{i-1}*mu_P)*I + (h_{i-1}*mu_C)*C'.
h_i := Hs(L_i||R_i)
Finally, he sets:
s_0 := s'_0 - h_{n-1}*(mu_P*p_n + mu_C*c_n)
sig := (h_0, s_0,..., s_{n-1}, I, C').
This way, the honest signing still passes the corresponding verification, but any attempt to find I' and C'' such that the linear combination mu_P*I + mu_C*C' = mu'_P*I' + mu'_C*C'' holds would fail, except with negligible probability, since the values of mu'_P and mu'_C would change unpredictably.
This signature format change would incur only the additional computational cost of two Hs operations, and two extra scalar multiplications per ring member, and the space cost of containing the extra point C'.
[Edit: I had forgotten to add C' to the definition of the hashed coefficients, but all points involved in the linear combination should be included, of course.]
We would like to see an investigation into the feasibility of placing STARKs (or even SNARKs? how about SNACKs? SHARKs?) inside bulletproofs, or just some general framework for how to begin that sort of process.
(note: moving this from Issue #58 for proper scope).
We can prove a given key image does NOT correspond with a one-time address from its corresponding ring. The verifier doesn't require the view key, although in an audit environment the view key is likely to be known so the auditor can verify which outputs are owned in the first place. This proof can be used to show an output has not been spent, without leaking its key image which would reveal when it's spent in the future. It can be implemented right now without changing how transactions are constructed.
Preliminary: assume the verifier knows r*K^v, the sender-receiver shared secret for a given owned output with one-time address K^o and transaction public key r*G. He either knows the view key k^v, or the prover provided r*K^v (or created a 2-base proof like below on the base points G and rG with signing key k^v) which allowed the verifier to calculate the owned-output check K^o - H_n(r*K^v,t)*G ?= K^s so he knows the output being tested belongs to the prover. Proof functions H_n() and H_p() create scalars and curve points respectively.
K^o is referenced in the ring of a transaction, take the key image to be tested KI_? of that ring signature.G, spend key K^s, and computed point KI_? - H_n(k_v*rG,t)*H_p(K^o): signing key k^sG and H_p(K^o): signing key k^s*k^sk^s[KI_? - H_n(k_v*rG,t)*H_p(K^o)] != k^s*k^s*H_p(K^o)This seemingly roundabout approach prevents the verifier from learning k^s*H_p(K^o), which he could use in combination with the view key to compute the real key image for that output, while leaving him confident that the tested key image doesn't correspond to that output.
In fact, the prover only needs to do proof (a) for each key image to be tested. There should only be on the order of 11 (current ring size) tests per owned output, since that's around how many times an output is likely to be included in rings as decoys.
We believe a Monero sidechain employing sapling without a transparent pool, with one-way deposits from the Monero main chain onto the (possibly untrustworthy!) sapling sidechain would provide Monero users the nice ability of being able to rely upon the untraceability of Monero RingCT to prevent the sort of traceability analyses seen in Zcash seen here, here, and here without running the risk associated with using an untrustworthy zcash trusted set-up causing a "minting money out of thin air" problem on the main Monero chain.
In the proof it is assumed, by contradiction, that there exists an adversary A that is able to forge the ASNL, but later on something much stronger is assumed, namely that A somehow knows the discrete logs of L-values to be numbers a and b. I don't see how that could be implied by A's ability to produce a forged signature. Isn't it possible that A has a way to produce L- and s-values that form a valid signature without knowing the discrete log of the L's? If so, the proof shouldn't use the numbers a and b.
Light nodes for wallets
Requirements/objectives
Note1: this Lee-Miller paper (prefixing the url with 'sci-hub.tw/' might gain access to the pdf) describes a similar approach, in which wallets still have to cooperate with remote nodes to build transactions. My proposal is a more advanced self-reliant local light node which focuses on maximal pruning for user convenience, without sacrificing the basic abilities of a node. The Lee-Miller suggestion for conflict resolution between different queried nodes might be worth further consideration.
Note2: my proposal may be similar to SPV Bitcoin nodes, although I have not looked into it.
Method
Creating a new light node, or adding recently mined blocks to it, involves downloading blockchain data, extracting all useful information, and discarding the rest. Prunable transaction data does not need to be downloaded, just its hash which goes into the ordinary transaction merkle tree as part of verifying a block's proof of work.
Information stored
The number of owned outputs is negligible in comparison to the total number of outputs, so by using the block ID merkle checkpoint method the vast majority of data stored will be one time addresses and output commitments for outputs. This turns out to be ~2 GB of storage per 30 million outputs on the blockchain.
Note that bitcoin currently has 500 million transactions on the blockchain, which implies around 800-900 million outputs, so our light node would require ~60 GB, or about 20% of Bitcoin's full size.
Extensions
These are possible options a light node operator could be given.
Tail emissions within XMR are an enormous game theoretic concept that we don't see in other (major) cryptocurrencies. However, there's no game theoretic paper that's been formally peer reviewed within Monero or the crypto community though. Everyone, including XMR contributors and MRL researchers, have opinions on tail emissions and nothing more than opinions. This is a serious matter that the MRL should be working on providing the community as it entails the future of XMR. It's tremendously brushed off as fine and all who challenge it are ridiculed, including by XMR contributors and Monero subreddit moderators, into the ground with no real proof behind their ridiculing rather than their opinions.
Eventually, a game theoretic paper within the crypto community might prove that XMR tail emissions is inefficient or unnecessary for the long term, and that zero-knowledge based decentralized self sovereign identity (SSI) will act as a natural "tail emissions" within capped supplies (of all crypto's) to provide proper redistribution and stability, so the ideology of immutability is sound (if you're trying to become anonymous 'digital cash' and not an anonymous 'payment network' which is what I believe XMR should be gunning for as it would create its own utility-niche (captures a giant multi-trillion dollar market) rather than competing/testing with/for Bitcoin, Zcash, fiat, continuously evolving formal peer reviewed papers, etc... As both, a governance system within Monero and this highly game theoretic topic evolve it shouldn't be off the table within any logically centralized governance system, full of an expanding pool of users (decentralization), of any decentralized cryptocurrency project, when maturity of the network has reached a certain point, to make a final decentralized political decision (of reassurance) on the supplied direction of the project for the long term. The community could even vote to leave everything as it is... All projects learn with time, mistakes are initially made and variables change. It shouldn't even be off the table to create a sustainable politically based supply schedule for the users to vote on periodically (e.g.: immutably every 10, 20, 30, 50, 100, etc years or so... A final decision could also be voted on to immutably never change a thing or to immutably only allow the one final decision indefinitely...).
In the modern implementation of Monero (protocol v12, core software release 0.15.x.x) the outputs from ancient pre-RingCT transactions are treated quite differently from RingCT outputs. This seems uncontroversial at first glance, since such large-scale changes to the transaction structure imply a need to migrate between versions. However, the treatment of coinbase outputs reveals a much more straightforward and harmonious migration process than is currently used.
A brief summary of the situation right now (as I understand it). In protocol v1 output amounts were communicated in clear text, much like the class of Bitcoin-esque currencies. Such an output amount might say 1938892901222. Then in v2-v3 these output amounts were split into denominations with a separate output for each chunk, say for example 1000000000000 + 900000000000 + 30000000000 + .... And, of course, in v4-onwards nearly all new outputs have had hidden amounts thanks to RingCT.
It is not clear to me how original ring signatures were constructed, given the strict limitation that amounts balance (the CryptonoteV2 whitepaper does not explain this, although they do claim to use ring signatures). In v2-v3, ring signature members all had the same amount denomination, which has fairly obvious functionality since there were likely to be at least a few multiples of each denomination floating around. In any case, now those early outputs are referred to as 'unmixable' since they can't be included in a ring with anything, and can only be spent in a pre-RingCT transaction (since RingCT transactions require a ring signature for inputs), where the outputs are denominated as in the v2-v3 style. The v2-v3 outputs are 'mixable' but can only be combined with other v2-v3 denomination outputs in a ring, and can be spent in a RingCT transaction. So, to get a hidden amount output when starting with an early v1 unmixable output, first create a transaction with v2-v3 outputs to make it mixable, then spend those in a normal RingCT tx.
The unusual thing is coinbase outputs, which CAN be spent in modern RingCT transactions despite having amounts in clear text. My proposal is merely to apply the same technique used on coinbase outputs to all pre-RingCT outputs. This would allow wallets to mostly deprecate those old transaction details, and only nodes would have to maintain backward compatibility. It means, going forward, that all decoy selection for ring membership would be performed across the entire history of available outputs (from genesis to today, including all coinbase and non-coinbase outputs from any kind of transaction).
The technique is simple. Each person recording a copy of the blockchain creates a commitment to any output amount communicated in clear text. For amount a, the commitment is C = 1G + aH, where H is the secondary generator used in Monero commitments.
To spend it in a ring signature, add it to a ring with other clear text and hidden amount outputs (doesn't matter). Create a pseudo output commitment (following theRCTTypeSimple construction being used in today's protocol) to the same amount, and sign in the MLSAG with the commitment to zero created. Amounts balance correctly, and observers are none the wiser as to whether you spent a cleartext amount or hidden amount.
Yes I actually read this whitepaper and yes I am indeed nitpicking but hey, better than leave it alone!
Page page 6/8, 3.2 New Algorithm, quote:
3.2.
New Algorithm.
Van Saberhagen makes excellent points that cost of in-
vestment should grow faster than linearly with power, and ge describes a perfect
ge should be replaced by he
Ok, so I'm moving this here to keep the monero-project/monero#1345 clutter-free.
@fluffypony @kenshi84 @knaccc @luigi1111
Todo:
n derivationChangelog:
2017-02-07: Initial: http://termbin.com/vdam, http://termbin.com/0a3o, http://termbin.com/n58g - knaccc
2017-02-07: Changed notation and supporting normal addresses as well: https://paste.fedoraproject.org/550729/50082614/ - all :)
2017-02-07: Multi-address support: https://paste.fedoraproject.org/550761/06389148/ - Luigi/JM
2017-02-08: More tweaks and improvement of readability: https://paste.fedoraproject.org/550825/65211341/ - Kenshi
2017-02-08: More tweaks, formatted and copied from monero-project/monero#1345 (comment) - Luigi/JM
2017-02-09: Apparently this is broken, because knowing C and n, it's trivial to find A
2017-02-17: See discussion below...
Initial discussion: https://paste.fedoraproject.org/551203/78349148/
Currently, each Monero wallet generates one set of keys and one public address which is given out to receive payments. However, a user may want to give out a dedicated address to each sender for dual purpose: to know which payment came from which sender and to avoid privacy loss via off-chain linking of the one address. To accomplish both goals, we propose a way to create multiple addresses which maintains reasonable performance of scanning the blockchain for outputs sent to any of the addresses created, all accessible from within the same wallet.
A recipient's root wallet address is defined as a pair of public view and spend keys (A,B) = (a*G,b*G), where a and b are the secret view and spend keys. The recipient creates a sub-address by choosing an arbitrary scalar n and defining a triplet (C,D,n). The choice of scalar n could be deterministic, as proposed below:
n = Hc(a || j)
C = n*A
m = Hs(a || n)
M = m*G
D = B+M,
where
j = 1,...,p.
Such a sub-address (C,D,n) gets passed to the sender. Note that the sender can't determine its root address (A,B). The sender can, if necessary, transfer to more than one such sub-addresses (C_i,D_i,n_i), i=1,...,w (either to the same recipient or to different recipients) in a single
transaction.
When constructing a transaction, the sender generates the transaction key R=r*G in a particular
manner: he rolls a random scalar s, and computes r as
r = s * n_1 * n_2 * ... * n_w.
Then, an output public key P for any standard destination address (A,B) is created as usual:
P = Hs(r * A) * G + B
In contrast, an output public key P_i for the i-th sub-address (C_i, D_i, n_i) is created as:
P_i = Hs(s * n_1 * n_2 * ... * n_{i-1} * n_{i+1} * ... * n_w * C_i) * G + D_i
Since C_i = n_i * A_i (while A_i is not known to the sender), the trick is in the following property:
s * n_1 * n_2 * ... * n_{i-1} * n_{i+1} * ... * n_w * C_i
= s * n_1 * n_2 * ... * n_{i-1} * n_{i+1} * ... * n_w * n_i * A_i
= r * A_i
Therefore, the output public key P_i is effectively equivalent to:
P_i = Hs(r * A_i) * G + B_i + M_i
even though the sender doesn't know (A_i,B_i).
When a recipient checks for incoming transfers, he first performs the standard key derivation
procedure to check if a given output key P matches to:
P' = Hs(a * R) * G + B.
If this test fails, he then goes through all previously created sub-addresses (C,D,n) and
checks if P matches to:
Q' = Hs(a * R) * G + B + M.
Similar to the aggregated addresses approach [1], this search can be done in a constant time
using a hash table: instead of computing Q' directly, the recipient computes
(B + M)' = P - Hs(a * R) * G, // I think that this is faster, as you pre-compute the EC addition only once, store it in the hash table and now don't have to subtract the B for each output. So, only one EC subtraction per output.
and looks for (B + M)' in the hash table. If such an (B + M)' is found, the output key P belongs to the recipient and its private key x can be recovered as:
x = Hs(a * R) + b + m.
From a known set of private keys (a,b), and with assumed number of previously used sub-addresses q>=p, the wallet must first reconstruct all the sub-address information:
n = Hc(a || j)
C = n*A
m = Hs(a || n)
M = m*G
D = B+M,
where
j = 1,...,q.
Then, it performs the full scan, as described in the previous section.
To make it stateless, wallet software could limit the range of p, and have q=p=10000, or any other arbitrary number.
The root address should never be made public because in that case, anyone could check whether any 2 sub-addresses belong to the same root address.
knaccc for the initial idea, Luigi for guidance and solution for multiple addresses, and kenshi84 for opening the topic in the first place and final touches.
[1] https://bytecoin.org/static/files/docs/aggregate-addresses.pdf
Supports multi-dest txs.
Increases 2-out tx size by (2+32) bytes (by adding a refund EC point in txextra).
For multi-dest txs (i.e. 3 outputs or more), increases tx size by ((3 upwards)+(32*number of outputs)) bytes.
Does not increase wallet scan time. Allows any amount to be sent to the return address, even an amount exceeding the funds received in the original transaction (useful if a customer is refunded in XMR-equivalent amounts of USD, rather than the exact XMR amount paid). Makes it easier and less error-prone to return funds to those that send funds into multisig wallets.
No consensus changes required. No risk of recipient sending refunds to non-refund capable wallets. Allows the sender to indicate that refunds are not allowed, with observers oblivious.
Saves 32 bytes per output vs the simpler solution of embedding a regular subaddress (pair of 32 byte EC points) into the tx.
No blockchain observer can tell whether any refunds have been sent.
Requires the recipients in a tx to be aware of the change output index (which is already the case in a 2-out tx). The public will remain oblivious as to the change output index.
Dusting attack immunity: This scheme encrypts the refund subaddress. If the refund subaddress were not encrypted, then a public observer of the blockchain could send lots of outputs, each of tiny amounts, to the unencrypted refund addresses listed against a number of transactions. This is known as "dusting". The attacker would then observe the movement of these dust outputs to see if they are spent alongside any of the outputs in their corresponding transactions. This would reveal the probable change output for each of those transactions. This impacts transaction untraceability.
The term "sender" means the original transaction sender, whom the refund will be sent to. The term "recipient" means a recipient of that original transaction.
Subaddresses require two components: a public key for which the original tx sender (i.e. the refund recipient) knows the private key, and a second public key which is the first public key multiplied by the refund recipient's private view key. This scheme takes advantage of the fact that the change output public key in the original transaction is a public key for which the sender knows the private key. In a 2-out tx, the recipient will know which is the change output. In a multi-dest tx, the recipients will therefore need to be privately advised of the change output index in the transaction.
For the original transaction (for which a refund will be issued), we'll refer to the change one-time output public key as P_change.
For the other output(s) in the original transaction, we'll refer to the output shared secret for the (i)th output as z_i, where as usual z_i = Hs(rA_i || i) or z_i = Hs(sC_i || i) depending on whether the recipient has a regular address or subaddress.
For the original transaction, a single refund EC point F is stored in the the txextra field. F = (y^-1)aP_change, where a is the private view key of the sender and y = Hs("refund" || z_i). Note: ^-1 means scalar inversion.
The refund subaddress will be calculated as (yF, P_change). The ordinary process of sending funds to this refund subaddress means:
txpubkey R = sP_change
one-time output public key P_refund = Hs(syF || i)G + P_change == Hs(saP_change || i) + P_change
Refund output P_refund is detected in the usual way as Hs(aR || i)G + P_change == Hs(asP_change || i)G + P_change
The refund output is later spent via the one-time output private key x_refund = Hs(aR || i) + x_change where x_change is the private key of the change output P_change.
This requires the existing subaddress lookup table to include the one-time public keys of all outputs ever received to the wallet. This will not incur a performance penalty.
A refund EC point F will need to be stored for each of the outputs, where each F is created the same way as described above.
In addition, the recipients will each need to be privately advised of the change output index in the transaction.
encrypted_change_index_subfield_length_bits = ceil(log2(number of outputs))
E.g. in a tx with 5 destinations (i.e. 6 outputs), encrypted_change_index_subfield_length_bits = 3.
For each output, encrypted_change_index_subfield = change_output_index XOR keccak("changeIndex" || z), where each operand will have a bit length of encrypted_change_index_subfield_length_bits. In the case of the first operand, care should be taken to represent the bits using the normal binary representation and not the varint binary representation. In the case of the second operand, this is achieved through truncation.
These bits will be concatenated to form encrypted_change_index. So in this 5-dest tx example, there will be a total of 3 * 6 = 18 bits of storage required to privately signal the change output index to each destination.
Therefore, for the 5 destination example, the transaction will need ceil(18/8) == 3 bytes of storage in the txextra field to communicate the encrypted index. These extra bytes are only required in the case of multi-dest txs.
Txextra fields are of the form [varint tag][varint data length in bytes][data].
We use the tag value TX_EXTRA_TAG_REFUND = 5.
For 2-out transactions, the data length will be 32, and the data will be a single refund EC point. When the txextra varint bytes are taken into consideration, this therefore means a total increase in tx size of 2+32 == 34 bytes.
For multi-dest txs (i.e. 3 or more outputs), the data length will be 32*(number of outputs) + ceil(num_outputs*ceil(log2(num_outputs))/8).
For multi-dest txs, the data format will be a list of 32 byte refund EC points, followed by the encrypted_change_index byte(s).
The original transaction specifies F as (y^-1)G. The recipient checks if yF==G, and if so does not allow the wallet to send a refund transaction.
It's possible to storage data in a Bulletproof range proof, under particular trust assumptions. In particular, knowledge of a PRNG seed used for random element generation can be used to store 32 bytes of arbitrary data; however, this allows for the brute-force recovery of all Pedersen values used in the proof by any entity that knows the seed. For a proof consisting of exactly one Pedersen commitment, the inclusion of another 32 bytes of data is possible, but this leaks the Pedersen mask. Storage of data should therefore be intended only for use by the prover.
Similarly, it's possible in Triptych to store 64 bytes of arbitrary data per proof in a way that leaks the signing index to a PRNG seed holder.
The Bitmessage protocol is based on the Bitcoin messaging layer protocol in which every node stores
all the messages in the network, thus behaving as a collective inbox. Proof of work on each message is used to deter spam abuse. Messages are kept by nodes for a determined period of time depending on the PoW applied to each message. Bitmessage is metadata free since no information about sender or receiver is included, and the message is just a ciphertext that each user tries to decrypt with their own keys. Bitmessage also uses Dandelion for broadcasting its messages to protect user's IP addresses.
Some Monero applications already make use of Bitmessage messaging system. For example:
(i) broadcasting Monero transactions to break link to originating IP address (Noether’s Gate);
(ii) multisig participants use Bitmessage to coordinate wallet creation and spending from it (MMS);
(iii) recently a version of Monero coinjoin has come under consideration. Participants will need to colaborate by messaging each other to coordinate the signing of different rings of a single transaction and generating corresponding bulletproofs required. This will likely use the MMS as well.
Bitmessage, however, is based on Bitcoin's cryptography and, to my knowledge, does not currently support Ed25519 cryptographic primitives. Also, Bitmessage nodes have to try to decrypt every single message to check whether they are the intended recipient, so they suffer from the same problem Monero had before the adoption of subaddresses.
Considering that these applications that Monero already have for Bitmessage-style messaging, and that the problem of scanning for multiple keys has already been solved in Monero, it would perhaps be a natural step to enable direct messaging between Monero addresses as viewed as Bitmessage-like addresses.
If that is achieved, Monero users may seamlessly and directly message other users they are transacting with, and conversely users that are chatting to each other may seamlessly send tips to each other. This could make the claim that cryptocurrencies make payments as easy as sending an email a reality for users of the system.
Here is the scheme I was thinking about. Please let me know what you think.
Let the user pick random a, b to form a family of subaddresses in the usual way. Let (C, D) be one such subaddress. For Monero uses, C is the view key, and D the spend key, as normal.
For messaging purposes, let E = e*G := C+D = (c+d)*G be the encryption key, and V = v*G := D = d*G be the verifying key.
For user (C' ,D') = (c'*G, d'*G), with encrypting and verifying keys (E',V') = (e'*G, v'*G) := ((c'+d')*G, d'*G) to send a message msg to (C, D), he proceeds as follows:
r, and compute P := H(r*C)*G + D;ct := Enc(msg, E);sig := Sign(ct, v');nonce such that the hash value H(ct, sig, (P,R), nonce) is low enough;(ct, sig, (P,R), nonce).User (C, D) scans the message pool and checks, for each message, whether P - H(c*R)*G belongs to his hash table. If so, he proceeds as follows: (Here I am assuming the sender's subaddress (C', D') is included in the message, since it should be hidden.)
msg := Dec(ct, e);(C',D') from msg;Verify(sig, V').When replying back to (C',D'), he repeats the process above, encrypting his reply with E' and signing with his signing key v.
Notice that the pair (P,R) in this context works only as an identifying tag that saves on scanning time for multiple keys. The choice of not encrypting with P is deliberate since, I believe (according to my extremely superficial knowledge of quantum computers), that not providing the encryption key along with the message might confer some level of quantum resistance, in the case that the keys (C, D) and (C',D') are assumed to have been exchanged securely; e.g. exchanged in person.
[Edit : The naive scheme I suggested at first (i.e. using the view key alone as the encryption key) had the severe drawback that if a wallet service, or any other entity, knows the user's private view key, then they would be able to read his messages. To avoid that, both the encryption and signing keys should depend on the spend key in some secure way. (At this time, I am suggesting the encryption key to be C+D, but clearly the goal should be to find the best way to view Monero addresses as Bitmessage addresses, and vice-versa.) Conveniently, a web wallet provider can still detect and keep the messages for the intended user. When the user logs in, he uses his private spend key to decrypt (with c+d) and sign new messages (with d). The wallet provider could enable client side in browser mining for the computation of the required PoW.]
Assuming that this idea or some variation of it is sound and secure, we could contact the Bitmessage developers to see if they would like to implement this as another address type in Bitmessage itself, which could foster Monero adoption among Bitmessage users; or perhaps or fork Bitmessage and bring this modified version under MMS development, which would allow for further tailoring it to Monero's needs.
The Triptych proving system is a d-LRS-type construction with functionality similar to that of MLSAG or CLSAG, permitting proofs on multiple components of key vectors in a set while hiding the signing index. The version specified in the preprint can be integrated into the Monero transaction protocol, requiring a separate proof for each spent input and using commitment offsets to assert transaction balance.
However, we've investigated an alternate Triptych construction (in math and code) that permits signing for multiple indices in the same list simultaneously within the same proof, while also taking care of balance assertion.
However, the soundness of this extension to Triptych is unknown. If shown to reduce to a known cryptographic hardness assumption, it would be useful due to its scaling benefits.
We all appreciate the work of Tim Ruffing, Sri Aravinda Krishnan Thyagarajan, Viktoria Ronge, and Dominique Schröder. I totally understand not wanting to use RuffCT as it doesn't give credit to the other researchers involved, but StringCT is a horrible alternative.
In English it has really bad connotations that we don't want to confuse new users with.
Do we want to associate a cryptographic function with these ideas? Oh so the outputs are strung together/connected somehow? There's a string of events that make the cryptography work? The cryptography is being done with string data? There's some kind of cryptographic hierarchy in place? None of those things are strictly true, but the word string carries to much meaning to casually use it to credit the authors. RingCT itself is not named after it's author.
The authors will still receive credit and kudos from the Monero community even if their names are not used in this manner.
I propose we use RingCT 2.0 or RingCT2 or Enhanced RingCT or RingCT+ or SL RingCT, or any other name than this.
They're going to name it and call it whatever they choose, but as we hear more and more from the research lab and as we discussed it on Reddit the purple cat might already be out of the bag as we cement the name further in the minds of users and contributors.
Previous studies on nonce distribution for our POW algorithm suggest that our algorithm is behaving badly as a random oracle.
Suggested change: instead of mining looking for H(block || nonce)*diff < targ, modify this to H(block || hmac(nonce))*diff < targ where the hmac is computed with some public key agreed upon by consensus, and possibly the hmac should be repeated over several rounds. hmac outputs are uniform under very weak assumptions, they are easy to compute (require a few hashes and xors) and guarantees that the input nonce to the POW hash is uniformly selected.
ASICs may be designed with greater energy efficiency when seeking nonces that solve H(block || nonce)*diff < targ within a certain range. This hmac removes the adversarial control over the nonce.
We need to investigate the relative impact this could have on CPU miners and investigate any and all impacts this could have on the incentive structure behind mining Monero.
There are at least two ways to visualize the transactions on the Monero blockchain: (1) as a forest of trees whose vertices are transaction output keys ("notes") and whose edges are defined by ring membership (allowing us to ask questions about vertex-induced subtrees with some given root) or (2) as a bipartite graph where in the first nodeset we see ring (signatures) and in the second nodeset we see transaction notes, and whose edgeset is defined by ring membership.
It would be nice to have some sort of library that visualizes these graphs and provides some analysis of statistics for these graphs. For example, for (1) above, what is the mean and median depth of the trees in the forest? What about the mean and median total number of transaction notes in the sub-trees? Etc.
@Gingeropolous: so the seed node thing always bums me out. Its like "in order to create a decentralized network, you need a centralized seeding system".....
A recent publication (see here) utilizes properties of the Bitcoin protocol to develop a way to probe the Bitcoin network topology, to determine whether two nodes are connected to each other. Under the assumptions that the network is sufficiently well connected and no more than 50% of nodes are behaving non-honestly (including semi-honest nodes), the method reveals the ground truth network topology of all honest nodes and provides estimates for the network topology of the remainder of the network as well.
Utilizing a similar approach, perhaps in Kovri, it may be possible to bootstrap a decentralized network without relying upon trusted network views.
The Janus attack can be used in an attempt to link known subaddresses, in order to determine if they are derived from the same master wallet address.
A user with wallet view and spend keys (a,b) generates a master wallet address (A,B) := (aG,bG). She generates subaddresses i and j as follows, where H is a hash-to-scalar function.
For index i:
B_i := H(a,i)*G + B and A_i := a*B_i
For index j:
B_j := H(a,j)*G + B and A_j := a*B_j
To attempt to link these subaddresses, an adversary generates a Janus output P, using transaction private key r:
R := r*B_i
P := H(r*A_i)*G + B_j
Note the mismatched indices in the output public key.
When recovering the output, the recipient computes P - H(a*R)*G == B_j and assumes the output is directed to subaddress j. If the recipient acknowledges receipt of the transaction, the adversary knows that subaddresses i and j are linked.
Note that the attack can also attempt to link a subaddress to its corresponding master address.
To allow the recipient to detect Janus outputs, the sender is required to include a second transaction public key R' := r*G using the fixed basepoint G.
On detection of the output public key P, the recipient computes the detected subaddress spend private key:
b_j = H(a,j) + b
Finally, the recipient checks that the following equation holds:
R - b_j*R' == 0
If the equation holds, the output is not a Janus output. If it fails, the output is malformed and may be a Janus output; the recipient should not acknowledge receipt, but may spend the funds if the output is spendable.
To see why the mitigation detects a Janus output:
R - b_j*R' == r*B_i - b_j*(r*G) == r*(B_i - B_j) != 0 (for i != j)
In order for the adversary to fool the mitigation check, it must provide R' such that b_jR' == b_i*G, which it cannot do since subaddress private keys are uniformly and independently distributed and unknown to the adversary.
This mitigation requires the addition of a single group element R' = r*G for each transaction private key r used in a transaction. This point is redundant in the case where no subaddresses appear as recipients, since it has the same construction as a standard-address transaction public key. The presence or absence of additional transaction public keys is already a signal of the presence of subaddress recipients, which is a separate concern.
No additional computational complexity is present when scanning transactions for controlled outputs. For each identified output requiring the mitigation, the complexity of the check is minimal. This check can also be batched across multiple transactions if desired, in order to increase efficiency when computing many checks at once.
In reference to this comment, it may be possible (although unnecessary) to develop some network-activity-based time series models for selecting transaction fees, to make something like fee structures algorithmically selected.
The feasibility, use, and general idea should be discussed and fleshed out.
As it stands, Bitcoin or any other conventional blockchain system could be compromised by an attack vector that not many people talk about. In a world where we have a cryptocurrency, centralised in a country that happens to have a huge firewall around it, there is an opportunity for an easy double-spend scenario, should that part of the world fall silent for a moment, forking the chain temporarily whilst the rest of the world's hashpower mines away at a shorter chain. Partition detectors don't solve this, and co-operation with a botnet or large amount of malicious hashpower worsens the situation.
some elements of Hashgraph can solve this, asynchronous byzantine can solve this. And I'm not sure at all how this could be implemented into Monero, considering its privacy model, but if it can, I'd love to have asked for it to be researched. As you can tell, I'm young, I don't have much experience, and am likely fallible on almost every term I've ever mentioned, but I'm convinced by Leemon that some elements of Hashgraph could be a game-changer for cryptocurrency or networked applications in general, and would hate to have not asked for more research to be done on it in relation to Monero/Kovri.
Hashgraph Whitepaper:
http://www.swirlds.com/downloads/SWIRLDS-TR-2016-01.pdf
Hashgraph Implementation in Non-Permissioned/Public Ledgers:
http://www.swirlds.com/downloads/Swirlds-and-Sybil-Attacks.pdf
Leemon Baird's most recent talk on his implementation of asynchronous byzantine in Hashgraph:
https://youtu.be/pOc23lJw7ls
Hello. Sorry, cannot find - where to ask. The problem is that i mistakenly used subaddress for mining pool, and they sent transaction. Balance not showing on my wallet. What i can do with that?
The code can be found here although it fails unit tests. Requires a lot more work...
We would like a tech note or a bulletin covering a failure model effects and criticality analysis in Monero. Namely: if things start to go wrong (say our PRNG is really bad), what happens? How bad is it? What ways can things fail, and to what degree of criticality?
This is a large-scale and very important analysis for the entire codebase, and may constitute multiple notes or bulletins. MRL is not aware of any other currencies with a formal, rigorous FMECA, and we would like to be one of the first to write a good one.
This issue to discuss the MRL roadmap as discussed in our meeting on 21 May 2018 (meeting notes can be seen here). We hope that the community can help us discuss, amend and modify the following as needed.
Technical notes and documentation: We intend on completing some discussions of the following and publishing technical notes on the results of those discussions. Presented in no particular order:
Off-chain improvements: We are looking into requisite payment channel infrastructure for Monero. We have also become aware of some advances that enable the following "new technology" investigations at MRL.
Literature reviews: This is an always-happening sort of thing, as Sarang and I read more papers, we are going to include short summaries of each and eventually just publish these notes.
Libraries for general use: Call this "research infrastructure." It's a lot easier to look into churn if we can easily measure statistics from the Monero blockchain, and it's wiser to model an attack, a PoW change, or a novel consensus mechanism like SPECTRE with a simulation than doing it live.
We model a single node's view of the blockchain to attain an estimate of expected spend-time of a given output on the Monero blockchain. We use the inter-transaction timing together with the number of spendable outputs to construct this estimate.
Preliminary stuff
We assume that transactions in the confirmed part of have non-negative real-valued timestamps consistent with the block ordering imposed on those transactions T[0] < T[1] < T[2] < ... and we define the inter-transaction or inter-renewal times S[i] = T[i] - T[i-1] for i >= 1. Assume inter-renewal times S[i] are independent and identically distributed by some cumulative distribution function F, and we assume without loss of generality that T[0] = 0 (by merely re-aligning our clocks).
For each real t > 0, define N(t) as the total number of transactions in the confirmed part of the blockchain that have ever been broadcast and confirmed before time t. Denote the number of outputs created in the transaction with time T[i] as P[i]. Denote the number of key images published in that transaction as Q[i]. We treat the sequence of T[i] as a renewal process and the sequences P[i], Q[i] as reward renewal processes.
Meat and potatoes results
The following is then justifiable using some starting theorems from Serfozo (Basics of Applied Stochastic Processes):
One application of these ideas: Let's try to estimate expected spend-time. Set a sample size, k = 1, 2, .... Say confirmed transactions have timestamps T[0] = 0, T[1], T[2], ..., T[i], T[i+1], ..., say N(t) is the number of T[i] in the interval 0 <= T[i] < t, say the number of outputs created in transaction i is P[i], say the number of key images published in transaction i is Q[i], and say R(t) = P[1] + ... + P[N(t)] - Q[1] - ... - Q[N(t)] = PP(t) - QQ(t). A simple empirical estimate of expected spend-time in Monero is R(t)(T[i]-T[i-k])/k for sufficiently large k and t.
A wallet dev that wishes to mitigate the bias between ring member ages and empirical estimates of spend-times by tweaking their distribution could do the following:
Better and different estimates can and should be derived from the above information, but this is an okay first-order approximation. For example, replacing R(t) in step 3 with an average may improve the precision of this estimate. See below.
Problems with the above: We assume that the ordering of transactions imposed by timestamps T[i] coincides with the ordering of transactions imposed by the blockchain topology. In reality, transactions may be confirmed on the blockchain in one order while their timestamps provide a distinctly different order. I sort of implicitly assume we are willing to re-arrange transaction timestamps using the minimal number of moves in order to obtain two consistent orderings. Timestamps are in general not trustworthy and if we did not reject transactions with unusual timestamps, this method would have no merit. Due to our rejection of unusual timestamps, this method is rather robust for large values of k (where "large" is subjective).
Detection of Bloat Attack: Unfortunately, we cannot detect a bloat attack solely by tracking U. In the event of a bloat attack, transaction outputs become more and more numerous. This can occur either (i) due to more transactions per second but with the same number of inputs and outputs, (ii) due to transactions producing more outputs than they destroy inputs but with the same number of transactions per second, or (iii) a mix of these two.
A typical spam attack may combine these two by broadcasting a lot of transactions that create more outputs than key images. In this case, T[i] - T[i-k] begins to decrease while R(t) increases; this estimate of spend-time may be held constant by a careful attacker.
Note that in case (i), R(t) is roughly constant, the same number of outputs are being produced as are being destroyed, and so the only way that a bloat attack can be occurring is if transactions are more and more numerous, and therefore more tightly spaced: the k-inter-renewal time T[i] - T[i-k] decreases so our estimate of spend-time decreases. In this case, it appears that the economy is picking up. In case (ii), then the number of outputs being produced exceed the number of inputs being destroyed: R(t) is growing. In this case, the inter-renewal time roughly constant while the spend-time gets longer and longer; it appears that the economy is slowing down.
More notes to come but I wanted to get my thoughts down in a single location.
STATUS: The solution in this comment appears to resolve the concerns raised by this issue.
NOTE: Starting at this comment the discussion shifted from the original topic to questions about scaling and network stability.
As many people know, the fee algorithm has gone through various iterations. At one point, JollyMort performed an extensive analysis which led to our dynamic fee algorithm based on a 'reference' transaction, and since then long term block weights have been added to mitigate the big bang attack. I believe there is still room for improvement.
Overview of current algorithms
Please see Zero to Monero: Second Edition, sections 7.3.2, 7.3.3, and 7.3.4. As I understand it, @ArticMine is the architect of those algorithms.
Problem to be solved
Imagine adoption is humming along and the long term median gets up really high, say 100x the current default penalty free zone (300kB, so we'd be at 30MB blocks [sic]). Suddenly catastrophe hits, and several major sources of transaction volume are taken offline (maybe some darknet markets were attacked by law enforcement, or perhaps it's world war 4 and some legal marketplaces get hit by EMPs). Short term transaction volume collapses to 5x the default penalty free zone, and now minimum fees are abruptly 20x higher. This is because per byte fees are divided by the minimum of short and long term medians.
Transactions built before the short term median falls will be using the older fees, which will now be inadequate, and those tx will get stranded, even if they are using the 'normal' fee priority which is 5x the minimum fee.
A similar thing could happen with much smaller volume shocks, to any transaction using the lowest fee priority (e.g. 1x the minimum).
It's not a problem if transaction volume never really exceeds the default penalty free zone, but design of the fee algorithm has always been forward looking so I don't see any reason to hold back.
Solution (OUTDATED, go to this comment)
Simply, make the minimum fee median FM = max(300kB, long_term_median). Now it will only gradually change as the long term median changes.
Of course, we must also change the penalty median since the fee is intended to afford one reference transaction's worth of penalty cost. Use the long term median ML = max(300kB, median_100000_long_term_weights) for penalty calculations instead of the cumulative median. But wait, this would seem to retract the upgrade for surge environments (we want some short term flexibility in block weights). The key insight here is making the 'penalty free zone' scale with the short term median, and the 'penalty zone' scale with long term median. Let's look at the penalty calculation (as it is done now; CM is the cumulative median CM = max(300kB, min(median_100_blocks_weights, 50*ML))).
P = B*(block_weight/CM - 1)^2
Note that the penalty only activates when block_weight > CM. We can reorganize it:
P = B*([block_weight - CM]/CM)^2
We want the 'activation' to happen when block weights are larger than the cumulative median, while the penalty itself scales with the long term median.
P = B*([block_weight - CM]/ML)^2
And the maximum block weight is MAX = CM + ML (instead of MAX = 2*CM which we have now).
The penalty to add one transaction above the cumulative median will slowly change as the long term median changes, but the penalty free zone is still free to fluctuate relatively rapidly. This also greatly increases the cost to set up a spam attack, as attackers will pay a fixed rate per byte to increase the short term median, rather than a fixed rate per percentage of the penalty zone (which becomes equivalent to more and more bytes as the short term median rises, with our current algorithms). It also ingrains this anti-spam mechanism directly into the penalty calculation, rather than the fee algorithm which is technically optional for nodes (it is network consensus, not protocol consensus, to enforce the minimum fee).
Changing long term median to long term average
The long term median is meant to reflect a large volume of transaction history, yet it can also change quite abruptly if short term volume shocks turn into long term volume shocks. Suppose transaction volume is chugging along at a high rate for quite a while, then after our catastrophe it halves semi-permanently. 35 days later the long term median will suffer a rapid adjustment, which seems to defy its supposed 'long term' nature. A similar thing could happen in the opposite direction with a sudden 40% rise in transaction volume. By making it a long term average, adjustments to changing overall transaction volume would be 'priced in' much more gradually.
It makes sense to keep our short term median, a median, since it works quite well for ignoring outliers. There are no meaningful outliers over 100000 blocks.
Reducing granularity: the construction-publish time delta heuristic
Transaction authors always base their tx fees off the current blockchain state, yet it can take some time before the tx actually gets mined into a block. Observers can compare the fee included, to the expected fee for a tx's resident block, to estimate the time delta (image credit: @Isthmus) between tx creation and being mined. That heuristic may be useful to fingerprint different kinds of users. Note that this heuristic also applies to age of the youngest ring member, so rounding fees like this doesn't completely solve the problem.
We can do simple rounding on the minimum fee, which already changes only slowly over the course of a single day (assuming my updated fee using long term average), to reduce the granularity of the time delta heuristic. Fewer significant digits equates to less granularity.
Suppose we want to round up to N significant digits, F is the explicitly calculated fee, and we are doing integer arithmetic. Find the order of magnitude of F (i.e. number of decimal digits), N_f, then calculate
throw_away = F % 10^(N_f - N);
if (throw_away > 0) then
{
F -= throw_away;
F += 10^(N_f - N);
}
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
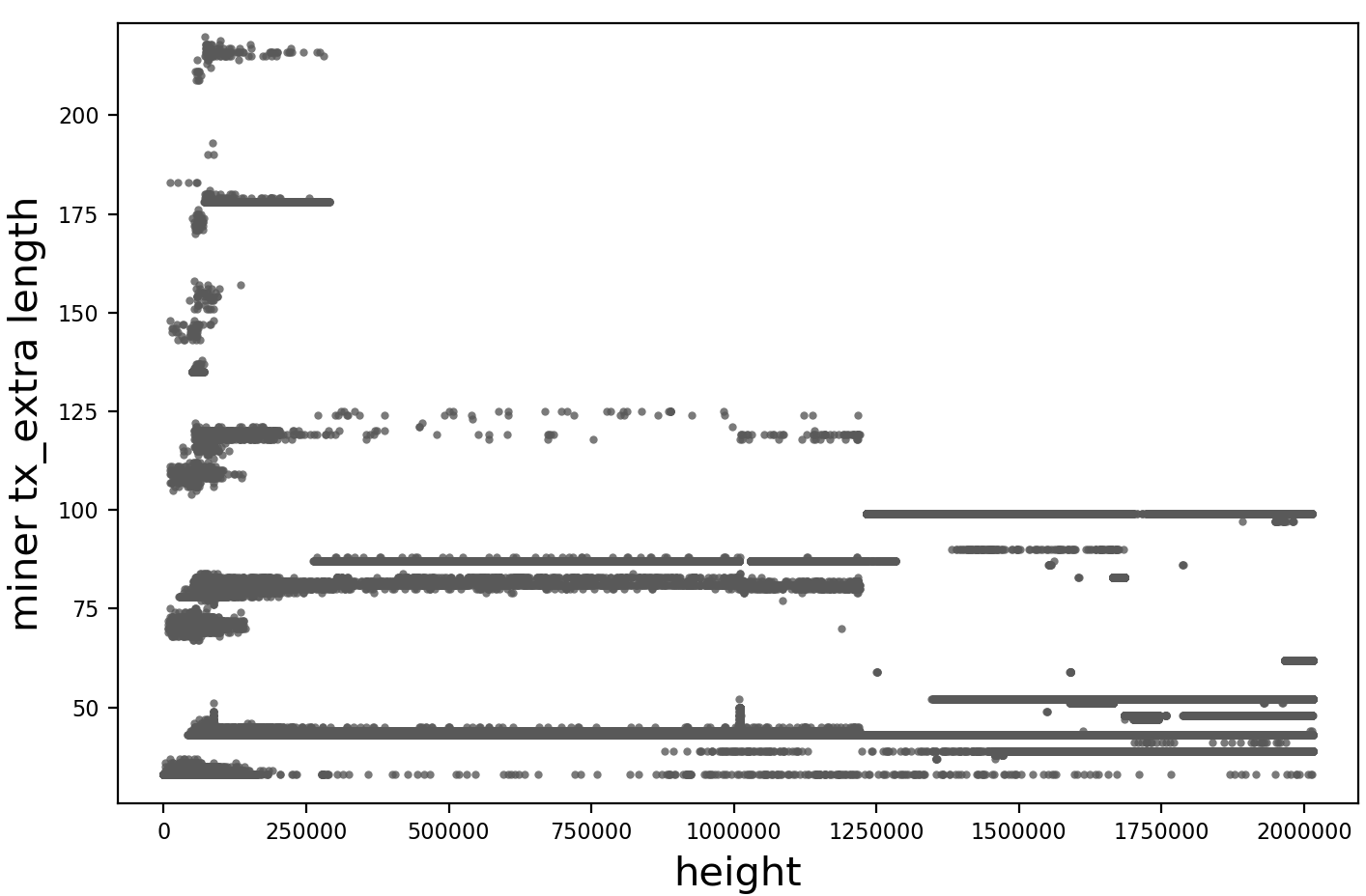{kind=link}
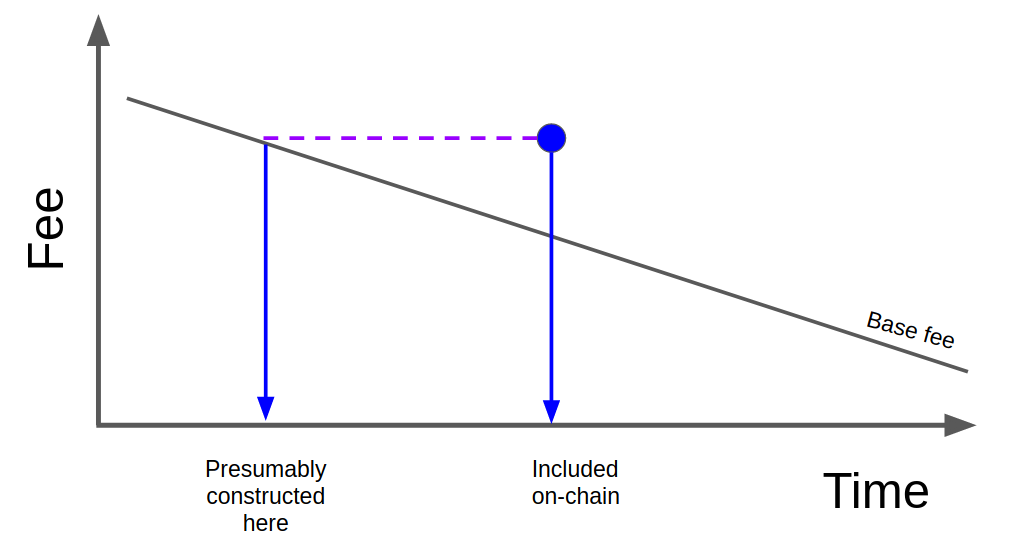{kind=link}