It replicate the data on 3 DataNodes
DataNode directories
Commands:
hdfs dfs -du -h <path>
hdfs dfs -rm -skipTrash <path>
hdfs dfs -get /user/hdfs/warehouse/Ericsson/LTE/CTR/hourly/rlret/customer=bouygues/* /tmp/parquet/
hdfs dfsadmin -report
systemctl status ambari-agent
systemctl status postgresql
sudo ambari-server restart
Logs: /var/log/ambari-server/ambari-server.out
hdfs dfsadmin -report
systemctl status ambari-agent
If is all down on ambari:
1) Start HDF
2) If there is not active NameNode, run the following command from NameNode1 server ONLY IT IS REQUIRED (run it on sparkmaster):
sudo -u hdfs hdfs haadmin -ns nameservice1 -transitionToActive --forceactive nn1 --forcemanual
sudo -u hdfs hdfs haadmin -ns nameservice1 -getServiceState nn2
standby
sudo -u hdfs hdfs haadmin -ns nameservice1 -getServiceState nn1
Active
Once data is processed, goes to warehouse directory and the files are parquet, files can not visualize clicking, but with impala tables we can see it.
Unprocessed data must be in hdfs/raw and then it will be moved to warehouse.
YARN enables multiple data access applications to process it.
Resource Manager keeps the meta info about which jobs are running on which Node Manage and how much memory and CPU is consumed and hence has a holistic view of total CPU and RAM consumption of the whole cluster.
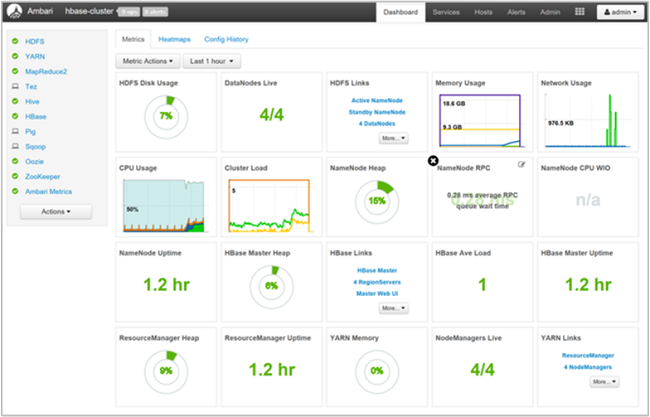
UI: Here we see the running jobs

To manage all the modules