# Set environment variables here.
# This script sets variables multiple times over the course of starting an hbase process,
# so try to keep things idempotent unless you want to take an even deeper look
# into the startup scripts (bin/hbase, etc.)
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
# Extra Java CLASSPATH elements. Optional.
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop/
# The maximum amount of heap to use. Default is left to JVM default.
# export HBASE_HEAPSIZE=1G
# Uncomment below if you intend to use off heap cache. For example, to allocate 8G of
# offheap, set the value to "8G".
# export HBASE_OFFHEAPSIZE=1G
# Extra Java runtime options.
# Below are what we set by default. May only work with SUN JVM.
# For more on why as well as other possible settings,
# see http://wiki.apache.org/hadoop/PerformanceTuning
export HBASE_OPTS="-XX:+UseConcMarkSweepGC"
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
# Uncomment one of the below three options to enable java garbage collection logging for the server-side processes.
# This enables basic gc logging to the .out file.
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
# This enables basic gc logging to its own file.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>"
# This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M"
# Uncomment one of the below three options to enable java garbage collection logging for the client processes.
# This enables basic gc logging to the .out file.
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
# This enables basic gc logging to its own file.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>"
# This enables basic GC logging to its own file with automatic log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+.
# If FILE-PATH is not replaced, the log file(.gc) would still be generated in the HBASE_LOG_DIR .
# export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M"
# See the package documentation for org.apache.hadoop.hbase.io.hfile for other configurations
# needed setting up off-heap block caching.
# Uncomment and adjust to enable JMX exporting
# See jmxremote.password and jmxremote.access in $JRE_HOME/lib/management to configure remote password access.
# More details at: http://java.sun.com/javase/6/docs/technotes/guides/management/agent.html
# NOTE: HBase provides an alternative JMX implementation to fix the random ports issue, please see JMX
# section in HBase Reference Guide for instructions.
# export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10101"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10102"
# export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10103"
# export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10104"
# export HBASE_REST_OPTS="$HBASE_REST_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10105"
# File naming hosts on which HRegionServers will run. $HBASE_HOME/conf/regionservers by default.
# export HBASE_REGIONSERVERS=${HBASE_HOME}/conf/regionservers
# Uncomment and adjust to keep all the Region Server pages mapped to be memory resident
#HBASE_REGIONSERVER_MLOCK=true
#HBASE_REGIONSERVER_UID="hbase"
# File naming hosts on which backup HMaster will run. $HBASE_HOME/conf/backup-masters by default.
# export HBASE_BACKUP_MASTERS=${HBASE_HOME}/conf/backup-masters
# Extra ssh options. Empty by default.
# export HBASE_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HBASE_CONF_DIR"
# Where log files are stored. $HBASE_HOME/logs by default.
# export HBASE_LOG_DIR=${HBASE_HOME}/logs
# Enable remote JDWP debugging of major HBase processes. Meant for Core Developers
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8070"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8071"
# export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8072"
# export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8073"
# A string representing this instance of hbase. $USER by default.
# export HBASE_IDENT_STRING=$USER
# The scheduling priority for daemon processes. See 'man nice'.
# export HBASE_NICENESS=10
# The directory where pid files are stored. /tmp by default.
# export HBASE_PID_DIR=/var/hadoop/pids
# Seconds to sleep between slave commands. Unset by default. This
# can be useful in large clusters, where, e.g., slave rsyncs can
# otherwise arrive faster than the master can service them.
# export HBASE_SLAVE_SLEEP=0.1
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=true
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
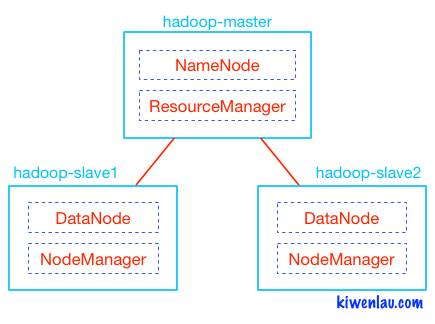
<value>hdfs://hadoop-master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>hadoop-master:60000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop-master,hadoop-slave1,hadoop-slave2,hadoop-slave3,hadoop-slave4</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
</configuration>
hbase(main):001:0> status
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
at org.apache.hadoop.hbase.master.HMaster.checkInitialized(HMaster.java:2293)
at org.apache.hadoop.hbase.master.MasterRpcServices.getClusterStatus(MasterRpcServices.java:777)
at org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:55652)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2180)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:133)
at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:108)
at java.lang.Thread.run(Thread.java:745)
Here is some help for this command:
Show cluster status. Can be 'summary', 'simple', 'detailed', or 'replication'. The
default is 'summary'. Examples:
hbase> status
hbase> status 'simple'
hbase> status 'summary'
hbase> status 'detailed'
hbase> status 'replication'
hbase> status 'replication', 'source'
hbase> status 'replication', 'sink
'
root@hadoop-master:~# jps
2116 Jps
1320 HQuorumPeer
222 NameNode
1430 HMaster
696 ResourceManager
1737 Main
467 SecondaryNameNode