liuhanqu / blog Goto Github PK
View Code? Open in Web Editor NEWrecord something
record something
















众所周知,JavaScript 是单线程的,而 Nodejs 又可以实现无阻塞的 I/O 操作,就是因为 Event Loop 的存在。
Event Loop 主要有以下几个阶段,一个矩形代表着一个阶段,如下所示:
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
每个阶段都会维护一个先进先出的队列结构,当事件循环进入某个阶段时,就会执行该阶段的一些特定操作,然后依序执行队列中的回调函数。 当队列中的回调函数都执行完毕或者已执行的回调函数的个数达到某个最大值,就会进入下一个阶段。
事件循环的开始阶段,执行 setTimeout 和 setInterval 的回调函数。
当定时器规定的时间到了之后,就会将定时器的回调函数放入队列中,然后依序执行。
假如你有 a、b、c 四个定时器,时间间隔分别为 10ms 、20ms 、 30ms。当进入事件循环的 timer 阶段时,时间过去了 25 ms,那么定时器 a 和 b 的回调就会被执行,执行完毕后就进入下一个阶段。
执行除了 setTimeout 、 setInterval 、 setImmediate 和 close callbacks 等的回调函数。
进行一些内部操作。
这应该是事件循环中最重要的一个阶段了。
如果这个阶段的队列不为空,那么队列中的回调会被顺序执行;如果队列为空,也有 setImmediate 函数被调用,那么就会进入 check 阶段。如果队列为空且没有 setImmediate 的函数调用,事件循环会进行等待,一旦有回调函数被添加到队列中时,立即执行。
setImmediate 的回调会在这个阶段被执行。
例如 socket.on('close', ...) 等的回调在这个阶段执行。
// timeout_vs_immediate_1.js
setTimeout(function timeout() {
console.log('timeout');
}, 0);
setImmediate(function immediate() {
console.log('immediate');
});按照之前的说法,事件循环会先进入 timer 阶段,执行 setTimeout 的回调,等到进入 check 阶段时, setImmediate 的回调才会被执行。所以有一些人认为上面的代码的输出结果应该是:
$ node timeout_vs_immediate_1.js
timeout
immediate
但其实这里的结果是不确定的。这里往往跟进程的性能有关系,而且,这里 setTimeout 的间隔虽然是 0,实际上会是 1。所以当启动程序进入事件循环,时间还未过去 1ms 时,timer 阶段的队列是空的,不会有回调被执行。而这里又有 setImmediate 函数的调用,所以之后走到 check 阶段时,setImmediate 的回调会被调用。如果事件循环进入 timer 阶段时,已经消耗了 1ms ,那么这个时候 setTimeout 的回调就会被执行,之前进入到 check 阶段,再执行 setImmediate 的回调。
所以,以下的两种输出都可能出现。
$ node timeout_vs_immediate_1.js
timeout
immediate
$ node timeout_vs_immediate_1.js
immediate
timeout假如,上面的代码是放在一个 I/0 循环内,如
// timeout_vs_immediate_2.js
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});那么结果就是确定的,输出结果如下
$ node timeout_vs_immediate_2.js
immediate
timeoutprocess.nextTick() 并不属于事件循环中的一部分,但也是异步的 API 。
当前的操作完成了之后,如果有 process.nextTick() 的调用,那么 process.nextTick() 中的回调会接着被执行,如果回调里面又有 process.nextTick() ,那么回调中的 process.nextTick() 的回调也会接着被执行。所以 procee.nextTick() 可能会阻塞事件循环进入下一个阶段。
// process_nexttick_1.js
let i = 0;
function foo() {
i += 1;
if (i > 3) return;
console.log('foo func');
setTimeout(() => {
console.log('timeout');
}, 0);
process.nextTick(foo);
}
setTimeout(foo, 5);按照之前的说法,上面的输出结果如下:
$ node process_nexttick_1.js
foo func
foo func
foo func
timeout
timeout
timeout你可能会有一个疑问,process.nextTick() 是在事件循环某个阶段的队列都清空之后再执行,还是在队列中某个回调执行完成后接着执行。想想下面的代码的输出结果是什么?
// process_nexttick_2.js
let i = 0;
function foo() {
i += 1;
if (i > 2) return;
console.log('foo func');
setTimeout(() => {
console.log('timeout');
}, 0);
process.nextTick(foo);
}
setTimeout(foo, 2);
setTimeout(() => {
console.log('another timeout');
}, 2);执行一下,看看结果
// node version: v11.12.0
$ node process_nexttick_2.js
foo func
foo func
another timeout
timeout
timeout结果如上所示,process.nextTick() 是在队列中的某个回调完成后就接着执行的。
你看到上面的结果,有个注释 node version: v11.12.0 。 即运行这段代码的 node 版本为 11.12.0 ,如果你的 node 版本是低于这个的,如 7.10.1 ,可能就会得到不同的结果。
// node version: v7.10.0
$ node process_nexttick_2.js
foo func
another timeout
foo func
timeout
timeout不同的版本表现不同,我想应该是新的版本做了更新调整。
process.nextTick() 对应的是 nextTickQueue,Promise 对应的是 microTaskQueue 。
这两者都不属于事件循环的某个部分,但它们执行的时机都是在当前的某个操作之后,那这两者的执行先后呢
// process_nexttick_vs_promise.js
let i = 0;
function foo() {
i += 1;
if (i > 2) return;
console.log('foo func');
setTimeout(() => {
console.log('timeout');
}, 0);
Promise.resolve().then(foo);
}
setTimeout(foo, 0);
Promise.resolve().then(() => {
console.log('promise');
});
process.nextTick(() => {
console.log('nexttick');
});运行代码,结果如下:
$ node process_nexttick_vs_promise.js
nexttick
promise
foo func
foo func
timeout
timeout如果你都搞懂了上面的输出结果是为何,那么对于 Nodejs 中的事件循环你也就可以掌握了。
前段时间看到了张云龙的文章 一个程序员的成长之路 - 剖析别人,总结自己,里面有这么一段话
栈外技术,是指栈内技术的上下游,领域外的相关专业知识,包括但不限于服务端技术、运维、CDN、测试,甚至 UI 设计、产品设计等等,扩展你栈内技术的周围领域,充分理解你的工作在整个技术研发体系中处于怎样的环节。工作之余多投入一份精力,把其他栈外技术不断纳入到你的知识体系中来,建立栈外能力。前端想要做的深入,往往会涉及到缓存、模板渲染、用户体验等知识,没有相当的栈外技术积累,你很难为自己的团队争取到足够的话语权。
想想自己在公司的时候,基本都是写业务,做前端相关的工作,但对于其他方面是涉猎比较少,或者基本没有的。又再想想之前面试的时候,面试官也会问一些栈外问题,比如说你们公司的代码是如何发布部署的,这时候的我是一脸懵逼的。这就使得我想要懂得如何部署代码,以下是折腾的过程,记录一下。
云服务器的购买,可以选择阿里云和腾讯云,我之前并没有仔细地去比价两者的价格如何,想着就是用来玩玩如何部署的,也就没有多在意这些,毕竟也不是长期购买,花不了几个钱,就选了腾讯云。至于选购什么配置的服务器,就看个人了。买完之后,还要做一些认证等,需要等待一两天的时间。对了,我还买了一个域名,但是后来发现备案的手续挺麻烦的,想着之后用 ip 地址也可以访问,就没有去管了。
有了服务器后,你需要登录。那要怎么登录呢,这里介绍一个简单的方法。
首先,你需要确认自己是否已经拥有秘钥。默认情况下,用户的 SSH 秘钥存储在~/.ssh 目录下。进入该目录并列出其中内容,便可以快速确认自己是否已拥有秘钥:
# 本地
$ cd ~/.ssh
$ ls
config id_rsa id_rsa.pub known_hosts我们需要寻找一对以 id_dsa 或 id_rsa 命名的文件,其中一个带有 .pub 扩展名。.pub 文件是你的公钥,另 一个则是私钥。如果找不到这样的文件或者根本没有 .ssh 目录, 你可以通过运行 ssh-keygen 程序来创建它们。
# 本地
$ ssh-keygen
Generating public/private rsa key pair.
# 输入 enter 键
Enter file in which to save the key (/Users/laohan/.ssh/id_rsa):
Created directory '/Users/laohan/.ssh'.
# 两次输入密码
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /Users/laohan/.ssh/id_rsa.
Your public key has been saved in /Users/laohan/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:XhI9aeGsVJklGyUTvNu+6ABzOZdZL2+y5aMOVQa+ZvI laohan@bogon
The key's randomart image is:
+---[RSA 2048]----+
| .O*+ |
| =+X . |
| o O.o o |
| . =.= = |
| o S *o* . |
| = =.*.o |
| o ..E + |
| . o.*. |
| .o.=o.. |
+----[SHA256]-----+首先 ssh-keygen 会确认密钥的存储位置(默认是 .ssh/id_rsa),然后它会让你重复一个密码两次,如果不想在使用公钥的时候输入密码,可以留空。
公钥看起来是这样的:
$ cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDc4xbJxlMTgiE13I1RL6IsG44+3CQc8Ft03eZnYfNrPVeQIf9r9kTuArSiUnY+BHXn3mrQ5i+5AGi+alys94Pum2dZ68QtlY1QdEl4iN3LFXUkbJc+M0rllaDGH5JNtfk5imVqDo8Tn7aJsFd4IXbwrl3Euf+ccOb+s92RHwzbSRx37tP9pLF9ujfL0UXfg3+DmRJMJT7iN3OiJxfuF5k8KSySEz+YbhQoNeySuvVPeRHG/U6xOGcpzNjQIPApGsuFdLT5R/5x15W7SrC//XWuIQMmlVTW2X0YH+5NjT0nlLVWxS4drtRCS66JXtRceVqs5H5InbsLfALfTPyIkZ4t laohan@bogon具体可以参考这里 Generating a new SSH key and adding it to the ssh-agent
$ cd
$ mkdir .ssh && chmod 700 .ssh
$ touch .ssh/authorized_keys && chmod 600 .ssh/authorized_keys接下来,把开发者的 SSH 公钥添加到这个用户的 authorized_keys 文件中。
$ vim .ssh/authorized_keys
# 把之前生成是 SSH 公钥添加到文件尾部现在已经可以通过 ssh 无密码的方式登录云服务器了
ssh root@IP
# IP 为 云服务器的 IP 地址如上,是不是感觉很方便。可是这种方式,你还是需要知道云服务器的 ip 地址,那有没有更省脑的方式呢?
有的,在~/.ssh 下的 config 文件中添加以下代码即可
Host hostname # hostname 为你想要设置的别名
HostName IP # IP 为云服务器的 IP 地址
User root
IdentitiesOnly yes之后,就可以通过如下的方式登录到云服务器了
ssh hostname # hostname 为你刚才设置的名称个人理解,云服务器也就是一台机器,你的代码在自己的电脑怎么跑,到了云服务器还是怎么跑,只是运行的环境不一样了,需要做一些配置。
现在,我们已经有了云服务器了,接下来就是如何把我们能在本地跑起来的代码部署在服务器上。
我采用的方式比较简单,就是直接在把我本地的代码 push 到 github 上面,然后在服务器那里用 git clone,把代码下载到本地。github 地址 koa-demo。又或者你可以把代码在本地打包后,利用 scp 远程复制。
nginx,是运维同学经常打交道的。你可能听过反向代理、负载均衡等名词,这都是跟 nginx 有关的。
我的服务器是 centos 系统的,所以安装的方式如下
yum install -y nginx至于其他系统的安装方式,自行查找了。
对于 nginx 来说,主要就是 nginx.cof 这份配置文件,位于/etc/nginx 路径下,下面就进行修改
cd /etc/nginx
vi nginx.conf修改后的内容如下
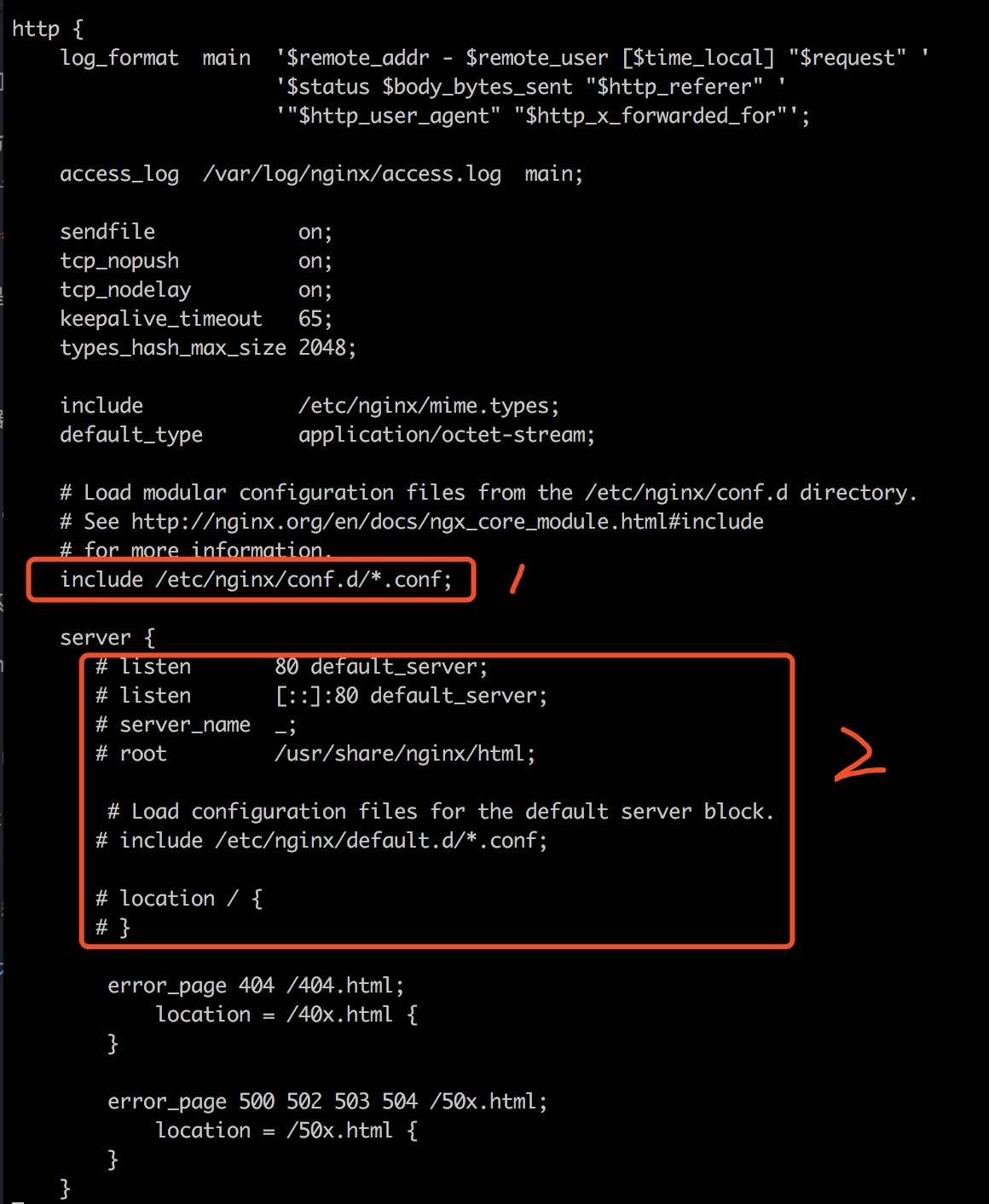
注意:确保红色圈中的 1 部分没有被注释,圈中的 2 部分注释。
这样做的目的是为了如果之后需要添加多个 server 的话,都在 nginx.conf 文件改,就不容易维护了。
接下来,添加我们这次需要的跟 nginx 相关的文件
cd /etc/nginx/conf.d
touch koa-demo.conf
vi koa-demo.conf然后,把以下内容 copy 到 koa-demo.con 中并保存
upstream koa-demo {
server 127.0.0.1:3000;
}
server {
listen 80;
location / {
proxy_pass http://koa-demo;
}
}
之后,使用下面的命令
nginx -t
# 用来测试你的配置文件是否 ok
nginx -s reload
# 重新加载配置文件没意外的话,这个时候在浏览器中输入你的云服务器 ip 地址,就可以看到效果了。
等等,你说你的浏览器没反应。不要慌,这是因为你的代码还没运行呢
# 我的代码克隆在这里,你的路径可能跟我的不同
cd /opt/koa-demo
npm start这时候再刷新页面,ok 了,大功告成。
接着,你可能就想给自己加个鸡腿庆祝一下,然后就退出了云服务器,跑去吃饭了。吃完饭回来,再次刷新浏览器,我了个去,怎么又没内容了。 为什么会这样呢?
这是因为你打开的方式不对,也就是启动代码的方式不对,你可以看看 packagek.json 的内容,npm start 其实就是执行 node index.js 。当你这边退出了,这个进程也就结束了,想想在你的本地是不是也这样,你在你的终端运行,打开浏览器是没有问题的,退出终端,再刷新页面,就出问题了。
那这个问题要如何解决呢?呃,如果你之前有接触过 node,那应该就听过 pm2 这个词了。是的,没错,接下来我们就用这个 pm2 解决我们的问题。
如何学习 pm2 呢,最快的方式就去看它的 官网 咯,里面的文档还是写的很不错的,一个 Quick Start 直接入门。
这里就不多介绍了,看文档会更快了解。 那接下来怎么跑呢,你可以看到 package.json 里面的 script 还有个命令,就是 pm2,这个就是我之前已经添加好了,用 pm2 来启动程序的命令。具体如下:
# 先登录到云服务器
ssh hostname
# 进入代码目录
cd /opt/koa-demo
# run
npm run pm2这个时候,即使你退出了,再次刷新页面,也不会有问题了。
docker,你应该听过这个名词吧,没听过说明你有点跟不上时代阿。 如果没有了解过 docker,可以参考阮一峰老师的 Docker 入门教程。
接下来,就试一试如何利用 docker 部署我们的 nodejs 应用。
首先,我们需要在我们的 koa-demo 中添加 Dockerfile 和.dockerignore。我已经在代码中添加好了,你可以直接简单地复制到你的项目中。至于其中的那些命令代表什么意思,就不多解释了。你看完阮老师的那篇文章,多少有点了解了。或者你可以 docker COMMAND -h 获取各个命令的使用。
首先,我们需要在云主机上安装 docker,可以参考 docker 官网 About Docker CE, 里面有关于各个系统的安装说明,很详细了。
进入到我们的代码目录,利用 docker build 命令,编译出我们需要的镜像文件,然后用 docker run,运行容器
cd /opt/koa-demo
docker build -t koa-demo .
docker run -d -p 7000:3000 koa-demo这里,我用本地的 7000 端口映射容器的 3000 端口。
这个时候,你可以使用一下命令,看是否正确运行
curl -i localhost:7000
# 应该会返回如下结果
HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Content-Length: 30
Date: Mon, 02 Jul 2018 12:12:26 GMT
Connection: keep-alive
It's success, congratulation!现在,我们的容器已经跑起来了,你可以想试试直接在浏览器输入 ip:port 这样的形式是否可以访问,等你输入之后,你会发现是没有反应的。
为什么呢,不要急,我们还没有添加 nginx 配置呢。
cd /etc/nginx/conf.d
vi docker-demo.conf
# 写入以下内容
upstream docker-demo {
server 127.0.0.1:7000;
}
server {
listen 7070;
location / {
proxy_pass http://docker-demo;
}
}记得用 nginx -t 来测试你的 conf 是否 ok, 然后 nginx -s reload 重新加载一下。
这个时候,你就可以用 IP:Port(这里的 Port 是上面的 listen 的端口) 的形式访问了。
假如,你这个时候还是没法访问的话,有可能是你的安全组设置的问题,设置一下即可。
以上就是一个小白的辛酸部署路,路程艰辛,但学到了不少东西,收获很多。
谁说前端不需要懂-Nginx 反向代理与负载均衡
Dockerizing a Node.js web app
Get Docker CE for CentOS
Docker — 从入门到实践
Vue 3.0 采取的 diff 算法和 2.0 的双端比较有点不同。大概的原理如下
// c1: a b [ c d e ] f g
// c2: a b [ d e c h ] f g假如有如上的 c1 和 c2 新旧 children,在 diff 的时候,会有一个预处理的过程。
先从前往后比较,当节点不同时,不再往后进行比较。接着又从后往前进行比较,当节点不同时,不再往前进行比较。
经过预处理之后,c1 和 c2 真正需要进行 diff 的部分如下所示:
// c1: c d e
// c2: d e c h最后利用 “最长递增子序列”,完成上述差异部分的比较,提高 diff 效率。
预处理过程代码如下所示:
const patchKeyedChildren = (
c1,
c2,
container,
parentAnchor,
parentComponent,
parentSuspense,
isSVG,
optimized
) => {
let i = 0;
const l2 = c2.length
let e1 = c1.length - 1
let e2 = c2.length - 1
// 1. sync from start
while (i <= e1 && i <= e2) {
const n1 = c1[i]
const n2 = c2[i]
if (isSameVNodeType(n1, n2)) {
patch(
n1,
n2,
container,
parentAnchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
} else {
break
}
i++
}
// 2. sync from end
while (i <= e1 && i <= e2) {
const n1 = c1[e1]
const n2 = c2[e2]
if (isSameVNodeType(n1, n2)) {
patch(
n1,
n2,
container,
parentAnchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
} else {
break
}
e1--
e2--
}
}进行预处理还有一个好处,就是在某些情况下,我们可以明确的知道有节点的新增或者删除。
i、e1、e2 满足下述关系时,可以认为是有节点新增
// 3. common sequence + mount
// (a b)
// (a b) c
// i = 2, e1 = 1, e2 = 2
// (a b)
// c (a b)
// i = 0, e1 = -1, e2 = 0
if (i > e1) {
if (i <= e2) {
const nextPos = e2 + 1;
const anchor = nextPos < l2 ? c2[nextPos] : parentAnchor
while (i <= e2) {
patch(
null,
c2[i],
container,
anchor,
parentComponent,
parentSuspense,
isSVG
)
i++
}
}
} else if {
//
} else {
//
}i、e1、e2 满足下述关系时,可以认为是有节点被移除
// 4. common sequence + unmount
// (a b) c
// (a b)
// i = 2, e1 = 2, e2 = 1
// a (b c)
// (b c)
// i = 0, e1 = 0, e2 = -1
if (i > e1) {
//
} else if (i > e2) {
while (i <= e1) {
unmount(c1[i], parentComponent, parentSuspense, true)
i++
}
} else {
//
}有时候情况可能没有上述那么地简单,即 i、e1、e2 并不满足上述两种情形时,我们就要寻找其中需要被移除、新增的节点,又或是判断哪些节点需要进行移动。
为此,我们需要去遍历 c1 中还没有进行处理的节点,然后查看在 c2 中是否有对应的节点(key 相同)。没有,则说明该节点已经被移除,那就执行 unmount 操作。
首先,为了快速确认 c1 的节点在 c2 中是否有对应的节点及所在的位置,对 c2 中的节点建立一个映射 (key: index)
// 5. unknown sequence
// [i ... e1 + 1]: a b [c d e] f g
// [i ... e2 + 1]: a b [d e c h] f g
// i = 2, e1 = 4, e2 = 5
if (i > e1) {
//
} else if (i > e2) {
//
} else {
const s1 = i
const s2 = i
const keyToNewIndexMap = new Map()
// 5.1 build key:index map for newChildren
for (i = s2; i <= e2; i++) {
const nextChild = c2[i]
if (nextChild.key !== null) {
keyToNewIndexMap.set(nextChild.key, i)
}
}
}接着,定义以下几个变量
let j
let patched = 0
const toBePatched = e2 - s2 + 1 // c2 中待处理的节点数目
let moved = false
// used to track whether any node has moved
let maxNewIndexSoFar = 0 // 已遍历的待处理的 c1 节点在 c2 中对应的索引最大值
// works as Map<newIndex, oldIndex>
// Note that oldIndex is offset by +1
// and oldIndex = 0 is a special value indicating the new node has
// no corresponding old node.
// used for determining longest stable subsequence
const newIndexToOldIndexMap = new Array(toBePatched) // 用于后面求最长递增子序列
for (i = 0; i < toBePatched; i++) {
newIndexToOldIndexMap[i] = 0
}然后,遍历 c1 中待处理的节点,判断否 c2 中是有相同 key 的节点存在。
// 5.2 loop through old children left to be patched and try to patch
// matching nodes & remove nodes that are no longer present
for (i = s1; i <= e1; i++) {
const prevChild = c1[i]
// (A)
let newIndex
if (prevChild.key !== null) {
newIndex = keyToNewIndexMap.get(prevChild.key)
} else {
for (j = s2; i <= e2; j++) {
if (
newIndexToOldIndexMap[j - s2] === 0 &&
isSameVNodeType(prevChild, c2[j])
) {
newIndex = j
break
}
}
}
if (newIndex === void 0) {
unmount(prevChild, parentComponent, parentSuspense, true)
} else {
newIndexToOldIndexMap[newIndex - s2] = i + 1 // (B)
if (newIndex >= maxNewIndexSoFar) {
maxNewIndexSoFar = newIndex
} else {
moved = true
}
patch(
prevChild,
c2[i],
container,
null,
parentComponent,
parentSuspense,
isSVG,
optimized
)
patched++ // (C)
}
}是不是 c1 中的所有节点都需要在 c2 中寻找对应节点,然后调用 patch 呢。
注意到上面的代码 (C),我们会更新已经 patched 的节点的数目,那么当 patched > toBePatched,可以认为接下来遍历的 c1 中的节点都是多余的了,直接移除就好。
所以在上面的 (A) 处需要补充一下代码
if (patched >= toBePatched) {
// all new children have been patched so this can only be a removal
unmount(prevChild, parentComponent, parentSuspense, true)
continue
}到这里,就是较难理解的部分了。
开篇我们说过,预处理过后,剩下的节点会借助最长递增子序列来提高 diff 效率。
求解最长递增子序列,主要的目的就是为了减少 dom 元素的移动,也可以理解为最少的 dom 操作。
首先,我们需要求解得到最长递增子序列
// generate longest stable subsequence only when nodes have moved
const increasingNewIndexSequence = moved
? getSequence(newIndexToOldIndexMap)
: EMPTY_ARR 先看看这里的 newIndexToOldIndexMap 的值是什么。
结合一下具体的例子,假设 c1 、c2 如下图所示

定义并初始化 newIndexToOldIndexMap
const newIndexToOldIndexMap = new Array(toBePatched)
for (i = 0; i < toBePatched; i++) {
newIndexToOldIndexMap[i] = 0
}toBePatched 即预处理后,c2 中待处理的节点数目。对应这里的例子,会有
toBePatched = 4
newIndexToOldIndexMap = [0, 0, 0, 0]注意到上面 5.2 遍历 c1 中节点的代码的 (B) 处,有
// 这里是 i + 1,不是 i
// 因为 0 是一个特殊值,表示这个是新增的节点
newIndexToOldIndexMap[newIndex - s2] = i + 1 // (B)所以处理完 c1 中的节点后,将有
moved = true
newIndexToOldIndexMap = [4, 5, 3, 0]那么,increasingNewIndexSequence 的值就是 getSequence(newIndexToOldIndexMap) 的返回值
// [4, 5, 3, 0] --> 最长递增子序列是 [4, 5]
// 对应的索引是 [0, 1]
increasingNewIndexSequence = [0, 1]在求解得到最长递增子序列之后,剩下的就是遍历 c2 中的待处理节点,判断是否节点是否属于新增,是否需要进行移动。
j = increasingNewIndexSequence.length - 1
// looping backwards so that we can use last patched node as anchor
// 注意:这里是从后往前遍历
for (i = toBePatched - 1; i >= 0; i--) {
const nextIndex = s2 + i
const nextChild = c2[nextIndex]
const anchor =
nextIndex + 1 < l2 ? (c2[nextIndex + 1]).el : parentAnchor
// newIndexToOldIndexMap 里的值默认初始化为 0
// 这里 === 0 表示 c2 中的节点在 c1 中没有对应的节点,属于新增
if (newIndexToOldIndexMap[i] === 0) {
// mount new
patch(
null,
nextChild,
container,
anchor,
parentComponent,
parentSuspense,
isSVG
)
} else if (moved) {
// move if:
// There is no stable subsequence (e.g. a reverse)
// OR current node is not among the stable sequence
// j < 0 --> 最长递增子序列为 []
if (j < 0 || i !== increasingNewIndexSequence[j]) {
move(nextChild, container, anchor, MoveType.REORDER)
} else {
j--
}
}
}在计算机科学中,最长递增子序列(longest increasing subsequence)问题是指,在一个给定的数值序列中,找到一个子序列,使得这个子序列元素的数值依次递增,并且这个子序列的长度尽可能地大。最长递增子序列中的元素在原序列中不一定是连续的。 -- 维基百科
对于以下的原始序列
0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15
最长递增子序列为
0, 2, 6, 9, 11, 15.
值得注意的是原始序列的最长递增子序列并不一定唯一,对于该原始序列,实际上还有以下两个最长递增子序列
0, 4, 6, 9, 11, 15
0, 4, 6, 9, 13, 15
到此,Vue 3.0 的 diff 代码就分析完了。有不同理解或不理解的,欢迎一起讨论。
具体的代码: renderer.ts
原文链接:Webpack 4 — Mysterious SplitChunks Plugin
官方发布了 webpack 4,舍弃了之前的 commonChunkPlugin,增加了 SplitChunksPlugin, 对于这个插件,它的 option 选项有‘initial’、'async'、'all'三个值。我想大多数刚学习 webpack 4 的同学都不能很好的理解这几个值的区别,到底每个选项值意味着什么呢,这篇文章为我们详细解释了这几个值的区别。
这是我的一个粗略尝试,通过一个常见的例子来理解和帮助你使用 SplitChunksPlugin 选项。
作为早期的爱好者,我试图理解代码分割 (Code-Spliting) 背后的魔法。文档说 splitChucnks 接受'initial', 'async', 'all'。我有点困惑,更加提高了我的好奇心。
我深入研究了文档的 Github 历史记录和 WebpackOptions 概要,并发现,
“There are 3 values possible ”initial”, ”async” and ”all”. When configured the optimization only selects initial chunks, on-demand chunks or all chunks.” — Github History
“Select chunks for determining shared modules (defaults to “async”, “initial” and “all” requires adding these chunks to the HTML) ”
— WebpackOptions Schema这里的想法是有 a.js 和 b.js 两个入口文件,然后引用相同的 node_modules。 其中的一些 module 会被动态引入,用来检验代码分割(Code-Spliting)的行为。
我们使用 Webpack Bundle Analyzer Plugin 来帮助我们理解我们的 node_modules 是如何被分割的。
只有 lodash 是动态引入的
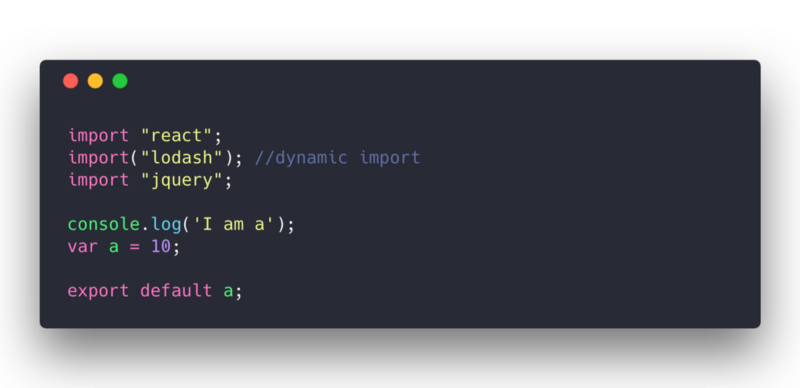
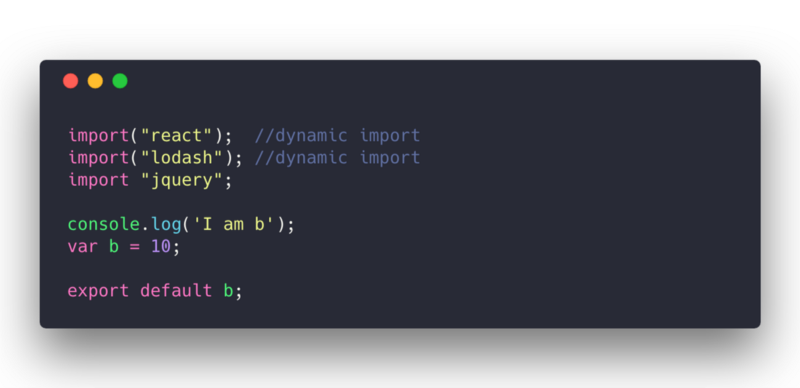
我选这样的配置的主要原因是为了理解当存在公共库时,Webpack 配置的表现是如何的
我们将保持这些文件不变,并通过 chunks 的值来更改 webpack 的配置。

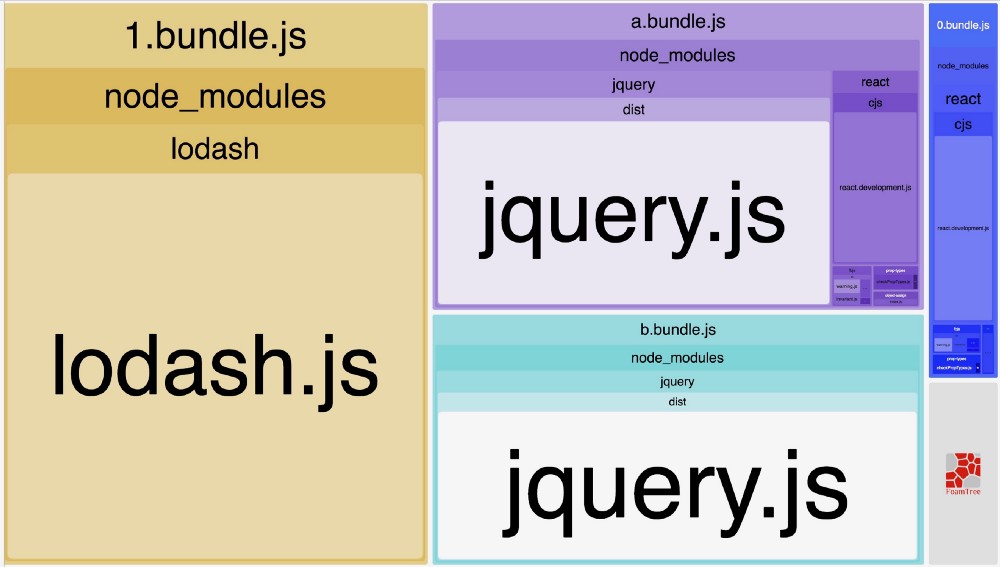
chunks: 'async' 告诉 webpack
”hey, webpack!我只关心动态导入的模块的优化。你可以保留非动态模块“
现在,让我们一步一步看看发生了什么

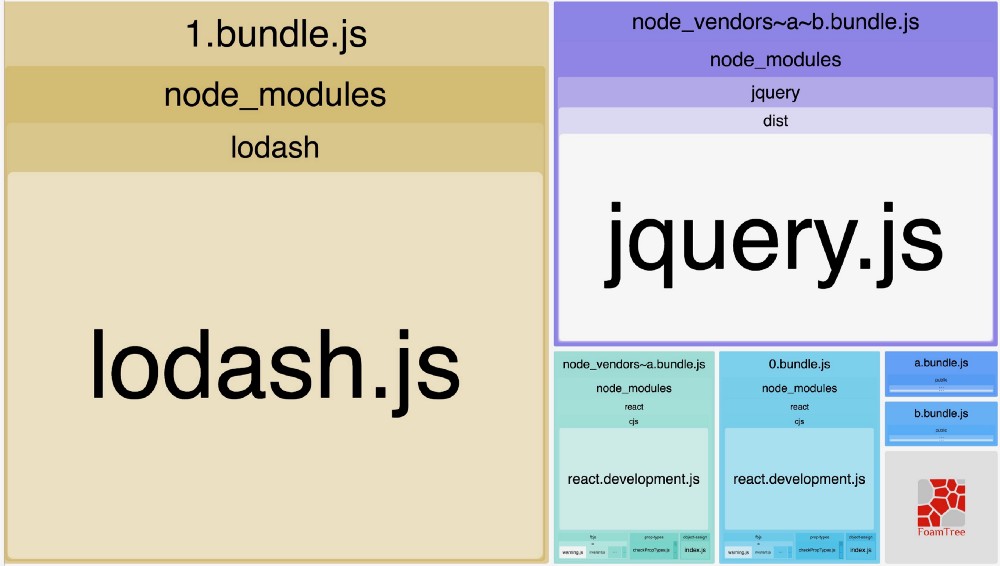
chunks: 'initial' 告诉 webpack
”hey, webpack!我不关心动态引入的模块,你可以为每一个模块分别创建文件。但是,我希望将所有非动态引入的模块放在一个 bundle 中,尽管它们还需要引入其他的非动态引入的木块,我准备与其他文件共享和分块我的非动态导入模块“
现在,让我们一步一步看看发生了什么

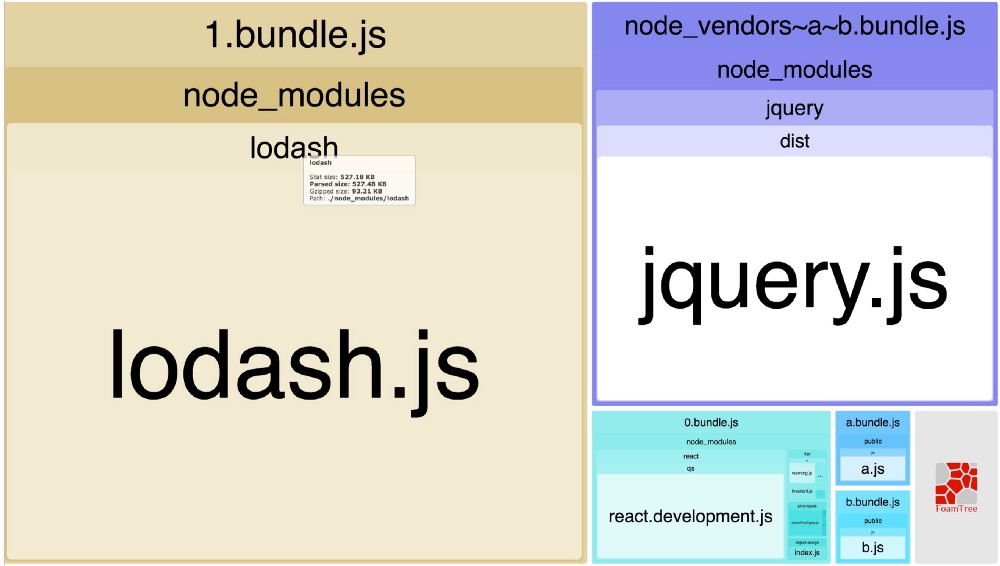
chunks: 'all' 告诉 webpack
”hey, webpack!我不关心这是一个动态还是非动态引入的模块。都对它们进行优化。 但要确保......你足够聪明这样做“
现在,让我们一步一步看看发生了什么
第一次翻译,有很多不到位的地方,欢迎指正。
引用 维基百科 里的介绍:
Cookie,类型为“小型文本文件”,指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据。
Cookie 是由服务器发送到浏览器的一小块数据,之后浏览器会保存 Cookie 的值,当再次向同一个服务器发起请求时,会携带之前保存的 Cookie。
Cookie 的表现形式为 <cookie-name>=<cookie-value>;,还可以带上 Path、Expired 等属性,它们之间用 ; 间隔。例如:
Cookie: name=laohan; Path=/; Expires=Thu, 31 Dec 2020 15:59:59 GMT;
更多详细的介绍可以参考这里 Using HTTP cookies
Cookie 主要有 Domain、Path、Expires、Secure、HttpOnly 等属性,作为一个 web 开发者,相信应该不会感到陌生。今天主要介绍的是 Cookie 中的大家可能不怎么熟悉 SameSite 属性。
SameSite 属性的存在可以有效地防止 CSRF ,其主要是告知浏览器发起请求时是否允许携带 Cookie 。
SameSite 可接收以下三个值
对于不同的值,会有不同的表现。
介绍之前,先了解一个概念:跨站(cross-site)。
浏览器的同源策略,大家应该都清楚。即两个站点中的协议、域名、端口中的一项不相同,就认为两个站点是非同源的。举个例子:
| oringinA | originB | |
|---|---|---|
| https://www.example.com:443 | http://www.example.com:443 | 非同源: 协议不同 |
| https://a.example.com:443 | 非同源: 域名不同 | |
| https://www.example.com:80 | 非同源: 端口不同 | |
| https://www.example.com:443 | 同源 |
那么,跨站又是指什么呢?
对应跨站,那应该也有同站的概念。如果两个站点不属于同站,那就是跨站了嘛。
相比较于同源,同站会更简单。并不要求协议、域名和端口都要一致,只要 eTLD + 1 一致就可以了。
Top-Level-Domain(TLD) 即顶级域名,例如 .com、.org 等。我们所说的 “站” 就是 domain + TLD 组成的部分。当两个站点的 “站” 相同时,我们就可以认为两个站属于同站。 但对于 .github.io 这样的站点,使用 .io 并不足以识别 “站”, effective TLDS 由此产生,即有效的顶级域名。
所以两个站点同站的条件是 eTLD + 1 相等。对于 https://www.example.com 来说,eTLD + 1 就是 example.com。对于 https://a.b.github.io 来说,eTLD + 1 就是 b.github.io 。
举个例子会更清晰一些:
| oringinA | originB | |
|---|---|---|
| https://www.example.com | https://www.evil.com | 跨站: 二级域名不同 |
| https://www.example.co | 跨站: 有效域名不同 | |
| https://a.example.com | 同站 |
| oringinA | originB | |
|---|---|---|
| https://example.github.io | https://evil.github.io | 跨站: 三级域名不同 |
| https://www.example.com | 跨站: 有效域名不同 | |
| https://a.example.github.io | 同站 |
当跨站时,发送请求不会带上 Cookie。仅当与当前页面属于同个站点时,才会携带 Cookie。
允许部分跨站请求携带 Cookie。但仅在以下几种情况
| 请求类型 | 示例 | 是否发送 |
|---|---|---|
| 链接 | <a href="xxx"></a> | 是 |
| 预加载 | <link rel="prerender" href="xxx" /> | 是 |
| GET 表单 | <form method="GET" action="xxx"> | 是 |
<img>、<script>加载资源时都不允许携带 Cookie
允许任意站点请求携带 Cookie。但是需要额外带上 Secure 属性。
由于这个值是在之后新添加进来,设置 SameSite=None 对于一些浏览器会存在兼容问题,不同的浏览器表现也不一致。有一些浏览器会忽略设置的值,有一些则会认为是 SameSite=Strict 。
但是对于 SameSite=None 这个又是大多数开发者需要的一个属性,比如常见的单点登录。那么,这个问题该如何解决呢?主要有以下两种方法:
// express
// 设置
res.cookie('3pcookie', 'value', { sameSite: 'none', secure: true });
res.cookie('3pcookie-legacy', 'value', { secure: true });
// 取值
if (req.cookies['3pcookie']) {
cookieVal = req.cookies['3pcookie'];
} else if (req.cookies['3pcookie-legacy']) {
cookieVal = req.cookies['3pcookie-legacy'];
}在这里可以看到不支持的浏览器。
如果你使用 JavaScript ,可以看看 https://github.com/linsight/should-send-same-site-none
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.