In this repo, I focused on building a Multi-Speaker Text-to-Speech system 😄 In general, I used Portaspeech as an acoustic model and iSTFTNet as vocoder...
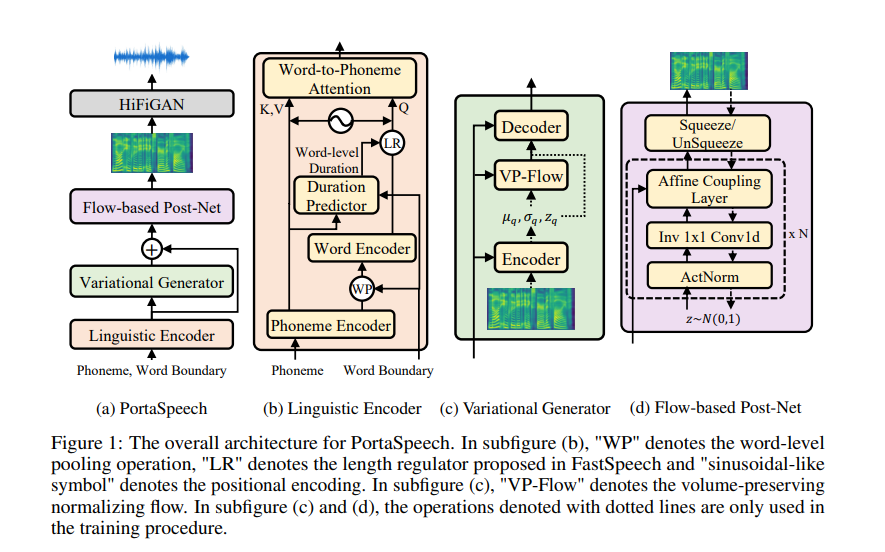
Portaspeech was published in 2022 and it meets the needs of fast, lightweight, diverse, expressive and high-quality by utilizing some special attributes: Mixture alignment, VAE lightweight with enhanced prior as well as flow-based postnet.
Mixture alignment is a big point of this paper, which uses both hard alignment (word level duration) and soft alignment (phoneme level duration) to eliminate the sensitivity of the normal alignment approach and also, an additional word-to-phoneme attention mechanism to capture more information about how relationship between a phoneme and a word. This mixture alignment module can be even applied to other TTS models.
Both Variational Generator and Flow-based Postnet use the linguistic information from the previous block utilize the robustness of normalizing flow and enjoy its benefits during special training and inference strategy. Moreover, the author proposed a sharing parameter mechanism, which furthermore reduces the model parameters, besides the used VAE lightweight-based architecture.
When it comes to vocoder, HiFIGan is quite a common choice, but I just wanna try one more vocoder named iSTFTNet. This reduces the computational cost from black-box modeling and avoids redundant estimations of high-dimensional spectrograms by substituting the inverse short-time Fourier transform (iSTFT) for some output-side layers of the mel-spectrogram vocoder after sufficiently reducing the frequency dimension using upsampling layers. Therefore, it's faster and more lightweight with a reasonable speech quality compared to HiFiGan.

You might want to clone the project and install some required packages in a virtual environment:
cd ViTTS
conda create -n porta python=3.8
conda activate porta
pip install -r requirements.txt
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html # for cuda 11.1
Assume you have a dataset named Article, which contains 2 speakers, each speaker should have wavs folder and a file that contains the scripts (metadata.csv). You need to place your data in folder raw_data as follow:
.
├── configs
│ ├── base
│ │ └── Article
│ └── small
│ └── Article
├── data
│ ├── custom_data
│ ├── lexicon
│ │ ├── lexicon.dict
│ ├── preprocessed_data
│ │ ├── spker_embed
│ │ └── TextGrid
│ │ ├── speaker1
│ │ ├── speaker2
│ ├── raw_data
│ │ ├── speaker1
│ │ │ └── wavs
│ │ │ └── metadata.csv
│ │ ├── speaker2
│ │ │ └── wavs
│ │ │ └── metadata.csv
├── demo
├── output
│ ├── base
│ │ └── ckpt
│ │ └── Article
│ │ ├──143000.pth.tar
│ └── small
│ └── ckpt
│ └── Article
│ ├──65000.pth.tar
├── src
│ ├── models
│ │ ├── vocoder
│ │ │ ├── hifigan
│ │ │ │ ├── generator_universal.pth.tar
│ │ │ └── iSTFTNet
│ │ │ ├── cp_hifigan
│ │ │ ├── g_00090000
│ │ ├── portaspeech
│ │ ├── deepspeech
│ ├── evaluation
│ │ └── MOSNet
│ │ └── pre_trained
│ │ ├── blstm.h5
│ │ ├── cnn.h5
│ │ ├── cnn_blstm.h5
└── tools
Note that, if you don't have alignments which are duration labels for the training process, you need to create them. Here I used MFA to do that. All file saved with .TextGrid tails should be placed like data/preprocessed_data/TextGrid/*/*.TextGrid.
Now, we should first have lexicon.dict in the folder data/lexicon. I actually implemented my own G2P tool here but note that is for Vietnamese. In case you use other languages, just use their corresponding g2p tool. To get the lexicon file (grapheme-phoneme dictionary), you should run:
python3 tools/phoneme_converter.py
Then you should try these commands to get the alignments for the given data:
conda install -c conda-forge montreal-forced-aligner
mfa train --config_path path_to_config/mfa_config.yml ./data/custom_data --clean ./data/lexicon/lexicon.dict ./data/preprocessed_data/TextGrid/ # in case you have lexicon.dict
Next, custom data with:
python3 tools/prepare_alignment.py
Following that, run the below command to create speaker embeddings (using pretrained DeepSpeaker model) and several important folders. This is for conditional input of Portaspeech so that during inference we can adjust which speaker is speaking.
CUDA_VISIBLE_DEVICES=0 python3 tools/preprocess.py
You can start off by training the vocoder (optional but important), here I implemented both HiFiGan and iSTFTNet. To train iSTFTNet, simply run:
CUDA_VISIBLE_DEVICES=0 python src/models/vocoder/iSTFTNet/train.py --config src/models/vocoder/iSTFTNet/config.json
Now you can train the acoustic model:
CUDA_VISIBLE_DEVICES=0 python3 train.py --restore_step 0 --model_type base # small or base version of portaspeech
For inference, run:
CUDA_VISIBLE_DEVICES=0 python3 synthesize.py --restore_step 0 --model_type base --mode single --text text_if_single_mode] --source path_to_txt_file_if_batch_mode
One special note is that you can find necessary checkpoints of iSTFTNet, HiFiGAN and MOSNet, Deepspeech in their official repos and put them in suitable folders as above structure. Meanwhile, I just cannot provide you with the trained acoustic models hehe! Please train it yourself :)
Here I used MOSNet to assess the generated speech. Of course this doesn't 100% reflect the speech quality but anyway it's a useful tool! Otherwise, to really get the most representative MOS scores (P-MOS and Q-MOS) for output speech, you might need a whole system including suitable groups of people following very strict rules, and ... to give feedback on them. Anyway, once you have all necessary trained models, you might wanna run:
cd src/evaluation/MOSNet/
python3 ./custom_test.py --rootdir path_to_folder_of_utterances
You might wanna check another repo of mine here, which supports both frontend (React) and backend (torchserve) developments. It should look like this when you run the service:

Lee, K. (2022). PortaSpeech (Version 0.2.0) [Computer software]. https://doi.org/10.5281/zenodo.5575261
@inproceedings{mosnet,
author={Lo, Chen-Chou and Fu, Szu-Wei and Huang, Wen-Chin and Wang, Xin and Yamagishi, Junichi and Tsao, Yu and Wang, Hsin-Min},
title={MOSNet: Deep Learning based Objective Assessment for Voice Conversion},
year=2019,
booktitle={Proc. Interspeech 2019},
}
@inproceedings{kaneko2022istftnet,
title={{iSTFTNet}: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform},
author={Takuhiro Kaneko and Kou Tanaka and Hirokazu Kameoka and Shogo Seki},
booktitle={ICASSP},
year={2022},
}








