deployment for project hugging face: https://huggingface.co/spaces/mohamedemam/Arabic-meeting-summarization
the translated dataset: https://huggingface.co/datasets/mohamedemam/Arabic-samsum-dialogsum
this project for Arabic summarization meeting the data was translated from sumsam and dialogsum useing bloomz 3b and lora
Information about BLOOM:
- Documentation: https://huggingface.co/docs/transformers/model_doc/bloom
- Model: https://huggingface.co/bigscience/bloom
- Github: https://github.com/bigscience-workshop/bigscience/tree/master/train/tr11-176B-ml#readme
Transformers Package Documentation in Huggingface.co:
- Tokenizer Class: https://huggingface.co/docs/transformers/glossary#attention-mask
- Trainer Class: https://huggingface.co/docs/transformers/v4.21.1/en/main_classes/trainer#transformers.Trainer
- Finetuning using Trainer: https://huggingface.co/docs/transformers/training
- Token Classification: https://huggingface.co/docs/transformers/tasks/token_classification
Architecture explained:
- The Technology Behind BLOOM Training: https://huggingface.co/blog/bloom-megatron-deepspeed
- Understand BLOOM, the Largest Open-Access AI, and Run It on Your Local Computer: https://towardsdatascience.com/run-bloom-the-largest-open-access-ai-model-on-your-desktop-computer-f48e1e2a9a32
Dataset used for Training explained:
- Corpus Map: https://huggingface.co/spaces/bigscience-catalogue-lm-data/corpus-map
- Building a TB Scale Multilingual Dataset for Language Modeling: https://bigscience.huggingface.co/blog/building-a-tb-scale-multilingual-dataset-for-language-modeling
Dataset for Finetuning:
- Conll2003: https://huggingface.co/datasets/conll2003
The Model:
- 3B parameters decoder-only architecture (GPT-like)
BLOOM uses a Transformer architecture composed of an input embeddings layer, and an output language-modeling layer, as shown in the figure below. Each Transformer block has a self-attention layer and a multi-layer perceptron layer, with input and post-attention layer norms.
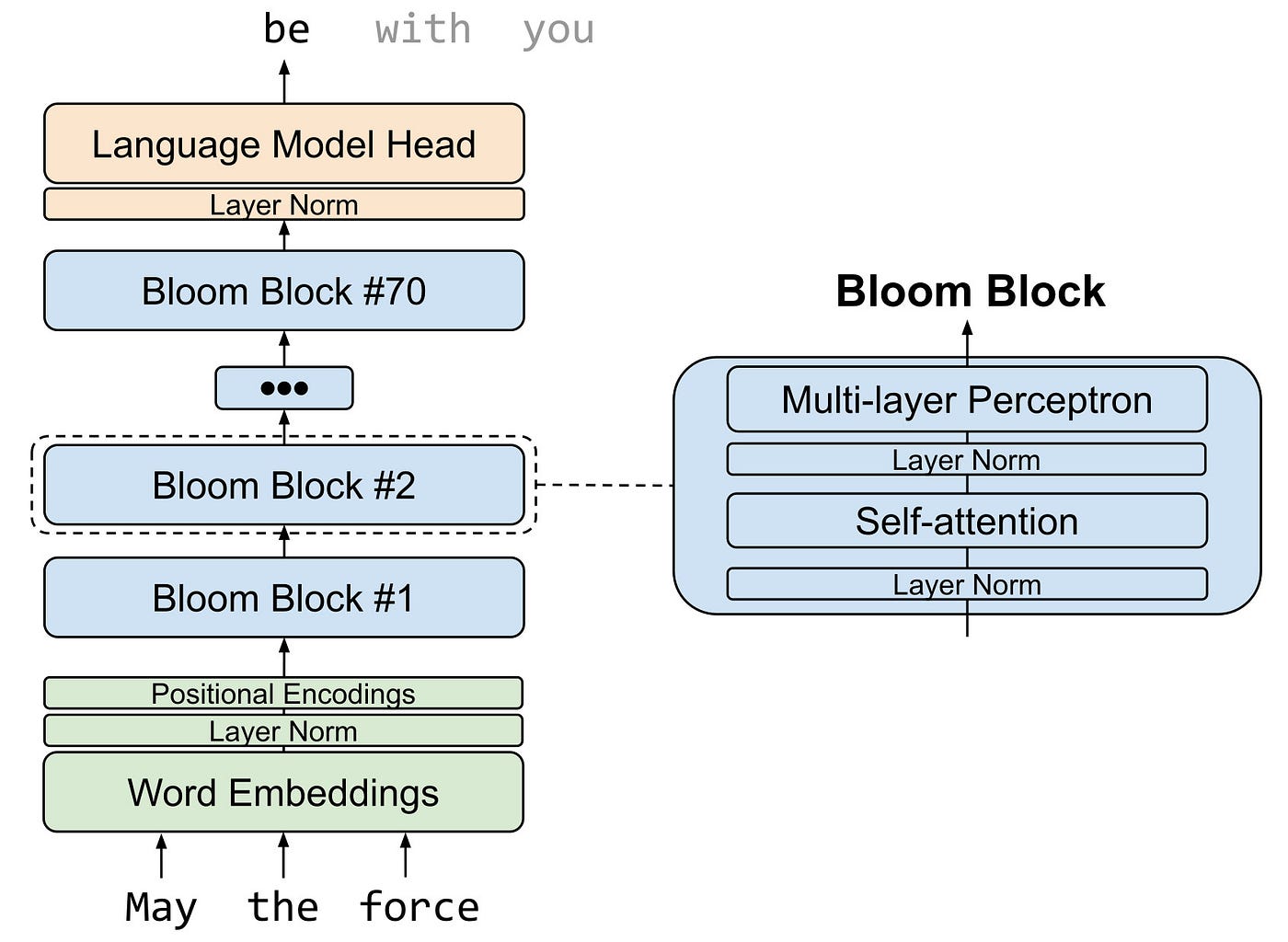
The Dataset:
- Multilingual: 46 languages: Full list is here: https://bigscience.huggingface.co/blog/building-a-tb-scale-multilingual-dataset-for-language-modeling
- 341.6 billion tokens (1.5 TB of text data)
- Tokenizer vocabulary: 250 680 tokens

