一个用于提取简体中文字符串中省,市和区并能够进行映射,检验和简单绘图的python模块。
举个例子:
["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区"]
↓ 转换
|省 |市 |区 |
|上海市|上海市|徐汇区|
|福建省|泉州市|洛江区|
如果你只是想快速实现以上类型的数据处理的话,那么只需要复制以下代码,不需要过多阅读本文档的内容(复制代码之前,先阅读安装说明将本模块装上):
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"] #任意的可迭代类型,比如Series也可以
from chinese_province_city_area_mapper.transformer import CPCATransformer
from chinese_province_city_area_mapper import myumap
cpca = CPCATransformer(myumap.umap)
df = cpca.transform(location_str)
df
代码目前仅仅支持python3
pip install chinese_province_city_area_mapper
- 基于jieba分词进行匹配,同时用比较复杂的匹配逻辑保证了准确率,笔者根据手头的海量地址描述数据进行了测试
- 自带完整的省,市,区三级地名及其经纬度的数据
- 支持自定义省,市,区映射
- 输出的是基于pandas的DataFrame类型的表结构,易于理解和使用
- 封装了简单的绘图功能,可以很方便地进行简单的数据可视化
- MIT 授权协议
本模块中最主要的类是chinese_province_city_area_mapper.transformer.CPCATransformer(注:CPCA是Chinese Province City Area的缩写),该类的transform方法可以输入任意的可迭代类型(如list,Series等),然后将其转换为一个DataFrame,示例代码如下:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"]
from chinese_province_city_area_mapper.transformer import CPCATransformer
cpca = CPCATransformer()
df = cpca.transform(location_str)
df
输出的结果为:
区 市 省
0 徐汇区 上海市 上海市
1 洛江区 泉州市 福建省
2 朝阳区
从上面的程序输出中你会发现朝阳区并没有被映射到北京市,这是因为在**有多个同名的叫做朝阳区的区,并且他们位于不同的市,所以程序就不知道该映射到哪一个市了(举个例子,南京市有一个鼓楼区,开封市有一个鼓楼区,福州市也有一个鼓楼区,这样程序就不知道应该把鼓楼区映射到哪一个市了),因此就不对其进行映射,如果你确定你的数据中的朝阳区都是指北京市的那个朝阳区的话,可以在CPCATransformer的构造函数中传一个字典(叫做umap参数,是user map的简称),指定朝阳区都要映射到北京市,注意只有区到市的这一级映射存在重名问题,**的市的名称都是唯一的,省的名称也都是唯一的,示例代码如下:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"]
from chinese_province_city_area_mapper.transformer import CPCATransformer
cpca = CPCATransformer({"朝阳区":"北京市"})
df = cpca.transform(location_str)
df
输出结果为:
区 市 省
0 徐汇区 上海市 上海市
1 洛江区 泉州市 福建省
2 朝阳区 北京市 北京市
模块中还内置了一个我推荐大家使用的umap,这个umap中我根据处理地址数据的经验将那些重名的区映射到了它最常见的一个市,这个umap位于chinese_province_city_area_mapper.myumap.umap,使用如下:
location_str = ["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区", "朝阳区北苑华贸城"]
from chinese_province_city_area_mapper.transformer import CPCATransformer
from chinese_province_city_area_mapper import myumap
print(myumap.umap) #查看这个umap的内容
cpca = CPCATransformer(myumap.umap)
df = cpca.transform(location_str)
df
输出和上一个程序一样
模块中还自带一个简单绘图工具,可以在地图上将上面输出的数据以热力图的形式画出来,代码如下:
from chinese_province_city_area_mapper import drawers
#df为上一段代码输出的df
drawers.draw_locations(df, "df.html")
这一段代码运行结束后会在运行代码的当前目录下生成一个df.html文件,用浏览器打开即可看到 绘制好的地图(如果某条数据'省','市'或'区'字段有缺,则会忽略该条数据不进行绘制),速度会比较慢,需要耐心等待,绘制的图像如下:

draw_locations函数还可以通过指定path参数来改变输出路径,示例代码如下::
from chinese_province_city_area_mapper import drawers
#在当前目录的父目录生成df.html
drawers.draw_locations(df, "df.html", path="../")
到这里就你就已经知道了本模块的基本使用了,接下来我会阐明更多细节。
本模块自带全国省市区的映射关系及其经纬度,如果你只是想使用这个数据的话可以使用如下代码:
from chinese_province_city_area_mapper.infrastructure import SuperMap
#地区到市的映射数据库,是一个字典类型(key为区名,value为其所属的市名),注意其中包含重复的区名
SuperMap.area_city_mapper
#重复的区名列表,列表类型,如果区名在这个列表中,说明存在多个同名区,则area_city_mapper的映射是不准确的
SuperMap.rep_areas
#市到省的映射数据库,字典类型(key为市的名称,value为省的名称)
SuperMap.city_province_mapper
#全国省市区的经纬度数据库,字典类型(key为"省,市,区",value为(维度,经度))
SuperMap.lat_lon_mapper
#获取北京市朝阳区的经纬度
SuperMap.lat_lon_mapper.get("北京市,北京市,朝阳区")
#获得一个地名的级别(即省,市或者区)
SuperMap.getType("江苏省") #返回"province",即常量SuperMap.PROVINCE
SuperMap.getType("南京市") #返回"city",即常量SuperMap.CITY
SuperMap.getType("海淀区") #返回"area",即常量SuperMap.AREA
#省略"省"字也能够识别出来
SuperMap.getType("江苏")
为了保证匹配与映射的正确性,我做了很多细节上的处理,如果在使用本模块的过程中遇到困惑可以参考这里。
- 能够匹配到省或者市的缩写,比如将"北京市"缩写为"北京","江苏省"缩写为"江苏",依旧能够匹配到并且能够自动补全为全称,示例代码如下:
#测试数据
location_strs = ["江苏省南京市鼓楼区256号", "江苏南京鼓楼区256号"]
from chinese_province_city_area_mapper.transformer import CPCATransformer
cpca = CPCATransformer()
df = cpca.transform(location_strs)
df
输出的结果为:
区 市 省
0 鼓楼区 南京市 江苏省
1 鼓楼区 南京市 江苏省
- 能够自动检测字符串中匹配到的省,市和区是否是所属关系,如果不是所属关系的话,则会删去优先级较低的(注:如果匹配到的是缩写的话,即将"南京市"缩写为"南京",则认为优先级较低),如果优先级一样的话,则删除地域范围较小的,示例代码如下:
#测试数据,一些故意错乱的地址描述
location_strs = ["静安区南京西路30号", "南京市静安区", "江苏省上海市", "上海市静安区南京西路"]
from chinese_province_city_area_mapper.transformer import CPCATransformer
cpca = CPCATransformer()
df = cpca.transform(location_strs)
df
输出结果如下:
区 市 省
0 静安区 上海市 上海市
1 南京市 江苏省
2 江苏省
3 静安区 上海市 上海市
分析:第一个测试数据"静安区南京西路"会同时匹配到"静安区"和"南京"两个地域名称,但是静安区是属于上海的,和"南京"想矛盾,而且因为"南京"是"南京市"的缩写,因此优先级比较低,故放弃"南京"这个地域名称。
第二个测试数据匹配到"南京市"和"静安区"两个矛盾的地域名称,而且这两个名称都是全称,优先级相同,所以保留地域范围比较大的,即保留"南京市"而放弃"静安区"。第三个测试数据也是一样的道理。
第四个测试数据中有两个市的名称会被匹配到,一个是"上海市",还有一个是"南京",但是因为"上海市"在前面被匹配到了,所以"南京"就会被忽略。
本仓库放了一份大约一万多条地址描述信息addr.csv,这是我当时测试与开发用的数据,目前的版本可以保证比较高的准确率,大家可以用这个数据继续进行测试,测试代码如下:
#读取数据
import pandas as pd
origin = pd.read_csv("addr.csv")
#转换
from chinese_province_city_area_mapper.transformer import CPCATransformer
from chinese_province_city_area_mapper import myumap
cpca = CPCATransformer(myumap.umap)
addr_df = cpca.transform(origin["原始地址"])
#输出
processed = pd.concat([origin, addr_df], axis=1)
processed.to_csv("processed.csv", index=False, encoding="utf-8")
注意以上代码会产生产生大量的warnning,这些warnning是因为程序无法确定某个区县属于哪个市(因为这些区县存在重名问题而且在umap中又没有指定它属于哪一个市).
绘图代码:
from chinese_province_city_area_mapper import drawers
#processed为上一段代码的processed
drawers.draw_locations(processed, "processed.html")
绘制的局部图像如下:
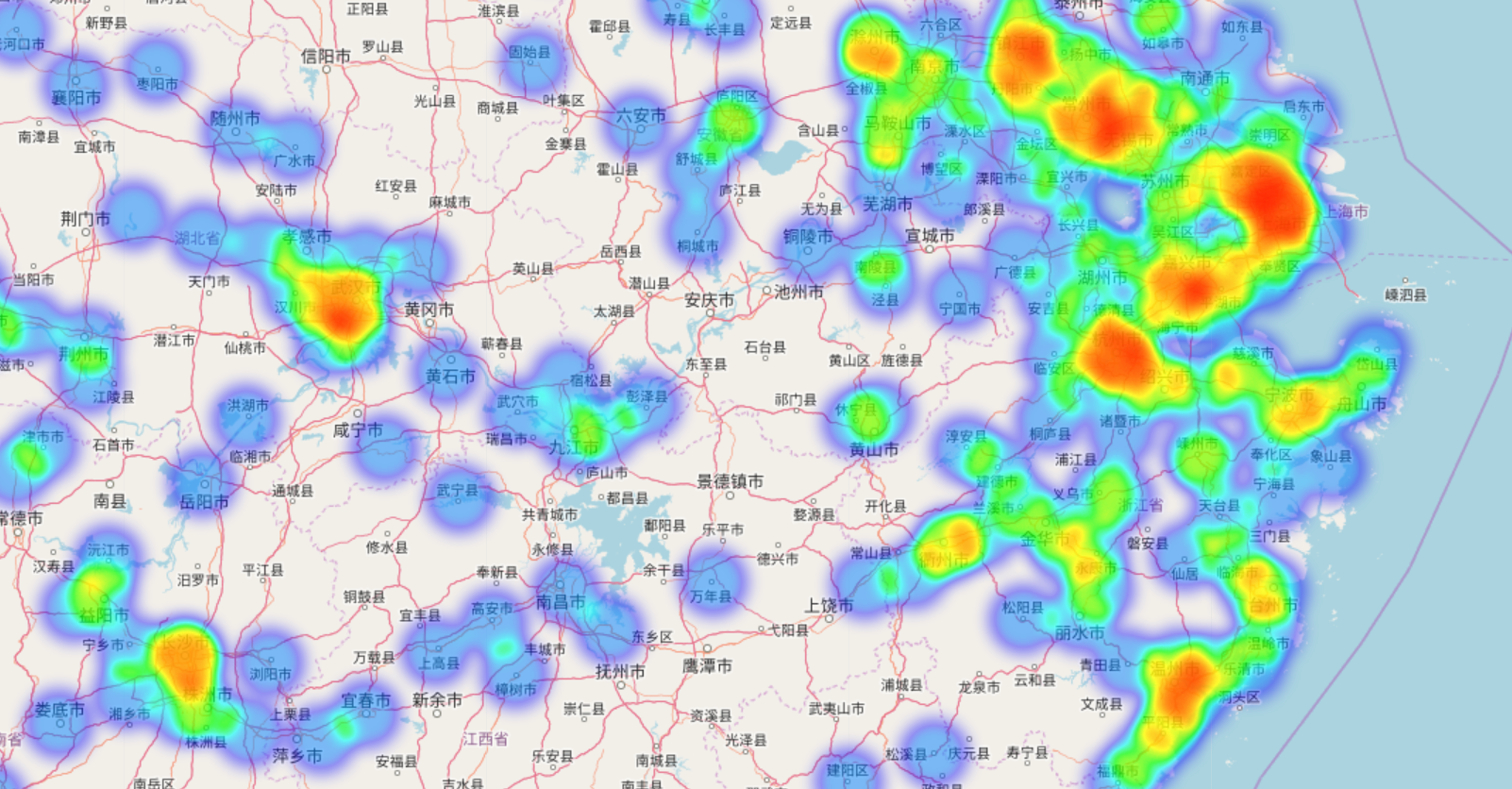
(注意:本模块在绘图时,只绘制那些可以精确地匹配到省市区的地址,对于省市区有一个或多个字段缺失的则会直接忽略)
-----------------------------------以下为2.0版本新增的接口----------------------------------------------
通过pip list查看模块版本,如果版本低于2.0,则应该使用如下的命令更新模块:
pip install -U chinese_province_city_area_mapper
之前版本的绘图接口是基于folium编写的,但是在国内folium的地图显示速度太慢了,所以2.0版本在保留原本的folium绘图接口的基础上添加了echarts的绘图接口.
第一个接口是echarts热力图绘制接口,代码如下,仍然使用之前的测试数据生成的processed变量:
from chinese_province_city_area_mapper import drawers
drawers.echarts_draw(processed, "test.html")
该接口的更多参数及其含义如下:
def echarts_draw(locations, fileName, path="./", title="地域分布图"
, subtitle="location distribute"):
"""
生成地域分布的echarts热力图的html文件.
:param locations: 样本的省市区, pandas的dataframe类型.
:param fileName: 生成的html文件的文件名.
:param path: 生成的html文件的路径.
:param title: 图表的标题
:param subtitle: 图表的子标题
"""
然后会在当前目录下生成一个test.html文件,用浏览器打开后即可看到图像:

第二个接口是样本分类绘制接口,通过额外传入一个样本的分类信息,能够在地图上以不同的颜色画出属于不同分类的样本散点图,以下代码以“省”作为类别信息绘制分类散点图(可以看到,属于不同省的样本被以不同的颜色标记了出来,这里以“省”作为分类标准只是举个例子,实际应用中可以选取更加有实际意义的分类指标):
from chinese_province_city_area_mapper import drawers
drawers.echarts_cate_draw(processed, processed["省"], "test2.html")
然后会在当前目录下生成一个test2.html文件,用浏览器打开后即可看到图像:

该接口更多的参数及其含义如下:
def echarts_cate_draw(locations, labels, fileName, path="./"
, title="地域分布图", subtitle="location distribute",
point_size=7):
"""
依据分类生成地域分布的echarts散点图的html文件.
:param locations: 样本的省市区, pandas的dataframe类型.
:param labels: 长度必须和locations相等, 代表每个样本所属的分类.
:param fileName: 生成的html文件的文件名.
:param path: 生成的html文件的路径.
:param title: 图表的标题
:param subtitle: 图表的子标题
:param point_size: 每个散点的大小,如果样本数较少可以考虑设置的大一些
"""
因为本模块的主要功能是地址匹配而不是画图,所以只是粗略地提供了一些绘图参数控制,如果想要进行更加精细的控制的话,可以自行使用pyecharts进行编码,需要注意的是pyecharts本身也自带一套**地理经纬度信息的数据(地址:https://github.com/pyecharts/pyecharts/blob/master/pyecharts/datasets/city_coordinates.json),这个数据集的一个缺点是没有考虑**的区县重名问题(举个例子,在这个数据集中,“鼓楼区”只对应一个唯一的经纬度,然而,福州市有一个鼓楼区,开封市也有一个鼓楼区),我给出的数据集考虑到了这个问题,所以本模块给出的echarts绘图接口都是基于本模块自带的经纬度数据集的,而不是pyecharts的数据集。如果想更加精细地控制pyecharts绘图参数的话可以直接把本仓库的drawers模块的源码复制过去修改。

