USB: A Unified Semi-supervised learning Benchmark for CV, NLP, and Audio Classification
Paper
·
Benchmark
·
Demo
·
Docs
·
Issue
·
Blog
·
Blog (Pytorch)
·
Blog (Chinese)
·
Video
·
Video (Chinese)
Table of Contents
-
[03/16/2024] Add EPASS, SequenceMatch, and ReFixMatch. Fixed some typos.
-
[07/07/2023] Add DeFixmatch. Fixed some bugs. Release semilearn=0.3.1/
-
[06/01/2023] USB has officially joined the Pytorch ecosystem! [Pytorch blog]
-
[01/30/2023] Update semilearn==0.3.0. Add FreeMatch and SoftMatch. Add imbalanced algorithms. Update results and add wandb support. Refer CHANGE_LOG for details. [Results][Logs][Wandb]. Older classic logs can be found here: [TorchSSL Log].
-
[10/16/2022] Dataset download link and process instructions released! [Datasets]
-
[10/13/2022] We have finished the camera ready version with updated [Results]. [Openreview]
-
[10/06/2022] Training logs and results of USB has been updated! Available dataset will be uploaded soon. [Logs] [Results]
-
[09/17/2022] The USB paper has been accepted by NeurIPS 2022 Dataset and Benchmark Track! [Openreview]
-
[08/21/2022] USB has been released!
USB is a Pytorch-based Python package for Semi-Supervised Learning (SSL). It is easy-to-use/extend, affordable to small groups, and comprehensive for developing and evaluating SSL algorithms. USB provides the implementation of 14 SSL algorithms based on Consistency Regularization, and 15 tasks for evaluation from CV, NLP, and Audio domain.

This is an example of how to set up USB locally. To get a local copy up, running follow these simple example steps.
USB is built on pytorch, with torchvision, torchaudio, and transformers.
To install the required packages, you can create a conda environment:
conda create --name usb python=3.8then use pip to install required packages:
pip install -r requirements.txtFrom now on, you can start use USB by typing
python train.py --c config/usb_cv/fixmatch/fixmatch_cifar100_200_0.yamlWe provide a Python package semilearn of USB for users who want to start training/testing the supported SSL algorithms on their data quickly:
pip install semilearnYou can also develop your own SSL algorithm and evaluate it by cloning USB:
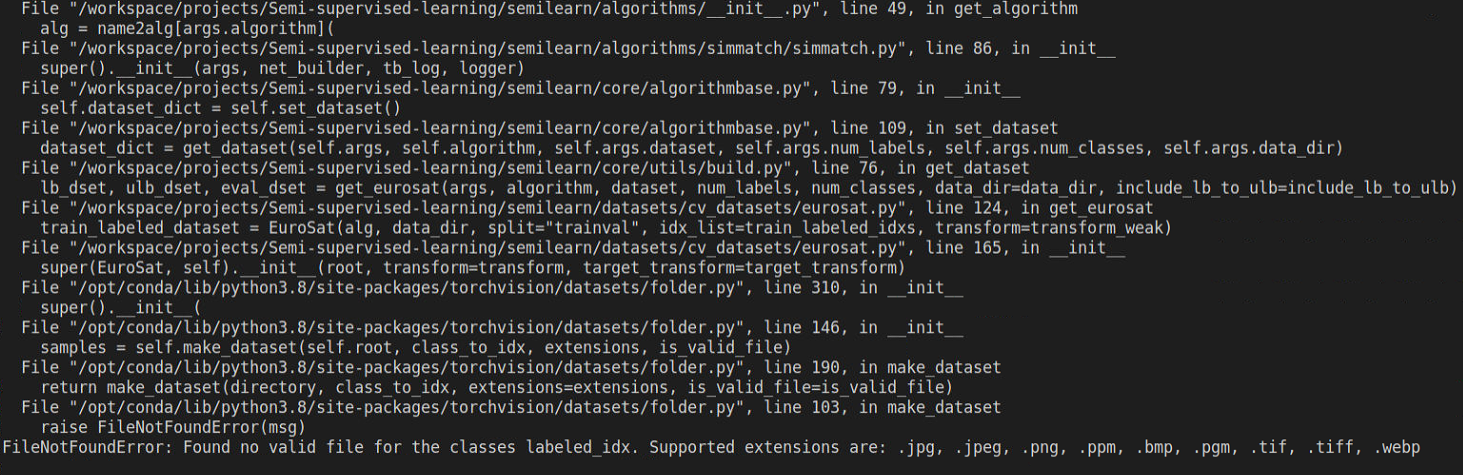
git clone https://github.com/microsoft/Semi-supervised-learning.gitThe detailed instructions for downloading and processing are shown in Dataset Download. Please follow it to download datasets before running or developing algorithms.
USB is easy to use and extend. Going through the bellowing examples will help you familiar with USB for quick use, evaluate an existing SSL algorithm on your own dataset, or developing new SSL algorithms.
Please see Installation to install USB first. We provide colab tutorials for:
Step1: Check your environment
You need to properly install Docker and nvidia driver first. To use GPU in a docker container
You also need to install nvidia-docker2 (Installation Guide).
Then, Please check your CUDA version via nvidia-smi
Step2: Clone the project
git clone https://github.com/microsoft/Semi-supervised-learning.gitStep3: Build the Docker image
Before building the image, you may modify the Dockerfile according to your CUDA version.
The CUDA version we use is 11.6. You can change the base image tag according to this site.
You also need to change the --extra-index-url according to your CUDA version in order to install the correct version of Pytorch.
You can check the url through Pytorch website.
Use this command to build the image
cd Semi-supervised-learning && docker build -t semilearn .Job done. You can use the image you just built for your own project. Don't forget to use the argument --gpu when you want
to use GPU in a container.
Here is an example to train FixMatch on CIFAR-100 with 200 labels. Training other supported algorithms (on other datasets with different label settings) can be specified by a config file:
python train.py --c config/usb_cv/fixmatch/fixmatch_cifar100_200_0.yamlAfter training, you can check the evaluation performance on training logs, or running evaluation script:
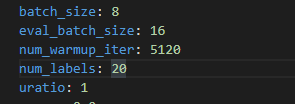
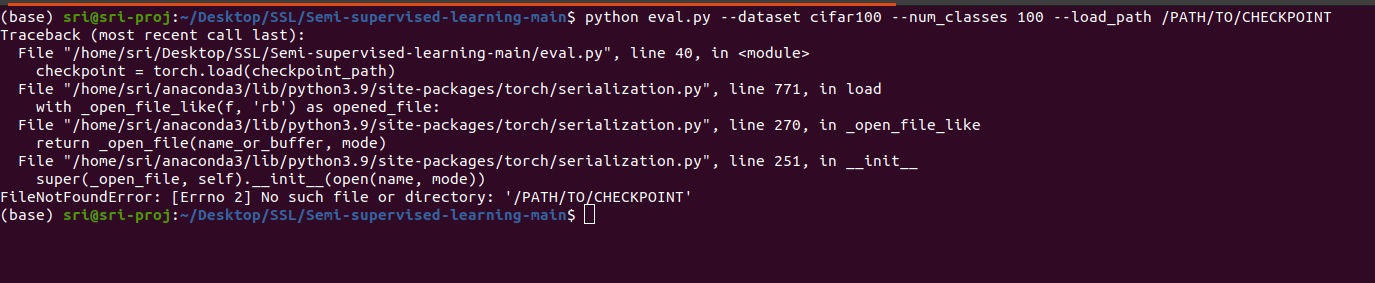
python eval.py --dataset cifar100 --num_classes 100 --load_path /PATH/TO/CHECKPOINT
Check the developing documentation for creating your own SSL algorithm!
For more examples, please refer to the Documentation
Please refer to Results for benchmark results on different tasks.
TODO: add pre-trained models.
- Finish Readme
- Updating SUPPORT.MD with content about this project's support experience
- Multi-language Support
- Chinese
See the open issues for a full list of proposed features (and known issues).
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
If you have a suggestion that would make USB better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement". Don't forget to give the project a star! Thanks again!
- Fork the project
- Create your branch (
git checkout -b your_name/your_branch) - Commit your changes (
git commit -m 'Add some features') - Push to the branch (
git push origin your_name/your_branch) - Open a Pull Request
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
Distributed under the MIT License. See LICENSE.txt for more information.
The USB community is maintained by:
- Yidong Wang ([email protected]), Tokyo Institute of Technology
- Hao Chen ([email protected]), Carnegie Mellon University
- Yue Fan ([email protected]), Max Planck Institute for Informatics
- Wenxin Hou ([email protected]), Microsoft STCA
- Ran Tao ([email protected]), Carnegie Mellon University
- Jindong Wang ([email protected]), Microsoft Research Asia
Please cite us if you fine this project helpful for your project/paper:
@inproceedings{usb2022,
doi = {10.48550/ARXIV.2208.07204},
url = {https://arxiv.org/abs/2208.07204},
author = {Wang, Yidong and Chen, Hao and Fan, Yue and Sun, Wang and Tao, Ran and Hou, Wenxin and Wang, Renjie and Yang, Linyi and Zhou, Zhi and Guo, Lan-Zhe and Qi, Heli and Wu, Zhen and Li, Yu-Feng and Nakamura, Satoshi and Ye, Wei and Savvides, Marios and Raj, Bhiksha and Shinozaki, Takahiro and Schiele, Bernt and Wang, Jindong and Xie, Xing and Zhang, Yue},
title = {USB: A Unified Semi-supervised Learning Benchmark for Classification},
booktitle = {Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year = {2022}
}
@article{wang2023freematch,
title={FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning},
author={Wang, Yidong and Chen, Hao and Heng, Qiang and Hou, Wenxin and Fan, Yue and and Wu, Zhen and Wang, Jindong and Savvides, Marios and Shinozaki, Takahiro and Raj, Bhiksha and Schiele, Bernt and Xie, Xing},
booktitle={International Conference on Learning Representations (ICLR)},
year={2023}
}
@article{chen2023softmatch,
title={SoftMatch: Addressing the Quantity-Quality Trade-off in Semi-supervised Learning},
author={Chen, Hao and Tao, Ran and Fan, Yue and Wang, Yidong and Wang, Jindong and Schiele, Bernt and Xie, Xing and Raj, Bhiksha and Savvides, Marios},
booktitle={International Conference on Learning Representations (ICLR)},
year={2023}
}
@article{zhang2021flexmatch,
title={FlexMatch: Boosting Semi-supervised Learning with Curriculum Pseudo Labeling},
author={Zhang, Bowen and Wang, Yidong and Hou, Wenxin and Wu, Hao and Wang, Jindong and Okumura, Manabu and Shinozaki, Takahiro},
booktitle={Neural Information Processing Systems (NeurIPS)},
year={2021}
}
We thanks the following projects for reference of creating USB:



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")







![microsoft-github-operations[bot] avatar](https://avatars.githubusercontent.com/in/41902?v=4 "microsoft-github-operations[bot]")