laihuamin / js-total Goto Github PK
View Code? Open in Web Editor NEWJS的流程图,每一个知识点都会配上相应的博客和面经
JS的流程图,每一个知识点都会配上相应的博客和面经
先说1.1总揽:
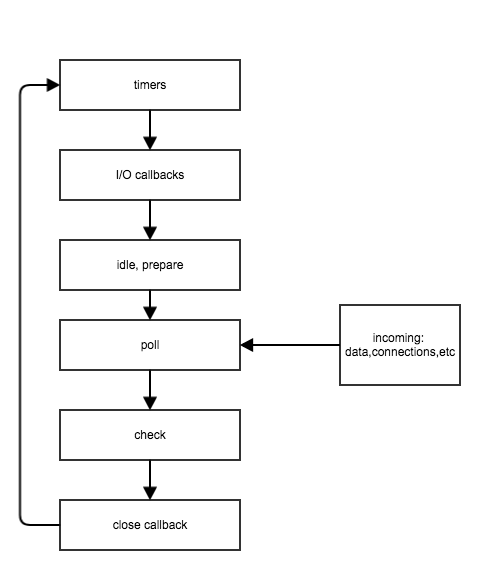
nodejs和其他编程平台的区别在于如何去处理I/O接口,我们听一个人介绍nodejs,总是会说是一个基于v8引擎,没有堵塞,事件驱动的语言,那这些又意味着什么呢?什么叫‘没有堵塞’和‘事件驱动’?所有的答案都在nodejs的核心——Event Loop。
在这一系列的帖子中,我们将一起去描述什么是Event Loop,它是如何工作的,它是如何影响我们的应用的,如何充分的利用他甚至更多。为什么不用一篇代替一个系列的帖子呢,因为这样的话,他就会变成一个很长很长的帖子,我会肯定会错过很多东西,因此我才把它写成一个系列,在第一篇帖子中,我将讲述nodejs如何工作,如何通过I/O,他如何与其他平台一起工作等。
nodejs工作在一个事件驱动的模型中,这个模型涉及一个事件分离器和事件循环,所有的I/O请求最终将会生成一个事件完成、事件失败或者唤醒其他事件的结果。这些事件将会根据以下规则做处理:
1.事件分离器收到I/O请求,之后将这些请求委托给相应的硬件
2.曾经被处理过的请求(比如来自可读取文件的数据,来自可读取接口的数据),事件分离器会为要进行的特殊操作添加注册回调程序。
3.如果事件可以在事件循环中被处理,那么将有序的被执行,直到循环为空
4.如果没有事件在事件循环中,或者事件分离器没有添加任何请求,这个 程序将被完成,否则,程序将从第一步在开始,进行循环操作。
这整个工程的协调机制我们叫做Event Loop
Event Loop其实是一个单线程的半无限循环,为什么会说是半无限呢?因为在没有工作需要完成的时候程序会退出。从开发者的角度来说,这些是程序退出的点。
注意:不要把Event Loop和Event Emitter弄混淆,Event Emitter和这个机制完全是不同的概念,在最后一篇帖子,我会解释Event Emitter是如何通过Event Loop影响事件的处理。
上面的图是对NodeJs如何工作以及展示一种被叫做Reactor Pattern的主要组件的设计模式的高级概览。
但是真正的复杂度远超于它,那它有多复杂呢?
Event demultiplexer不是一个在所有os平台中解析所有I/O类型的单一组件。
Event queue在这里展示出来的不是一个单一的队列,在其中所有类型的事件会在队列中排队或者从队列中移除,并且I/O不是唯一一个要排队的事件类型
让我们继续深挖
Event Demultiplexer并不是一个现实存在的组件,而是在reactor pattern中的一个抽象概念。
在现实中,Event Demultiplexer 在不同的系统中以不同的名字被实现,比如在linux中叫做epoll, 在MacOS中叫做kqueue,在Solaris中叫event post,在window系统下叫做IOCP等。
nodeJS可以使用Event Demultiplexer提供的底层非阻塞、异步硬件I/O功能。
但是令人苦恼的是,不是所有类型的I/O都可以使用Event Demultiplexer被执行,甚至是在相同的操作系统中,支持不同类型的I/O也是很复杂的。
通常来说,epoll, kqueue, event ports和IOCP可以使用非阻塞的方式执行网络I/O。
但是文件I/O就复杂多了,某些系统,比如Linux不支持完全异步的方式去访问文件系统,在MacOS系统中文件系统对事件的发送和接收会有限制(你可以在这里了解更多)。
为了提供完全异步而去解决所有文件系统的复杂性是非常复杂的,几乎是不可能的。
和文件I/O一样,由node API提供某些DNS的功能也存在一定的复杂性。
比如dns.lookup等Node DNS功能访问系统的一些配置文件,例如nsswitch.conf、resolv.conf和/etc/hosts。
上面描述的文件系统复杂性也适用于dns.resolve函数。
因此,引入了一个线程池来支持I/O功能,这些功能不能由硬件异步I/O实用程序(如epoll / kqueue / event ports或IOCP)直接解决。
现在我们知道不是所有的I/O功能都可以在线程池中运行。nodeJS已经尽最大努力来使用非阻塞和硬件的异步I/O方式来完成大部分I/O功能,但是对于一些复杂的、阻塞的I/O还是通过引入一个线程池的方式来解决
该篇先翻译到这,有些地方翻译的不好请指出,过几天我会继续出第二篇。
instanceof的发明是为了弥补typeof所带来的缺陷,因为typeof在检测object类型的时候,总是会返回object,所以js提供了另外一个接口来实现对对象类型的判断,那就是我们的instanceof,我们先来看一下他的用法:
const obj = new Object();
console.log(obj instanceof Object) //true其实他的功能还很强大,我们可以看一下下面的例子
function Foo(){};
const foo = new Foo();
console.log(foo instanceof Foo);不仅可以检测原有的object类型,还可以检测自定义你构造函数类型
instance不仅可以检测实例本身的构造函数,他还可以检测,实例的父类型继承,我们看一下下面这个例子
function Foo() {};
function Bar() {};
Bar.prototype = new Foo();
Bar.prototype.constructor = Bar;
const bar = new Bar();
console.log(bar instanceof Bar); //true
console.log(bar instanceof Foo); //true其实instanceof还有很多复杂用法,我们看一下下面的例子
function Foo() {};
console.log(Object instanceof Object); //true
console.log(Function instanceof Function); //true
console.log(Number instanceof Number); //false
console.log(String instanceof String); //false
console.log(Function instanceof Object); //true
console.log(Foo instanceof Function); //true
console.log(Foo instanceof Foo); //false从网上的一篇博客中找到一段自己实现instanceof的代码,如下
function instance_of (L, R){
var O = R.prototype; //右边表达式的显示原型
var L = L._proto_; //左边的表达式的隐式原型
while(true){
if(L === null){
return false;
};
if(O === L){
return true;
};
L = L._proto_;
}
}原型和原型链是js中很重要的一部分,我们用流程图来看一下
有几点需要注意:
1.Object是构造函数,他的_proto_指向Function.prototype
2.Function.prototype的_proto_指向Object.prototype
3.Object.prototype的_proto_指向null
左边的Object的_proto_指向Function.prototype,Function.prototype指向Object.prototype
左边的Function的_proto_指向Function.prototype
左边的Number的_proto_指向Function.prototype,所以原型链向上已经回不到Number.prototype,所以返回false
和上面同理
左边的Function的_proto_指向Function.prototype,而Function.prototype的_proto_指向Object.prototype,所以返回true
Foo是构造函数,所以他的_proto_是指向Function.prototype,所以返回true
上面已经解释了指向,这个肯定为false
配置webpack的环节中,entry是必不可少的一个环节,我最近做了一篇关于webpack的分享,然后也想做一个关于webpack的一个系列,讲讲我对于webpack的理解,以及我对于我们工程架构的理解。有兴趣的也可以关注一下我的github,可以点个关注,喜欢或者收藏谢了0.0
在能有什么用之前,然我们前去了解一下他们两个到底是什么,其实entry和context从英文层面上我们就可以清晰的知道,一个是入口的意思,还有一个是上下文的意思,那么我们想知道他们到底有什么用,请看下面。
其实这个目录结构是这样的,有兴趣的可以去看一下这个小demo,是这个上下文的示意。
目录中的dist是我打包出来的文件,而app中的文件是我书写的原文件,而webpack.config.js中的代码是这样的
const path = require('path');
module.exports = {
context: path.resolve(__dirname, 'app'),
entry: './main.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js'
}
}
看这段代码,其实我们就可以猜到context的作用了,如果没有这个context,那我们的entry应该怎么写,是不是应该书写成
'./app/main.js'
还好我app中就一个main.js,要是来10个或者100个,那要多写多少个app,所以我们可以看到context的作用。他就是会将entry的根路口指向app这个文件夹
讲完context,那么我们应该要来讲讲什么呢,当然是entry入口文件啦,对于一个webpack打包配置文件来说,entry是我们最初配置的时候就该解决的问题。
对于entry这个配置项来说,我们可以把他分类型来看,entry一共可以分为string、array和object。其他的都是这几种的组合。
对于字符串,其实这是一个单一的入口,是一个一对一或者一对多的关系,在现在的单页应用SPA上面用的很多,我们可以来看一下我们的demo。
在demo中我们的目录结构是这样的
我们可以看一下webpack.config.js中的代码:
module.exports = {
entry: './main.js',
output: {
path: __dirname,
filename: 'bundle.js'
}
}
这是个一对一的关系,一个入口,产出一个bundle.js,所以这个是举个例子,比较简单,但是在真实的单页应用中,不会这么简单,他会是一个一对多的关系,一个入口,然后webpack会解析依赖然后将其打包多个文件。
讲完字符串我们来讲讲数组是个什么关系呢,数组其实是多对一的关系,就是入口可以是多个文件,但是出口会是一个模块,这个可以用在哪里呢,比如,我们项目中肯定会有很多公用的模块,那么这些模块有必要打包到很多个文件中么,答案当然是没有这个必要的,放一个里面,我们只要在html中引入一个就行了,多省事,还会用在这种情况上,比如jquery和lodash这样的不相互依赖的文件可以放到一个模块中。那我们来看看具体的demo
在demo中我们的目录结构是这样的
我们可以看一下webpack.config.js中的代码:
module.exports = {
entry: ['./main1.js', './main2.js'],
output: {
path: __dirname,
filename: 'bundle.js'
}
}
到这里我们可以打开index.html文件看一下,是不是main1.js和main2.js中的两条代码都在bundle.js中了,所以,这个多对一的关系可以很好的用到真实的项目中。
最后一个对象,不用说大家应该也猜得到,当然是多对多的关系。也是在多页面应用中我们经常用到的,我这里举一个简单点的例子,具体的demo
在demo中我们的目录结构是这样的
我们可以看一下webpack.config.js中的代码:
module.exports = {
entry: {
one: './main1.js',
two: './main2.js',
'path/to/main': './main3.js'
},
output: {
path: __dirname,
filename: '[name].js'
}
}
我们可以看到,前两个entry对象的键值对还是比较正常的,但第三个的时候我却把它换成了一个路径名,但是webpack很聪明,看到目录结构你就知道,其实webpack会解析这个路径,然后他会帮我们创建相对应的路径,比如,path文件夹中有to文件夹,在to文件夹中还有main.js。
但是在实际的项目中,entry肯定不会变的这么简单,我可以给大家提供几个例子,关于entry对象的收集,因为如果是数组和字符串,在单页应用中算简单的,但是在多页面应用中却是困难重重。
收集entry对象的函数
const glob = require('glob')
const path = require('path')
const GLOB_FILE_PATH = './src/pages/**/index.js'
const CUT_PATH = './src/pages/'
exports.getEntries = function(argv){
let paths = glob.sync(GLOB_FILE_PATH)
let entries = {}
for (let i = 0; i < paths.length; i++){
let pathName = path.dirname(paths[i]).replace(new RegExp('^' + CUT_PATH), '')
entries[pathName] = paths[i]
}
return entries
}
这里用正则来提取的键值对,有兴趣的同学也可以去了解一下glob这个文件读取模块。
这算是我的第二篇webpack的文章,也是希望能给我个人的webpack系列文章有一个很好的开始,写写大家的支持,我会将webpack的配置项一个一个拿出来讲,然后配上demo这样希望能让大家更好的理解,这期讲了比较简单点的context和entry。下期将会带来output,希望喜欢的可以去我的github上面点个star,文章属于纯原创,转载请注明出处谢谢
前一篇文章梳理了promise的基础聊聊promise系列(基础)
这篇文章将从容易出现错误的几种用法出发,得出如何去正确的用promise。
想必大家在项目中会见过这样的写法。
const p1 = new promise((resolve, reject) => {
resolve(true);
})
p1.then((res) => {
if(res) {
const p2 = new promise((resolve, reject) => {
resolve(true);
})
p2.then((res) => {
const p3 = new promise((resolve, reject) => {
resolve(true);
})
})
}
})这个写法写出了回调地狱的感觉。那如何优化他呢!!
const p1 = new promise((resolve, reject) => {
resolve(true);
})
const p2 = new promise((resolve, reject) => {
resolve(true);
})
const p3 = new promise((resolve, reject) => {
resolve(true);
})
p1.then((res) => {
if(res) {
return p2
}
}).then((res) => {
if(res) {
return p3
}
})用这种链式调用的方式还是十分的优雅的。
举个等价的例子:
Promise.reject('error').catch((res) => {
console.log(res);
})
Promise.reject('error').then(null, (res) => {
console.log(res);
})catch是用then(null, ...)来实现的,但是在某些条件下,并不是等价的,比如以下例子:
const p1 = new Promise((resolve, reject) => {
if(/*正确的条件*/) {
resolve('success');
} else {
reject('false');
}
});
//用法一:
p1.then((res) => {
console.log(res);
throw new Error('我在then出错了');
}, (res) => {
console.log(res);
});
//用法二:
p1.then((res) => {
console.log(res);
throw new Error('我在then出错了');
}).catch((res) => {
console.log(res);
})上述例子的区别就在与,catch可以捕捉then中发生的错误,但是then的第二个回调函数捕捉不了第一个参数中的报错。
输出的结果:
什么是promise穿透问题呢?举个例子:
Promise.resolve('foo').then(Promise.resolve('bar')).then(function (result) {
console.log(result);
});这个鬼东西会输出啥??
斟酌良久,你可能回答bar,那你就错了,实际输出的是foo。
因为then中希望获得的是一个函数。而当你传入一个promise的时候,相当于then(null),无论你添加多少个then(null),promise都会穿透到下一个。
当然,对于上述例子,你可能希望的是这样做:
Promise.resolve('foo').then(() => {
return Promise.resolve('bar');
}).then(function (result) {
console.log(result);
});切记,一定要往then里面传入函数
接下来,我们通过一个例子,来看一下不同写法带来的后果。
const func = function(last, num) {
return new Promise((resolve, reject)=>{
console.log(last, num);
resolve(num);
});
};
// 写法一
Promise.resolve()
.then((last)=>{return func(last, 1);})
.then((last)=>{return func(last, 2);})
.then((last)=>{return func(last, 3);});
// 写法二
Promise.resolve()
.then((last)=>{func(last, 1);})
.then((last)=>{func(last, 2);})
.then((last)=>{func(last, 3);});
// 写法三
Promise.resolve()
.then(func(undefined, 1))
.then(func(undefined, 2))
.then(func(undefined, 3));
// 写法四
func(undefined, 1).then(func(undefined, 2)).then(func(undefined, 3));结果:
undefined 1
1 2
2 3
这是我们想要的结果,也是promise链式调用正确的写法。
undefined 1
undefined 2
undefined 3
虽然在then中执行了函数,但是并没有return有结果的promise给下一个then,所以后面的then永远是收不到结果值的。
结果:
undefined 1
undefined 2
undefined 3
这种写法是造成promise穿透引起的。then里面需要是一个函数,但是却传了一个promise进去。
结果:
undefined 1
undefined 2
undefined 3
和第三种也发一致,也是promise穿透,then里面需要是一个函数,但是却传了一个promise进去。
如果自己去实现数据驱动的模式,如何解决一下几个问题:
我们需要知道数据的获取和改变,数据劫持是最基础的手段。在Obeserver中,我们可以看到代码如下:
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
// ...
},
set: function reactiveSetter (newVal) {
// ...
}
})通过Object.defineProperty这个方法,我们可以在数据发生改变或者获取的时候,插入一些自定义操作。同理,vue也是在这个方法中做依赖收集和派发更新的。
从初始化开始,我们渲染视图的时候,便会生成一个watcher,他是监视视图中参数变化以及更新视图的。代码如下:
// 在mount的生命钩子中
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)当然,我们可以保留疑问:
具体的绑定和更新的流程,我们到后续的依赖收集中讲解。
我们先来讲讲响应式系统中涉及到的设计模式。
在发布订阅模式中,发布者和订阅者之间多了一个发布通道;一方面从发布者接收事件,另一方面向订阅者发布事件;订阅者需要从事件通道订阅事件
以此避免发布者和订阅者之间产生依赖关系
vue的响应式系统借鉴了数据劫持和发布订阅模式。
Vue用Dep作为一个中间者,解藕了Observer和Watcher之间的关系,使得两者的职能更加明确。
那具体是如何来完成依赖收集和订阅更新的呢?
举个例子
<div id="app">
{{ message }}
{{ message1 }}
<input type="text" v-model="message">
<div @click="changeMessage">改变message</div>
</div>var app = new Vue({
el: '#app',
data: {
message: '1',
message1: '2',
},
methods: {
changeMessage() {
this.message = '2'
}
},
watch: {
message: function(val) {
this.message1 = val
}
}
})依赖收集流程图:
如何看懂这个依赖收集流程?关键在watcher代码中:
get () {
pushTarget(this)
let value
const vm = this.vm
try {
value = this.getter.call(vm, vm)
} catch (e) {
// 省略
} finally {
if (this.deep) {
traverse(value)
}
popTarget()
this.cleanupDeps()
}
return value
}调用的这个this.getter有两种,一种是key值的getter方法,还有一种是expOrFn,比如mounted中传入的updateComponent。
我们不妨想想什么才算是重复收集了?
笔者想到一种情况:就是dep数组中,出现了多个一样的watcher。
比如renderWatch就容易被重复收集,因为我们在html模版中,会重复使用data中的某个变量。那他是如何去重的呢?
1、只有watch在执行get时,触发的取数操作,才会被收集
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
const value = getter ? getter.call(obj) : val
if (Dep.target) {
dep.depend()
// ...
}
return value
},
set: function reactiveSetter (newVal) {
// ...
dep.notify()
}
})当只有Dep.target这个存在的时候才进行依赖收集。Dep.target这个值只有在watcher执行get方法的时候才会存在。
2、在dep.depend的时候会判断watch的id
depend () {
if (Dep.target) {
Dep.target.addDep(this)
}
}addDep (dep: Dep) {
const id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}我们会发现,在depend过程中,会有一个newDepIds去记录已经存入的dep的id,当一个watcher已经被该dep存过时,便不再会进行依赖收集操作。
收集流程讲完了,不妨在听听更新流程。
<div id="app">
{{ message }}
{{ message1 }}
<input type="text" v-model="message">
<div @click="changeMessage">改变message</div>
</div>var app = new Vue({
el: '#app',
data: {
message: '1',
message1: '2',
},
methods: {
changeMessage() {
this.message = '3'
}
},
watch: {
message: function(val) {
this.message1 = val
}
}
})依赖收集的最终结果:
当触发click事件的时候,便会触发订阅更新流程。
订阅更新流程图:
当renderWatch执行更新的时候,回去调用beforeUpdate生命钩子,然后执行patch方法,进行视图的变更。
如何去防止重复更新呢?renderWatch会被很多dep进行收集,如果视图多次渲染,会造成性能问题。
其实问题的关在在于——queueWatcher
在queueWatcher中有两个操作:去重和异步更新。
function queueWatcher (watcher) {
const id = watcher.id
if (has[id] == null) {
has[id] = true
queue.push(watcher)
// ...
if (!waiting) {
waiting = true
// ...
nextTick(flushSchedulerQueue)
}
}
}其实queueWatcher很简单,将所有watch收集到一个数组当中,然后去重。
这样至少可以避免renderWatch频繁更新。
比如上述例子中的,message和message1都有一个renderWatch,但是只会执行一次。
异步更新也可以保证当一个事件结束之后,才会触发视图层的更新,也能防止renderWatch重复更新
文章讲述了响应式流程的原因,代码细节并未深入,如果喜欢了解源码的,可以翻看笔者其他的文章:
Watcher源码解析(未完成)
一个源码中,理不清的依赖是最烦的,让我们继续往下看,如何实现它,工具的github地址,觉得可以的可以点个star,博客的地址,喜欢的也可以点个star,谢谢。
先让我们来看看最后的效果如何:
选中的情况下,会把其余的都隐藏,显示它引入的依赖。
我们先了解echart和node的fs和path模块,这是编写的基础。fs的几个处理文件的方法,path几个处理路径的方法,还有echart中的和弦图,我们要整理出来的nodes节点和links依赖关系。
第二步,先定义一些常量,然后我们要用fs模块去读取文件夹中的文件的filename和pathname,我们还要判断一个文件是不是文件夹,如果是文件夹,我们要递归调用的个函数,继续读取,直到所有的都遍历完毕。代码如下:
// 该文件是这个npm包用到的常量
// 需要忽略的文件夹
module.exports.IGNORE_DIR = ['node_modules', '.git', 'dist', 'build', 'test', '.DS_Store', '.gitignore', 'package-lock.json', 'README.md'];
// 符合标准的文件的扩展名
module.exports.INCLUDE_EXT = ['.js', '.json', '.node']var fs = require('fs');
var path = require('path');
// 引入我们定义好的常量
var extName = require('./constant.js').INCLUDE_EXT,
ignoreFile = require('./constant.js').IGNORE_DIR,
res = {
filename: [],
pathname: []
};
function getFileName(dir, addIgnore) {
var files = fs.readdirSync(dir),
ignoreList = [];
// 判断不需要的文件
if(Array.prototype.isPrototypeOf(addIgnore)) {
ignoreList = addIgnore.concat(ignoreFile);
} else {
ignoreList = ignoreFile;
}
// 收集文件名称和所属路径
files.forEach(function(item) {
var extname = path.extname(item),
currentPath = path.join(dir, item),
isFile = fs.statSync(currentPath).isFile(),
isDir = fs.statSync(currentPath).isDirectory();
// 先在ignore的列表中寻找,如果找到直接return
if (ignoreList.indexOf(item) !== -1) {
return;
} else {
// 判断他是不是我们需要的文件名
if(isFile && extName.indexOf(extname) !== -1) {
res.filename.push(item);
res.pathname.push(currentPath);
} else if (isDir) {
// 如果是文件夹,调用函数继续处理
getFileName(currentPath);
}
}
})
return res;
}你会发现这里的输出结果整理一下已经可以作为echarts的节点了。
第三步的话,我倾向于把links这个关系整理出来,那么我们要做的活就是用fs读取每一个文件,然后在用正则,将import和require的文件整理到target中,这样我们就得未经处理的links。那我就直接上代码了!!!
var fs = require('fs'),
path = require('path'),
reqReg = /require\(['|"](.*?)['|"]\)/g,
impReg = /import\s.*?['|"](.*?)['|"]/g,
resDep = [];
function getDepend(res, dir) {
// 根据上一个文件res获得的pathname数组进行依赖收集
res.pathname.forEach(function(item, index) {
// 读取文件
var data = fs.readFileSync(item, 'utf-8'),
results = [];
// 正则匹配require
while((results = reqReg.exec(data)) !== null) {
var link = {
source: res.pathname[index],
target: results[1],
weight: 1,
name: '依赖'
};
resDep.push(link);
}
// 正则匹配import
while((results = impReg.exec(data)) !== null) {
var link = {
source: res.pathname[index],
target: results[1],
weight: 1,
name: '依赖'
};
resDep.push(link);
}
});
return resDep;
}
第四步的话,下回在讲吧,要跑去要饭了
如果你能确切的答出可以,那恭喜你,你可以绕道了
有人会说,这个问题好奇葩,放在别的语言里,这要是能输出true,估计是见鬼了,但是你别说,放在js中好真有可能。最近在一个人的推特上提了一个问题:
在这篇文章中,我将解释这段代码的原理:
const a = {
num: 0,
valueOf: function() {
return this.num += 1
}
};
const equality = (a==1 && a==2 && a==3);
console.log(equality); // true你可以打开chorme浏览器,然后打开开发者模式,在console中输入这段代码,你就可以看到输出结果([windows]: Ctrl + Shift + J [mac]: Cmd + Opt + J)
其实也没有,能有的就是js中的两个概念:
注意:这题里面我们用的是==而不是===,在js中==代表的是等于而不是全等,那么就存在变量的隐式转化问题。这就意味着结果会比我们所期望的更多的可能性。对于js的隐式转化,真的有很多文章,我推荐一下以下几篇博客,如果你想要了解,可以点进去:
JavaScript提供了一种将对象转化为原始值的方法:Object.prototype.valueOf(),默认情况下,返回正在被调用的对象。
我们举个例子:
const a = {
num: 0
}我们可以对上述对象使用valueOf方法,他会返回一个对象。
a.valueOf();
// {num: 0}是不是很酷,我们可以用typeOf来检测一下这个输出结果的类型:
typeof a.valueOf();
// "object"为了让valueOf可以更方便将一个对象转化成原始值,我们可以重写他,换种说法就是我们可以通过valueOf来返回一个字符串、数字、布尔值等来代替一个对象,我们可以看以下代码:
a.valueOf = function() {
return this.num;
}我们已经重写了原生的valueOf()方法,当我们调用valueOf的时候,他会返回a.num。那我们现在运行以下:
a.valueOf();
// 0我们得到0了,这很合理,因为0就是赋给a.num的值。那我们可以来做几个测试:
typeof a.valueOf();
// "number"
a.num == a.valueOf()
// true很好,但为什么这个很重要呢?
这很重要,因为当你两种不同类型的遇到相等操作符的时候,js会对其进行类型转化——它企图将操作数的类型转化为类似的。
在我们的问题中:(a==1 && a==2 && a==3)JavaScript会企图将对象转化成数字的类型,进行比较。当要转化的是一个Object的时候,JavaScript会调用valueOf()方法。
自从我们改变了valueOf()方法之后,我们能不能做到以下几点呢:
a == 0
// true我们做到了,异常轻松。
现在我们需要做的的一点是:当我们每次去调用a的值的时候,能改变它。
幸运的是,在JavaScript中有+=符号。
+=这个运算符可以轻松的去改变一个的值,我们可以举个简单的例子:
let b = 1
console.log(b+=1); // 2
console.log(b+=1); // 3
console.log(b+=1); // 4正如你所见的,我们每次使用加法赋值运算符,可以让我们的变量增加。
所以我们可以将这个观念用到valueOf()中。
a.valueOf = function() {
return this.num += 1;
}当我们每次调用valueOf的时候,他会将变量增加1返回给我们。
随着这个改变,我们来运行下面的代码:
const equality = (a==1 && a==2 && a==3);
console.log(equality); // true这就是它的工作原理。
记住下面两点:
所以比较的时候我们每次都能得到true。
a == 1 ->
a.valueOf() == 1 ->
a.num += 1 == 1 ->
0 += 1 == 1 ->
1 == 1 -> true
a == 2 ->
a.valueOf() == 2 ->
a.num += 1 == 2 ->
1 += 1 == 2 ->
2 == 2 -> true
a == 3 ->
a.valueOf() == 3 ->
a.num += 1 == 3 ->
2 += 1 == 3 ->
3 == 3 -> true谢谢你观看这个小实验,希望你能从中学到东西,有兴趣的朋友也可以去我的github点个star,你的支持是我持续输出的动力,谢谢!!!
以前呢position只有4种属性,但是到了css3之后呢,又添了这个家伙,刚接触css的时候也不知道,最近业务中碰到的次数越来越多了,就想写一篇自己研究的,让大家参考参考,可能写的不够好,不过,看了之后觉得喜欢的可以点个喜欢,或者点个关注,博文中有几篇高赞的也可以看一看,或者觉得博主写的不错,可以给我的github点个star
在讲什么是sticky之前,我们先来补一下css中的三个定位,知道的朋友可以跳过这一段,我们先来看一下没有定位的默认状态,一下都会以这个举例:
相对于其正常位置进行定位,但是不影响其他元素的偏移。元素的位置通过 left, top, right 以及 bottom 属性进行规定。
相对定位的元素并未脱离文档流,而绝对定位的元素则脱离了文档流。在布置文档流中其它元素时,绝对定位元素不占据空间。绝对定位元素相对于最近的非 static 祖先元素定位。当这样的祖先元素不存在时,则相对于根级容器定位。举个例子:
固定定位与绝对定位相似,但元素的包含块为 viewport 视口。该定位方式常用于创建在滚动屏幕时仍固定在相同位置的元素。
MDN给出的解释是
粘性定位是相对定位和固定定位的混合。元素在跨越特定阈值前为相对定位,之后为固定定位。
MDN中的说法以及例子
可以,我的实践结果告诉我,MDN给的那个解释有错误,可能是我理解的不够深,但是我把我的探索过程和大家分享,要是大家觉得我哪里说错了,一定要在评论中纠正我,这样我可以及时修改,以免误导大家.
首先我们来看一下,relative和fixed定位下,滚动会有什么样的效果,我们来看几张图片
我来大致介绍一下这两个情况下滚动会发生些什么,fixed是根据html定位的,他会一直呆在原地,而relative就不一样,他会跟着滚上去,有兴趣的可以自己去jsbin上试一试,亲身体验一下,接下来我要和大家讲讲我们今天的主角,sticky,我们也来看几张图,我们先来研究他到底是基于什么定位的。
笔者自己玩过了,总结出来一套:
1、其实sticky是根据窗口定位的,但是这个有个前提,不能脱离body的范围,我们可以从1和2看到,当top小于body的margin的时候,它的top是不起作用的,只有当向上滚了50以上之后,你会发现,sticky是基于窗口定位的,笔者很巧的用了100和50这两个值,其实我为什么说和MDN上有区别,就是这个阈值范围是错的,你们可以自己体验一把,可以将margin设成100,top设置成30,你就可以看出阈值是70.
2、第二点,我在放两张图,是sticky和fixed的区别。
你会发现,其实fixed属于脱离文档流,sticky不属于脱离文档流,这点和relative很像,不影响布局,但是会根据位置偏移,但是也没有MDN中所说的阈值变化一说,只能说很像。
这两点是我自己实践出来的,和权威有区别,你们也可以试试,然后我们在评论中可以探讨。
关注新东西时,兼容性总是关键,掌握他也得从这点入手,这样才能挑战移动端的各种机型等等。
我们先看pc端的,IE是完全不支持的,在后面我会讲一种js来实现sticky的效果,其他兼容性还可以,我们可以用到浏览器前缀,来更好的兼容它。何为浏览器前缀,我们举个例子:
.sticky {
position: -webkit-sticky;
position:sticky;
top: 15px;
}
我们先要搞清楚sticky这个属性是怎么来的,sticky的提出是因为屏幕越做越大,但是屏幕大了不适宜阅读,网页主体大小没有多大变化,这样就会导致很多空白区,这些空白区用来干什么呢,打广告呗,还有就是用来做导航条,不需要考虑内容已开始就被导航条遮盖的情况,导航条的情况属于大多数,我们可以用js来模拟一下:
HTML
<div class="header"></div> CSS
.sticky {
position: fixed;
top: 0;
}
.header {
width: 100%;
background: red;
height:100px;}JS
const header = document.querySelector('.header');
const origOffsetY = header.offsetTop;
function onScroll(e) {
window.scrollY >= origOffsetY ? header.classList.add('sticky') : header.classList.remove('sticky');
}
document.addEventListener('scroll', onScroll);这个原理就是监听滚动事件,然后给元素添加position:fixed属性,我模拟的这个有两点做的不够好:
1、滚动事件触发的太频繁,没有用节流函数,也算我懒吧,大家用的时候要注意
2、还有一点就是那个我上面指出的第二点,未滚动时,那个类似于relative的状态我模拟不出来,或者就是那个第二点我理解错误,有什么想法,可以一起在评论中交流。
这种属性,自己摸索一边真的有助于掌握,这篇博文,是我摸索的结果,我信我自己没有出错,如果有意见不符可以在评论中探讨,本来还有几个例子的,但是我觉得直接放代码晦涩难懂,又没有一种好的方式,不知道掘金允不允许将jsbin嵌到页面中,自己也没尝试,不过,我觉得我已经把特性搞懂了,也尽最大努力把它讲明白,还是建议自己实践一遍,如果喜欢给个喜欢,关注,或者去我的github点个star,对我的支持是我在前端探索的最大动力,谢谢。
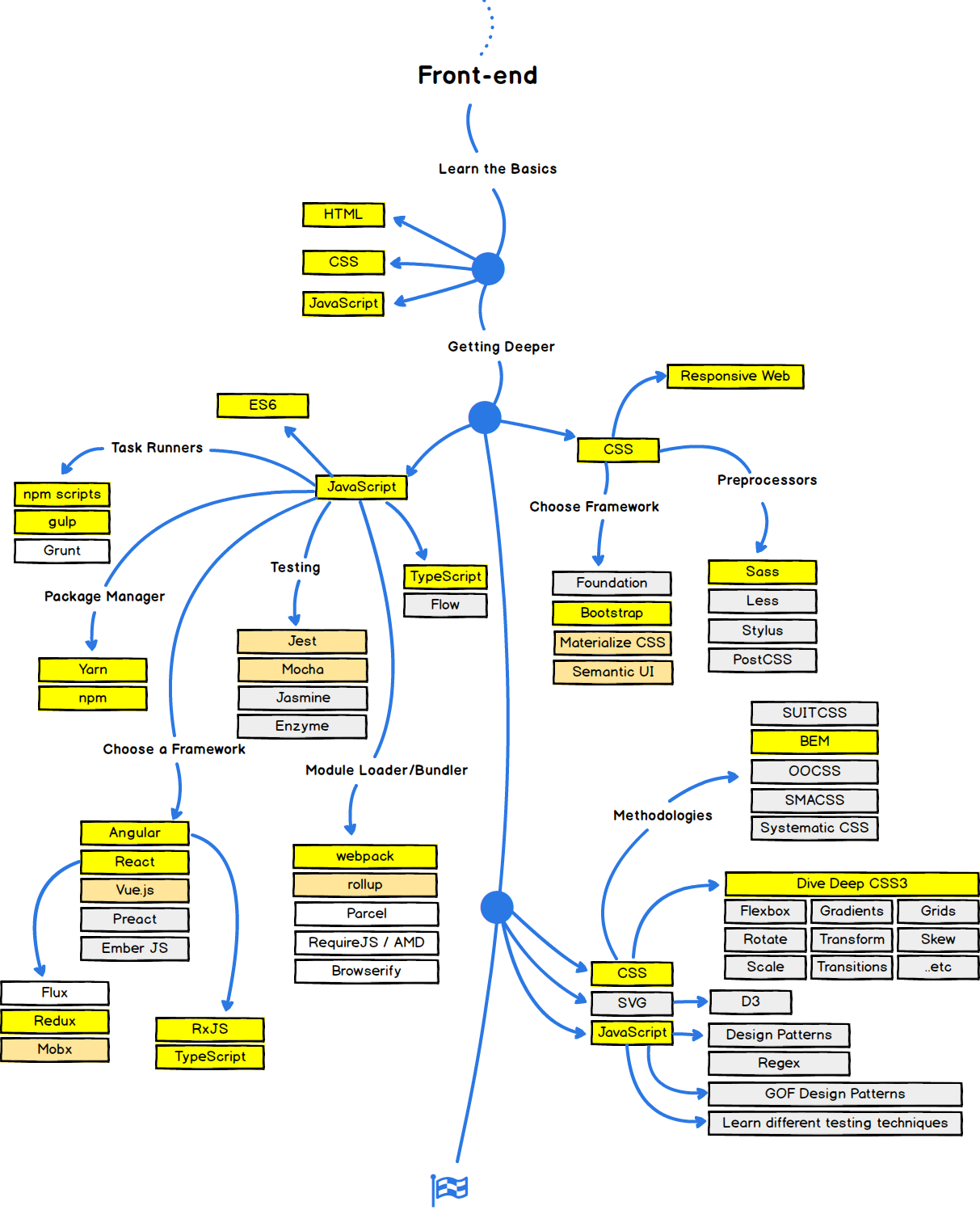
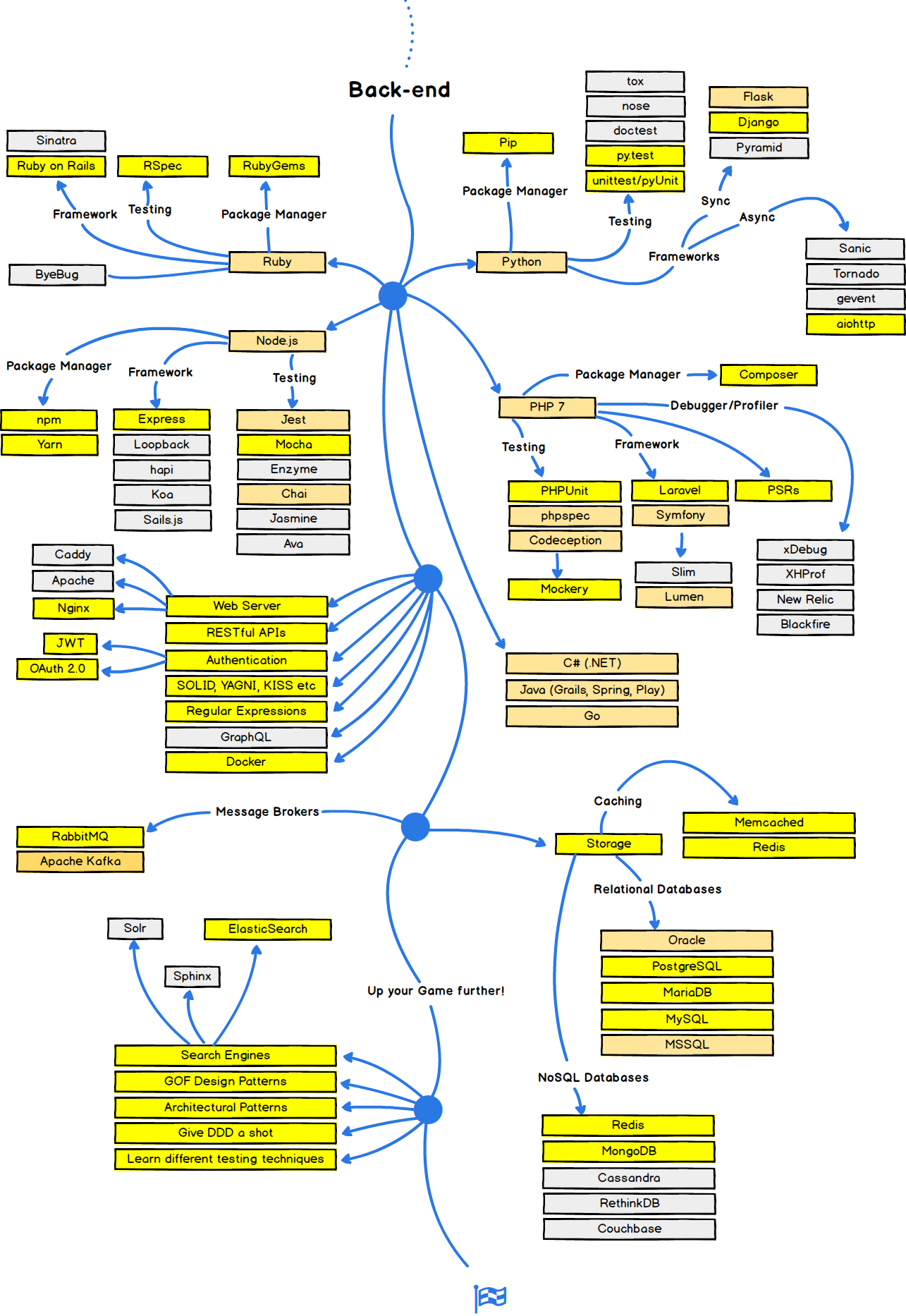
学前端也快一年了,最近想试试大公司的面试,然后这里把所有的知识点都整理出来,然后慢慢消化。该片总字数:1861,速读三分半钟,普通阅读五分钟。有兴趣的可以关注一下我的blog
语法、数据类型、运算、对象、function、继承、闭包、作用域、原型链、事件、RegExp、JSON、Ajax、DOM、BOM、内存泄漏、跨域、异步加载、模板引擎、前端MVC、前端MVVM、路由、模块化、Http、Canvas、jQuery、EMCAScript、ES6、NodeJS、Vue、React
一般来说,一个函数是可以供外部调用的“子程序”(或者供内部调用比如递归),在JS中,函数是一等公民,因为它可以像任何对象一样拥有方法和属性。与其他对象的区别是可以被调用。
函数的定义中有两种函数声明和函数表达式,而函数声明就是其中的一种。
function name([param[,param[,...param]]]){statements}不以function开头的就是函数表达式。
var myFunction = function() {
statements
}当函数只使用一次时,一般使用IIFE,如以下这种形式
(function() {
statements
})();IIFE是在函数声明后立即调用的函数表达式。
我们先来举个例子:
//函数声明
function foo() {}
//函数表达式
var foo = function () {}方法一和方法二都是创建一个函数,且都是命名为foo,但是两者还是有区别的,js解析器中存在一种变量(函数)声明被提升的机制,也就是说变量(函数)声明会被提升到最前端,即使写在最后面的也会被提升到最前方。
我们可以看个例子:
console.log(foo); // function foo() {}
console.log(bar); // undefined
function foo() {}
var bar = function bar_fn() {};
console.log(foo); // function foo() {}
console.log(bar); // function bar_fn() {}箭头函数表达书存在着更简短的语法。
//第一种
([param][, param]) => {statements}
//第二种
param => expression参数名称,零参数需要用()表示,只有一个参数的时候不需要用括号
多个声明statements需要用大括号扩起来,单个的时候不需要。expression也表示隐式返回值。
举两个例子:
//第一种
(a, b) => {
var c = a + b;
return c;
}
//第二种
n => n + 1从ES6开始,在严格模式下禁止使用块里的函数作用域。举个例子
'use strict';
function f() {
return 1;
}
//block-level函数
{
function f() {
return 2;
}
}
f() === 1;// true在非严格模式下,也不要用。块中的函数声明表现奇怪。
if (shouldDefineZero) {
function zero() { // DANGER: 兼容性风险
console.log("This is zero.");
}
}在ES6中,shouldDefineZero为false,那么zero永远不会被定义,但是存在历史遗留问题,ES6是新的标准,但是在以前,无论这个块是否执行,一些浏览器都会定义zero。
更加安全的方式是使用函数表达式:
var zero;
if (0) {
zero = function() {
console.log("This is zero.");
};
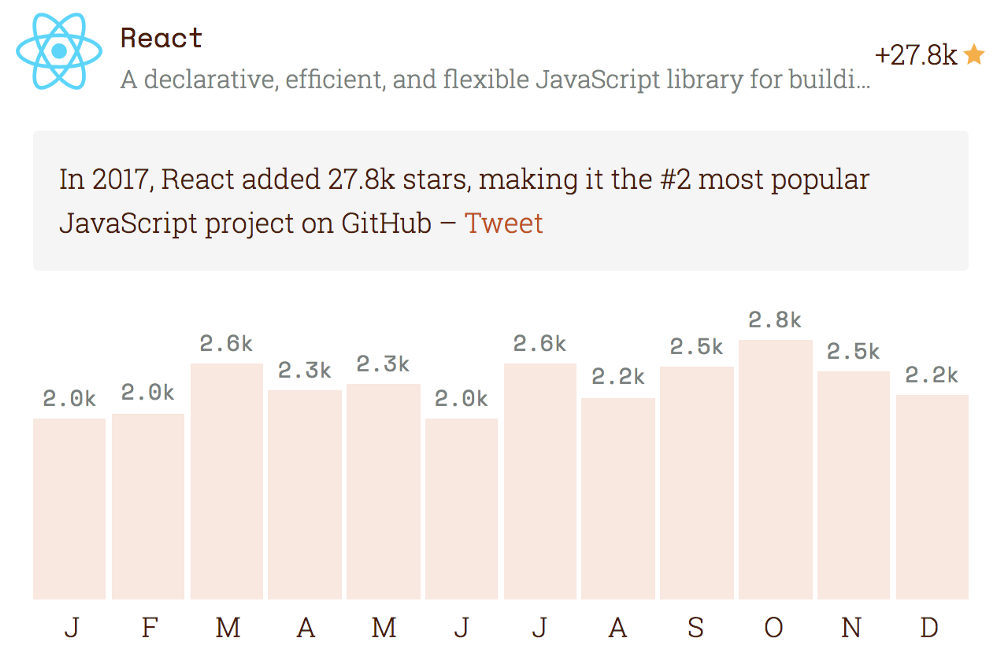
}和去年一样,vue是js项目中点赞数增加最多的,我们可以看下图:
这并不代表是最受欢迎项目,在项目总的点赞数量上依旧是react(86102 stars),但是确实是增长速度最快的,如果按照这个速率,接下来有可能会超过react。
如果vue是成功的,那么无疑react表现的更加不错。
虽然react点赞增加速率不很快(对于一个老项目来说,我们应该满足),但是react的成功更倾向于看他的生态圈,如下图:
前五个项目的总star数超过67.9K,和vue的44.4K比无疑是成功的。
react经历了许可证的闹剧之后,它的最大的障碍也不复存在了,我们可以一起来见证它在2018能够带来什么新的东西。
parcel在一个月内增加的点赞数量可以超过大多数项目一年增加的。
你可能不能想象,一个12月份才推出的项目,点赞数的增加量可以排到年度的第12名,哈哈哈
甚至超过了webpack,就单单一个月哈,我已经抑制不住好奇心了!!!
三大框架的战争应该已经告一段落,总结所有框架一年的star增长量,如下图:
位列前三的框架(Vue、React和Angular),还有一些更小的框架比如preact(这个在react许可证闹剧的时候听说),还有一些自己没有接触没有用过的(Hyperapp、dva等)。
虽然三大框架各有千秋,但是从流行度和生态圈来讲,已经不能像以前一样同日而语了。
但是你还是可以选择使用任何一门框架,但是他们不在具有一样的势头了。
优胜劣汰,或许也是另一种美好,至少不用像我学前端的时候一样,需要去考虑先学哪个,哪个才是潮流。
2017年最成功编译工具无疑是vscode。vscode在编辑器中star增加量毫无悬念是第一名,然后他在受欢迎度排行中排到了第六名,很不错的成绩。
这也证实了VSCode成为我们前端开发者的头号编辑器。
VScode是成功的,但也不是完美的,他有需要改进的地方,按网上的说法,他在用户界面的渲染速度是一个很大缺陷,会导致初始化的时候速度变慢
当然用一句话总结:VSCode比webstorm更轻、比sumlime开源、比atom更快。
GraphQL是facebook在2012年的时候提出,然后在2015年的时候开源,和RESTful对比有优点也有缺点。这是一门查询语言,可能不是主流,但是它强大的功能可能能激起不小的浪花,还是挺期待的,虽然要许久才能用到。
推荐博客
新的打包工具,自己一开始的时候接触过gulp,前端时间搭建公司新项目架子的时候研究过webpack的配置,对于webpack还是挺了解的,webpack需要自己去配置,比如整理entry,output,module,还有一系列的插件,有些许麻烦,不过,webpack有很好的中文文档,但是,新的工具来的势头很猛。看了下面这片博文,知道了点parcel的好处,但是他在2018年还有好多问题要解决,希望我们能用上一个更好的工具。
推荐博客
这个工具在2017年也取得了不小的成就,自动格式化代码,让团队具备统一的代码风格,听起来比eslint还厉害,但是有优点也有缺点,或许在2018年能更智能一点,在配置方面能够更灵活等问题,希望它能变得更好,那我们就又有一个神器了!!!
推荐博客
这个是google发行的,时间好像是8月份,但是还是受到大家的追捧,想了解的也可以了解一下,因为在4个月时间里就可以增加20000stars,
希望2018前端变得更美好,希望自己在2018年还能有过多的产出,希望自己对技术还满怀好奇,有探索的心,希望自己抓住一些不变的东西,巩固自己,充实自己,输出给大家,最后希望学习前端的同志们一起加油!!!个人博客喜欢的可以点个赞,谢谢!!
代理模式是为一个对象提供一个代用品或占位符,以便控制对它的访问。
按职责来划分的话,分为以下8种代理:
1、缓存代理
2、虚拟代理
3、写时复制Copy-on-Write 代理
4、保护(Protect or Access)代理
5、Cache代理
6、防火墙(Firewall)代理
7、同步化(Synchronization)代理
8、智能引用(Smart Reference)代理
在js中常用到的是缓存代理和虚拟代理
// 不使用代理的预加载图片函数如下
var myImage = (function(){
var imgNode = document.createElement("img");
document.body.appendChild(imgNode);
var img = new Image();
img.onload = function(){
imgNode.src = this.src;
};
return {
setSrc: function(src) {
imgNode.src = "loading.gif";
img.src = src;
}
}
})();
// 调用方式
myImage.setSrc("pic.png");var myImage = (function(){
var imgNode = document.createElement("img");
document.body.appendChild(imgNode);
return {
setSrc: function(src) {
imgNode.src = src;
}
}
})();
// 代理模式
var ProxyImage = (function(){
var img = new Image();
img.onload = function(){
myImage.setSrc(this.src);
};
return {
setSrc: function(src) {
myImage.setSrc("loading.gif");
img.src = src;
}
}
})();
// 调用方式
ProxyImage.setSrc("pic.png");1、创建img标签
2、插入img标签
3、创建img对象
4、书写onloading方法
5、返回设置图片对象。
缺点:
1、代码耦合度比较大,一个函数内负责做了几件事情。未满足面向对象设计原则中单一职责原则;
2、当某个时候不需要图片预加载的时候,需要从myImage 函数内把代码删掉,这样代码耦合性太高。
1、myImage中创建img标签
2、myImage中插入img标签
3、myImage中返回设置imgNode的src方法
4、ProxyImage中创建img对象
5、ProxyImage中书写onload方法
6、ProxyImage中返回设置图片的方法。
优点:
1、myImage 函数只负责做一件事。创建img元素加入到页面中,其中的加载loading图片交给代理函数ProxyImage 去做。
2、加载成功以后,代理函数ProxyImage 会通知及执行myImage 函数的方法。
3、当以后不需要代理对象的话,我们直接可以调用本体对象的方法即可
缓存代理,就是将前面使用的值缓存下来,后续还有使用的话,就直接拿出来用。
var add = function(){
var sum = 0
for(var i = 0, l = arguments.length; i < l; i++){
sum += arguments[i]
}
return sum
}
var proxyAdd = (function(){
var cache = {} //缓存运算结果的缓存对象
return function(){
var args = Array.prototype.join.call(arguments)
if(cache.hasOwnProperty(args)){//等价 args in cache
console.log('使用缓存结果')
return cache[args]//直接使用缓存对象的“值”
}
console.log('计算结果')
return cache[args] = add.apply(this,arguments)//使用本体函数计算结果并加入缓存
console.log(cache);
}
})()
console.log(proxyAdd(1,2,3,4,5))
console.log(proxyAdd(1,2,3,4,5))
console.log(proxyAdd(1,2,3,4,5))
// 输出结果
计算结果
15
使用缓存结果
15
使用缓存结果
15两者的职责划分:add函数提供计算功能。proxyAdd提供访问add函数的功能和缓存功能。
const target = {}, handler = {}
const proxy = new Proxy(target, handler)target是目标对象,handler是处理函数。
var handler = {
get: function() {},
set: function() {},
apply: function() {},
construct: function() {},
}参数:目标对象、属性名、proxy实例本身
例子:
var person = {
name: "张三"
};
var proxy = new Proxy(person, {
get: function(target, property) {
if (property in target) {
return target[property];
} else {
throw new ReferenceError("Property \"" + property + "\" does not exist.");
}
}
});
proxy.name // "张三"
proxy.age // 抛出一个错误参数:目标对象、属性名、属性值、proxy实例本身
例子:
let validator = {
set: function(obj, prop, value) {
if (prop === 'age') {
if (!Number.isInteger(value)) {
throw new TypeError('The age is not an integer');
}
if (value > 200) {
throw new RangeError('The age seems invalid');
}
}
// 对于满足条件的 age 属性以及其他属性,直接保存
obj[prop] = value;
}
};
let a = {}
let person = new Proxy(a, validator);
person.age = 100;
a.age // 100
person.age = 'young' // 报错
person.age = 300 // 报错参数:目标对象,目标对象的上下文,参数组
例子:
var target = function () { return 'I am the target'; };
var handler = {
apply: function () {
return 'I am the proxy';
}
};
var p = new Proxy(target, handler);
p() // I am the proxy当调用p函数时,就会被proxy拦截,返回I am the proxy。
construct方法用于拦截new指令。
参数:目标对象、构造函数的参数对象
例子:
var P = new Proxy(function () {}, {
construct: function(target, args) {
console.log('called: ' + args.join(', '));
return { value: args[0] * 10 };
}
});
const p = new P(1);
// "called: 1"
p.value
// 10let myImage = (function(){
var imgNode = document.createElement("img");
document.body.appendChild(imgNode);
return {
setSrc: function(src) {
imgNode.src = src;
}
}
})();
let myImageProxy = new Proxy(myImage, {
apply(target, ctx, arguments) {
let img = new Image
img.onload = function(){
// 图片加载完成,正式加载图片
target.call(ctx, ...arguments)
}
// 图片未被载入时,加载一张提示图片
target.call(ctx, 'file://c:/loading.png')
img.src = arguments[0]
}
})
// 调用
let myImg = new myImageProxy(document)
myImg.setSrc('http://images/qq.jpg')在平常开发中,当我们需要用一个模块的时候,只需要require一下就行了,但是对于其内部的原理,不一定都清楚。读《深入浅出的nodejs》的时候,我们会发现,书中提到,每一个模块在编译过程中,node都会在模块外面封装一层,(function(exports, require, module, __filename, __dirname){})。但是真正调用require的时候,发生了什么,必须得细究一下。
Module.prototype.require = function(id) {
if (typeof id !== 'string') {
throw new ERR_INVALID_ARG_TYPE('id', 'string', id);
}
if (id === '') {
throw new ERR_INVALID_ARG_VALUE('id', id,'must be a non-empty string');
}
return Module._load(id, this, /* isMain */ false);
};Module._load = function(request, parent, isMain) {
if (parent) {
debug('Module._load REQUEST %s parent: %s', request, parent.id);
}
var filename = Module._resolveFilename(request, parent, isMain);
var cachedModule = Module._cache[filename];
if (cachedModule) {
updateChildren(parent, cachedModule, true);
return cachedModule.exports;
}
if (NativeModule.nonInternalExists(filename)) {
debug('load native module %s', request);
return NativeModule.require(filename);
}
// Don't call updateChildren(), Module constructor already does.
var module = new Module(filename, parent);
if (isMain) {
process.mainModule = module;
module.id = '.';
}
Module._cache[filename] = module;
tryModuleLoad(module, filename);
return module.exports;
};从上述两个函数中,require的大致过程如下:
1、先检测传入的id是否有效。
2、如果有效,则调用Module._load方法,该方法主要负责加载新模块和管理模块的缓存,而require本身就是对该方法的一个封装。
3、然后会调用Module._resolveFilename去取文件地址。
4、判断是否有缓存模块,如果有返回缓存模块的exports。
5、如果没有缓存,在检测文件名是否是核心模块,如果是调用核心模块的require。
6、如果不是核心模块,那么,创建新的一个module对象。
7、在 Module._cache中缓存该对象,
8、返回模块本身的exports对象。
上述的解读中,我们抛开了两个没有谈,一个是Module._resolveFilename()方法,还有一个是tryModuleLoad()方法。
Module._resolveFilename = function(request, parent, isMain, options) {
if (NativeModule.nonInternalExists(request)) {
return request;
}
var paths;
if (typeof options === 'object' && options !== null &&
Array.isArray(options.paths)) {
const fakeParent = new Module('', null);
paths = [];
for (var i = 0; i < options.paths.length; i++) {
const path = options.paths[i];
fakeParent.paths = Module._nodeModulePaths(path);
const lookupPaths = Module._resolveLookupPaths(request, fakeParent, true);
if (!paths.includes(path))
paths.push(path);
for (var j = 0; j < lookupPaths.length; j++) {
if (!paths.includes(lookupPaths[j]))
paths.push(lookupPaths[j]);
}
}
} else {
paths = Module._resolveLookupPaths(request, parent, true);
}
var filename = Module._findPath(request, paths, isMain);
if (!filename) {
var err = new Error(`Cannot find module '${request}'`);
err.code = 'MODULE_NOT_FOUND';
throw err;
}
return filename;
};_resolveFilename的大致流程:
1、查询文件名是否是核心模块,如果是直接返回传入的id
2、因为option没有参数传入,所以会调用 Module._resolveLookupPaths方法去获取路径
3、调用Module._findPath方法
我们可以写如下测试代码:
console.log(require('module')._resolveFilename('./lodash'));
let paths = require('module')._resolveLookupPaths('./lodash');
console.log(paths);
console.log(require('module')._findPath("./lodash", paths[1]));输出的结果:
/Users/laihuamin/Documents/learn-record/node_modules/lodash/lodash.js
[ './lodash',
[ '.',
'/Users/laihuamin/Documents/learn-record/node_modules',
'/Users/laihuamin/Documents/node_modules',
'/Users/laihuamin/node_modules',
'/Users/node_modules',
'/node_modules',
'/Users/laihuamin/.node_modules',
'/Users/laihuamin/.node_libraries',
'/Users/laihuamin/.nvm/versions/node/v6.9.1/lib/node' ] ]
/Users/laihuamin/Documents/learn-record/node_modules/lodash/lodash.js_resolveLookupPaths:其实就是node解析模块中的路径查找,他会向父目录查找,直到根目录为止。
_findPath:其实就是将_resolveLookupPaths查找出来的文件名和文件id向匹配,返回一个文件地址。
function tryModuleLoad(module, filename) {
var threw = true;
try {
module.load(filename);
threw = false;
} finally {
if (threw) {
delete Module._cache[filename];
}
}
}在拿到文件地址之后,module会调用这个方法取tryModuleLoad,去尝试加载模块,如果报错,那么清除模块的缓存。
最近在写一篇weex的webpack配置,刚刚踩坑了,weekpack中会用到path模块,而对于这个模块,我想抽离出来看一下,因为这个用到的还是比较多的,喜欢的朋友可以点个喜欢,或者去我的github点个star也行,谢谢支持,举起小手指点一点哦😯。
node中的路径大致分5类,__dirname,__filename,process.cwd(),./,../,其中前三个都是绝对路径
我们先来看一个简单点的例子
假如,我有一个文件的目录结构如下:
editor/
- dist/
- src/
- task.js
然后我们在task.js文件中写入一下代码
const path = require('path');
console.log(__dirname);
console.log(__filename);
console.log(process.cwd());
console.log(path.resolve('./'));在editor目录下运行node src/task.js,我们可以看到结果如下:
/Users/laihuamin/Documents/richEditor/editor/src
/Users/laihuamin/Documents/richEditor/editor/src/task.js
/Users/laihuamin/Documents/richEditor/editor
/Users/laihuamin/Documents/richEditor/editor
然后我们有可以在src目录下运行这个文件,node task.js,运行结果如下:
/Users/laihuamin/Documents/richEditor/editor/src
/Users/laihuamin/Documents/richEditor/editor/src/task.js
/Users/laihuamin/Documents/richEditor/editor/src
/Users/laihuamin/Documents/richEditor/editor/src
对比两个输出结果,我们可以归纳一下几点:
1.__dirname:返回的是这个文件所在文件夹的位置
2.__filename:你运行命令代表的是文件所在的位置,不管你运行什么命令,都是指向文件
3.process.cwd():你运行node命令所在文件夹的位置,比如你在src目录下运行,那么就是输出到src为止,下面的同理。
讲完前面三个绝对路径,我倒是挺想来聊聊path这个模块的,这个node模块在很多地方都有应用,所以,对于我们来说,掌握他,对我们以后的发展更有利,不用每次看webpack的配置文件还要去查询一下这个api是干什么用的,很影响我们的效率
上面那个网站有详细的api,但是我们这里不用都掌握吧,我就讲几个我遇到过的,我觉得webpack等工程配置中会用到的
这个方法就是把不规范的路径规范化,比如看下面的例子
const path = require('path');
console.log(path.normalize('/foo/bar//baz/asdf/quux/..'));输出结果:
/foo/bar/baz/asdf
const path = require('path');
console.log(path.join('src', 'task.js'));
const path = require('path');
console.log(path.join('dist', 'task.js'));
const path = require('path');
console.log(path.join(''));这么两个的输出结果是:
src/task.js
dist/task.js
.
他的作用也就显而易见,他有一下几条规则:
1.传入的参数是字符串的路径片段,可以是一个,也可以是多个
2.返回的是一个拼接好的路径,但是根据平台的不同,他会对路径进行不同的规范化,举个例子,Unix系统是”/“,Windows系统是”\“,那么你在两个系统下看到的返回结果就不一样。
3.如果返回的路径字符串长度为零,那么他会返回一个'.',代表当前的文件夹。
4.如果传入的参数中有不是字符串的,那就直接会报错
我们先来看个例子,在src目录下的task.js写入
const path = require('path');
console.log(path.parse('/Users/laihuamin/Documents/richEditor/editor'));然后运行node src/task.js之后,输出的结果如下:
{
root: '/',
dir: '/Users/laihuamin/Documents/richEditor',
base: 'editor',
ext: '',
name: 'editor'
}他返回的是一个对象,那么我们来把这么几个名词熟悉一下:
┌────────────────────—————————————————————─┬───────────┐
│ dir │ base │
├────┬ ├─────—─┬───┤
│root│ │ name │ext│
" / Users/laihuamin/Documents/richEditor / editor ''
└────┴────────——————————————————————───—───┴───—───┴───┘
这个表格应该展示的很形象,但是我们还是来解释一下这些名词:
1.root:代表根目录
2.dir:代表文件所在的文件夹
3.base:代表整一个文件
4.name:代表文件名
5.ext: 代表文件的后缀名
那我们根据下面的规则,来看一下下面这个例子,最好自己脑子做一遍
const path = require('path');
console.log(path.parse('/Users/laihuamin/Documents/richEditor/editor/src/task.js'));输出的结果:
{
root: '/',
dir: '/Users/laihuamin/Documents/richEditor/editor/src',
base: 'task.js',
ext: '.js',
name: 'task'
}
你做对了么?0.0
那有了前面这个铺垫,想必这个接口猜也能猜的到了。。。。我们看下面这个例子
const path = require('path');
console.log(path.basename('/Users/laihuamin/Documents/richEditor/editor/src/task.js'));输出的结果是:
task.js
我们还是简单介绍一下,接收两个参数,一个是path,还有一个是ext(可选参数).
const path = require('path')
console.log(path.basename('/Users/laihuamin/Documents/richEditor/editor/src/task.js', '.js'));输出结果:
task
这个接口比basename还要简单,我就不多说了,看例子,看结果
const path = require('path');
console.log(path.basename('/Users/laihuamin/Documents/richEditor/editor/src/task.js'));输出的结果:
/Users/laihuamin/Documents/richEditor/editor/src
注意一下,接收的参数是字符串类型
这个就是展示文件的扩展名,我们得注意几种情况
const path = require('path');
path.extname('index.html');
path.extname('index.coffee.md');
path.extname('index.');
path.extname('index');
path.extname('.index');输出的结果是:
.html
.md
.
''
''
自己注意一下这几个情况
我们通过下面这几个例子先来熟悉一下:
const path = require('path');
console.log(path.resolve('/foo/bar', '/bar/faa', '..', 'a/../c'));输出的结果是
/bar/c
他就相当于一堆cd操作,我们一步一步看
cd /foo/bar/ //这是第一步, 现在的位置是/foo/bar/
cd /bar/faa //这是第二步,这里和第一步有区别,他是从/进入的,也就时候根目录,现在的位置是/bar/faa
cd .. //第三步,从faa退出来,现在的位置是 /bar
cd a/../c //第四步,进入a,然后在推出,在进入c,最后位置是/bar/c
但是这个操作和cd还是有区别的,这个路径不一定要存在,而且最后的可以是文件
这个返回的是from到to的相对路径,什么意思呢,我们看下面的例子就知道了.
const path = require('path');
console.log(path.relative('src/bar/baz', 'src/aaa/bbb'));输出的结果是:
../../aaa/bbb
这些比较实用的方法,分享给大家,自己还是老老实实去看weektool的webpack的配置文件了,喜欢的朋友可以点个喜欢,或者去我的github点个star也行,谢谢支持,举起小手指点一点哦😯。
最近在写业务的时候,总是会遇到一些和vue的生命周期相关的问题,比如:
你用ajax请求数据,然后将数据props到子组件的时候,因为ajax是异步的,然后会发生没有数据。然后查找原因还是自己对这个东西理解不够深入。
什么是生命周期函数?
比如:
mounted: function() {
}
// 或者
mounted() {
}错误的形式:
mounted:() => {
}
在实例初始化之后,数据观测和暴露了一些有用的实例属性与方法。
实例初始化——new Vue()
数据观测——在vue的响应式系统中加入data对象中所有数据,这边涉及到vue的双向绑定,可以看官方文档上的这篇深度响应式原理
深度响应式原理
暴露属性和方法——就是vue实例自带的一些属性和方法,我们可以看一个官网的例子,例子中带$的属性和方法就是vue实例自带的,可以和用户定义的区分开来
var data = { a: 1 }
var vm = new Vue({
el: '#example',
data: data
})
vm.$data === data // => true
vm.$el === document.getElementById('example') // => true
// $watch 是一个实例方法
vm.$watch('a', function (newValue, oldValue) {
// 这个回调将在 `vm.a` 改变后调用
})// 有el属性的情况下
new Vue({
el: '#app',
beforeCreate: function() {
console.log('调用了beforeCreate')
},
created: function() {
console.log('调用了created')
},
beforeMount: function() {
console.log('调用了beforeMount')
},
mounted: function() {
console.log('调用了mounted')
}
})
// 输出结果
// 调用了beforeCreate
// 调用了created
// 调用了beforeMount
// 调用了mounted// 在没有el属性的情况下,没有vm.$mount
new Vue({
beforeCreate: function() {
console.log('调用了beforeCreate')
},
created: function() {
console.log('调用了created')
},
beforeMount: function() {
console.log('调用了beforeMount')
},
mounted: function() {
console.log('调用了mounted')
}
})
// 输出结果
// 调用了beforeCreate
// 调用了created// 在没有el属性的情况下,但是有vm.$mount方法
var vm = new Vue({
beforeCreate: function() {
console.log('调用了beforeCreate')
},
created: function() {
console.log('调用了created')
},
beforeMount: function() {
console.log('调用了beforeMount')
},
mounted: function() {
console.log('调用了mounted')
}
})
vm.$mount('#app')
// 输出结果
// 调用了beforeCreate
// 调用了created
// 调用了beforeMount
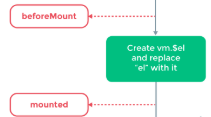
// 调用了mounted这里面分三种情况:
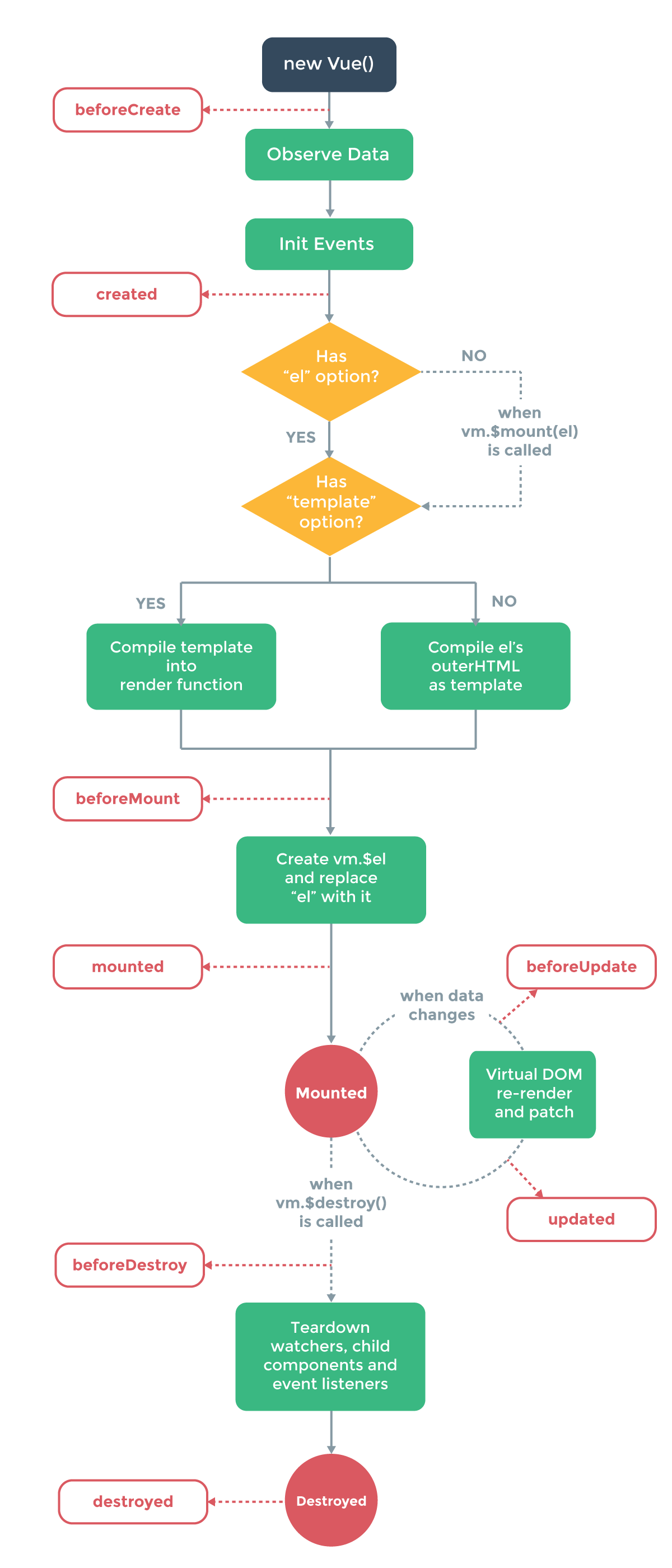
1、在实例内部有template属性的时候,直接用内部的,然后调用render函数去渲染。
2、在实例内部没有找到template,就调用外部的html。实例内部的template属性比外部的优先级高。
3、要是前两者都不满足,那么就抛出错误。
我们来看以下几个例子:
new Vue({
el: '#app',
template: '<div id="app">hello world</div>'
})
//页面上渲染出了hello world<div id="app">hello world</div>
new Vue({
el: '#app'
})
// 页面上渲染出了hello world
//两者都存在的时候
<div id="app">hello world2</div>
new Vue({
el: '#app',
template: '<div id="app">hello world1</div>'
})
// 页面上渲染出了hello world1
从上述的例子可以看出内部的优先外部的。
1、为什么el属性的判断在template之前?
因为el是一个选择器,比如上述例子中我们用到的最多的是id选择器app,vue实例需要用这个el去template中寻找对应的。
2、实际上,vue实例中还有一种render选项,我们可以从文档上看一下他的用法:
new Vue({
el: '#app',
render() {
return (...)
}
})3、上述三者的渲染优先级:render函数 > template属性 > 外部html
4、vue编译过程——把tempalte编译成render函数的过程。
我们先来看一个例子:
<div id="app">
<p>{{message}}</p>
</div>
new Vue({
el: '#app',
data: {
message: 1
},
beforeMount: function() {
console.log('调用了beforeMount');
console.log(this.message)
console.log(this.$el)
},
mounted: function() {
console.log('调用了mounted');
console.log(this.message)
console.log(this.$el)
}
})
// 输出的结果:
// 调用了beforeMount
// 1
// <div>
// </div>
// 调用了mounted
// 1
// <div id="app">
// <p>1</p>
// </div>
创建vue实例的$el,然后用它替代el属性。
这个过程中,我们会发现,当一个数据发生改变时,你的视图也将随之改变,整个更新的过程是:数据改变——导致虚拟DOM的改变——调用这两个生命钩子去改变视图
// 没绑定的情况
var vm = new Vue({
el: '#app',
template: '<div id="app"></div>',
beforeUpdate: function() {
console.log('调用了beforeUpdate')
},
updated: function() {
console.log('调用了uodated')
},
data: {
a: 1
}
})
vm.a = 2
//这种情况在控制台中是什么都不会输出的。var vm = new Vue({
el: '#app',
template: '<div id="app">{{a}}</div>',
beforeUpdate: function() {
console.log('调用了beforeUpdate')
},
updated: function() {
console.log('调用了uodated')
},
data: {
a: 1
}
})
vm.a = 2
// 输出结果:
// 调用了beforeUpdate
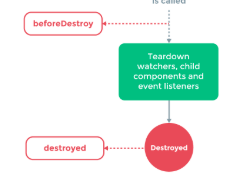
// 调用了uodated在beferoDestory生命钩子调用之前,所有实例都可以用,但是当调用后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。
let vm = new Vue({
el: '#app',
data: {
message: 1
},
template: '<div id="app"><p>{{message}}</p></div>',
beforeCreate() {
console.log('调用了beforeCreate')
console.log(this.message)
console.log(this.$el)
},
created() {
console.log('调用了created')
console.log(this.message)
console.log(this.$el)
},
beforeMount() {
console.log('调用了beforeMount')
console.log(this.message)
console.log(this.$el)
},
mounted() {
console.log('调用了mounted')
console.log(this.message)
console.log(this.$el)
},
beforeUpdate() {
console.log('调用了beforeUpdate')
console.log(this.message)
console.log(this.$el)
},
updated() {
console.log('调用了updated')
console.log(this.message)
console.log(this.$el)
},
beforeDestory() {
console.log('调用了beforeDestory')
console.log(this.message)
console.log(this.$el)
},
destoryed() {
console.log('调用了Destoryed')
console.log(this.message)
console.log(this.$el)
}
})
vm.message = 2
// 调用了beforeCreate
// undefined
// undefined
// 调用了created
// 1
// undefined
// 调用了beforeMount
// 1
// <div></div>
// 调用了mounted
// 1
// <div id="app"><p>1</p></div>
// 调用了beforeUpdate
// 2
// <div id="app"><p>2</p></div>
// 调用了updated
// 2
// <div id="app"><p>2</p></div>移动端真的比pc端难好多,一,移动端分ios和安卓,二,安卓机总类众多,作为一名h5下面是我遇到过的适配问题
想把ES6的所有东西在重新啃一遍,第一篇文章,就从变量声明开始梳理。
用法于ES5中的var一致。
var操作符就存在变量提升现象,你在变量申明之前使用它,变量的值为undefined,并不是报错。
举个例子:
console.log(a); //undefined
var a = 1;
console.log(b); //报错
let b = 2;避免了变量提升的现象,让我们编码过程更加规范。因为按正常逻辑,一个变量需要先申明,后使用。
举个例子:
if(true) {
let i = 1;
console.log(i); // 1
}
console.log(i); // 报错ReferenceErrorlet声明的i变量只会在if这个块中有效,对于外部无效。
块级作用域的好处:
1、防止内部变量影响外部变量,造成不必要的影响。
2、避免循环中的变量泄漏出去变成全局变量。
分为两点:1、不能在相同作用域内申明两次变量。2、不能在函数作用域内申明参数。
if(true) {
let a = 1;
let a = 2; // 报错SyntaxError
}function func(arg) {
let arg = 0; // 报错SyntaxError
}在代码块内,使用let命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”
满足两个条件:
1、用了let或者const指令。
2、在变量申明之前使用。
console.log(a);
let a = 1;这个描述起来很繁琐,但是用一个例子来讲解一下就会很明白。
var a = 1;
window.a // 1
let b = 2;
window.b // undefined在ES6之前,全局变量的赋值和顶层对象的赋值是同一件事情。
而ES6为了改变这一点,在ES6的赋值操作中,都与顶层对象的属性脱钩。比如let、const、class,都不影响顶层对象,而为了兼容ES5,var和function的赋值还是影响顶层对象。
const也具有let的特性。比如:
const是用来申明一个只读常量的。申明的时候必须赋值,不然会发生报错。
const a; //报错SyntaxError1、const保证的是存储变量的内存地址不会发生改变。而不是变量的值不会发生改变。
2、对于Number,String,Boolean而言,本身的值就保存在自身的内存地址,所以等同于变量。如果改变,会发生报错。
3、而对于对象等复合数据类型来说,确保的是内存地址不发生变化,而数据结构不受控制。
ES5中,变量申明的方式有:
ES6中,新增的申明方式有:
梳理这些主要是扎实自己的基础,能更好的服务于业务。同时也希望自己的博客有好的东西和大家分享,如果对以上内容有补充或者质疑的地方,请在评论区留言。
下一篇将给大家带来【ES6】解构赋值(整理篇)
学前端也快一年了,最近想试试大公司的面试,然后这里把所有的知识点都整理出来,然后慢慢消化。该片总字数:2585,速读四分半,普通阅读7分钟。有兴趣的可以关注一下我的blog
语法、数据类型、运算、对象、function、继承、闭包、作用域、原型链、事件、RegExp、JSON、Ajax、DOM、BOM、内存泄漏、跨域、异步加载、模板引擎、前端MVC、前端MVVM、路由、模块化、Http、Canvas、jQuery、EMCAScript、ES6、NodeJS、Vue、React
一个JS的对象可以有很多属性。我们来举个例子:
var myCar = new Object();
myCar.make = "Ford";
myCar.model = "Mustang";
myCar.year = 1969;当一个属性未赋值时值为undefined;
console.log(myCar.noProperty) //undefined当然属性的访问不仅只有点的形式,还可以使用方括号
myCar["make"] = "Ford";原生的三种方法:
定义构造函数
function Car(make, model, year) {
this.make = make;
this.model = model;
this.year = year;
}new创建一个新的实例对象
var mycar = new Car("Eagle", "Talon TSi", 1993);var myCar = {
make: 'Eagle',
model: 'Talon TSi',
year: 1993
}//创建一个原型为null的空对象
var o = Object.create(null);
//创建一个原型为空对象的,拥有属性值p,值为24
var o = Object.create({}, {p: {value: 24}})
console.log(o.p); //24
//该属性值是只可读,不可写、不可枚举、不可配置
//以下对象的p属性是可读可写可配置可枚举。
var o2 = Object.create({}, {
p: {
value: 24,
writable: true,
enumerable: true,
configurable: true
}
})this在这里指的是上下午指针,很多情况我们都用它来代表一个对象,我们可以看一段下面的代码:
//方法
function validate(obj, lowval, hival) {
if ((obj.value < lowval) || (obj.value > hival)) {
alert("Invalid Value!");
}
}<input type="text" name="age" size="3"
onChange="validate(this, 18, 99)">这里的this代表的就是input这个dom节点。当然它还有好多方面,以后我们细讲。
getter是一个获取对象某个值的方法,而setters是一个设置对象某个值的方法。我们来看一下他们的使用:
var o = {
a: 7,
get b() {
return this.a + 1;
},
set c(d) {
this.a = d / 2;
}
}
console.log(o.a); //7
console.log(o.b); //8
o.c = 50;
console.log(o.a); //25上述过程就是:
先输出o中a的属性值,
在输出o中b的属性值,等于a + 1,
再设定o中a的值,
最后输出设定过的a的值。
var d = Date.prototype;
Object.defineProperty(d, "year", {
get: function() { return this.getFullYear() },
set: function(y) { this.setFullYear(y) }
});例子中的getFullYear和setFullYear,指的是其他的方法。
当然我们还可以用Object.defineProperties方法来把第一个例子改的更具可读性。
var o = { a:0 }
Object.defineProperties(o, {
"b": { get: function () { return this.a + 1; } },
"c": { set: function (x) { this.a = x / 2; } }
});
o.c = 10;
console.log(o.b);对象是一个引用类型,两个独立声明的对象永远不可能相等,即使值相同也是,我们看下面的例子:
var fruit = {name: "apple"};
var fruitbear = {name: "apple"};
fruit == fruitbear // return false
fruit === fruitbear // return false只有两个对象的引用相同的时候才会返回true。
// 两个变量, 同一个对象
var fruit = {name: "apple"};
var fruitbear = fruit; // 将fruit的对象引用(reference)赋值给 fruitbear
// 也称为将fruitbear“指向”fruit对象
// fruit与fruitbear都指向同样的对象
fruit == fruitbear // return true
fruit === fruitbear // return truesetTimeout(cb, time);
setTimeout传入的是两个参数,第一个参数是cb代表的是回调函数callback,第二个代表的是时间,以ms计算
setInterval(cb, time);
setInterval传入的也是两个参数,第一个参数是cb代表的是回调函数callback,第二个代表的也是时间,以ms计算
setTimeout含义是定时器,到达一定的时间触发一次,但是setInterval含义是计时器,到达一定时间触发一次,并且会持续触发
function run() {
//其他代码
setTimeout(function(){
run();
}, 10000);
}
setInterval(function(){
run();
}, 10000);上面的代码还是有区别的:
第一段代码使用的是setTimeout来实现的,这个实现就有一个缺点,就是setTimeout是在代码的执行时间上加10秒,比如run()执行了100s,而整个过程可能是110s,
第二段代码就不一样了,setInterval是当run()跑了不到10s,那么就是10s走一回,如果setInterval大于10s,我们后面详解。
setInterval(function(){
// ...
}, 100)第一个当执行时间小于100ms的时候

我们先看类似于150ms的,当执行完后他会立即触发第二次

那我们来看一下第三种情况,其实根据setInterval的机制,他会抛弃掉中间所发生的,我们用图表来看一看就明白了

var i = 0;
const o = {
i: 1;
fn: function(){
console.log(this.i);
}
}
setTimeout(o.fn, 1000); //0这里可以看出,如果是o对象调用的话,就会是1,但是他输出的确实0,因为有两点原因:
1.setTimeout是运行在全局环境下的
2.其实他是发生了下面的步骤:
var a = o.fn;
a();
//只有这样,this才会被绑定到全局上去其实不是的,我们先来看一下,setTimeout的一个面试中经常会问到的问题
setTimeout(function(){
console.log(1);
},0);
console.log(2);其实这个特性说来话长,输出的是先2后1,因为setTimeout会把第一个函数放进任务队列,然后走一个event loop,所以会先输出的是2,才会输出1
那我们试想一下,这个特性我们可以用来做什么?当事件冒泡的时候,会正常情况下,会先触发子元素,然后在触发父元素,那么我们使用这个特性是不是能让其先触发父元素,在触发子元素,(题主没试过)
这篇文章就写到这儿,后面会出一篇定时器和事件循环的博客总结
最近给团队分享了一篇babel原理,然后我把他整理成一篇blog,本篇总字数6059(含代码),速读3分钟,普通阅读5分钟,有兴趣的可以关注一下我的github博客
我们来看一段代码:
[1,2,3].map(n => n + 1);经过babel之后,这段代码变成了这样:
[1, 2, 3].map(function (n) {
return n + 1;
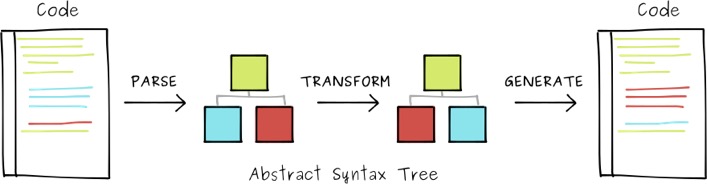
});babel的过程:解析——转换——生成。
这边又一个中间的东西,是抽象语法树(AST)
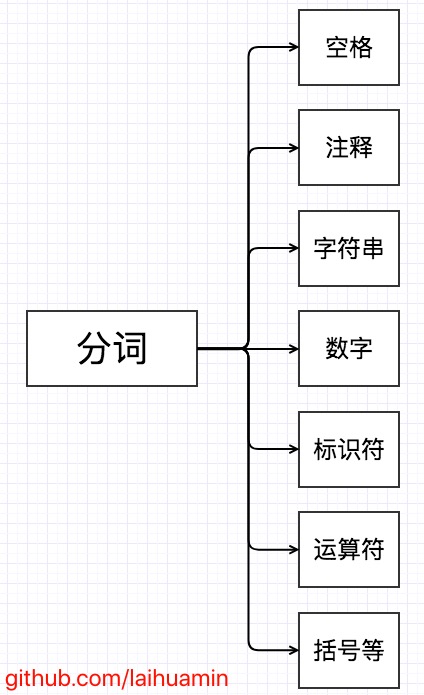
一个js语句是怎么被解析成AST的呢?这个中间有两个步骤,一个是分词,第二个是语义分析,怎么理解这两个东西呢?
什么叫分词?
比如我们在读一句话的时候,我们也会做分词操作,比如:“今天天气真好”,我们会把他切割成“今天”,“天气”,“真好”。
那换成js的解析器呢,我们看一下下面一个语句console.log(1);,js会看成console,.,log,(,1,),;。
所以我们可以把js解析器能识别的最小词法单元。
当然这样的分词器我们可以简易实现一下。
//思路分析:传入的是字符串的参数,然后每次取一个字符去校验,用if语句去判断,然后最后结果存入一个数组中,对于标识符和数字进行特殊处理
function tokenCode(code) {
const tokens = [];
//字符串的循环
for(let i = 0; i < code.length; i++) {
let currentChar = code.charAt(i);
//是分号括号的情况
if (currentChar === ';' || currentChar === '(' || currentChar === ')' || currentChar === '}' || currentChar === '{' || currentChar === '.' || currentChar === '=') {
// 对于这种只有一个字符的语法单元,直接加到结果当中
tokens.push({
type: 'Punctuator',
value: currentChar,
});
continue;
}
//是运算符的情况
if (currentChar === '>' || currentChar === '<' || currentChar === '+' || currentChar === '-') {
// 与上一步类似只是语法单元类型不同
tokens.push({
type: 'operator',
value: currentChar,
});
continue;
}
//是双引号或者单引号的情况
if (currentChar === '"' || currentChar === '\'') {
// 引号表示一个字符传的开始
const token = {
type: 'string',
value: currentChar, // 记录这个语法单元目前的内容
};
tokens.push(token);
const closer = currentChar;
// 进行嵌套循环遍历,寻找字符串结尾
for (i++; i < code.length; i++) {
currentChar = code.charAt(i);
// 先将当前遍历到的字符无条件加到字符串的内容当中
token.value += currentChar;
if (currentChar === closer) {
break;
}
}
continue;
}
if (/[0-9]/.test(currentChar)) {
// 数字是以0到9的字符开始的
const token = {
type: 'number',
value: currentChar,
};
tokens.push(token);
for (i++; i < code.length; i++) {
currentChar = code.charAt(i);
if (/[0-9\.]/.test(currentChar)) {
// 如果遍历到的字符还是数字的一部分(0到9或小数点)
// 这里暂不考虑会出现多个小数点以及其他进制的情况
token.value += currentChar;
} else {
// 遇到不是数字的字符就退出,需要把 i 往回调,
// 因为当前的字符并不属于数字的一部分,需要做后续解析
i--;
break;
}
}
continue;
}
if (/[a-zA-Z\$\_]/.test(currentChar)) {
// 标识符是以字母、$、_开始的
const token = {
type: 'identifier',
value: currentChar,
};
tokens.push(token);
// 与数字同理
for (i++; i < code.length; i++) {
currentChar = code.charAt(i);
if (/[a-zA-Z0-9\$\_]/.test(currentChar)) {
token.value += currentChar;
} else {
i--;
break;
}
}
continue;
}
if (/\s/.test(currentChar)) {
// 连续的空白字符组合到一起
const token = {
type: 'whitespace',
value: currentChar,
};
// 与数字同理
for (i++; i < code.length; i++) {
currentChar = code.charAt(i);
if (/\s]/.test(currentChar)) {
token.value += currentChar;
} else {
i--;
break;
}
}
continue;
}
throw new Error('Unexpected ' + currentChar);
}
return tokens;
}语义分析的话就比较难了,为什么这么说呢?
因为这个不像分词这样有个标准,有些东西都要靠自己去摸索。
其实语义分析分为两块,一块是语句,还有一块是表达式。
什么叫语句?什么叫表达式呢?
表达式,比如:a > b; a + b;这一类的,可以嵌套,也可以运用在语句中。
语句,比如:var a = 1, b = 2, c =3;等,我们理解中的一个语句。类似于语文中的一个句子一样。
当然,有人会问,console.log(1);这个算什么呢。
其实这种情况可以归为一类,单语句表达式,你既可以看作表达式,也可以看作语句,一个表达式单成一个语句。
既然分完了,我们也可以尝试这来写一下,简单点的语句分析。
比如var定义语句,或者复杂点的if语句块。
生成AST的形式可以参考这个网站,AST的一些语法可以从这个网站试出个大概
//思路分析:既然分三种情况,那么我们也从语句,表达式,单语句表达式入手,我们先定义一个方法用来分析表达式,在定义一个方法来分析语句,最后在定义一个方法分析单语句表达式。整个过程也是分为那么几步。就多了对于指针的管控。
function parse (tokens) {
// 位置暂存栈,用于支持很多时候需要返回到某个之前的位置
const stashStack = [];
let i = -1; // 用于标识当前遍历位置
let curToken; // 用于记录当前符号
// 暂存当前位置
function stash () {
stashStack.push(i);
}
// 往后移动读取指针
function nextToken () {
i++;
curToken = tokens[i] || { type: 'EOF' };;
}
function parseFalse () {
// 解析失败,回到上一个暂存的位置
i = stashStack.pop();
curToken = tokens[i];
}
function parseSuccess () {
// 解析成功,不需要再返回
stashStack.pop();
}
const ast = {
type: 'Program',
body: [],
sourceType: "script"
};
// 读取下一个语句
function nextStatement () {
// 暂存当前的i,如果无法找到符合条件的情况会需要回到这里
stash();
// 读取下一个符号
nextToken();
if (curToken.type === 'identifier' && curToken.value === 'if') {
// 解析 if 语句
const statement = {
type: 'IfStatement',
};
// if 后面必须紧跟着 (
nextToken();
if (curToken.type !== 'Punctuator' || curToken.value !== '(') {
throw new Error('Expected ( after if');
}
// 后续的一个表达式是 if 的判断条件
statement.test = nextExpression();
// 判断条件之后必须是 )
nextToken();
if (curToken.type !== 'Punctuator' || curToken.value !== ')') {
throw new Error('Expected ) after if test expression');
}
// 下一个语句是 if 成立时执行的语句
statement.consequent = nextStatement();
// 如果下一个符号是 else 就说明还存在 if 不成立时的逻辑
if (curToken === 'identifier' && curToken.value === 'else') {
statement.alternative = nextStatement();
} else {
statement.alternative = null;
}
parseSuccess();
return statement;
}
// 如果是花括号的代码块
if (curToken.type === 'Punctuator' && curToken.value === '{') {
// 以 { 开头表示是个代码块
const statement = {
type: 'BlockStatement',
body: [],
};
while (i < tokens.length) {
// 检查下一个符号是不是 }
stash();
nextToken();
if (curToken.type === 'Punctuator' && curToken.value === '}') {
// } 表示代码块的结尾
parseSuccess();
break;
}
// 还原到原来的位置,并将解析的下一个语句加到body
parseFalse();
statement.body.push(nextStatement());
}
// 代码块语句解析完毕,返回结果
parseSuccess();
return statement;
}
// 没有找到特别的语句标志,回到语句开头
parseFalse();
// 尝试解析单表达式语句
const statement = {
type: 'ExpressionStatement',
expression: nextExpression(),
};
if (statement.expression) {
nextToken();
return statement;
}
}
// 读取下一个表达式
function nextExpression () {
nextToken();
if (curToken.type === 'identifier' && curToken.value === 'var') {
// 如果是定义var
const variable = {
type: 'VariableDeclaration',
declarations: [],
kind: curToken.value
};
stash();
nextToken();
// 如果是分号就说明单句结束了
if(curToken.type === 'Punctuator' && curToken.value === ';') {
parseSuccess();
throw new Error('error');
} else {
// 循环
while (i < tokens.length) {
if(curToken.type === 'identifier') {
variable.declarations.id = {
type: 'Identifier',
name: curToken.value
}
}
if(curToken.type === 'Punctuator' && curToken.value === '=') {
nextToken();
variable.declarations.init = {
type: 'Literal',
name: curToken.value
}
}
nextToken();
// 遇到;结束
if (curToken.type === 'Punctuator' && curToken.value === ';') {
break;
}
}
}
parseSuccess();
return variable;
}
// 常量表达式
if (curToken.type === 'number' || curToken.type === 'string') {
const literal = {
type: 'Literal',
value: eval(curToken.value),
};
// 但如果下一个符号是运算符
// 此处暂不考虑多个运算衔接,或者有变量存在
stash();
nextToken();
if (curToken.type === 'operator') {
parseSuccess();
return {
type: 'BinaryExpression',
operator: curToken.value,
left: literal,
right: nextExpression(),
};
}
parseFalse();
return literal;
}
if (curToken.type !== 'EOF') {
throw new Error('Unexpected token ' + curToken.value);
}
}
// 逐条解析顶层语句
while (i < tokens.length) {
const statement = nextStatement();
if (!statement) {
break;
}
ast.body.push(statement);
}
return ast;
}关于转换和生成,笔者还在研究,不过生成其实就是解析过程的反向,转换的话,还是挺值得深入的,因为AST这东西在好多方面用到,比如:
这篇文章讲完了,其实不理解代码没关系,把整体思路把握住就行。
最近一段时间比较迷茫,不知道这么提升自己的水平,想从js入手在从新温习一遍,突然想把babel啃一遍,自然先从babel的引擎入手。
比较流行的是babel的解析引擎babylon,acron这个比较小巧,资源文档比较多的esprima。
这是源码地址,其他的资源进一步满满整理
babel是现在几乎每个项目中必备的一个东西,但是其工作原理避不开对js的解析在生成的过程,babel有引擎babylon,早期fork了项目acron,了解这个之前我们先来看看这种引擎解析出来是什么东西。不光是babel还有webpack等都是通过javascript parser将代码转化成抽象语法树,这棵树定义了代码本身,通过操作这颗树,可以精准的定位到赋值语句、声明语句和运算语句
我们可以来看一个简单的例子:
var a = 1;
var b = a + 1;我们通过这个网站,他是一个esprima引擎的网站,十分好用.画成流程图如下:
而他的json对象格式是这样的:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "a"
},
"init": {
"type": "Literal",
"value": 1,
"raw": "1"
}
}
],
"kind": "var"
},
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "b"
},
"init": {
"type": "BinaryExpression",
"operator": "+",
"left": {
"type": "Identifier",
"name": "a"
},
"right": {
"type": "Literal",
"value": 1,
"raw": "1"
}
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}chrome有v8,firefix有spidermonkey.还有一些常用的引擎有:
下面是一些引擎的速度对比,以及用不同的框架,引擎们的加载速度:
我个人认为,封装的越完美的,其实解析的时间更长,引擎之间也是acron这个速度比较优秀,babel引擎前身就是fork这个项目的。
我们可以来做一个简单的例子:
1.先新建一个test的工程目录
2.在test工程下安装esprima、estraverse、escodegen的npm模块
npm i esprima estraverse escodegen --save3.在目录下面新建一个test.js文件,载入以下代码:
const esprima = require('esprima');
let code = 'const a = 1';
const ast = esprima.parseScript(code);
console.log(ast);你将会看到输出结果:
Script {
type: 'Program',
body:
[ VariableDeclaration {
type: 'VariableDeclaration',
declarations: [Array],
kind: 'const' } ],
sourceType: 'script' }4.再在test文件中,载入以下代码:
const estraverse = require('estraverse');
estraverse.traverse(ast, {
enter: function (node) {
node.kind = "var";
}
});
console.log(ast);输出的结果:
Script {
type: 'Program',
body:
[ VariableDeclaration {
type: 'VariableDeclaration',
declarations: [Array],
kind: 'var' } ],
sourceType: 'script' }5.最后在test文件中,加入以下代码:
const escodegen = require("escodegen");
const transformCode = escodegen.generate(ast)
console.log(transformCode);输出的结果:
var a = 1;const a = 1转化成了var a = 1有没有babel的感觉0.0
esprima源码
acron源码
speed comparison
AST explorer
esprima可视化
在线可视化AST
抽象树在前端用的很多很多,现在流行的工具,不管是webpack还是babel都会通过那个三板斧的流程,这里我只是大致介绍一下,过段时间,会出一篇抽象树的语法,有兴趣的也可以把esprima的源码看一下,为什么是esprima呢,因为esprima的资料比较多,而acron比较轻量级。有兴趣的可以关注一下我的github,记得点个star,就当是对笔者的支持,谢谢。
学前端也快一年了,最近想试试大公司的面试,然后这里把所有的知识点都整理出来,然后慢慢消化。该片总字数:1494,速读3分钟,普通阅读5分钟。有兴趣的可以关注一下我的blog
语法、数据类型、运算、对象、function、继承、闭包、作用域、原型链、事件、RegExp、JSON、Ajax、DOM、BOM、内存泄漏、跨域、异步加载、模板引擎、前端MVC、前端MVVM、路由、模块化、Http、Canvas、jQuery、EMCAScript、ES6、NodeJS、Vue、React
有三种:var、let、const(具体的知识点放到后面总结)
区分大小写,必须以字母、下划线(_)或者美元符号($)开头,后续可以是数字或字母
声明在所有函数之外的叫全局作用域,可以被这个模块中的所有代码访问。
声明在函数内部的叫局部作用域,只能被该函数内部访问
console.log(a);//undefined
var a = 1;这里就是变量提升的效果,其实相当于发生了以下过程:
var a;
console.log(a)
a = 1;仅对var有效
定义一个函数有两种方式,一个是函数声明,还有一个是函数表达式。而只有函数声明会被提升到顶部,不包括函数表达式。
// 函数声明
foo(); //bar
function foo() {
console.log('bar')
}
//函数表达式
var baz = function() {
console.log('baz');
}JavaScript是一种弱类型或者说动态语言,你不用提前设定变量类型,在运行的时候会自动确定。
var foo = 2; //foo is a Number now
var foo = 'baz' //foo is a String now
var foo = true //foo is Boolean now加上es6的symbol之后就是七个:六个原始类型和一个复杂数据类型
对于JavaScript中,对于参数传递、构造函数带return等情况都是按值传递的,对于引用类型,其实传的是对象的地址。我们可以看一下以下这个例子:
//函数内部参数的改变并没有影响到外部变量
function foo(a) {
a = a * 10;
}
var num = 10;
foo(num);
console.log(num); // 10 没有变化
function bar(b) {
b.item = "new_value"; // 参数b得到了obj1的地址,也叫"指向obj1"
console.log(b === obj1) ; // true
}
var obj1 = {item: "old_value"};
bar(obj1);
console.log(obj1.item); // new_value每一门语言都有一些奇技淫巧,JS也不例外,一直想总结这么篇文章,我包括一些新手,都会有这么一个疑问,每次面对一张空白的页面,不知从何下手,没有思路,高手有的是设计模式,但是在这里讲一些设计模式,我可能不够格,这些书籍都有可以自己去翻阅,我能给的就是,总结我写代码的时候,会优化的一些技巧
我为什么把立即执行放在第一个,因为一般做业务的时候都会有一个入口函数,比如一下这种格式
function init(){
//...
}
init()我一开始也跟上面这样写,但是后来看了《你所不知道的javaScript》,我是这么写的
(function init(){
//...
})()立即执行的好处:
作用域隔离,因为init这个函数名是没有必要在全局作用域中展示的
这个技巧我在业务中也是经常使用的,没学会之前是这么写的
function(){
console.log(12345678901)
}但是学会之后,是这样的
const TEL = 12345678901
function(){
console.log(TEL)
}可能这里有人会问,你这不是多此一举,而且还添加了一个全局常量,但是事实是这样的,好处如下:
这个方法在红宝书中有写到,我不知道常不常用,如有错误,请纠正我,因为我递归一直在用,面试写算法题也在用,没学会之前的写法
function a(){
//...
a();
}学会之后,我的递归一般是这么写的
function a(){
//...
argument.callee();
}解耦的好处:
修改函数名即可,不影响里面的代码
你可能以前看到过parseInt和parseFloat这两个方法来转换成number类型的整数型和浮点型,其实,一开始我也是用这么笨的方法的,为什么说笨呢,举个例子
let str = '123'
console.log(typeof parseInt(str)); //number接下来是加号操作符
let str = '123'
console.log(typeof +str); //number好处就不多说了吧,你打字打得累死,不如加号来的快,而且加号实现方式还优雅
没学会这个方法之前我的代码是这样的:
if(!foo){
foo = bar
}但是我学会短路操作之后的是这样的:
foo = foo || bar好处:
缺点:
代码可读性降低
短路原理:
在js中&&和||这两个操作符有一个特性,比如&&前后有两个表达式,前者为false,后者不会执行,||会反过来
条件表达式或许在每门语言中都会用到,你没学会之前你会这么写
if(a === true){
b = c;
}else{
b = d;
}但是你学会之后,你会这么写
let b = a ? c : d
好处:
1.减少代码量
2.代码优雅
缺点:
代码可读性降低
我没有实习之前不喜欢用alert的,现在也不怎么用,都是console.log,这样就可以在浏览器的控制台中看到页面数据的输出,但是h5不一样,h5有时候pc端没什么问题,但是手机端就是各种bug,想调试一个数据很麻烦,但是我们有个宝贝,alert这个东西在手机端调试比console.log棒的地方就是我们能看见我们的数据,他会以一个弹框的形式显示给我们
向下取整有很多种方式,做常用的,是调用Math的方法,如下图的例子
let num = 1.23
let num1 = Math.floor(num);
console.log(num1); //1
但是下面有一种更加优雅的方式
let num = 1.23
let num1 = num | 0;
console.log(num1) // 1这种方式更加简洁,这种方式的原理是来源于js的位运算,这边的 | 不是逻辑或,是按或运算
在编程中,最好养成一个习惯,一个函数的参数,声明在函数的顶部,然后用这个声明操作符来完成,例如:
let a = 0,
b = 0,
c = 0,
d = 0;这个怎么解释呢?其实es6箭头函数已经解决了,我也当一个技巧跟大家絮叨絮叨,我们在设计整个js代码怎么书写的时候,常常会把一块功能相同的代码放到一块,看看下面的例子,你就懂了
function bindEvent(){
let _this = this;
function a () {
//可以在a中使用_this;
}
function b () {
//可以在b中使用_this;
}
}学前端也快一年了,最近想试试大公司的面试,然后这里把所有的知识点都整理出来,然后慢慢消化。该片总字数:1770,速读三分半,普通6分钟。有兴趣的可以关注一下我的blog
语法、数据类型、运算、对象、function、继承、闭包、作用域、原型链、事件、RegExp、JSON、Ajax、DOM、BOM、内存泄漏、跨域、异步加载、模板引擎、前端MVC、前端MVVM、路由、模块化、Http、Canvas、jQuery、EMCAScript、ES6、NodeJS、Vue、React
运算符分类:赋值运算符、比较运算符、算数运算符、位运算符、逻辑运算符、字符串运算符、条件运算符、逗号运算符、一元运算符、关系运算符
=。| 名字 | 简单操作符 |
|---|---|
| 加法赋值 | x += y |
| 减法赋值 | x -= y |
| 乘法赋值 | x *= y |
| 除法赋值 | x /= y |
| 求余赋值 | x %= y |
| 求幂赋值 | x **= y |
| 左位移赋值 | x <<= y |
| 右位移赋值 | x >>= y |
| 无符号右移位赋值 | x >>>= y |
| 按位与赋值 | x &= y |
| 按位异或赋值 | x ^= y |
| 按位或赋值 | x |
var foo = ["one", "two", "three"];
// 不使用解构
var one = foo[0];
var two = foo[1];
var three = foo[2];
// 使用解构
var [one, two, three] = foo;| 运算符 | 描述 |
|---|---|
| 等于(==) | 操作数两边相等返回true |
| 不等于(!=) | 操作数两边不想等返回true |
| 全等(===) | 操作睡两边相等且数据类型相同返回true |
| 不全等(!==) | 于上述相反 |
| 大于(>) | 左边操作数大于右边操作数返回true |
| 大于等于(>=) | 左边操作数大于等于右边操作数返回true |
| 小于(<) | 左边操作数小于右边操作数返回true |
| 小于等于(<=) | 左边操作数小于等于右边操作数返回true |
算术运算符除了普通的加减乘除(+-*/)
| 运算符 | 例子 |
|---|---|
| 求余(%) | 12 % 5 = 2 |
| 自增(++) | var a = 3;a++;console.log(a);//4 |
| 自减(--) | var a =3;a--;console.log(a);//2 |
| 一元负值符(-) | var a = 3; console.log(-a);//-3 |
| 一元正值符(+) | var a = '3'; console.log(+a);//3 |
| 指数运算符(**) | 2 ** 3 = 8 |
| 符号 | 使用 | 描述 |
|---|---|---|
| 与 | a & b |
在a和b的二进制表示中,每位都是1的时候才返回1 |
| 或 | `a | b` |
| 异或 | a ^ b |
在a和b的二进制表示中,只要a和b的相同位不同就返回1 |
| 非 | ~a |
对a的二进制表示,求反 |
| 左移 | a << b |
把a的二进制串向左移b位,右边移入0 |
| 右移 | a >> b |
把a的二进制串向右移b位,左边移入0 |
| 无符号右移 | a >>> b |
把a的二进制表示向右移动b位,丢弃被移出的所有位,并把左边空出的位都填充为0 |
我们先介绍一下有三个逻辑运算符,然后讲几个运用技巧
| 运算符 | 范例 | 描述 |
|---|---|---|
| 与 | a && b |
a和b全为true的时候返回true |
| 或 | `a | |
| 非 | !a |
如果a为true。那么返回false |
false && anything //返回false
true || anything //返回true
true && anything //anything
false || anything //anything`
条件 ? 值1 : 值2
例如:
var status = (age >= 18) ? "adult" : "minor";
这样会比if-else简便的多。
看到medium上面的一篇外文,就来转发一下,写的主要是前端和后端改如何发展,感觉路线上还是可以的,只是细化部分做的不够,需要自己学到那一块的时候满满细化。
终于毕业了,前段时间被毕业设计搞得头昏脑胀,现在所有事情都搞定了,又要开始定期更新博客了,从这边总结开始,后期挑每个板块好好研究。
作为一门mvvm框架最为出色的地方就是data更新的时候,他就会对相应的dom进行更新,免除了jquery时代对dom更新的操作
Object.defineProperty()这个方法是vue进行双向绑定的核心,我们可以来研究一下这个方法
const obj = {};
Object.defineProperty(obj, 'num', {
enumerable: true,
configurable: true,
get(){
console.log('get');
return 10;
},
set(){
console.log('set');
}
})
console.log(obj.num);
obj.num = 1;
//get
//10
//set
看到这个或许大家会和我一样懵逼,我们可以一起来看看源码,了解一下这是个什么东西
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array<Watcher>;
constructor () {
this.id = uid++
this.subs = []
}
addSub (sub: Watcher) {
this.subs.push(sub)
}
removeSub (sub: Watcher) {
remove(this.subs, sub)
}
depend () {
if (Dep.target) {
Dep.target.addDep(this)
}
}
notify () {
const subs = this.subs.slice()
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}
}这个函数中有id和subs这么两者,一个是身份的代表,每一个dep实例都有一个对应的id,还有一个是本质的代表,dep实例就是一个watcher的数组
Dep的target属性属于每个实例的静态成员,他是一个可选的订阅者类型,所以addDep这个方法在watch的源码中应该会有解释,我们这里大致可以知道,起到的是依赖收集的作用,将相关的收集到一个dep中,更新时,将dep中每一个watch更新一边。
这里第一步做了个slice的处理,其实这个我们在做项目的时候也可以学习,slice方法是不会修改数组,但是他会返回一个子数组,然后在利用循环,将每一个subs的元素遍历一遍,每个都更新一下
watcher的源码过多,我不再这里贴了,给你们一个大致的框架,然后看看里面的方法
export default class Watcher {
//这里定义了在watch中用到的一些属性的类型,TS的语法
vm: Component;
expression: string;
cb: Function;
id: number;
deep: boolean;
user: boolean;
lazy: boolean;
sync: boolean;
dirty: boolean;
active: boolean;
deps: Array<Dep>;
newDeps: Array<Dep>;
depIds: ISet;
newDepIds: ISet;
getter: Function;
value: any;
constructor (
//...
}
get () {
//...
}
addDep (dep: Dep) {
//...
}
cleanupDeps () {
//...
}
update () {
//...
}
run () {
//....
}
evaluate () {
//...
}
depend () {
//...
}
teardown () {
// ...
}
}//constructor中的属性是很多都是每个实例都有的
constructor (vm: Component, expOrFn: string | Function, cb: Function, options?: Object) {
this.vm = vm
vm._watchers.push(this)
if (options) {
this.deep = !!options.deep
this.user = !!options.user
this.lazy = !!options.lazy
this.sync = !!options.sync
} else {
this.deep = this.user = this.lazy = this.sync = false
}
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
this.dirty = this.lazy // for lazy watchers
this.deps = []
this.newDeps = []
this.depIds = new Set()
this.newDepIds = new Set()
this.expression = process.env.NODE_ENV !== 'production'
? expOrFn.toString()
: ''
// parse expression for getter
if (typeof expOrFn === 'function') {
this.getter = expOrFn
} else {
this.getter = parsePath(expOrFn)
if (!this.getter) {
this.getter = function () {}
process.env.NODE_ENV !== 'production' && warn(
`Failed watching path: "${expOrFn}" ` +
'Watcher only accepts simple dot-delimited paths. ' +
'For full control, use a function instead.',
vm
)
}
}
this.value = this.lazy
? undefined
: this.get()
}这篇文章总字数:1214,普通阅读4分钟,速读2分钟,主要讲的是新的打包工具parcel的一些新特性,谢谢,有兴趣朋友可以关注一下我的github上面有30多篇文章,喜欢的可以watch或者star。你的支持是我输出的动力。
今天很高兴来讲一下新的打包工具parcel,一个快速的,零配置的打包工具。可以点击这里看他的github.
为了解决现有webpack等打包工具存在的问题:性能和配置复杂度。我开始研究parcel。
以webpack举例,我认为打包工具是用来减轻前端负担的,但是在webpack上我并没有感觉到,除了需要学习webpack外,配置的时候还是要查询中文文档,因为太多的插件根本不适合记忆,还有性能方面,当页面足够多时,打包的速度开始变得很慢,我记得我们公司一个运营中心的项目,打包时间惨目忍睹。
首先我想说的就是性能,我上面已经说了,当一个项目有好多个页面的时候,你的打包速度真的是慢,webpack也是一样,一个项目要打包上线,这里花的时间,都可以早点下班了,开发过程中也是一样,不过本地的话,你还可以给打包单一几个页面。
很多打包工具都注重于能快速的重新构建,这是伟大的,但是,初次构建的性能对于开发和生产来说是很重要的
parcel解决了这个问题,在编译过程中,并行的编译代码,并使用现代的多核处理器解决这个问题。上述原因影响了初步构建的速度。他也有文件缓存系统,以便于快速的重建。
第二个原因就是帮助我们减轻配置的负担,大多数打包工具是围绕着配置文件建立起来的,配置文件有很多的插件。一个webpack的打包工程500行代码,已经不是什么稀罕的事情了。
这种配置不仅繁琐耗时,而且你不能保证你一定是正确的,还得参照规范改,这可能导致优化应用程序而影响正常的生产
parcel被设计为零配置:只需要应用程序入口给它,他就可以正确的打包。Parcel支持JS,CSS,HTML,图像,文件资产等等 - 不需要任何插件。
parcel的零配置体验还体现在不局限于文件格式,当parcel检测到一个.babelrc, .postcssrc等文件,就会自动转化相应模块,比如Babel, PostCSS和PostHTML。这甚至适用于仅用于该模块的node_modules中的第三方代码,因为应用的使用者,不需要知道构建的时候每一个模块是如何导入的。并且这次构建也没有必要让Babel在每一个文件上的运行
最后,parcel也很好的支持一些先进的打包功能,像代码拆分,热更新等。在生产模式中,还支持自动压缩,未来也可能加入像tree-shaking等优化
开启新项目的好处就是,parcel可以使用现代的体系结构,没有历史包袱,并且在这个体系结构上扩展,更加灵活,并支持代码拆分和热更新等功能。
现在主流的打包工具还是主要关注JavaScript,比如webpack,其他类型的文件也要通过loader将其变成JavaScript来进行打包。
但在parcel中,任何类型的文件都有机会成为一等公民,很容易可以添加一种新类型输入文件,并将类似类型的文件组合到输出文件中
你可以在这个网站上了解更多关于parcel如何工作的
parcel才刚刚开始就收到大众追捧,尝试一下吧
es2015虽然是主流,但是每年都会有新的东西更新,在这些东西中,有许多东西值得我们去学习,以及使用,本篇文章,将提供一些平常业务开发中经常会用到的方法。希望能对大家的学习有帮助。个人的github博客
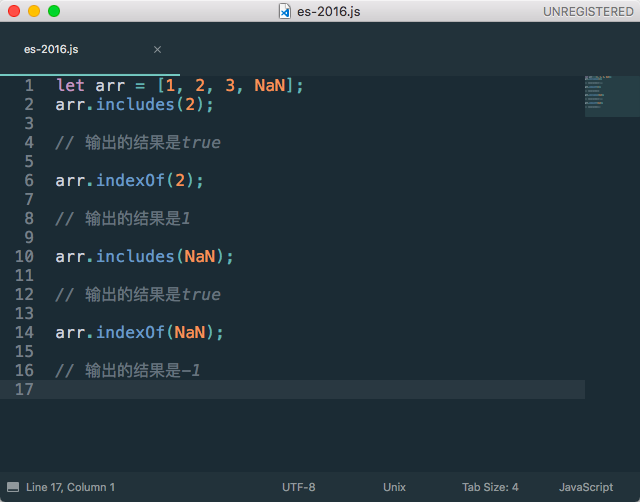
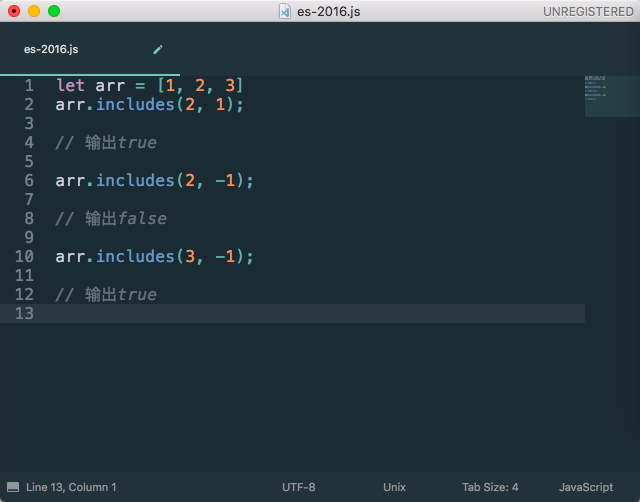
includes这个方法,是检测数组中是否含有相应的元素,返回的值是true和false。与indexOf方法功能相似,但是还会有许多差异性。
其第二个参数还可以代表查询的位置是否正确
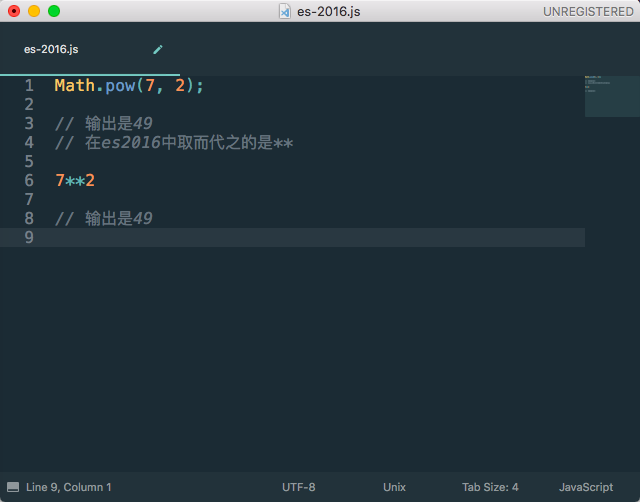
在es2016里面平方操作变得更加渐变,只要使用操作符**就可以实现。
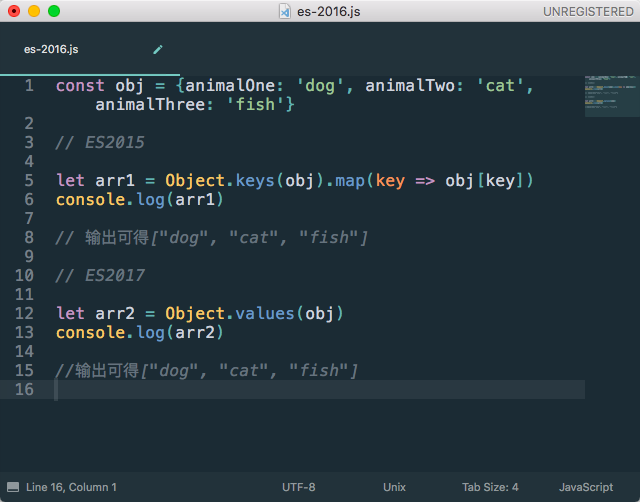
Object.value()的功能其实和Object.keys()相似,主要作用是取得对象的值,放入到数组中,同样不包括任何原型链中的值。
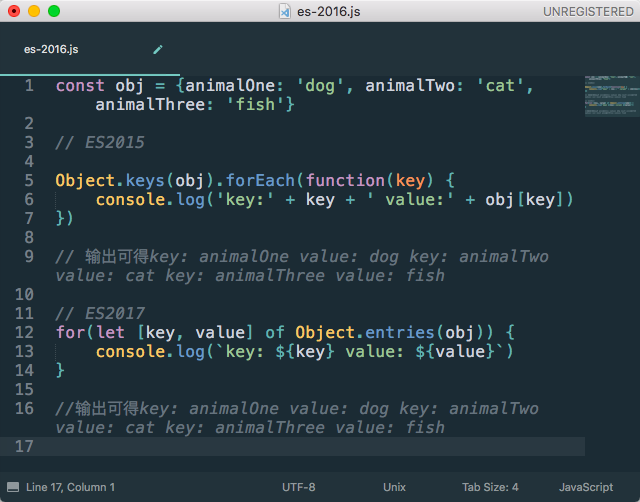
Object.entries()也是和Object.key()相关的,该方法是返回一个数组,数组的元素是对象自身的所有可以遍历的键值对数组
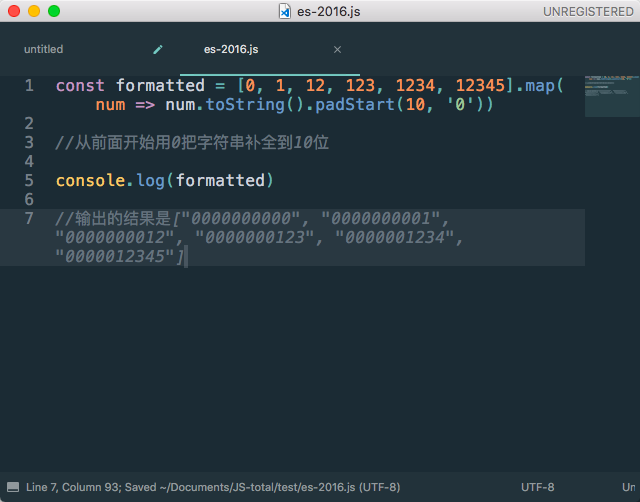
该方法的作用就是用自定义的字符补全字符串的长度,比如我们平常在做的,小于10的时候自动补零就可以用这个实现。
例子1:
该方法和String.padStart相同,只是前者是从字符串的头部开始补全,后者是从字符串的尾部开始补全。
这一篇只是介绍了一些实用的方法,下一篇会具体分析一下async/await。
1.艺龙的面试面试官问到了,让我知道了你想扩展的你的基础,你不能放弃任意一个知识点
2.就是今天做业务碰到了这个bug,肯定有人想知道,这个会产生什么bug,bug一般都是不注意细节,才会导致的,业务中有一个分享到朋友圈和微信好友的一个业务模块,大家都知道,一般这种模块都是要利用客户端给你提供一个hybrid的一个接口,然后,你通过调用这个接口,来完成分享这一个举动,但是在测试的时候并没有发现问题,但是到了线上问题来了,我们一个主管的账号分享不了,但是很多人的账号却可以分享,这种问题是最烦人的,而且更气人的是安卓机都可以分享,那我们是不是该分分锅,ios的锅?还是账号的锅?又或者是前端的锅?故事发展到最后,很多人都忙了一下午来查找bug,我来写这篇文章,肯定说明是前端的锅啊,有人奇怪,这安卓的,ios的部分都是可以的,说明功能没问题,我当时也是这么想的,但是结果却出乎意料,先说说为什么部分ios可以,因为url里面带了昵称参数,一部分人的昵称是英文,一部分是中文,这就是结果——在url中的中文字符都要用base64转成ASCII字符进行传递。
很多不了解的人,应该更关心怎么用,这里我会讲几个web的api,后面一部分博文,可能会深入点,无聊点,程序员写作能力欠缺0.0
这两个接口是我们经常用的,他们的用途一致,是对URL进行编码,但是他们之间还是有区别
总结,encodeURIComponent的编码范围比encodeURI大,我的问题就是用encodeURIComponent解决的
上面的两个对URL进行编码,这个接口就是对字符串进行编码,让字符串可以在所有计算机上被读取,编码之后的效果是%XX或者%uXXXX这种形式。
//举个例子
let str = '来铧敏';
let encodeStr = escape(str);
console.log(encodeStr);//%u6765%u94E7%u654F
这三者是解码用的,分别对应上面的三个,看下面的例子就知道了
let str = '来铧敏';
let encodeStr = escape(str);
console.log(encodeStr);
console.log(unescape(encodeStr));
let _encodeStr = encodeURIComponent(str);
console.log(_encodeStr);
console.log(decodeURIComponent(_encodeStr));
输出结果我就不写了,有几点需要注意,编码和解码需一一对应,默写场景encodeURI进行编码的decodeURIComponent可以解码,但是escape编码的decodeURIComponent解码会报错
URL中允许的只有英文字符,阿拉伯数字,某些标志,你肯定没有看过这样的网站:
http://github.com/laihuamin/来点赞
为什么会上述网站不行呢,因为网络标准RFC 1738做了硬性规定:
原文:"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
用编码可以对前端的一些重要信息进行加密,其实前端并没有上面严格意义上的加密,这里说的加密更多偏向与混淆,我们来实现一个简单点的加密:
//这里实现的是对js代码的加密,这是个例子
console.log('我要加密这个语句');
//下面是加密和解密处理
escape('console.log("我要加密这个语句")')
//先进行编码获得加密后的
const code = unescape(console.log%28%22%u6211%u8981%u52A0%u5BC6%u8FD9%u4E2A%u8BED%u53E5%22%29)
eval(code)说了这么多编码,那到底有多少种编码形式呢?熟悉计算机的朋友应该都听过这样的词汇:ASCII、Unicode、UTF-8、UTF-16等等,那我们就来絮叨絮叨常见的
ASCII码我们在熟悉不过,它是使用8位二进制来表示英文字符和符号,但是吹生出一个问题,中华文化博大精深,光汉字就有几万个,256个字符哪里够用呢。。。。
一个英文字母一个字节足够表示,但是10万个汉字,一个字节怎么够,那就两个呗,256x256才足以表示,中文编码就是GB2312,但在日本或者其他地方就不能使用,所以众多的编码方式,没有统一性
众多的编码方式困扰这大家,电子邮件也时常出现乱码,如果有一种字符集可以把所有的字符都收录进来,不就可以解决问题,Unicode应运而生,Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。
UTF-8是Unicode的一种实现,它是一种可变的编码规则,当在ASCII范围内时,用一个字节读取,如果在范围之外,就用多个字节读取,注意,中文字符在Unicode中是两个字节,在UTF-8中是3个字节,Unicode到UTF-8的转换规则有相应的算法
聊了这么多关于编码的,我简单总结几点:
<meta charset="utf-8">
知识来源网络,实践获得真知,借鉴网络的地方过多,无法著名出处,侵删
cookie在web开发中时常被用到,也是面试官喜欢问的一块技术,很多人或许和我以前一样,只知其一不知其二,谈起web存储,都会答localStorage、sessionStorage、还有就是cookie,然后一些区别啊什么的倒背如流,cookie的优缺点也了然于心,但是当你看完这块内容之后,你会对cookie有另外独到的见解,希望以后问到这块技术,或者项目中遇到这个你都会处理,我在实习的过程中,一直在用,所以它真的不是口头说说的那么简单,让我们进入cookie的世界
这个讲起来很简单,了解http的同学,肯定知道,http是一个不保存状态的协议,什么叫不保存状态,就是一个服务器是不清楚是不是同一个浏览器在访问他,在cookie之前,有另外的技术是可以解决,这里简单讲一下,就是在请求中插入一个token,然后在发送请求的时候,把这个东西带给服务器,这种方式是易出错,所以有了cookie的出现
cookie是什么,cookie就是一种浏览器管理状态的一个文件,它有name,也有value,后面那些看不见的是Domain、path等等,我们后面会介绍
第一次访问网站的时候,浏览器发出请求,服务器响应请求后,会将cookie放入到响应请求中,在浏览器第二次发请求的时候,会把cookie带过去,服务端会辨别用户身份,当然服务器也可以修改cookie内容
我就几个例子你就懂了,当我打开百度的网页,我要设置一个cookie的时候,我的指令如下
javascript:document.cookie='myname=laihuamin;path=/;domain=.baidu.com';javascript:document.cookie='myname=huaminlai;path=/;domain=.google.com';当我将这两个语句都放到浏览器控制台运行的时候,你会发现一点,注意,上面两个cookie的值是不相同的,看清楚
显而易见的是,真正能把cookie设置上去的只有domain是.baidu.com的cookie绑定到了域名上,所以上面所说的不可跨域性,就是不能在不同的域名下用,每个cookie都会绑定单一的域名
cookie的属性众多,我们可以来看一下下面这张图,然后我们一个一个分析
这个显而易见,就是代表cookie的名字的意思,一个域名下绑定的cookie,name不能相同,相同的name的值会被覆盖掉,有兴趣的同学可以试一试,我在项目中切实用到过
这个就是每个cookie拥有的一个属性,它表示cookie的值,但是我在这里想说的不是这个,因为我在网上看到两种说法,如下:
1.cookie的值必须被URL编码
2.对cookie的值进行编码不是必须的,还举了原始文档中所说的,仅对三种符号必须进行编码:分号、逗号和空格
这个东西得一分为二来看,先看下面的图
我在网上看到那么一种说法:
由于cookie规定是名称/值是不允许包含分号,逗号,空格的,所以为了不给用户到来麻烦,考虑服务器的兼容性,任何存储cookie的数据都应该被编码。
这个是指的域名,这个代表的是,cookie绑定的域名,如果没有设置,就会自动绑定到执行语句的当前域,还有值得注意的点,统一个域名下的二级域名也是不可以交换使用cookie的,比如,你设置www.baidu.com和image.baidu.com,依旧是不能公用的
path这个属性默认是'/',这个值匹配的是web的路由,举个例子:
//默认路径
www.baidu.com
//blog路径
www.baidu.com/blog
我为什么说的是匹配呢,就是当你路径设置成/blog的时候,其实它会给/blog、/blogabc等等的绑定cookie
什么是有效期,就是图中的Expires属性,一般浏览器的cookie都是默认储存的,当关闭浏览器结束这个会话的时候,这个cookie也就会被删除,这就是上图中的——session(会话储存)。
如果你想要cookie存在一段时间,那么你可以通过设置Expires属性为未来的一个时间节点,Expires这个是代表当前时间的,这个属性已经逐渐被我们下面这个主人公所取代——Max-Age
Max-Age,是以秒为单位的,Max-Age为正数时,cookie会在Max-Age秒之后,被删除,当Max-Age为负数时,表示的是临时储存,不会生出cookie文件,只会存在浏览器内存中,且只会在打开的浏览器窗口或者子窗口有效,一旦浏览器关闭,cookie就会消失,当Max-Age为0时,又会发生什么呢,删除cookie,因为cookie机制本身没有设置删除cookie,失效的cookie会被浏览器自动从内存中删除,所以,它实现的就是让cookie失效。
这个属性译为安全,http不仅是无状态的,还是不安全的协议,容易被劫持,打个比方,你在手机端浏览网页的时候,有没有**移动图标跳出来过,闲言少叙,当这个属性设置为true时,此cookie只会在https和ssl等安全协议下传输
这个属性是面试的时候常考的,如果这个属性设置为true,就不能通过js脚本来获取cookie的值,能有效的防止xss攻击,看MDN的官方文档:
document.cookie可以对cookie进行读写,看一下两条指令:
//读取浏览器中的cookie
console.log(document.cookie);
//写入cookie
document.cookie='myname=laihuamin;path=/;domain=.baidu.com';
关于怎么设置cookie,我们只要打开控制台,看一个http的请求头和响应头中的东西即可明白:
服务端就是通过setCookie来设置cookie的,注意点,要设置多个cookie时,得多写几个setCookie,我们还可以从上图看到,请求可以携带cookie给后端。
cookie讲了这么多,自己也收获了很多,也希望分享给大家,或许写的不够好,请见谅,如果觉得我写的好的朋友,给个star,github地址
我为什么要写这个呢,以前面试的时候问过这些,还有就是我个人来看,学习前端其实闭包啊,原型啊,等等的问题,被写烂了,但是关于数据交互这一块的很少,我们在业务中,数据交互用的并不占少数,整理一篇给大家,也给我自己,希望喜欢的点一个关注GitHub
其实呢,说起ajax,大家都不陌生,但是这里我还是详细的介绍一下,也好为我下一篇博文做基础,下一篇内容是和数据交互相关的,ajax全称Asynchronous JavaScript and XML(异步的javascript和XML),为什么会有这么一种技术的出现呢,因为前端时常会有这样的需求,我们只要局部刷新,不需要整一个刷新的时候,便吹生了这样的技术ajax,具体它是怎么实现的我们下面娓娓道来。
其实以前看到过一个变态的面试题,让你自己写一个原生的ajax,如果你让我查接口我能写的出来,但是让我默写我办不到,因为现在用的基本都是jquery封装的ajax,确实人家封装的很好,所以我们只要懂得了ajax的怎么实现的基本流程,我觉得对于像我这样的应届生够了。
ajax的基本流程:
ajax实现局部刷新的流程也是这样,因为我们可以发出ajax向服务器获取这个局部相关的少量数据,然后运用这部分数据来更新页面
其实呢,ajax是在2005年由google的Jesse James Garrett发表了一篇文章中提出的,它依赖于XMLHttp实现的,XMLHttp是1998年由微软提出的,google用ajax开发Google Maps等产品,运用若干年之后,才在文章中发表,那么其实ajax是给Google Maps这样的复杂应用而生的,但是,我想谈谈ajax带来的副产品,表单提交
我觉得ajax用于数据交互,对于我这些初学者更应该把握好两点,一点是GET和POST的区别,重中之重,还有一点,可以了解一下什么是RESTFUL风格,其他更加深人的可以结合promise规范,看一下jquery的ajax是怎么封装的等等,这篇博文不会写这些,我打算后期出一篇promise规范相关的,把现在的一些fetch等新出来的数据交互手段进行归纳,举个ajax应用的例子:
$.ajax({
type: "post", //数据传输的方法
url: ..., //一般这里会是后端给你的接口路径
data: {data},//这里是一个提交的数据内容
success: function(){} //成功后进行的操作
error: function(){} //数据审核不通过,后端一般会返回false然后进行的操作碰到一样东西时,我们应该先去查文档,把基本概念搞清楚,然后在开始分析利和弊
其实在MDN的解释中就可以清楚的发现两者的区别:
HTTP GET 方法请求指定的资源。使用 GET 的请求应该只用于获取数据。
HTTP POST 方法 发送数据给服务器.
关于两者的安全性,这个毋庸置疑,但是你只知道POST是比GET安全,但你不知道,为什么?
深入了解一点的会发现,get方式的http请求是这样的
你的参数会被拼接到url上,然后进行传输,这样就会又一个问题,参数都是可见的,就像我截图的一样,而POST就不一样
涂了点,因为接口是公司的,POST方式url后面是不带参数的,POST放在Request body中(这点是来自W3C)
GET可作为书签收藏,因为参数是拼在URL上的,POST就不可以了
GET请求的参数能存在浏览器历史中,而POST不能,原因也在于一个参数是拼接在url中,而一个不是
这一点我想要好好谈谈,GET的数据长度限制来源于哪里,还是上面讲的一点,GET的参数是拼接在URL中的,理论上URL中的参数是可以无限加长的,但是这样势必会给浏览器和服务器带来很重的负担,所以业界有一种不成文的规定,大多数浏览器在URL的限制是2K,而大多数服务器的限制在64K。
在这点上很多人都会有误区,我们得明白一下几点:
1.http是没有限制GET和POST的传递数据长度的
The HTTP protocol does not place any a priori limit on the length of a URI. Servers MUST be able to handle the URI of any resource they serve, and SHOULD be able to handle URIs of unbounded length if they provide GET-based forms that could generate such URIs. A server SHOULD return 414 (Request-URI Too Long) status if a URI is longer than the server can handle (see section 10.4.15).
Note: Servers ought to be cautious about depending on URI lengths above 255 bytes, because some older client or proxy implementations might not properly support these lengths.
2.规定是来源于浏览器和服务器
这点也是跟GET是拼接在URL上一样,那么GET的参数只能进行URL编码,而POST就不一样,可以进行二进制编码等
这个方面就是GET比较出色了,这一点自己也是在整理的时候才关注起来的,很多知识来源于网络,所以,大家可以看,如果和你实际情况不符,可以在评论中提出:
GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET请求来说,是把http header和data一起发送给服务器,然后服务器会返回200。
但是POST就不一样,是先发送http header,然后服务器响应100后,在将data发送给服务器,然后服务器响应200
对于性能而言,一个走了一趟,一个走了两趟,明显是走一趟的来的快捷
全部使用POST明显是不合理的,在一些数据不敏感,请求频繁,数据量小于浏览器限制2K,这样的情况还是选择GET会比较合理。
关于RESTful风格,笔者也在探索阶段,现在只会书写,但是为什么是这样写的,这样的格式是怎么来的,自己也不清楚,哈哈哈,不过,可以给大家推荐几本书,有兴趣的可以看一下《REST in Practice》,还有一个是REST风格的提出者发表的论文(英文版)
希望喜欢的朋友点个喜欢,也可以关注,要是能给博主的GitHub点个star就更好了,大家一起努力,🙏🙏🙏
最近在研究webpack的东西,然后也陆陆续续整理了几篇文章,从里面可以学到许多有用的插件和node的一些模块,今天我要介绍的就是hash和chunkhash,这个在webpack打包的过程中经常见到,有兴趣的可以关注一下我的github,点个star,关注和喜欢都行,🙏
//使用hash的情况
output: {
path: path.resolve(__dirname, '../dist/static'),
publicPath: '/',
filename: 'static/js/[name].[hash].js',
chunkFilename: 'static/js/[id].[hash].js'
}
//使用chunkhash的情况
output: {
path: config.prod.assetsRoot,
filename: 'static/js/[name]-[chunkhash:16].js',
chunkFilename: 'static/js/[id]-[chunkhash:16].js',
publicPath: '/'
},一般使用的时候,会用在文件的产出中,css和js都有,用于打包产出的文件
大家都知道,用于优化页面性能的常用方法就是利用浏览器的缓存,文件的hash值,就相当于一个文件的身份证一样,很适用于前端静态资源的版本管理,前端实现增量更新的方案之一,那为什么会有两个东西呢,我们娓娓道来,先看两者的定义
[hash] is replaced by the hash of the compilation.
compilation的hash值
[chunkhash] is replaced by the hash of the chunk.
chunk的hash值
后者很容易理解,因为chunk在webpack中的含义就是模块,那么chunkhash根据定义来就是模块内容计算出来的hash值。
在理解前者之前我们先来看一下compilation有什么作用
webpack的官网文档中HOW TO WRITE A PLUGIN中对这个有一段文字的解析
A compilation object represents a single build of versioned assets. While running Webpack development middleware, a new compilation will be created each time a file change is detected, thus generating a new set of compiled assets. A compilation surfaces information about the present state of module resources, compiled assets, changed files, and watched dependencies. The compilation also provides many callback points at which a plugin may choose to perform custom actions.
翻译:
compilation对象代表某个版本的资源对应的编译进程,当你跑webpack的development中间件,每当检测到一个文件被更新之后,一个新的comilation对象会被创建,从而引起新的一系列的资源编译。一个compilation含有关于模块资源的当前状态、被编译的资源,改变的文件和监听依赖的表面信息。compilation也提供很多回调方法,在一个插件可能选择执行制定操作的节点
而与compilation对应的还有一个compiler对象,我们也来介绍一下,这样能够更方便理解compilation
The compiler object represents the fully configured Webpack environment. This object is built once upon starting Webpack, and is configured with all operational settings including options, loaders, and plugins. When applying a plugin to the Webpack environment, the plugin will receive a reference to this compiler. Use the compiler to access the main Webpack environment.
翻译:
compiler对象代表的是整个webpack的配置环境,这个对象只在webpack开始的时候构建一次,且所有的操作设置包括options,loaders,plugin都会被配置,当在webpack中应用插件时,这个插件会接受这个compiler对象的引用。通过webpack的主环境去使用这个compiler。
简单的说,compiler是针对webpack的,是不变的webpack环境,而compilation这个就是每次有一个文件更新,然后会重新生成一个,那么当你一个文件的更新,所有的hash字段都会发生变化,这就很坑了,本来我们做增量更新就是想改的那个文件发生变化,但是如果全部都发生变化就没有意义了,我们来看一下实际操作中的例子:
而且从上图中可以看出,每次有文件更新,会产生一个新的compilation,从而会用新的compilation来计算得出新的hash,而且每个文件带有的hash值还是一样的,这样的肯定达不到我们的要求,那么如何避免这个问题呢?——chunkhash
chunkhash是由chunk计算的得出的hash值,chunk指的是模块,这个hash值就是模块内容计算出来的hash值
这里我们还得提一个问题,比如像vue这些框架,把js和css共同放在一个里面会时,我们一般会用一个插件叫extract-text-webpack-plugin,这样我们就能把css单独打包,但是这样就会产生一个问题,这样打包出来的css的chunkhash和js的chunkhash会不会是一样的呢,其实我这么问了,当然是会的啦。我们可以看一下下面两张图片。
其实也很简单,webpack的理念就是为了js的打包,style标签也会视为js的一部分,那么这我们会发现,还是有坑,当我们只改css的时候,js也会同时发生改变,那么我们还是没有做到严格意义上的增量更新,那么我们又该怎么解决呢?
使用方式如下:
new ExtractTextPlugin({
filename: 'static/css/[name]-[contenthash:16].css',
allChunks: true
})这样我们看打包后的效果。
静态资源的管理是前端很重要的一块,最近由于业务转型,自己也在尝试换个架子,那么肯定得从研究webpack入手,现在webpack已经是必不可少的工具之一,这篇博文有借鉴网上的,如有侵权删,但是研究得出的结论我会记忆一生,所以建议看完这篇的小伙伴自己动手配置一边,喜欢的可以去github上点个star,喜欢和关注都行,最近有点忙,但是我还是每天会写一点博文。谢谢大家
这种情况就是我们所说的调用时决定的绑定,举个例子
function thisBind() {
console.log(this.name);
}
const obj = {
name: 'laihuamin',
fn: thisBind
}
obj.fn(); // laihuamin
const bar = obj.fn;
let name = 'huaminlai';
bar(); // undefined
setTimeout(obj.fn, 1000); //undefined
是不是很奇怪,不应该绑定到全局么,基础不扎实的我也是这么认为的,那我们看下面这个例子
function thisBind() {
console.log(this.name);
}
const obj = {
name: 'laihuamin',
fn: thisBind
}
obj.fn(); // laihuamin
const bar = obj.fn;
var name = 'huaminlai'; //改了操作符哦
bar(); // huaminlai
setTimeout(obj.fn, 1000); //huaminlai
其实到这里,我们已经大致知道了,是let这里出了问题,跑个题继续往下看,我们在看一个例子
window.a = 1;
console.log(a) // 1
var a = 2;
window.a // 2
其实在这里,有两个概念,顶层对象和全局变量,顶层对象即window对象,全局变量在ES5中是顶层对象的属性,但是这就会产生很大的问题,第一个,顶层对象的属性是可读可写的,这个不利于模块化编程,第二个,window对象是实体含义,但是可以随意改变属性就不是这个味道了。
var a = 1;
window.a // 1
let b = 1;
window.b // undefined
在ES6中对这个就有所改观,es6中规定,let,const,class定义的全局变量不属于顶层对象,但是还保留了var,function定义的变量为顶层对象的属性
显示绑定是用apply和call方法将this绑定到指定的
他们的第一个参数都是要绑定的对象,第二个参数call和apply有区别,apply需要传入的是一个数组,而call传入的是一个个变量
function foo() {
console.log(this.a);
}
const obj = {
a: 2
}
foo.call(obj); //2
call和apply会把这些基本累心转化成new String(...),new Boolean(...),new Number(...)来处理
new操作符,对于大家来说并不陌生,那么,他是进行了什么样的操作呢?
_proto_function NewFunc(){
const obj = {};
if(func.prototype !== null){
obj._proto_ = func.prototype;
}
var ret1 = func.apply(obj, Array.prototype.slice.call(arguments, 1))
if((typeof ret1 === 'object' || typeof ret1 === 'function') && ret1 !== null ){
return ret1
}
return obj;
}
function Person1(name) {
this.name = name;
}
function Person2(name) {
this.name = name;
return this.name;
}
function Person3(name) {
this.name = name;
return new Array();
}
function Person4(name) {
this.name = name;
return new String(name);
}
function Person5(name) {
this.name = name;
return function() {};
}
const person1 = new Person1('xl');
const person2 = new Person2('xl');
const person3 = new Person3('xl');
const person4 = new Person4('xl');
const person5 = new Person5('xl');
xl
xl
[]
xl
function(){}
介绍完上面这几个,还遗漏了一个,便是bind,这个就是我们这里将的硬绑定,bind会把this强制绑定到对象上
function thisBind(){
console.log(this.name)
}
obj={
name: 'laihuamin'
}
var bar = thisBind.bind(obj);
bar(); //laihuamin
function bind(fn, obj){
fn.apply(obj, arguments)
}
if(!Function.prototype.bind) {
Function.prototype.bind = function(oThis){
if(typeof this !== 'function') {
throw new TypeError(
"Function.prototype.bind what is trying to be bound is not callable"
);
}
var aArgs = Array.prototype.slice.call(arguments, 1),
fToBind = this,
fNOP = function(){},
fBound = function () {
return fToBind.apply((this instanceof fNOP && oThis ? this : oThis), aArgs.concat(Array.prototype.call(arguments)))
}
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}
}
function thisBind(){
console.log(this.name);
}
obj1 = {
name: 'laihuamin',
fn: thisBind
}
obj2 = {
name: 'huaminlai',
fn: thisBind
}
obj1.fn(); //laihuamin
obj1.fn.apply(obj2) //huaminlai
这里明显可以看出显性绑定优先级高于隐性绑定
硬绑定和显性绑定的优先级应该是一致的,因为bind在显性绑定的基础上封装了一层,那我们就比较显性绑定是不能与new绑定进行比较的,因为new没有办法和apply、call一起使用那么我们有什么更好的方法呢,可以让new绑定和硬绑定进行比较
function thisBind(){
this.name = name
}
obj = {}
var bar = thisBind.bind(obj);
bar(2);
var obj2 = new bar(3);
console.log(obj.name); //2
console.log(obj2.name); //3
从这个例子我们可以看出,new绑定可以改变硬绑定的this的指向,所以,优先级是比硬绑定高的
new绑定 > 硬绑定 = 显示绑定 > 隐性绑定 > 默认绑定
1、先看有没有new关键字
2、在看是否有显性绑定和硬绑定
3、再次,你可以看是否隐形绑定
4、最后在根据默认绑定来判断
如果你把null和undefined作为this的绑定,这些值就会被忽略,实际应用的是默认的绑定
function foo() {
console.log(this.a)
}
var a = 2;
foo.call(null); //2
function foo() {
console.log(this.a + 'is' + this.b);
}
//展开参数
foo.apply(null, [2, 3]);
//类似与es6中的扩展运算符
foo(...[2, 3]);
//函数柯里化
var bar = foo.bind(null, 2);
bar(3); // 2+3
忽略this绑定我们有更安全的方式,传入一个DMZ对象
//DMZ对象
Object.create(null)
//展开对象
var a = Object.create(null);
function foo() {
console.log(this.a + 'is' + this.b);
}
//展开参数
foo.apply(a, [2, 3]);
//类似与es6中的扩展运算符
foo(...[2, 3]);
//函数柯里化
var bar = foo.bind(a, 2);
bar(3); // 2+3
可维护性显而易见,未模块化之前,你要改代码,可能得改好几处,模块化之后,代码复用了,改一处就可以了
什么叫命名空间,简单点讲就是变量容易重名,你叫张三,他也叫张三,这就很尴尬。
还有就是模块化可以防止污染全局变量,为什么这么说,因为打包过之后,是没有全局变量这一个概念的,模块顶级作用域定义的也会被封装到局部作用域中
这点基本不用讲,模块化的根本就是复用,
commonJS有三部分分别是模块的定义,模块的引用和模块的标识
导入:require
const fs = require('fs');
注意点:commonJS是同步加载的,具体后面会讲到
AMD又称异步模块加载,非阻塞性的模块加载
define(['myModule', 'otherModule'], function(myModule, otherModule){
console.log(myModule.hello());
console.log(otherModule.hello());
})
AMD是通过appendChlid插入到DOM的,在模块加载成功之后,define会调用第二个回调函数
和AMD原理一样
define(function(require, export, module){
var a = require('./a');
module.export = {
fn: a.doSomeThing()
}
})
模块与script有很大的不同:
利用export关键字将模块的部分代码导出,导出部分可以是常量,变量,函数,类等
//直接导出——不能匿名,但是可以是任何类型
export let color = "red";
//接口导出——跟上面直接导出类似
const b = (c) => c;
export {b};
//接口名修改导出——函数名是张三,我们非要把他导出叫李四
const a = (b) => b;
export { a as b}; //注意——引用也要引用李四
//默认值导出——对于匿名的我们可以这么做
export default function (){
...
}
//默认值导出2——和上面的类似,就是导出放在下面了
export {xxx as default}
// 完全导入
import * as xx from './example.js';
// 部分导入
import {xx, yy} from './example.js';
// 重命名导入
import {yy as xx} from './example.js';
举个例子
import {sum} from "./example.js"
import {multiply} from "./example.js"
import {magicNumber} from "./example.js"
在这个例子中example文件只会被执行一次,其余的都是读取缓存来进行的
//错误
function(){
export.xxx;
import xx from xx
}
//错误
import {obj} from xx;
obj = {} //错误
原因在与import是只读的,不可改变
//------ a.js ------
import {bar} from 'b'; // (i)
export function foo() {
bar(); // (ii)
}
//------ b.js ------
import {foo} from 'a'; // (iii)
export function bar() {
if (Math.random()) {
foo(); // (iv)
}
}
//foo永远是a.js中的foo,无法被改变
//错误
import {foo: {bar}} from './example.js'
为什么题目是这个呢,因为自己最近在用npm包的时候被mac的权限恶心到了。
在mac中全局安装npm包,需要用sudo,因为npm包安装的位置在/usr/local/bin中,然后自己在安装weex-toolkit的时候,用了sudo命令,然后用weex命令创建文件夹的时候也要用sudo,导致创建的文件夹权限也是只读,不能写入。
产生这种现状是因为我们没有对node这个东西进行管理,首推nvm,其次是brew。nvm是mac下的node管理工具,当然你手头上有好几个不同的项目,依赖不同的node版本,这个东西也可以很好的解决。
sudo rm /usr/local/bin/npm
sudo rm /usr/local/share/man/man1/node.1
sudo rm /usr/local/lib/dtrace/node.d
sudo rm -rf ~/.npm
sudo rm -rf ~/.node-gyp
sudo rm /opt/local/bin/node
sudo rm /opt/local/include/node
sudo rm -rf /opt/local/lib/node_modules
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.0/install.sh | bash
nvm install 8.9.1
nvm install stable
使用命令nvm use加版本号
nvm use 8.9.1
我们可以通过创建项目目录中的.nvmrc文件来指定要使用的nodejs版本。之后在项目目录中执行nvm use即可。
其实每个版本的node,都会自带一个不同版本的npm,可以用npm -v来查看npm的版本。全局安装的npm,并不会在不同的node版本**享。
在实习过程中,这个东西用到的确实多,当初只知道我该怎么去配这个东西,预发调试的时候,这个东西用的很多,等会我会先介绍工具,然后再去了解这个东西的原理,工作中应该都能用的到,我去两家公司实习过,确实都用到了,所以,觉得有用的可以收藏,点个喜欢,或者关注都可以,或者在去我的github点个赞也是极好的,谢谢支持。
hosts文件(域名解析文件)是一个用于储存计算机网络中各节点信息的计算机文件。这个文件负责将主机名称映射到相应的IP地址。hosts文件通常用于补充或取代网络中DNS的功能。和DNS不同的是,计算机的用户可以直接对hosts文件进行控制。
或许可以举个例子,讲的通俗点,我们就拿百度举例子好了,www.baidu.com的ip地址长久不发生变化的话,你就可以将百度的网址写到host里面,那样的话我们,以后访问百度这个地址就不在需要DNS解析了,当你输入www.baidu.com之后,会直接去host文件中寻找,直接进行访问。
这个工具真的好用,和charles一样,如果已经在用了的朋友可以跳过这一段,还没有用的,我来安利一下,没有接触这款工具的时候,我们修改host文件有以下几种方法:
先将host文件是不允许直接修改的,先将host文件复制出来,然后修改后在复制进去,覆盖掉。
但是switchHosts用起来就比较简单,按钮切换就行
其实host的书写格式很简单,如下:
IP地址 主机或者域名 [主机的别名] [主机的别名]
host文件的注释格式,如下:
# ...
我们可以看一下以下这个例子
能干嘛是我们最想要了解到,知道是什么之后,主要作用有以下几点:
正如他是什么里面书写的
一般我们不改变host文件的时候,我文件中会有以下内容
127.0.0.1 localhost localhost.localdomain
这个是代表什么呢,其实localhost大家在开发中也经常用到,而127.0.0.1这个是本地的ip地址,我们可以用localhost:8080访问本地,我们也可以用127.0.0.1:8080访问本地是一个道理.那么我们在本地调试的时候,可以把线上的域名映射到本地,那么一些页面路由的跳转,调试起来会方便很多
写这篇文章的目的一来是介绍一个工具switchHosts,二来是让大家了解以下hosts文件,因为很多公司都会自己配一些host。这些host我觉得第一可以方便调试,还有就是让一些域名不受到污染,因为域名绑定的dns是错误的,而host中的ip地址才是正确的。如果觉得我写的还可以的给我的github点个star,谢谢支持
//输出页面的dom结构,包含tagName和层级关系
//html
// head
// meta
// title
// style
// body
// script
// div
// spana = [1, 3, 5]
b = [2, 4, 6, 7, 8, 9]
- 输出结果
c = [1, 2, 3, 4 ,5, 6, 7, 8, 9]
最近一直在研究event loop相关的,首先我们可以从HTML standard,标准中对于event loop的介绍。
To coordinate events, user interaction, scripts, rendering, networking, and so forth, user agents must use event loops as described in this section. There are two kinds of event loops: those for browsing contexts, and those for workers.
为了协调事件,用户交互,脚本,渲染,网络请求,等等,必须用到event loop。而event loop有两种类型,一种browsing contexts和另一种workers。
一个event loop中会有一个或者多个task队列。而来源不同的task将会放入到不同的task中。
典型的任务源:
大致有这么几种,关于macrotask这个说法,并没有在标准中被提及。
一个事件循环只有一个Microtask,以下几种任务被认为是microtask
可以观看标准的8.1.4.2 processing model中的解释,过程很长,很复杂。
但是其实总结的来说就是以下这段话:
先运行一个task,然后再去清空Microtask队列,在运行一个task,然后再去清空Microtask队列
那么我们来看一个例子:
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
setTimeout(() => {
console.log('timer3')
}, 0)
}, 0)
Promise.resolve().then(function() {
console.log('promise3')
})
console.log('start')当然,答案不重要,其中的过程能理解最重要。
运行过程:
script脚本被当作一个task,放入到task队列中
【task队列】:
1、将定时器set1和set2放入到task队列中。
2、将Promise放入到microtask队列中
3、输出start
【microtask队列】:
1、执行promise的回调,输出promise3
运行过程:
在task队列中,将set1当作一个task。
【task队列】:
1、输出timer1
2、将promise放入到microtask队列中
【microtask队列】
1、执行promise的回调,输出promise1
运行过程:
在task队列中,将set2当作一个task。
【task队列】:
1、输出timer2
2、将promise放入到microtask中
3、将set3放入到task队列中
【microtask】
1、执行promise的回调,输出promise2
运行过程:
在task队列中,将set3当作一个task。
【task队列】:
1、输出timer3
2、经过 microtask checkpoint检测,microtask队列为空,跳过。
start
promise3
timer1
promise1
timer2
promise2
timer3
在ES6中多了两个变量定义的操作符——let和const,在现在项目中,ES6已经是不可获缺,我打算在掘金上整理一套ES6的系列,会收集常用的知识点,喜欢的可以点个喜欢,关注,或者可以去github点个star
大家都知道js是没有块级作用域的,我们先了解一下块级作用域。
任何一对花括号中的语句集都属于一个块,在这之中定义的所有变量在代码块外都是不可见的
了解定义之后,我们👀一个用烂了的例子:
for(var i = 0; i < 10; i++) {
console.log(1);
}
console.log(i);上面这个例子,最外面会输出10。显而易见,没有块级作用域。
关于这一点我们可以看道面试题就能明白。
var func = [];
for(var i = 0; i < 10; i++) {
func.push(function(){
console.log(i)
});
}
func.forEach((func) => {
func();
})
//10个10为什么会产生这样的事情呢?因为在循环内部这些i都是用同一个词法作用域的,换言之,这10个i用的都是最后的输出的i,最后的i也就等于10。
而立即执行函数就不一样,他用函数作用域代替块级作用域,强制在循环内部创建副本,以便输出1,2,3,4...
var func = [];
for(var i = 0; i < 10; i++) {
func.push((function(value){
return function() {
console.log(value)
}
})(i));
}
func.forEach((func) => {
func();
})
//会输出1到9对立即执行函数有兴趣的好可以看看这么几篇博文,我在这里就不用大篇幅赘述,我们简单过一下下面几种方法,然后去将我们今天的主角们。
推荐博文
推荐博文
try-catch这个创建块级作用域在红皮书中有提到过,我没用过,觉得这个知识点了解就可以,也不常用。
try {
throw 'myException';
}
catch (e) {
console.log(e);
}
console.log(e);
//第一个输出myException,第二个输出e is not defined在ES6中提出了let和const,我们可以看一下下面这几个例子,在每次循环中,let会创建一个词法作用域,并与之前迭代中同名变量的值将其初始化。
for(let i = 0; i < 10; i++) {
console.log(1);
}
console.log(i);
//报错i is not definedconst func = [];
for(let i = 0; i < 10; i++) {
func.push(function(){
console.log(i)
});
}
func.forEach((func) => {
func();
})
//会输出0到9这个特性同样适用于for in
const funcs = [],
obj = {
a: 'lai',
b: 'hua',
c: 'min'
};
for (let key in obj) {
funcs.push(() => {
console.log(key)
})
}
funcs.forEach((func) => {
func()
});
//输出的是a b c在一个作用域中,已经用var、let、const声明过某标识符之后,不能在用let、const声明变量,不然会抛出错误
var a = 0;
let a = 10;
// 报错但是在作用域中嵌套一个作用域就不会,看下面这个例子
var a = 0;
if (true) {
let a = 10;
}
// 不会报错const效果也是一致的,不过const用于定义常量,const还有一下特性
当你用const声明变量,不初始化的话,就会发生报错
const a;
// 报错而const的本质是声明的,不允许修改绑定,但是允许修改值,所以大多数场景,我们都用const来声明对象,那样对象的指针不会改变,相对来说安全,看一下下面的例子
const person = {
name = 'laihuamin'
}
person.name = 'lai';
//到这里不会发生报错,只会改变值
person = {};
//这里改变了对象的指针,所以会发生报错而const不止能用于对象指针绑定,还能运用在for in的迭代中,因为每次迭代不会修改已有的绑定,而是会创建新的绑定。看下面的例子
const funcs = [],
obj = {
a: 'lai',
b: 'hua',
c: 'min'
};
for (const key in obj) {
funcs.push(() => {
console.log(key)
})
}
funcs.forEach((func) => {
func()
});
//输出a b c但是在循环中就不能用,循环会修改已有的绑定,而const定义的常量时不能修改绑定的,所以会报错。
对于ES5的变量提升有一个经典的考题。如下:
var a = 10;
(function () {
console.log(a);
var a = 1;
})();
// 这个会输出undefined其实这个很好理解,js作用域连是从内向外寻找变量的,那么函数的作用域中有a这个变量,由于var会发生变量提升,就相当于下面这个过程
var a;
console.log(a);
a = 1;所以,这个a变量就是undefined。而let和const就不一样,把var换成let或者const都会报错。
我们先来看例子,再来根据例子解析:
console.log(a);
let a = 10;
//Uncaught ReferenceError: a is not definedlet和const定义的变量是存在暂时性死区的,而var没有,我们来了解一下两个操作符的工作原理:
对于var而言,当进入var变量的作用域时,会立即为他创建存储空间,并对它进行初始化,赋值为undefined,当函数加载到变量声明语句时,会根据语句对变量赋值。
而let和const却不一样,当进入let变量的作用域时,会立即给他创建存储空间,但是不会对他进行初始化,所以会抛出如上错误。
而对于typeof操作符来说,结果是一致的,一样会报错:
console.log(typeof a);
let a = 10;
//Uncaught SyntaxError: Identifier 'a' has already been declared所以最佳实践是把声明的变量全部提到作用域的开头,这样既方便管理,又能避免不必要的麻烦
var声明全局变量的时候,当使用关键词,那么就会覆盖掉window对象上原本拥有的属性,我们看一下下面这个例子:
var RegExp = 'lai';
console.log(window.RegExp);
var a = 'hua';
console.log(window.a);
var Array = 'min';
console.log(window.Array);
var b = new Array();
//lai
//hua
//min
//Uncaught TypeError: Array is not a constructor而换成let和const的时候就不会发生这样的事情,我们用同样的例子来看一看:
let RegExp = 'lai';
console.log(window.RegExp);
let a = 'hua';
console.log(window.a);
let Array = 'min';
console.log(window.Array);
let b = new window.Array();
console.log(b);
//ƒ RegExp() { [native code] }
//undefined
//ƒ Array() { [native code] }
//[]结果和上面一样,我们更可以进一步认证
let RegExp = 'lai';
console.log(RegExp === window.RegExp);
var Array = 'hua';
console.log(Array === window.Array);
//会输出 false 和 true根据以上讲的,最佳实践应该是,能用const定义对象的,不要用let,能用let定义变量的,不要用var。至于他的很多特性,了解了能更好的帮助你运用。如果觉得笔者写的可以的点一个喜欢,之后还会持续更新其他板块,希望能给笔者的github点个star,谢谢支持
这篇文章是网上看到的,自己实验了一遍,把过程和结果都分享给大家,网上的那片我也会注明出处,希望对大家真实过程中有用,喜欢的点个赞,或者给我的github点个star谢谢.
let a = 10;
console.log(a);这个使用在正常不过,确实方便,而且还可以用alert一样的效果。不过下面和大家介绍的,对大家应该有用。
console.log(10); //10
console.info('信息');
console.warn('警告');
console.error('错误');后面几个的输出结果如下:
先看例子:
占位符不止这些,还有字符串%s,浮点型%f和对象%o。不过这些功能现在应该用不到了,从es6出了模版字符串之后,字符串的拼接已经不是什么难事。
console.group("第一组");
console.log("第一组第一条:github:github.com/laihuamin");
console.log("第一组第二条:github:github.com/laihuamin");
console.groupEnd();
console.group("第二组信息");
console.log("第二组第一条:github:github.com/laihuamin");
console.log("第二组第二条:github:github.com/laihuamin");
console.groupEnd();输出结果:
console.dir可以输出对象的所有属性和方法,console.log可以输出对象内容
console.log(document.body);
console.dir(document.body);输出结果:
console.time是输出时间的函数
console.time("控制台计时器一");
for(var i=0;i<10000;i++){
for(var j=0;j<10000;j++){}
}
console.timeEnd("控制台计时器一");输出结果:
console.trace是追踪函数的轨迹
function add(a,b){
console.trace();
return a+b;
}
let x = add3(1,1);
function add3(a,b){
return add2(a,b);
}
function add2(a,b){
return add1(a,b);
}
function add1(a,b){
return add(a,b);
}输出结果:
这篇文章出于猎奇心里0.0
我们在引入vue的过程中,其实使用的代码很简单,但是从源码层面来说,一个引入的过程,经历了很多流程,我们今天就一起来了解一下整个vue的初始化过程。
我们先看core文件夹中的index.js文件,我们可以发现,这边进行了vue的引入操作。源码示例:
import Vue from './instance/index'
import { initGlobalAPI } from './global-api/index'
initGlobalAPI(Vue)可以从这边看出,vue方法是来自于instance/index.js文件
这个文件我们可以用一张图来表示:
然后我们看起始的一段源码:
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)
) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}这个里面执行了initMixin中添加到原型上的_init方法
本文将从浅到深的去剖析promise。由于内容较多,分为上下两篇。
js是一门单线程的语言,所以其中会涉及到很多异步的操作,异步编程的解决方案有很多种,我们主要讲一种最基础的和这篇文章的主角(promise):
在异步编程中,这种的应用范围最广,举个定时器的例子:
setTimeout(() => {
// ...
}, 1000);当然在业务中异步请求也会用到很多,但当多个异步操作需要串行操作的时候,就会有回调地狱产生。
$.get(url, data1 => {
console.log(data1)
$.get(data1.url, data2 => {
console.log(data2)
$.get(data2.url, data3 => {
console.log(data3)
})
})
})代码没有美感,且不利于维护。当然,我们可以通过减少代码嵌套,模块化等手段来修复。但是并不如下面的解决方案优雅。
const reqMethod = (url) => {
return new Promise((reslove, reject) => {
$.get(url, data => {
if(data.success) {
reslove();
} else {
reject();
}
})
})
}
reqMethod(url).then((data1) => {
return reqMethod(data1.url);
}).then((data2) => {
return reqMethod(data2.url);
}).then((data3) => {
return reqMethod(data3.url);
})这样的实现方式,符合易于阅读,因为每一步操作都是按照先后顺序进行的。
Promise从不同角度理解,有很多种含义。
promise从字面意思理解,就是许诺和承诺的意思,对于一种承诺而言,有三种状态:
1、承诺还未达成,还在纠结过程中(pending状态)
2、承诺没有实现,失言了(rejected状态)
3、承诺实现了,就是成功的状态(fulfilled状态)
在这里不过多展开,大家可以去看Promise/A+ 规范或者ECMAscript规范;
Promise是一个对象,是一个构造函数,ES6将其写进了语言标准。统一了用法。最基础的用法如下:
const promiseMethod = new Promise((resolve, reject) => {
// some code
if(/*异步成功的条件*/) {
resolve();
} else {
reject();
}
})Promise是一个构造函数,最基础的作用就是用new操作符生成一个实例对象
const promiseMethod = new Promise((resolve, reject) => {
// some code
if(/*异步成功的条件*/) {
resolve();
} else {
reject();
}
})Promise可接受的参数是一个函数,resolve和reject是该函数的两个参数,由js引擎提供,不需要自己定义。
resolve的作用是将pending状态变更为fulfilled状态。
reject的作用是将pending状态变更为rejected状态。
Promise新建时就会立即执行,与何时调用无关,与结果也无关
举个例子
const promiseOne = new Promise((resolve, reject) => {
console.log('has finish');
resolve();
})1、console.log在新建过程中就执行了。
2、promiseOne的结果已经固定下来了,无论何时调用,结果都不会发生改变。
then方法是被定义在Promise的原型上,作用是:添加Promise状态改变后的回调函数。
then方法接收两个参数,第一个参数是resolve状态执行的函数,第二个参数是reject执行的函数。
then方法返回的是一个新的Promise对象。
举个例子:
const promiseOne = new Promise((resolve, reject) => {
console.log('has finish');
resolve();
})
const promiseTwo = new Promise((resolve, reject) => {
console.log('has reject');
reject();
})
const promiseThree = promiseOne.then(() => {
console.log('成功的回调')
}, () => {
console.log('失败的回调')
})
promiseTwo.then(() => {
console.log('成功的回调')
}, () => {
console.log('失败的回调')
})
console.log(promiseThree);输出的结果:
has finish
has reject
<Promise>(pending)
成功的回调
失败的回调
catch方法其实和then第二个回调函数的别名,作用是用于储物发生时的回调处理。
catch捕获两类错误:
1、异步操作时抛出错误,导致状态变为reject
2、then回调过程中产生的错误。
举个例子:
//第一种情况:异步操作过程中报错
const promise = new Promise(function(resolve, reject) {
throw new Error('test');
});
promise.catch(function(error) {
console.log(error);
});
// 第二种情况:then执行过程中报错
const promise = new Promise((resolve, reject) => {
resolve();
})
promise.then(() => {
throw new Error('test');
}).catch(function(error) {
console.log(error);
});关于catch和then第二个参数的区别:
// bad
promise
.then(function(data) {
// success
}, function(err) {
// error
});
// good
promise
.then(function(data) { //cb
// success
})
.catch(function(err) {
// error
});第二种写法的优点在于,then执行过程中的报错,catch一样能捕获,优于第一种写法。
更深入的错误捕获我们单独放一章讲。
finally方法作用在于不管promise返回的状态是什么,它都会在执行。
finally不接受任何参数。
promise
.then(function(data) {
// success
})
.catch(function(err) {
// error
}).finally(() => {
});finally中执行的状态与promise的结果无关,而且在方法中无法得知promise的运行结果。
用法:
Promise.all([p1, p2, p3]);作用:是将多个promise示例封装成一个promise实例。结果只有以下两种情形:
所有promise都成功,总的promise才会成功
const p1 = new Promise((resolve, reject) => {
resolve('hello');
})
const p2 = new Promise((resolve, reject) => {
resolve('hello');
})
Promise.all([p1, p2]).then(() => {
console.log('全部成功')
}).catch(() => {
console.log('全部失败')
})
// 全部成功只要有一个promise的状态从pending变成reject就是失败。
const p1 = new Promise((resolve, reject) => {
resolve();
})
const p2 = new Promise((resolve, reject) => {
reject();
})
Promise.all([p1, p2]).then(() => {
console.log('全部成功')
}).catch(() => {
console.log('全部失败')
})Promise的时间如何计算?
const newDate = new Date();
const p1 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve();
}, 500)
})
const p2 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve();
}, 1000)
})
Promise.all([p1, p2]).then(() => {
const now = new Date();
let time = now.getTime() - newDate.getTime();
console.log(time);
})
// 1001按最长的那个为准。
用法:
Promise.race([p1, p2, p3]);作用:是将多个promise示例封装成一个promise实例。
Promise.race与Promise.all的区别
Promise.race的状态取决于最先完成的promise的状态。
举个例子,我们需要对一个请求做5秒的timeout,就可以用Promise.race。
const reqMethod = (url) => {
return new Promise((reslove, reject) => {
$.get(url, data => {
reslove();
})
})
}
const timeout = new Promise((resolve, reject) => {
setTimeout(() => {
reject('timeout')
}, 5000)
})
Promise.race([reqMethod(xxx),timeout]).then(() => {
console.log('请求成功')
}).catch(() => {
console.log('timeout')
})作用:需要将现有的对象转化为promise对象。
Promise.resolve({});
//等价于
new Promise(resolve => resolve({}));Promise.resolve会根据传入的不同参数做不同的处理
不做任何操作,原封不动的返回该对象。
立即执行thenable对象中的then方法,然后返回一个resolved状态的promise。
let thenable = {
then: function(resolve, reject) {
resolve('success')
}
}
const p = Promise.resolve(thenable);
p.then((e) => {
console.log(e);
})直接返回一个resolved状态的promise。并将参数带给回调函数。
const p = Promise.resolve('参数');
p.then((e) => {
console.log(e)
})直接返回一个resolved状态的promise。
其作用是返回一个新的promise实例,状态直接为reject
Promise.reject('error');
//等价于
new Promise((resolve, reject) => reject('error'));不同于Promise.resolve,其参数会原封不动的作为reject的理由。
举个例子:
const p = Promise.reject('error');
p.catch((e) => {
console.log(e)
})
// error1、promise代表一个异步操作,一共有三种状态:pending、fulfilled和rejected。
2、promise的结果只服从于异步操作的结果,成功进入fulfilled状态,失败进入rejected状态。
1、promise状态变化只有两种可能,一种从pending到fulfilled,或者是从pending到reject。
2、当状态变更完时,状态将不在发生改变。
本文对promise的用法进行了详解,之后会更新两篇深入一点的文章:
注意图片中的第7条:If Type(y) is Boolean, return the result of the comparison x == ToNumber(y).
第9条:If Type(x) is Object and Type(y) is either String or Number,return the result of the comparison ToPrimitive(x) == y.
那么我们以[] == false为例,先对x进行ToPrimitive(x),在对y进行ToNumber(y).
这里我们先来了解一下ToPrimitive()和ToNumber()的源码
ToPrimitive
// ECMA-262, section 9.1, page 30. Use null/undefined for no hint,
// (1) for number hint, and (2) for string hint.
function ToPrimitive(x, hint) {
// Fast case check.
if (IS_STRING(x)) return x;
// Normal behavior.
if (!IS_SPEC_OBJECT(x)) return x;
if (IS_SYMBOL_WRAPPER(x)) throw MakeTypeError(kSymbolToPrimitive);
if (hint == NO_HINT) hint = (IS_DATE(x)) ? STRING_HINT : NUMBER_HINT;
return (hint == NUMBER_HINT) ? DefaultNumber(x) : DefaultString(x);
}
// ECMA-262, section 8.6.2.6, page 28.
function DefaultNumber(x) {
if (!IS_SYMBOL_WRAPPER(x)) {
var valueOf = x.valueOf;
if (IS_SPEC_FUNCTION(valueOf)) {
var v = %_CallFunction(x, valueOf);
if (IsPrimitive(v)) return v;
}
var toString = x.toString;
if (IS_SPEC_FUNCTION(toString)) {
var s = %_CallFunction(x, toString);
if (IsPrimitive(s)) return s;
}
}
throw MakeTypeError(kCannotConvertToPrimitive);
}
// ECMA-262, section 8.6.2.6, page 28.
function DefaultString(x) {
if (!IS_SYMBOL_WRAPPER(x)) {
var toString = x.toString;
if (IS_SPEC_FUNCTION(toString)) {
var s = %_CallFunction(x, toString);
if (IsPrimitive(s)) return s;
}
var valueOf = x.valueOf;
if (IS_SPEC_FUNCTION(valueOf)) {
var v = %_CallFunction(x, valueOf);
if (IsPrimitive(v)) return v;
}
}
throw MakeTypeError(kCannotConvertToPrimitive);
}大致的代码逻辑是:
ToNumber
// ECMA-262, section 9.3, page 31.
function ToNumber(x) {
if (IS_NUMBER(x)) return x;
// 字符串转数字调用StringToNumber
if (IS_STRING(x)) {
return %_HasCachedArrayIndex(x) ? %_GetCachedArrayIndex(x) : %StringToNumber(x);
}
// 布尔型转数字时true返回1,false返回0
if (IS_BOOLEAN(x)) return x ? 1 : 0;
// undefined返回NAN
if (IS_UNDEFINED(x)) return NAN;
// Symbol抛出异常,例如:Symbol() + 1
if (IS_SYMBOL(x)) throw MakeTypeError(kSymbolToNumber);
return (IS_NULL(x)) ? 0 : ToNumber(DefaultNumber(x));
}ToString
// ECMA-262, section 9.8, page 35.
function ToString(x) {
if (IS_STRING(x)) return x;
// 数字转字符串,调用内部的_NumberToString
if (IS_NUMBER(x)) return %_NumberToString(x);
// 布尔型转字符串,true返回字符串true
if (IS_BOOLEAN(x)) return x ? 'true' : 'false';
// undefined转字符串,返回undefined
if (IS_UNDEFINED(x)) return 'undefined';
// Symbol抛出异常
if (IS_SYMBOL(x)) throw MakeTypeError(kSymbolToString);
return (IS_NULL(x)) ? 'null' : ToString(DefaultString(x));
}那么[].valueOf()的结果是[],在对[]调用toString的方法,得到的结果是""。
而true调用ToNumber的方法得到的结果是1。
"" == 1 返回的是false,所以[] == true,返回false。
那么我们再来看看!![] == true是怎么解读的?
根据优先级,先进行!操作。
所以!![]相当于!!(ToBoolean([]))
ToBoolean源码
// ECMA-262, section 9.2, page 30
function ToBoolean(x) {
if (IS_BOOLEAN(x)) return x;
// 字符串转布尔型时,如果length不为0就返回true
if (IS_STRING(x)) return x.length != 0;
if (x == null) return false;
// 数字转布尔型时,变量不为0或NAN时返回true
if (IS_NUMBER(x)) return !((x == 0) || NUMBER_IS_NAN(x));
return true;
}从源码中,我们得知,null,undefined,0,"",false,NaN,返回false。其余都是返回true。
那么!![],转换之后等于!!true,即true。
那其余的一个就留给大家自己分析啦!!!
这个模糊效果在ios的6plus上上滑的时候,会产生留白的过程,这个状态的解决方案其实在网上页查到了。
在filter的class中引用:
-webkit-backdrop-filter: blur(16/@b);
才解决。
在毕业一年的关头,给自己的一份总结以及展望。
最近一年,团队的学习氛围浓厚,自己也把vue的源码看了一遍,然后,满满开始梳理和写作博客。最大的区别就是,这个写作过程中,完全是按照自己的认知去写作,而不是从别的博客拼凑。然后自己将会梳理一份大纲,然后讲vue初始化到数据响应到模版解析再到patch的过程,全部过一遍。
在语言方面,在做业务的过程中,虽然时常运用,但是还是需要整理,以及深化。特别是对es6的一些属性,有些在业务中并不常用。而且对于设计模式,自己也要学习,有一次,在写小游戏的时候,就会发现,逻辑越写越多,感觉像堆砌的产物。
node方面在过去一年进步很小,尝试的方面也就服务端渲染,以及写过获取服务端时间等中间件。明年这一块是自己可以进步的地方。
weex是业务中用的比较多的点,一年下来,也踩了不少的坑,对于这一块,自己没有过多的要求,只要把自己踩的坑记下来,然后避免自己在踩坑。
业务能力是我们必不可少的能力,对于开发来说,不是只要完成开发任务就可以了,需要去理解这个需求能带来什么东西,以及活动上线,或者是改版之后,真实起到的效果。当一个需求下来的时候,需要和产品核对清楚,需求里面的细节点,防止重复开发。这是我一年中学到的东西,但是还有待加强。
这一块我从自己的leader身上学到了很多,他会要求我们在解决问题的同事,剖析问题发生的原因以及本质。我们需要做到的是如何去避免问题的再次发生。以及自己解决问题的时候,会不会还会有新的问题产生等等。这一块是自己可以持续学习和提升的一点。
对于团队的管理,这可能是自己以后需要经历的,但是就现在而言,我会记录下来,对自己有用的东西。总结以下几点:
1、作为领导层,需要多关心下属的学习,因为作为技术,必须以技术知识武装自己。
2、对于客诉问题,在团队建立oncall的轮岗机制,这样可以让问题有效的解决。
3、建立团队的工作流程规范,这样可以使得团队减少工作失误。
4、待补充。
知识需要成块存在,所以自己也会结合自己的所学,梳理一系列的文章,比如(vue源码系列,Es6系列等等)。
自己未来一年,需要更多的接触nodejs,ts,js设计模式等,这些东西可以为自己以后的职业生涯打下扎实的基础。
在程序员层面,这是涉猎范围的问题,我觉得自己不需要仅限于js等等,也可以熟悉熟悉java,py等。当然就算不能在业务上面用,就当强化一下自身。
距离掘金优秀作者,自己还有一半的路要走,自己还得更加的努力。
目前项目的star在500多,自己需要做好的是输出优质的博文,以及readme页面的整理,做的更加清晰
晋升是对自己职业方面的要求,当然是自己越高越好,当然也要靠自己的努力,以及改正一些不良的习惯。
js是一门弱类型语言或者又叫动态类型语言,不用声明数据类型,在执行过程中,自动会确定数据的类型,这就意味着一个变量可能不同时刻用于不同数据类型。
举个例子
let foo = true; //现在他是boolean呦~
let foo = 'string' //字符串
let foo = 1 //number我们看看其他语言长什么样
//先声明类型在声明变量名
double a;
int b;
Boolean c;关于事件这一块在《深入浅出的nodejs》中很少讲到,书里面只是在第三章提及了4个API方法,比如两个定时器(setTimeout和setInterval),process.nextTick()和setImmediate。
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
setTimeout(() => {
console.log('timer3')
}, 0)
}, 0)
Promise.resolve().then(function() {
console.log('promise3')
})
console.log('start')浏览器中输出结果:
start
promise3
timer1
promise1
timer2
promise2
timer3这个输出结果的原因我们已经在上一篇文章中说明,本章就不多加赘述。
在nodejs中,运行却能得到不同的结果,让我们先来过一下node的事件模型。
start
promise3
timer1
timer2
promise1
promise2
timer3node的事件循环分为6个阶段
源代码地址有兴趣的可以去看一下源代码
六个阶段的功能如下:
当有数据或者连接传入事件循环的时候,先进入的是poll阶段,这个阶段,先检查poll queue中是否有事件,有任务就按先进先出的顺序执行回调,如果队列为空,那么会先检查是否有到期的setImmdiate,如果有,将其的callback推入check队列中,同时还会检查是否有到期的timer,如果有,将其callback推入到timers队列中。如果前面两者都为空,那么直接进入I/O callback,并执行这个事件的callback。
check阶段专门用来执行setImmidate的回调函数。
用于执行close事件的回调函数
用于执行定时器设置的回调函数
用于执行大部分I/O事件的回调函数。
这个钩子在node的事件循环模型中没有提及,但是node中有一个特殊的队列,nextTick queue。在node事件循环进入到下一个阶段的时候,都会去检测nextTick queue中有没有清空,如果没有清空,那么就会去清空nextTick queue中的事件。
在官网的文档里面有那么一段话:
When Node.js starts, it initializes the event loop, processes the provided input script (or drops into the REPL, which is not covered in this document) which may make async API calls, schedule timers, or call process.nextTick(), then begins processing the event loop.
1、所有同步任务
2、脚本任务中发送的api请求
3、规划定时器同步任务的生效时间
4、执行process.nextTick()
第一种情况
1、清空当前循环内的 Timers Queue,清空NextTick Queue,清空Microtask Queue
2、清空当前循环内的 I/O Queue,清空NextTick Queue,清空Microtask Queue
3、进入poll阶段
4、清空当前循环内的 Check Queue,清空NextTick Queue,清空Microtask Queue
5、清空当前循环内的 Close Queue,清空NextTick Queue,清空Microtask Queue
第二种情况
1、先进入poll阶段
2、清空当前循环内的 Check Queue,清空NextTick Queue,清空Microtask Queue
3、清空当前循环内的 Close Queue,清空NextTick Queue,清空Microtask Queue
4、清空当前循环内的 Timers Queue,清空NextTick Queue,清空Microtask Queue
5、清空当前循环内的 I/O Queue,清空NextTick Queue,清空Microtask Queue
setTimeout(() => {
console.log('timeout')
}, 0);
setImmediate(() => {
console.log('immediate')
});直接运行脚本,输出的结果是
timeout
immediate当我们把他放在同一个I/O循环中运行
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout')
}, 0)
setImmediate(() => {
console.log('immediate')
})
})输出的结果是
immediate
timeoutprocess.nextTick(() => {
console.log('nextTick')
})
Promise.resolve().then(() => {
console.log('promise')
})输出的结果是
nextTick
promisenodejs中的实现方式:microtask queue的任务通过runMicrotasks将microtask queue中的task放入到nextTick中,所以microtask的任务会在nextTick queue之后执行。
书本中是推荐使用setImmediate(),用户如果递归调用process.nextTick()的时候,会造成I/O被榨干。而使用setImmediate,只会在check中执行,不至于异步调用的时候无法执行。
和去年一样,vue是js项目中点赞数增加最多的,我们可以看下图:
这并不代表是最受欢迎项目,在项目总的点赞数量上依旧是react(86102 stars),但是确实是增长速度最快的,如果按照这个速率,接下来有可能会超过react。
如果vue是成功的,那么无疑react表现的更加不错。
虽然react点赞增加速率不很快(对于一个老项目来说,我们应该满足),但是react的成功更倾向于看他的生态圈,如下图:
前五个项目的总star数超过67.9K,和vue的44.4K比无疑是成功的。
react经历了许可证的闹剧之后,它的最大的障碍也不复存在了,我们可以一起来见证它在2018能够带来什么新的东西。
parcel在一个月内增加的点赞数量可以超过大多数项目一年增加的。
你可能不能想象,一个12月份才推出的项目,点赞数的增加量可以排到年度的第12名,哈哈哈
甚至超过了webpack,就单单一个月哈,我已经抑制不住好奇心了!!!
三大框架的战争应该已经告一段落,总结所有框架一年的star增长量,如下图:
位列前三的框架(Vue、React和Angular),还有一些更小的框架比如preact(这个在react许可证闹剧的时候听说),还有一些自己没有接触没有用过的(Hyperapp、dva等)。
虽然三大框架各有千秋,但是从流行度和生态圈来讲,已经不能像以前一样同日而语了。
但是你还是可以选择使用任何一门框架,但是他们不在具有一样的势头了。
优胜劣汰,或许也是另一种美好,至少不用像我学前端的时候一样,需要去考虑先学哪个,哪个才是潮流。
2017年最成功编译工具无疑是vscode。vscode在编辑器中star增加量毫无悬念是第一名,然后他在受欢迎度排行中排到了第六名,很不错的成绩。
这也证实了VSCode成为我们前端开发者的头号编辑器。
VScode是成功的,但也不是完美的,他有需要改进的地方,按网上的说法,他在用户界面的渲染速度是一个很大缺陷,会导致初始化的时候速度变慢
当然用一句话总结:VSCode比webstorm更轻、比sumlime开源、比atom更快。
GraphQL是facebook在2012年的时候提出,然后在2015年的时候开源,和RESTful对比有优点也有缺点。这是一门查询语言,可能不是主流,但是它强大的功能可能能激起不小的浪花,还是挺期待的,虽然要许久才能用到。
推荐博客
新的打包工具,自己一开始的时候接触过gulp,前端时间搭建公司新项目架子的时候研究过webpack的配置,对于webpack还是挺了解的,webpack需要自己去配置,比如整理entry,output,module,还有一系列的插件,有些许麻烦,不过,webpack有很好的中文文档,但是,新的工具来的势头很猛。看了下面这片博文,知道了点parcel的好处,但是他在2018年还有好多问题要解决,希望我们能用上一个更好的工具。
推荐博客
这个工具在2017年也取得了不小的成就,自动格式化代码,让团队具备统一的代码风格,听起来比eslint还厉害,但是有优点也有缺点,或许在2018年能更智能一点,在配置方面能够更灵活等问题,希望它能变得更好,那我们就又有一个神器了!!!
推荐博客
这个是google发行的,时间好像是8月份,但是还是受到大家的追捧,想了解的也可以了解一下,因为在4个月时间里就可以增加20000stars,
希望2018前端变得更美好,希望自己在2018年还能有过多的产出,希望自己对技术还满怀好奇,有探索的心,希望自己抓住一些不变的东西,巩固自己,充实自己,输出给大家,最后希望学习前端的同志们一起加油!!!个人博客喜欢的可以点个赞,谢谢!!
你好,我这边是杭州阿里支付宝商家组的前端团队,我们团队正在打造一个前端基础研发体系,会涉及大量的工具制作,包括web-ide, ui自动化测试等,有兴趣可以关注这篇文章:https://zhuanlan.zhihu.com/p/34790596
如果觉得不错的话,可以联系我的个人邮箱: [email protected]
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.