We constructed a controller for Shadow-Hand model in Mujoco environment using Deep Learning & Deep Reinforcement Learning. The controller allows the hand to perform sign-language gestures. The supported gestures of this hand are:
- Rest
- Drop
- Middle Finger
- Yes
- No
- Rock
- Circle
Shadow-Hand DEMO: https://youtu.be/vT_boOel3fU

Shadow-Hand is a 3D Robotic hand provided by mujoco_menagerie repository, for academic and research purposes. It can be found here: https://github.com/deepmind/mujoco_menagerie/tree/main/shadow_hand
Shadow-Hand uses 20 Positional Motors as actuators to enable movement on its fingers and its wrist. It's actuator has a limited control range defined by the manufacturer. The positions of each actuator can be found by downloading the Mujoco Simulator and importing the Shadow-Hand XML file (located in objecs/shadow_hand/scene_left.xml) into the simulator via Drag & Drop. To view the position and orientation of each actuator, Joints option must be enabled inside the simulation window, which can be found in Rendering/Model-Element panel. Alrnatively, they are analytically described inside the xml file.
The position as well as the control range of each actuator of the hand are provided below:
| id | ctrl_limit_left | ctrl_limit_right |
|---|---|---|
| 0 | -0.523599 | 0.174533 |
| 1 | -0.698132 | 0.488692 |
| 2 | -1.0472 | 1.0472 |
| 3 | 0 | 1.22173 |
| 4 | -0.20944 | 0.20944 |
| 5 | -0.698132 | 0.698132 |
| 6 | -0.261799 | 1.5708 |
| 7 | -0.349066 | 0.349066 |
| 8 | -0.261799 | 1.5708 |
| 9 | 0 | 3.1415 |
| 10 | -0.349066 | 0.349066 |
| 11 | -0.261799 | 1.5708 |
| 12 | 0 | 3.1415 |
| 13 | -0.349066 | 0.349066 |
| 14 | -0.261799 | 1.5708 |
| 15 | 0 | 3.1415 |
| 16 | 0 | 0.785398 |
| 17 | -0.349066 | 0.349066 |
| 18 | -0.261799 | 1.5708 |
| 19 | 0 | 3.1415 |

Behavioral Cloning (BC) is a method of teaching controllers to perform tasks by observing and imitating human experts. It's particularly common technique in robotics, where a model learns to perform tasks by imitating humans. This method involves:
- Data Collection: A human expert should construct a dataset, which consists of pairs: (Observations, Actions).
- Learning Algorithm: A learning algorithm (e.g. a neural network) is then designed in order to map the Observations (Inputs) to expected Actions (Outputs).
- Deployment: The controller is then evaluated & deployed on the physical model.
Deep Reinforcement Learning (DRL) is another popular technique for teaching machines to perform tasks in an optimal way, but it differs from Behavioral Cloning. While Behavioral Cloning learns directly from examples (demonstrations) of desired behavior, DRL learns through interaction with an environment and receiving feedback in the form of rewards or penalties. In DRL environments, an agent receives its state
There are two popular family of algorithms that are used in DRL problems:
-
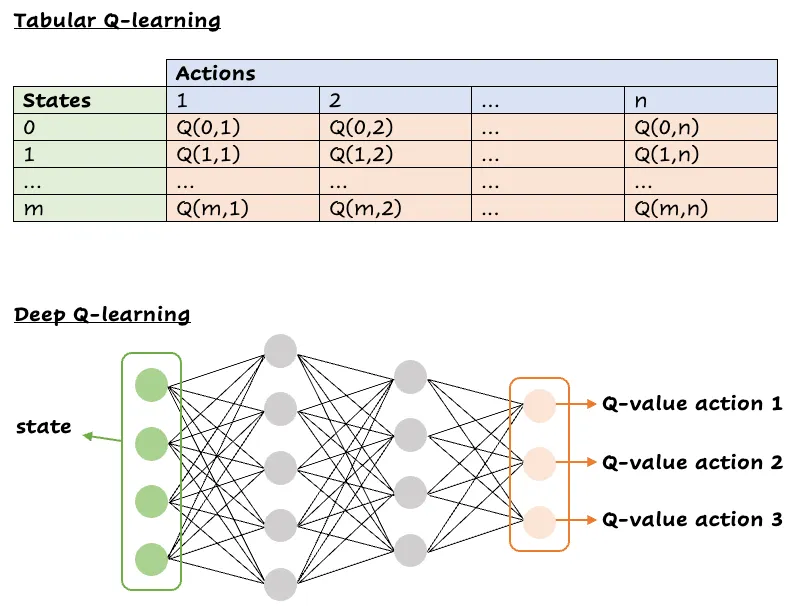
Value-Based Methods: These methods aim to find a value function, which is a measure of the expected cumulative reward an agent can obtain from any given state (or state-action pair). The most common value function is the Q-function, Q(s,a), which measures the expected return from taking action
$a_{t}$ in a state$s_{t}$ . Another way of measuring the expected return is via the use of$V(s)$ , which measures how good is a state$s_{t}$ . Sometimes, these two functions are combined in order to speedup the training process and learning performance of the agent. By estimating the value function correctly, the agent can make optimal transition between consecutive states, and thus learn an optimal behavior. Both Q-Function and Value functions can be estimated using a Neural Network, as shown below.
- Policy-Gradient Methods: Instead of computing the estimated returns, Policy-Gradient methods directly optimize the policy function without the necessity of a value function as an intermediary. The policy is typically parameterized by a set of weights (e.g. a neural network), and learning involves adjusting these weights to maximize expected reward. The idea is that by changing the weights of a neural network, and thus changing the selected actions, it also changes the rewards that the agent receives by the environment. The goal of the agent is to changes its policy (its weights) in the directin that maximizes its rewards, as shown below. One major advantage of Policy-Gradient methods over Value-Based methods is that they allow the use of continuous actions (e.g. float values), instead of discrete actions (e.g. 1,2,3). This is specifically useful in Mujoco environments, such as ours, where the goal is to predict the control (float values) of each actuator.

Both Behavioral Cloning & DRL technique require a dataset or a simulation environment to retrieve the data. To train both agents, we constructed a dataset which consists of pairs
- Sign: Sign is a set of sequential controls, which the hand controller has to execute, in order to perform a sign gesture. For example, in order to perform a "Yes" gesture, the hand must first make a fist (1), then move its hand down (2) and then up again (3).
- Order: Order is the index of the desired control inside the sequence. This is a necessary, because the agent should execute all controls sequentially, in a specified order. For example, in the "Yes" example, the controls (1), (2), (3) must be executed as consecutively.
- Control: Control is a vector (array) of 20 values, one for each actuator. Each value is a float number that controls the position of the actuator and does not exceed its control limits described the above table.
The neural network receives an input vector and outputs the control vector. While the input vector is expected to be a vector of float values, our dataset contains Signs, which are strings (words) and Orders, which are integer numbers. Because the dataset is very small, we converted each word and order to a unique vector as shown below:
| sign | vector |
|---|---|
| rest | [0,0,0,0,0,0,1] |
| drop | [0,0,0,0,0,1,0] |
| middle finger | [0,0,0,0,1,0,0] |
| yes | [0,0,0,1,0,0,0] |
| no | [0,0,1,0,0,0,0] |
| rock | [0,1,0,0,0,0,0] |
| circle | [1,0,0,0,0,0,0] |
| order | vector |
|---|---|
| 1 | [0,0,1] |
| 2 | [0,1,0] |
| 3 | [1,0,0] |
Now, these features can be concatenated and inserted into the neural network/DRL agent controller.
The goal of the neural network is to predict the control values of the 20 actuators:

Proximal Policy Optimization (PPO) is a popular policy gradient algoithm that addresses some challenges in training stability and efficiency faced by Trust Region Policy Optimization (TRPO). PPO introduces a clipping mechanism to prevent the policy from being updated too drastically in any single step (prevents the weights from receiving large updates and change drastically), ensuring that the new policy doesn't deviate too much from the old one. When udating the policy, instead of directly maximizing the expected reward, PPO aims to maximize a clipped version of the objective function. This clipped objective limits the ratio of the probabilities of the new and old policies. Specifically, if the new policy would increase the action's probability significantly compared to the old policy, this change is clipped to be within a specified range (e.g., between 0.8 and 1.2). This prevents overly aggressive updates which could quickly converge into sub-optimal policies. This range is defined by a clipping parameter
Just like BC Neural Network, PPO receives pairs of (sign, order) as inputs and outputs the target control of the hand. Then, instead of using a Loss (Error) Function to evaluate its error, it uses a reward function to receive rewards, which it tries to maximize in each iteration. The reward function

- python==3.9 https://www.python.org/downloads/release/python-390/
- mujoco=2.3.7 https://github.com/deepmind/mujoco
- tensorflow==2.9.1 https://www.tensorflow.org/install
- ray[rllib]==2.3.1 https://docs.ray.io/en/latest/rllib/index.html
- gymnasium==0.26.1 https://gymnasium.farama.org/
- matplotlib==3.7.2 https://matplotlib.org/
- python generate_expert_dataset.py to build a dataset. The hand can switch gestures using key buttons (1-7). THe mouse can be used to navigate through the simulation world
- python train_nn.py to train and evaluate the Neural Network
- python train_ppo.py to train and evaluate PPO agent
- python simulate_neural_network_controller.py to deploy and evaluate the Neural-Network-Based controller
- python simulate_neural_network_controller.py to deploy and evaluate the PPO-Based controller
- trajectory_steps: The number of intermidate controls to execute between two consecutive controls (e.g. if
start_ctrl = [1,1,1], end_ctrl = [2,2,2] and trajectory_steps=5, then the hand executes 2 + 3 controls between [1,1,1] and [2,2,2]. This is only required for visualization purposes, as the simulator instantly execute the controls within a single step. - cam_verbose: Prints the camera position in terminal (This helps initially adjust the camera position & orientation).
- sim_verbose: Prints the controls of each actuator at each timestep.
- one_hot_signs: Whether to one-hot signs and orders. If false, then signs and orders will be returned as strings and integers respectively. However, both the neural network and the drl agent will have to be modified in order to allow the use of strings as input. One way to do it is to add an embedding layer (https://www.tensorflow.org/text/guide/word_embeddings). This could be useful in cases where the number of gestures, as well as the sequence sizes of signs are extremely large, so one-hot encoding method cannot be used.
- learning_rate: The leearning rate of the neural network. This reduces the network updates, ensuring that the network will converge slowly to local minimum. 0.001 is a good typical valuee
- epochs: The number of epochs to train the network (Number of times the dataset will be fed to the network). Defaults to 1000.
- loss_fn: The loss function of neural network. Defaults to "MAE".
- train_iterations: The number of iterarations the agent will be trained. Defaults to 1000.
- seed: The random seed, which is used to generate random numbers. This enables the experiments to be reproduced. Defaults to 0.
A custom Model Controller can be provided in GLFWSimulator class in order o control hand's actuators (Check simulate_neural_network_controller.py and simulate_neural_network_controller.py examples). The following line can be modified
hand_controller = Controller(
model=agent,
ctrl_limits=ctrl_limits
)
so that the agent is replaced with a custom Agent. The agent (or model) should inherit the Controller class, found in controllers/controller.py file and define the following methods:
def _set_sign(self, sign: str): Sets the controller's behavior to specified signdef _get_next_control(self, sign: str, order: int): Gets the next control of the specified sign (e.g. if a sign is defined as 10 sequential controls, thenget_next_controlshould return the next predicted control of that sequence (Check model.py file).
The simulation environment is writen using GLFW library, which is provided by Mujoco. It can easily be modified by modifying the while loop of simulaton/pyopengl.py file.
The Neural Network is built in models/tf/nn.py using Tensorflow library. A custom Neural Network can be built by extending the build method of NeuralNetwork class. The current architectures uses 2 layers of 128 units for each input vector (128 for sign vector and 128 for order vector) and ReLU activation function in each layer. Then, the 2 layers are concatenated into a vector of 256 units, which is then followed by another layer of 128 neurons and finally 20 output units. The final 20 units are used to set the actuator controls.
This repository uses PPO agent of RLLib. However, several things can be added:
- Fine-Tune (search better parameters for PPO). Currently, the algorith, uses the default parameters of PPO, as described by John Schulman et. al in the original paper https://arxiv.org/abs/1707.06347
- Add a stronger learning algorithm: e.g. Soft Actor-Critic, a.k.a. SAC is known to have very strong performance in Mujoco environments: https://arxiv.org/pdf/1801.01290.pdf
- Increase the training iterations: In the pre-trained models provided in this library, both Neural Network and PPO agent were trained for 1000 iterations. Although the Neural Network converged to a small error, PPO requires more training iterations in order to converge. That's the reason PPO's controller appears to have a weird behavior.
- Add a custom Neural Network as the Actor-Critic model. This is a very difficult task to achieve, however, we have created a repository for that purpose as well: https://github.com/kochlisGit/Deep-RL-Frameworks





