A solution to 2021-CCKS-QA-Task(https://tianchi.aliyun.com/competition/entrance/531904/introduction)
这个比赛结束已经大半年了,期间参赛者似乎都没有做方案的开源,讨论区也很冷清。 其实自结束以来一直都想做开源工作,分享自己在算法比赛过程中的思路,奈何学业科研繁忙一直搁置。最近因为机缘巧合,打算践行开源,给有需要的同学,提供一些思路(抛砖引玉233)。同时也希望NLP开源社区可以越来越活跃。 最后这个比赛是我自学NLP之后认真筹备的第一个项目,构建代码时做了很多尝试,比较乱,望见谅。
基于给定的运营商知识图谱,使用模型预测用户所提出问题的答案,任务来自2021CCKS会议在阿里云天池平台组织的算法竞赛。在自然语言处理领域该任务属于KBQA(Knowledge Base Question Answering)。
场景案例
Q:流量日包的流量有多少?
A:100MB
Q:不含彩铃的套餐有哪些?
A:流量月包|流量年包
用以问答的数据的数据包含(数据下载地址 https://tianchi.aliyun.com/dataset/dataDetail?dataId=109340 )
-
知识图谱schema:定义了结点的实体、关系类型。
-
知识图谱三元组:类似于<流量日包, 流量, 100MB>形式的三元组。
-
同义词文件:用户口语化问题中实体的同义词,辅助实体的分类。
-
训练数据:5000条。
-
测试数据:1000条。
| 用户问题 | 答案类型 | 属性名 | 实体 | 约束属性名 | 约束属性值 | 约束算子 | 答案 |
|---|---|---|---|---|---|---|---|
| 我的20元20G流量怎么取消 | 属性值 | 档位介绍-取消方式 | 新惠享流量券活动 | 价格|流量 | 20|20 | =|= | 取消方式_133 |
| 问题 |
|---|
| 什么时候可以办理70元的优酷会员 |
目前知识图谱问答系统在简单句(单实体单属性)上已经取得比较好的效果,而在约束句:条件约束句、时间约束句,以及推理型问句:比较句、最值句、是否型问句以及问句中带有交集、并集和取反的问句等,其逻辑推理能力还有待提升。
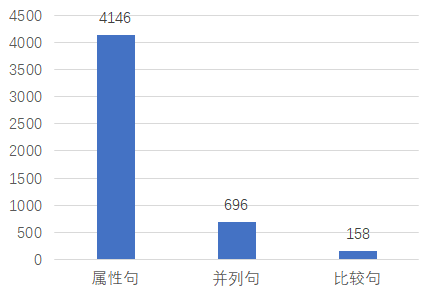
图1展示了问句类型的分布。训练数据中4146个样本是属性句,696条样本是并列句,158条样本是比较句。虽然预测难度较小的属性句占比较大,但是在测试集上取得较高的指标仍然需要聚焦于其他两种类型的数据。
图2展示了数据中的实体分布,前三的实体是新惠享流量券活动,全国亲情网,北京移动plus会员。可以看出实体的分布存在长尾效应,而类别最少的样本仅1条。
为了提高推理的性能,我们算法的整体思路是用NLP模型对文本进行语义解析后,将解析到的成分拼接成SPARQL查询语句,利用查询语句查询知识库得到最终的答案。 语义解析部分分为两个部分
- 多任务分类模型预测答案类型、属性名、实体;
- 命名实体识别模型预测约束属性名和约束属性值。

数据预处理主要分为数据清洗、数据集处理、数据增强三个方面。
数据清洗工作包含了对训练、测试数据,三元组数据的清洗,主要做以下处理
- 英文字母转化成小写形式,例如A—>a
- 中文的数字表示用阿拉伯数字表示,例如五十—>50
- 去除问句中包含的空格
这里的数据集处理主要将原数据转化成可训练的数据格式。
| 用户问题 | 答案类型 | 属性名 | 实体 | 约束属性名 | 约束属性值 | 约束算子 | 答案 |
|---|---|---|---|---|---|---|---|
| 我的20元20G流量怎么取消 | 属性值 | 档位介绍-取消方式 | 新惠享流量券活动 | 价格|流量 | 20|20 | =|= | 取消方式_133 |
答案类型、属性名、实体的预测被作为视作是文本的分类,其中答案类型、实体预测属于多分类任务,属性名是多标签分类任务。约束属性名、约束属性值是在字符级别上的分类,这被我们理解为命名实体识别任务,这就需要将约束属性名对应到原问句中的约束属性值。 在仔细分析标注数据后发现约束属性值基本都会出现在原问句中,如表3中的两个20。因此使用正则匹配的方法自动进行约束属性名和属性值的标注。 标注数据 采用BIEO方法,用train.xlsx中的「约束属性」和「约束值」对「用户问题」进行标注。注意标注前需要统一数字和字母的大小写。标注示例如下:
'我 的 2 0 元 2 0 G 流 量 怎 么 取 消'
'O O B-PRICE E-PRICE O B-FLOW E-FLOW O O O O O O O'
数据增强从主要考虑三个角度
少样本增强 少样本增强的动机是观察到数据中的标签存在分布不平衡的现象。我们利用nlpcda包,使用EDA的方案对数据量少于某个阈值的标签样本进行增强。由于EDA中的随机删除操作会导致模型性能变差,随机删除操作被我们去除。
同义词增强 比赛数据中包含了实体的同义词文件,为了尽最大化利用该数据,提高模型在测试集中的泛化能力,我们利用该文件对问句中的实体用其同义词进行替换,生成新的问句,从而达到扩充训练数据的目的。但是由于同义词较多,初次生成的样本达20000+例,是原训练样本的四倍,增加了训练时间开销且提升效果不明显。通过对数据的分析,我们发现训练集中样本量多的实体其同义词一般也较多。如果直接替换,会加剧标签分布不平衡的问题,从而导致提升不明显。基于这个问题,我们遵从少样本增强的**,对样本量较多的实体按概率来进行同义词替换,对样本量较少的实体全量进行替换。基于该方法,得到增强样本6000+例,提高了训练速度,明显地增加了模型的泛化性能。
基于Bert的文本生成增强 前两种增强方式都是基于原样本的小范围修改,本次增强方式利用nlpcda包中的simbert模型来生成与原句意思相近,但表达方式不同的样本,进一步提升模型的泛化能力。基于该方法得到增强样本4000+例。
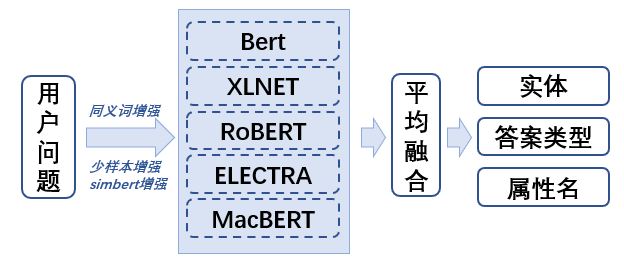
分类模块作用是对答案类型、属性名、实体的分类。由于一个问句只有一个答案类型和一个实体,而可以有多个属性名,所以我们把答案类型和实体分类视作多分类任务,把属性名视作多标签分类任务。 使用多任务学习的考虑是多个相近的任务一起来训练可以提高准确率、学习速度和泛化能力。我们的实验证明多任务模型比单任务模型准确率整体更高且更稳定。 最终的分类结果由五个模型平均融合得到,分别是BERT-base、XLNET-base、RoBERTa-base、ELECTRA-base、MacBERT-base。 接下来开始介绍单模型中使用的方法。
- 任务级的注意力机制

对BERT等预训练模型产生的字符级embedding使用任务级别的Attention机制,得到适合于当前子任务的句子级embedding,进而用于后续的分类器。实验证明结果该注意力机制对于结果的稳定与提升有明显的效果,比赛实验结果无记录。方法详情可见Same Representation, Different Attentions: Shareable Sentence Representation Learning from Multiple Tasks。
- 样本有效率
在经过数据增强操作后,得到了近15000例的增强文本。这些样本的质量或多或少低于原数据,直接用于模型的训练会使模型向这些低质量样本拟合,进而导致模型无法准确学习到原标注样本中数据分布,最终导致训练费时且效果低下。 设置样本有效率权重是解决该问题的一个思路。我们在仔细分析了不同数据增强文本后,为不同方法得到的样本设置了不同的有效率,以让模型可以从这堆样本中学习到东西同时又不会在低质量的样本上过拟合。以下是实验结果。
| Base | Base + 加入样本权重 | |
|---|---|---|
| 复赛结果 | 0.9423 | 0.9453 |
- 二阶段的训练模式
当原数据混合了增强样本,在训练时如果还是按照原来的模式——将训练样本随机划分20%作为验证集,必然会在验证集中混入增强的样本。挑选验证集上表现最佳的模型时,这个模型是在低质量的数据上表现最优,这会导致模型在高质量的测试集下表现得远不如验证集。 我们在解决这个问题的思路是使用两个阶段来训练模型。一阶段时,模型在全量的增强样本上进行训练,不划分验证集,训练λ个epoch,λ作为超参来调整,在训练完后保存该模型参数。二阶段时,加载一阶段的模型并在原训练集上进行“微调”训练,划分20%的数据作为验证集,挑选在验证集上表现最优的模型。实验结果显示,模型有少量的提升,更重要的是由于减少了整体训练的epoch,训练的时间开销减少约一倍。
| 原训练方式 | 二阶段训练 | |
|---|---|---|
| 复赛结果 | 0.9477 | 0.9485 |
| 运行时间 | 50min | 29min |
- 损失函数优化
多任务模型的损失值来自于三个子任务的损失值的加权和,加权方式使用可学习的参数来进行自动调整,相比于固定权重的方法,该方法可以使模型结果更加稳定。比赛实验结果无记录。
本模块目的是为了预测出句子中的「约束属性」和「约束值」。
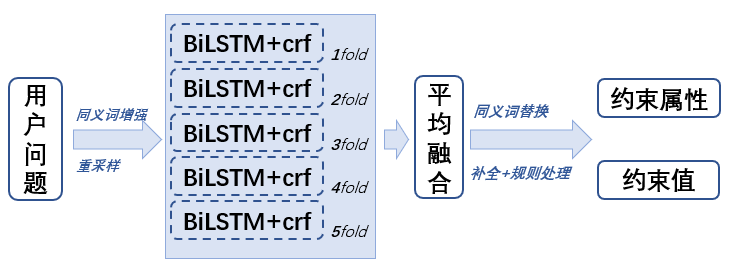
重采样 实体对应很多同义词,但是有些同义词在训练集中出现次数很少,甚至只出现一次,如果该同义词中又出现了价格或者流量等,就很有可能导致预测错误。比如「和家庭流量包」有一个同义词「100元5g」,「100元5g」是一个同义词,其中的「100元」不应该被预测成约束;但是由于「100元5g」在训练集中就只出现了一次,并且其他样本中「100元」经常被标注出来,所以导致模型错误地把同义词中的价格也预测出来了。因此对句子实体存在同义词的样本进行重采样,让模型充分学习这些样本。
同义词增强 同一个实体中不同约束出现的频率不同,比如「天气预报」的价格有「3元」「5元」「6元」三档,但「3元」在训练集中出现次数远少于其他两个。针对这些样本我们对实体进行同义词替换后加入到了训练集。
| base | base + 重采样 | base + 同义词增强 | |
|---|---|---|---|
| 复赛结果 | 0.9518 | 0.9534 | 0.9567 |
模型训练 模型采用了BiLSTM-crf 模型进行训练,数据分为5折交叉训练,batch_size 选用64,lr 选用0.001,epoch选用50。
推理前的同义词替换 很多实体对应大量同义词,其中部分同义词会对实体识别造成干扰(干扰主要是由于同义词中包含价格、流量、子业务),比如「天气预报」和「天气预报年包」是同义词。模型会把「年包」标注出来(但实际不应该标注出来),所以在推理前采用同义词替换,将对标注造成干扰的词进行同义词替换。
推理部分 5折训练的模型分别推理,并将5折模型结果进行平均融合,得分相加取平均再转换到BIEO标的预测结果。
| base | base + 5折平均融合 | base + 5折平均融合+推理前的同义词替换 | |
|---|---|---|---|
| 复赛结果 | 0.9486 | 0.9518 | 0.9544 |
实体识别预测结果补全 实体识别预测出的结果存在部分错误,比如「680」只识别了「68」,或「半年包」只识别了「年包」。针对以上情况,通过判断「年包」前面的字符是否是「半」,「68」紧邻的前后字符是否是数字等,对结果进行补全。
实体识别结果规则处理 对预测结果不合理的部分进行规则处理。比如:(1)价格和流量预测反。通过判断‘元’‘G’等单位,来判断是否出现价格预测成了流量,或者流量预测成了价格的情况。(2)针对容易预测错误的句子,采用规则方法进行纠正。比如「新惠享流量券活动」只需要判断句子中是否存在「20」或者「30」就可以得到约束属性。
空结果处理 在使用SPARQL查询过程中可能会有空结果的情况出现。当发生此类情况时,将模型预测的标签转化成其可能会混淆的标签,设置多层的判定条件,可以尽最大可能性避免空结果的产生。
属性名细分处理 分类模型在“开通方式”和“开通条件”上混淆较为严重。当多任务模型只预测了上述标签中的其中一个,我们使用一个二分类模型和规则方法去修正标签是否正确。二分类模型的分类标签为“开通方式”和“开通条件”。
实体规则处理 使用同义词表中的同义词来修正模型预测的属性名标签结果。
从比赛初期的方案构思到复赛白热化的“军备竞赛”,团队成员在这次比赛中成长了很多,收获了很多。以下是我们本次比赛的总结。
- 知识图谱推理问答与一般的文本匹配或分类任务有较大的不同,获取答案需要有多个维度的信息,系统中每一个薄弱点都可能成为木桶里的“短板”,因此既要兼顾大局又要各个击破。
- 比赛由于任务自身的问题,标注信息没有那么准确,因此需要对数据进行仔细的甄别,有疑问的数据需要去除;
- 由于复赛的docker运行时长只有6小时,所以不光要考虑模型的性能还需要考虑训练的效率;
- 没有万金油的方案,深度学习需要不断实现方案并实验;
此外,由于实验室的学业压力,仍有很多方案没有进行尝试,同时很多方案尝试了但没有提升结果,与前排大佬也有不少差距。希望吸取本次比赛的经验和教训,继续提升自身的实力。
.
└── code
├── data.py # 数据模块
├── data_argument.py # 数据增强模块
├── doc2unix.py # 修改回车符
├── docker_process.py # docker中预处理模块
├── inference.py # 推理模块
├── model.py # 模型结构
├── module.py # 必要模块
├── run.sh # 一键数据处理、训练、推理
├── statistic.py # 数据统计模块
├── test.py # 测试类
├── train.py # 多任务学习训练模块
├── train_evaluate_constraint.py # 命名实体识别训练模块
├── triples.py # 知识图谱与三元组处理模块
└── utils.py # 工具类bert4keras==0.7.7
jieba==0.42.1
Keras==2.3.1
nlpcda==2.5.6
numpy==1.16.5
openpyxl==3.0.7
pandas==1.2.3
scikit-learn==0.23.2
tensorboard==1.14.0
tensorflow-gpu==1.14.0
textda==0.1.0.6
torch==1.5.0
tqdm==4.50.2
transformers==4.0.1
xlrd==2.0.1
rdflib==5.0.0
nvidia-ml-py3==7.352.0
sh run.sh