- 生成文件问题。cl1e-DOR
- 饱和速度问题
1、使用Java或C++写模拟器,用于模拟消息的路由过程(文件夹中给了一个模拟器样例,可以使用这个,也可以自己写);
2、模拟器主要实现网络的结构,消息结构,路由算法;
3、下文提供45种路由算法供同学们选择,需要每位同学在课程讨论区留言,前面的同学已经选择的路由算法不能再选择。可以选择除这些之外的路由算法,但需要跟我讲一下。
4、网络大小可以设定二维的为8 * 8,三维的为4 * 4 * 4,流量模式使用uniform,transpose,hotspot中的一种就可以; (均匀、转置、热点)
5、最后提交源代码(有注释和文档说明)以及平均延迟和吞吐量的实验结果。实验结果指的是随着注入率的增加,平均延迟和吞吐量的变化曲线,如文件夹中实验结果样例图所示:一个是average latency,一个是throughput,横坐标可以是代码中的linkrate,展示随着linkrate的增加average latency和throughput如何变化的曲线,到饱和点就可以了。饱和点指的是average latency迅速增加,throughput下降的那个点。
Uniform Traffic Pattern:
- 在uniform流量模式中,任何一个节点发送到其他节点的消息概率是均等的。这种模式用于评估网络在负载均匀分布时的性能。它是理想状态下的流量分布,用于基线性能测试,因为它提供了一个均匀的网络压力场景。
Transpose Traffic Pattern:
- Transpose流量模式在网格结构中尤为有用。例如,在一个n×n的2D网格中,如果源节点位于位置 (i, j),则目标节点在位置 (j, i)。在3D网格中,这种模式可以类似地定义。这种模式用于评估网络在特定数据流动模式下的性能,这种模式在某些应用如矩阵操作中较为常见。
Hotspot Traffic Pattern:
- 在hotspot流量模式中,网络中的一个或多个节点会接收比其他节点多得多的数据(即这些节点是“热点”)。这种模式用来测试网络如何处理极端情况下的负载不平衡,以及网络在面对局部过载时的稳定性和效率。
对于流量控制基路由在三维网格的选择,这取决于你想模拟哪种实际场景:
- 如果你的目的是测试网络在一般情况下的表现,uniform模式是一个好的起点。
- 如果你的应用或任务涉及到大量的矩阵转置或者数据需要在特定的模式下传输,transpose模式更合适。
- 如果你需要模拟和评估网络在处理数据中心或特定节点过载情况下的表现,使用hotspot模式将更加适宜。
路由算法的选取?
流量控制方法的选取?与给定的三种流量模式的关系?
一个小问题:
解决:
在
Q3DMeshNode.h中继续使用前向声明class Q3DMesh;。在
Q3DMesh.h中包含Q3DMeshNode.h以获取Q3DMeshNode的完整定义。确保在
Q3DMeshNode.cpp中包含Q3DMesh.h,以便编译器在实现文件中了解完整的类定义。
使用像 gdb 这样的调试器可以帮助您准确找到程序崩溃的位置。如果您在 Linux 或类似系统上,可以按以下方式使用 gdb:
gdb ./build/NOC然后在 gdb 提示符下输入 run 命令启动程序。当程序崩溃时,gdb 会停下来,并显示导致问题的具体行号和文件名。您可以使用 bt (backtrace) 命令查看调用栈。
使用 GDB 调试时,尝试在 setMesh 和其他相关方法中设置断点,查看 mesh 的值:
(gdb) break Q3DMeshNode::setMesh
(gdb) run
(gdb) print mesh(gdb) print this
(gdb) print mesh
(gdb) print *this
(gdb) print *mesh
==r为一直执行,n为单步执行。p为输出print,b为设置断点break,clear 删除所有断点 delete 删除编号为Num的断点==
==list src/main.cpp:107来查看特定的文件和行号。jump命令用于改变程序的执行流程==
调试之后的输出:
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./NOC...
(No debugging symbols found in ./NOC)
(gdb) r
Starting program: /home/lugy35/Project/NOC_Simulator/Simulator/build/NOC
Program received signal SIGSEGV, Segmentation fault.
0x0000555555556c1e in Q3DMeshNode::setMesh(Q3DMesh*) ()// 设置节点所在的网络
void Q3DMeshNode::setMesh(Q3DMesh *mesh)
{
assert(mesh != nullptr); // 确保mesh不是空指针
this->mesh = mesh;
}//这个函数报错:
// Program received signal SIGSEGV, Segmentation fault.
// 0x0000555555556c1e in Q3DMeshNode::setMesh(Q3DMesh*) ()定位到出错的代码,分析问题。
Linux环境下段错误的产生原因及调试方法小结 - 大圆那些事 - 博客园 (cnblogs.com)
使用gdb来debug程序并查找Segmentation fault原因_gdb 分析 segmentation fault-CSDN博客
ulimit -a: 查看系统参数,若后面的数字为0,则代表不生成core文件
ulimit -c unlimited: 将core文件大小设置为无限制,即生成core文件设置好之后,执行生成的文件,然后会生成core文件
执行gdb,示例:
gdb ./segfault3 ./core
再比如:
gdb ./NOC ./core.NOC.448874 输入如下:
(gdb) bt
#0 0x000055b72ddc0c48 in Q3DMeshNode::setMesh (this=0x55b72f0bffe8, mesh=0x55b72f0b3120) at src/Q3DMeshNode.cpp:158
#1 0x000055b72ddc3787 in Q3DMesh::Q3DMesh (this=0x55b72f0b3120, n=4, R1buffer=16, R2buffer=0) at src/Q3DMesh.cpp:29
#2 0x000055b72ddc4046 in main () at src/main.cpp:74这样会输出更多的内容。
同样,makefile里面增加:
# 新增一个目标来运行程序,允许生成 core 文件
run: $(BUILD_DIR)/$(TARGET_EXEC)
ulimit -c unlimited; ./$(BUILD_DIR)/$(TARGET_EXEC)
# 这个目标是专门用来调试已经崩溃并生成了 core 文件的程序。
debug-core:
gdb -c core $(BUILD_DIR)/$(TARGET_EXEC)
# 使用 -c core 参数启动 GDB,这告诉 GDB 加载指定的 core 文件。Core 文件包含了程序崩溃时的内存快照、寄存器状态、程序计数器位置等信息,非常有助于分析程序崩溃的原因。
# 这个目标用于直接启动 GDB 调试正在运行的或是可重新启动的程序。
debug: $(BUILD_DIR)/$(TARGET_EXEC) # 新增 debug 目标
gdb $(BUILD_DIR)/$(TARGET_EXEC)
# 这个目标用于直接启动 GDB 调试正在运行的或是可重新启动的程序。然后先make run,再make debug-core。
make debug是单纯用来启动gdb的。
Program received signal SIGSEGV, Segmentation fault.
0x0000555555559a69 in Q3DMesh::operator[] (this=0x100000000, n=65) at src/Q3DMesh.cpp:80
80 return (head + n);
(gdb) bt
#0 0x0000555555559a69 in Q3DMesh::operator[] (this=0x100000000, n=65) at src/Q3DMesh.cpp:80
#1 0x0000555555556a31 in Q3DMeshNode::setLinkBuffer (this=0x555555578748, x1=-1, x2=65, y1=-1, y2=68, z1=48, z2=80) at src/Q3DMeshNode.cpp:112
#2 0x0000555555559a39 in Q3DMesh::Q3DMesh (this=0x555555576120, n=4, R1buffer=16, R2buffer=0) at src/Q3DMesh.cpp:73
#3 0x000055555555a046 in main () at src/main.cpp:74
(gdb) 看到,n = 65。
但是线性索引 n 最大就是 63
int id = x + y * k + z * k * k; // 线性索引最大值为 3 + 3*4 + 3*4*4 = 3 + 12 + 48 = 63我们检查:Q3DMesh::Q3DMesh (this=0x555555576120, n=4, R1buffer=16, R2buffer=0) at src/Q3DMesh.cpp:73在这里的时候还是正确的,
然后Q3DMeshNode::setLinkBuffer (this=0x555555578748, x1=-1, x2=65, y1=-1, y2=68, z1=48, z2=80) at src/Q3DMeshNode.cpp:112这里就出错了。
问题出现在:
// Q3DMesh类的构造函数
Q3DMesh::Q3DMesh(int n, int R1buffer, int R2buffer)
// 设置每个节点的邻接节点链接
for (x = 0; x < k; x++)
{
for (y = 0; y < k; y++)
{
for(z = 0; z < k; z++)
{
int id = x + y * k + z * k * k;
// 线性索引最大值为 3 + 3*4 + 3*4*4 = 3 + 12 + 48 = 63
int xneg, xpos, yneg, ypos, zneg, zpos; // 存储相邻节点的索引
// 设置该节点各个方向相邻的节点
// 设置x维度的链接
if (x != 0) // 如果不是第一列,则向左的节点是前一个,否则不存在(-1)
xneg = (x - 1) + y * k + z * k * k;
else
xneg = -1;
if (x != k - 1) // 如果不是最后一列,则向右的节点是后一个,否则不存在(-1)
xpos = (x + 1) + y * k + z * k * k;
else
xpos = -1;
// 设置y维度的链接
if (y != 0) // 如果不是第一行,则向上的节点是上一行的同列,否则不存在(-1)
yneg = x + (y - 1) * k + z * k * k;
else
yneg = -1;
if (y != k - 1) // 如果不是最后一行,则向下的节点是下一行的同列,否则不存在(-1)
ypos = x + (y + 1) * k + z * k * k;
else
ypos = -1;
// 设置z维度的链接
if (z != 0) // 如果不是第一层,则向前的节点是前一层的同位置
zneg = x + y * k + (z - 1) * k * k;
else // 第一层的节点在z负向没有相邻节点
zneg = -1;
if (z != k - 1) // 如果不是最后一层,则向后的节点是后一层的同位置
zpos = x + y * k + (z + 1) * k * k;
else // 最后一层的节点在z正向没有相邻节点
zpos = -1;
// 设置当前节点的各方向链接
(head + id)->setLinkBuffer(xneg, xpos, yneg, ypos, zneg, zpos);
}
}
}这里就是根据遍历xyz的每个点,然后计算他的线性id——即变量id,并把这个线性id与MESH拓扑中的相邻的节点进行链接——相邻节点的线性id就是计算的 xneg xpos yneg ypos zneg zpos。
int id = x + y * k + z * k * k; // 线性索引最大值为 3 + 3*4 + 3*4*4 = 3 + 12 + 48 = 63最后发现是求xneg xpos yneg ypos zneg zpos的代码出了问题。
// // 设置该节点各个方向相邻的节点
// // 设置x维度的链接
xneg = (x > 0) ? x - 1 + y * k + z * k * k : -1;
xpos = (x < k - 1) ? x + 1 + y * k + z * k * k : -1;
yneg = (y > 0) ? x + (y - 1) * k + z * k * k : -1;
ypos = (y < k - 1) ? x + (y + 1) * k + z * k * k : -1;
zneg = (z > 0) ? x + y * k + (z - 1) * k * k : -1;
zpos = (z < k - 1) ? x + y * k + (z + 1) * k * k : -1;
// if (x != 0) // 如果不是第一列,则向左的节点是前一个,否则不存在(-1)
// xneg = (x - 1) + y * k + z * k * k;
// else
// xneg = -1;
// if (x != k - 1) // 如果不是最后一列,则向右的节点是后一个,否则不存在(-1)
// xpos = (x + 1) + y * k + z * k * k;
// else
// xpos = -1;
// // 设置y维度的链接
// if (y != 0) // 如果不是第一行,则向上的节点是上一行的同列,否则不存在(-1)
// yneg = x + (y - 1) * k + z * k * k;
// else
// yneg = -1;
// if (y != k - 1) // 如果不是最后一行,则向下的节点是下一行的同列,否则不存在(-1)
// ypos = x + (y + 1) * k + z * k * k;
// else
// ypos = -1;
// // 设置z维度的链接
// if (z != 0) // 如果不是第一层,则向前的节点是前一层的同位置
// zneg = x + y * k + (z - 1) * k * k;
// else // 第一层的节点在z负向没有相邻节点
// zneg = -1;
// if (z != k - 1) // 如果不是最后一层,则向后的节点是后一层的同位置
// zpos = x + y * k + (z + 1) * k * k;
// else // 最后一层的节点在z正向没有相邻节点
// zpos = -1;
把原来的的代码注释掉,换成新的代码,就可以了。
但是发现改回去之后又没有问题了。。。。。。。。。。。。。。。。。真的是很玄学的问题。
上面的问题解决之后:
linkrate:0.01 arrive: 7 in the network : 93
average latency: 18.5714 nomalized accepted traffic: 0.0007
linkrate:0.06 arrive: 31 in the network : 569
average latency: 18.0645 nomalized accepted traffic: 0.0031
linkrate:0.11 arrive: 28 in the network : 800
average latency: 18.0714 nomalized accepted traffic: 0.00371981
Saturation point, drain.......
in the network: 175
Program received signal SIGSEGV, Segmentation fault.
0x0000555555558795 in outtotest (allvecmess=0x7fffffffd6b0, mes=0x555555581d40) at src/testfuc.cpp:30
30 << " tail:( " << (*mes)[(*it)->routpath[19].node]->x << " ," << (*mes)[(*it)->routpath[19].node]->y << ", " << (*mes)[(*it)->routpath[19].node]->z << ")"
(gdb) bt
#0 0x0000555555558795 in outtotest (allvecmess=0x7fffffffd6b0, mes=0x555555581d40) at src/testfuc.cpp:30
#1 0x000055555555a867 in main () at src/main.cpp:195
(gdb) print (*it)->routpath[19].node
$2 = -136647936发现了新问题,发现in the network : 800,而main里面int threshold = 2500; // 设置一个阈值,用于控制网络中的消息数量,,而且Saturation point, drain.......输出了,所以问题出现在,消息数量已经超过了设定的阈值。
但是增大阈值之后也是出错,所以问题不只是这个。因为还有一个totalcircle的变量,两个任意一个满足了都会输出Saturation point, drain.......,然后结束程序。
==所以,其实还是要分析代码的功能:如下,在分析代码的功能过程中,其实这个地方还是有错误的,还是要解决。==
最后提交源代码(有注释和文档说明)以及平均延迟和吞吐量的实验结果。
实验结果指的是
随着注入率的增加,平均延迟和吞吐量的变化曲线,如文件夹中实验结果样例图所示:一个是average latency,一个是throughput,横坐标可以是代码中的linkrate,展示随着linkrate的增加average latency和throughput如何变化的曲线,到饱和点就可以了。饱和点指的是average latency迅速增加,throughput下降的那个点。
代码中:吞吐量、延迟和注入率的计算与展示如下:
-
注入率 (linkrate): 是控制消息产生速率的参数,根据它计算每个周期每个节点应该生成的消息数。在代码中,
linkrate从0.01开始,逐步增加,用于模拟不同负载下的网络性能。 -
平均延迟 (average latency): 这是测量网络中消息从发送到接收的平均时间。在代码中,平均延迟的计算方式是
s->totalcir / s->messarrive,其中s->totalcir是消息在网络中累计花费的周期数,而s->messarrive是到达目的地的消息数量。输出语句中表示为:cout << "average latency: " << (s->totalcir / s->messarrive) << " nomalized accepted traffic: " << linkrate * ((float)s->messarrive / allmess) << endl; -
吞吐量 (throughput): 这是网络每秒能处理的数据量。在代码中,吞吐量通过
linkrate * ((float)s->messarrive / allmess)计算,它基于实际到达目的地的消息数与总生成消息数的比率,调整为当前的链路利用率linkrate。输出语句中表示为nomalized accepted traffic。 -
饱和点: 这是网络性能测试中,当进一步增加负载不再导致吞吐量增加,反而使得延迟迅速增加的点。在代码中,饱和点的判定基于吞吐量的变化小于
0.01的比率,并且当getsize(allvecmess) < threshold(意味着网络中的消息数量没有达到阈值)时,认为网络达到饱和。 -
数据输出和图形生成: 您提到需要提交平均延迟和吞吐量的实验结果,包括变化曲线。这通常需要收集这些数据并使用绘图工具(如Excel,Python的matplotlib库,或其他科学计算软件)来生成图表。数据是从程序输出(例如写入的文件或控制台输出)中收集的,然后根据这些数据绘制延迟和吞吐量随注入率的变化曲线。
输出:
linkrate:0.01 arrive: 1 in the network : 9 average latency: 19 nomalized accepted traffic: 0.001 ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- linkrate:0.06 arrive: 9 in the network : 51 average latency: 18.5556 nomalized accepted traffic: 0.009 ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- linkrate:0.11 arrive: 15 in the network : 95 average latency: 18.8 nomalized accepted traffic: 0.015 ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- ponit------- 3333 -------------------- linkrate:0.16 arrive: 15 in the network : 145 average latency: 19.1333 nomalized accepted traffic: 0.015 Saturation point, drain....... ponit------- 1111 -------------------- ponit------- 1111 -------------------- ponit------- 1111 -------------------- ponit------- 1111 -------------------- in the network: 103 Segmentation fault (core dumped) make: *** [Makefile:34: run] Error 139linkrate:0.16 arrive: 15 in the network : 145 average latency: 19.1333 nomalized accepted traffic: 0.015每个指标的详细解释:
- linkrate: 0.16 这表示链路利用率为0.16。这是一个测量网络负载程度的指标,显示了网络链路上流量的比例。值为0.16意味着链路的16%正在被使用,这是一个评估网络负载的指标。
- arrive: 15 这指的是在当前模拟周期内,有15个消息成功到达了它们的目的地。这个数字是衡量网络效率和性能的一个直接指标,显示了在一定时间内成功完成的传输数量。
- in the network: 145 这表示在模拟的当前时间点,网络中总共有145个消息正在传输过程中。这包括了所有在途中、等待中或处理中的消息。这个指标有助于了解网络的拥堵程度以及系统当前的活跃程度。
- average latency: 19.1333 平均延迟是指消息从源到目的地平均所花费的时间,这里是19.1333个时间单位。这是网络性能的一个关键指标,用于评估消息在网络中传输的速度和效率。
- nomalized accepted traffic: 0.015 归一化接受流量是一个衡量网络容量被利用程度的指标。在这里,它的值是0.015,意味着从理论上讲,每个周期每个节点可以处理的流量中有1.5%被成功处理了。这通常用于评估网络的总体吞吐量性能。
point——是在代码中加的用于调试的:
if (linkrate * ((float)s->messarrive / allmess) > max && ((linkrate * ((float)s->messarrive / allmess) - max) / max) > 0.01 && getsize(allvecmess) < threshold) max = linkrate * ((float)s->messarrive / allmess); else { cout << "Saturation point, drain......." << endl; drain(allvecmess, mes, s); // 当达到饱和点时,清空网络并输出相关信息 int size = 0; for (int j = 0; j < 10; j++) { if (!allvecmess[j].empty()) { size += allvecmess[j].size(); printf("ponit------- 1111 --------------------\r\n"); } } cout << "in the network: " << size << endl; outtotest(allvecmess, mes); bufferleft(mes, knode); cout << "max:" << max << endl; printf("ponit------- 2222 --------------------\r\n"); break; } /************************************************************************************ clean *******************************************************************************************/ // 清理资源,准备下一轮模拟 for (int m = 0; m < 10; m++) { printf("ponit------- 3333 --------------------\r\n"); for (vector<Message *>::iterator it = allvecmess[m].begin(); it != allvecmess[m].end(); it++) delete (*it); // 删除所有消息 } delete rout1; // 删除路由对象 delete mes; // 删除网络结构对象 delete s; // 删除事件处理对象但是可以看到,饱和的时候,只是printf("ponit------- 1111 --------------------\r\n");,
而没有能够printf("ponit------- 2222 --------------------\r\n");,说明
这个代码确实还是segment fault 有问题,所以还是要去检查。
一直segment fault,是因为:
//将消息输出到测试文件
void outtotest(vector<Message *> *allvecmess, Q3DMesh *mes)
{
ofstream out = ofstream("test"); // 创建一个输出文件流
for (int i = 0; i < 10; i++)
{
vector<Message *> &vecmess = allvecmess[i]; // 引用每一个消息队列
for (vector<Message *>::iterator it = vecmess.begin(); it != vecmess.end(); it++)
{
// 输出消息的计数、源点和目的地坐标(包括z坐标),以及头部和尾部的信息
out << "count: " << (*it)->count
<< " src: ( " << (*mes)[(*it)->src]->x << " ," << (*mes)[(*it)->src]->y << ", " << (*mes)[(*it)->src]->z << ")"
<< " dst: ( " << (*mes)[(*it)->dst]->x << " ," << (*mes)[(*it)->dst]->y << ", " << (*mes)[(*it)->dst]->z << ")"
<< " head:( " << (*mes)[(*it)->routpath[0].node]->x << " ," << (*mes)[(*it)->routpath[0].node]->y << ", " << (*mes)[(*it)->routpath[0].node]->z
<< ", R" << (*it)->routpath[0].channel << ")"//<<endl;
// int j = 0;
// while(1){
// if((*it)->routpath[j].node != -1) j++;
// else break;
// }
// message length = 1
<< " tail:( " << (*mes)[(*it)->routpath[MESSLENGTH - 1].node]->x << " ," << (*mes)[(*it)->routpath[MESSLENGTH - 1].node]->y << ", " << (*mes)[(*it)->routpath[MESSLENGTH - 1].node]->z << ")"
<< endl;
}
}
}这个函数里面的tail那一行。
首先,注释掉这一行,看是不是还有错误。
发现没有。说明确实就是这一行的问题。
然后注释一半,只留下x部分
也是出错。
应该是数字的问题,19有问题。改一下数字,换成0。
没问题。说明根本没有19,所以肯定会访问超出界限,然后出错。所以需要查找tail的符号。
(上述 注释的代码本来是想用(*it)->routpath[j] != NULL来计算(或者叫等到)最后一个tail。)
最终查看到EVENT.cpp中,发现消息的长度只有 MESSLENGTH = 16(定义在Q3DMesh.h中),也就是说,包括了head和tail的flit,那么最终输出tali就只是MESSLENGTH -1的索引。
这里还有个问题是,main函数最后return 1,正常的执行是return 0,而原来这里return了1,所以导致最后还是error,但是却没有报错信息。
![image-20240621230800168]()
Routing2.h:
负责路由信息相关,增加z维度即可。
Routing2.cpp:
NodeInfo *Routing2::forward(Message &s)实现的是一个多维路由选择算法,用于在一个3D Mesh网络中决定数据包(消息)的传输路径。/*
这段代码实现的是一个多维路由选择算法,用于在一个3D Mesh网络中决定数据包(消息)的传输路径。
是一种自适应路由算法,因为它考虑了不同方向上缓冲区的使用情况来动态选择最佳的传输路径。
这种算法尤其适用于多维网络结构,如3D Mesh,能有效减少拥塞并平衡负载。
在多维网络(如3D Mesh)中,每个方向(x, y, z)都可能有独立的缓冲区。
*next = *temp1; 这行代码实际上是将 temp1(表示在x方向上的下一个节点及其相关信息)的内容赋给 next,这意味着路由算法决定沿x方向发送消息。
当决定使用某个维度时,通常考虑的是该方向上缓冲区的可用性。这里的 "x维度缓冲区最大" 指的是与其他可用维度相比,x方向的缓冲区(合并R1和R2缓冲区)拥有最大的剩余容量。
减少拥塞:选择缓冲区最大的维度可以帮助避免路由拥塞,因为更大的缓冲区意味着更高的处理能力和更低的拥塞可能性。
平衡负载:通过动态选择最佳路由路径,算法可以更有效地分散网络流量,减少某一路径上的压力,从而实现更均匀的网络负载分布。
提高效率:使用最大缓冲区的路由可能意味着该路径下的处理和转发延迟更低,因此可以提高整体网络性能。
*/
关键特点包括:
- 多维考量:根据消息在x、y、z三个维度上的目标节点位置差(即距离差),动态决定消息的转发路径。
- 缓冲区自适应选择:在选择路径时,算法会考虑各个方向的缓冲区大小,优先选择缓冲区资源充足的路径,以减少因缓冲区不足造成的阻塞。
- 环绕链路处理:特别处理跨越环绕链路的情况,即当目标节点在某维度上的距离超过一半网格尺寸时,可能会通过环绕链路(如果存在)进行路由,以缩短实际传输距离。
- 动态链路使用标记:对所选路径上的链路进行标记,表示其正在被使用,这有助于后续的路由决策。
NodeInfo *Routing2::forward(Message &s) { int var1 = 0; int var2 = 0; int var3 = 0; int var = 0; next->node = -1; // 初始化下一个节点标志为无效 next->buff = NULL; // 初始化下一个缓冲区指针为NULL // 调用xdimension函数和ydimension函数和zdimension函数来尝试在两个维度上确定路由路径 NodeInfo *temp1 = xdimension(s); //临时节点 NodeInfo *temp2 = ydimension(s); NodeInfo *temp3 = zdimension(s); // 如果在x维或y维或z维找到合适的路由节点,相应的var1或var2或var3设为1 if (temp1 != NULL) var1 = 1; if (temp2 != NULL) var2 = 1; if (temp3 != NULL) var3 = 1; // 计算缓冲区大小,决定采用哪个维度的路由信息 int allbuff1 = 0; int allbuff2 = 0; int allbuff3 = 0; // 计算var值,用于决定采用哪个维度的路由信息 原来是2D的,所以为 0:表示没有维度是可用的。1:表示只有第二个维度(y维)是可用的。2:表示只有第一个维度(x维)是可用的。3:表示两个维度都是可用的。 //这里是采用二进制编码,改成3位就变成 a*4 + b*2 + c var = var1 * 4 + var2 * 2 + var3; /*********** 编码 **************** 0:没有维度是可用的。 1:只有 z 维度是可用的。 2:只有 y 维度是可用的。 3:y 和 z 维度都是可用的。 4:只有 x 维度是可用的。 5:x 和 z 维度都是可用的。 6:x 和 y 维度都是可用的。 7:x、y 和 z 维度都是可用的。 *********************************/ switch (var) { case 7: // 所有维度都有可用的路由节点 allbuff1 = temp1->buff->r1 + temp1->buff->r2;// 计算x维度缓冲区的总大小 allbuff2 = temp2->buff->r1 + temp2->buff->r2;// 计算y维度缓冲区的总大小 allbuff3 = temp3->buff->r1 + temp3->buff->r2;// 计算z维度缓冲区的总大小 // 三个维度都可用的情况下,通过buffer大小来判断 if (allbuff1 >= allbuff2 && allbuff1 >= allbuff3) //如果x维度缓冲区最大 { *next = *temp1; //x维度 next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } else if (allbuff2 >= allbuff3) //如果y维度最大 { *next = *temp2; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } else //如果z维度最大 { *next = *temp3; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } break; case 6: // x 和 y 可用 if (temp1->buff->r1 + temp1->buff->r2 >= temp2->buff->r1 + temp2->buff->r2) { *next = *temp1; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } else { *next = *temp2; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } break; case 5: // x 和 z 可用 if (temp1->buff->r1 + temp1->buff->r2 >= temp3->buff->r1 + temp3->buff->r2) { *next = *temp1; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } else { *next = *temp3; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } break; case 3: // y 和 z 可用 if (temp2->buff->r1 + temp2->buff->r2 >= temp3->buff->r1 + temp3->buff->r2) { *next = *temp2; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } else { *next = *temp3; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 } break; case 4: // 只有 x 可用 *next = *temp1; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 break; case 2: // 只有 y 可用 *next = *temp2; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 break; case 1: // 只有 z 可用 *next = *temp3; next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 next->buff->linkused = true; // 标记链路为已使用 break; default: // 没有可用的 next->node = -1; break; } // ----------------------- 注释:原来2D mesh的判断 ----------------------------------------- // if (var == 7) // 如果两个维度都有可用的路由节点 // { // allbuff1 = temp1->buff->r1 + temp1->buff->r2;// 计算x维度缓冲区的总大小 // allbuff2 = temp2->buff->r1 + temp2->buff->r2;// 计算y维度缓冲区的总大小 // allbuff2 = temp3->buff->r1 + temp3->buff->r2;// 计算z维度缓冲区的总大小 // } // if (var == 2 || (var == 3 && allbuff1 >= allbuff2)) // { // 如果只有y维度有效或者两个维度都有效但x维度缓冲区更大 // *next = *temp1; // 选择x维度的路由 // next->buff->bufferMin(next->channel, MESSLENGTH);// 更新缓冲区信息 // next->buff->linkused = true; // 标记链路为已使用 // } // else if (var == 1 || (var == 3 && allbuff1 < allbuff2)) // { // 如果只有x维度有效或者两个维度都有效但y维度缓冲区更大 // *next = *temp2; // 选择y维度的路由 // next->buff->bufferMin(next->channel, MESSLENGTH); // 更新缓冲区信息 // next->buff->linkused = true; // 标记链路为已使用 // } return next; // 返回下一个节点的信息 }
之前这里只是2D的,也就是注释的部分,没有z维度的判断。
而下面有处理沿xyz三个维度的路由决策函数。比如下面x的:
==这里有关于routpath的部分,所以之前的segment fault很有可能就是这里的问题。==
需要修改:
xdimension函数的代码主要处理沿 x 维度的路由决策,适用于一个具有环绕链路的 3D Mesh 网络。以下是一些可能需要修改或确认的地方:
- 环绕链路处理:
- ==当距离超过半个网格大小时,代码尝试通过交换链路和节点索引来处理环绕链路,这适用于环状(torus)网格。如果是在一个没有环绕链路的3D Mesh中,这段代码将不适用,因为环绕链路不存在。==
- 链路使用情况判断:
- 在判断链路是否被使用时,您需要确认
linkused的逻辑是否正确实现,并确保它正确地反映了链路的使用状态。- 缓冲区容量判断:
- 您的代码在决定是否可以使用一个方向的链路时,检查了
r1和r2通道的缓冲区容量。这是正确的,但需要确保xlink[xdis > 0]的索引安全性和逻辑正确性(考虑 xdis 正负和数组界限)。- 特殊情况处理:
- 特殊情况的逻辑(
special变量)似乎是为了处理特定的环绕链路情况。这个逻辑在当前形式下可能有误,因为您在任何情况下都将special设为true,这可能不是您的预期。- 返回值构造:
- 代码中假设了存在一个
xtemp的局部变量,但实际上没有看到相关的定义。这可能是一个遗漏,需要创建一个NodeInfo类型的变量xtemp并在返回之前正确设置其值。
==修改 处理沿xyz三个维度的路由决策函数:==
首先3D mesh中无环链路,所以关于链路判断的部分可以删除,下面是x维度的部分,y、z维度相同,都要删除。
Event.cpp代码描述了一种使用在计算机网络中的 wormhole路由(wormhole routing)的流量控制机制。在wormhole路由中,数据包(通常被分割为更小的单元称为flits)被分段传输。一旦头部flit(header flit)为自身找到了前进的路径,后续的flits会跟随相同的路径前进,而不需要为每个flit重新确定路径。
在wormhole路由中,flits几乎立即离开路由器,并在下游缓冲区中紧随其后的flits可用时继续前进,这显著降低了延迟,因为它最小化了flits在任何给定路由器中的驻留时间。关键特征如下:
- Header flit决定路径:只有header flit参与路径决策和链路占用。一旦确定了路径,其他flits(如body和tail flits)会沿着这条路径传输。
- 链路占用:当一个数据包的header flit通过路由器时,它会占用必要的链路,直到整个数据包通过完毕。这意味着即使header flit已经离开,链路也会继续被该数据包的其他部分占用。
- 阻塞和释放:如果在某个点上路由器不能向前传输flit(例如,由于下一个节点的缓冲区已满),则整个数据包在网络中的传输会停止,并且占用的链路会保持活跃,直到阻塞解除。当tail flit通过后,相关链路和资源将被释放。
GDB调试不是非常方便,所以使用VSCode的debug,只需要使用makefile编译出可执行文件NOC即可(可以改成NOC.elf)
(Task是用来编译的,所以不需要。)
==launch.json决定了debug能不能用。c_cpp_properties.json决定了语法检测功能能不能用。==
{
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) Launch",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/Simulator/build/NOC",
"args": [],
"stopAtEntry": false,
"cwd": "${fileDirname}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "Set Disassembly Flavor to Intel",
"text": "-gdb-set disassembly-flavor intel",
"ignoreFailures": true
}
]
}
]
}这是c_cpp_properties:
{
"configurations": [
{
"name": "Linux",
"includePath": [
"${workspaceFolder}/**",
"${workspaceFolder}/Simulator/src",
"${workspaceFolder}/Simulator/include"
],
"defines": [],
"compilerPath": "/usr/bin/g++",
"cStandard": "c17",
"cppStandard": "gnu++17",
"intelliSenseMode": "linux-gcc-x64",
"configurationProvider": "ms-vscode.makefile-tools"
}
],
"version": 4
}threshold = 80000;
totalcircle = 10000;
linkrate:0.01 arrive: 1 in the network : 9
average latency: 19 nomalized accepted traffic: 0.001
linkrate:0.06 arrive: 9 in the network : 51
average latency: 18.5556 nomalized accepted traffic: 0.009
linkrate:0.11 arrive: 15 in the network : 95
average latency: 18.8 nomalized accepted traffic: 0.015
linkrate:0.16 arrive: 15 in the network : 145
average latency: 19.1333 nomalized accepted traffic: 0.015
Saturation point, drain.......
in the network: 103
buffer left ---> x-neg: 44, x-pos: 43, y-neg: 30, y-pos: 36, z-neg: 64, z-pos: 64
max:0.015linkrate: 表示网络链路的利用率或负载,从 0.01 递增到 0.16。arrive: 表示成功到达目的地的消息数。in the network: 表示在模拟结束时网络中还存在的消息数。average latency: 表示消息从源到目的地平均所需的周期数。normalized accepted traffic: 表示网络实际能够处理的有效流量(考虑到消息成功到达的比例)。
- 链路利用率与网络性能
- 随着
linkrate从 0.01 增加到 0.16,arrive的数量从 1 增加到 15,显示出网络能够处理更多消息,但在linkrate达到 0.11 后,到达数量不再增加,说明网络接近饱和状态。 average latency略有波动,从 19 到 18.5556 再到 19.1333,变化不大,这表明网络处理消息的速度相对稳定。
- 随着
- 网络饱和点
- 当
linkrate达到 0.16 时,尽管负载增加,但normalized accepted traffic保持在 0.015 不变,表明进一步增加负载并未提高网络的吞吐量,即达到了饱和点。 - 在饱和点声明输出“Saturation point, drain.......",这表示网络无法处理更多的流量,需要进行资源释放。
- 当
- 资源状态
- 网络在经历饱和和资源释放后,显示“in the network: 103”,表明即使在尝试清空网络后,仍有 103 条消息留在网络中。这可能是因为某些消息被严重阻塞或因链路资源限制无法前进。
- 缓冲区剩余情况显示不同方向的缓冲使用情况,有助于分析网络的瓶颈方向。例如,
z-neg和z-pos方向的缓冲剩余最多,可能意味着这些方向的链路利用率较低。
- 优化路由算法:考虑改进或尝试不同的路由算法来更均匀地分配网络流量,减少某些链路的负载集中现象。
- 调整网络参数:根据网络在不同
linkrate下的表现,调整如消息生成率、缓冲区大小或周期总数等参数,以寻求更优的网络性能。 - 增强监控与管理:加强对阻塞消息的处理策略,例如引入优先级机制或更智能的流量控制策略,以避免网络饱和导致的服务降级。
count: 1984 src: ( 3 ,0, 3) dst: ( 0 ,2, 0) head:( 0 ,2, 3, R1) tail:( 0 ,2, 3)
count: 1884 src: ( 2 ,2, 3) dst: ( 0 ,1, 1) head:( 0 ,2, 3, R1) tail:( 0 ,2, 3)
count: 1859 src: ( 0 ,1, 2) dst: ( 0 ,2, 1) head:( 0 ,2, 2, R1) tail:( 0 ,2, 2)
count: 1809 src: ( 0 ,3, 3) dst: ( 1 ,1, 2) head:( 1 ,1, 3, R1) tail:( 1 ,1, 3)
count: 1759 src: ( 1 ,1, 0) dst: ( 1 ,0, 3) head:( 1 ,0, 0, R1) tail:( 1 ,0, 0)
count: 1734 src: ( 3 ,2, 3) dst: ( 2 ,0, 2) head:( 2 ,1, 3, R1) tail:( 2 ,1, 3)
count: 1709 src: ( 3 ,0, 2) dst: ( 3 ,3, 2) head:( 3 ,1, 2, R1) tail:( 3 ,1, 2)
count: 1659 src: ( 3 ,3, 1) dst: ( 0 ,2, 3) head:( 0 ,2, 1, R1) tail:( 0 ,2, 1)
count: 1609 src: ( 0 ,1, 2) dst: ( 3 ,0, 0) head:( 3 ,0, 2, R1) tail:( 3 ,0, 2)
count: 1559 src: ( 3 ,1, 3) dst: ( 1 ,2, 0) head:( 1 ,2, 3, R1) tail:( 1 ,2, 3)
count: 1509 src: ( 1 ,3, 0) dst: ( 2 ,1, 1) head:( 2 ,2, 0, R1) tail:( 2 ,2, 0)
count: 1459 src: ( 3 ,2, 0) dst: ( 0 ,2, 0) head:( 2 ,2, 0, R1) tail:( 2 ,2, 0)
count: 1434 src: ( 2 ,3, 2) dst: ( 3 ,0, 0) head:( 3 ,2, 2, R1) tail:( 3 ,2, 2)
count: 1409 src: ( 1 ,3, 2) dst: ( 2 ,0, 1) head:( 2 ,3, 2, R1) tail:( 2 ,3, 2)
count: 1384 src: ( 2 ,0, 2) dst: ( 2 ,1, 1) head:( 2 ,1, 2, R1) tail:( 2 ,1, 2)
count: 1359 src: ( 1 ,2, 1) dst: ( 1 ,3, 0) head:( 1 ,3, 1, R1) tail:( 1 ,3, 1)
count: 1284 src: ( 1 ,2, 2) dst: ( 0 ,3, 3) head:( 0 ,3, 2, R1) tail:( 0 ,3, 2)
count: 1259 src: ( 2 ,3, 3) dst: ( 3 ,2, 2) head:( 3 ,2, 3, R1) tail:( 3 ,2, 3)
count: 1234 src: ( 1 ,1, 3) dst: ( 3 ,1, 2) head:( 3 ,1, 3, R1) tail:( 3 ,1, 3)
count: 1184 src: ( 3 ,3, 3) dst: ( 1 ,3, 0) head:( 1 ,3, 3, R1) tail:( 1 ,3, 3)
count: 1134 src: ( 2 ,0, 0) dst: ( 0 ,1, 3) head:( 1 ,0, 0, R1) tail:( 1 ,0, 0)
count: 1109 src: ( 1 ,0, 0) dst: ( 1 ,3, 0) head:( 1 ,1, 0, R1) tail:( 1 ,1, 0)
count: 1034 src: ( 3 ,2, 1) dst: ( 3 ,3, 3) head:( 3 ,3, 1, R1) tail:( 3 ,3, 1)
count: 1978 src: ( 0 ,1, 0) dst: ( 3 ,0, 1) head:( 3 ,0, 0, R1) tail:( 3 ,0, 0)
count: 1953 src: ( 2 ,0, 3) dst: ( 3 ,1, 1) head:( 3 ,1, 3, R1) tail:( 3 ,1, 3)
count: 1928 src: ( 1 ,1, 2) dst: ( 3 ,3, 0) head:( 3 ,3, 2, R1) tail:( 3 ,3, 2)
count: 1878 src: ( 0 ,2, 1) dst: ( 1 ,1, 3) head:( 1 ,1, 1, R1) tail:( 1 ,1, 1)
count: 1853 src: ( 1 ,2, 1) dst: ( 0 ,2, 2) head:( 0 ,2, 1, R1) tail:( 0 ,2, 1)
count: 1828 src: ( 3 ,3, 3) dst: ( 2 ,0, 2) head:( 2 ,0, 3, R1) tail:( 2 ,0, 3)
count: 1803 src: ( 1 ,2, 0) dst: ( 2 ,3, 0) head:( 2 ,2, 0, R1) tail:( 2 ,2, 0)
count: 1753 src: ( 0 ,3, 0) dst: ( 2 ,1, 2) head:( 2 ,1, 0, R1) tail:( 2 ,1, 0)
count: 1728 src: ( 0 ,3, 3) dst: ( 0 ,1, 2) head:( 0 ,2, 3, R1) tail:( 0 ,2, 3)
count: 1703 src: ( 2 ,0, 2) dst: ( 0 ,3, 3) head:( 0 ,1, 2, R1) tail:( 0 ,1, 2)
count: 1653 src: ( 1 ,3, 2) dst: ( 1 ,0, 1) head:( 1 ,0, 2, R1) tail:( 1 ,0, 2)
count: 1628 src: ( 0 ,1, 1) dst: ( 2 ,1, 3) head:( 2 ,1, 1, R1) tail:( 2 ,1, 1)
count: 1603 src: ( 3 ,1, 2) dst: ( 0 ,2, 1) head:( 0 ,1, 2, R1) tail:( 0 ,1, 2)
count: 1578 src: ( 2 ,0, 0) dst: ( 0 ,2, 1) head:( 0 ,0, 0, R1) tail:( 0 ,0, 0)
count: 1528 src: ( 2 ,0, 0) dst: ( 2 ,2, 0) head:( 2 ,1, 0, R1) tail:( 2 ,1, 0)
count: 1503 src: ( 0 ,2, 2) dst: ( 2 ,2, 3) head:( 2 ,2, 2, R1) tail:( 2 ,2, 2)
count: 1478 src: ( 2 ,2, 0) dst: ( 1 ,2, 1) head:( 1 ,2, 0, R1) tail:( 1 ,2, 0)
count: 1453 src: ( 3 ,3, 0) dst: ( 1 ,0, 2) head:( 1 ,2, 0, R1) tail:( 1 ,2, 0)
count: 1428 src: ( 0 ,2, 2) dst: ( 2 ,2, 1) head:( 1 ,2, 2, R1) tail:( 1 ,2, 2)
count: 1403 src: ( 3 ,0, 1) dst: ( 1 ,2, 1) head:( 1 ,0, 1, R1) tail:( 1 ,0, 1)
count: 1378 src: ( 2 ,2, 1) dst: ( 0 ,1, 1) head:( 1 ,2, 1, R1) tail:( 1 ,2, 1)
count: 1353 src: ( 1 ,1, 0) dst: ( 3 ,0, 2) head:( 3 ,1, 0, R1) tail:( 3 ,1, 0)
count: 1303 src: ( 3 ,1, 0) dst: ( 1 ,0, 2) head:( 2 ,1, 0, R1) tail:( 2 ,1, 0)
count: 1278 src: ( 2 ,0, 3) dst: ( 1 ,0, 0) head:( 1 ,0, 3, R1) tail:( 1 ,0, 3)
count: 1228 src: ( 3 ,3, 0) dst: ( 2 ,1, 3) head:( 2 ,3, 0, R1) tail:( 2 ,3, 0)
count: 1178 src: ( 1 ,2, 2) dst: ( 0 ,3, 0) head:( 0 ,2, 2, R1) tail:( 0 ,2, 2)
count: 1053 src: ( 3 ,0, 0) dst: ( 1 ,0, 1) head:( 2 ,0, 0, R1) tail:( 2 ,0, 0)
count: 1028 src: ( 3 ,2, 2) dst: ( 2 ,3, 0) head:( 2 ,2, 2, R1) tail:( 2 ,2, 2)
count: 1972 src: ( 2 ,2, 3) dst: ( 0 ,1, 1) head:( 0 ,1, 3, R1) tail:( 0 ,1, 3)
count: 1947 src: ( 0 ,1, 0) dst: ( 2 ,3, 2) head:( 2 ,3, 0, R1) tail:( 2 ,3, 0)
count: 1922 src: ( 0 ,2, 0) dst: ( 1 ,1, 3) head:( 1 ,1, 0, R1) tail:( 1 ,1, 0)
count: 1872 src: ( 0 ,2, 2) dst: ( 0 ,1, 1) head:( 0 ,1, 2, R1) tail:( 0 ,1, 2)
count: 1847 src: ( 3 ,1, 0) dst: ( 1 ,1, 3) head:( 1 ,1, 0, R1) tail:( 1 ,1, 0)
count: 1822 src: ( 0 ,0, 0) dst: ( 1 ,2, 2) head:( 1 ,2, 0, R1) tail:( 1 ,2, 0)
count: 1772 src: ( 0 ,0, 0) dst: ( 0 ,3, 2) head:( 0 ,3, 0, R1) tail:( 0 ,3, 0)
count: 1747 src: ( 1 ,0, 3) dst: ( 0 ,3, 3) head:( 0 ,1, 3, R1) tail:( 0 ,1, 3)
count: 1722 src: ( 2 ,1, 2) dst: ( 2 ,2, 1) head:( 2 ,2, 2, R1) tail:( 2 ,2, 2)
count: 1697 src: ( 3 ,0, 0) dst: ( 0 ,1, 3) head:( 0 ,1, 0, R1) tail:( 0 ,1, 0)
count: 1647 src: ( 0 ,1, 3) dst: ( 1 ,3, 2) head:( 1 ,3, 3, R1) tail:( 1 ,3, 3)
count: 1622 src: ( 3 ,0, 2) dst: ( 1 ,1, 3) head:( 1 ,1, 2, R1) tail:( 1 ,1, 2)
count: 1597 src: ( 1 ,3, 2) dst: ( 2 ,1, 1) head:( 2 ,1, 2, R1) tail:( 2 ,1, 2)
count: 1572 src: ( 1 ,1, 2) dst: ( 2 ,2, 0) head:( 2 ,1, 2, R1) tail:( 2 ,1, 2)
count: 1547 src: ( 2 ,1, 1) dst: ( 1 ,0, 0) head:( 1 ,0, 1, R1) tail:( 1 ,0, 1)
count: 1522 src: ( 0 ,3, 2) dst: ( 1 ,2, 0) head:( 1 ,2, 2, R1) tail:( 1 ,2, 2)
count: 1497 src: ( 0 ,3, 2) dst: ( 2 ,2, 3) head:( 2 ,2, 2, R1) tail:( 2 ,2, 2)
count: 1422 src: ( 0 ,3, 0) dst: ( 3 ,1, 1) head:( 2 ,3, 0, R1) tail:( 2 ,3, 0)
count: 1397 src: ( 0 ,3, 0) dst: ( 1 ,2, 3) head:( 1 ,3, 0, R1) tail:( 1 ,3, 0)
count: 1372 src: ( 0 ,2, 1) dst: ( 1 ,0, 1) head:( 1 ,2, 1, R1) tail:( 1 ,2, 1)
count: 1347 src: ( 1 ,0, 1) dst: ( 2 ,1, 0) head:( 2 ,1, 1, R1) tail:( 2 ,1, 1)
count: 1297 src: ( 0 ,3, 3) dst: ( 3 ,0, 1) head:( 3 ,0, 3, R1) tail:( 3 ,0, 3)
count: 1247 src: ( 1 ,0, 3) dst: ( 3 ,2, 0) head:( 3 ,0, 3, R1) tail:( 3 ,0, 3)
count: 1222 src: ( 2 ,2, 2) dst: ( 2 ,3, 3) head:( 2 ,3, 2, R1) tail:( 2 ,3, 2)
count: 1197 src: ( 2 ,3, 3) dst: ( 3 ,0, 0) head:( 3 ,3, 3, R1) tail:( 3 ,3, 3)
count: 1147 src: ( 3 ,1, 0) dst: ( 3 ,2, 1) head:( 3 ,2, 0, R1) tail:( 3 ,2, 0)
count: 1122 src: ( 2 ,0, 3) dst: ( 2 ,1, 1) head:( 2 ,1, 3, R1) tail:( 2 ,1, 3)
count: 1097 src: ( 0 ,0, 1) dst: ( 3 ,2, 0) head:( 3 ,2, 1, R1) tail:( 3 ,2, 1)
count: 1072 src: ( 3 ,3, 1) dst: ( 2 ,3, 0) head:( 2 ,3, 1, R1) tail:( 2 ,3, 1)
count: 1047 src: ( 0 ,3, 3) dst: ( 3 ,1, 2) head:( 2 ,3, 3, R1) tail:( 2 ,3, 3)
count: 1941 src: ( 3 ,2, 1) dst: ( 0 ,3, 3) head:( 0 ,3, 1, R1) tail:( 0 ,3, 1)
count: 1891 src: ( 0 ,0, 1) dst: ( 1 ,1, 0) head:( 1 ,1, 1, R1) tail:( 1 ,1, 1)
count: 1866 src: ( 2 ,1, 2) dst: ( 2 ,0, 0) head:( 2 ,0, 2, R1) tail:( 2 ,0, 2)
count: 1841 src: ( 1 ,1, 2) dst: ( 0 ,0, 3) head:( 0 ,0, 2, R1) tail:( 0 ,0, 2)
count: 1816 src: ( 0 ,1, 0) dst: ( 2 ,3, 1) head:( 2 ,2, 0, R1) tail:( 2 ,2, 0)
count: 1766 src: ( 3 ,1, 1) dst: ( 0 ,1, 2) head:( 0 ,1, 1, R1) tail:( 0 ,1, 1)
count: 1741 src: ( 0 ,0, 0) dst: ( 0 ,3, 3) head:( 0 ,2, 0, R1) tail:( 0 ,2, 0)
count: 1716 src: ( 1 ,0, 2) dst: ( 3 ,2, 0) head:( 3 ,2, 2, R1) tail:( 3 ,2, 2)
count: 1691 src: ( 1 ,2, 2) dst: ( 3 ,3, 2) head:( 3 ,2, 2, R1) tail:( 3 ,2, 2)
count: 1666 src: ( 0 ,3, 2) dst: ( 3 ,1, 0) head:( 3 ,1, 2, R1) tail:( 3 ,1, 2)
count: 1641 src: ( 1 ,3, 0) dst: ( 3 ,3, 2) head:( 3 ,3, 0, R1) tail:( 3 ,3, 0)
count: 1591 src: ( 2 ,0, 1) dst: ( 0 ,3, 2) head:( 0 ,2, 1, R1) tail:( 0 ,2, 1)
count: 1566 src: ( 0 ,2, 3) dst: ( 1 ,3, 1) head:( 1 ,2, 3, R1) tail:( 1 ,2, 3)
count: 1541 src: ( 0 ,1, 3) dst: ( 3 ,3, 1) head:( 3 ,3, 3, R1) tail:( 3 ,3, 3)
count: 1516 src: ( 2 ,3, 2) dst: ( 0 ,0, 1) head:( 0 ,2, 2, R1) tail:( 0 ,2, 2)
count: 1466 src: ( 3 ,1, 3) dst: ( 2 ,2, 2) head:( 2 ,2, 3, R1) tail:( 2 ,2, 3)
count: 1441 src: ( 0 ,0, 0) dst: ( 2 ,3, 1) head:( 2 ,0, 0, R1) tail:( 2 ,0, 0)
count: 1416 src: ( 2 ,2, 2) dst: ( 1 ,2, 1) head:( 1 ,2, 2, R1) tail:( 1 ,2, 2)
count: 1366 src: ( 2 ,3, 3) dst: ( 0 ,1, 2) head:( 0 ,3, 3, R1) tail:( 0 ,3, 3)
count: 1216 src: ( 0 ,1, 2) dst: ( 3 ,3, 3) head:( 1 ,1, 2, R1) tail:( 1 ,1, 2)
count: 1191 src: ( 3 ,2, 1) dst: ( 3 ,1, 2) head:( 3 ,1, 1, R1) tail:( 3 ,1, 1)
count: 1116 src: ( 0 ,3, 2) dst: ( 3 ,0, 3) head:( 1 ,3, 2, R1) tail:( 1 ,3, 2)计算一下所有的count:
# Sum of all count values from the provided data
counts = [
1984, 1884, 1859, 1809, 1759, 1734, 1709, 1659, 1609, 1559,
1509, 1459, 1434, 1409, 1384, 1359, 1284, 1259, 1234, 1184,
1134, 1109, 1034, 1978, 1953, 1928, 1878, 1853, 1828, 1803,
1753, 1728, 1703, 1653, 1628, 1603, 1578, 1528, 1503, 1478,
1453, 1428, 1403, 1378, 1366, 1353, 1303, 1278, 1228, 1178,
1053, 1028, 1972, 1947, 1922, 1872, 1847, 1822, 1772, 1747,
1722, 1697, 1666, 1641, 1591, 1566, 1541, 1516, 1466, 1441,
1416, 1372, 1347, 1297, 1247, 1222, 1197, 1147, 1122, 1097,
1072, 1047, 1941, 1891, 1866, 1841, 1816, 1766, 1741, 1716,
1691, 1647, 1622, 1597, 1572, 1547, 1522, 1497, 1422, 1397, 1372, 1347
]
total_count = sum(counts)
total_count所有的 count 值加起来等于 157,324。
count: 在代码中,count似乎表示每个Message对象自其创建以来在网络中传输的周期数。每个消息对象有一个count属性,该属性在每次消息转发时递增,用于追踪消息从源到目的地的延迟。threshold: 这个变量设置为 80000,用于控制在模拟过程中网络中可以存在的消息的最大数量。一旦消息的总数量超过这个阈值,模拟将停止生成新的消息。这是一种防止网络过载和保持模拟管理性的措施。totalcircle: 设置为 10000,表示模拟的总周期数。这意味着模拟将在 10000 个周期后结束,除非消息的总数先达到了threshold。
这两个参数的合适值取决于您希望网络承载的负载水平以及您希望模拟运行的时间长度。这里的设置必须基于模拟目标和网络容量:
- 如果目标是测试网络在高负载下的性能(例如,考察拥塞控制和网络饱和点),则可能需要一个高的
threshold值来允许更多的消息在网络中积累。同时,totalcircle也需要足够大,以便网络达到稳态或饱和状态。 - 如果目标是观察网络的快速响应或在较低负载下的性能,则可以设置较低的
threshold和totalcircle,以便快速完成模拟并观察结果。
threshold: 如果您的网络模型是高容量和高复杂度的,或者如果您希望测试网络在接近实际负载下的表现,可以将threshold提高到 100000 或更高。这会允许更多消息同时在网络中存在,有助于测试网络在高负载情况下的行为。totalcircle: 如果模拟目的是测试在持续高负载下网络的长期性能,可以将totalcircle增加到 20000 或更多周期。这样可以更全面地观察网络在长时间运行后的稳定性和性能指标。
threshold 代表在网络中可以存在的消息的最大数量。选择合适的 threshold 值时应考虑以下因素:
- 网络规模:网络节点数越多,相应的
threshold应该更高,以便允许更多消息同时在网络中传输,这有助于更好地模拟大规模网络环境。 - 处理能力:确保模拟的计算机或服务器的处理能力可以处理设定的消息数量,以避免过载。
- 目标分析:如果重点是分析网络在高负载下的表现,
threshold应设置得相对较高,这样可以观察到网络接近或达到饱和状态时的行为。
建议根据网络的节点数 k3k^3k3 选择 threshold。例如,如果 k=4k = 4k=4,网络总节点数为 64,threshold 可以设置为接近或超过这个数的几倍,比如 5000 到 8000,以观察网络在较高负载下的性能。
totalcircle 定义了模拟的总周期数,这影响到模拟的持续时间和深度。
- 实验目的:长周期有助于观察长期的网络性能表现,包括消息在复杂网络条件下的传输特性。
- 资源限制:更多的周期意味着更高的计算需求和更长的运行时间。确保设置的周期数在可接受的运行时间内能完成。
- 测试需求:周期数应足以观察到网络在不同负载下从稳态到可能的饱和状态的转变。
如果 threshold 被设为较高值,totalcircle 也应相应增加,以允许网络状态充分发展,观察到饱和或稳定状态。例如,可以设置为 10000 到 20000,以确保网络动态得到充分的展示。
结合以上两个参数,推荐的设置可能如下:
threshold = 8000;totalcircle = 15000;
这样的设置可以平衡模拟的详尽程度和计算资源的合理使用,特别是对于研究 uniform 流量模式下的网络行为非常有用。
threshold = 8000;totalcircle = 15000;
linkrate:0.01 arrive: 1 in the network : 14
average latency: 19 nomalized accepted traffic: 0.000666667
linkrate:0.06 arrive: 9 in the network : 81
average latency: 18.2222 nomalized accepted traffic: 0.006
linkrate:0.11 arrive: 24 in the network : 141
average latency: 18.3333 nomalized accepted traffic: 0.016
linkrate:0.16 arrive: 29 in the network : 211
average latency: 18.4138 nomalized accepted traffic: 0.0193333
linkrate:0.21 arrive: 29 in the network : 287
average latency: 19.2069 nomalized accepted traffic: 0.0192722
Saturation point, drain.......
in the network: 139
buffer left ---> x-neg: 28, x-pos: 33, y-neg: 29, y-pos: 27, z-neg: 64, z-pos: 64
max:0.0193333threshold = 10000;totalcircle = 17000;
linkrate:0.01 arrive: 1 in the network : 16
average latency: 19 nomalized accepted traffic: 0.000588235
linkrate:0.06 arrive: 12 in the network : 90
average latency: 18.0833 nomalized accepted traffic: 0.00705882
linkrate:0.11 arrive: 21 in the network : 166
average latency: 18.4286 nomalized accepted traffic: 0.0123529
linkrate:0.16 arrive: 26 in the network : 246
average latency: 18.2692 nomalized accepted traffic: 0.0152941
linkrate:0.21 arrive: 28 in the network : 330
average latency: 18.5714 nomalized accepted traffic: 0.0164246
linkrate:0.26 arrive: 26 in the network : 417
average latency: 17.8462 nomalized accepted traffic: 0.0152596
Saturation point, drain.......
in the network: 147
buffer left ---> x-neg: 23, x-pos: 24, y-neg: 32, y-pos: 30, z-neg: 64, z-pos: 64
max:0.0164246前两次对比:
threshold的影响:
- 更高的
threshold(80000)允许网络处理更多的消息而不达到饱和状态,这可能导致in the network的值较低,因为网络能够在不饱和的状态下持续处理消息。- 较低的
threshold(8000)导致网络更快达到饱和,因此在较低的linkrate时就已经显示出高in the network的数量。这表明网络中有大量消息未能及时处理,导致网络拥堵。totalcircle的影响:
- 较短的周期数(10000)可能没有足够的时间让消息流穿越网络,导致了较高的
average latency和较低的normalized accepted traffic。- 较长的周期数(15000)提供了更多时间来处理消息,可能导致更多消息成功到达其目的地,表现为更高的
arrive值和更低的平均延迟。
- 消息到达数(
arrive):
- 在
threshold = 80000; totalcircle = 10000;时,到达数较低,表明网络较早达到饱和。- 在
threshold = 8000; totalcircle = 15000;时,到达数更高,显示出在增加周期数的情况下,更多的消息得到处理。- 网络中的消息数(
in the network):
- 较低的
threshold导致更高的in the network值,表明消息在网络中堆积。- 平均延迟(
average latency):
- 更长的
totalcircle有助于降低平均延迟,因为消息有更多的时间被处理。- 归一化接受流量(
normalized accepted traffic):
- 较高的归一化接受流量在较高的
threshold设置下出现,表明网络在处理更多消息方面更为有效。
- 调整
threshold和totalcircle:这两个参数对网络性能的影响显著。threshold较高可以减轻网络在高流量下的压力,而totalcircle的增加则有助于提高消息处理的效率和降低平均延迟。- 网络设计建议:根据实际需求调整这两个参数。如果网络需要处理大量数据且对延迟敏感,建议提高
threshold和totalcircle以优化性能。
三次的对比:
-
原始参数
:
threshold = 80000;totalcircle = 10000;
-
第一次调整
:
threshold = 8000;totalcircle = 15000;
-
第二次调整
:
threshold = 10000;totalcircle = 17000;
- 消息到达率(
arrive):- 在原始参数下,消息到达率较低,随着
threshold的降低,到达率有所增加。这可能是因为降低threshold后,系统更快地达到饱和,导致更多消息在较短时间内被处理。 - 在第二次调整后,到达率与第一次调整相近,显示出一定的稳定性。
- 在原始参数下,消息到达率较低,随着
- 在网络中的消息数量(
in the network):- 在网络中的消息数量在调整后显著增加,这表明较低的
threshold和较高的totalcircle允许更多的消息在网络中累积,反映出网络的处理能力在逐渐增加。
- 在网络中的消息数量在调整后显著增加,这表明较低的
- 平均延迟(
average latency):- 所有情况下的平均延迟都相对稳定,说明即使网络负载增加,平均延迟并没有显著变化,这可能是由于有效的路由算法和缓冲管理机制。
- 归一化接受交通量(
nomalized accepted traffic):- 归一化接受交通量在逐渐提高,显示网络在更高负载下仍能有效处理消息。特别是在第二次调整后,尽管
threshold和totalcircle的提高使得网络可以容纳更多消息,归一化交通量仍表现出稳定增长。
- 归一化接受交通量在逐渐提高,显示网络在更高负载下仍能有效处理消息。特别是在第二次调整后,尽管
通过调整 threshold 和 totalcircle,我们可以看到网络处理能力的提升和延迟的相对稳定。这表明通过合理设置这两个参数,可以在不牺牲延迟的前提下增加网络的吞吐量。调整参数对网络性能有直接的影响,特别是在高负载情况下,如何平衡消息到达率与系统延迟成为关键:
- 提高
threshold可以允许更多消息在网络中存在,这有助于提高系统的利用率,但同时也可能引起拥堵,尤其是在节点或链路资源有限的情况下。 - 增加
totalcircle提供了更长的时间窗口来处理消息,这有助于处理更多的累积消息,但也意味着在达到饱和点前,系统需要运行更长时间。 - 结果显示,随着
linkrate的增加,网络能够在饱和前处理更多的消息,但随后迅速达到饱和点。饱和点后,网络中的消息数量显著增多,表明进一步增加linkrate已无法有效提升吞吐量,反而可能导致网络性能下降。
- 对于实验设置而言,适当的
threshold和totalcircle设置是实现高效网络运行的关键。对于不同的网络配置和预期的流量模式,应根据实际需求调整这些参数。 - 在实际应用中,应继续观察不同参数设置下的网络性能,特别是在不同的流量模式和网络负载条件下,以找到最佳的参数平衡点。
- 考虑到实验结果,建议在后续实验中进一步增加
threshold和totalcircle的值,观察在更高负载和更长周期下网络的表现,以及是否可以进一步推迟饱和点的出现,从而提高网络的整体性能。
在 C++ 中,assert() 函数是用来进行条件测试的,确保程序中某些假设为真,是一个宏,定义在 <assert.h>(或在 C++ 中通常是 <cassert>)标准库中。
如果 assert() 中的条件为真(非零),则程序继续执行;如果条件为假(零),assert() 会打印一个错误消息到标准错误输出,并终止程序执行。
head = new Q2DTorusNode[t]; // 创建节点数组 assert(head); // 断言,确保节点数组创建成功
head应该是一个指向动态分配的Q2DTorusNode数组的指针。- 这条
assert()语句是用来确保内存分配成功的。如果new Q2DTorusNode[t];成功分配内存,head将不会是nullptr(空指针)。- 如果内存分配失败(可能由于内存不足等原因),
new表达式将抛出一个std::bad_alloc异常,除非使用了nothrow版本,这时head将会是nullptr。- 因此,
assert(head);确保如果head是nullptr(指示内存分配失败),程序将报告错误并立即终止。这有助于在开发过程中快速发现内存问题。
拓扑、路由和流量控制
流量控制指定当数据包从源传输到目的地时如何将网络资源(即缓冲区和链路)分配给数据包。
【NoC片上网络 On-Chip Network】第一章 NoC导论_noc片上网络集成设计-CSDN博客
对于少量核心(例如四核或八核),总线(Buses)和交叉开关(Crossbars)是主要的互连方式。然而,随着核心数量的增加,片上网络(Network-on-Chip,NoC)开始取代总线和交叉开关,成为多核芯片中普遍使用的通信架构。
集中式架构包括总线和交叉开关,它们共同特点是在芯片中通过一个中心节点来管理所有核心的数据交换。
- 总线 (Buses)
- 特点:所有的核心都连接到一个共享的通信通道。在任何给定时间,只有一个核心可以使用总线进行数据传输。
- 优点:实现简单,成本较低,延迟相对较低。
- 缺点:随着核心数量的增加,总线的带宽限制和冲突变得越来越严重,不适合大规模多核系统。
- 交叉开关 (Crossbars)
- 特点:每个核心通过一个独立的通道与交叉开关连接,交叉开关允许多个核心同时进行非阻塞的通信。
- 优点:提供高带宽和较低的延迟,支持多核心同时通信。
- 缺点:随着核心数的增加,交叉开关的复杂性、成本和功耗急剧上升,扩展性受限。
片上网络 (NoC) 代表了分布式架构,它采用网络路由器和连接这些路由器的链路来管理数据流,类似于大规模计算机网络。
- 特点:每个核心连接到一个本地路由器,路由器之间通过链路相连,形成一个网络。数据包在这些路由器之间按照特定的路由协议转发。
- 优点:
- 可扩展性:通过添加更多的路由器和链路,NoC能够支持更多核心的通信需求。
- 高带宽:支持多路径和并行数据传输,提高了数据传输的带宽。
- 灵活性:可以采用不同的网络拓扑结构,如网格、环形、树形等,以适应不同的应用需求。
- 缺点:设计和实现较为复杂,需要精心设计网络拓扑、路由算法和流控策略。
Intel和Facebook 都看好的技术:NoC神奇在哪里?_片上 (sohu.com)
在NoC出现之前,传统的片上互联方法包括Bus总线和Crossbar两种。Bus总线的互联方式即所有数据主从模块都连接在同一个互联矩阵上,当有多个模块同时需要使用总线传输数据时,则采用仲裁的方法来确定谁能使用总线,在仲裁中获得总线使用权限的设备则在完成数据读写后释放总线。ARM著名的AXI、AHB、APB等互联协议就是典型的总线型片上互联。
**除了总线互联之外,另一种方法是Crossbar互联。**总线互联同时只能有一对主从设备使用总线传输数据,因此对于需要较大带宽的架构来说不一定够用。除此之外,在一些系统架构中,一个主设备的数据往往会需要同时广播给多个从设备。在这种情况下,Crossbar就是更好的选择。Crossbar的主要特性是可以同时实现多个主从设备的数据传输,同时能实现一个主设备对多个从设备进行数据广播。然而,Crossbar的主要问题是互联线很复杂,给数字后端设计带来了较大的挑战。
与总线和Crossbar相比,**NoC则是一种可扩展性更好的设计。**NoC从计算机网络中获取了灵感,在芯片上也实现了一个类似的网络。在NoC架构中,每一个模块都连接到片上路由器,而模块传输的数据则是形成了一个个数据包,通过路由器去送达数据包的目标模块。
与片上总线和Crossbar相比,NoC的主要优势可以体现在横向和纵向两方面。**横向的优势是指当片上使用互联的模块数量增加时,NoC的复杂度并不会上升很多。**这也是符合直觉的,因为NoC使用了类似计算机网络的架构,因此可以更好地支持多个互联模块,同时可以轻松地加入更多互联模块——这和我们把一台新的电脑接入互联网而几乎不会对互联网造成影响一样。**与NoC相比,片上总线和Crossbar在互联模块数量上升时就显得有些力不从心,尤其是Crossbar的互联复杂性与互联模块的数量呈指数关系,因此一旦加入更多模组其后端物理设计就会要完全重做。**当然,NoC为了实现可扩展性,也需要付出路由器逻辑之类的额外开销。因此,在互联模块数量较少时,片上总线和Crossbar因为设计简单而更适合;而一旦片上互联模块数量上升时(如大于30个模块),NoC的优势就得到体现,这时候路由器逻辑和网络协议的开销就可以忽略不计,因此在互联模块数量较多时NoC可以实现更高的性能,同时面积却更小。
**NoC纵向的优势则来自于其物理层、传输层和接口是分开的。**拿传统的总线为例,ARM的AXI接口在不同的版本定义了不同的信号,因此在使用不同版本的AXI时候,一方面模块的接口逻辑要重写,另一方面AXI矩阵的逻辑、物理实现和接口也要重写,因此造成了IP复用和向后兼容上的麻烦。而NoC中,传输层、物理层和接口是分开的,因此用户可以在传输层方便地自定义传输规则,而无需修改模块接口,而另一方面传输层的更改对于物理层互联的影响也不大,因此不用担心修改了传输层之后对于NoC的时钟频率造成显著的影响。
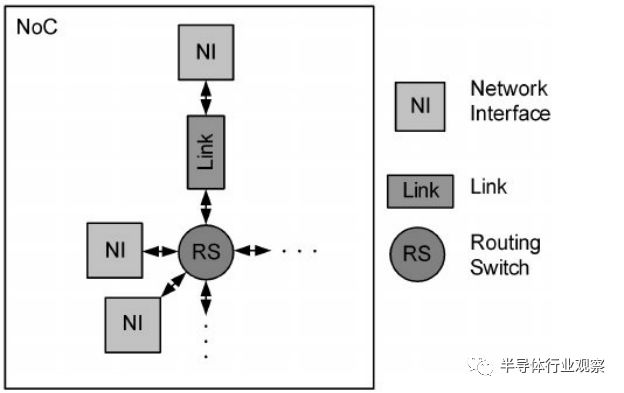
设计片上网络(NoC)涉及多个关键组成部分,这些部分共同管理并优化芯片上处理器间的数据流。
- 概念:片上网络由通道和路由器节点组成。网络拓扑确定了网络中节点与通道之间的物理布局和连接方式。
- 重要性:拓扑结构直接影响网络的性能和效率,因为它定义了消息传输的路径和网络的结构复杂性。
- 概念:对于给定的拓扑结构,路由算法确定消息通过网络到达目的地的路径。
- 功能:路由算法能够平衡网络流量(或负载),直接影响网络的吞吐量和性能。
- 概念:流量控制决定了消息在网络中传输时如何分配资源。
- 机制:流量控制机制负责为等待的数据包分配(及回收)缓冲区和通道带宽。与基于以太网的离片网络相比,大多数片上网络在设计上被认为是无丢失的。
- 组成:通用的路由器微体系结构包括输入缓冲区、路由器状态、路由逻辑、分配器和交叉开关(或开关)。
- 功能:路由器功能通常是流水线化的,以提高吞吐量。每个路由器在片上网络中的延迟是通信延迟的主要来源,因此大量研究工作致力于减少路由器流水线阶段和提高吞吐量。
- 技术:大多数片上网络原型使用传统的全摆动逻辑和重复的线路。全摆动线路在传输数字1时从0伏(接地)跳变到供应电压,传输0时回到接地。
- 优化:在长线上等间隔放置中继器(反相器或缓冲器)是一种有效的技术,可以减少延迟,使延迟与中继器的数量成线性比例,而不是与线路长度成二次方比例。****
当我们讨论不同的片上设计点和相关研究时,重要的是要考虑网络的性能和成本。
性能通常根据网络延迟或接受的流量来衡量。
- 对于粗略的性能计算,通常使用零负载延迟(zero-load latency),即当网络中没有其他数据包传输时,数据包经历网络所需要的时间。零负载延迟提供了平均消息延迟的下限。零负载延迟是通过将消息传输的平均距离(以网络跳数给出)乘以每一跳跳的延迟,来计算具体数值。
- 高饱和吞吐量表明,网络可以在所有数据包经历非常高的延迟之前,接受大量流量,从而维持更高的带宽。下图展示了片上网络的延迟和吞吐量的关系曲线,标注了零负载延迟和饱和吞吐量。

【NoC片上网络 On-Chip Network】第二章 NoC系统架构接口_noc 广播-CSDN博客
我们将探讨片上网络构成关键骨干的三种主要计算机系统类型:高端服务器和嵌入式设备中的共享内存芯片多处理器 (Chip Multiprocessor, CMP),基于消息传递接口(Message Passing Interface, MPI)技术的多处理器系统和应用于移动消费市场的多处理器片上系统(MPSoC)。
【NoC片上网络 On-Chip Network】第三章 拓扑_蝶形网络的节点度是多少-CSDN博客
- 片上网络的拓扑确定了网络中节点和通道之间的物理布局和连接。拓扑对于网络的整体成本效率有重要影响。拓扑决定了一条消息的跳数以及每跳经过的互连线的物理距离。经过路由器和链路都会有一定的延迟和功耗。此外拓扑也决定了节点之间可用路径的总数。
- 拓扑实现的难易程度取决于两个因素:1)每个节点上的链路数量(节点度)和在芯片上布局拓扑的难易程度(所需的导线长度和金属布线层数)
- 总线是最简单的拓扑,但是其带宽受限,可扩展性受限。
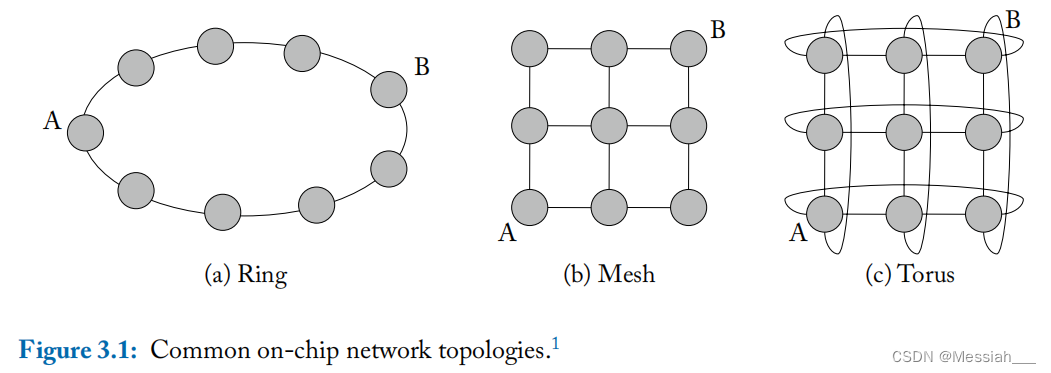
- 度 degree
- 度表示每个节点拥有的链路数量。ring结构中每个节点有2个链路,度为2;torus中每个节点与四个相邻的节点间都存在链路,故度为4;而mesh结构中不同位置节点的度是不同的。
- 度是一个有效衡量网络开销的指标,度越大,节点路由器需要的端口越多,相应的路由器实现的复杂度和面积功耗都会增大。
- 我们把每个路由器的端口数成为路由器基数(router radix)
- 对分带宽 bisection bandwidth
- 对分带宽是指将网络划分为两个相同的部分后,两部分之间的通信带宽。例如穿过ring的对分线的链路数量为2,则对分带宽为2;mesh为3;torus为6。
- 对分带宽可以有效的反映特定网络在最坏工作情况下的性能,因为对分带宽限制了可以从系统一端到另一端的总数据量。 **同时也表示了实现片上网络所必需的全局连线数量,也可以衡量网络开销。**但片上网络的连线资源丰富,对分带宽在连线方面的评价不是很全面。
- 网络直径 diameter
- 网络直径是指拓扑中任意两个节点的最短路径中的跳数最大值。例如ring为4,mesh为4,torus为2。在没有链路竞争的情况下,网络直径可认为是衡量拓扑中最大延迟的指标。
-
跳数 hop count
- 跳数是指从一个节点到另一个节点需要跳的次数。除了最大跳数,平均跳数也可以很好的反映网络延迟
- 当三种拓扑具有相同数量的节点时,且网络流量随机均匀,ring的跳数比mesh和torus都要多。例如如果采用最短路径路由,ring和mesh的最大跳数都是4,torus是2;而平均跳数torus最小,mesh其次,ring最大。
-
最大通道负载 maximum channel load
- 通道负载是和带宽相比得到的比例,例如当通道负载为2时,意味着该通道是注入带宽的2倍,**即如果每个节点每个周期将1个flit注入网络,则会出现2个flit在同一周期内都需要穿过该通道。**如果该通道每个时钟周期只能处理一个,那么这条通道即是瓶颈,限制注入带宽为之前的一半。因此最大通道负载越大,网络最大注入带宽越小。
- 最大注入带宽 = 1/最大通道负载
通道负载描述了网络中某一特定通道上的数据流量相对于该通道设计带宽的比例。如果通道负载大于1,这意味着该通道上的流量已经超过了它的设计容量,可能导致数据拥堵和增加的延迟。例如,通道负载为2表示该通道的流量是其设计带宽的两倍,这通常会在网络中形成瓶颈,影响整体性能。
注入带宽决定通道负载:网络中每个节点的注入带宽决定了进入网络的数据量。如果多个节点同时向同一通道注入数据,而这些数据的总量超过了通道的设计带宽,通道负载就会增加。因此,节点的注入带宽总和和通道的设计带宽必须相匹配,以避免产生高通道负载和网络拥堵。
通道负载影响注入策略:在设计网络或调整网络设置时,了解通道的最大负载可以帮助决定合理的注入带宽。如果某个通道经常出现高负载,可能需要减少该通道的注入带宽或优化路由策略,以平衡网络负载并提高效率。
注入带宽指的是单个网络节点(如处理器、核心或其他计算单元)可以向网络中注入数据的最大速率。这通常以每秒传输的数据量(比如位/秒、字节/秒)或者在网络通信中以每周期能注入的最小数据单元数量(如flits/周期)来衡量。
- 作用和重要性:注入带宽是衡量单个节点能够有效利用网络资源的指标。对于高性能计算系统而言,足够的注入带宽意味着数据可以迅速从生成点传输到需要处理的位置,减少了等待时间和增加了处理效率。
- **注入带宽的概念关键在于它定义了单个节点使用网络资源的能力上限。**在多核处理器或计算网络中,每个节点的注入带宽必须得到合理的配置和管理,以确保数据能高效流动,同时避免过载导致的网络拥堵和性能下降。
对分带宽是一个网络拓扑属性,它衡量的是将网络通过一种方式划分为两个等部分时,这两部分之间的最小带宽。通常情况下,这种划分尝试使两部分具有相等数量的节点,并测量连接这两部分的最小总带宽。
- 作用和重要性:对分带宽是衡量网络整体性能的关键指标之一,尤其是在需要大规模数据并行处理的应用中。高的对分带宽意味着网络能够在其两个子部分之间支持高速数据传输,这对于保持系统性能和防止网络成为性能瓶颈至关重要。
- 平衡性:在理想的网络设计中,单个节点的注入带宽应当与网络的对分带宽相匹配。如果每个节点的注入带宽总和远大于对分带宽,网络可能会在数据密集的操作中遭遇瓶颈,导致性能下降。
- 扩展性和性能:随着网络节点数的增加,理想情况下对分带宽应该相应增加,以支持更高的总体注入带宽,确保网络可以无阻碍地处理大量数据流。
flit(flow control digit 的缩写)是数据传输中的基本单位。**Flit 是组成数据包的最小元素,它是路由和流量控制过程中处理的基本单位。**Flit 的概念在设计高效网络通信结构时尤为重要,特别是在处理高性能计算和并行处理系统的通信需求时。
在多数片上网络中,**一个较大的数据结构(如消息或数据包)被分割成多个更小的单位进行传输,这些小单位就是flits。**Flit 的大小通常固定,并与网络的路由器设计密切相关。数据包可以分为以下几种类型的flit:
- 头部flit(Header Flit):
- 它包含了路由和控制信息,如目标地址和数据包类型。头部flit对于设定数据包在网络中的路径至关重要。
- 有效载荷flit(Payload Flit):
- 这些flit携带实际的数据内容。在头部flit后,一个或多个有效载荷flit包含了消息的主体数据。
- 尾部flit(Tail Flit):
- 这标志着数据包的结束。尾部flit有助于管理数据流和维持网络的完整性。
- 高效的数据处理:通过将大的数据包分解为flits,网络可以在多个并行通道上同时传输多个flit,从而提高数据传输的效率和速度。
- 简化的路由和流量控制:使用flit作为传输单位简化了路由器的设计,因为每个flit的处理方式相同,这使得路由器可以使用统一的方式来处理流入的flit。
- 降低延迟:flit级的流量控制允许更细粒度的网络资源管理,如缓冲区分配和链路使用,从而降低通信延迟。
-
路径多样性 path diversity
- 给定源节点和目标节点的前提下,如果这对节点在某个拓扑中拥有n条(多条)最短路径,而另一个拓扑中只用一条,则认为前者拥有更大的路径多样性。
- 路径多样性使路由算法在处理负载均衡问题是时具有更大的灵活性,从而减小通道负载,提高网络吞吐量。路径多样性还拥有一定的容错能力,能够使数据包绕开网络故障的潜力。
- 图中ring结构只有一条最短路径,而mesh有6条。
- **直连拓扑指的是每个终端节点都配备一个路由器的网络拓扑,使得所有的节点都是流量的产生和汇入端,又是流量的中转站。**大部分片上网络都采取了直连网络,因为将路由器和终端放在一起考虑适合芯片这种存在电路面积限制的场景。
- 直连拓扑可以描述为 k-ary n-cube,k是每个维度上的节点数,n是维度数。例如4x4的mesh/torus可以描述为4-ary 2-cube。节点总数可以描述为k^n。多大多数的片上网络使用2D mesh拓扑。
- 而对于torus结构来说(ring可以描述为k-ary 1-cube,可以归为torus类),所有的节点有相同的节点度,且边缘对称,可以更好地平衡各通道的流量,而mesh对中心通道的负载要求比边缘通道要高。
**非直连拓扑是指所有的终端节点通过一个或多个中间交换节点(switch node)相连的网络拓扑。**与直连拓扑不同,终端节点和交换节点是分离的,终端节点只是源或者目的地,中间交换节点只是中转站。
- Crossbars
- 最简单的非直连拓扑,通过nxm个简单的交换节点连接了n个输入和m个输出,非阻塞全连接
- Butterflies
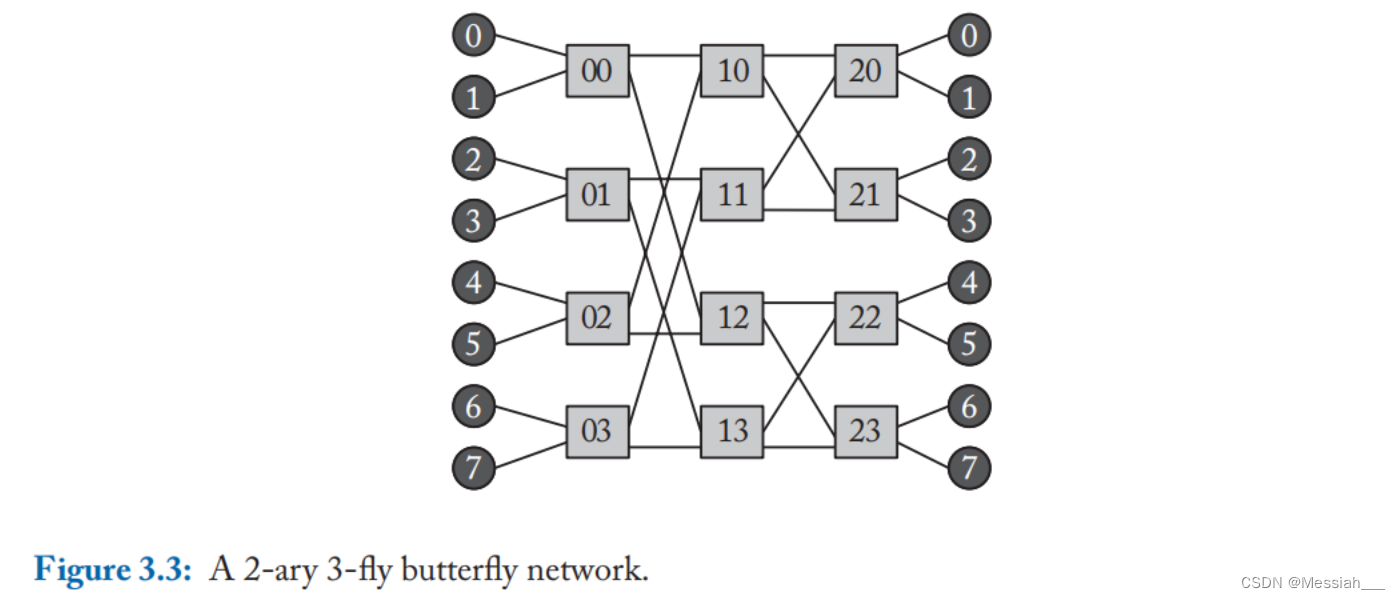
- 蝶形网络可以描述为k-ary n-fly。网络具有k^n 个终端节点,具有n级交换节点,每级含k^(n-1)个kxk的交换节点。即k是交换节点的出入度,n是交换节点的级数。如下图所示。
- 蝶形网络的中间交换节点度为2k,跳数始终为n-1。(实际中终端节点一般和边缘中间交换节点集成,即0和1与00集成在一起,故总跳数为n-1)。
- 蝶形网络的最大缺点是缺失路径多样性并缺少对网络局部性的利用,使得其在非平衡流量模式下性能很差。
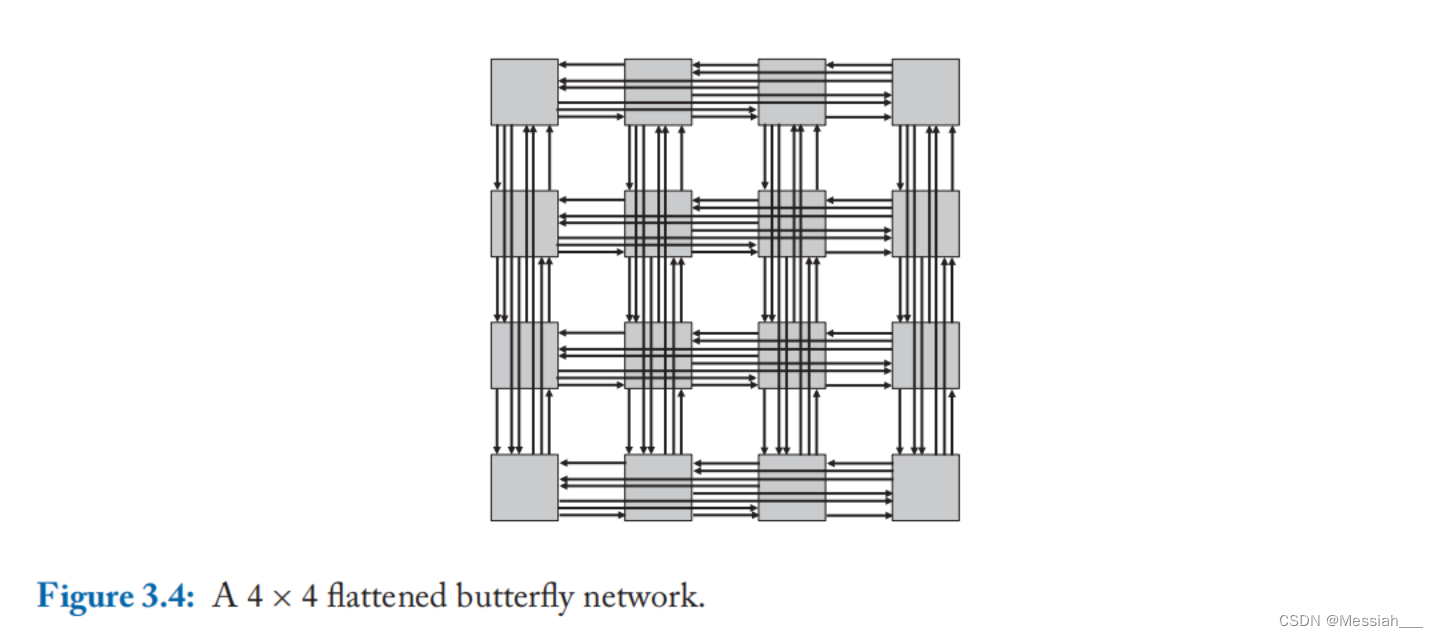
- 一个蝶形网络将各个交换节点合并之后称为扁平蝶形(flattened butterfly)网络,将同一行的中间交换节点合并为一个交换节点,从而将非直连拓扑转换为直连拓扑。由4-ary 2-fly的蝶形网络得到4-ary 2-fly的扁平蝶形网络。一个4x4的扁平蝶形网络如下图所示,其网络直径为2,但最短路径不能满足所有的节点对,故需要使用一些非最短路径。
- 蝶形网络可以描述为k-ary n-fly。网络具有k^n 个终端节点,具有n级交换节点,每级含k^(n-1)个kxk的交换节点。即k是交换节点的出入度,n是交换节点的级数。如下图所示。
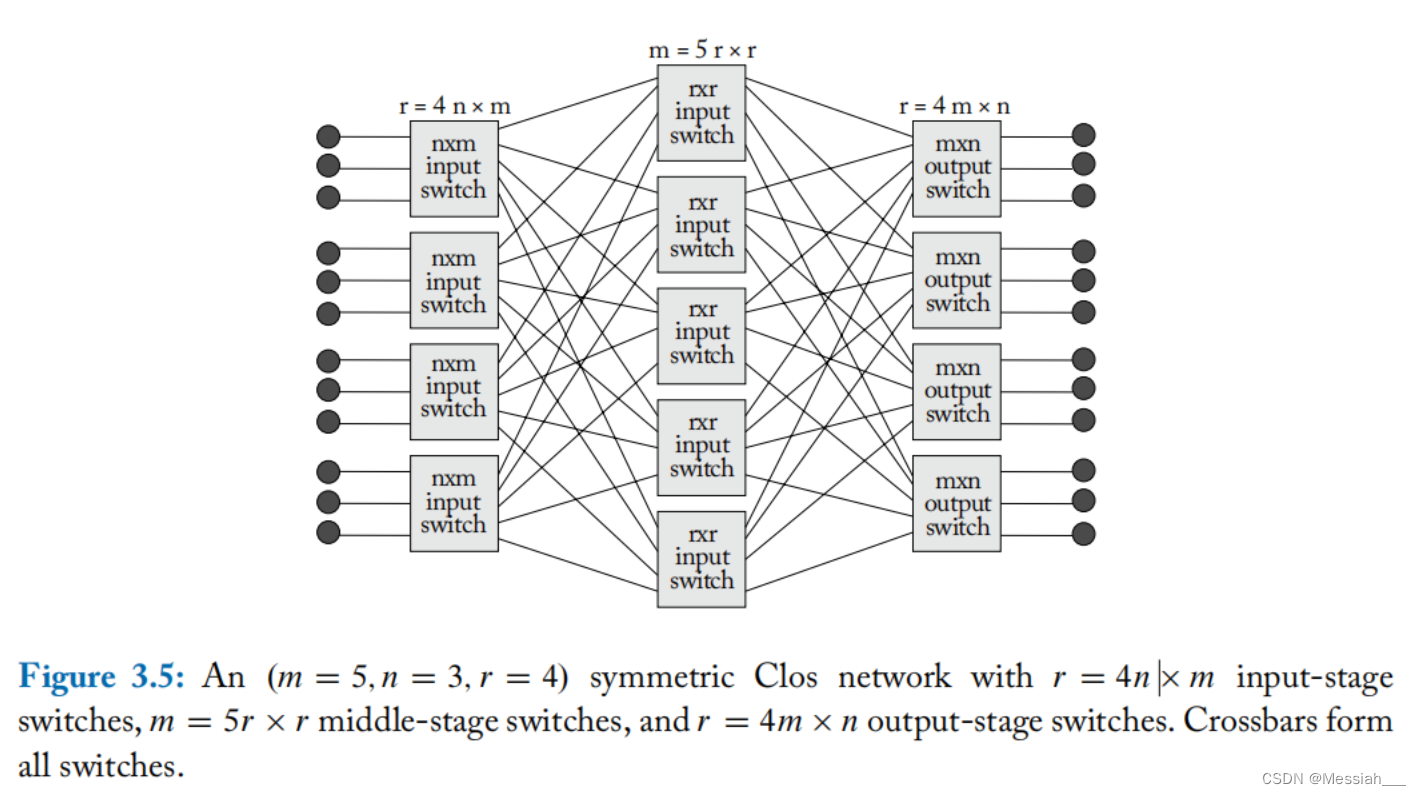
- Clos Networks
- 对称clos网络可用三元数组(m,n,r)表示的3级网络,m是中间级交换节点数,n指的是输入输出级交换节点的输入输出端口数,r表示网络第一级或最后一级的节点数。m>2n-1,对应的clos网络是严格无阻塞的,任意一个输入端口都可以连接到任何一个输出端口。
- 下图展示了一个(5,3,4)表示的对称clos网络
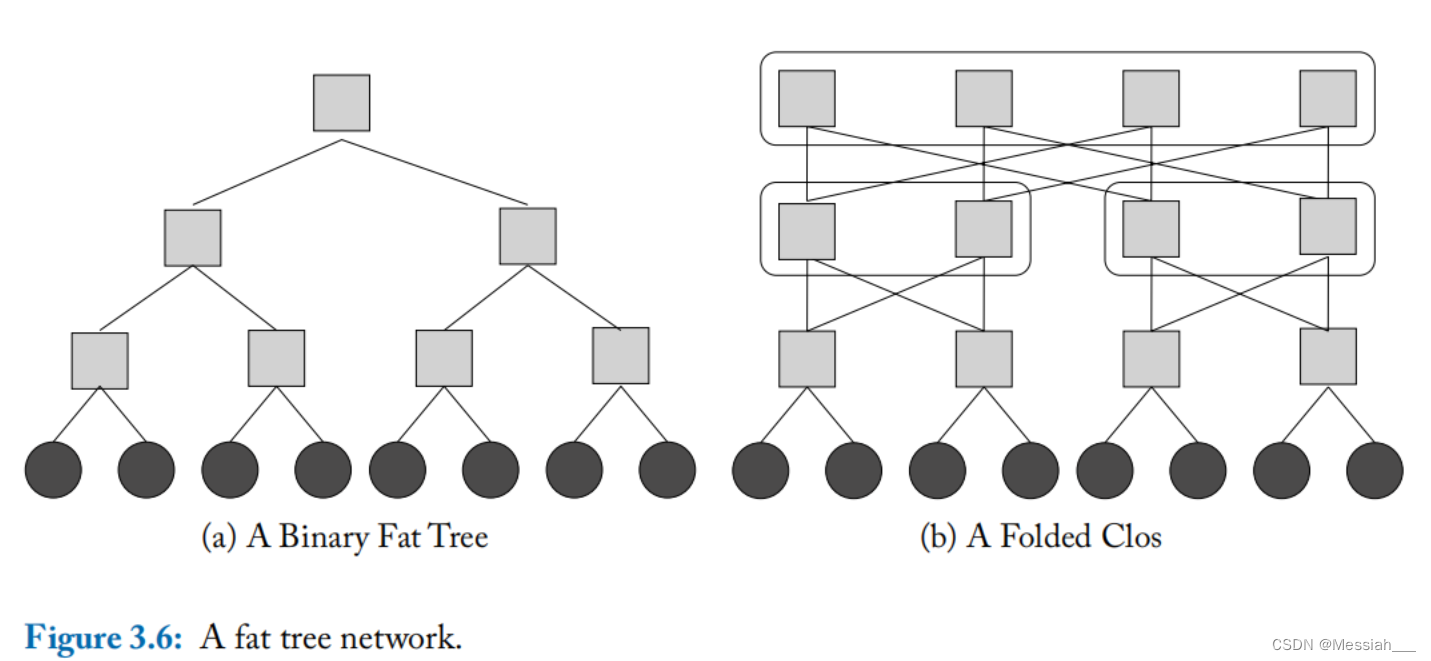
- Fat Trees
- fat tree在逻辑上是一个如图a的二叉树结构,各节点布线资源不同,距离根结点越近连线资源越多。如图b,一个fat tree网络可以由clos网络折叠而成。根节点处存在多个可以连接左右两边的节点,因此fat tree具有路径多样性。每个交换节点的逻辑上的度为4。
- 多处理器片上系统(MPSoC)可以使用多种异构IP模块,则前文所描述的规则拓扑可能不适合此类场景,一个定制的拓扑往往可以比标准拓扑更高的能效和更好的性能。
- 事实上,具体的应用可能不需要让所有的IP模块进行通信,不需要具备完全的连通性。如下图所示。
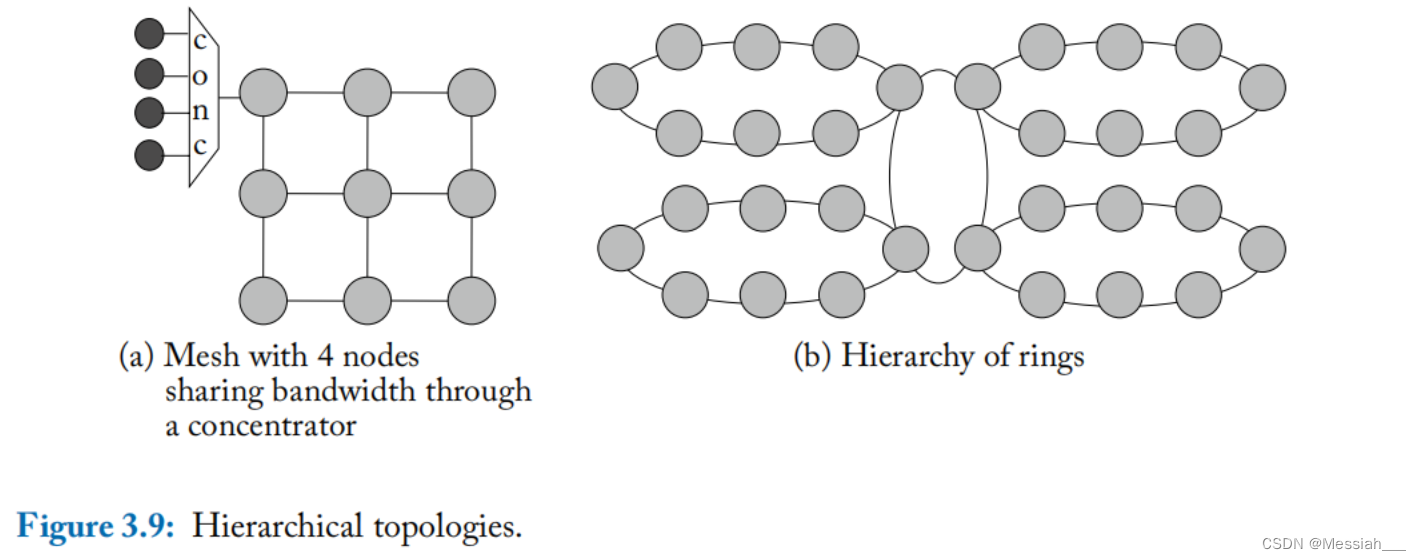
- 图a中利用集线器可以使3x3的mesh连接36个节点,而不再使用6x6的结构。图b中使用一个一级ring结构去连接4个二级的ring结构。层级拓扑的设计挑战在于如何设计对中心结构的带宽仲裁。
【NoC片上网络 On-Chip Network】第四章 Routing 路由_valiant random routing 随机路由-CSDN博客
路由算法决定数据包在网络拓扑中从起点到终点的路径的算法。路由算法的目标是在网络拓扑提供的路径之间均匀分配流量,以避免热点并最大限度地减少争用,从而改善网络延迟和吞吐量。在实现这些性能目标的同时,遵守设计约束,避免关键路径过长、面积过大。虽然路由电路本身的功耗通常较低,但特定的路由算法会直接影响到跳数,从而大大影响到消息传输的能量消耗。此外,路由算法实现的路径多样性对于提高网络故障时的弹性也影响很大。
路由算法一般分为三类:确定性路由(deterministic routing)、无关路由(oblivious routing)的和自适应路由(adaptive routing)。片上网络最常用的路由算法是最简单的维度排序路由(DOR),因为它很简单。维度顺序路由 (DOR) 维度顺序路由是确定性路由算法的一个例子,其中从节点 A 到 B 的所有确定性路由消息将始终经过相同的路径。通过 DOR,消息逐维遍历网络,到达与其目的地匹配的纵坐标,然后再切换到下一个维度。在二维拓扑(如图 4.1 中的网格)中,X-Y 维度排序路由首先沿 X 维度发送数据包,然后沿 Y 维度发送数据包。从 (0,0) 到 (2,3) 的数据包将首先沿 X 维度遍历 2 个跃点,到达 (2,0),然后沿 Y 维度遍历 3 个跃点到达目的地。
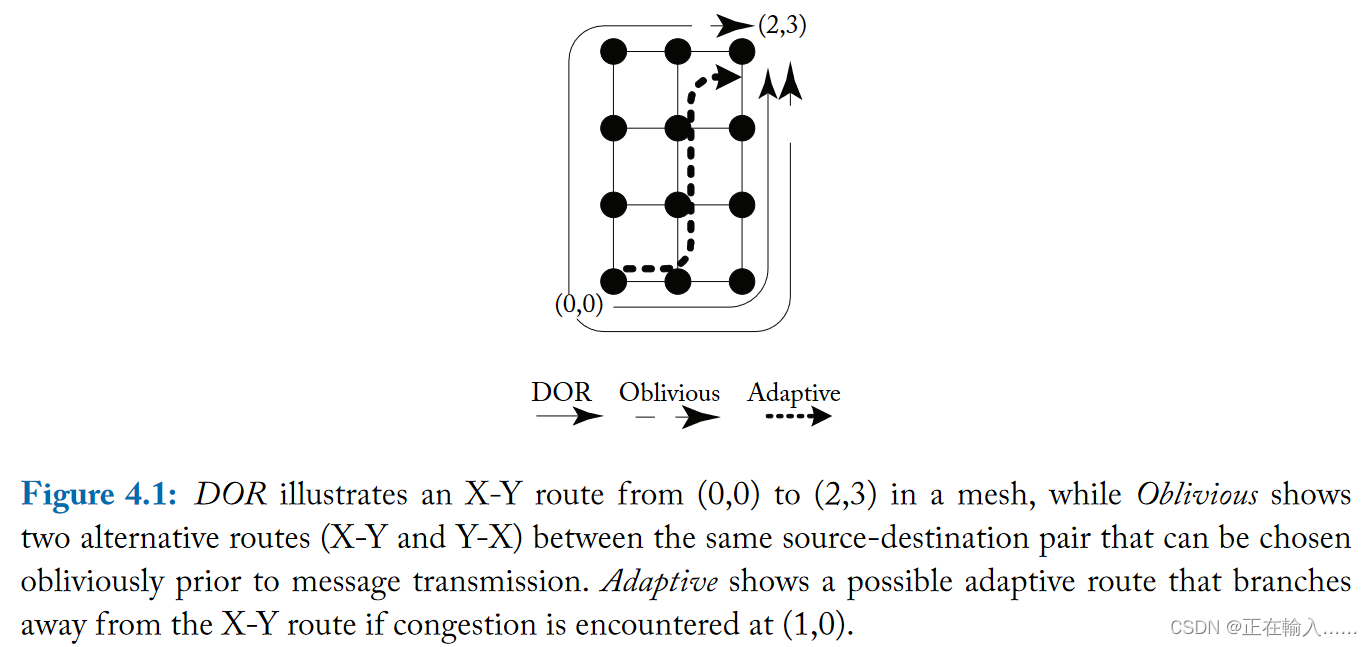
另一类路由算法是oblivious的路由算法,其中消息从 A 到 B可以有多条不同的路径选择 ,但选择路径时不考虑网络拥塞。例如,路由器可以在发送消息之前随机选择替代路径。图 4.1 显示了一个示例,其中从 (0,0) 到 (2,3) 的消息可以沿 Y-X 路由或 X-Y 路由随机发送。确定性路由是不经意路由的子集。
**更复杂的路由算法可以是自适应的,其中消息自适应路由从A到B所采取的路径取决于网络流量情况。**例如,消息最初可能遵循 X-Y 路线,并在 (1,0) 的东传出链路处看到拥塞。由于这种拥塞,消息将选择采用北向传出链路到达目的地(参见图 4.1)。
路由算法也可以分为最小路由算法和非最小路由算法。**最短路由算法仅选择源和目标之间需要最少跳数的路径。非最小路由算法允许选择可能增加非最小路由源和目的地之间的跳数的路径。**在没有拥塞的情况下,非最小路由会增加延迟,并且还会增加功耗,因为消息会遍历额外的路由器和链路。而存在拥塞时,选择避免拥塞链路的非最小路由可能会降低数据包的延迟。
简单来说,死锁是由多个数据包在传输路径上形成了**打结的环路(knotted cycle)**造成的。下图展示了一个由四个数据包的路径形成的死锁。ABCD代表路由器网络节点,折线代表数据包流动方向,从节点A南侧输入的数据包需要从节点A的东侧输出端口离开,但与此同时,另一个正在B节点西侧输入端口的数据包占据着AB之间的链路,依次类推,数据包之间的占用和依赖关系形成了一个环路,每个数据包都无法向前推进。
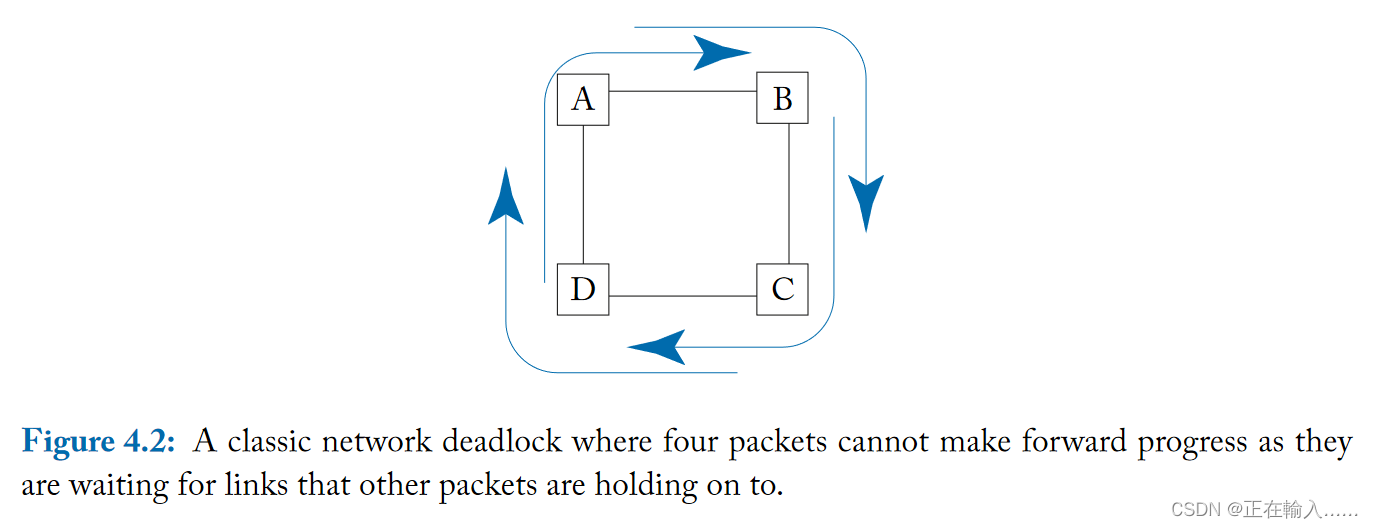
死锁可以通过两种方法解决:
- 设计路由算法避免在网络中形成环路。
- 设计数据流控制协议以避免路由器缓冲区的占用和请求构成循环依赖。
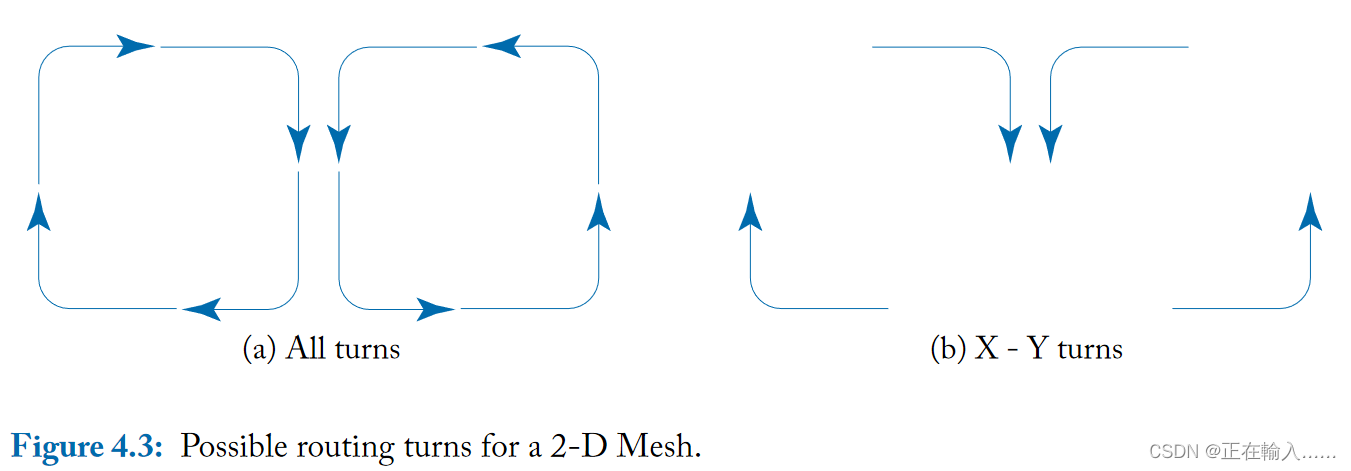
路由算法可以由允许的转向描述。下图a说明了 2D mesh网络中所有可能的转向,而图b则说明了 DOR X-Y 路由所允许的更有限的允许转向集。
**允许所有转向会导致循环资源依赖,这可能导致网络死锁。为了防止这些循环依赖性,应禁止某些转向。**图b中不存在循环。具体来说,**向东或向西传播的消息允许转向北或向南;然而,向北和向南传送的信息是不允许转向的。**图中的四个转向中的两个是不允许的,因此不可能形成循环。
或者可以**使用 Y-X 路由,其中允许向北或向南行进的消息向东或向西转向,但一旦消息向东或向西行进,则不允许进一步转向。**根据网络维度,即沿 X 或 Y 是否有更多节点,这些路由算法之一将更好地平衡均匀随机流量的负载,因为沿节点较少的维度,通道负载较高。
维度顺序路由既简单又无死锁;然而,它消除了mesh网络中的路径多样性,从而降低了吞吐量。通过维度顺序路由,每个源和目标对之间都存在一条路径。如果没有路径多样性,路由算法就无法绕过网络中的故障或避开拥塞区域。由于路由限制,维序路由在网络负载平衡方面表现不佳。
不经意路由算法选择路由路径时无需考虑网络状态。通过不使用有关网络状态的信息,这些路由算法可以保持简单。
如下图,Valiant 的随机路由算法是不经意路由算法的一个例子。Valiant 算法将数据包从源 s 路由到目的地 d,会随机选择中间目的地 d’。数据包首先从 s 路由到 d’,然后从 d’ 路由到 d。通过在路由到最终目的地之前首先路由到随机选择的中间目的地,Valiant 的算法能够对整个网络的流量进行负载平衡;随机化导致任何流量模式看起来都是均匀随机的。使用 Valiant 算法进行负载平衡是以牺牲局部性为代价的。
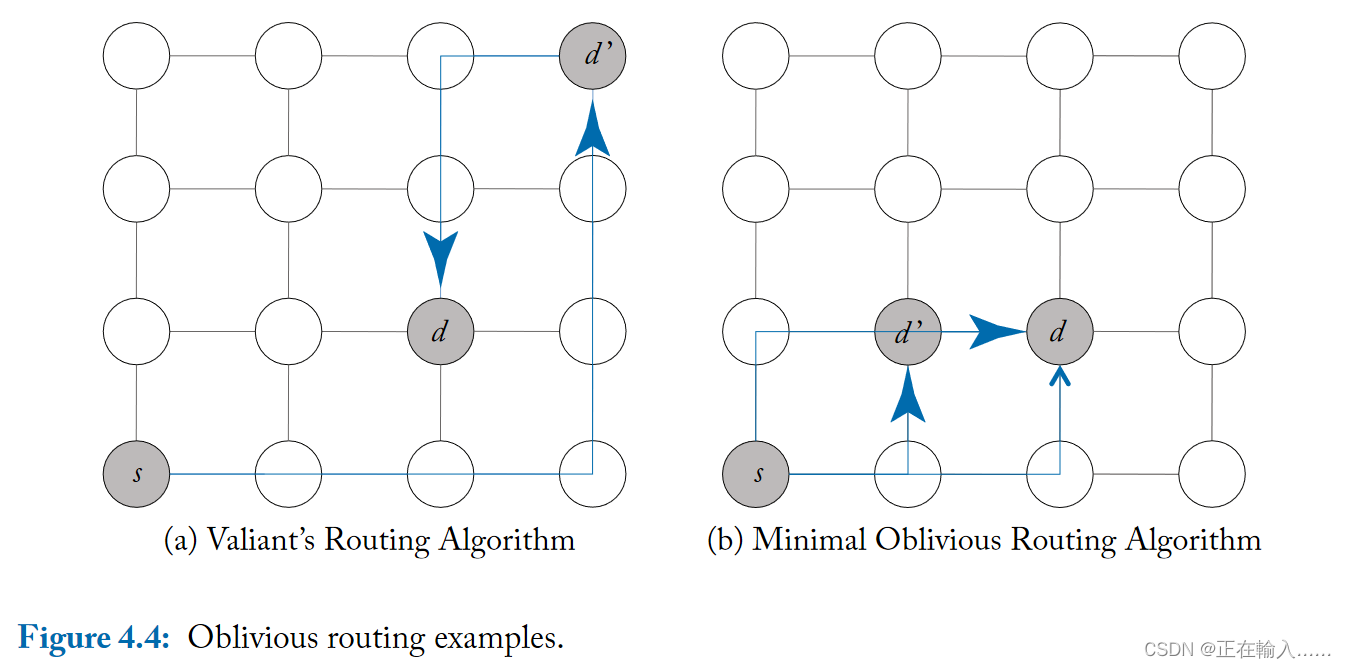
例如对于终点和起点相邻的情况下,这种路由算法会破坏原有的局部性,跳数增加,进而增加平均数据包延迟和网络中数据包消耗的平均能量。此外,Valiant的算法不仅破坏了局部性,还可以将最大通道负载加倍,使网络带宽减半。
Valiant 的路由算法可以限制为仅支持最少的路由(中间节点限制在最小象限),通过将路由选择限制为仅最短路径以保留局部性。Valiant 路由算法和最短路径 Valiant 路由算法两个阶段都可以采用DOR路由,虽然并非所有路径都考虑,但这种路由的负载会比确定性路由(直接从S-D没有中间节点)更加平衡。
**Valiant 路由算法和最短路径 Valiant 路由算法与 X-Y(或DOR) 路由结合使用时不会出现死锁。**但如果在 X-Y 或 Y-X 路由之间随机选择的无关路由算法并不是无死锁的,因为允许图 4.2 中的所有四个转弯都可能导致链路获取图中的潜在循环。
-
自适应路由更为复杂,即数据包从A到B所选取的路径动态地取决于网络流量情况。
通常可以用局部或全局的拥塞信息来完成自适应路由的决策。自适应路由经常使用局部路由器信息(如队列的占用情况或队列延迟情况)来估计拥塞和选择链路。流控制使用反压(backpressure)机制,可以使拥塞信息从拥塞地区沿着网络反向传播。
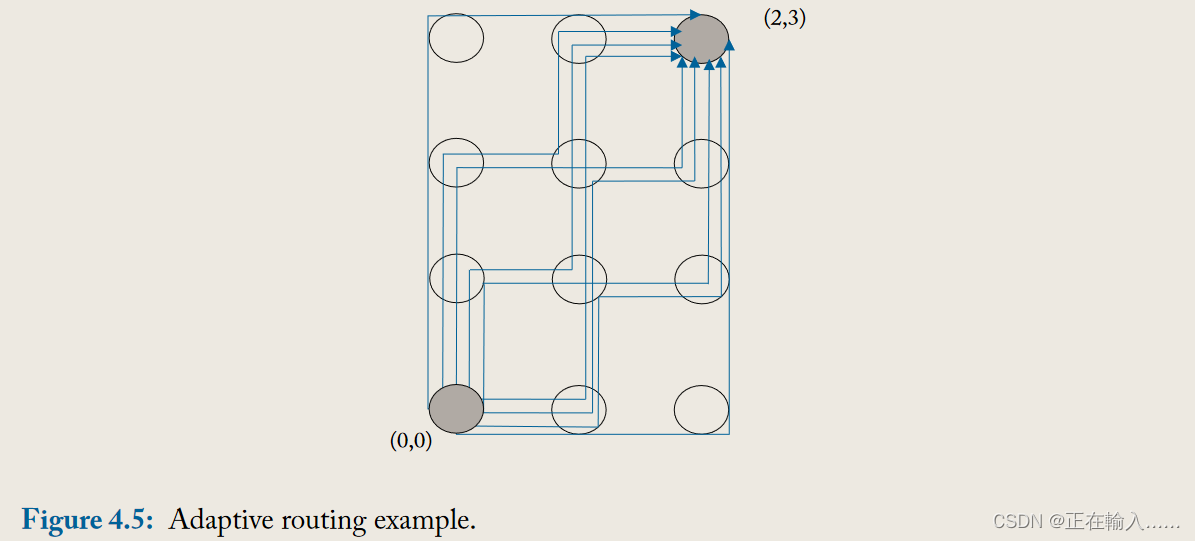
图4.5展示了一个数据包从(0,0)到(2,3)的所有可能最短路径,总共9条路径。仅利用最短路径的自适应路由算法也能够利用路径多样性来提供负载平衡和故障容错。
自适应路由选择的路径可以被限制在起点和终点的最短路径中。另一种方案是***绕远路由(misrouting),绕远路由即允许数据包沿着非有效方向(non-productive direction)路由并选择非最短路径。***(能够缩短当前节点位置和目标节点距离的方向称为有效方向(productive direction),无法缩短的方向称为非有效方向(non-productive direction))
**如果允许绕远路由,则容易产生活锁,即数据包一直被绕远路由,从而无法到达终点。需要加入保证数据包朝目标移动的机制。可以通过设定每个数据包被绕远的次数或最大阈值,并在仲裁中为已经被多次绕远路由的数据包设定高优先级来解决活锁。**虽然绕远路由会增大跳数,但可以避免拥塞,从而降低数据包的延迟。
对于完全自适应的路由算法,死锁可能会成为一个问题。例如,图 4.1 中所示的自适应路由是不经意路由的超集,并且存在潜在的死锁。平面自适应路由(planar-adaptive routing)通过将自适应性限制在一次仅两个维度上来限制处理死锁所需的资源。 **Duato 提出了流量控制技术,在加入逃逸通道的情况下允许完全路由自适应,同时确保避免死锁。**无死锁流量控制将在第 5 章中讨论。自适应路由的另一个挑战是保持一致性协议可能需要的消息间排序。如果消息必须按照源发出消息的顺序到达目的地,则自适应路由可能会出现问题。可以采用在目的地对消息重新排序的机制,或者可以在其路由中限制给定类别的消息以防止重新排序。
-
在 4.3 节介绍了转弯模型路由,并讨论了DOR/ X-Y 路由禁止所有的八个转弯中的四个来避免死锁(图 4.3)。在这里,我们解释如何更广泛地应用转向模型来导出无死锁自适应路由算法。
自适应转向模型路由(简称转向模型路由)消除了实现无死锁所需的最小转弯集,同时较大程度保留了一些路径多样性和自适应。
对于维序布线,2D Mehs 中可用的八个转弯中仅允许四个可能的转弯。转弯模型路由通过允许八个转弯中的六个来增加算法的灵活性,在顺时针转向和逆时针转向中各有一个转向被禁止。
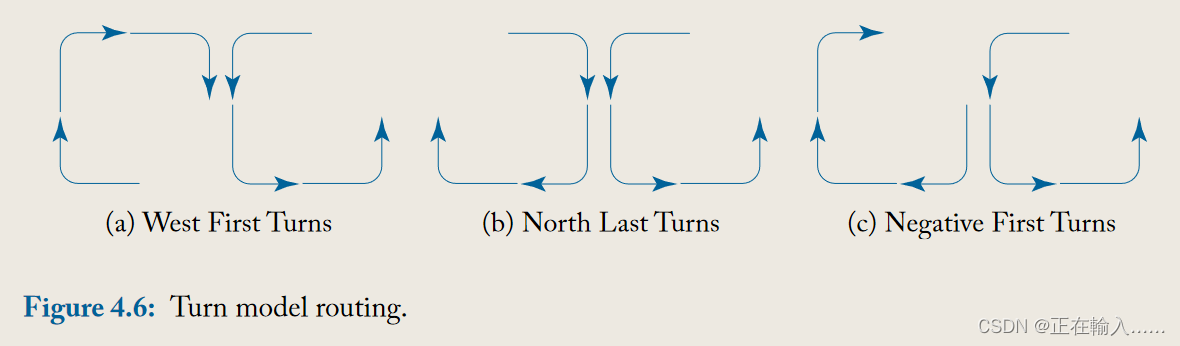
图 4.6 展示了三种可能的路由算法。从所有可能的转弯开始(如图4.6a所示),逆时针转向中消除北向西的转弯,然后顺时针中分别禁止三个不同的转向可以推导出三种不同的路由算法,可以得到图4.6所示的三种路由算法。
图4.6a所示为西优先算法(west-first);除了消除北向西转弯外,还消除了南向西转弯。换句话说,消息必须首先向西方向传播,然后再向其他方向传播。 North-Last 算法(图 4.6b)消除了从北向西和从北向东的转弯。一旦消息转向北,就不允许再转向;因此,必须最后向北转弯。 最后,图 4.6c 删除了从北到西和从东到南的转弯,以创建负优先算法(negative-first)。**消息首先沿负方向(西和南)传播,然后才被允许沿正方向(东和北)传播。**所有这三种转弯模型路由算法都是无死锁的。
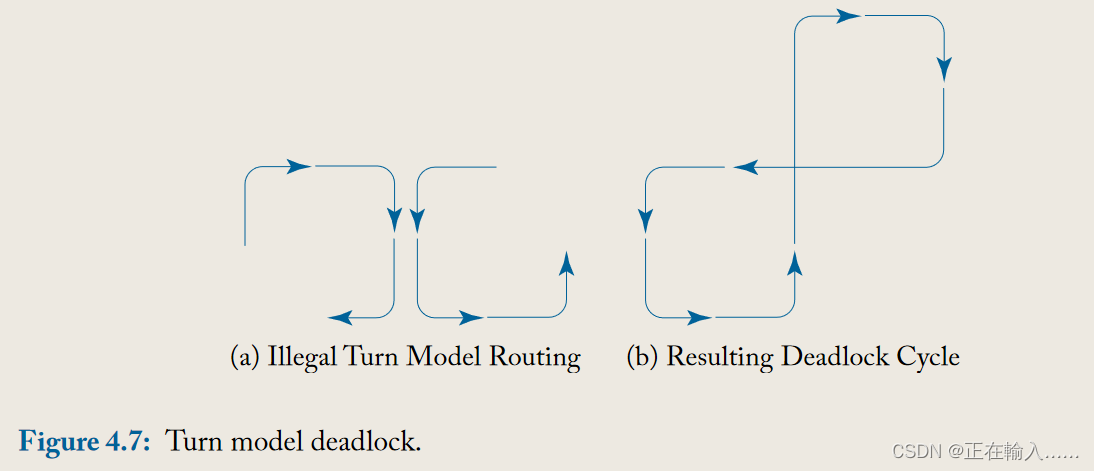
以上**三种转向模型路由算法都是无死锁的。**然而并不是在顺时针和逆时针转向中分别禁止一个方向就可以避免死锁。如图4.7所示。
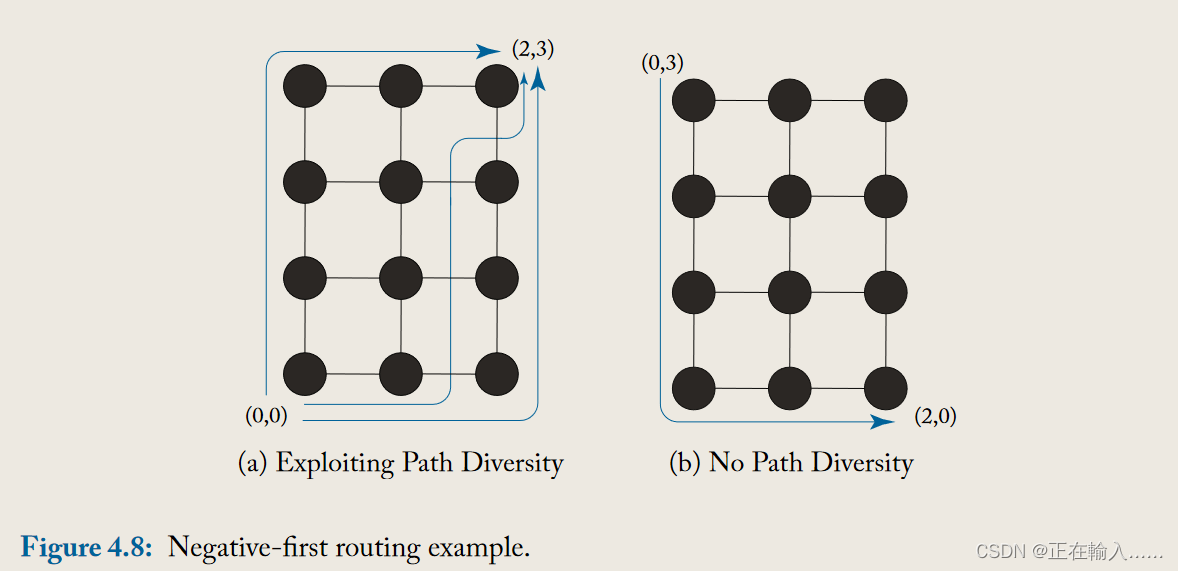
图4.8中,将负优先算法(negative-first)应用于两个不同的源-目标节点对。在a图中,允许先北后东或者先东后北,因此实际路由具有路径多样性。但是在b图中由于是负优先所以只有唯一可行路径,导致缺失路径多样性。
奇偶转向(odd-even turn)模型路由根据当前节点所在奇数列或偶数列,分别禁止一组不同的转向。例如一个数据包在偶数列中移动,先东后北和先北后西被同时禁止;在奇数列中移动,先东后南和先南后西被同时禁止。在这种限制下,奇偶转向模型路由是无死锁的,不存在180°转弯。与其他转向模型如west-first相比,奇偶转向可以提供更好的适应性。如图4.9所示。
综上,尽管转向模型路由能够提供比维序路由更好的灵活性和适应性,但仍有些限制。其他的转向模型仅保留八个转向中的六个,**而奇偶转向模型存在全部的八个转向,因此能够提供更好的适应性。**同时west-first negative-first north-last都存在只有一条路径的情况,而奇偶转向模型中不存在。
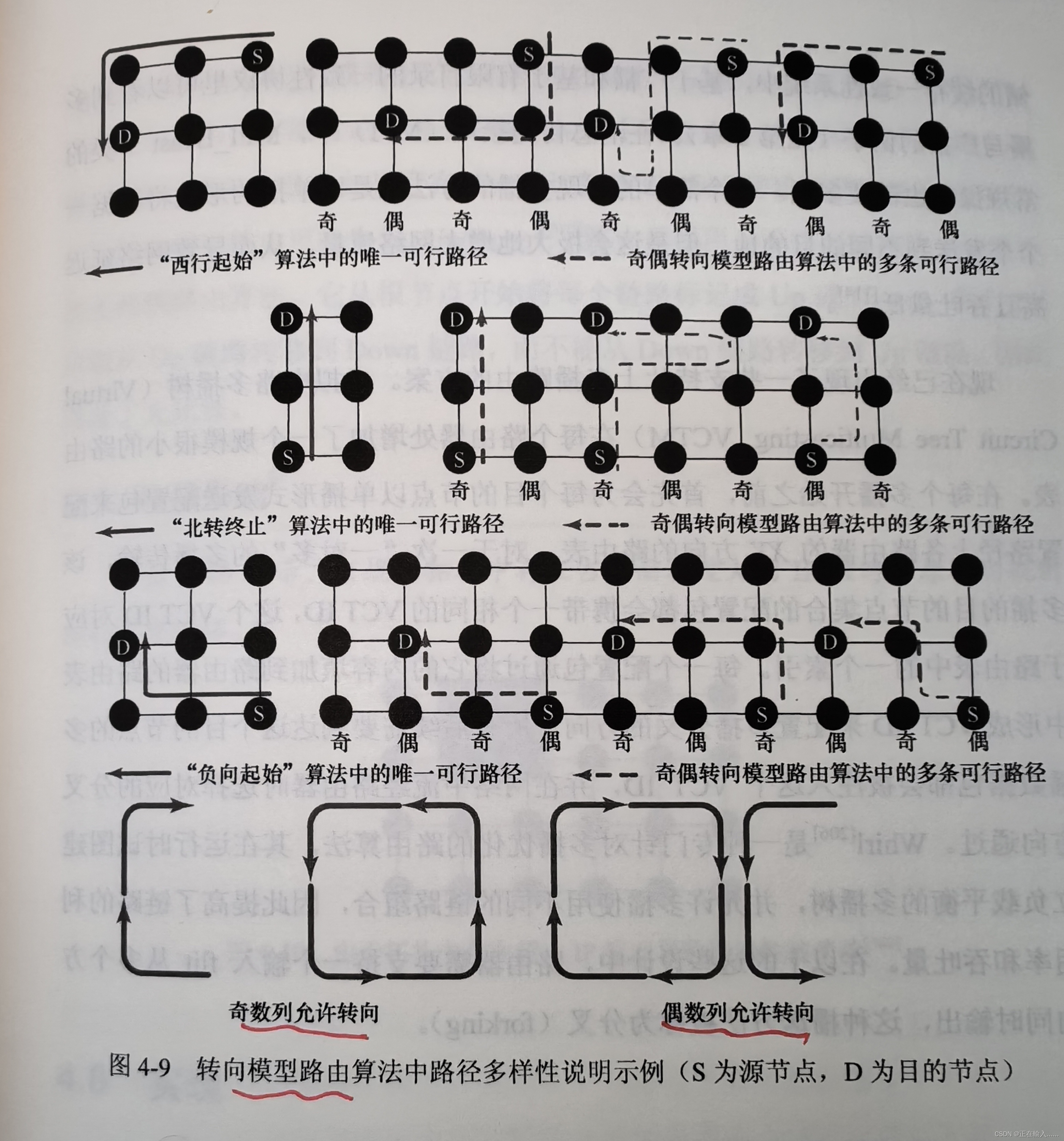
到目前为止,我们主要关注单播(即一对一)路由算法。然而,经常会出现一个核需要向多个核发送相同消息的情况。这称为广播(如果系统中的所有核心都需要发信号)或多播(如果系统中的核心子集需要发信号)。
在共享内存缓存一致性系统中,这样的例子可以在基于广播和基于有限目录的一致性协议中看到。在消息传递系统 MPI 中,这是 MPI_Bcast 等例程所必需的。多播的一种简单实现是简单地发送多个单播,每个目的地一个。但这大大增加了网络流量,导致网络延迟和吞吐量较差。
已经有一些支持片上多播路由的方案。**虚拟电路树多播(Virtual Circuit Multicasting, VCTM)在每个路由器上添加小型路由表。**在每个多播开始之前,首先会为每个目的节点以单播的形式发送配置包来配置沿 XY 路由的路由表。同一组播目的地集的所有配置包都携带相同的VCT ID,其对应于路由表中的索引。每个设置数据包将其输出端口附加到路由表中的VCT ID条目,从而设置多播流应该被分叉的方向。到该目的地的所有后续多播都被注入该VCT ID,并在网络中的路由器处适当地分叉。 Whirl是一种针对广播优化的路由算法,它试图动态创建负载平衡的广播树,允许广播使用不同的链路组合,从而提高链路利用率和吞吐量。在这两种设计中,路由器都需要支持从多个方向分叉(forking)。
不规则网络的常见路由实现依赖于源表路由或节点表路由。指定路由时必须小心,以免引发死锁。例如,如果由于网状网络中存在超大核心而删除了某些连接,则转弯模型路由可能不可行。 Up*/Down*路由是一种流行的用于不规则拓扑的无死锁路由算法,它从根节点开始将每个链路标记为“Up”或“Down”。所有的 flits 只能从 Up 链路转换到 Down 链路,而不能从相反方向转换,这保证了死锁的自由。
源路由:路由信息可以源节点处集成到数据包的报头中,这种方式叫源路由。这个机制支持确定性路由和无关路由。
基于节点查找表的路由:每个节点都维护了一张路由表记录路由条目,数据包在每一跳的路由器处获取路由信息,而不是在起点处获取所有的路由信息。这个机制支持自适应路由算法。
同时也应注意容错路由,这类算法对于软错误(瞬时故障)和硬错误(永久故障)等原因造成的故障设计路由。在检测到故障时,能够重构路由表实现无死锁路由。
【NoC片上网络 On-Chip Network】第五章 流控制_network on chip-CSDN博客
**流量控制(flow control)管理网络缓冲区和链路的分配。它决定何时以及以什么粒度将缓冲区和链路分配给消息,并且决定如何在使用网络的众多消息之间共享这些资源。**一个良好的流量控制协议通过在低负载时不对资源分配施加高开销,降低消息经历的延迟,并通过有效地跨消息共享缓冲区和链路来提高网络吞吐量。**流量控制在确定数据包访问缓冲区的速率(或完全跳过缓冲区访问)以及穿越链路的方式上发挥着关键作用,从而影响网络能源和功耗。**流量控制协议的实施复杂性包括路由器微体系结构的复杂性以及为在路由器之间传递资源信息所需的布线开销。
**当一条消息注入网络时,它首先被分割成数据包(packets),然后被划分为固定长度的flits(flow control units,流控单元),用于流量控制。**例如,一个128字节的缓存行作为一个消息发送,如果最大的数据包大小超过128字节,整个消息将被编码成一个单独的数据包。
该数据包将包含一个头flit(head flit),内含目的地址(destination address),消息体flits(body flits),以及一个尾flit(tail flit),表示数据包的结束。
**Flits还可以进一步细分为phits(physical units,物理单元),与物理通道宽度相对应。**消息到数据包再到flit的拆分如图5.1a所示。头部、主体和尾部的flits都包含部分缓存行和缓存一致性命令(cache coherence command)。
消息到数据包和数据包到 flits 的细分如图 5.1a 所示;图b所示,如果 flit 大小为 128 位即16字节,则一个64字节大小的高速缓存行数据包需要5个flit组成;图c中,一个缓存一致性命令数据包只有一个单独的flit。
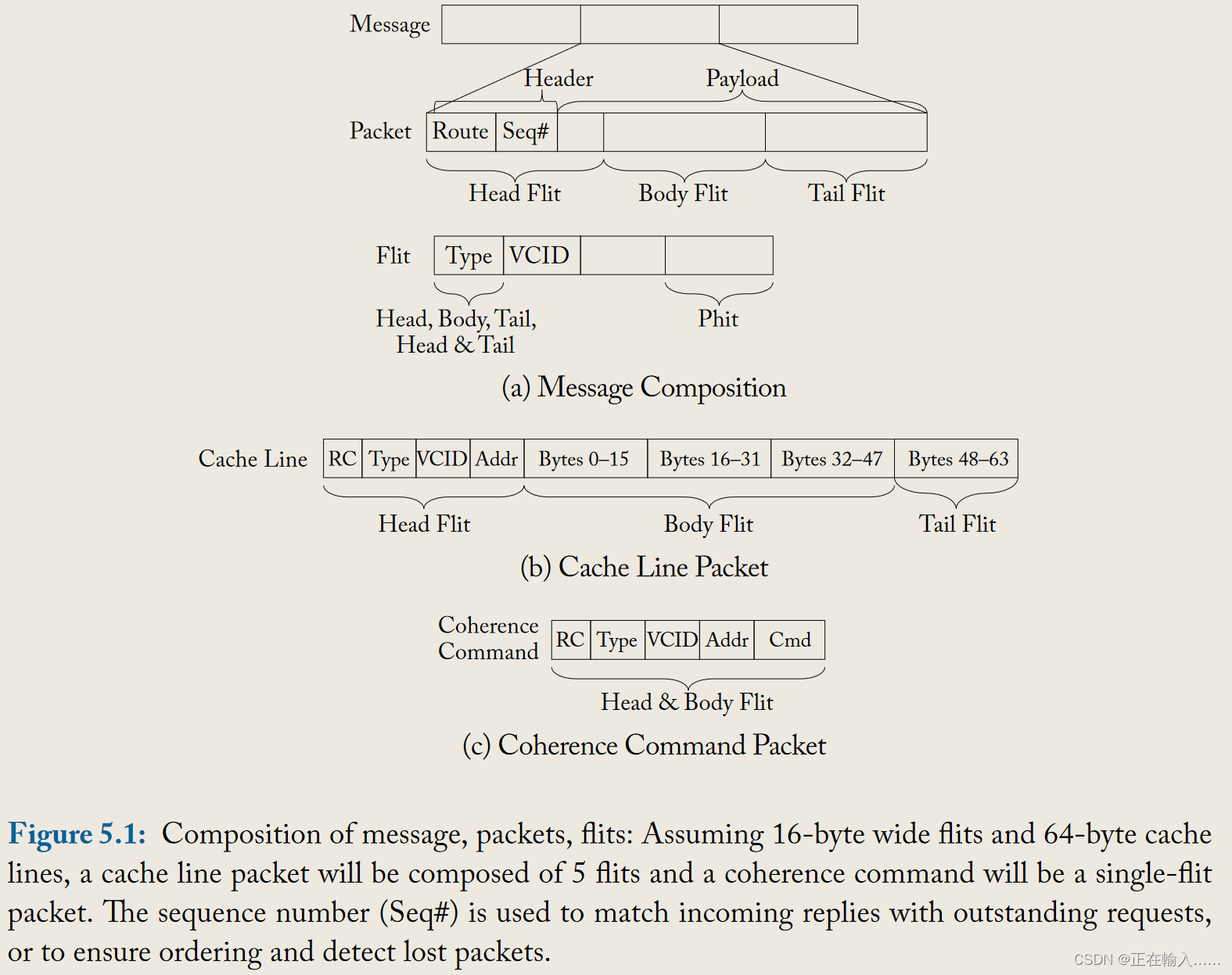
序列号Seq#用于将输入的响应和未决请求相匹配,或确保数据包的通信顺序及检测丢失的数据包。
每个flit还包含某些控制信息,如flit类型和虚拟通道号(virtual channel number)。例如,如果flit大小为128位,那么128字节的数据包将包含8个flits:1个头部,6个主体,1个尾部,忽略编码目的地所需的额外比特和流控协议(flow control protocol)需要的其他信息。**简而言之,消息是网络上的逻辑通信单元,而数据包是对网络有意义的物理单元。**数据包包含目的地信息而flit可能不包含,因此数据包中的所有flits必须走相同路线。
**由于片上网络(on-chip networks)的丰富布线资源,通道往往在片上更宽,因此消息很可能由单个数据包组成。在片外网络(off-chip networks)中,由于引脚带宽的限制,通道宽度受限,这导致flits需要被拆分成更小的块,即phits。**到目前为止,在片上网络中,flits是消息的最小划分单位,因为片上通道宽度较宽。
如图5.1所示,实际上许多消息将是单个flit的数据包。例如,一个一致性命令(coherence command)只需要携带命令和可以放入16字节宽flit的内存地址。流量控制技术按资源分配发生的粒度进行分类。我们将在接下来的章节中讨论在消息、数据包和flit粒度上操作的技术,并在最后总结每种技术的粒度。
circuit-switching电路交换是一种在消息级别(最粗粒度)运行的技术。电路交换跨多跳将资源(链路)预先分配给整个消息。
电路交换预先分配资源(links),跨越多个跳点(hops)为整个消息服务。
一个探针(probe,一小段设置消息)被发送到网络中,并预留了从源到目的地传输整个消息(或多个消息)所需的链路。一旦探针到达目的地(成功分配了必要的链路),目的地就会发送一个确认消息(acknowledgement message)回到源头。当源头收到确认消息后,它会释放消息,然后消息可以快速通过网络传输。消息传输完成后,资源被释放。
优势:在设置阶段之后,避免了每跳获取资源的延迟。对于足够大的消息,这种延迟减少可以摊销最初设置阶段的成本。除了可能的延迟优势外,电路交换也是无缓冲(bufferless)的。由于链路被预先保留,每个跳点不需要缓冲区来存放等待分配的数据包,从而节省了功耗。
缺点:虽然延迟可以被减少,但电路交换的带宽利用率较差。在设置和实际消息传输之间,链路处于空闲状态,其他寻求使用这些资源的消息被阻塞。
图5.2举例说明了电路交换流量控制是如何工作的。计算核心0到8的数据传输过程。
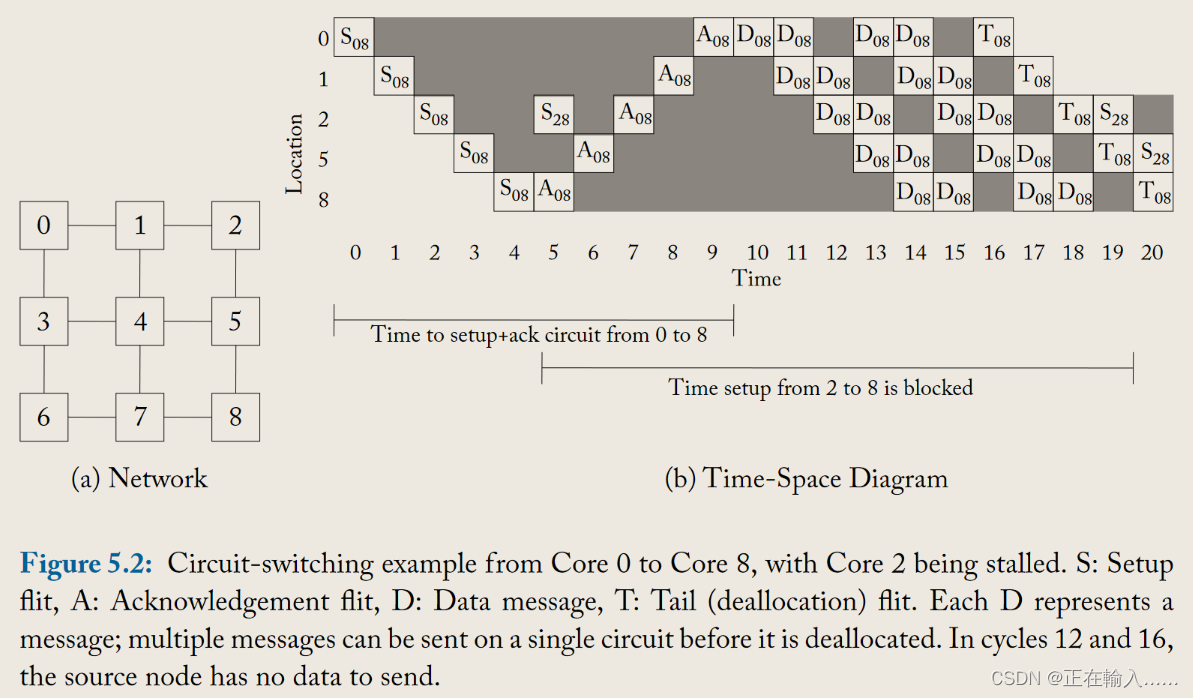
假设网络采用维度顺序X-Y路由(Dimension order X-Y routing),如图5.2a所示。随着时间从左向右推移(图5.2b),设置flit(setup flit)S从核心0构建了一个电路到核心8,通过网络选择的路线行进。在第4时间点,设置flit到达目的地并开始发送确认flit(acknowledgement flit)A回到核心0。**在第5时间点,核心2希望启动传输到核心8;然而,到达核心8所需的资源(链路)已经被核心0占用。因此,核心2的请求被延迟。**在第9时间点,确认请求被核心0收到,**数据传输D可以开始。**一旦所需数据发送完毕,核心0发送一个尾部flit(tail flit)T来释放这些资源。**在第19时间点,核心2现在可以开始获取刚刚被尾部flit释放的资源。**从这个例子中我们可以看到,链路带宽有显著的浪费。在设置时间和链路被预留但没有数据需要传输时,这些链路处于空闲但不可用于其他消息(浪费的链路带宽以灰色阴影表示)。核心2也因为等待大部分时间处于空闲状态的资源而遭受了显著的延迟。异步传输模式(ATM)[102]建立虚拟电路连接;在数据可以发送之前,必须从源头到目的地预留网络资源(类似电路交换)。然而,数据通过网络的交换是以数据包的粒度而不是消息的粒度进行的。
电路交换为消息分配资源,并跨多个网络跃点进行分配。该方案存在一些效率低下的问题;接下来,我们看看为数据包分配资源的方案。**基于数据包的流量控制技术首先将消息拆分成数据包,然后在链路上交错传输这些数据包,从而提高链路利用率。**与电路交换不同,其余技术将需要每个节点的缓冲区来存储在传输中的数据包。
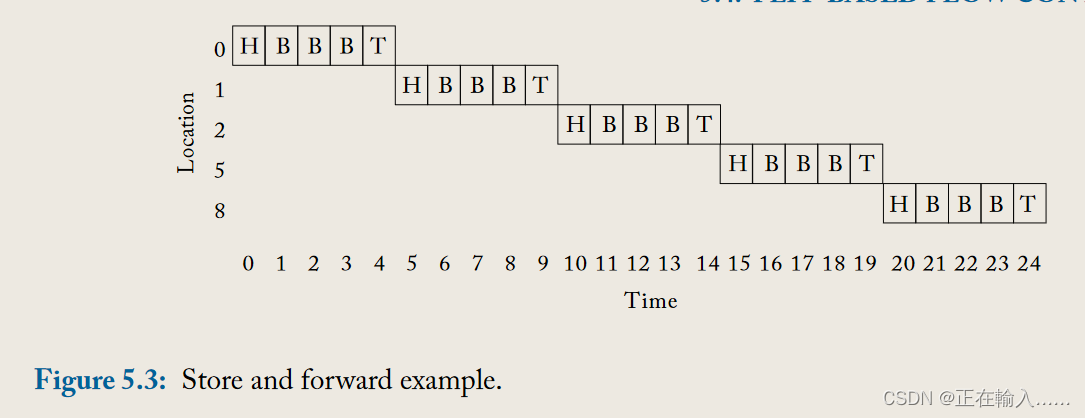
在基于数据包的技术中,消息被拆分成多个数据包,每个数据包由网络独立处理。**在存储转发(store-and-forward)流量控制中,每个节点都会等到接收到整个数据包后才会将该数据包的任何部分转发到下一个节点。**因此,**每个跳点都会产生长时间的延迟,这使得它们不适用于通常对延迟非常敏感的片上网络。**此外,存储转发流量控制要求每个路由器有足够的缓冲区来缓存整个数据包。这种高缓冲要求降低了存储转发交换在片上网络中的适用性。
在图5.3中,我们描述了一个数据包从核心0传输到核心8使用存储转发切换的过程。**一旦尾flit(tail flit)在每个节点被缓冲后,头flit(head flit)就可以分配下一个链路并出发到下一个路由器。**每个跳点都要为主体flit(body flit)和尾flit追赶头flit付出序列化延迟。对于一个包含5个flit的数据包,在每个跳点传输数据包的延迟是5个周期。
为了减少数据包在每个跳点的延迟,**虚拟截断流量控制(virtual cut-through flow control)允许在当前路由器接收到整个数据包之前,数据包就开始传输到下一个节点。**这样,数据包经历的延迟与存储转发流量控制相比有了显著的减少,如图5.4a所示。在图5.3中,传输整个数据包需要25个周期;通过虚拟直通,该延迟可减少至 9 个周期。
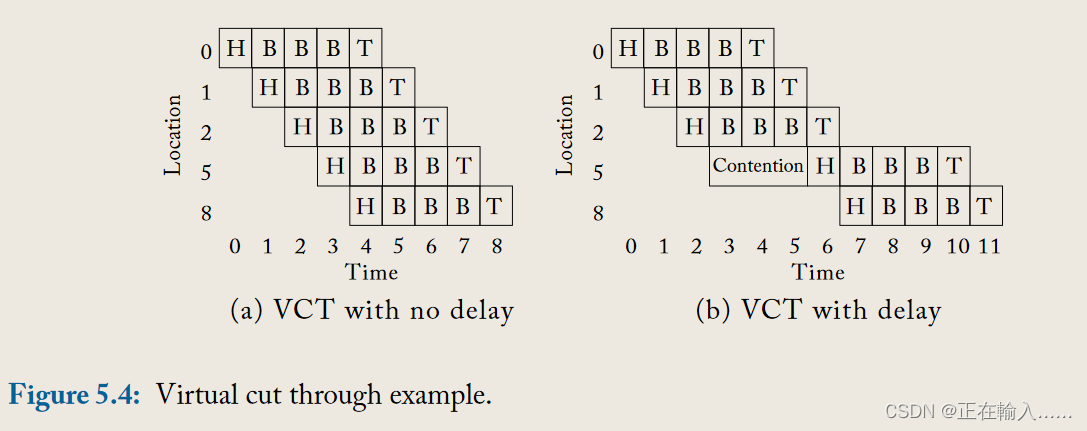
然而,带宽和存储仍然以数据包大小的单位进行分配。仅当下一个下游路由器有足够的存储空间来容纳整个数据包时,数据包才会继续前进。当数据包大小较大(例如 64 或 128 字节高速缓存行)时,面积和功率限制有限的片上网络可能很难容纳支持虚拟直通所需的大型缓冲区。(也就是说,我可以没接受完就提前往前传,但是你像接收必须保证你当前全是空)
在图5.4b中,**即使节点5有2个flit的缓冲区可用,整个数据包在从节点2到节点5的传输过程中仍然会被延迟。直到所有5个flit的缓冲区可用,flits才能继续前进。**这种现象展示了存储转发流量控制模式中一个关键的限制:整个数据包的传输必须等待直到目的节点的所有缓冲区均可用,这可能导致不必要的延迟,尤其是在高速且需要低延迟的网络环境中。
总结: 存储转发和虚拟直通流控制都是基于数据包粒度去分配缓冲区和链路的。具体来说就是下游节点需要有一个数据包大小的空闲缓冲区才能继续发送,另外传输过程中链路保留,其他数据包不能使用。唯一的区别就在于虚拟直通允许数据包未完全到达之前进行传输。
为了减少基于数据包技术的缓冲需求,存在基于flit的流量控制机制。低缓冲需求有助于路由器在片上满足严格的面积或功率限制。这种控制方式通过在传输过程中只处理更小的数据单元——flits,而非整个数据包,从而降低了对存储资源的依赖。这样不仅减少了路由器的缓存大小,也提高了其在高密度集成电路中的适应性和效率。
像虚拟截断流量控制一样,**虫洞流量控制(wormhole flow control)允许flits在整个数据包被当前位置接收之前就移动到下一个路由器。**在虫洞流量控制中,**一旦后续节点有足够的缓冲区用于该flit,该flit就可以离开当前节点。**然而,与存储转发和虚拟截断流量控制不同,虫洞流量控制为flits而不是整个数据包分配存储和带宽。这允许在每个路由器中使用相对较小的flit缓冲区,即使是大尺寸的数据包也是如此。虽然虫洞流量控制有效地使用了缓冲区,**但它对链路带宽的使用效率不高。虽然它以flit大小的单位分配存储和带宽,但链路在数据包在路由器中的生命周期内被持续占用。结果是,当一个数据包被阻塞时,该数据包占用的所有物理链路都处于空闲状态。**由于虫洞流量控制以flit粒度分配缓冲区,一个由许多flits组成的数据包可能跨越几个路由器,这将导致许多物理链路空闲。吞吐量受损,因为排在被阻塞数据包后面的其他数据包无法使用这些空闲的物理链路。
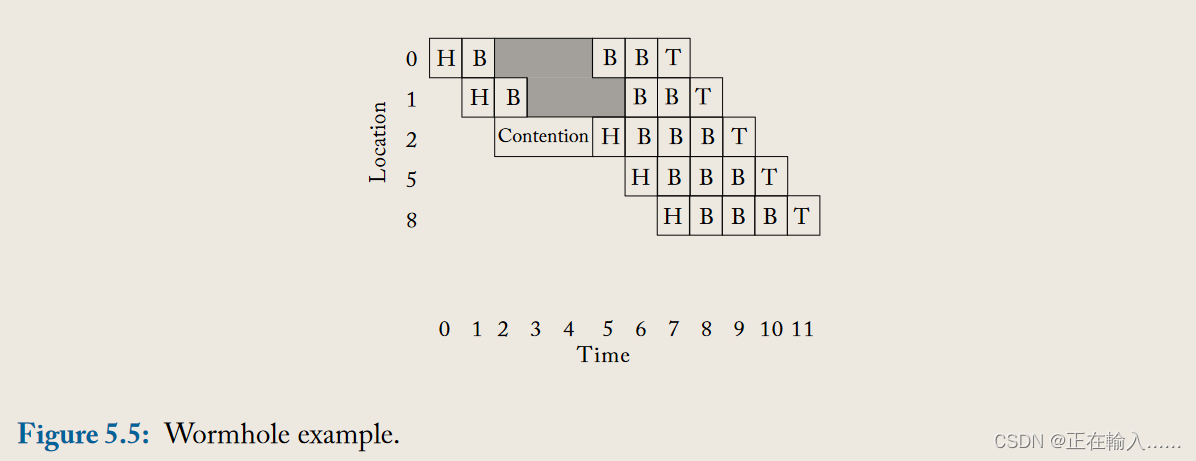
在图5.5中的示例中,每个路由器有2个flit缓冲区。当头flit在从1到2的过程中遇到争用时,剩余的两个主体和尾部flit在核心0处停滞,因为在头部移动到核心2之前,核心1没有可用的缓冲空间。然而,即使通道处于空闲状态(如灰色所示),数据包仍持有该通道。
虫洞流量控制通过允许flit在下游缓冲区可用时尽快离开路由器来降低数据包的延迟(在没有争用的情况下,延迟与虚拟截断相同)。此外,虫洞流量控制可以用比基于数据包的技术更少的缓冲区来实现。由于片上网络的严格面积和功耗限制,虫洞流量控制目前是采用的主要技术。
虚拟通道通道(Virtual channels, VCs)被解释为互连网络的“瑞士军刀”。它们最初被提出作为避免死锁的解决方案,因此扩展了吞吐量,但也被应用于缓解头阻塞(Head-of-line blocking)。头阻塞在所有流量控制技术中都可能发生,在这些技术中,每个输入处有一个队列;当队列头部的数据包被阻塞时,它会阻塞后面排队的数据包,即使有资源可供被阻塞的数据包使用。
从本质上讲,虚拟通道(VC)基本上是路由器中的一个单独队列;多个虚拟通道共享(时分复用)两个路由器之间的物理线路(物理链路)。**通过将多个独立队列与每个输入端口关联,可以减少头阻塞。**虚拟通道以时钟周期为控制粒度,仲裁物理链路带宽的分配。当一个数据包持有一个虚拟通道变得阻塞时,其他数据包仍然可以通过其他虚拟通道穿越物理链路。因此,VCs提高了物理链路的利用率并扩展了整体网络吞吐量。
从技术上讲,VCs可以应用于所有上述流量控制技术以减轻头阻塞,尽管Dally最初是与虫洞流量控制(wormhole flow control)一起提出它们的。例如,在电路交换中可以在虚拟通道而不是物理通道上应用,所以一条消息预留了一系列的VCs而不是物理链路,而VCs是在物理链路上周期性多路复用的,也称为虚拟电路交换。存储转发流量控制也可以使用VCs,每个VC有多个数据包缓冲队列,每个队列一个。虚拟截断流量控制与VCs的工作方式相似,只是VCs是在链路上按flit分批多路复用的。然而,由于片上网络设计通常采用虫洞流量控制因其小面积和功耗占优,使用虚拟通道来扩展带宽,本书其余部分在提及虚拟通道流量控制时,我们假设它应用于虫洞,具有缓冲区和链路在flit粒度上的管理和多路复用。
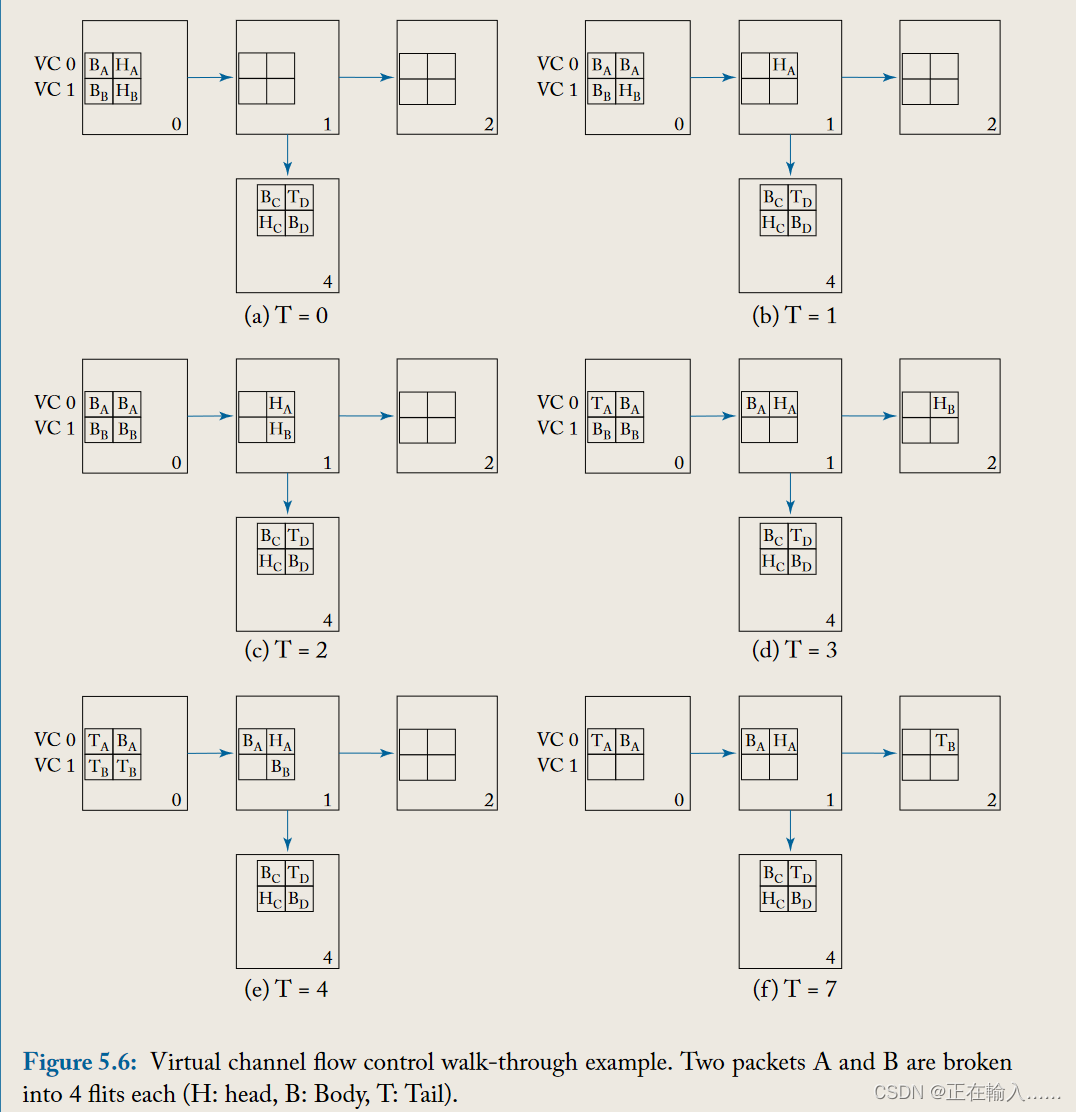
图 5.6 描述了说明虚拟通道流量控制操作的示例。数据包 A 初始占用 VC 0,目的地为节点 4,数据包 B 初始占用 VC 1,目的地为节点 2。在时间 0,数据包 A 和数据包 B 都有flit 在节点 0 的西输入虚拟通道中等待,并希望在东向输出物理通道上出站。假设数据包 A 的头部 flit 被分配给路由器 1 西侧输入的虚拟通道 0,并赢得交换机分配,数据包 A 的头flit在时间 1 传输到路由器 1。
在时刻2,数据包B在开关分配中获得批准,从而传输到路由器1中。同时路由器4两个输入端口虚拟通道都被占用,因此数据包A的头flit没有分配到虚拟通道,从而无法前往下一跳。 在时刻3,数据包A的第一个body flit继承了虚拟通道前往路由器1,同时数据包B的head flit被分配到下游节点路由器2的VC0并继续前进。 在时刻4,数据包B继承了虚拟通道,赢得开关分配后前往路由器1。 … 在时刻7,B的除尾flit所有flit都已到达目的地,而数据包A头flit仍被阻塞,只有路由器4有空闲的虚拟通道后才能传输。
使用单个虚拟通道的虫洞流量控制下,数据包B将在路由器1被数据包A阻塞,尽管有缓冲区、链路和交换机可用,也无法继续前往路由器2。虚拟通道允许数据包B继续前往其目的地,尽管数据包A被阻塞。虚拟通道在每个路由器一次分配给头flit,其余flits继承该虚拟通道。使用虚拟通道流量控制,不同数据包的flits可以在同一物理通道上交错使用,如示例中时间0至2所见。虚拟通道也广泛用于打破死锁,无论是网络内部(见第5.6节),还是处理系统级或协议级死锁(见第2.1.3节)。
前几节解释了不同技术如何处理资源分配和利用。这些技术在表5.1中总结。
| flow control techniques | Links | Buffers | Comments |
|---|---|---|---|
| Circuit-Switching | Messages | N/A (buffer-less) | Requires setup and acknowledgment |
| Store and Forward | Packet | Packet | Head flit must wait for entire packet before proceeding on next link |
| Virtual Cut Trough | Packet | Packet | Head can begin next link traversal before tail arrives at current node |
| Wormhole | Packet | Flit | Head of line blocking reduces efficiency of link bandwidth |
| Virtual Channel | Flit | Flit | Can interleave flits of different packets on links |
可以通过使用确保不会发生循环的约束路由算法(参见第 4 章)或通过使用允许使用任何路由算法的无死锁流控制来保持死锁自由。
由于大多数片上网络设计不能容忍数据包丢失,因此必须有缓冲区反压机制来阻止 flits。当下一跳没有可用的缓冲区来容纳 Flit 时,不得传输它们。buffer backpressure的单位粒度取决于具体的流控协议。存储转发和虚拟直通流量控制技术以数据包为单位管理缓冲区,而虫洞和虚拟通道流量控制以flit为单位管理缓冲区。**电路交换是一种无缓冲流量控制技术,不需要缓冲反压机制。**两种常用的缓冲区反压机制是基于credit的缓冲区反压机制和基于开启/关闭信号的缓冲区反压机制。
credit计数器记录了下一跳路由器空闲缓冲区的个数。每个节点空出缓冲区时(当flit/数据包离开路由器时)向前一跳发送credit。前一跳路由器接受credit后递增credit计数。当一个flit离开当前路由器时,当前路由器会减少相应下游缓冲区的credit计数。
credit计数器记录的是下一跳路由器缓冲区空闲空间还能存储多少个flit。当前路由器可以根据credit计数决定继续或暂停传输数据包。若当前credit减为零则表示下一跳没有空闲缓冲区,需停止传输。一旦下一跳路由器发送出一个flit,被占据的缓冲区就会释放一个单位,因此下一跳路由器会向当前路由器发送信号使credit计数加1。一般每个端口的每个VC通道都会由上游路由器维护单独的一个CR。
开启关闭信号指的是相邻路由器之间的一个信号。当下一跳路由器空闲缓冲区的数量缓冲区数量达到关闭阈值时,该信号就会被关闭(off-signal)以阻止当前路由器继续发送flit。关闭阈值的设定必须确保正在传输的flit在抵达时都有相应的缓冲区。在关闭信号传输过程中,必须为离开当前路由器的flit提供缓冲区。一旦下一跳路由器空闲缓冲区数量超过开启阈值,开启信号(on-signal)以使当前路由器恢复flit传输。开启阈值时,在开启信号发送时下游路由器缓冲区不应为空,而是需要有可容纳flit的缓冲区以覆盖信号传输的延迟,提高带宽利用率。
流量控制协议的实现复杂性本质上涉及整个路由器微体系结构的复杂性以及路由器之间传递资源信息所带来的布线开销。在这里,我们重点关注后者,因为第 6 章详细阐述了路由器微体系结构和相关的实现问题。当选择特定的缓冲区反压机制时,我们需要考虑其缓冲区周转时间方面的性能,以及反向信号线数量方面的开销。
**缓冲区周转时间是连续的 flits 可以重复使用缓冲区所间隔的最短空闲时间。**缓冲区周转时间过长会导致缓冲区重用效率低下,从而导致网络吞吐量较差。如果实现的缓冲区数量没有覆盖缓冲区周转时间,则网络将在每个路由器处被人为地节流,因为即使没有来自路由器其他端口的争用,flit也无法连续流到下一个路由器(没有可用缓冲区而阻塞)。如图 5.10 所示,Credit计数在发送两个flit后变为0,无法继续发送flit。只能等待下游路由发送Credit更新后,才能继续发送。两个路由器之间的链路空闲 6 个周期,同时等待下游路由器的空闲缓冲区。
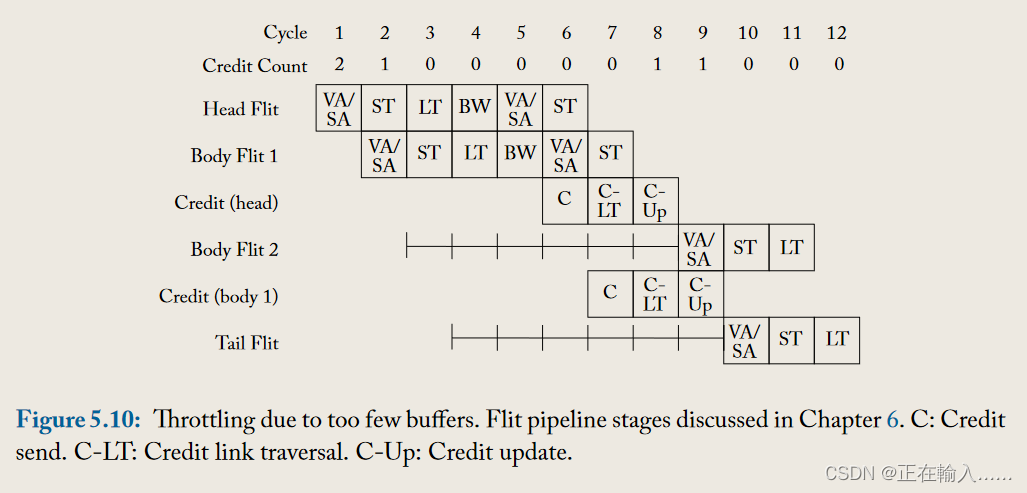
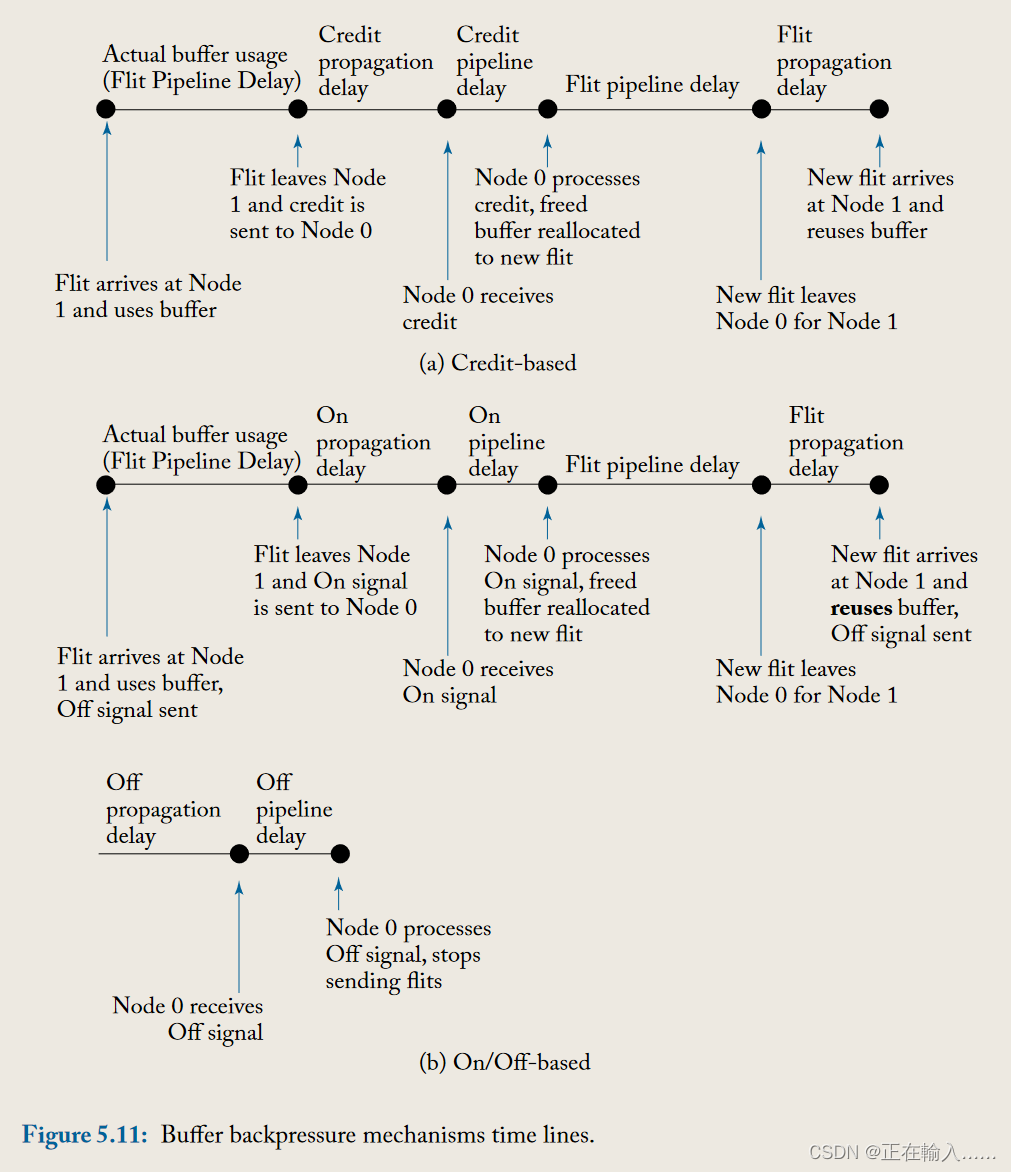
此处,缓冲器周转时间至少是开/关信号传播延迟的两倍加上数据片传播延迟和流水线延迟,如图 5.11b 所示。
如果我们对相邻节点之间的数据流和反向信令有 1 个周期的传播延迟,对缓冲区反压信号有 1 个周期的管道延迟,以及 3 个周期的路由器管道,那么基于信用的反压将有一个缓冲区周转时间至少 6 个周期,而开/关背压将具有至少 8 个周期的缓冲区周转时间。请注意,这意味着使用开/关背压的网络每个端口至少需要 8 个缓冲区来覆盖周转时间,而如果选择基于信用的背压,则每个端口需要的缓冲区少 2 个。因此,缓冲区周转时间也会影响区域开销,因为缓冲区占据了路由器占用空间的很大一部分。请注意,一旦确定 flit 将离开路由器并且不再需要其缓冲区,就可以通过触发反压信号(credits 或 on/off )来优化缓冲区周转时间。
虽然开/关反压与基于信用的反压相比表现较差,但它在反向信号线开销方面具有较低的开销。图 5.12 说明了两种反压机制所需的反向信号线数量:基于信用的要求每个队列(虚拟通道)有 logB 条线,其中 B 是队列中缓冲区的数量,用于对信用计数进行编码。另一方面,开/关每个队列只需要一根线。每个队列有八个缓冲区和两个虚拟通道,基于信用的背压需要六个反向信号线(图 5.12a),而开/关只需要两个反向线(图 5.12b)。在片上网络中,片上布线丰富,与区域开销和吞吐量相比,反向信号线开销往往不太受关注。因此,基于信用的背压将更合适。

