
![]()

Mito is a spreadsheet that lives inside your Jupyter notebooks, Dash apps, and Streamlit apps. It allows you to edit Pandas dataframes like an Excel file, and generates Python code that corresponds to each of your edits.
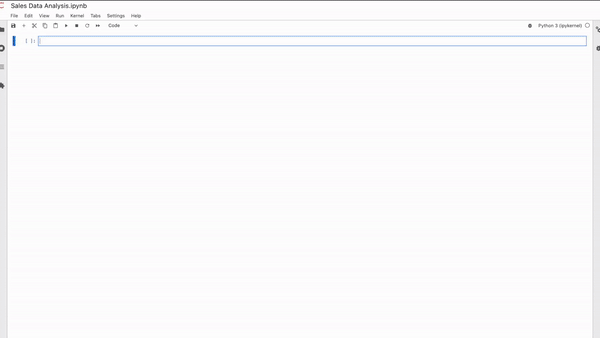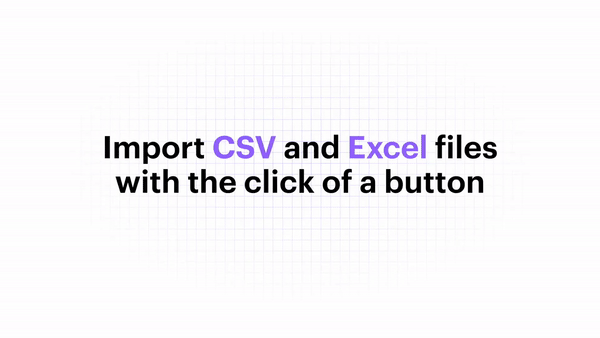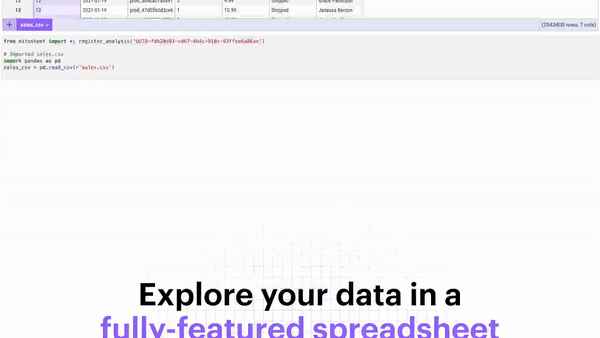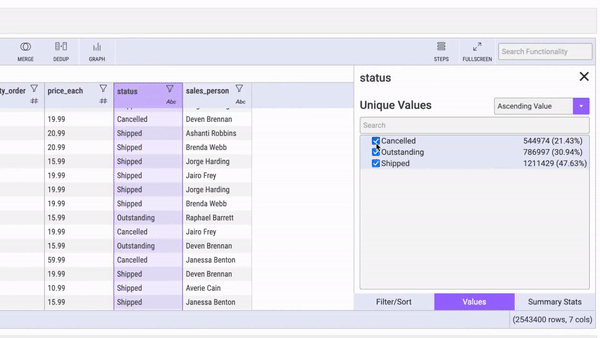
Mito aims to be the first tool in your data science toolkit and supports:
- Point-and-click CSV and XLSX import
- Excel-style pivot tables
- Graph generation
- Filtering and sorting
- Merge (lookups)
- Excel-Style formulas
- Column summary statistics
- And much more!
Mito is an open source tool (look around...), and will always be built by and for our community. See our plans page for more detail about our features, and consider purchasing Mito Pro to help fund development.
To get started, open a terminal, command prompt, or Anaconda Prompt. Then, download the Mito installer:
python -m pip install mitoinstaller
Then, run the installer. This command may take a few moments to run:
python -m mitoinstaller install
This will install Mito for classic Jupyter Notebooks and JupyterLab 3.0. More detailed installation instructions can also be found here.
If you're interested in Mito Pro, see our plans page.
You can find all Mito documentation available here.
To get support, join our Discord or Slack.
Coming soon!
MyBinder link for the main branch:
This repo is the monorepo for the Mito project, and so contains the mitosheet package, the trymito.io website, and our documentation as well.
To see the code for the mitosheet package, see the mitosheet folder.
To test the current version of mitosheet that is deployed on Test PyPi, create an empty venv, and run the command
python3 -m pip install mitoinstaller
python3 -m mitoinstaller install --test-pypi
Then, launch JLab to test the current version of the mitosheet package on Test PyPi.
To see the mitoinstaller package, see the mitoinstaller folder.
To see the code for our website, see the trymito.io folder.
Our docs are hosted on Gitbooks here. You can see and edit the docs in the /docs folder, PRs greatly appreciated!







































































































































