
- CS@ZJU
- Coding for fun, and for free.
- Doing things in a geek way. Everything we have is composable and can be customized!
- 🌱 C++ for Graphics, Python for LLM, Rust for Fun.
- ⭐ Dreaming to be an individual Game Developer
I write blogs using the issues of this repository. Moved to my own blog webpage: https://blog.locietta.xyz/




原文链接: http://llvm.org/docs/tutorial/MyFirstLanguageFrontend/index.html
预备知识:此教程假定您熟悉C++,不过不需要有编译器开发方面的经验
欢迎来到我的第一个基于LLLVM后端的编程语言教程。在此,我们将通过实现一个简单的语言来展示这能有多简单和有趣。本教程将带您快速地过一遍开发流程,并且向您展示一个具体的,使用LLVM来产生代码的例子。
本教程引入了一个简单的Kaleidoscope(万花筒)语言,并在接下来的数章之中逐步搭建这个语言。您可以逐步观察这门简单的语言是如何被实现的。这使得这门教程可以涵盖大部分关于语言设计和LLVM相关的知识,并在此过程中阐释与之相关的代码,却不必涉及各种过于具体的细节。我们特别希望您能使用这些代码——复制,hack,试验,尝试任何您所想的功能。
警告:为了集中注意力在编译器技巧和LLVM上,本教程所示的代码不是软件工程上的最佳实践。例如,这些代码大量地使用全局变量,没有使用GoF访问者模式设计等等。不过这样一来使得事情变得简单明了,让我们能够集中注意力在当前的主题上。
本教程按照不同的主题分为了若干章节,您可以根据需要跳过其中的部分章节:
这一节描述了总体的目标和一些我们希望实现的功能。词法分析器Lexer同时也是构建语法分析器Parser的第一步,我们将用简单而易于理解的C++ Lexer来做演示。
搭建好Lexer之后,我们可以来讨论语法分析技术和基本的抽象语法树构造。这一节描述了递归下降和操作符优先级的语法分析
To be continued...
在WSL上编译安装最新版本的编译器,之后的C开发环境应该会以WSL为主啦
(当然,这个博客也适用于各个Linux发行版)
GCC10.2于2020/07/23发布,修复了10.1存在的一系列bug并且增强了一些支持
我选择了从gcc阿里云镜像下载gcc10.2.0源代码
下载完成后得到一个压缩包👇

将它放到WSL目录下
请务必打开WSL使用cp或者mv命令进行操作,直接利用windows资源管理器移动文件可能会造成不能识别的错误
# 打开bash
cp /mnt/.../gcc-10.2.0.tar.gz ~/gcccd到压缩包目录下输入tar zxvf gcc-10.2.0.tar.gz进行解压
解压大约耗时10分钟
gcc自带configure脚本帮助你配置好一切环境并生成makefile,可以用--prefix=来指定编译目录,否则就将直接编译到当前目录
configure必须在解压出来的gcc目录下才能访问
注意GCC不支持直接编译到源代码文件夹,所以需要我们另外在解压得到的文件夹中建一个build文件夹
mkdir build
cd build
../configure # 利用GCC自带的脚本进行配置
然后如果之前没有编译过的话,会提示你缺了一些依赖👇

...然后网上的一些教程就会告诉你:去那些包的官网下源码然后自己编译接着折腾LD_LIBRARY_PATH变量
说的就是你C S D N
不过这样的教程还挺多的(博客园和阿里云社区上也都有
只能说,不要信这些鬼话(血与泪的教训)
Stackoverflow上这位仁兄说的太好了
就是说嘛,都0202年了,GCC怎么可能还强制要求你自己去折腾呢?🤦
况且自己折腾完全没法处理各种环境配置问题。。
gcc在./contrib目录下提供了download_prerequisite脚本用于下载并解压需要的包
所以只需执行./contrib/download_prerequisite即可,下载没有进度条,需要一定的时间
一段时间的等待过后,当前目录下就解压好所有所需的依赖了,接下来重新进入build文件夹配置
cd build
../configure # --prefix=xxx
再次等待一小会后,配置成功!
回到源代码文件夹执行make -j 32 (其中-j用于指定线程数)
编译相当耗时,如果有没安装的依赖,它会自动配置编译并安装,最后才是编译gcc本体
编译完成大约需要2-4个小时可以先睡一觉
最后sudo make install完成安装
查看gcc/g++版本↓

现在可以体验gcc10带来的concepts, ranges, coroutine等C++20特性了😀
Clang10.0.1
Clang的build基于
cmake,这也意味着可以在windows上采用完全相同的方式来编译Clang不过要编译Clang10的话,cmake的版本至少要在3.13.4以上
官网文档的第一行说明👇
但是...
ubuntu1804目前apt里最新版的cmake也只有3.10.x,所以要想build最新的clang就只能自己去cmake官网下载cmake源码来编译了
第一篇算法,从最基础的搜索开始。
所谓搜索算法,也就是从某个状态出发,按照一定顺序遍历所有能到达的状态来解决问题的办法。一般来说,按照搜索顺序的不同,主要分为深度优先搜索(DFS) 和 广度优先搜索(BFS) 两种手段。
这里我们用一个经典的搜索问题:迷宫最短路问题 来看看这两种搜索方式具体是什么,又有什么异同。
题目描述:
给定一个由n*n的二维数组表示的迷宫,其中只包含0和1,0表示可以走的路,1表示不可通过的墙壁。
最初,有一个人位于左上角(0, 0)处,已知该人每次可以向上、下、左、右任意一个方向移动一个位置。
请问,此人从左上角移动至右下角(n-1,n-1)处,至少需要移动多少次?输入格式:
第一行包含一个整数n,代表迷宫的大小为n*n
接下来的n行,每行包含n个整数(0或1)表示完整的迷宫
输出格式:
若有可行的通道则输出一个整数,代表求出的通道的最短步长;若没有通道则输出"No solution"
输入与输出样例:
输入1:
5 0 0 1 1 0 0 1 0 0 1 0 0 0 1 0 1 0 0 0 1 0 0 1 0 0输出1:
8输入2:
5 0 1 0 1 0 0 0 1 0 1 1 0 0 0 1 1 0 1 0 1 0 1 0 1 0输出2:
No solution输入3:
9 0 0 1 0 1 0 0 0 1 1 0 0 0 1 0 1 0 1 0 0 1 0 1 0 1 0 1 1 0 1 0 0 0 1 0 1 1 0 1 1 1 1 0 0 1 1 0 1 0 1 0 0 1 1 0 0 0 1 0 0 0 0 1 0 1 0 0 1 1 0 1 0 1 1 0 1 0 0 0 0 0输出3:
24
所谓的深度优先指的是从某个状态开始,不断地转移到下一个状态,直到不能继续转移为止,这时候返回前一步,转移到其他的状态,直到到达解状态。
emmm有亿点抽象,那...具体在这个迷宫问题上来看呢?
在迷宫问题上翻译一下深度优先的定义的话:就是说从某个格子出发,不断地往四周的格子走,如果考虑不走回头路的话,那么总会出现不能继续走的情况。这时候,退回到上一步,在上一步走其他的路,如果上一步没有其他的路可走了就再退回到上一步......不断重复这个过程,直到走到终点为止。
这就很直观了,就像一个人通过试错法来走迷宫的过程:先一路走到死路,然后回到前一步选另一条路,不断地试错,这样就遍历了所有能走的路。事实上也就是一种回溯法。
画成搜索树的话就是这样👇

这个搜索过程对应LIFO的栈结构:不断push新的状态入栈,不能继续时,pop出最后push的状态,push另一个状态。而众所周知,所有的栈操作和递归函数是等价的,所以DFS通常用递归来实现。
先来看看DFS解迷宫问题的C++代码(顺便也练习了一下面向对象和STL):
#include <iostream>
#include <stack>
#include <cstdio>
#include <string>
using namespace std;
class Walker : public stack<pair<int, int>> {
private:
const int n_;
int map[50][50] = {};
const pair<int, int> start_, end_;
inline void next(const pair<int, int> &pos) {
const auto &cur = this->top();
map[cur.first][cur.second] = -1;
this->push(pos);
dfs();
this->pop();
map[cur.first][cur.second] = 0;
}
public:
int length = INT_MAX, count = 0;
Walker(const int &n, pair<int, int> &&start, pair<int, int> &&end)
: n_(n), start_(start), end_(end) { // 读取地图
for (int i = 0; i < n_; ++i) {
for (int j = 0; j < n_; ++j) {
cin >> map[i][j];
}
}
this->push(start);
}
bool reach() const { return this->top() == end_; }
void dfs();
};
int main() {
int n;
while (cin >> n) {
Walker w(n, pair(0, 0), pair(n - 1, n - 1));
w.dfs();
w.count ? printf("%d\n", w.length) : puts("No solution");
// w.count ? printf("%d %d\n", w.length, w.count) : puts("No solution");
}
}
void Walker::dfs() {
if (this->reach()) {
count++;
if (int temp = this->size() - 1; temp < length) length = temp;
return;
}
auto pos = this->top();
int i = pos.first, j = pos.second;
if (i && !map[i - 1][j]) next(pair(i - 1, j)); // left
if (j && !map[i][j - 1]) next(pair(i, j - 1)); // up
if (i < n_ - 1 && !map[i + 1][j]) next(pair(i + 1, j)); // right
if (j < n_ - 1 && !map[i][j + 1]) next(pair(i, j + 1)); // down
}Walker类完成了所有的操作,利用pair来保存状态(也就是走到的位置)。为了简明,它直接继承自STL的stack,其中构造函数完成读取的操作,dfs()实现DFS,next()是DFS状态转移的精髓。
所有的DFS都有类似next()的代码:状态转移→递归调用→状态还原。只要掌握了这个,所有的DFS就都会写了。
当然栈和面向对象语言都是不必要的(这里主要是我想练习一下刚学的C++(逃)),我们来看C语言的版本:
#include <stdio.h>
int map[50][50], n, count, length;
void dfs(const int step, int i, int j) {
if (i == n - 1 && j == n - 1) {
count++;
if (step < length) length = step;
return;
}
map[i][j] = 1;
if (i && !map[i - 1][j]) dfs(step + 1, i - 1, j); // left
if (j && !map[i][j - 1]) dfs(step + 1, i, j - 1); // up
if (i < n - 1 && !map[i + 1][j]) dfs(step + 1, i + 1, j); // right
if (j < n - 1 && !map[i][j + 1]) dfs(step + 1, i, j + 1); // down
map[i][j] = 0;
}
int main(void) {
while (scanf("%d", &n) != EOF) {
count = 0, length = __INT_MAX__;
for (int i = 0; i < n; ++i) { // read
for (int j = 0; j < n; ++j) {
scanf("%d", &map[i][j]);
}
}
dfs(0,0,0);
count ? printf("%d\n", length) : puts("No solution");
}
return 0;
}仅28行,单纯依靠dfs()递归来实现,注意下面的这段代码👇
/* 状态转移 */
map[i][j] = 1;
/* 递归调用 */
if (i && !map[i - 1][j]) dfs(step + 1, i - 1, j);
if (j && !map[i][j - 1]) dfs(step + 1, i, j - 1);
if (i < n - 1 && !map[i + 1][j]) dfs(step + 1, i + 1, j);
if (j < n - 1 && !map[i][j + 1]) dfs(step + 1, i, j + 1);
/* 状态还原 */
map[i][j] = 0;是很经典的状态转移→递归调用→状态还原模式。
严格来讲,我这里由于采用了离开的时候才标记的策略,把状态修改给延后了。
如果按照到达时就标记的策略,应该把状态修改塞到每个if分支里。也就是每个if分支都该是一个完整的状态转移→递归调用→状态还原过程
看,是不是很容易~

BFS和DFS很类似,区别只在于搜索的顺序不同:BFS总是先搜索距离初始状态近的状态。
也就是说,它是按照 开始状态→1次转移可以到达的所有状态→2次转移可以到达的所有状态→…… 这样的顺序进行搜索。
在迷宫的例子里,就是说我们按照走1步能到达的位置,走2步能到达的位置...这样的顺序逐一搜索,直到不再有能到达的位置。
想象我们拿着地图,画出一系列的“等高线”,先标距离为1的,再标距离为2的,直到地图上的每一个位置都被标上了要到达所需的步数。
画成搜索树的话就是这样👇

这个搜索过程对应 FIFO 的队列结构:enqueue加入一层的状态,再dequeue丢出最先加入的那一层状态。当然由于BFS依赖于“步数”的概念,所以有时也可以考虑直接利用循环来实现。
BFS的C++代码(夹杂了各种私货,主要是为了练习新学的C++,不过应该还是清楚的(大概))
#include <iostream>
#include <deque>
#include <tuple>
#include <cstdio>
#include <string>
using namespace std;
class Walker : public deque<tuple<int, int, int>> {
private:
const int n_;
int map[50][50] = {};
const pair<int, int> start_, end_;
public:
int step = 0;
Walker(const int &n, pair<int, int> &&start, pair<int, int> &&end)
: n_(n), start_(start), end_(end) {
for (int i = 0; i < n_; ++i) {
for (int j = 0; j < n_; ++j) {
cin >> map[i][j];
}
}
this->push_back(tuple(start.first, start.second, 0));
}
void next();
bool reach() const { return map[end_.first][end_.second] == -1; };
};
int main() {
int n;
while (cin >> n) {
Walker w(n, pair(0, 0), pair(n - 1, n - 1));
while (!w.reach()) {
try {
w.next();
} catch (const char *err) {
cout << err << endl;
break;
}
}
if (w.reach()) cout << w.step << endl;
}
}
void Walker::next() {
if (!size()) throw "No solution";
for (auto &&position = front(); get<2>(position) == step;) {
int i = get<0>(position), j = get<1>(position);
if (i && !map[i - 1][j]) { // left
push_back(tuple(i - 1, j, step + 1));
map[i - 1][j] = -1; // this position has been visited
}
if (j && !map[i][j - 1]) { // up
push_back(tuple(i, j - 1, step + 1));
map[i][j - 1] = -1;
}
if (i < n_ - 1 && !map[i + 1][j]) { // right
push_back(tuple(i + 1, j, step + 1));
map[i + 1][j] = -1;
}
if (j < n_ - 1 && !map[i][j + 1]) { // down
push_back(tuple(i, j + 1, step + 1));
map[i][j + 1] = -1;
}
pop_front();
if (size()) {
position = front();
} else {
throw "No solution";
}
}
step++;
}因为BFS对应于队列操作,所以让Walker类继承自deque,同样重载构造函数用于读入数据,利用tuple<i,j,step>来保存状态。next()函数将下一步的所有可能加入队列,并将上一步的状态移除,并维护一个step变量用于指示现在是第几步。当发现能到达终点时,输出步数。
当然实际上我们仔细思考的话,“地图”和状态完全可以二合一,我们可以把状态信息(这里也就是步数)直接标在地图上,这样一来就可以不用队列来实现这个迷宫BFS.
按照这样的思路,我们可以写出相应的C代码:
#include <stdio.h>
int map[50][50];
int main(void) {
int n, temp;
while (scanf("%d", &n) != EOF) {
for (int i = 0; i < n; ++i) { // read
for (int j = 0; j < n; ++j) {
scanf("%d", &temp);
map[i][j] = -temp;
}
}
int step = 0;
if (!map[0][1]) map[0][1] = 1;
if (!map[1][0]) map[1][0] = 1;
for (step = 1; map[n - 1][n - 1] <= 0; ++step) {
int flag = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
if (map[i][j] != step) continue;
if (i && !map[i - 1][j] && (flag = 1)) map[i - 1][j] = step + 1;
if (j && !map[i][j - 1] && (flag = 1)) map[i][j - 1] = step + 1;
if (i < n - 1 && !map[i + 1][j] && (flag = 1)) map[i + 1][j] = step + 1;
if (j < n - 1 && !map[i][j + 1] && (flag = 1)) map[i][j + 1] = step + 1;
}
}
if (!flag) break;
}
(map[n - 1][n - 1]) ? printf("%d\n", map[n - 1][n - 1]) : puts("No solution");
}
}用了一些技巧把代码压到了30行,思路还是比较简单的。按照步数step循环,最终判断有没有到达过终点。简单的用循环实现了BFS。
不过要注意的是这里因为去除了队列的关系,我们没有保存上一步的所有状态,所以只能每次遍历整个地图寻找标号恰为step的位置,这一操作增加了复杂度。
虽然暑期都快过去了(
大概做不完就是了
基本上应该都是扒谱(
大二了,该搞点事情好好学习了
新的一年了
拖计划也是常态了(尬笑
Learning List
暑假条目中已完成/未完成,但现在热情不高的部分
要想在Windows上安装C环境,最著名的方案之一就是MinGW/MinGW-w64
所谓MinGW是Minimalist GNU for Windows的缩写,也就是一个在Win环境下的简易GNU工具链
这个项目在Windows下建立了原生的GNU工具链,基本上在完美适配了Windows的同时最大限度地还原*nix环境下的C/C++,Fortran,Ada等的开发流程
注:更详细地说,MinGW包含了WIN32的API,能够将代码编译为windows下的.exe,不过不包含MFC等框架(据说DirectX可以,不过估计都挺麻烦的,想用这些最好还是装上一个微软的VS来的方便)
MinGW-w64则是这个项目在64bit环境下的继承,它同时包含32/64bit的支持,现在提到mingw一般都是指mingw-w64
安装MinGW很简单,只需要访问官网的下载页面

你会发现有很多的条目,而我们需要安装的就是途中红框框出的MSYS2
MSYS是Minimal GNU(POSIX)system on Windows的缩写,旨在在windows上搭建类*nix环境,是mingw的进一步扩展,其核心工具链仍然是mingw
pacman而MSYS2是MSYS项目的延续(老项目没人维护了,另一批开发者重新集结,继续推进了这个项目)
那是因为mingw64自带的安装包版本过于老旧啦,特别是对在gcc10添加了C++20支持后特别想试试的人来说,8.x.0版本实在是不得劲
这是由于mingw的在线安装包出了个申必bug(或许只是没人维护(?)),导致只能下载到2018年的8.x版本
结果现在官网下载页上好像直接去掉了这个在线安装包(至少我找不到了)
不过现在CodeBlocks的自带mingw安装应该还是这个(毕竟也没有其他的setup.exe了
大部分人(包括我)接触mingw还都是因为CodeBlocks的吧
实话说如果完全小白的话,装一个CB来获取C编译环境确实是不错的选择
安装了MSYS2之后,就比较方便获取最新版本的mingw(主要是MSYS2的社区比较活跃,以gcc10.2.0为例,在发布的第二天MSYS2社区就跟进了Windows Build)
安装好mingw工具链之后只需要将%MSYS2%/mingw64/bin路径添加到环境变量中即可安然使用gcc10了
另外的话,安装MSYS2之后,除了gcc以外,还能获得一大批Linux命令行程序在Windows下的移植,比如说whereis, pacman, vim一类的命令
只需要将%MSYS2%/usr/bin路径添加到环境变量即可
至于MSYS2的Shell嘛。。不太行,bug挺多的
我就遇到一个线程溢出的bug,由于MSYS2的限制好像只能手动打开资源监视器Kill掉MSYS进程树才能解决
基本上我只把MSYS2当软件仓库用就是了,至于Shell。。不想管,这玩意升级一下都会暴死,还是算了
反正,pacman在添加了环境变量后在cmd/pwsh里也能用,那又何必开个MSYS2-Shell自找麻烦呢
如果打算把MSYS2作为主力Shell的话,更详细的配置可以参照这里
我觉得现在有WSL了,实在不怎么需要MSYS2的Shell就是
不过因为WSL里的程序并不兼容Windows才装了MSYS2的来着
下面简单介绍MSYS2安装mingw工具链
pacman -S mingw-w64-x86_64-toolchain libraries development compression VCS sys-utils net-utils msys2-devel
(滑稽)
没错,确实如此简单。
MSYS2和同类的Cygwin最大的不同就是有一个包管理器pacman(这也是ArchLinux的包管理)
所以下载安装新的软件包相当容易,只需要命令行输入pacman命令即可,作为软件仓库来讲也更加的方便
因为要尝试自己动手编译安装最新版的gcc,所以不得不面临这么个问题...
所以打算开一个简单的记录贴,简单地贴一下各种后缀名的解压方法好了
为了用docker,今天才决定更新到win10 2004
打算另外装一个WSL2的发行版折腾docker和GPU,发现之前装WSL到非系统盘的教程找不到了。现在网上也没找到有这方面的东西,干脆自己写一个留作记录吧~
WSL(Windows Subsystem for Linux) 是win10的一项十分强大的功能。WSL让我们可以像使用普通的软件一样直接使用Linux的功能。配合微软的Windows Terminal,拥有比通常的虚拟机更方便的启动方式(告别需要重启切换的双系统方案吧)。在WSL2更新之后,WSL支持了GPU、图形界面和docker等各种功能,速度也有了不小提升。
但是有一个大问题:在Microsoft Store下载的WSL发行版会自动安装到C盘,不能手动选择安装位置。
如果你不是只有一个C盘的话,基本上WSL里装不了什么东西,C盘就满了。所以我们需要想办法把它装到其它盘去。
有一个办法是找到安装的WSL的位置,然后用
mklink命令打洞到其他盘,不过这里我们采用其它的办法
其实也很简单,微软提供了一个手动下载WSL发行版的网址:手动下载适用于 Linux 的 Windows 子系统发行版包
选择想要的发行版下载后,可以得到一个后缀名为.appx的文件↓
把它的后缀改为.zip,然后解压到想要安装WSL的目录下,我们可以得到一些文件
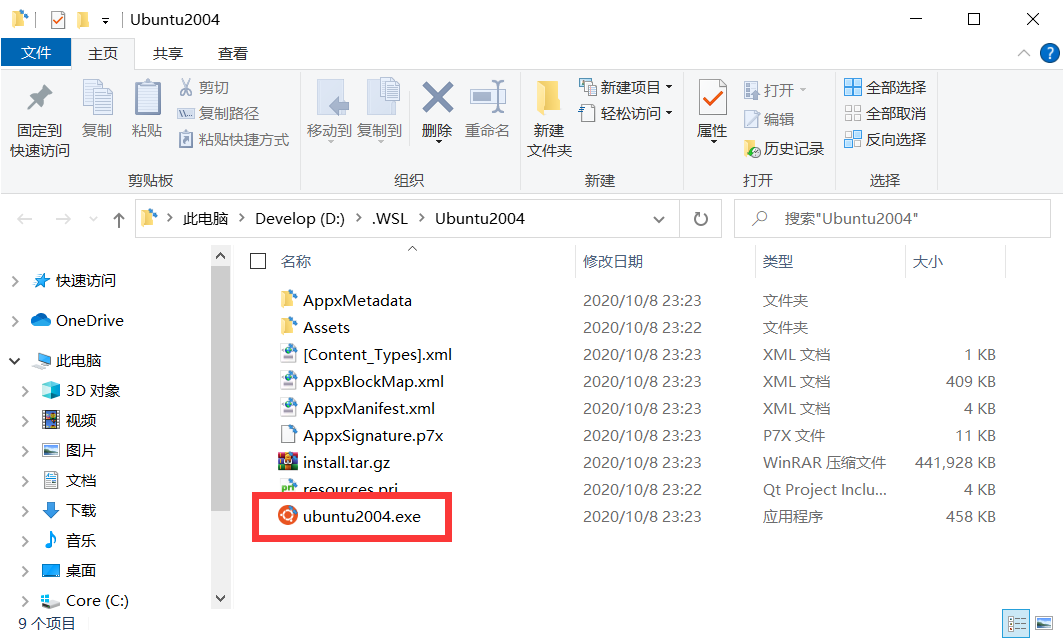
双击红框框出的那个ubuntu.exe(其他发行版的话也有类似的程序),等待一段时间就成功安装到当前目录啦~
需要注意的是安装目录的磁盘不能开压缩内容以便节省磁盘空间选项,否则会报错
0xc03a001a可以右键
文件夹-->属性-->常规-->高级找到并关闭这个选项
原文链接: http://llvm.org/docs/tutorial/MyFirstLanguageFrontend/LangImpl01.html
本教程以一个玩具语言Kaleidoscope为例阐释如何基于LLVM实现一门语言。
Kaleidoscope是一个基于过程的语言,它允许用户定义函数,使用条件判断,数学计算等等。通过这一系列教程,我们将扩展Kaleidoscope语言以支持if/then/else结构,for循环,用户自定义操作符,支持简易命令行界面的JIT编译,调试(debug)信息等特性。
我们希望事情能尽量简单,所以Kaleidoscope语言中只有唯一一种数据类型:64位浮点数类型(也就是C语言中的double类型)从而所有的值都隐含地具有double精度,并且不需要类型声明。这使得Kaleidoscope语言具有非常简单和漂亮的语法。比如,下面这个简单的例子可以计算斐波那契数 :
# Compute the x'th fibonacci number
def fib(x)
if x < 3 then
1
else
fib(x-1)+fib(x-2)
# This expression will compute the 40th number.
fib(40)我们同时允许Kaleidoscope调用标准库函数——LLVM JIT使得这十分容易。这意味着你可以使用extern关键字来定义(这些标准库)函数以使用它们(这对于相互递归调用的函数也很有用)比如:
extern sin(arg);
extern cos(arg);
extern atan2(arg1 arg2);
atan2(sin(.4), cos(42))在第6章有一个更加有趣的例子:我们写了一个简单的Kaleidoscope程序来以各种精度展示曼德勃罗集(译注:一种分形结构)
让我们一起深入这门语言的实现吧!
要实现一个语言,您第一个需要做的就是处理文本文档并识别它表达了什么.。要做到这件事,传统的做法是利用词法分析器(lexer)将输入的源代码分解为一些"token"。每个被lexer返回的token都具有一个token代码以及一些元数据(比如说一个数的数值)。
首先,我们来定义所有可能的token:
// The lexer returns tokens [0-255] if it is an unknown character, otherwise one
// of these for known things.
enum Token {
tok_eof = -1,
// commands
tok_def = -2,
tok_extern = -3,
// primary
tok_identifier = -4,
tok_number = -5,
};
static std::string IdentifierStr; // Filled in if tok_identifier
static double NumVal; // Filled in if tok_number我们的lexer所返回的token要么是Token枚举类型定义的值,要么就是"未知的"符号,比如说'+' 我们返回这些"未知"符号的ASCII值。如果当前的token是一个标识符(identifier),那么IdentifierStr全局变量将会保存这个标识符的名称。如果当前的token是一个数值字面量(比如1.0), NumVal全局变量将保存它的值。这里我们为了简单起见用了全局变量,不过这在真正的语言实现中并不是最好的选择: ).
lexer的实现是一个叫做gettok的函数。我们调用gettok函数来从标准输入中读取下一个token。下面是这个函数定义的开头部分:
/// gettok - Return the next token from standard input.
static int gettok() {
static int LastChar = ' ';
// Skip any whitespace.
while (isspace(LastChar))
LastChar = getchar();gettok通过调用C语言的getchar()函数来从标准输入一个一个读取字符。它识别并读取这些字符到LastChar中,但并不处理它们。gettok所需做的第一件事就是忽略token之间的空白(空格,[tab]之类的不可见字符)。这通过上面所示的循环来完成。
gettok需要做的下一件事是识别标识符和像"def"一样的特殊关键字(keywords)。Kaleidoscope利用下面的简单循环来做到这一点:
if (isalpha(LastChar)) { // identifier: [a-zA-Z][a-zA-Z0-9]*
IdentifierStr = LastChar;
while (isalnum((LastChar = getchar())))
IdentifierStr += LastChar;
if (IdentifierStr == "def")
return tok_def;
if (IdentifierStr == "extern")
return tok_extern;
return tok_identifier;
}注意,每当识别到一个标识符,这段代码就设置一次IdentifierStr全局变量。同样地,因为我们在同一个循环里匹配语言的关键字,所以我们也在这里处理它们。数值也是类似:
if (isdigit(LastChar) || LastChar == '.') { // Number: [0-9.]+
std::string NumStr;
do {
NumStr += LastChar;
LastChar = getchar();
} while (isdigit(LastChar) || LastChar == '.');
NumVal = strtod(NumStr.c_str(), 0);
return tok_number;
}这些都是非常直接的处理输入的代码。当我们从输入读取到一个数值时,我们利用C语言的strtod函数将它转换为数值并存入NumVal变量中。注意这里缺少充分的错误检查:gettok会错误地读取"1.23.45.67"然后把它当作"1.23"来处理。请随意扩展这些代码来应对这些问题吧! 接下来我们来处理注释:
if (LastChar == '#') {
// Comment until end of line.
do
LastChar = getchar();
while (LastChar != EOF && LastChar != '\n' && LastChar != '\r');
if (LastChar != EOF)
return gettok();
}当遇到注释号#,我们就直接跳过该行剩余的部分,并读取下一个token。最后,如果输入不在上述的任何一种情况之中的话,那么这要么是像'+'一样的运算符符号,要么就是文件的结尾EOF。这些情况可以用以下代码来处理:
// Check for end of file. Don't eat the EOF.
if (LastChar == EOF)
return tok_eof;
// Otherwise, just return the character as its ascii value.
int ThisChar = LastChar;
LastChar = getchar();
return ThisChar;
}加上了这段代码后,我们就完成了整个基本Kaleidoscope语言的lexer(完整的代码可以在教程的下一章看到)。接下来,我们将搭建一个简单的,可以生成一个抽象语法树(AST, Abstract Syntax Tree)的语法分析器(parser)。完成了那之后,我们将引入一个驱动(driver)以便同时使用lexer和parser。
sudo apt install zsh

官方GitHub页面:oh-my-zsh's GitHub repository
可以通过curl或者wget来下载并安装
sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
sh -c "$(wget -O- https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
这里我选择使用curl来安装:
然后发现报了一个错👇

之前在win下用git的时候也有过这个错误,大概是SSL证书一类的问题
之前是自签署的证书问题,这次好像是根本没有证书(
总之输入如下命令设置git来忽略各种证书错误:
git config --global http.sslverify false
果然就可以啦

安装完毕,设置zsh为默认的shell,效果如下👇

emmmm....不太行,需要配置一下外观
zsh皮肤文件在$ZSH/themes路径下,这里有各种.zsh-theme文件
可以通过修改~/.zshrc中的ZSH_THEME变量的值来选择不同的皮肤(主题)

当然,也可以编写自己的皮肤文件(后缀名为.zsh-theme的文件)将其存放到$ZSH/themes下,即可像其他主题一样被启用了
zsh主题编写参考这里
不知道要写些啥XD
今天终于结束了短学期机器学习的课,可以偷懒了(不
总之,试试看issue写博客效果如何吧~
Hello World!
原文链接: http://llvm.org/docs/tutorial/MyFirstLanguageFrontend/LangImpl02.html
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.



