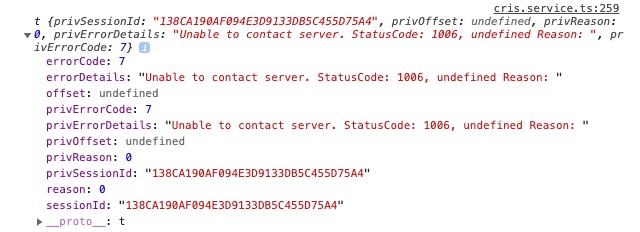
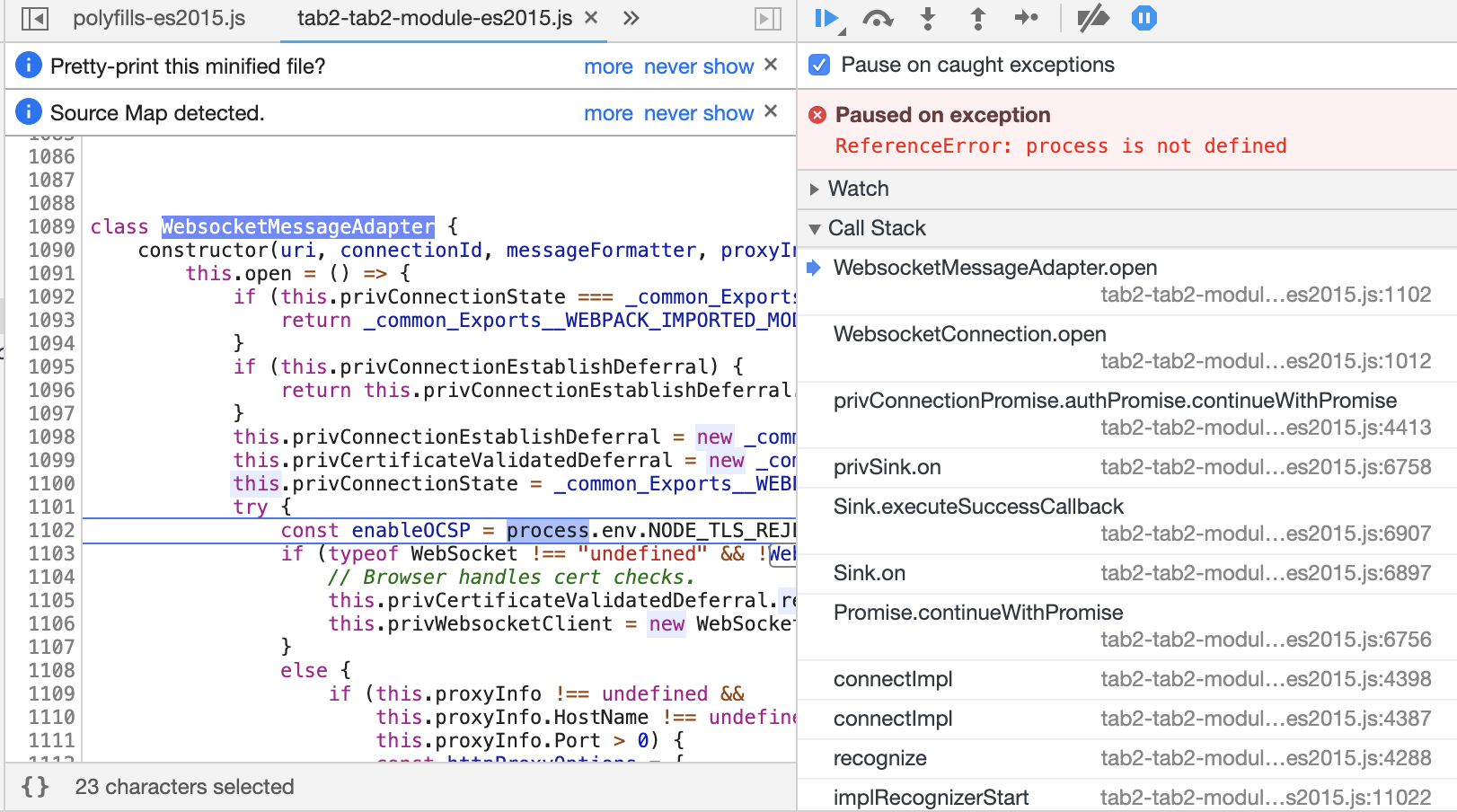
The Microsoft Cognitive Services Speech SDK for JavaScript is the JavaScript version of the Microsoft Cognitive Services Speech SDK. An in-depth description of feature set, functionality, supported platforms, as well as installation options is available here.
The JavaScript versions of the Cognitive Services Speech SDK supports browser scenarios as well as the Node.js environment.
For the latest stable version:
npm install microsoft-cognitiveservices-speech-sdk- Quick-start samples for Node.js: In the Speech SDK samples repo under quickstart/javascript/node.
- Quick-start samples for Browser: In the Speech SDK samples repo under quickstart/javascript/browser.
- Other Node.js and Browser samples: In the Speech SDK samples repo under samples/js.
This source code for the Cognitive Services Speech SDK (JavaScript) is available in a public GitHub repository. You are not required to go through the build process. We create prebuilt packages tuned for your use-cases. These are updated in regular intervals.
In order to build the Speech SDK, ensure that you have Git and Node.js installed. Version requirement for Node: 12.44.0 or higher (or 14.17.0 or higher for Node 14).
Clone the repository:
git clone https://github.com/Microsoft/cognitive-services-speech-sdk-jsChange to the Speech SDK directory:
cd cognitive-services-speech-sdk-jsRun setup to pull updated dependency versions:
npm run setup
Install the required packages:
npm install
Run the build:
npm run build
Run tests (see ci/build.yml) -- complete results require several specifically-configured subscriptions, but incomplete results can be obtained with a subset (expect and ignore failures involving missing assignments).
At a minimum, invoking npm run test will compile/lint the test files to catch early problems in test code changes.
RunTests.cmd ^
SpeechSubscriptionKey:SPEECH_KEY ^
SpeechRegion:SPEECH_REGION ^
LuisSubscriptionKey:LUIS_KEY ^
LuisRegion:LUIS_REGION ^
SpeechTestEndpointId:CUSTOM_ENDPOINT ^
BotSubscription:BOT_KEY ^
BotRegion:BOT_REGION ^
SpeakerIDSubscriptionKey:SPEAKER_ID_KEY ^
SpeakerIDRegion:SPEAKER_ID_SUBSCRIPTION_REGION ^
CustomVoiceSubscriptionKey:CUSTOM_VOICE_KEY ^
CustomVoiceRegion:CUSTOM_VOICE_REGION
-
Edit the file
jest.config.js. Replace the regex expressions intestRegex: "tests/.*Tests\\.ts$"with one that defines the test file (or files) you want to run. For example, to only run tests defined inAutoSourceLangDetectionTests.ts, replace it withtestRegex: "tests/AutoSourceLangDetectionTests.ts". Do this is for the two projectjsdomandnode. -
Option 1: Use a secrets file. Create the file
secrets\TestConfiguration.ts. It should import the default configuration settings and define the values of the mandatory ones for this test, as well as and any additional optional settings. For example, to run theAutoSourceLangDetectionTests.tstests, the required mandatory values are the speech key and region (using a fake key here as an example):import { Settings } from "../tests/Settings"; Settings.SpeechSubscriptionKey = "0123456789abcdef0123456789abcdef"; Settings.SpeechRegion = "westcentralus";
Then to run the tests type
RunTests.cmdin the root of the repo. -
Option 2: Use command line arguments. Instead of creating
secrets\TestConfiguration.ts, pass the values directly toRunTests.cmd. For the above example, this would be:RunTests.cmd SpeechSubscriptionKey:0123456789abcdef0123456789abcdef SpeechRegion:westcentralus -
Option 3: Edit the file
tests\Settings.tsdirectly and enter values needed to run the test. -
See summary of the test results in
test-javascript-junit.xml.
This project collects data and sends it to Microsoft to help monitor our service performance and improve our products and services. Read the Microsoft Privacy Statement to learn more.
To disable telemetry, you can call the following API:
// disable telemetry data
sdk.Recognizer.enableTelemetry(false);This is a global setting and will disable telemetry for all recognizers (already created or new recognizers).
We strongly recommend you keep telemetry enabled. With telemetry enabled you transmit information about your platform (operating system and possibly, Speech Service relevant information like microphone characteristics, etc.), and information about the performance of the Speech Service (the time when you did send data and when you received data). It can be used to tune the service, monitor service performance and stability, and might help us to analyze reported problems. Without telemetry enabled, it is not possible for us to do any form of detailed analysis in case of a support request.
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.microsoft.com.
When you submit a pull request, a CLA-bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., label, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.





![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")












![microsoft-github-policy-service[bot] avatar](https://avatars.githubusercontent.com/in/95686?v=4 "microsoft-github-policy-service[bot]")