
The Logging Operator is now a CNCF Sandbox project.
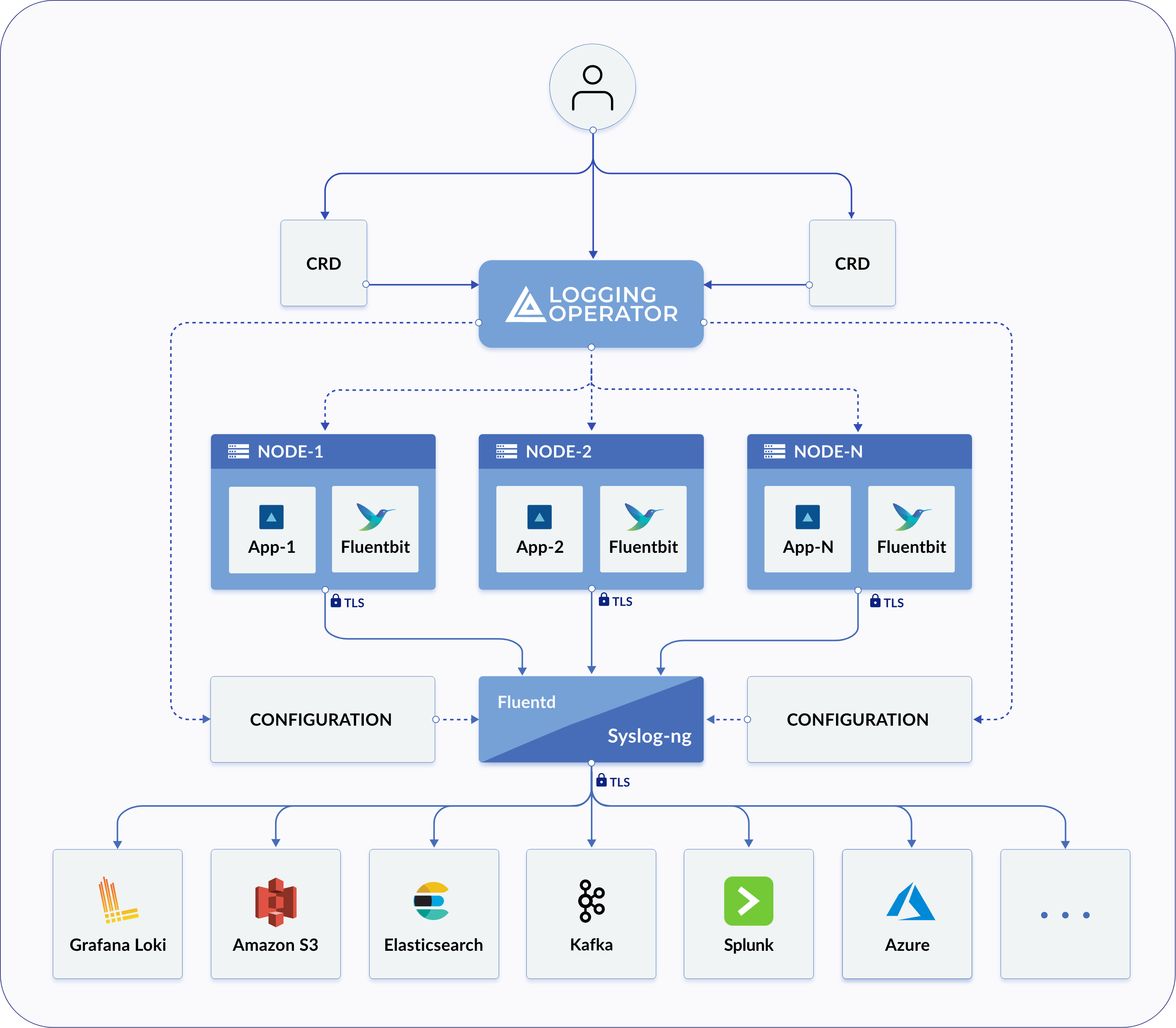
The Logging operator solves your logging-related problems in Kubernetes environments by automating the deployment and configuration of a Kubernetes logging pipeline.
- The operator deploys and configures a log collector (currently a Fluent Bit DaemonSet) on every node to collect container and application logs from the node file system.
- Fluent Bit queries the Kubernetes API and enriches the logs with metadata about the pods, and transfers both the logs and the metadata to a log forwarder instance.
- The log forwarder instance receives, filters, and transforms the incoming the logs, and transfers them to one or more destination outputs. The Logging operator supports Fluentd and syslog-ng as log forwarders.
Your logs are always transferred on authenticated and encrypted channels.
This operator helps you bundle logging information with your applications: you can describe the behavior of your application in its charts, the Logging operator does the rest.
This operator helps you bundle logging information with your applications: you can describe the behavior of your application in its charts, the Logging operator does the rest.
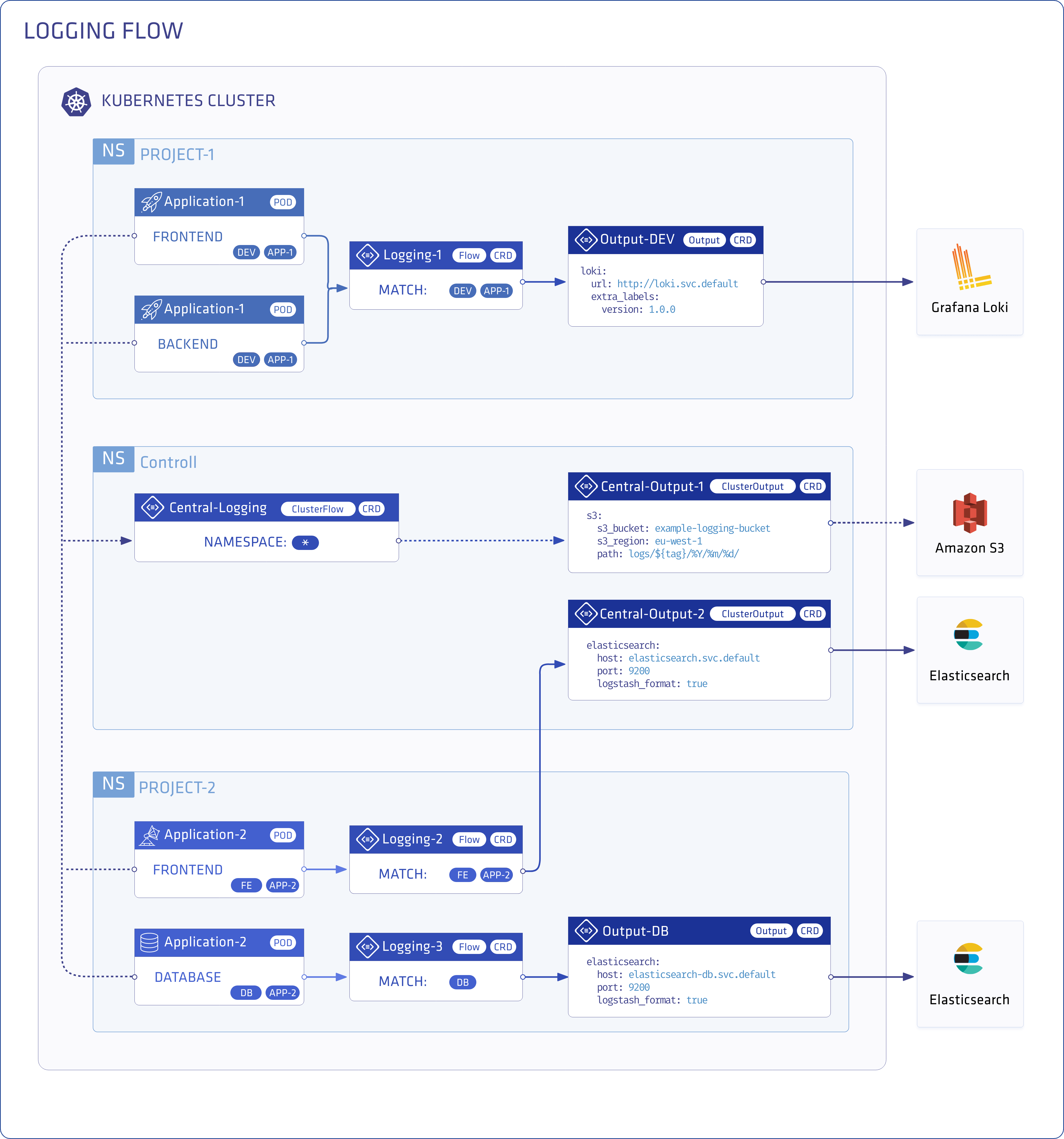
- Namespace isolation
- Native Kubernetes label selectors
- Secure communication (TLS)
- Configuration validation
- Multiple flow support (multiply logs for different transformations)
- Multiple output support (store the same logs in multiple storage: S3, GCS, ES, Loki and more...)
- Multiple logging system support (multiple fluentd, fluent-bit deployment on the same cluster)
The Logging operator manages the log collectors and log forwarders of your logging infrastructure, and the routing rules that specify where you want to send your different log messages.
The log collectors are endpoint agents that collect the logs of your Kubernetes nodes and send them to the log forwarders. Logging operator currently uses Fluent Bit as log collector agents.
The log forwarder instance receives, filters, and transforms the incoming the logs, and transfers them to one or more destination outputs. The Logging operator supports Fluentd and syslog-ng as log forwarders. Which log forwarder is best for you depends on your logging requirements.
You can filter and process the incoming log messages using the flow custom resource of the log forwarder to route them to the appropriate output. The outputs are the destinations where you want to send your log messages, for example, Elasticsearch, or an Amazon S3 bucket. You can also define cluster-wide outputs and flows, for example, to use a centralized output that namespaced users can reference but cannot modify. Note that flows and outputs are specific to the type of log forwarder you use (Fluentd or syslog-ng).
You can configure the Logging operator using the following Custom Resource Definitions.
- Logging - The
Loggingresource defines the logging infrastructure (the log collectors and forwarders) for your cluster that collects and transports your log messages. It also contains configurations for Fluent Bit, Fluentd, and syslog-ng. - CRDs for Fluentd:
- Output - Defines a Fluentd Output for a logging flow, where the log messages are sent using Fluentd. This is a namespaced resource. See also
ClusterOutput. To configure syslog-ng outputs, seeSyslogNGOutput. - Flow - Defines a Fluentd logging flow using
filtersandoutputs. Basically, the flow routes the selected log messages to the specified outputs. This is a namespaced resource. See alsoClusterFlow. To configure syslog-ng flows, seeSyslogNGFlow. - ClusterOutput - Defines a Fluentd output that is available from all flows and clusterflows. The operator evaluates clusteroutputs in the
controlNamespaceonly unlessallowClusterResourcesFromAllNamespacesis set to true. - ClusterFlow - Defines a Fluentd logging flow that collects logs from all namespaces by default. The operator evaluates clusterflows in the
controlNamespaceonly unlessallowClusterResourcesFromAllNamespacesis set to true. To configure syslog-ng clusterflows, seeSyslogNGClusterFlow.
- Output - Defines a Fluentd Output for a logging flow, where the log messages are sent using Fluentd. This is a namespaced resource. See also
- CRDs for syslog-ng (these resources like their Fluentd counterparts, but are tailored to features available via syslog-ng):
- SyslogNGOutput - Defines a syslog-ng Output for a logging flow, where the log messages are sent using Fluentd. This is a namespaced resource. See also
SyslogNGClusterOutput. To configure Fluentd outputs, seeoutput. - SyslogNGFlow - Defines a syslog-ng logging flow using
filtersandoutputs. Basically, the flow routes the selected log messages to the specified outputs. This is a namespaced resource. See alsoSyslogNGClusterFlow. To configure Fluentd flows, seeflow. - SyslogNGClusterOutput - Defines a syslog-ng output that is available from all flows and clusterflows. The operator evaluates clusteroutputs in the
controlNamespaceonly unlessallowClusterResourcesFromAllNamespacesis set to true. - SyslogNGClusterFlow - Defines a syslog-ng logging flow that collects logs from all namespaces by default. The operator evaluates clusterflows in the
controlNamespaceonly unlessallowClusterResourcesFromAllNamespacesis set to true. To configure Fluentd clusterflows, seeclusterflow.
- SyslogNGOutput - Defines a syslog-ng Output for a logging flow, where the log messages are sent using Fluentd. This is a namespaced resource. See also
See the detailed CRDs documentation.

Follow these quickstart guides to try out the Logging operator!
Deploy Logging Operator with our Helm chart.
Caution: The master branch is under heavy development. Use releases instead of the master branch to get stable software.
If you encounter problems while using the Logging operator the documentation does not address, open an issue or talk to us on the #logging-operator Discord channel.
You can find the complete documentation on the Logging operator documentation page 📘
If you find this project useful, help us:
- Support the development of this project and star this repo! ⭐
- If you use the Logging operator in a production environment, add yourself to the list of production adopters.:metal:
- Help new users with issues they may encounter 💪
- Send a pull request with your new features and bug fixes 🚀
Please read the Organisation's Code of Conduct!
For more information, read the developer documentation.
Copyright (c) 2021-2023 Cisco Systems, Inc. and its affiliates Copyright (c) 2017-2020 Banzai Cloud, Inc.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.









![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")











![renovate[bot] avatar](https://avatars.githubusercontent.com/in/2740?v=4 "renovate[bot]")











































































































































