liusaint / ls-blog Goto Github PK
View Code? Open in Web Editor NEWJavaScript日常记录 github上的个人博客
JavaScript日常记录 github上的个人博客
如< iframe src="a.com?id=1"></iframe>。对于只要发请求,不需要回调操作的很适合用这种方式。把请求发出去就不管了。
其实是生成一个script标签,因为script标签本身是跨域的。只支持GET请求。
用script标签拿到包裹了数据的方法(相当于是返回了一段js代码),比如回调函数是fnA(data),那么服务端返回的是fnA({status:1,data{}})。然后script标签拿到返回的js代码就可以直接运行回调。
需要前后端代码的一个规范。后端要拿到回调函数名。并处理成前端需要的js代码。
需要浏览器和服务器都支持。
相当于是服务端说明一下我允许来自哪个域的请求。要一些服务端配置。
前端ajax代码几乎不需要修改。
让本域的服务端去请求跨域的数据。然后返回过来到前端。主要是服务端的工作。
对前端来讲,就是一个非跨域的请求。
以nodejs为例,下面的代码可以实现使用
http://localhost:8300/news-at/api/4/news/latest
获取
http://news-at.zhihu.com/api/4/news/latest
这个接口的的数据
var proxyMiddleware = require('http-proxy-middleware')
var express = require('express')
var app = express()
app.use(proxyMiddleware('/news-at', {
target: 'http://news-at.zhihu.com',
changeOrigin: true,
pathRewrite: {
'^/news-at/api': '/api', // rewrite path
}
}))原理:form表单提交可以跨域。form表单提交之后其实是会跳转页面的。将其跳转到一个iframe中去。
如果提交后的页面保持是b域,那么a域依然无法访问iframe的。
从a域发到b域的请求在b域中被处理后重定向到a域的将请求结果和回调函数名放到b域的代理页面中去处理。
所以iframe回到了a域。就没有跨域了。 在iframe中可以互相访问了,可以在iframe中调用它的parent中的函数。
缺点:因为是把数据放到链接中的。url的长度是有限制的。所以处理之后返回的数据的大小是有限制的。
优点:可发送post请求。
本域:a.com\page_a 代理页面:a.com\page_b
外域:b.com
a.com\page_a,也就是我们发起请求的页面。
<iframe src="" name="proxyIframe" id="proxyIframe"></iframe>
<form action="http://b.com" method="post" target="proxyIframe">
<input type="text" name="proxyPage" value="http://a.com/page_b">
<input type="text" name="callback" value="alert">
<input type="submit" value="提交">
</form>b.com后台处理我们的请求:
<?php
$proxyPage = $_POST['proxyPage'];
$callback = $_POST['callback'];
$returnData = ['status'=>1,'data'=>['info' => '操作成功!',]];
//把操作的结果放到发送请求的域内的一个代理页面。
$url = $proxyPage."?callback=".$callback."&arg=".json_encode($returnData);
//跳转到http://a.com/page_b?callback=alert&arg={"status":1,"data":{"info":"\u64cd\u4f5c\u6210\u529f!"}}
header("Location:".$url);
?>a.com\page_b:在iframe中执行。拿到链接上的b域的返回结果和回调函数。运行回调。
// 会在iframe中执行
if(parent == self){
return;
}
var href = location.href;
var callback = href.callback;//伪代码
var arg = href.arg;//伪代码
arg = JSON.parse(arg);
var parentFn = parent[callback];
if(typeof parentFn == 'function'){
parentFn(arg);
}这个方法是在 张容铭的《JavaScript设计模式》第十一章代理模式中看到的。
最近在用cocos动画引擎写应用,为了优化性能封装了一个分帧加载的处理,简单讲就是拿到数据之后不一次性把数据展示出来,而是每一帧展示几个节点出来,每一帧作的操作少,应用体验更流畅。
1秒大概是60帧,每帧大概是16ms,一帧中做的事情太多,执行时间太久,就会导致卡顿掉帧。 由于js是单线程,单个操作耗时不宜太久,要及时把线程让出来,对庞大的任务就需要作任务分解,异步执行。cocos项目或是传统前端项目,都可以利用异步的**来分解任务,优化性能。
封装一个任务队列,每次不直接执行任务,而是把任务往任务队列里面推,由任务中心统一调度。 可实现了2种任务分配方式, 一种每一帧固定执行几个任务,另一种是每一帧里给一个任务执行的总时间,比如8ms,这段时间内能执行几个任务就去执行几个任务。 后者任务完成时间可能会远远小于前者,并且在不同的设备上完成任务的时间可能会差别很大,能发挥机器的最大性能,不同设备都能找到合适自己的节奏,适合于一些比较单纯不会有太多副作用的任务。前者相对会耗时久一些,对于一些可能会引起很多其他副作用比如会发请求的任务,保持一种克制性的缓慢是有必要的。
在cocos中,可以在每个场景加一个调度组件,放上对应该的脚本,利用这个组件脚本的生命周期update做每一帧的处理。在传统前端项目中则需要自己在每一轮任务结束后去延时执行下一轮任务。
其实人也是这样,不能一次想把事情干完,要有节奏,有条理,有控制,适时把舞台让出来,才能更执久,保持身心健康。
IE9有个console的坑。即window.console对象可能是不存在的,也可能是存在的。所以代码中遗留的console.log都可能是引起报错代码中断。而当你把控制台打开,这个console就存在了,代码就能正常运行了。所以一般人并不容易找到代码的问题出在哪里。
早期的解决无非是
(function() {
if (!window.console) {
window.console = {}
console.log = function() {}
}
})()
这样就保证了运行console.log不报错。
但是console中其实是有很多方法的,比如console.time。我们需要为所有可能的调用写一个保底的空函数。这样大多数的调用都不会报错了。
(function() {
var emptyFn = function() {};
if (!window.console) {
window.console = {};
}
var consoleArr = ['log', 'info', 'warn', 'error', 'dir', 'time', 'timeEnd', 'trace', 'assert', 'Console', 'debug', 'dirxml', 'table', 'group', 'groupCollapsed', 'groupEnd', 'clear', 'count', 'markTimeline', 'profile', 'profileEnd', 'timeline', 'timelineEnd', 'timeStamp'];
var consoleLen = consoleArr.length;
while (consoleLen--) {
if (!window.console[consoleArr[consoleLen]]) {
window.console[consoleArr[consoleLen]] = emptyFn;
}
}
})()
IE9下面的console方法只有9个。而chrome下有20多个。正常情况下现在使用console下的各种方法都不报错了。
但是测试说IE9偶尔会报console.time的错。输出console一看,发现并没有自已添加的那些方法。是我的兼容代码没有运行吗?不是的,分析了下流程应该是这样:打开网页的时候测试并没有打开控制台,这时console对象不存在,我们自已创建了一个并且挂了很多空的方法上去,包括了IE本来没有的方法。但是在打开控制台的瞬间,浏览器又自已定义了一遍console。于是我们添加的那些多余的方法又没有了。调用IE不存在的console方法还是报错了。
当然,对于普通用户来讲其实做到这个地步已经够了,因为普通用户不会打开控制台来看,会打开控制台的用户一般也不会用IE浏览器了。不打开控制台,代码也是能正常运行的。
最后,出于对代码健壮性的考虑。我们可以不直接使用原生的console方法。而是自已在外面封装一层。调用我们封装之后的方法。这样我们不管是简单地防报错中断,还是针对浏览器写shim方法。都能减少代码的不可控性。当然,如果有这样封装,一定要在代码规范里写清楚,避免其他同事直接调用相关原生方法。
看你写的抢购插件了,用来买小米8可以,不知道能不能抢购米8探索版?今天偶然看到小米今天抢购米8探索版,压根就抢不到,偶然看到你写的这个插件了,上来问问支持抢购米8探索版么?
<script>
alert(1);
setTimeout(function(){
alert(1.1)
},0)
ddd//故意报个错
alert(1.2);
</script>
<script>
alert(2);
</script> <script>
alert(1);
setTimeout(function(){
alert(1.1)
},0)
ddd//故意报个错
alert(1.2);
alert(2);
</script>请问输出顺序是什么?
动态添加的script标签不会阻塞。
var scriptObj = document.createElement("script");
scriptObj.src = 'a.js';
scriptObj.type = "text/javascript";
scriptObj.id = 'ak';
document.getElementsByTagName("head")[0].appendChild(scriptObj);
console.log(document.getElementsByTagName('script').length);
console.log('haha')
React 使用总结
最近到了新公司,开始用 React 写项目。开始自己搭了脚手架,后来直接用了 ant-design-pro。毕竟很多组件是现成的,节省工作量。
经常有这样的功能需求,当路由变化,用户要离开页面的时候提示用户正在编辑是否确认要离开。在 react-router4 之前可能有对应的 React 生命周期 routerWillLeave 来实现。到了react-router4 则提供了组件 Prompt。官方文档参考:https://reacttraining.com/react-router/core/api/Prompt。粗略看了一下它不太好实现自定义样式,比如我们要使用 ant-design-pro 中的 Modal.confirm 是不太好实现了。
于是找到一个替代组件,react-router-navigation-prompt。https://github.com/ZacharyRSmith/react-router-navigation-prompt。使用方式类似下面。给自定义的 modal 组件传入组件的 onConfirm 和 onCancel 回调就行。
<NavigationPrompt when={this.state.needConfirm}>
{({ onConfirm, onCancel }) => {
Modal.confirm({
title: '确认离开?',
content: '此时离开,已编辑内容将不会保存',
autoFocusButton: null,
onOk: onConfirm,
onCancel: onCancel,
});
}}
</NavigationPrompt>
注意,某些情况下会弹出 2 次确认框。
某个页面有大量的渲染传统组件的需求,我们因为某些原因使用了修改后的 webuploader 做上传组件,并且该页面初始化上传组件的次数非常之多。
需要非常严格地检测是否要重新渲染上传组件,在 componentWillReceiveProps 中做严格的判断,不能多初始化,不能不初始化。
ant-design-pro 的面包屑与菜单主要是由 config/router.config.js 中的路由配置来实现。参考文档:https://pro.ant.design/docs/router-and-nav-cn 。
文档有些地方写的并不是特别清楚,一个页面的 path 是 /a/b/c,那么面包屑的生成顺序可能是['/a','/a/b','/a/b/c']这样子,并且如果'/a'是左边菜单中的某一项,那么此时'/a'菜单项也是处理选中状态的。所以有时候根据面包屑需求的不同,要修改的可能不是路由的结构层级,而是路由中的各项 path路径。
除了根据路由配置生成的面包屑,一定程度上也可以自定义,给 PageHeaderWrapper 组件传入 breadcrumbNameMap 属性。这个属性具体内容,文档上写的不是很详细,这里简单说下,比如某个页面 path 为'/a/b/c',那么可传入:
const breadcrumbNameMap = {
'/a': {
name: '一级',
locale: 'a',
},
'/a/b': {
name: '二级',
locale: 'b',
},
'/a/b/c': {
name: '三级',
locale: 'c',
},
};
最终生成的面包屑为:一级/二级/三级,如果二级'/a/b'不传入,则生成一级/三级这样。
(待续)
最近遇到一个奇怪的问题。IE9下面,不打开控制台代码无法正常运行,
一打开控制台就没有问题了。
对于惯于用控制台调试bug的人来讲,打开控制台,问题就没了,还怎么调试。
灵机一动想起来不知道哪本书上看到的。onerror方法的改写。似乎挺合适这种情况。多看书果然有好处。于是一试。
原始代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>error</title>
</head>
<body>
<script>
console.log(123);
alert('Running normally!');
</script>
</body>
</html>从浏览器一打开就没打开过控制台的话,这段代码在IE9或360兼容模式下是不会弹出Running normally!的。
如果打开了,请关闭浏览器重新打开。
现在增加onerror方法:
window.onerror= function(){
var htmlArr = [];
for (var i = 0; i < arguments.length; i++) {
htmlArr.push(arguments[i].toString());
}
alert(htmlArr.join('\n'));
return true;
}
console.log(123);
alert('Running normally!');不开控制台的情况下,遇到错误弹出(错误原因、文件、行号)
console未定义
error.html
19
原理:修改window.onerror方法会在代码遇到错误时进行一些你自定义的操作。比如这里输出错误信息(arguments中拿)。
于是问题就找到了。查一下就知道。在早期的IE浏览器中,有时console对象需要
在控制台打开后才会存在。
于是全局添加一个防止console报错的函数。这里只对console.log作了处理,因为用得多。现在我们公司的库的公共文件里都加上了这一句。以避免console在IE下的bug。当然,理论上console在生产环境上还是要少用。只是以防万一。
;(function(){
if(!window.console){
window.console = {}
console.log = function(){}
}
})();至此,问题解决。IE9下运行。弹出Running normally!
删除window.onerror方法。
这里主要记录两点:
1.IE下的console的bug。
2.使用window.onerror在不打开控制台的情况下弹出错误信息解决一些不方便打开控制台的bug。
最近越来越感觉到正则表达式的强大,可以简化很多代码。并且正则表达式入门并不是很难。简单列一下JavaScript中使用正则表达式的一些方法。
//定义几个会用到的变量
var href = 'baidu.com?where=b5s&a=b';
var regObj = /(\w+)=(\w+)/;
//全局搜索
var regObj1 = /(\w+)=(\w+)/g;regObj.test(href);//trueconsole.log(regObj1.exec(href));//[ 'where=b5s', 'where', 'b5s', index: 10, input: 'baidu.com?where=b5s&a=b' ]
console.log(regObj1.lastIndex);//19
console.log(regObj1.exec(href));//[ 'a=b', 'a', 'b', index: 20, input: 'baidu.com?where=b5s&a=b' ]href.search(regObj1);//10
href.search('a');//1
href.search('abcd');//-1匹配不到href.match('123');//null
href.match(regObj1);//[ 'where=b5s', 'a=b' ]var splitRegObj = /&|\?/;//以&或?分割
href.split(splitRegObj);//[ 'baidu.com', 'where=b5s', 'a=b' ];var res = href.replace(/a|c/,'aaaa');//b__idu.com?where=b5s&a=b 单个替换
var res = href.replace(/a|c/g,'aaaa');//b__idu.__om?where=b5s&__=b 全局替换
var res = href.replace(/(a|c)/g,'$1-$1');//ba-aidu.c-com?where=b5s&a-a=b 对正则分组的反向引用替换var res = href.replace(regObj1,function(){
return 123
});//baidu.com?123&123var res = href.replace(regObj1,function(match,$1,$2,index,input){
console.log(arguments); //{ '0': 'where=b5s', '1': 'where', '2': 'b5s', '3': 10, '4': 'baidu.com?where=b5s&a=b' };
});//baidu.com?undefined&undefined 这里没给返回值。var obj = {};
href.replace(regObj1,function(match,$1,$2){
obj[$1] = $2;
return match;//返回匹配的值,即不会修改原始的字符串
})
console.log(obj);//{ where: 'b5s', a: 'b' }我们某个项目基于requirejs。发现一个模块require加载失败后再次require并不会重新去请求该模块,也不会执行回调。感觉算是个bug吧。
进入页面后突然断网,控制台输入:
require(['a'], function() {
console.log(1);
});
'a'模块加载失败,不会执行回调。
网络恢复,再执行:
require(['a'], function() {
console.log(2);
});
不会再次去请求a模块,也不执行回调。html的head标签中有a.js的script标签。
这样显然不太合理。
一个解决办法是使用requirejs.onError方法来处理。
requirejs.onError = function(err){
var failedId = err.requireModules && err.requireModules[0];
if(failedId){
console.log(failedId+'加载失败');
requirejs.undef(failedId);
}
}
使用了这个代码之后,再次require(['a']),就会重新去请求a模块。这个全局函数requirejs.undef()用来undefine一个模块。它会重置loader的内部状态以使其忘记之前定义的一个模块。但是若有其他模块已将此模块作为依赖使用了,该模块就不会被清除。
这样我们再次require,就能成功请求到数据并且执行回调。
不过,另一个问题是,执行的回调,不只是本次require的回调,还包含前几次require的回调。
看了下api和源码中对应的部分,好像没有合适的接口来控制要不要执行之前的失败加载的回调。如果要自定义控制,大概就需要修改源码中的requirejs.undef()函数了。
写了一年小程序,每天接受数万付费用户的考验,踩过小程序的坑数不胜数。先写一下视频篇,写一些会影响到用户正常看视频功能和影响业务主体流程的坑。
需要接入转码,提供2种分辨率的视频。如果检测到播放高清视频报错,自动切入低清视频。也有可能高清视频播放不出来,也检测不到报错,所以还需要一个按钮来手动切换标清视频。问题现象是在有些设备直接播不出来,在有些设备上是有声音但黑屏无图像,可能会报一些类似MEDIA_ERR_DECODE(-4003,-1)这样的报错。
小程序video已经支持同层渲染,但是在某些版本微信某些设备上,比如某些三星设备,同层渲染可能失效,导致在视频上面的按钮看不到。所以对于一些重要的按钮功能。可以做一些彩蛋式的操作:比如连续点5下屏幕,触发切换标清的逻辑。避免按钮没显示出来用户播放不了视频也切换不了标清。
可以加一个检测,如果调用ended事件的时候,最大播放进度离视频长度还有一段距离。可以尝试触发切换标清的逻辑接着播放。
iOS用户偶现播放视频的时候会出现播放不了黑屏,可能会报MEDIA_ERR_NETWORK。这个时候把视频的链接给用户,直接在微信中播放大概率也播放不了。 这个问题很大程度跟用户网络有关系,可以切换网络或者还原网络试一下,有时候会生效。比如国外播放我们国内的视频,就有很多用户会出现问题。
iOS用户偶现播放到结束的时候不会调用ended事件,而是会回到开头,重新播放。对于视频播放结束之后需要做一些操作的程序,就要做一些特殊的检测,比如当前的最大进度已经到了视频长度后,进度又突然变到了0。就可以手动结束视频播放,调用结束回调函数。
部分Android用户视频快结束的时候会一直卡在最后几秒钟过不去。针对这种情况,在播放快要结束的时候增加一个定时器。到定时器触发的时候,视频还没有调用ended回调,就手动去调用一下。
用户设备存储空间剩的很少的时候,视频播放也有可能会有问题,可能会有MEDIA_ERR_DECODE(-4999,-1)这样的错误,经常出现在一些华为的机器上。实际上在设备存储空间很少的时候,小程序的其他很多功能都会受到影响,包括网络请求,资源下载等。
还有某些时候视频没有声音之类的,可以用重启大法。
实际填坑的时候根据业务场景可能要考虑的更多,比如拖动进度条之类的会造成的影响之类。
后续还会更新微信小程序其他方面的坑,原则还是只提供大概思路。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>使用ul,li模拟multiple select。实现拖拽多选,不按ctrl,单击选中</title>
<link rel="stylesheet" href="select.css">
</head>
<body>
<div class="title">原生select</div>
<select name="" class="ori_select" multiple="">
<option value="1">1</option>
<option value="2">2</option>
<option value="3">3</option>
<option value="4">4</option>
<option value="5">5</option>
<option value="6">6</option>
<option value="7">7</option>
<option value="8">8</option>
<option value="9">9</option>
<option value="10">10</option>
<option value="11">11</option>
<option value="12">12</option>
<option value="13">13</option>
<option value="14">14</option>
<option value="15">15</option>
</select>
<div class="title">模拟select</div>
<ul class="ul_select">
<li value="1">1</li>
<li value="2">2</li>
<li value="3">3</li>
<li value="4">4</li>
<li value="5">5</li>
<li value="6">6</li>
<li value="7">7</li>
<li value="8">8</li>
<li value="9">9</li>
<li value="10">10</li>
<li value="11">11</li>
<li value="12">12</li>
<li value="13">13</li>
<li value="14">14</li>
<li value="15">15</li>
</ul>
<script src="http://apps.bdimg.com/libs/jquery/1.8.1/jquery.min.js"></script>
<script src="select.js"></script>
</body>
</html>$(function() {
/*模拟select功能 begin*/
(function() {
var $startLi, //移动的初始节点
$currentLi, //移动的当前节点
currentIndex, //当前节点的索引
startIndex, //初始索引
maxIndex, //本次移动的最大索引
minIndex, //本次移动最小索引
isMoving;//是否在移动中
//避免重复绑定,先解绑事件。
$('body').off('.ul_select_event');
//数据同步。仅仅是从模拟的同步到原生的。
function setSelectVal() {
$(".ori_select").val('');
$('.ul_select .choosed').each(function(index, el) {
var val = $.trim($(this).attr('value'));
$('.ori_select option[value="' + val + '"]').prop('selected', true);
});
}
//不使用ctrl,单选的时候选中选项
$("body").on('click.ul_select_event', '.ul_select li', function(event) {
$(this).toggleClass('choosed');
setSelectVal();
});
//鼠标按下去的事件。
$("body").on('mousedown.ul_select', '.ul_select li', function(event) {
//mousedown的时候,部分数据需要初始化。
$startLi = $(this);
startIndex = maxIndex = minIndex = $startLi.index();
//延时一点。绑定。一定程度避免点击事件跟移动事件的冲突。
setTimeout(function() {
$(".ul_select li").on('mousemove', function(event) {
isMoving = true;
$currentLi = $(this);
currentIndex = $currentLi.index();
if (currentIndex > maxIndex) {
maxIndex = currentIndex;
}
if (currentIndex < minIndex) {
minIndex = currentIndex;
}
for (var i = minIndex; i <= maxIndex; i++) {
$('.ul_select li').eq(i).removeClass('choosed');
}
if (currentIndex >= startIndex) {
for (var i = startIndex; i <= currentIndex; i++) {
$('.ul_select li').eq(i).addClass('choosed');
}
} else {
for (var i = startIndex; i >= currentIndex; i--) {
$('.ul_select li').eq(i).addClass('choosed');
}
}
})
}, 50)
});
//结束移动状态
$("body").on('mouseup.ul_select_event', function(event) {
$(".ul_select li").off('mousemove');
if (isMoving) {
isMoving = false;
setSelectVal();
}
});
})();
/*模拟select功能 end*/
});微信公众号开发接口配置需要一个外网能访问的域名。localhost不在这个域名下,wx.config会失败。如果每次修改都发布到测试环境,又太影响开发效率。
总结一下除了直接上测试环境之外的两种本地jssdk调试方案。
让外网能通过某个域名访问到我们本机的localhost。从而实现在本机上修改看效果。参考 https://blog.csdn.net/differ_c/article/details/54880316
使用测试环境的域名,或者自己注册微信平台测试号配置的域名都可以。
本地的项目一般不是80端口。所以要用nginx代理一下。本地的项目是80端口,则可以直接配置host,不需要另配nginx。
本地启nginx,映射localhost:3000到test.com(实际的测试环境地址),
增加host 127.0.0.1 test.com 本机就可以通过test.com访问本地项目localhost:3000了。
测试wx.config,成功。 要在手机上使用test.com看本地项目效果的话,需要手机跟电脑在同一个内网,然后让电脑代理手机的请求。
推荐一个小工具SwitchHosts,方便在不同的host之间切换。
工具使用参考:
配置:/usr/local/etc/nginx/nginx.conf
server {
listen 80;
server_name test.com;
location / {
proxy_pass http://127.0.0.1:3000/;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
}
}
修改配置后要reload
sudo nginx -s reload
参考文章:
使用手机访问test.com要能直访问我们的本地项目,需要代理手机的请求。可以用微信开发工具自带的真机调试功能,也可以使用Charles代理请求。
Charles使用相关文章:
建议安装url转二维码的chrome插件:https://cli.im/news/6527 快速访问电脑上的网页。
缓存请求,并保持缓存内容大小与性能之间的平衡。比如某个请求涉及大量的数据库操作,耗时很长,并且有一定概率多次请求。在这个数据的实时性和重要性不是那么强的情况下,我们可以将请求结果缓存到变量中或浏览器的一些别的存储机制中。但是缓存内容过多也会对性能有影响,所以我们也要根据一定的规则(比如访问频率,访问先后时间,缓存总数量等)及时地清除部分缓存。如果不想改动代码,那么http响应可以返回Expires http请求头,在过期之前就不再发请求。
cookie优化,减少cookie传输量
Bigpipe技术。产生于Facebook公司的前端加载技术,它的提出主要是为了解决重数据页面的加载速度问题,是一种数据渐进式预加载方案,基于HTTP Chunk。
PWA技术。service worker。
避免空的src和href。
图片懒加载。lazy load。
脚本加载优化
requestAnimationFrame方法。
逻辑优化,减少耗时操作。很多功能并不是只有一种途径去实现。如果一种操作特别耗时。也许可以优化一些逻辑就减少这样的操作。
定时器的控制。
应用中存在过多的定时器会影响性能。特别是单页应用中,如果我们定义了一些定时器而没有随着场景消失而清掉定时器,还可能会产生很多逻辑上的问题。
正则表达式优化。
css gpu加速。
补充:
20.memoize。缓存函数结果。对于某些递归效果特别明显。
欢迎补充交流。github地址:#22
最近玩一个叫动物餐厅的微信小游戏,挺有意思。
看到淘宝上有买游戏中的小鱼干的,试试能不能给自己加一些游戏中需要的东西。
简单写下尝试流程。
发现charles的功能还挺多的。程序员要实现一个东西也可以有很多种方法。程序员能做的事情也可以更多。
over。
最近做leetcode题目。总结一下二叉树遍历的一般方法。
function Node(val){
this.left = this.right = null;
this.val = val;
}
var node4 = {left: null, right: null, val: 4 };
var node5 = {left: null, right: null, val: 5 };
var node6 = {left: null, right: null, val: 6 };
var node7 = {left: null, right: null, val: 7 };
var node3 = {left: node6, right: node7, val: 3 };
var node2 = {left: node4, right: node5, val: 2 };
var node1 = {left: node2, right: node3, val: 1 };
// 1
// /\
// 2 3
// /\ /\
// 4 5 6 7
以一个根节点带两个叶子节点举例。 根据访问的顺序,根节点在前面就是前序(根左右),在中间就是中序(左根右),在后面就是后续(左右根)。
function preorderTraversal(root) {
if (!root) {
return;
}
console.log(root.val);
var left = root.left;
var right = root.right;
left && preorderTraversal(left);
right && preorderTraversal(right);
}
preorderTraversal(node1); //1 2 4 5 3 6 7
function preorderTraversal1(root) {
if (!root) {
return;
}
var stack = [root];
while (stack.length > 0) {
//取第一个。
var item = stack.shift();
console.log(item.val);
if (item.right) {
stack.unshift(item.right);
}
if (item.left) {
stack.unshift(item.left);
}
}
}
preorderTraversal1(node1); //1 2 4 5 3 6 7
function inorderTraversal(root) {
if (!root) {
return;
}
var left = root.left;
var right = root.right;
left && inorderTraversal(left);
console.log(root.val);
right && inorderTraversal(right);
}
console.log(inorderTraversal(node1)); //4 2 5 1 6 3 7
//中序遍历迭代方式。
function inorderTraversal1(root) {
if (!root) {
return;
}
var stack = [root];
while (stack.length > 0) {
var item = stack[stack.length - 1];
if (!item.left || (item.left && item.left.isOk)) {
stack.pop();
item.isOk = true;
console.log(item.val);
item.right && stack.push(item.right);
} else if (item.left && !item.left.isOk) {
stack.push(item.left);
}
}
}
inorderTraversal1(node1); //4 2 5 1 6 3 7
function postorderTraversal(root) {
if (!root) {
return;
}
var left = root.left;
var right = root.right;
left && postorderTraversal(left);
right && postorderTraversal(right);
console.log(root.val);
}
postorderTraversal(node1);//4 5 2 6 7 3 1
function postorderTraversal1(root) {
if (!root) {
return;
}
var stack = [root];
while (stack.length > 0) {
var item = stack[stack.length - 1];
//满足这些就可以直接输出它了。它是叶子节点。或它的子节点都ok了。
if ((item.left == null && item.right == null) || (item.left && item.left.isOk && item.right && item.right.isOk) || (item.left && item.left.isOk && item.right == null) || (item.left == null && item.right && item.right.isOk)) {
item.isOk = true;
console.log(item.val);
stack.pop();
} else if (item.left && !item.left.isOk) {
//如果左边的没ok,就把左边的入栈
stack.push(item.left);
} else if (item.right && !item.right.isOk) {
//如果右边的没ok就把右边的入栈。
stack.push(item.right);
}
}
}
postorderTraversal1(node1);//4 5 2 6 7 3 1
从上往下,从左往右,一层一层的遍历。
var levelOrder = function(root) {
if(!root){
return;
}
var checkArr = [root];
while (checkArr.length > 0) {
var newCheckArr = [];
for (var i = 0; i < checkArr.length; i++) {
var item = checkArr[i];
console.log(item.val);
item.left && newCheckArr.push(item.left);
item.right && newCheckArr.push(item.right);
}
checkArr = newCheckArr;
}
};
levelOrder(node1);//1 2 3 4 5 6 7
JavaScript的事件循环event loop很多文章都写的非常详细了。这里也不多做介绍。
在很多文章中都有介绍鼠标事件Mouse Event是属于macrotask。本文探究一下Mouse Event在event loop的情况。点击事件是同步还是异步?点击事件何时加入事件队列?点击事件加入事件队列的是什么,是回调函数吗?
var btn = document.querySelector('button');
btn.onclick = function(){ console.log('1') }
btn.click();
console.log('2');
输出:
1
2
结论:模拟点击而非真实点击的时候,事件处理是同步操作。
首先,我们用鼠标点的,根据常识,应该是异步的。不过我们依然要验证一下。
我们在线程繁忙的时候发起多次点击,查看执行顺序。
promise.then是属于microtask,事件循环中执行完一个macrotask会把所有的microtask执行一下。所以我们在线程繁忙的时候点击,在点击事件的回调中加入promise.then。如果执行了promise.then中的内容说明执行完了一次事件循环。
var btn = document.querySelector('button');
var promise = new Promise(function(resolve){
resolve();
})
btn.onclick = function(){
console.log('click');
//页面失去响应2s。
var time = new Date().getTime();
while(new Date().getTime()-time < 2000){};
promise.then(function(){
console.log('then');
})
}
连续点三次,输出:
click
then
click
then
click
then
分析: 一次点击->执行click回调->页面卡顿时,线程繁忙连续点击两次->加入promise.then->执行promise.then()->执行下个循环,click->加入promise.then->执行promise.then->执行下个循环,click->加入promise.then->执行promise.then。
如果三次点击是同步,应该先输出三次click,再输出三次promise。
结论:手动点击是异步的。
是我们点击的时间吗?我们来间接验证一下。setTimeout在事件循环中属于macrotask,跟点击事件是平级的。我们在点击事件的回调中中插入setTimeout,查看执行顺序,根据执行顺序我们可以推测加入事件循环的顺序。
var btn = document.querySelector('button');
btn.onclick = function(){
console.log('click');
//页面失去响应2s。
var time = new Date().getTime();
while(new Date().getTime()-time < 2000){};
setTimeout(function(){
console.log('timeout');
})
}
快速点击三次按钮,输出:
click *3
timeout *3
分析:线程空闲时点击第一次(加入事件队列)->执行click->线程繁忙->点击2次(加入2个点击事件到事件队列)->加入第一个setTimeout到队列->
执行第二次点击的回调->加入第二个setTimeout到队列->执行第三次点击的回调->加入第三个setTimeout到队列->执行第一个setTimeout->执行第二个setTimeout->执行第三个setTimeout
结论:加入事件循环的时机是我们点击的时机。
一开始我是这样认为的。既然加入了队列,那么肯定是回调函数咯。结果发现并不是。
如果加入事件队列的是回调函数,会发生什么?
之前一个项目中,测试说狂点保存会保存多次。那个按钮的防重复点击使用的是遮罩,也就是一点按钮,发ajax请求提交,就会出现一个遮罩把按钮挡住,就无法再次点击按钮了。 测试用的的4g内存的笔记本的IE9,那个页面从点击保存按钮到从页面中提取数据,到打开遮罩居然要好几秒。在打开遮罩之前页面一直处理无响应的状态,但是测试可以继续点按钮。我猜想是因为点击事件的回调加入了事件队列,所以后面会执行多次请求。 然后按这个思路把bug解决了。
后来有一天一个偶然的尝试,我发现上次那个bug解决的思路似乎不对,虽然bug也确实是解决了。。。
那个表单提交,点提交之后有一个异步操作,因为用了require.js,在异步操作里有耗时操作获取数据,然后才是打开遮罩,发起ajax请求。
简化场景:
var btn = document.querySelector('button');
btn.onclick = function(){
console.log('click');
setTimeout(function(){
//页面失去响应2s。
var time = new Date().getTime();
while(new Date().getTime()-time < 2000){};
btn.style.display = 'none';//遮罩,用隐藏按钮代替
console.log('timeout');
})
}
连续点击三次,输出:
click
timeout
都只输出了一次。后面两次点击的时候页面处于无响应状态。但是按钮是存在的,并且代码也并没有执行到隐藏按钮那一句去。 由前面的推论,加入事件循环的时机应该是点击的时候。如果回调函数直接加入到事件队列中去了,那么后面还会有四次输出的。
分析:页面空闲->点击按钮(点击加入事件循环)->执行click->加入setTimeout->执行setTimeout->页面卡顿,线程繁忙,第二次点击(点击加入事件循环队列)->页面卡顿,线程繁忙,第三次点击(点击加入事件循环队列)->卡顿结束,按钮被隐藏->延迟点击第二次->延迟点击第三次
推论:加入事件队列的是点击本身,而不是回调。当这个点击事件进入队列的时候,会尝试在该地方去点一下,然后再看该地方的元素有没回调什么的。相当于把整个点击都延迟了。
顺带提一下那个bug之所以会提交多次,是因为那个页面进去的瞬间会加载很多富文本编辑器之类的,执行很多初始化代码,所以页面本身卡的时候点击那个本身带异步函数的按钮,就会出现这个异步操作被多次加入队列的情况。
对上面的结论进行再次验证。我们点击之后,用代码移动滚动条,把第二个按钮移动到第一个按钮我们点击的位置下面。
<body>
<button class="a">打开控制台,快速点击三次</button>
<br/>
<button class="b" style="height: 1000px;">按钮b</button>
<script>
var btn = document.querySelector('.a');
btn.onclick = function(){
console.log('click a');
setTimeout(function(){
//页面失去响应2s。
var time = new Date().getTime();
while(new Date().getTime()-time < 2000){};
window.scrollTo(100,500);//滚动到第二个按钮上。
console.log('timeout');
})
}
var btn1 = document.querySelector('.b');
btn1.onclick = function(){
console.log('click b');
}
</script>
</body>
连续点击a按钮三次,输出:
click a
timeout
click b * 2
我们点的时候虽然是在a按钮上点的,效果却成了点击b按钮的效果。相当于整个点击延迟了。跟我们上面的结论吻合。
分析:页面空闲->点击按钮a(点击加入事件循环)->执行click->加入setTimeout->执行setTimeout->页面卡顿,线程繁忙,第二次点击a(点击加入事件循环队列)->页面卡顿,线程繁忙,第三次点击a(点击加入事件循环队列)->卡顿结束,页面滚动,把按钮b移动到前三次点击的位置->延迟点击第二次,点到b->执行b的click回调->延迟点击第三次,点到b按钮->执行b的click回调。
页面工作线程繁忙时点击按钮,点击事件会在点击页面的时候加入事件循环队列。
加入事件队列的并不是事件的回调函数,而是单纯的点击本身,可能包含了本次点击的位置信息等,
当事件循环轮到执行该事件循环的时候,根据记录的信息延迟点击,
这个时候可能点击到的已经不是鼠标点击时点击的按钮。如果按钮被遮住或隐藏,该按钮是点不到的,但是点击位置出现了其他按钮(移动过来一个按钮),也会执行其他按钮的回调。
都是我根据现象和已知信息进行的推论,我在网上并没有找到相关文献以及理论依据。
查了很久的资料都没有看到相关的。
如果有不对的地方,希望不吝赐教。
编程的一大好处是可以给生活带来很多方便。
比如我有一个放电影的盘,我担心有一天盘坏了,所有的电影文件丢失,那么我需要对文件做一个备份。备份电影到网盘显然不太现实。但是备份电影名字还是可以的。如果硬盘坏了还可以重新对着名字下载。
所以写一个脚本。遍历文件夹,并将所有的文件名字输入到一个txt文档中。
代码如下:
// 读取目录下的文件名。并备份。
var fs = require("fs")
var path = require("path")
var root = path.join(__dirname)
var txt = '';
readDirSync(root)
//读取文件夹的信息。
function readDirSync(path) {
var pa = fs.readdirSync(path);
pa.forEach(function(ele, index) {
try {
var info = fs.statSync(path + "/" + ele);
//判断是不是文件夹
if (info.isDirectory()) {
//递归
readDirSync(path + "/" + ele);
} else {
txt += ele + '\r\n';
}
} catch (e) {
}
})
}
var path = __dirname + 'backup.txt';
//文件不存在刚新建一个。
fs.open(path, 'w', function(err, data) {
//将读取的文件名,写入到此文件中。
fs.writeFile(path, txt, function(err, data) {
console.log(err, data);
})
})对nodejs还不是特别熟悉,很多接口都还要现查。这个代码也没有用异步的方式来写。后面再改写吧。
最近需要写移动端的项目,调研了一下android抓包。
这里主要使用charles抓包。对于https请求,需要在电脑和手机上都安装ca证书。
具体可以先看下这篇文章 :https://blog.csdn.net/ManyPeng/article/details/79475870
我使用小米手机miui10下载的证书是pem格式,需要修改成crt格式才可以正常安装。
完成上面的步骤就可以给手机上的https请求抓包了,但是在抓包小程序的时候,发现抓到的是unknown,实际是没有成功。 微信7.0。 于是安装微信6.7.3,抓包成功。
这个问题的原因是在android 7.0及之后android 8 ,android 9 即使系统选择了信任证书, app也可以自行配置不信任证书。 所以抓包不成功。
这时候如果我们要抓包手机上的一些配置了不信任的app的数据怎么办呢?使用模拟器,直接到android 6中去抓包。 我这里使用的是木木模拟器。
同样,需要给模拟器中的网络设置代理。 以及安装ca证书。才可以代理。 可以参考:https://www.fujieace.com/hacker/charles-mumu.html
还有一种方案是把ca证书放到系统的的ca证书目录下,我在小米8下测试没有成功。参考:https://blog.csdn.net/zhangmiaoping23/article/details/80402954
到了android 6中就比较顺利能抓包到想要的数据了。
很多少儿英语启蒙学习的程序都有26个英文字母大小写笔画绘制的功能。小朋友可以跟着提示,一第一笔的将一个字母写出来。这里解析一下该功能实现流程。
有一些初步的预想后,参考了竞品,流利说少儿英语,lingokids等。
流利说的字母笔画教学,每一笔看起来都很自然,就像是人手写的一样,仔细看会发现,每一次写同一个字母写出来的字都是一模一样的,其实它是有一些预设的轨迹,当用户的触点经过某些关键坐标点的时候,把对应的预设轨迹绘制出来。不过简单的将这些点连起来,看起来不会很自然:绘制的笔画可能会压到某一笔边框上面去,甚至写到边框外面。所以在真正实现的时候,除了最底层的一个字母底图,还会有上层的一个中空的字母图盖在上面,我们在两层图片中间进行绘制,这样即使我们的绘制轨迹有少许的不规则,也被上层图片给盖住了,理想情况下,绘制出来的字母会跟上层边框的形状一样,这里就需要设计的很大的工作量了。解压流利说少儿英语的apk,可以找到他完整的字母图片素材,以及关键坐标点和轨迹坐标点。写了脚本,将这些数据提取出来,还原流利说的绘制过程,最终绘制出来的效果,跟流利说的基本一致。当然我们只是参考他的设计思路,我们的实现也跟他们不一样。流利说少儿英语字母笔画绘制功能还原:
我们采取的方案,**也基本类似,上下两层图片,在中间进行绘制。
理论上讲,只要我们的笔画比上层图片中空的区域更粗,绘制出来的最终图案,就会跟设计预设的图案一样。
然而实际上如果我们绘制出来的曲线比上层图片中空区域更粗的话,虽然最终绘制出来的效果中空区域被涂满之后跟预期一致,但在绘制的过程中,涉及到两笔交汇的地方,就会出现把第一笔填满,然后在第二笔中溢出的现象,很不精致,所以我们的笔触必须比外面中空的区域更细。那么我们就得保证我们绘制出来的曲线是光滑的,不能直接把关键点连接起来,这样绘制出来会有很多毛刺,就需要用到一些曲线绘制算法,经过多个点的平滑曲线绘制。可以参考:http://scaledinnovation.com/analytics/splines/aboutSplines.html
解决了平滑曲线绘制的问题之后,要解决canvas的move事件采样精度的问题。采样精度跟设备有关系,也跟我们手指滑动的速度有关系。我们划的很快,那我们可能就跳过了中间的好几个点,绘制过程就可能被打断。所以我们绘制到某一个点的时候,会记录下这一个点是第几笔第几个点,然后当下一次move事件触发,我们会检测这个点的后面好几个点,同时判断距离上一个已绘制核心点的距离,使我们的轨迹刚好绘制到最近的核心点处,这样能够一定程度上解决划太快和采样精度太稀疏的问题。
这个功能是给小孩子使用的,判断错误不能那么严苛。不一定要触碰到了核心点,沿着字母比划外面一定区域内绘制,手指没有在字母上,只要方向是正确的,我们也会绘制出正确的轨迹,当然不能偏的太离谱,可以通过增大判断触碰点是不是在核心点周围的距离范围实现这一点。在一笔结束和下一笔开始中间的绘制,也不会判错。一笔的最后一两个点,我们可以允许跳过,自动补全。距离上一个绘制点一定区域内都不判错。实现这些之后可以让小朋友也能够很轻松的完成绘制,达到教学的目的。
还有一个很大的工作组成,是设计如何给我们提供这些关键坐标点的数据。设计绘制出路径,路径上的点的密度和大小是可以控制的,设置路径上的每一个点都是1px*1px的大小。 然后将带有每个字母的路径的设计稿上传到蓝湖。 我们拉取蓝湖的数据接口,写脚本从蓝湖标注的坐标数据中,过滤出路径上的点的关键点坐标,再进行一些坐标换算和排序,就可以拿到需要的关键坐标点。 最后根据实现出来的效果可能需要一些补点,使绘制出来的字母更完美。
经过以上步骤,就基本完成了字母笔画绘制教学功能。
UEditor官网地址 http://fex.baidu.com/ueditor/
最近使用富文本编辑器Braft Editor、wangEditor多少都有一些问题。于是使用了比较老牌的富文本编辑器UEditor。虽然也有一些问题,但是好在踩过坑的人多,一般的问题都可以解决。这里总结一下。
UEditor自身提供了contentChange事件,但是UEditor的contentChange事件有bug,按住Shift再输入内容,不会触发事件,比如很多标点符号或大写字母的输入就无法触发contentChange事件。 selectionChange事件也有同样的bug。
处理办法,监听UEditor初始化后的iframe中的body的input事件,在这个input事件中手动触发UEditor的contentChange事件。
var body = ueditor.body;
body.addEventListener('input', function() {
ueditor.fireEvent('contentChange');
});
这样做存在问题: 对于没有按住Shift的输入会触发两次contentChange事件,自身封装的React的组件需要有个过滤,避免一些可能的性能问题。
为什么不直接使用input事件呢,因为富文本内容的有些变化并不是通过input事件引起的。比如插入图片,这些都由UEditor内部自己去触发contentChange事件。
当富文本中没有内容的时候给绝对定位显示一个div。
依然用到iframe中的body。给它绑定focus事件和blur事件。
body.addEventListener('focus', () => {
//隐藏
});
body.addEventListener('blur', () => {
//判断富文本中是否有内容,决定显示与隐藏placeholder
});
另外要注意如果手动修改了富文本中的值也要去判断一下placeholder的隐藏与显示,比如执行了ueditor.setContent。
点击到placehlder的div上手动触发body的focus,隐藏placeholder。
默认从UEditor中导出的有序列表无序列表是这样的结构:
<ol><li><p></p></li></ol>
导致使用富文本中内容的时候可能会有显示上的问题。在UEditor源码找到一个配置参数:
disablePInList: true, //导出有序列表的时候把p标签去掉
加上之后导出的就是
<ol><li></li></ol>
这样了。
UEditor有一个自动保存的功能,默认会把编辑器中的内容保存到localStorage中。这个功能不需要的话配置enableAutoSave:false可以关闭。
但是要注意1.4的版本这样配置可能没有用。 需要到github上下载1.5的版本自己grunt编译一下使用。
测试发现上传图片之后再执行一些粘贴操作的时候,原来上传的图片全部变成了loading状态,不能正常显示。这是因为对于不同域的图片,ueditor会尝试重新上传到本域,就会出现这样的情况。
在图片上传中用户执行提交操作,这个时候取到的富文本内容会包含一个<img class="loadingclass">这样的loading图。 这显然是不合理的。
处理办法是在contentChange的时候往组件上层传递onChange(value)的时候对value进行过滤。
比如使用jq过滤。注意要尽量减少过滤操作。在组件中缓存过滤前的值,如果值没变,就不去执行过滤,不往上触发onChange事件。
var html = ueditor.getContent();
var filterdHtml =
$(`<div>${html}</div>`)
.find('.loadingclass')
.remove()
.end()
.prop('innerHTML') || '';
该功能可通过修改上传图片的插件实现,见第8条。
UEditor有部分配置会在后端,比如图片上传的部分配置,UEditor会调接口去请求。 这不符合我们的项目情况:一来服务端不一定方便给你返回这个配置也没有比要,二来用UEditor中的方法来加载这个配置文件还很容易遇到跨域的问题。
修改源码:
1.将原来服务端返回过来的配置放到 ueditor.config.js中。 比如图片上传的配置。
2.修改源码ueditor.all.js中loadServerConfig方法。 注释掉setTimeout方法中try ...catch请求服务端内容相关的内容,需要以下两句以保持编辑器的其他逻辑正常。
me.fireEvent('serverConfigLoaded');
me._serverConfigLoaded = true;
一般公司都有固定的中台上传接口和返回格式,跟ueditor的不一样。所以用ueditor上传有2个方案。一个是新写一个上传组件显示在工具栏,二个是修改自带的上传组件simpleupload。这里采用第二种,修改插件。
这个插件使用了iframe来上传,实际应用中也会出现跨域的问题。所以我们修改它的上传方法。拿到file后 根据配置文件的的格式和内容来判断文件是否符合要求,然后使用
var xhr = new XMLHttpRequest();
var fd = new FormData();
来上传并执行回调。
上传成功或失败需要设置 input.value="" 避免再次上传同一个文件时点击按钮无反应。
输出过滤:getContent的时候过滤掉上传中和上传失败的图片,在该插件的outputRule中添加 loadingclass的过滤。
if (/\b(loaderrorclass)|(bloaderrorclass)\b/.test(n.getAttr('class'))) {
n.parentNode.removeChild(n);
}
在ueditor.all.js中,上传失败的时候,触发一个自定义事件:me.fireEvent('antdError', '上传失败');
然后在封装的react组件中监听antdError事件就可以了。
目前主是在浏览器下使用JavaScript,偶尔在Nodejs环境使用,发现跟浏览器下还是有很多差异的。先写几个遇到的,后面再慢慢补充。
1.setTimeout的不同。 Nodejs下setTimeout返回的不是数字,且回调中的this与浏览器中不同。
2.直接定义的函数的表现不同。全局环境定义function abc(){}。浏览器下可以直接this.abc()调用,方法abc是window对象的一个属性。Nodejs环境不能这样定义。
3.Nodejs下this的不同。比如全局直接定义this.a = 1; this指向的谁。
待续
一个常见场景,点击保存,获取表单数据,发送请求。
一种防重复点击的策略:点击按钮,出现遮罩,提交请求。。。能不能保证只提交一次请求呢?
未点保存时页面处理很卡没有响应的情况呢?
点了保存后的操作导致页面无响应时继续点保存呢?
在表单超复杂,用户的系统配置低的情况下,获取表单数据可能会花很长一段时间,甚至让浏览器停止响应,这时保存操作导致浏览器停止响应而我们又再次点击了保存按钮,会触发点击事件吗?会在什么时机执行。特别是我们的点击事件触发了一个异步的保存操作的情况下。
看下面的代码。
var btn = document.querySelector('button');
btn.onclick = function(){
console.log('事件响应')
//页面卡5s
var time = new Date().getTime();
while(new Date().getTime()-time < 5000){
}
setTimeout(function(){
console.log('timeout');
},0)
}快速连续点5次按钮。
输出顺序:
‘事件响应‘ 每5s输出一个
‘timeout‘ 瞬间输出5个
一开始以为是点击事件的优先级比setTimeout要高,所以先执行。
后来发现dom点击事件与setTimeout在event loop都是属于macrotask。
是我的5次点击结束之后才会执行到setTimeout,所以是5次点击事件加入消息队列的顺序先于setTimeout,所以先执行。没毛病。
当我们的浏览器因为代码执行时间过长停止响应的时候,依然是可以往事件队列中添加事件的。来自用户操作,来自网络等。
加入遮罩。用display:none。替代。
var btn = document.querySelector('button');
btn.onclick = function(){
console.log('事件响应')
//页面卡5s
var time = new Date().getTime();
while(new Date().getTime()-time < 5000){
}
btn.style.display = 'none';//隐藏
setTimeout(function(){
console.log('timeout');
},0)
}输出:
事件响应 1次
timeout 1次
所以是可以实现只点击一次的效果的。
然而,在我们的项目中,出现了保存多次的情况。
观察发现,只是当开页面的那个瞬间狂点保存会出现保存多次的情况。同时我们的耗时操作是在异步操作中。分离场景如下:
var btn = document.querySelector('button');
btn.onclick = function(){
console.log('事件响应')
setTimeout(function(){
//页面卡2s
var time = new Date().getTime();
while(new Date().getTime()-time < 2000){}
btn.style.display = 'none';//隐藏按钮
console.log('保存数据',new Date().getTime());
},0)
}
//加载完之后让页面卡5秒,在这5s中点击按钮。
window.onload = function(){
setTimeout(function(){
console.log('卡页面,请在卡页面的时候点三次保存')
var time = new Date().getTime();
while(new Date().getTime()-time < 5000){}
console.log('卡页面结束');
},1000)
}在点保存之前页面就很卡的时候,连续点3次按钮:
事件响应 X 3
保存数据 1517486862740
保存数据 1517486864742
保存数据 1517486866742
页面正常的情况下连续点3次保存按钮,输出 事件响应 1次 保存数据 1次
回到上面的问题,遮罩防点击的思路用的时候并不是那么靠谱。所以我们主要考虑页面本来很卡的时候我们再点了多次保存,这个时候遮罩无法阻挡我们保存多次。要用其他的防护措施。比如加个class表示暂时不能点它。
1.循环加载的情况。
2.路径查找的情况。
3.加载执行与模块缓存。
4.变量导出方式。修改导出的变量是否会影响原来的变量。
5.this。
6.兼容写法。
common.js http://javascript.ruanyifeng.com/nodejs/module.html
最近尝试破解某app的网页版和安卓版vip。该app每日能看长/短视频数量有限,看几个视频就会让你充vip。破解之后可以无限观看。
一、网页版破解。
采用了三种方式,其中2,3种方式效果都很好,操作也很简单。
1.类似浏览器插件的做法,控制台注入脚本,循环执行:从页面中找到video标签,将video标签的pause方法替换为空方法。隐藏弹出的注册框,播放被暂停的视频。给video标签添加onPause事件,重复执行。
2.chrome浏览器使用Local Overrides使用本地脚本替换远程脚本。搜索源码发现有个isVip的方法。将app.js存入本地,修改isVip方法,让它返回true。然后使用本地js。
3.观察AJAX请求,找到用户相关的请求。分析哪一个可能是代表vip的字段,然后抓包软件的rewrite功能正则替换一下这个接口返回的内容。
二、安卓app破解。
网页版的体验并不是很好,比app版本差很多,还是决定破解一下安卓app。
首先想到的还是抓包AJAX请求,替换对应的用户相关的接口。然而一抓包发现所有的接口都是经过加密的,看到的并不是明文,也就无从修改。暂时先放弃这条路。
还是老老实实地进行逆向反编译,除了上一次解压少儿流利说app研究他们的笔画教学功能实现之外,这是第一次正式对安卓app进行反编译。遇到了很多的问题,最终还是实现了预期,记录一下过程:
1.使用apktool反编译。得到解压后的文件夹hgsp。
apktool d hgsp.apk.
2.使用jdax查看apk文件,发现并不能看到真正的Java代码。查看AndroidManifest.xml,找到入口文件是com.security.shell.AppStub1。看起来不像是正常的入口,google搜索这个入口,得知这是顶象加固。
3.在手机上安装App,然后使用xposed和fdex2输出真正的dex。一共输出了九个,将这些文件移到电脑里面。使用jdax查看这些dex文件,可以看到正常的Java代码,第一步算是成功了。然后逐步分析Java代码,猜测哪个地方是判断是不是VIP,搜到一个setVipFlag方法,但是出现的地方太多,一一修改的话工作量太大。猜测所有的setVipFlag方法会有一个相对唯一数据来源。找到一个userInfoBean.java的文件,里面定义的字段跟网页版用户接口拿到的字段一样,根据对网页版的分析猜测,修改其中某字段的setter, getter方法可以实现我们的目的。我们不能直接修改java代码。需要修改对应smali文件。
4.将dex文件转化为smali文件夹,放到hgsp文件夹中,多个dex文件夹命名smali smali_classes2 smali_classes3这样,smali文件夹里的内容跟java的文件是一一对应的。dex转smali的方法看下面这个文章。
https://blog.csdn.net/weixin_34319817/article/details/88005176
https://bitbucket.org/JesusFreke/smali/downloads/
5.找到userInfoBean.java对应的smali文件。不懂smali语法没有关系, 给android studio安装java2smali插件,将修改后的java文件转成smali,替换掉对应smali文件里的我们修改的内容。
6.然后要进行的就是脱壳后对加固的修复,加固之后的app的应用入口,替换成了加固的壳的入口,我们需要找到原来的真正的入口。 查询了一下顶象加固的真正入口的地方应该是写在AndroidManifest.xml,有一个APPLICATION_CLASS_NAME的地方说明,但并没有找到,可能升级了,于是进入加固后的入口,发现入口类前面一个配置说明,看起来像是应用入口。复制进AndroidManifest.xml。
@Config(app = "com.XX.XX.MyApplication", appFactory = "android.support.v4.app.CoreComponentFactory", versionStr = "XXX")
public class AppStub1 extends Application {
7.修改之后的App进行打包。apktool b ./hgsp
打包过程中遇到很多错误,可能也是加固的壳对原包的一些干扰性修改。主要是一些xml资源的格式问题。
将类似
<layout name="APKTOOL_DUMMY_1ec"></layout>
这种改成
<item type="layout" name="APKTOOL_DUMMY_1ec" />
打包之后在 hgsp/dist下面有一个hgsp.apk。
这个还不能直接安装,需要进行签名。
8.生成证书并签名。
生成证书,命令行输入:
keytool -genkey -keystore my-release-key.keystore -alias my_alias -keyalg RSA -keysize 4096 -validity 10000
用证书给apk签名
jarsigner -sigalg MD5withRSA -digestalg SHA1 -keystore my-release-key.keystore -signedjar hgsp_sign.apk hgsp.apk my_alias
生成了签名后的apk hgsp_sign.apk。
9.验证。怀着忐忑的心情,把App安装到手机上打开App 。个人中心的播放次数还是没有变。但是播放长视频和短视频,可以无限观看并且没有广告。成功!
看起来挺顺利,其实中间还是费了不少功夫。解决了不少问题。
本文仅作技术交流之用。
做英语学习类产品经常会遇到读句子的时候针对单个单词的类卡拉ok的高亮效果。 这里记录一下音频进度和单词的一一对应关系(类似于歌词文件,粒度为单词级别)如何生成。纯人工来校对的话人工成本还是比较大的。 专业的词语是强制对齐(Forced Alignment)。这里介绍python库aeneas,可针对每句或每个单词的时间节点的json文件,还可以批量操作。准确率还不错。文档:
https://github.com/readbeyond/aeneas
http://www.readbeyond.it/aeneas/
使用方式:
1.安装软件
一键安装包(windows版本和mac版本)
https://github.com/sillsdev/aeneas-installer/releases
2.准备文档。一个文件夹。取名,如folder。
包含
config.txt //配置文件 包含格式、输出路径等
audios/ //音频和句子信息
-- Can_you_see_me.txt //包含对应句子文本
-- Can_you_see_me.m4a //对应音频。 与文本文件名一致
-- Yes_can.txt //可批量操作
-- Yes_can.m4a
3.打开命令行工具、终端。进入folder所在的目录下。创建一个output文件夹。
执行命令行: python -m aeneas.tools.execute_job folder/ output/
4.生成成功。到输出目录下找对应的文件生成文件。可自己写个简单的h5,上传生成的json和音频做准确率校验。
5.Windows下aeneas错误处理。the default input encoding is not UTF-8.You might want to set 'PYTHONIOENCODING=UTF-8' in your shell. 解决方案,终端进入python安装目录下,执行命令如:
cd C:\Python27\Scripts
set PYTHONIOENCODING=UTF-8
6.config.txt配置,包含路径、格式等信息。
is_hierarchy_type=flat
is_hierarchy_prefix=audios/
is_text_file_relative_path=.
is_text_file_name_regex=.*\.txt
is_text_type=mplain
is_audio_file_relative_path=.
is_audio_file_name_regex=.*\.m4a
is_audio_file_detect_head_max=10.000
is_audio_file_detect_tail_max=10.000
os_job_file_name=output_example1
os_job_file_container=zip
os_job_file_hierarchy_type=flat
os_job_file_hierarchy_prefix=audios/
os_task_file_name=$PREFIX.json
os_task_file_format=json
os_task_file_smil_page_ref=$PREFIX.xhtml
os_task_file_smil_audio_ref=$PREFIX.m4a
os_task_file_levels=3
job_language=en
job_description=Example 1 (flat hierarchy, parsed text files)
7.输出。
{
"fragments": [
{
"begin": "1.560",
"end": "2.070",
"lines": [
"Thanks"
]
},
{
"begin": "2.070",
"end": "2.360",
"lines": [
"for"
]
},
{
"begin": "2.360",
"end": "2.950",
"lines": [
"taking"
]
},
{
"begin": "2.950",
"end": "3.405",
"lines": [
"care"
]
},
{
"begin": "3.405",
"end": "3.750",
"lines": [
"of"
]
},
{
"begin": "3.750",
"end": "4.140",
"lines": [
"my"
]
},
{
"begin": "4.140",
"end": "4.520",
"lines": [
"dog!"
]
}
]
}
总结几点大型canvas 2d应用的事件处理机制
canvas画布是一个独立的dom。我们不能给我们绘制的元素单独添加事件。所有的事件都添加在canvas画布上,然后再来分发具体的操作。有点类似于我们的dom事件代理,将事件绑在父层节点,再根据点的dom来决定事件操作。前两年用canvas写小游戏的时候,就是在canvas的dom上绑定事件,然后根据鼠标的位置和所在位置的状态来处理对应的事件操作。
对于多人开发的大型canvas应用,如何处理事件分发?如何分模块来分工?
事件必须有清晰的处理机制,才能让大家分工明确,代码耦合少。而模块划分,可以按照绘制的不同类型的对象或不同的功能操作来分。
假设我们的应用有一个工具栏,工具栏上的每个按钮代表一种可绘制对象或者一种可执行的操作,当我们点击工具栏上的按钮时。就切换成代表工工具栏每种操作的序号toolType。
我们触发onmousedown onmousemove等事件的时候,根据toolType来获取当前操作下对每种事件的处理函数,比如我们的每个模块都返回一个eventHandler对象,这个对象可能包含{mouseDown:function(){},mouseMove:function(){},mouseUp:function(){}}对不同事件处理逻辑。
这样,负责每个模块人只处理自已模块的事件逻辑就好了。
canvas画布上的对象的层级,一般来讲画布上的东西画上去是没有所谓层级的,但是我们要与画布上的东西进行精细的交互,就要在逻辑上给它一个层级。当我们的事件在多个对象的区域范围内的时候,我们应该作用于层级高的对象。这个就要让我们的每个绘制对象保存一个index的属性。 当事件来了,我们可能会给所有的绘制对象按这个index排序。然后遍历判断是否在每个对象的作用范围内。第一个满足条件的进行对应操作,其他的就作不满足的操作。
另外,有了这个index属性,在每次重绘的时候也可以保证不同元素对象的绘制顺序正确。
数据与绘制分开。只要有每个绘制对象的数据信息就能重绘出来。 任何的事件操作只处理数据不实际操作绘制。 数据处理完毕之后统一触发重绘。 这样我们可以分别专注于数据处理与对象绘制了。
每种绘制元素作为一种对象,拥有自已的一套方法。 其中可能有很多同名方法,处理逻辑不一样。也算是一种形式的多态吧。 所有类型的对象也可能拥有很多的公共方法。
比如localstorage最大缓存数量5mb左右。一般情况下用户缓存的数量不会有那么大。但是如果到了最大量,是怎么处理,报错导致本次事件循环任务停止运行,还是给用户以提示,还是以其他某种方式保障后续代码的运行。
setTimeout与setInterval。大型项目中不可避免会有一些timer的使用。正常逻辑下我们的timer是会在某种条件下清除,但是实际应用中,用户可能等待不到该timer清除的时机就离开了该页面,于是就有一个timer被遗忘在那里,但它依然会正常运行!比如我们的项目中,一个页面有很多个不同的编辑器,早先的逻辑里有一个timer,每隔200ms检测一下是否所有的编辑器都加载完毕,然后才可以执行一些操作,等到所有的编辑器加载完毕之后清除该timer。但是用户可能反复进入该页面并且没有等到所有编辑器都加载完毕。于是可能就会有越来越多个timer在同时运行。如果timer中有跟其他模块逻辑交互的地方,甚至有可能会出现逻辑错乱。
处理方式:
我们的实验编辑页面,涉及多个模块,有10几个富文本编辑器,以及其他自定义模块,每个模块又涉及到很多的业务逻辑。
由于我们产品的缓存策略。会比较频繁地从表单中获取数据缓存到localstorage,这中间就有了出错的可能。在我们网络和设备条件好的时候可能感觉不到,但是用户的网络或设备配置比较低,很多问题就暴露出来了。
提交或缓存数据,正常表单的数据一般是可以直接获取到的,但是,富文本编辑器,比如我们用的ewebeditor,kindeditor,结构式编辑器,excel表格等,如果它们没有加载好,原始内容还没有加载到它们的里面,缓存或提交的时候从编辑器中就拿不到数据,如果保存成功,那么该编辑器中之前的数据就丢失了。这种情况下,我们需要逐一判断编辑器是否已经加载好,如果加载好了我们按正常的逻辑走,如果没有加载好,我们就取用于初始化编辑器的原始数据。
另外一种思路是等待所有富文本编辑器都加载好才可以执行缓存或保存的操作,但是从网站可用性来讲,网络和设备的条件多种各样,我们无法保证所有就的编辑器就一定能操作成功。在用户无法加载成功编辑器的情况下,我们保障了功能的可用性并且保证之前的数据不丢失无疑更好。
事件是js中必不可少的功能点。我们一般用原生的事件比较多。但是如果能理解掌握自定义事件,很多功能处理起来会很轻松。是设计模式观察者模式的典型应用了。
比如我们的系统有一个自定义的前端路由管理的模块。我们在这个方法里处理url分发、页面内容替换、以及所有页面加载成功之后共同处理。那么单个页面的特殊的非公共的逻辑要如何初始化呢。
我们在页面完成替换之后触发一个自定义事件。$('body').trigger('pageLoaded');
然后在我们的业务逻辑的某个模块监听这个自定义事件。
$('body').on('pageLoaded',function(){
console.log('这里是日历页面,如果当前打开的是日历页面,请执行后面的代码,否则请return');
})事件命名空间可以对事件进行更好的管理。
对于复杂且没有良好管理全局变量的系统而言。常常因为某个全局变量的意外改变而导致bug。你并不知道是谁在哪个地方动了这个变量,你只是发现你的断点断着断着,断到某个异步函数中之后。这个变量意外的改变了。那么在事件循环中哪里插入了什么任务,就蒙了。
这个时候就要用到Object.defineProperty这个方法了。在setter中放一个断点。当该变量修改的时候调用栈一下子就看到了。
Object.defineProperty(window, 'expUpdate', {
get: function() {
},
set: function(value) {
debugger;
}
});当时定位bug到一个富文本编辑器中的自定义修改中去了。
Object.defineProperty()的set方法除了用于双向绑定还能干嘛?
微信小程序开发的时候,很多接口都不太能信任,需要作一些额外的兜底处理。保证程序在什么情况下都能尽可能健康的运行。 也要有一套健全的异常收集反馈机制,方便迅速发现问题解决问题。 小程序生态的异常监控体系,主要包含小程序后台的代码运行报错,小程序告警群的使用,具体用户的信息收集上报,代码逻辑中可能的预警上报统计,微信新版本的内测跟进等方面。
在ios12上 css3的支持不够好。有时候动画animation的forward无效。现象是动画结束后突然回到初始状态。
极少数ios机型会出现animation-delay失效的情况。
不同组件之间的animation-name如果一致的话会被覆盖,整个小程序中需要确保没有重复的animation-name。
rpx单位计算错误问题,比如从竖屏页面进入横屏页面,再返回竖屏页面,页面元素可能变得特别大,超出屏幕。 横竖屏切换时小程序内部的rpx单位计算错误,解决办法是不使用微信小程序的rpx单位,使用vh,vw单位。横屏页面一般使用vh,竖屏页面一般使用vw。如果小程序已经使用rpx开发完了,可用node脚本替换单位。
早期的微信版本不支持横屏。
触摸事件失效。在canvas和canvas外层绑定touchend事件。业务逻辑中作事件的去重处理。
canvas上画的线条层级比正常元素高,如果正常元素要显示在上层,可以用cover-view放在canvas上层。但是cover-view的pointer-events:none;不生效,事件无法穿透到canvas上。可以在cover-view上层使用一个与canvas同样大小的cover-view来承接事件并作坐标转换处理。
播放音频不完整。锤子手机百分百出现。小米手机小概率出现。 可能使用mp3格式音频会好一些。
获取音频播放进度的接口不准确,一个是更新频率不一定能满足,二个是有时候播放结束之后进度会突然跳到不正确的位置。对于做单词高亮效果等效果影响比较大。解决方案是不用原生的接口获取播放进度,而是使用定时器自己获取从播放开始的时间到当前时间的时间差,从onPlay事件触发的时候开始计时,到onEned事件时结束。需要小程序音频提前下载好再播放,否则拿到的也不准了,如果暂停了或被打断了,就重新播放。
onEnd事件不执行。解决办法在播放结束需要执行回调的情况,需要设置一个最大的预期播放时间 (如果能拿到duration就用duration加一点点),超过了这个时间无论它有没有执行onEnded事件,都执行一下回调。保证回调能执行到。注意控制回调只执行一次。
微信7.0.5 对下载好的音频的临时地址无法播放。
微信7.0.12 出现音频0.5倍速播放的情况。 与代码中onPlay之前的定时器有关系。
有时候设备首次调起录音时间很长,可能超过30s。 本地模拟的话在网特别差的情况能重现出来。 解决办法是进入小程序之后先调起一次录音。 真正要调用录音的时候就会比较快了。
部分机型调起录音失败,会报一些录音机内部的错误,需要重启手机。
录音分片接口onFrameRecorded不稳定。
有时候最后一帧isLastFrame会返回false。可结合定时器和stop接口作一些兜底处理,保证相关回调一定能执行。
可自己实现tab组件。
微信小程序对华为平板的兼容不是很理想,多个微信版本上华为平板上出现了横屏显示问题。7.0.13,7.0.14,7.0.18等。可以通过引导用户修改机器的一些设置来解决。
华为平板进小程序的时候,如果设备处理横放状态,可能无法进入小程序。需要竖屏进入。
主要是vivo x7 x6,x5,以及部分小米低端机型。可以考虑安装旧版本微信。
可以尝试清下微信缓存。关闭后台程序。重启设备等方案。
小概率微信接口拿到的设备型号不对,比如部分ipad机型识别不出来是ipad,可以用屏幕长宽比来加强判断。确保ipad适配生效。
获取右侧胶囊位置不正确的情况。可能需要一些校正。
对vue双向绑定原理稍有了解的人都知道es5给Object增加了defineProperty这个方法,可以监控对象的变化,vue也用了它来实现双向绑定。那么这个方法除了用于双向绑定还能做什么呢?
最近给一个很复杂的项目迭代维护。这个项目很多早期功能是其他人开发的,中间有很多隐藏的坑。
今天遇到一个bug,经过断点调试相关功能,将问题定位到一个全局变量上,在断点开始的时候它的值是true,在运行了大量代码之后,它的值变成了false。断点跟踪了老长一段距离,都没有头绪。还是在坑爹的ie9下面调试。
于是我想,如何监测到这个变量是在哪里发生变化的呢,发生变化的时候的调用栈是什么样子的呢。然后就想到了defineProperty方法。一试,果然很迅速地找到了发生变化的时候的调用栈。
代码如下:
Object.defineProperty(window, 'expUpdate', {
get: function() {
},
set: function(value) {
debugger;
}
});在公共js中放入上面代码,再运行。
很顺利地定位到了改变这个全局变量的地方。
是在一个富文本编辑器源码里。(我们的项目对富文本编辑器的源码做了一些修改)。
成功定位问题,解决就是分分钟的事了。解决问题时候顺便还解决了一个潜在的逻辑bug。
做程序久了,就会发现程序很多人都能写,但是解bug的能力却是相差很大。一方面要经验,另一方面也要对技巧的总结和对技术的运用思考。在不同的场景使用不同的方法,可以大大提高定位问题的准确性和解决问题的效率。
在用户的输入被直接动态拼装sql语句时,可能用户的恶意输入被拼到了sql语句上,而造成了一些恶意操作。比如查询到一些数据甚至删除一些数据。一般应对方法是对sql语句进行预处理。
thinkPHP防sql注入:https://www.kancloud.cn/manual/thinkphp/1844#
想办法让 你 在某个网站上执行 我 的js。
一般情况下,XSS攻击代码会加载一个<script src="..js"></script>的文件。这样的好处是攻击代码可以控制。只要自己修改了恶意脚本,被攻击者也会受到不同的攻击。
比如盗取cookie。
这里先说一下,http是无状态的。服务器端和浏览器端的身份判断一般是通过cookie。 后端会根据请求者传递的cookie信息判断请求者的身份。 攻击者的请求只要是带上了目标用户的cookie,就可以合法请求。
利用跨域标签img iframe等在b网站发送往a网站get请求,会带上a网站的cookie,由此可见对于数据修改的请求最好不要用get。如果你在a站登录了,又访问了恶意网站b,而b上面有一个恶意img标签的get请求,那你的数据可能就被删除了。 而跨域的ajax请求因为同源策略,不会带上cookie,但是也能请求到结果,后端会处理这个请求,不过因为没有携带cookie信息,后端拿 不到登录状态,很多操作不会成功。跨域请求的结果也会发到客户端,不过由于同源策略的限制,浏览器读取不到这个响应结果。
伪造form表单提交。那么,post请求就安全了吗?form表单是跨域的。并且可以提交post请求。我们在b网站伪造一个form表单自动提交到a网站。
对于普通用户而言,别人发过来的网站不要轻易点。不管它是本域的还是跨域的。
var innerA = document.getElementsByTagName('iframe')[0].contentWindow.a;
var inndrB = document.getElementsByTagName('iframe')[0].contentWindow.b;
修改成
var ifrContent = document.getElementsByTagName('iframe')[0].contentWindow
var innerA = ifrContent.a;
var inndrB = ifrContent.b;
$(this).trigger('click');
$(this).find('.b');
$('.a').trigger('click');
$('.a').find('.b');修改成
var $this = $(this);
var $a = $('.a');
$this.trigger('click');
$this.find('.b');
$a.trigger('click');
$a.find('.b');function A(){
var a='',b='',c='';
---函数体---
}$.fn.extend({
alertValue:function(){
alert(this.val());
}
});
$("input.a").alertValue();//这样调用 this指向$("input.a")$.extend({
alert1:function(){
alert(1);
}
});
$.alert1();//这样调用 $(function() {
function Person() {
}
Person.prototype = {
constructor: Person,
bindEvent: function() {
var self = this;
$('body').on('click', '.person-btn', function(event) {
var $this = $(this),
method = '';
if ($this.hasClass('disabled')) {
return;
}
method = $this.attr('method');
typeof self[method] == 'function' && self[method]($this, event);
});
},
sayHello: function($obj, event) {
},
sayGoodbye: function($obj, event) {
}
};
(new Person()).bindEvent();
})
html:
<button class="person-btn" method="sayHello">你好</button>
<button class="person-btn" method="sayGoodbye">再见</button>function log(){
if('dev' == window.environment){
console.log.apply(console,arguments);
}
}
log(1,2);//1,2目前我们兼容到IE9,在系统的时候会遇到一些坑。这里稍稍记录一下。
给一些非表单节点加上了disabled属性,在IE9下,样式也会发生变化。
常常顺手给dom节点,比如按钮上加一个type="1",type="2"这样子,在chrome下运行得好好的,结果到ie9下面getAttribute('type')或$(..).attr('type')运行不正常,调试发现读出来的type都是'submit'
最近跟踪一个bug,event中的某些属性读取不到,发现问题出在这句代码上。当代码执行过去之后,window.event可能已经变了。
所以应该改写成:event || window.event。
这种的选择判断,理论上都应该以高级优先原则。 先看看功能强大 的存不存在,然后再考虑低级一点的。 因为有些浏览器可能是高级与低级并存的。
比如document.addEventListener与document.attachEvent。
可能是因为td之间有换行。
以前遇到IE9下面系统无法运行,但是打开控制台想要调试一下,看看问题在哪,居又能正常运行,这还怎么玩? 后来发现在IE9,8下面,有时候不打开控制台,console对象是不存在的,那么调用console.log就会报错导致js运行不下去,而一打开控制台console对象就存在了,又看不到bug所在了。
这个时候我们可能需要,不打开控制台的调试方法:#4
另外线上环境尽量不要console.log东西出来。可考虑将原生console.log封装一下:
function log(){
if('dev' == window.environment){
console.log.apply(console,arguments);
}
}
log(1,2);//1,2这样正式环境也不会有输出。另外,为了预防其他同事潜在的console.log输出。可以增加以下保险代码。当然,实际可能还有console下面的其它方法也要做处理。
if(!window.console){
window.console = {};
window.console.log = function(){
}
}IE9不支持flex
IE9不支持FileReader
a标签触发onbeforeunload事件
这个情况也不是常常会出现,要看概率。我们的a标签即使加了javascript:void:(0)也触发了绑定的window.onbeforeunload方案,然而页面其实并不会跳转。
一般考虑解决办法是给所有的a标签代理一下,检测到href为javascript时,阻止默认事件,event.preventdefault();但是实际并不是么有效果,特别是后面添加上去的a标签。比如生成的ajax分页的a标签,连jQuery的on方法代理都没什么效果。只有每次生成分页的a标签后都给它们单独绑一个click事件来阻止默认操作event.preventdefault();
我们常常会遇到图片所在的域跟网页的域不一样的情况。那么使用canvas的一些方法提取编辑过的图片数据的时候就会遇到跨域的问题。比如canvas的toDataURL()方法。其他浏览器可以通过服务器配置CORS跨域加上 img.crossOrigin="anonymous"来解决问题,但IE9不行, 所以一些功能在IE9下面就需要后端来做,比如图片的旋转,在IE9下还是乖乖地传个角度给后端吧。或者在IE9下面直接舍弃部分功能。
说出来你可能不信,localStorage在IE偶尔抽风的情况下会出现,两个标签页,完全一样的网址,读出来的localStorage不一样的情况。(页面经过反复刷新,请不要怀疑我的操作。) 因为最近做的项目对缓存要求很高,对localStorage有大量的运用,然后产生了一些奇怪的bug,才发现了这个深坑。 许多多年经验的同事都表示从来没遇到过这样诡异的bug。
又要功能强,又要兼容低,前端不好当啊。
先写到这里。
我们在做很多学习或者游戏类的小程序的时候,经常会有一个场景,在正式进入学习之前,把所有需要的音频图片等资源下载好,这样在学习过程中,会有一种近乎离线学习的体验。这是学习产品中很重要的一个环节。这里总结一下,如何实现一个相对完善的资源加载环节。
我们假定会有100个左右的图片音频下载。
1.下载并发限制。如果我们一次性发100个下载请求,小程序毫无疑问会崩掉。按照官方文档小程序一次性下载的最大数量为10个。我们把下载请求统一控制,使用一个封装后的下载接口。在这个接口内部维护一个下载队列和等待队列,来保证同时在进行的请求不超过某个数量。这样只需要简单的替换接口,业务逻辑不需要做任何处理,也不需要再关心并发问题。
2.失败处理。对于100个左右的请求数量,在c端用户复杂的网络和设备条件下,某几个请求失败,是一个大概率事件。需要对这种情况有所准备,给予用户友好的提示或者退出到上一页。
3.缓存策略。如果我们下载失败了,重新进入环节,重新拉取新的数据,重新去下载这100个请求,会有很大的问题:一个是下载量没有减少,一个是下载失败的概率也没有减少,一个是用户等待的下载时间没有减少。使用缓存可以解决这几个问题,在全局的下载请求接口中,按需给所有可能的下载请求加上缓存。这样如果一个资源下载失败或者重新进入学习,重新进来下载时,之前已经下载好的文件,不用再次下载,直接拿到之前已经下载好的临时地址,可以保证是从上次下载到的地方去接着下载。 要注意的是,如果在某些业务场景下,接口每一次拿到的资源地址后面的参数不一样,但其实资源是一样的,可以以请求url问号之前的部分来当做缓存的key。这样即使后面的参数不一样,也可以被识别为同一个资源。
4.setData节流。在加入缓存之后,用户再一次进入一个环节的时候,因为所有的资源都已经下载好,导致进度条更新过快,一秒钟之内进度条可能更新上百次,不断的setData,会引起新的性能问题。所以进度条的更新需要加节流操作。
5.超时与重试。小程序的下载接口其实并不是很稳定,有可能同一个资源这一秒下载不好,隔一秒钟再去下载,它就可以顺利下载下来。在下载失败之后,隔一秒钟之后重试下载,可以很大程度上提高下载的成功率。同时要缩短一下超时时间,从后台日志记录中,分析用户的下载用时,将下载超时相对缩短一点,并且增加重试机制。可以大大的提高下载的成功率。
6.使用原始地址。使用下载好的临时地址的目的,是为了保证用户学习中的流畅性。但也不能为了流畅性而牺牲可用性。当我们多次重试依然没有下载成功的时候,可以考虑使用原始地址。对要下载的资源做分类,像某些提示音,背景图之类的资源,不是那么重要,下载不成功就使用原始地址。学习中的关键资源,则需要尽可能地保证下载好。
7.域名自动替换机制。部分网络下某个cdn域名无法访问,可增加一些自动的域名替换机制。当一个域名下载失败一定数量的次数,并且替换域名下载成功,那么后续下载优先使用备用域名来下载。
做了上面7点,资源下载这一块的用户反馈就可以降到很低。我们随机回访了一些后台监控到下载异常比较多的用户,他们在使用过程中几乎是没有感受到有下载失败。整个优化的效果很明显。
昨天上知乎一看,发现自己关注的问题接近1000个了,不能忍,希望控制在500个以以内最好是100个以内。于是打开我关注的问题列表。发现这个列表已经由滚动加载变成了分页,并且不能在问题列表页面直接点取消关注,需要进入问题详情页面去取消关注。这样一来工作量就太大了。
之前滚动加载的时候只要写个小脚本在控制台运行一下就可以把所有的问题加载出来,现在想把所有的问题加载出来就不行了。
但是作为一个前端,对页面上的东西,总是可以想想办法的。那就写个小小的chrome插件吧。
要实现的功能点:
思路:
实现的时候要注意的是什么时候去点击下一页,在什么时机触发。因为我们要确定下一页的数据加载过来了,才能进行下一次点击,不然就可能出现漏页的情况。 观察页面发现每一页的数据加载好,知乎就会把滚动条移动到顶部去。所以我们可以通过监测scroll事件来判断当前页面的数据是否已经加载完毕。监测到scroll事件的时候就是我们发起下一次点击的时候。并且当下一页加载好之后我们要再把滚动条移动到底部去。这样加载新一页的时候滚动条才会再次往上移,从而触发我们绑定的scroll事件。
另外,就是scroll事件一般会一次性触发好多个。我们要保证我们绑定的事件的逻辑代码只执行一次。所以我加了一个timeout定时器,稍微延迟一下。等滚动条停下来的时候才真正执行事件逻辑。在这个timeout运行之前的再次触发的scroll事件都会直接return掉。并且设置一个适当延迟,也减小了被误认为是爬虫的概率。
思路:
为了方便,我就直接写成chrome插件使用了。就不用每次手动到控制台去运行了。
直接拿之前写的一个chrome插件的架子过来开干。
chrome插件的入门写法以及使用我之前有篇文章写过。一个简单的chrome拓展程序开发
并且之前的chrome插件架子里集成了jQuery,代码写起来就更欢快了。
/*
* 功能说明:
* 1.把所有关注的问题列出来。
* 2.给所有的问题添加取消关注按钮并完成取消关注。
*
* author: [email protected]
* date: 20180120
*/
var ZhiHu = {
htmlArr: [], //保存每一页的问题的html数据。
pageItems: {}, //保存每一页的数量。
INTEVAL: 2000, //翻页的时间间隔。请求下一页的间隔。可以调小一些。
timer: '', //定时器
//初始化。
init: function() {
var that = this;
//绑定滚动事件。当页面滚动了就可以开始请求下一页的数据了。
$(window).on('scroll', this.scrollFn.bind(this));
//初始调用。
this.scrollFn();
//给我们添加的按钮绑定事件。
$("body").on("click", '.del-q', function(event) {
that.delQ($(this));
});
},
//取消关注。拼装url,发送delete请求。
//需要拼装的url接口格式:https://www.zhihu.com/api/v4/questions/20008370/followers
delQ: function(jqObj) {
var questionUrl, matchArr, delUrl, questionId;
//问题页面链接
questionUrl = jqObj.siblings('.QuestionItem-title').find('a').attr('href');
if (!questionUrl) {
return;
}
//正则匹配问题id
matchArr = questionUrl.match(/\d+/);
if (matchArr) {
questionId = matchArr[0];
}
delUrl = 'https://www.zhihu.com/api/v4/questions/' + questionId + '/followers';
$.ajax({
url: delUrl,
type: 'delete',
success: function(data) {
//成功的话删除该列。
jqObj.closest('.List-item').remove();
}
})
},
//页面滚动时触发的事件。
scrollFn: function(event) {
var that = this;
//滚动条滚动时会多次调用此方法,拦截掉。
if (this.timer) {
return;
}
this.timer = setTimeout(function() {
//页面内容提取
that.saveData();
//如果有下一页,模拟点击。
if ($(".PaginationButton-next").length > 0) {
$(".PaginationButton-next")[0].click();
//移动到底部。
that.scrollBottom();
} else {
//到了最后一页了。最后的数据处理。
that.mergeList();
//解绑事件
$(window).off('scroll');
}
clearTimeout(that.timer);
that.timer = '';
}, this.INTEVAL)
},
//从页面中提取问题html数据与每页的数量。
saveData: function() {
var html = $(".List-header+div").prop('outerHTML');
this.htmlArr.push(html);
//当前页面的问题数量
this.pageItems[$('.PaginationButton--current').text()] = $('.List-item').length;
},
//数据收集完成后对列表的处理。
mergeList: function() {
var html = this.htmlArr.join('');
//组装所有页的数据到一页。
$(".List-header+div").html(html);
//移除分页
$(".Pagination").remove();
//给每个问题添加取消关注按钮
$(".ContentItem-title").append('<button class="del-q" style="float:right;color:#1388ff;">取消关注</button>');
//把每页的数量打出来看一下,发现并不是每页都是20条数据。
top.console.log(this.pageItems);
},
//滚动到底部
scrollBottom: function() {
var h = $(document).height() - $(window).height();
$(document).scrollTop(h);
},
}
/* chrome插件部分。核心代码是上面的内容 */
chrome.extension.onRequest.addListener(
function(request, sender, sendResponse) {
if (request.greeting == "hello") {
//执行上面的内容
ZhiHu.init();
}
}
);
插件完成,加载到chrome浏览器,点击运行。功能正常。大功告成。
不过当所有问题都加载出来之后发现了比较奇怪的事情,就是一共加载出来911个问题。而实际上知乎显示我关注的问题有950个。所以我一度怀疑是不是哪个逻辑有错误少加载了一两页的数据。就在代码里加入了一个对象保存每一个问题页面的问题数据。
得出的结果是并不是每一页都有20个问题的。有些页面只有19个,最少的甚至只有16个。于是我点开某一页最少的,挨个数一下,发现真是只有16个。然后把这些数据加起来,确实是911个。
另外39个问题真是消失在搜索结果中了。
本代码具有时效性,仅供参考。知乎的列表的dom结构和接口都可能会修改。如果发现代码不能运行,可以酌情修改代码再运行。
效果图: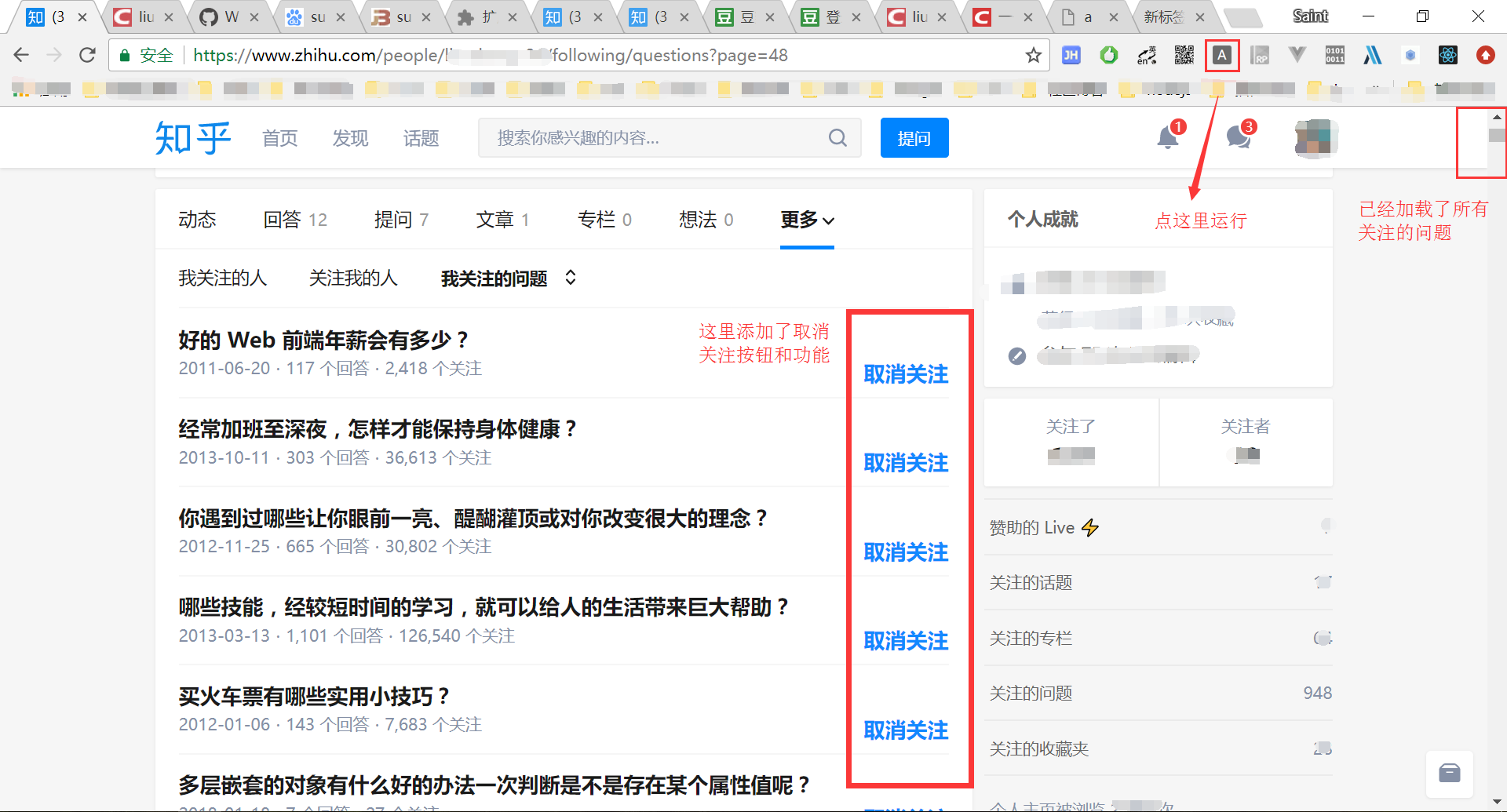
插件github地址:https://github.com/liusaint/ls-blog/tree/master/zhihu%20chorme%20plugin
文章github地址:#17
//1.字面量
var obj1 = {}
//2.构造函数
function A(){}
var obj2 = new A();//{}
//3.Object.create()
var obj3 = Object.create(obj1)
//构造函数。与普通函数的区别只是调用方式。所以一般约定首字母大写。
function A(){
this.a = 1;
this.fnA = function(){}
}
//实例。不要忘记new。
var objA= new A();//{a: 1, fnA: ƒ}
objA.__proto__ == A.prototype;//true
A.prototype.pFnA = function(){console.log(1)};
A.prototype.pA1 = 1;
objA.pFnA();//1;
objA.pA1 == 1; //true;
var objB == new A();
objB.pFnA == objA.pFnA;//true;
objB.pA1 == objA.pA1;//true;
//在构造函数原型上加一个实例属性的同名属性。
A.prototype.a = 2;
objA.a;//1;
objA;//{a: 1, fnA: ƒ}
delete objA.a;
objA;//{fnA: ƒ},实例属性中的a已删除。
objA.a;//2 来自A.prototype;
a的查找顺序顺序:实例属性(objA)=>原型(A.prototype)。一旦找到就不会继续往上找。
//对象通用方法。
objA.hasOwnProperty;//ƒ hasOwnProperty() { [native code] }
hasOwnProperty是多数对象的公有方法。它是怎么找到的呢。
objA实例属性中没有。A.prototype中没有。
查看A.prototype,发现它中间也有一个值__prototype__。是的,prototype其实也是一个普通的对象,也是某个构造函数的实例,这个值指向它的构造函数Object()的原型,Object.prototype。在Object.prototype中找到hasOwnProperty方法。即是objA._proto_.__proto__中,这样就形成了一条原型链。
终点:
objA.haha;//undefined;
haha是实例属性中没找到,原型链中也没找到,所以返回undefined。
从上面的分析我们找到了Object.prototype中。然后继续找。发现Object.prototype.proto == null;这就是原型链的终点了。
如果把构造函数看成类。根据原型链的查找原理,我们要让子构造函数的实例能调用到父类的原型中的方法和属性,要原型链查找的时候能查找到父类的prototype。子类的prototype为父类的实例或直接等于父亲的prototype。
C.prototype = new P();
function C(){
P1.apply(this);
P2.apply(this);
}
C.prototype = P.prototype
function C(a,b,c,d){
P.apply(this,arguments);
}
C.prototype = new P();
function inheirt(C,P){
var F = function(){}
F.prototype = P.prototype;
C.prototype = new F()
}
C.prototype = Object.create(P.prototype)
class C extends P {
constructor(){
super()
}
say(){
console.log('hello');
}
}
注:重写过后的prototype对象需要prototype.constructor = C;上面的代码都省略了。
属于一个分层结构的同一个分支的对象,在发送相同的消息时(也即在被告知执行同一件事时),可通过不同方式表现出该行为。
function Animal(){}
Animal.prototype.makeSound = function(){
console.log('animal makeSound');
}
function Dog(){}
Dog.prototype = new Animal();
Dog.prototype.makeSound = function(){
console.log('wangwang');
}
function Duck(){}
Duck.prototype = new Animal();
Duck.prototype.makeSound = function(){
console.log('gaga');
}
function Bird(){}
Bird.prototype = new Animal();
function makeSound(obj){
obj.makeSound && obj.makeSound();
}
makeSound(new Dog);//wangwang
makeSound(new Duck);//gaga
makeSound(new Bird);//animal makeSound。没有重写该方法,调用父类方法。
子类的原型上的定义了与父类同名的方法,根据原型链查找的原理,会直接调用子类原型中定义的方法。如果没有自定义该方法,则调用父类方法。
在某些设计模式下,如果不允许直接调用父类的该方法。可以在父类的改方法中抛出错误,而实现类似其他语言的抽象方法的功能。
把一个对象的状态和行为聚合在一起。数据和实现的隐藏。
我们发现上面无论是字面量定义的对象还是new出来的对象。它的属性都可以直接obj.a这样来读写。相当于是暴露在外的。很容易被其他程序代码修改。
JavaScript中的数据隐藏主要通过闭包来实现。我们把一些变量定义在闭包中,通过特定的函数来对其进行读写。
示例一:
function A(){
var name = 'nameA';
this.getName = function(){
return name;
}
this.setName = function(newName){
name = newName;
}
}
var a = new A();
a.name;//undefined;
a.getName();//nameA
a.setName('name2');
a.getName();//name2;
示例二.所有实例**享的私有变量:
function A(){}
A.prototype = (function(){
var name = 'name1';
return {
getName:function(){
return name;
}
}
})();
var a1 = new A;
var a2 = new A;
a1.getName();//name1;
a2.getName();//name1
示例三.一个简单的模块:
var module = (function() {
//私有变量
var privateA = '1';
var privateB = '2';
//私有方法。
function A(a) {return privateA+1}
function B() {}
function C() {}
//公有API。可选择暴露一些接口出去。
return {
A: A,
B: B
}
})();
另外,对于暴露出去的数据,如果是引用类型。可能出现私有性失效的问题。可通过克隆以及最低授权原则来处理。
function A(){
var arr = [1,2,3];
this.getArr = function(){
return arr;
}
}
var a = new A();
var arr = a.getArr();//[1,2,3];
arr.push(4);
a.getArr();//[1,2,3,4],私有变量被修改了。
近来已经很难遇到让人打起精神来对付的bug了。
这是一个弹窗上的操作,这个项目使用了bootstrap中的modal插件。在IE9下面发现有参数没有提交过去。但是在chrome上提交的参数是正常的。
调试发现运行到正式提交的那个方法,有一个判断,if($('.input_part.sign_change:visible').length>0),在IE9下,这个值是false,也就是找不到该元素。这个元素是弹窗上的一个元素,此时的情况是这个元素我明明还能看见它,但是代码却找不到它了。
难道是IE浏览器的bug?难道我眼睛看到的并不一定是真的?
于是更大范围的调试,发现在某一个方法中,执行了$.closeModal(),关闭了弹窗,这显然是一个逻辑错误,此时并不应当关闭弹窗,我们只要加入一些判断,让这个$.closeModal()在当前情况下不执行,IE下功能就正常了,代码的逻辑也正常了,到此,bug解决。但是我们遇到bug不仅仅是解决bug就够了,能从bug中有所收获当然更好。
分析原因:弹窗已关闭并删除,于是在dom树上这个弹窗已经找不到了,但是界面还没有重新绘制。所以我们眼睛看到的弹窗其实已经不存在,这是浏览器渲染机制的问题。
观察到弹窗消失的时间是发送ajax请求,让出线程的时候。
于是IE下的这个奇怪的问题似乎有了可靠的解释,那么问题到这里就结束了吗?不,并没有,因为更诡异的是这样的逻辑有问题的代码在chrome上居然按代码编写者所预期地进行了!
代码还原到错误逻辑,转战chrome。
执行$.closeModal(),弹窗正常消失(IE下不消失),$('.input_part.sign_change:visible')元素依然能找到!!
这就是之前错误代码能正常运行的原因:界面重新绘制了,dom树没有更新?
然后发送ajax请求,让出线程。再运行$('.input_part.sign_change'),发现已经找不到元素,dom树已更新。
看起来似乎这个解释也很圆满。但是这跟我一贯的认知并不太符合,如果我们的代码操纵了dom树,但是dom树没有更新,那么我们后面的代码还有什么可以相信的?
于是将场景抽离,把弹窗相关组件抽出,情景模拟简化,发现chrome下的分析果然有问题。
测试发现这个closeModal()方法在弹窗加入了动画效果fade的时候是并不完全是一个同步的操作。所以在动画效果结束之后才会真正设置弹窗display:none并删除dom,在此之前只会把组件的opacity属性由1变成0,也就是肉眼不可见,其实元素还存在,并且jQuery的$(':visible')依然可以找到它,所以我们后面的代码执行才没有问题。让组件display:none并删除dom的操作则是一个异步操作,在主线程让出循环之后它才会执行。
而在IE下。测试发现过程弹窗显示与关闭是同步操作。到bootstrap的modal插件源码调试了一下发现IE9中确实是同步操作。IE9中的情况我们上面分析是正常的。dom元素已删除,界面未有即时更新。$(':visible')以及原生document.querySelector都无法找到元素了。
到此,一个逻辑错误的代码,在IE下不能正常运行和chrome下能“正常”运行的原因我们都找了出来。
注:之所以会删除dom。是我们额外添加了hidden.bs.modal事件。会在弹窗完全消失之后删除dom。
前端开发,有一项很重要的基本功,就是在大型项目中,比如几万行js代码中,迅速找到新增功能或调试bug的切入点。特别是你只是接手这个项目,并不了解其中每一个功能点所在的位置,也没有时间一行行读代码的情况,这个基本功显得尤其重要。
这项能力除了娴熟的调试工具使用技巧,更重要的还是对变化的观察力和总结归纳的能力。本文用一个讲一个功能案例的实现。
一款大型canvas应用。我们使用了一些开源库实现canvas上的文字与html文字的互转。使我们可以在一个输入框中输入文字然后绘制到canvas上去。也可以点击canvas上的文字然后通过开源库进行文字编辑。
我们的canvas应用有整体放大缩小的功能。但是文本输入与我们的canvas应用是两个不同的体系,现在我们要对这个文本输入相关的库进行对应的放大缩小的调整。在canvas应用处于放大缩小的场景,text输入框对应放大缩小。并且在放大缩小的场景下对输入框中的字体的放大缩小,在回归到正常大小的时候。显示与100%时设置的字体大小相同。
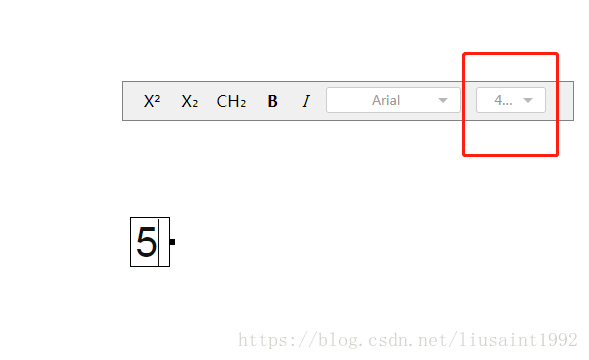
目前的情况是应用处于放大状态时,输入内容以及转化到canvas上的大小依然是画布100%时的大小。然后当画布变回正常大小,之前绘制到canvas上的的文本就小的没法看了。
canvas应用放到大300%时文本组件的情况:
canvas应用放到大300%时绘制到canvas上的文本:
canvas应用回到正常100%时绘制到canvas上的文本情况:
首先观察输入框的大小什么决定。要先观察输入框的组成结构。查看elements,发现它是dom结构,没有在iframe中,也不是canvas绘制,先松一口气,看来仅仅是dom上的变换。
然后我们在输入框中输入,同时观察右边dom结构有什么变化。发现输入到第二个字符的时候多了一个带内联属性的font-size的span,我们输入的内定到这个span标签中。
然后通过输入组件的工具栏把输入的字体调整到其他字号。发现内联的font-size有变化。字体变大。输入框变大。
猜测输入框大小跟这个字号有关系。
在不同的缩放比例下,按照我们的缩放比例乘以100%状态下的的字体大小。就是在该比例下的大小了。
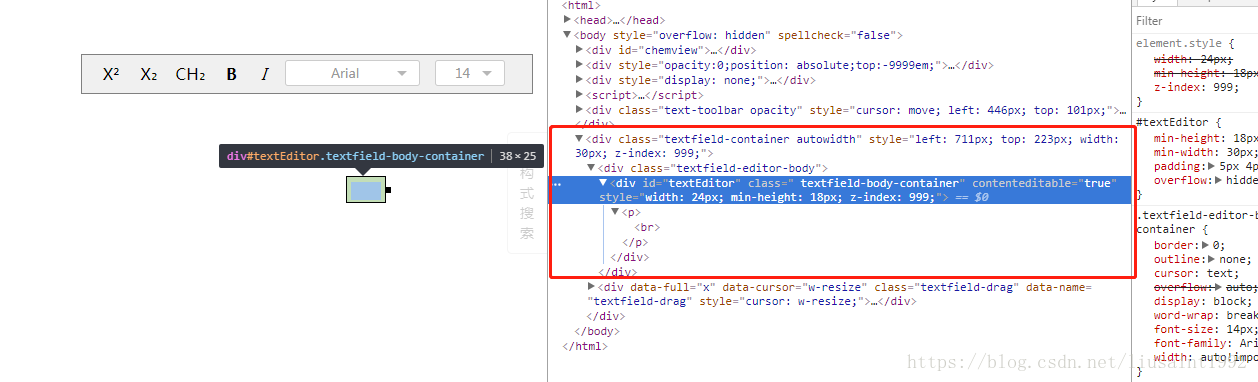
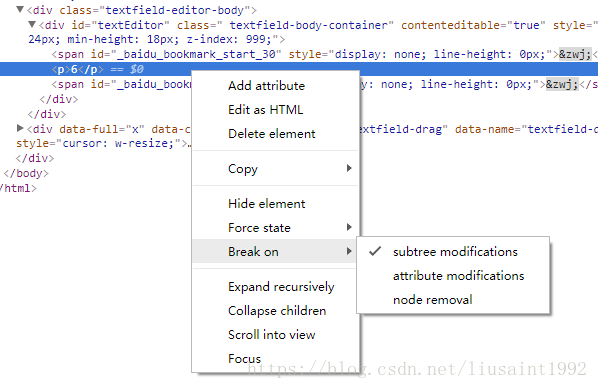
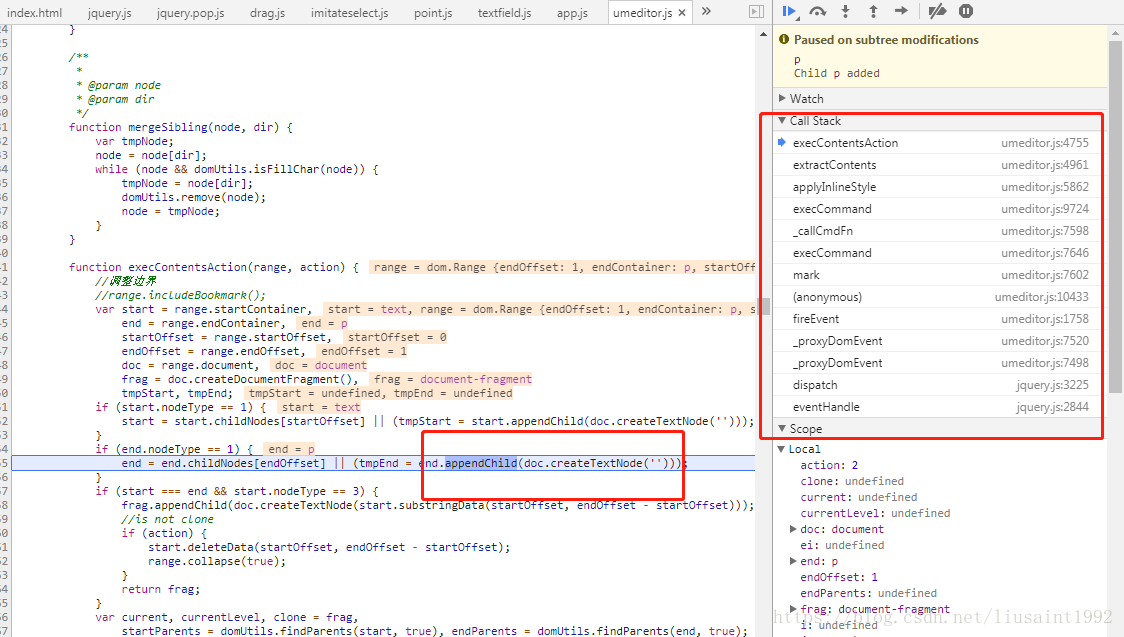
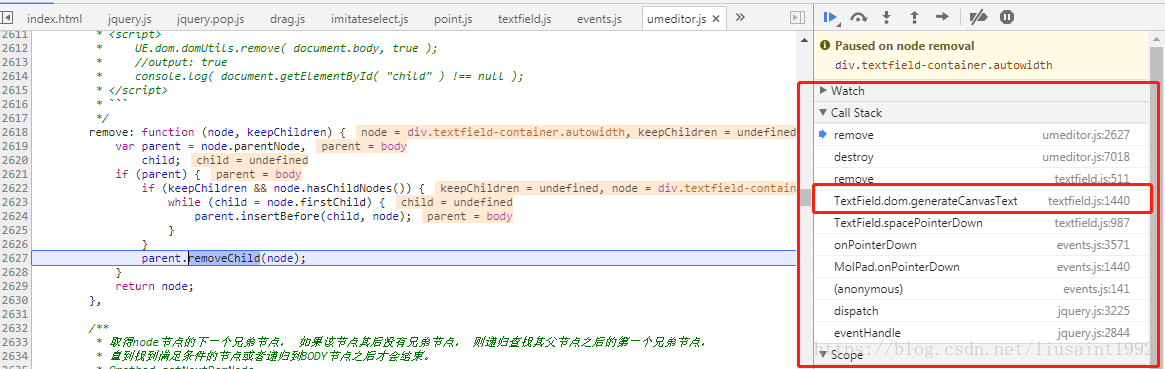
首先看span是怎么加入进去的,监听p的子节点变化。加一个dom断点。
监听到了appendChild。然后查看调用栈。
定位到这个位置,看到是在这里给span设置了14px的默认大小,修改它:
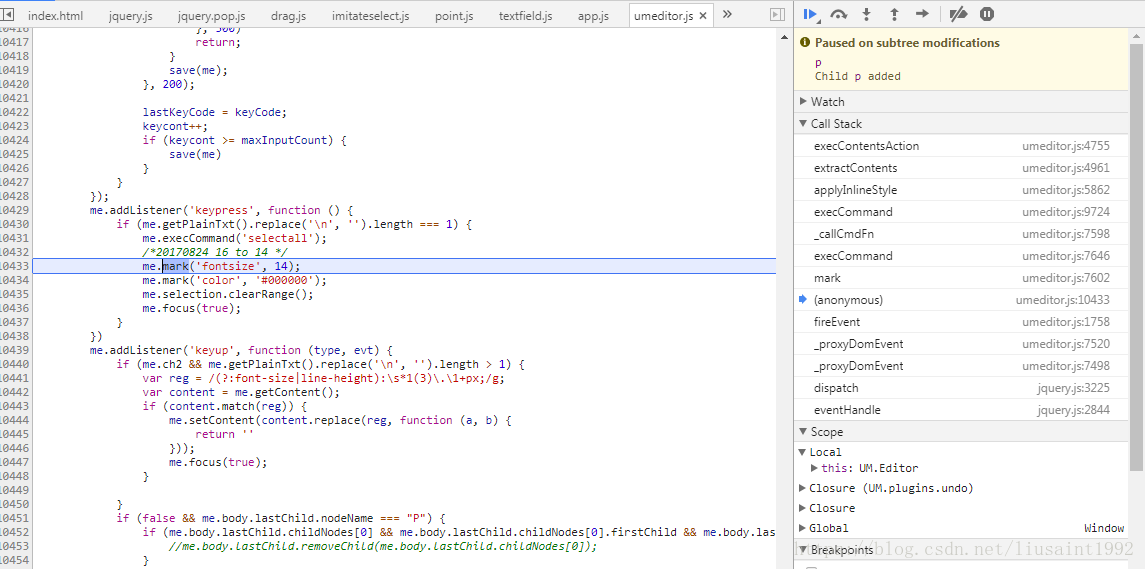
var scaleValue = $("#zoomIn-container").attr('data-float')||1;
me.mark('fontsize', 14*scaleValue);
刷新,发现打开输入框,输入框大小跟之前一样,输入第一个字时还跟之前一样,输入第二个字母,span出来之后,字体和输入框就变成当前比例下我们想要的大小了。
另外,发现那句代码有一句注释 16 to 14。
猜测之前有一次默认字体大小从16到14的整体改动。如果我们全局搜索一下16 to 14这个改动,也许会有意想不到的发现。
那么第一个字母的大小由什么决定?用chrome一看,由css决定。父元素的font-size决定。所以现在我们父元素的css要动态修改。在初始化输入框的时候就要设置好内联的css。如何知道在哪里初始化的文本dom,哪里改?
观察,发现输入框消失之后,整个输入框相关的节点都消失了。猜测整个输入相关的节点由js动态生成。于是全局搜索class名。
果然搜到,然后在dom初始化之后的代码中加入以下代码,设置字体大小。
// ls20180523 把传入的字体大小。根据当前比例做一个缩放。
var scaleValue = $("#zoomIn-container").attr('data-float') || 1;
$container.find(id).css('font-size',14*scaleValue);
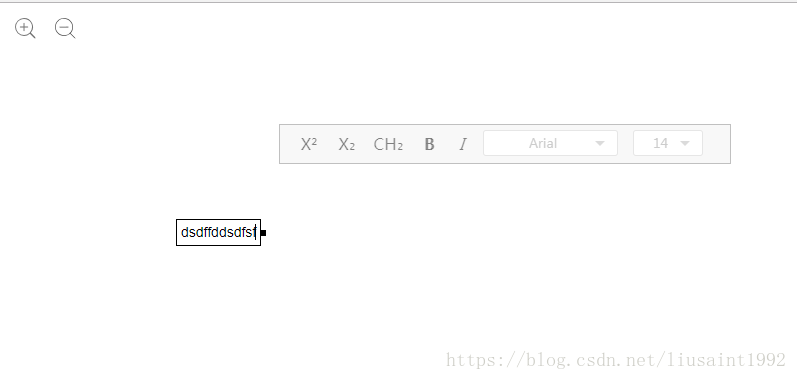
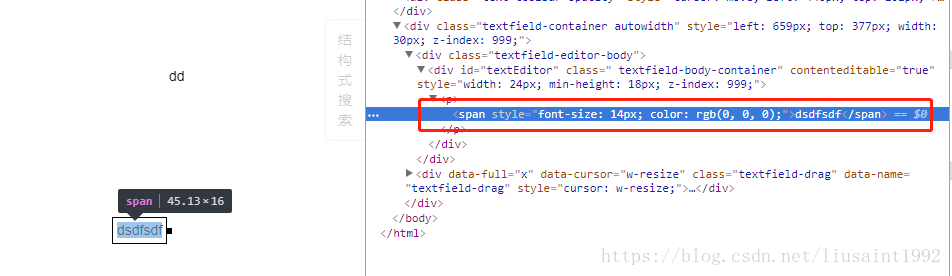
刷新。初始框变大。第一个字母变大。继续输入字体依然变大。
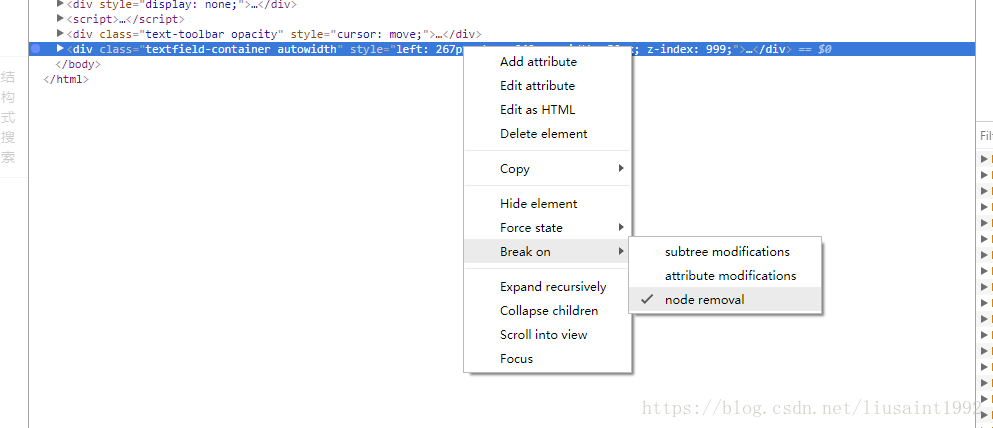
然而输入第一个字母,点出去,发现绘制到canvas上的依然是100%状态下的14px。而输入多个字符的时候,字体是该比例下的大小。因为上面的观察我们知道只有一个字母的时候是没有span生成的,所以可能对产生的canvas字体有影响。 那么我们txt转canvas的函数可能也需要修改。
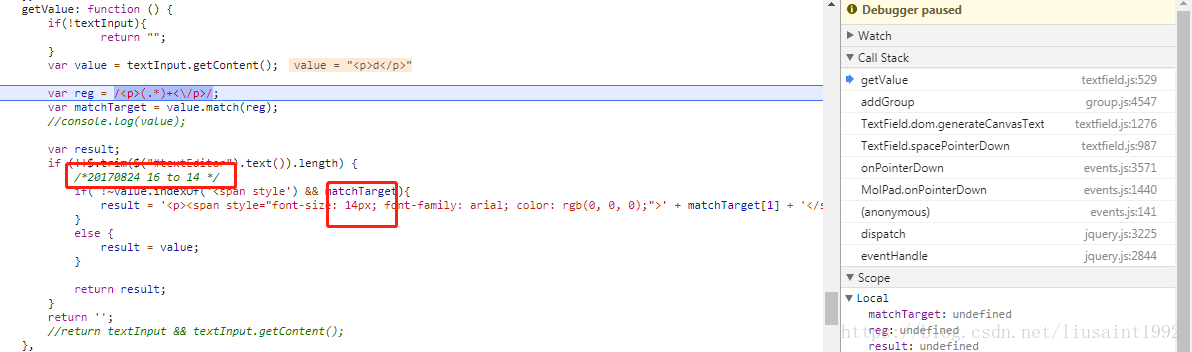
这个函数在哪里?是不是有这样一个函数?有什么办法知道?由前面的观察我们发现点出去的时候文本组件相关dom是会消失的。于是,断点它。
在调用栈里发现这样一个函数。果断进去看一看。
然后在这个函数里设置断点。重新操作,在里面一步步走一下。
很容易地,我们找到这个函数,并最终定位到这行代码。修改之。
//ls20180524 根据缩放比例调整。
var scaleValue = $("#zoomIn-container").attr('data-float')||1;
result = '<p><span style="font-size: ' + 14 * scaleValue + 'px; font-family: arial; color: rgb(0, 0, 0);">' + matchTarget[1] + '</span></p>';
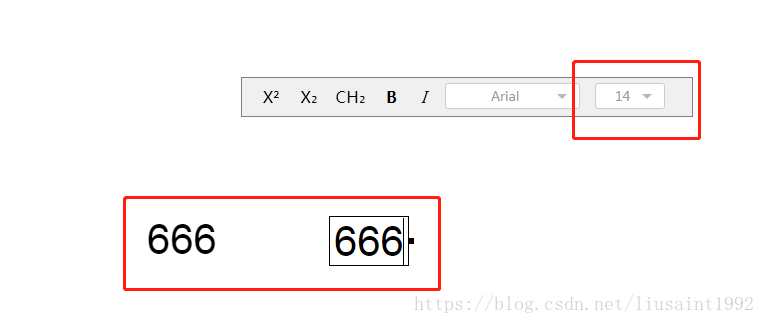
再测试。发现只输入一个字。到canvas上大小正确。
然而出现了新的问题。如图。这个字号设置的地方。显示变成了我们实际的大小值。实际应该显示的是我们dom上设置的大小值除以当前页面比例的值,才是我们100%比例时候的值。我们要找到它在哪里修改的。观察这个节点是何时从14变成这个值的。然后设置断点观察节点变动。到这个赋值的地方给值进行一个换算就可以了。
然后剩下最后一个功能。修改字号。修改字号后我们框里的字体大小应该是缩放后的比例下的这个字号的大小。只要监测相关节点的变动,然后切换一下字号,就可以找到设置span大小的节点。都很好修改了。
到这里这个功能就基本完成,哪怕是一个刚接手的项目,整个功能修改过程也不超过2小时。当然,后续还有问题要考虑,比如高分屏设备像素比的问题。
修改后,canvas应用放大300%时的字体组件:
到这我们就基本实现了我们的功能,代码量很小。要注意修改其他人代码的时候,要考虑修改的地方的方法的作用,使用范围等。尽量保证自已写的东西不会影响到其他可能的逻辑,要从代码编写者的角度进行多方面的思考。对于第三方库的使用,我们首先要考虑库原有接口的组合使用,在原有接口不足的情况下才考虑修改源码。
通过观察分析和断点技巧,我们很容易地就从一个大型项目几万行代码中迅速定位到我们要修改的地方。
最近在给项目中的富文本编辑器进行更换。由tinymce改成kindeditor。
之前tinymce是由离职同事引入的。并且对其源码进行了一些修改。增加了一些自定义的功能。这几天给它切换成kindeditor编辑器,并且要将我们自定义的功能也迁进来。
富文本编辑器的内容区一般是iframe中。我要在iframe中引入js代码。
有一些常用的功能需要用到$以及KindEditor中的接口,在iframe中重新引入一个jQuery或KindEditor文件显然是不划算的。那么直接取得两个iframe之外的现成的对象又如何?
直接引入
var $ = parent.$;
var KindEditor = parent.KindEditor;这样的话,我们就可以使用对象的大部分接口方法了。
需要注意的是,由于我们的js的初始化环境是在parent环境,这些接口方法也是在这个环境里生成的,那么由于作用域原理,在库中使用到的document\window等宿主对象也是指向的parent中的对象而不是当前iframe中的对应对象。
所以有些接口不能那么放心地使用。
举个例子:
比如iframe中有一个
<span class="a"></span>在iframe中输入使用$('.a')是找不到它的。它实际上是在父窗口里面在找。
但是我们可以使用find方法。它是一个相对安全的方法。
var body = document.getElementsByTagName('body')[0];
$(body).find('.a');//注意这里的body没有引号简单讲,如果你发现你在iframe中引入的parent窗口的对象的某些方法没有正常运行,你可能要考虑它的一些作用域引起的问题。
不过其实大多数方法是安全而有效的。比如addClass()、offset()等。
如果方法不是那么有效,那么也是一定有替代方法的。
准备总结一篇填坑经验的文章。先列一下提纲吧。有时间再完整写。
1.断点。debugger。console。的高效使用。
2.如何查看请求从哪里发起,要做什么?
3.如何快速找到一块功能的js实现在哪里?
4.如何监测任意一个变量是在哪里发生的变化?变量的作用域、私有化、及统一管理。
5.如何在不打开控制台的情况下知道报错情况?非常规情况下的js调试。
6.如何提问,如何搜索?提问越精准,你离答案越近。
7.如何排除影响的元素?排除法。
8.如何抽离场景分析?场景抽离得越纯粹,效率越高。
9.引用插件的时候对接口的补充与分析。对于接口文档不完善的引用库,如何放心地使用。
10.修改代码的时候如何减少对原有逻辑的影响。以及如何加强自己代码的健壮性,避免被他人影响。
11.异步代码调试。
12.大量代码整理优化。从模仿到优化。
13.http。谁的锅?
14.性能优化。
15.API。你真的读了吗?接口猜测与快速开搞。
16.挥一挥衣袖,不带走一片云彩。状态改变你收拾残局了吗?
17.必须会的总结与归纳?
18.条条大路通罗马。换思路。
最近使用一个兼容IE的plceholder组件jQuery Placeholder Plugin。
使用过程中发现它是给元素设置假值和特殊class来实现的。本来以为用这个插件需要在所有的表单提交的时候加一层单独处理的逻辑。结果一试。 document.querySelector('input1').value; //"请输入"
$('input1').val(); //''。感觉挺神奇的,它怎么就改变了val()方法的返回呢。是重写了val方法吗还是其他的什么黑科技?于是就去看了下源码。
组件地址
requestAnimationFrame的用法就不说了。
requestAnimationFrame方法告诉浏览器您希望执行动画并请求浏览器在下一次重绘之前调用指定的函数来更新动画。该方法使用一个回调函数作为参数,这个回调函数会在浏览器重绘之前调用。
这里主要说一点。 在断点单步调试canvas应用的时候,发现并没有一步一步的效果,而是执行完代码之后才有一次性的canvas更新。后来发现原因是这个绘制的函数是放在requestAnimationFrame的回调中。
试了一下,除了canvas动画。其他的对dom的样式改变,都不会立刻生效。
推论:因为这个函数的回调是在重绘之前调用,在这个函数的回调中不会进行页面的重绘。
如果要调试回调中的页面更新,比如canvas变化,dom的样式变化,需要直接调用回调才能看到单步的效果。因为requestAnimationFrame是异步的,要模仿的话可以把回调放一些异步接口的回调中。
update 20180314
发现在chrome下mousemove事件的回调以及canvas的单步效果也是看不到效果的。应该是也是合并渲染了。不过360和火狐是能看到单步效果的。
在火狐下requestAnimationFrame中的内容也能看到单步效果。
录音与翻页功能
http://fdfs.xmcdn.com/group87/M07/66/12/wKg5J19ePhXhM74GADHorDmIZCA731.mp4
字母书写教学功能
http://fdfs.xmcdn.com/group83/M00/67/83/wKg5I19ePbTh2G4NAEJmb4OpJwE631.mp4
小车掉落题
http://fdfs.xmcdn.com/group82/M02/64/8D/wKg5HF9ePLbxZ9aZAHalInzHyO8099.mp4
拼读题
http://fdfs.xmcdn.com/group85/M04/66/6D/wKg5H19ePYryq7B8AEZ6kna_wgE570.mp4
文本排序题目
http://fdfs.xmcdn.com/group83/M02/67/41/wKg5HV9ePQKB0YPOADnExHzzz6E595.mp4
阅读拖拽题目
http://fdfs.xmcdn.com/group82/M05/64/97/wKg5HF9ePjvToJMRAEX0mn3hALQ090.mp4
浴室泡泡题
http://fdfs.xmcdn.com/group86/M09/68/31/wKg5IF9ePSyiaCbiAEt2gKIAc0E920.mp4
螃蟹拖拽题
http://fdfs.xmcdn.com/group84/M0B/67/2A/wKg5JF9ePUfDlA8-AE62Du_TqBM845.mp4
翻牌题
http://fdfs.xmcdn.com/group87/M07/66/0E/wKg5J19ePevxfMsYAEf_9GTcPbU875.mp4
听音选餐盘题
http://fdfs.xmcdn.com/group84/M09/67/4E/wKg5Hl9ePW3TC33kADCL2AKa5eE280.mp4
ant-design-pro使用了umi.js,没有直接使用webpack,我们要配置自定义的构建打包跟直接的webpack配置不太一样。
首先,大部分的webpack打包配置都可以直接修改config/config.js来实现,比如 proxy,publicPath等。参考umi.js配置文档。https://umijs.org/zh/config/#%E5%9F%BA%E6%9C%AC%E9%85%8D%E7%BD%AE。
这里记录一些针对性的配置。
我们的编译生成的index.html文件交给了后端,index.html上引用的umi.js,umi.css的版本号给后端控制,其他静态资源文件如js,css,图片则放到cdn服务器上,所以其他文件则通过hash文件名来控制版本号。umi默认配置hash要么是true要么是false,不能满足我们的需求。
怎么办?观察发现打包构建生成的文件名是4.64e1afbe.chunk.css,4.6cf0f5d2.async.js这种格式,在node_modules中搜索.async.js,发现相关配置在node_modules/af-webpack下,代码如下:
if (opts.hash) {
webpackConfig.output.filename(`[name].[chunkhash:8].js`).chunkFilename(`[name].[chunkhash:8].async.js`);
}
const hash = !isDev && opts.hash ? '.[contenthash:8]' : '';
webpackConfig.plugin('extract-css').use(require('mini-css-extract-plugin'), [{
filename: `[name]${hash}.css`,
chunkFilename: `[name]${hash}.chunk.css`
}]);
手动修改对应内容,发现配置生效。但是我们不能直接个性它,而是要用外部配置来覆盖它。
config/config.js 中有一个属性 chainWebpack,使用了webpack-chain,详细配置在config/plugin.config.js。
webpack-chain 配置文档: https://github.com/neutrinojs/webpack-chain/tree/v4
于是我们在config/plugin.config.js中添加代码:
//css的修改
config.plugin('extract-css').use(require('mini-css-extract-plugin'), [
{
filename: `[name].css`,
chunkFilename: `[name].[contenthash:8].chunk.css`,
},
]);
//js的修改
config.output.filename('[name].js');
编译,成功。
实际开发中,不是所有的依赖都会放到 node_modules中,特别是一些我们自定义修改过的依赖,在 src/lib文件夹下放置这些特殊的依赖组件。组件放在这个文件夹下的表现并不跟放到node_modules中一样,很多的原生构建打包配置都对node_modules作了排除处理,主要是css modules和babel编译的时候,src/lib文件夹也需要做对应处理。
ant-design-pro默认开启了css modules。
如果css modules作用范围不排除src/lib文件夹,会导致引入组件的样式错乱。
查看config/config.js发现cssLoaderOptions中有个getLocalIdent方法,用来生成css modules最终的class名。有下面几行代码:
if (
context.resourcePath.includes('node_modules') ||
context.resourcePath.includes('ant.design.pro.less') ||
context.resourcePath.includes('global.less')
) {
return localName;
}
可以看出,node_modules,ant.design.pro.less,global.less 这几种文件下 css modules 使用原始的css class名称,相当于是把这些文件排除在css modules作用范围之外了。于是我们要排除src/lib文件夹,只需要在这个函数中加一行:
if (
context.resourcePath.includes('node_modules') ||
context.resourcePath.includes('ant.design.pro.less') ||
context.resourcePath.includes('global.less')||
context.resourcePath.includes('/src/lib/')
) {
return localName;
}
引用src/lib下部分es5写的组件的时候,发现运行报错:
TypeError: 'caller', 'callee', and 'arguments' properties may not be accessed on strict mode functions or the arguments objects for calls to them
因为babel转译的时候貌似默认都转成严格模式了。本来只需要exclude一下这些组件的,但是umi的配置里并没有找到相关的项。同样,我们在node_modules/af-webpack下搜索babel相关配置。搜到如下代码:
webpackConfig.module
.rule('js')
.test(/\.js$/)
.include.add(opts.cwd)
.end()
.exclude.add(/node_modules/)
.end()
.use('babel-loader')
.loader(require.resolve('babel-loader'))
.options(babelOpts); // module -> jsx
对应的,我们在config/plugin.config.js中添加下面的代码:
config.module
.rule('js')
.exclude.add(/\/src\/lib\/webuploader/)
.end();
搞定。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.