This repository contains the LARC dataset and supporting assets
"How can we build intelligent systems that achieve human-level performance on challenging and structured domains (like ARC), with or without additional human guidance? We posit the answer may be found in studying natural programs - instructions humans give to each other to communicate how to solve a task. Like a computer program, these instructions can be reliably "executed" by others to produce intended outputs."
A comprehensive view of this dataset and its goals can be found in Communicating Natural Programs to Humans and Machines
LARC is curated from a communication game, where one participant, the describer solves an ARC task and describes the solution to a different participant, the builder, who must solve the task on the new input using the description alone. The successful descriptions are "language-complete" in a sense that it fully captures the underlying ARC task in the absence of the original input-output examples.
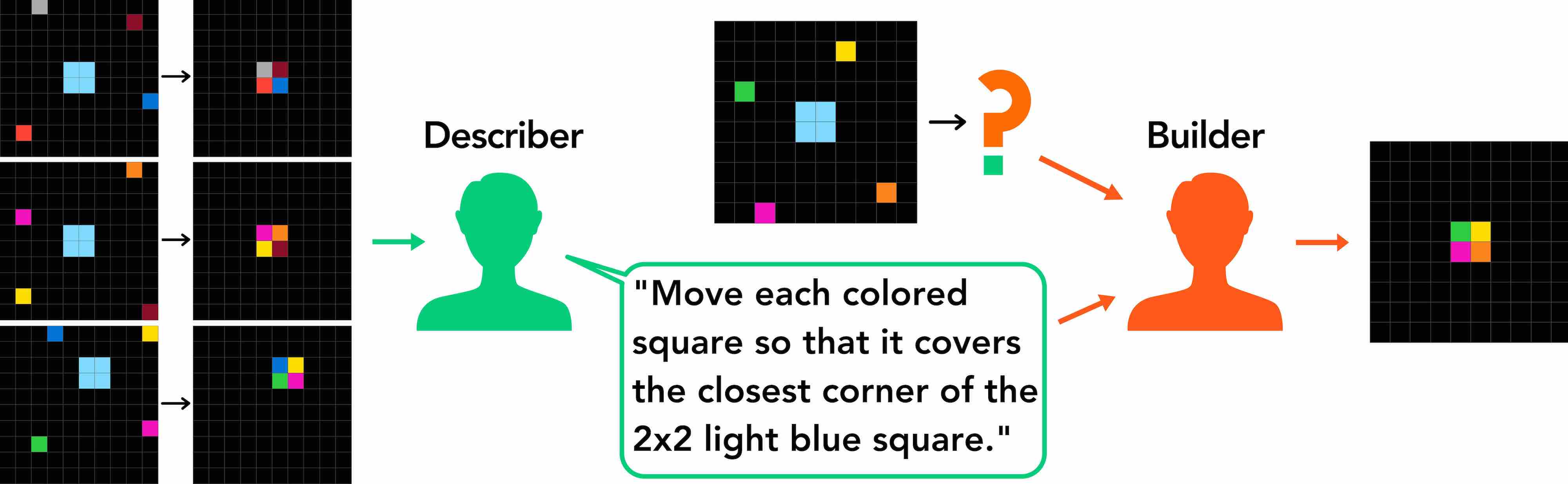
The entire dataset can be browsed at the explorer interface or by downloading the project and run python3 -m http.server from the root directory and point to localhost:8000/explore/ from your browser.
Citation
@article{acquaviva2021communicating,
title={Communicating Natural Programs to Humans and Machines},
author={Acquaviva, Samuel and Pu, Yewen and Kryven, Marta and Wong, Catherine and Ecanow, Gabrielle E and Nye, Maxwell and Sechopoulos, Theodoros and Tessler, Michael Henry and Tenenbaum, Joshua B},
journal={arXiv preprint arXiv:2106.07824},
year={2021}
}
The original ARC data can be found here The Abstraction and Reasoning Corpus
datasetcontains the language-complete ARC tasks and successful natural program phrase annotationsexplorercontains the explorer code that allows for easy browsing of the annotated taskscollectioncontains the source code used to curate the datasetbanditcontains the formulation and environment for bandit algorithm used for collection


