karthuslorin / blog Goto Github PK
View Code? Open in Web Editor NEW格子熊的博客
格子熊的博客






































如果统计一番前端最常用的方法,那么 console.log 一定位列其中。无论你写的是原生 JS 亦或者是 JQuery、Vue等等,调试之时,都离不开 console.log 方法。但是,console 对象中的方法不仅仅只有 log 方法。强大的 console 对象提供了大量控制台调试的相关方法,掌握这些方法可以大大方便你的调试,甚至做出一些炫酷的控制台字符画。
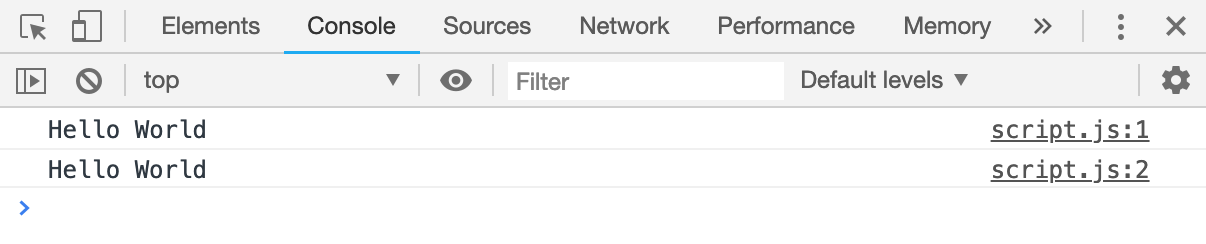
console 对象最基础的方法毫无疑问是 log,该方法会直接在控制台上输出参数,如果输入多个参数,那么输出在控制台上的参数用空格分隔,如下所示:
console.log('Hello World');
console.log('Hello', 'World');打开控制台,运行结果如下图所示:
console.log 还含有类似于 Python 的占位符功能,但是,个人认为该功能可以完全被 ES6 中的字符串模板完全替代,有兴趣的可以去了解,在此不再赘述。
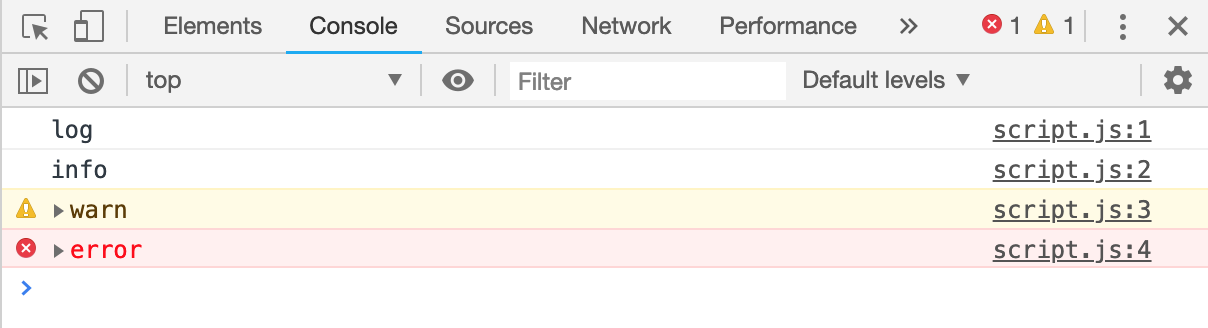
厌倦了 console.log 单调的输出?欢迎尝试 console 对象的分类输出功能。console 对象提供了 info、warn、error 方法分别输出提示、警告以及错误信息。
我们输入下面这段代码:
console.log('log')
console.info('info')
console.warn('warn')
console.error('error')结果如下图所示:
可以发现,warn 和 error 方法分别输出了一条警告和一条错误信息。但是,为什么 log 方法和 info 方法输出是一样的呢?
原因在于,我使用的是 Chrome 浏览器,在 Chrome 浏览器上,log 方法和 info 方法的表现是一样的。但是,在其他浏览器上,比如 FireFox,info 方法前面会有一个信息图标。
由于 info 方法的效果不明显,并且各个浏览器中效果有差异,所以一般情况下,我们使用 log 方法代替 info 方法。
console 对象提供了类似于单元测试中的断言的方法:assert。该方法接收两个参数,第一个参数为断言条件,第二个参数代表断言信息。
同单元测试断言一样,当断言条件为 true 时,assert 无输出;只有当断言条件为 false 时,assert 方法才会在控制台中输出一条断言错误信息。
我们输入以下代码:
console.assert(true, 'true')
console.assert(false, 'false')控制台如下所示:
可以发现,控制台只输出了那一条断言条件为 false 的语句。
当你的控制台上输出了大量信息时,控制台会显得极其杂乱,你甚至不知道某一条信息是哪条代码输出的。此时,console 对象的 group 以及 groupEnd 方法可以拯救你。
将部分 console 语句放入 group 与 groupEnd 之间,可以形成将这部分 console 语句划定为一组信息进行输出。其中,group 方法接收一个字符,作为分组名称,groupEnd 方法不接收参数用于结束分组。
输入以下代码:
console.group('1')
console.log('1-1')
console.warn('1-2')
console.error('1-3')
console.groupEnd()
console.group('2')
console.log('2-1')
console.warn('2-2')
console.error('2-3')
console.groupEnd()结果如图所示:

通过点击分组的箭头,可以折叠分组,方便归纳整理控制台信息,避免控制台被海量信息淹没。
我们不仅可以将控制台信息分组输出,我们还可以将其以表格的形式输出。
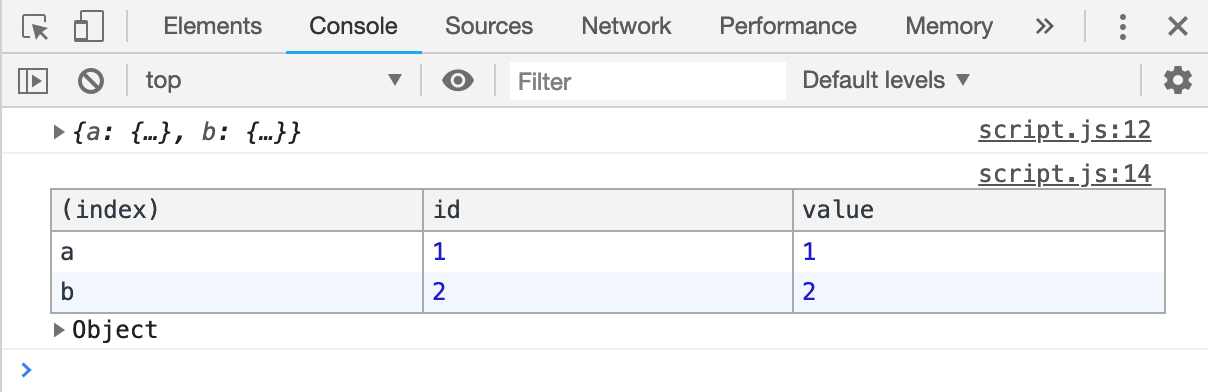
console 的 table 方法可以将一个对象以表格的形式输出,当输入的参数不是对象时,此时,table 方法相当于 log 方法。
输入以下代码:
const obj = {
a: {
id: 1,
value: 1
},
b: {
id: 2,
value: 2
}
};
console.log(obj)
console.table(obj)控制台如图所示:
控制台不仅以表格形式输出了对象,还以基础输出的方式输出了对象以方便查看信息。
在日常开发中,有一个常见的调试需求——计算一段代码的执行次数。一般来说,我们会在这段代码中定义一个变量,每执行一次它就进行一次自增,并通过 console.log 方法输出该变量。
可以看出,上述的方法略显麻烦,可不可以一行代码就解决这个问题呢?当然可以!count 方法,你值得拥有。
for(let i = 0; i < 5; i++){
console.count("num");
}
console.count("num");
console.count("anotherNum")结果如下图所示:
可以发现,count 方法通过输入的字符串区分不同的计数语句。
当测试算法性能时,我们通常使用时间复杂度来评价算法的性能,但是,时间复杂度哪里有代码执行时间来的直观呢?
在之前不了解 console 对象的时候,我们在算法的头尾分别获取时间戳,取时间戳的差值作为代码执行时间。很明显,这种方法太过繁琐。
使用 console 对象的 time 以及 timeEnd 方法可以计算出代码执行时间。
console.time('time');
let sum = 0;
for (let i = 0; i < 100000;i++) {
sum += i;
}
console.timeEnd('time');结果如下图所示:

除了上述的方法,cnosole 方法还有很多强大的方法,比如:dir、debug、trace等,但是它们有的在 Chrome 效果不佳,有的能被 Chrome debugger 完美替代,所以,在此不再赘述。如果有兴趣,可以进一步了解。
很多时候,在直觉上,我们都会认为JS代码在执行时都是自上而下一行一行执行的,但是实际上,有一种情况会导致这个假设是错误的。
a = 2;
var a;
console.log(a);按照传统眼光,console.log(a)输出的应该是undefined,因为var a在a = 2之后。但是,输出的是2。
再看第二段代码:
console.log(a);
var a = 2;有人会想到第一段代码,然后回答undefined。还有人会认为a在使用前未被声明,因此抛出ReferenceError异常。遗憾的是,结果是undefined。
为什么呢?
JS在编译阶段,编译器的一部分工作就是找到所有声明,并用合适的作用域将他们关联起来。对于一般人来说var a = 2仅仅是一个声明,但是,JS编译器会将该段代码拆为两段,即:var a和a = 2。var a这个定义声明会在编译阶段执行,而a = 2这个赋值声明会在原地等待传统意义上的从上到下的执行。
所以,在编译器的角度来看,第一段代码实际上是这样的:
var a; // 编译阶段执行
a = 2;
console.log(a);所以,输出的是2。
类似的,第二个代码片段实际上是这样执行的:
var a;
console.log(a);
a = 2;这样的话,很明显,输出的应该是undefined,因为只对a进行了定义声明,没有对a进行赋值声明。
从上面这两个例子可以看出,变量声明会从它们在代码中出现的位置被移动到当前作用域的最上方进行执行,这个过程叫做提升。
下面,再来看一段代码
foo();
function foo () {
console.log(a);
var a = 2;
}在这个例子中,输出undefined而不会报错,因为,函数变量也能提升。即,实际上像如下的情况运行。
function foo () {
var a;
console.log(a);
a = 2;
}
foo();说到这里,你是不是认为提升很简单,只要把变量都放到当前作用域最上方执行就好了?
下面,我来说一种意外情况:函数表达式的提升情况。
foo();
var foo = function bar () {
console.log(a);
var a = 2;
}你是不是想说,这个例子不是和之前的那个差不多吗?输出的当然是undefined呀。但是,结果是,不输出,因为JS报了TypeError错误!
因为,函数表达式不会进行提升!
该例子的实际运行情况是这样的:
var foo;
foo();
foo = function bar () {
var a;
console.log(a);
a = 2;
}由于执行时,在作用域中找得到foo(该作用域最上方声明了foo),所以不会报ReferenceError错误,但是,foo此时没有进行赋值(如果foo是一个函数声明而不是函数表达式,那么就会赋值),也就是说实际上foo()是对一个值为undefined的变量进行函数调用,所以,理所应当抛出TypeError异常。
值得一提的是,即使是具名的函数表达式,名称标识符在赋值之前也无法在所在作用域中使用,即:
foo(); // TypeError
bar(); // ReferenceError
var foo = function bar () {}函数声明和变量声明都会被提升,但是有一个值得注意的细节,那就是,函数会首先提升,然后才是变量!
看下面这一段代码:
foo();
var foo;
function foo () {
console.log(1);
}
foo = function () {
console.log(2);
}这一段代码会输出1,原因就在于,函数优先。
这一段代码可以转换为以下形式:
function foo () {
console.log(1);
}
var foo; // 重复声明,被忽略
foo(); // 输出1
foo = function () {
console.log(2);
}如果,在代码的结尾再执行一次foo函数,此时,输出的是1。
function foo () {
console.log(1);
}
var foo; // 重复声明,被忽略
foo(); // 输出1
foo = function () {
console.log(2);
}
foo(); // 输出2因为,尽管重复的声明会被忽略了,但是后面的函数还是可以覆盖前面的函数。
明白了这个道理,你就可以理解下面这个问题了:
foo();
var a = true;
if (a) {
function foo () {
console.log("a");
}
} else {
function foo () {
console.log("b");
}
}你猜这道题输出的结果是什么?是b!为什么?因为foo进行了两次的声明,但是,后一次函数覆盖了前一次的函数。所以调用foo时,永远调用的都是console.log("b")。
1.所有声明(变量和函数)都会被移动到各自作用域的最顶端,这个过程被称为提升
2.函数表达式等各种赋值操作并不会被提升
3.函数优先原则
4.尽量避免产生提升问题
前端性能优化一直是前端工作中必不可少的一部分,但是我们如何知道哪些部分的性能有优化的空间呢?此时,Chrome 性能监测就派上用场了。
正所谓:知己知彼,百战百胜,只有确定了性能瓶颈,才能有条不紊地进行前端性能优化工作。
Performance 是 Chrome 开发者工具中的一个功能,用于记录网页从初始化到运行时的所有性能指标。
使用 Performance 之前,我们需要先打开 Chrome 的无痕模式,因为,身为开发者,Chrome 上一般都有着大量的 Chrome 插件,而 Chrome 插件会显著影响页面的性能。所以,我们需要进入无痕模式来规避 Chrome 插件对页面性能的影响。
进入无痕模式后,我们打开需要进行性能监测的网站,开启 Chrome 开发者工具,点击 Performance 选项卡,进入面板。此时的面板什么都没有,只有几个操作提示。
接下来,我们点击左上角的 Record(小圆点)按钮,Performance 进入 Record 阶段,从此刻开始,它会记录用户的交互以及这些交互对页面性能数据的影响。当交互完成后,点击 Stop 来停止 Record ,Performance 面板会展示出刚才录制的页面性能数据。如下所示:

拿到 Performance 性能报告,首先,我们先看顶部的三个数据:FPS、CPU 以及 NET。
接下来,我们来了解一下最杂乱的中间部分,一般情况下,我们主要根据中间部分中 Main 的图表来分析页面性能。
由于 Main 的图表长得像一团团倒立的火焰,所以,我们将其称为火焰图。它展现了主线程在 Record 过程中做的所有事情,包括:Loading、Scripting、Rendering、Painting 等等。火焰图的横轴代表着时间,纵轴代表着调用堆栈。每一个长条代表执行了一个事件或函数,长条的长度代表着耗时的长短,如果某个长条右上角是红色的则表示该函数存在性能问题,需要重点关注。
活用 Performance,按照 Chrome 的提示进行优化,可以解决掉绝大部分的性能问题。
看起来,Performance 提供的性能监测功能已经较为完备,但是,它有两个问题:
为了解决这两个问题,Chrome 提供了 Performance monitor 功能,以实时直观的数据展示页面性能。
相比 Performance ,Performance monitor 所在的位置较为隐蔽,需要以下几个步骤才能打开:
由于 Performance monitor 是实时的,所以,进入面板后,Performance monitor 将会自动运行,记录页面性能数据,通过点击左侧的选项,可以调整记录的数据类型。
相比 Performance,Performance monitor 的功能虽然不够全面,但胜在简洁、实时。通常情况下,可以通过 Performance monitor 来分析页面使用过程中的性能问题,例如:动画性能等。
虽然 Performance 以及 Performance monitor 提供了大量性能数据,但是,如果开发者经验不足,复杂的性能数据无异于天书。那么,Chrome 能不能自动分析出页面的性能缺陷,给出具体的性能优化点呢?万幸,Chrome 提供了 Audits。
Audits 源于著名的开源自动化分析插件——Lighthouse,Lighthouse 不仅能够分析页面性能,还能够对 PWA、无障碍访问、SEO 等进行测试评分,并给出优化建议。为了方便开发者使用,在 Chrome 60 版本,Chrome 开发团队直接将其加入 Chrome 开发者工具中的 Audits 面板中。
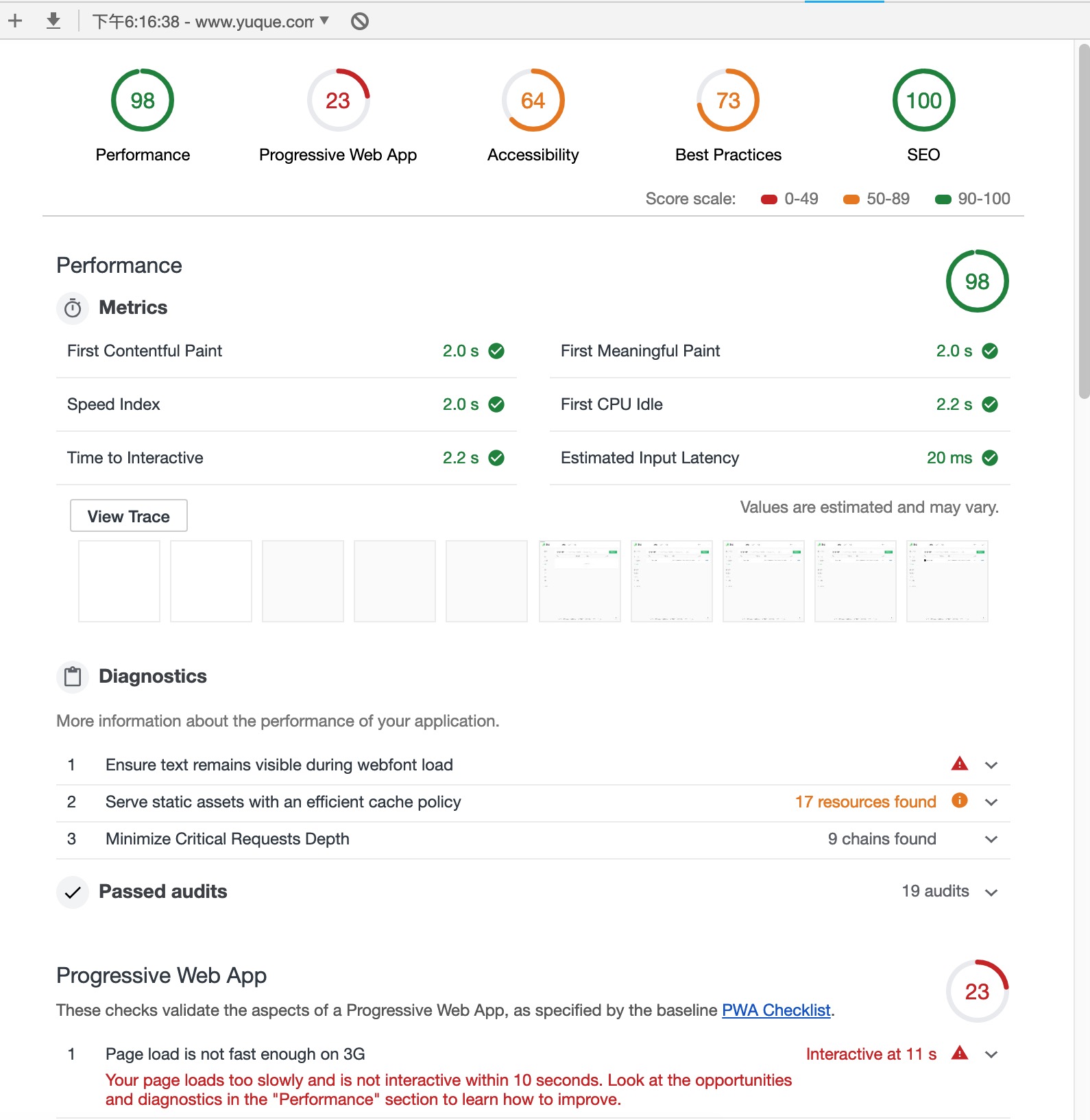
Lighthouse 转正之后,使用该功能不需要安装额外的 Chrome 插件,只需要进入 Audits 面板,点击 Run audits 按钮即可生成一份页面分析报告,如下所示:
通过结果可以看到,Audits 不仅能够自动分析出页面的缺陷,还能根据缺陷给出具体的优化建议。这就意味着,使用了 Audits 之后,我们只需要按照 Audits 给出的优化建议逐条尝试,即可大幅度提高页面性能,实乃前端偷懒神器~
之前我们一直说的是基于 Chrome 浏览器的性能监测方案,但是,其实还有一种不基于浏览器的性能监测方案:编程式性能监测。
编程式性能监测主要依托于 W3C 推出的 Performance API,该套 API 的目的是简化开发者对网站性能进行精确分析与控制的过程,方便开发者采取手段提高 web 性能。
相比之前的性能监测方法,Performance API 最大的优点是:灵活、精确,所以一经推出便风靡全球。比如,Vue 中便封装了 Performance API 方便开发者进行性能追踪。
由于篇幅有限,在此不再赘述,有兴趣的同学可以自行了解。
性能监测是前端性能优化的第一步,只有学会了性能监测,我们才能更好地剖析性能问题,直至彻底解决性能问题。
由于之前的 Vue 项目打包成果物一直是嵌入集成平台中,所以一直没有关注过项目的 title。直到最近,突然有个需求,要求点击按钮在集成平台外新开一个页面,此时我才发现,原来我的项目的 title 一直是万年不变的 vue-project。理所应当的,这个问题被测试爸爸提了一个大大的缺陷。
犯了错的我赶紧解决这个问题,但是经过一段时间的摸索,我却发现,这一个小小的问题,却有着很多不同的解法。
首先,毫无疑问的是,我们应该使用 document.title 方法通过 DOM 操作来修改 title 的值。此时,距离解决问题还差两步:
ps:很多人提到过在微信或者一部分 IOS webview (下文一律以微信指代)中无法通过 document.title 方法修改 title 的值,这个问题的解决方案在文末的彩蛋中会提及。
接下来进入第一个重点:title 的传递。根据传递 title 值的方式,分为两种方案:
何为全局变量传递?全局变量传递指的是所有页面维护同一个全局变量,切换页面对其重新赋值,最常见的方法是使用 Vuex,当然,如果你要使用 this.$root 甚至丧心病狂地想要使用 provide/inject 一样可以达到类似的效果。
路由传递的方法就比较容易理解了,即通过路由跳转传参传递 title 的值。由于业务逻辑中本身就包含大量的路由传参,为了解耦方便后续维护,推荐将 title 的值通过路由配置中的 meta 进行传递。
之后,通过访问当前路由对象($route)的 meta 属性即可获取到 title 值。
// router.js
const routes = [
{
path: '/',
...
meta: {
title: '首页'
}
}, {
path: '/A',
meta: {
title: 'A模块'
}
}
]// 业务模块,获取 title
...
beforeCreate () {
console.log(this.$route.meta)
}
...通过上面的两种方法,可以顺利传递 title 的值。
完成了 title 值的传递,接下来我们谈谈何时该修改 title。
想到这个问题,大多数人第一个想到的应该就是在生命周期钩子中修改 title。
一般情况下,我们在 mounted 生命周期钩子中进行初始化请求,所以惯性思维之下,我在 mounted 中进行了 title 的修改。
// 业务代码
mounted () {
document.title = this.$route.meta.title
}结果,效果不佳,标签页的 title 延迟 1 秒以上才成功修改。通过这个延迟可以发现,显然,我们的代码执行地太晚了!
回忆了一下 Vue 源码中初始化相关的代码细节,我们可以发现,我们甚至在 beforeCreate 钩子中就可以进行 title 的修改。
改动后的代码如下:
// 业务代码
beforeCreate () {
document.title = this.$route.meta.title
}可以发现,修改后的代码效果明显好了许多,延迟感虽然还有,但是已经不太明显。
比起在生命周期钩子中修改 title 值,在路由跳转时利用路由守卫完成 title 的修改,岂不美哉?毕竟路由跳转发生在生命周期函数执行之前,使用路由守卫修改 title 值可以明显降低 title 修改的延时。
// router.js
router.beforeEach((to, from, next) => {
document.title = to.meta.title
next()
})此时,我们基本完美完成了功能需求,但是,还是有一点小瑕疵——如果 meta 中没有定义 title 值,此时 title 值就变成了 undefined,扑街~
所以,我们需要设置默认的 title 值(一般可以是该项目的名称),作为 title 值不存在时的备胎。修改后的代码如下:
// router.js
const defaultTitle = '默认 title'
router.beforeEach((to, from, next) => {
document.title = to.meta.title ? to.meta.title : defaultTitle
next()
})到这里为止,我们完美实现了需求,并且实现了该功能与业务代码的解耦。
vue-meta 插件在安装时,像 Vuex 类似,注入了全局状态——metaInfo,你可以通过定义 metaInfo 对象中的 title 属性,实现 title 的动态修改。
在搜索相关资料的时候,vue-wechat-title 这个包的出现频率出乎意料的高,这个包主要解决了前面提到的那个问题:在微信中无法通过 document.title 方法修改 title 的值。当然,这个兼容性问题都能解决了,正常情况下的 title 修改当然不在话下。
我们先来看看 vue-wechat-title 的源码:
// vue-wechat-title 源码
(function () {
// 插件安装钩子
function install (Vue) {
var setWechatTitle = function (title, img) {
if (title === undefined || window.document.title === title) {
return
}
// 修改 title
document.title = title
var mobile = navigator.userAgent.toLowerCase()
// 兼容性判断
if (/iphone|ipad|ipod/.test(mobile)) {
// 创建空的 iframe,触发 onload 事件
var iframe = document.createElement('iframe')
iframe.style.display = 'none'
// 替换成站标favicon路径或者任意存在的较小的图片即可
iframe.setAttribute('src', img || 'data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7')
// onload 回调函数
var iframeCallback = function () {
setTimeout(function () {
// 卸磨杀驴
iframe.removeEventListener('load', iframeCallback)
document.body.removeChild(iframe)
}, 0)
}
// 定义事件
iframe.addEventListener('load', iframeCallback)
document.body.appendChild(iframe)
}
}
// 定义全局指令,
Vue.directive('wechat-title', function (el, binding) {
// update 钩子,调用 title 修改函数
setWechatTitle(binding.value, el.getAttribute('img-set') || null)
})
}
if (typeof exports === 'object') {
module.exports = install
} else if (typeof define === 'function' && define.amd) {
define([], function () {
return install
})
} else if (window.Vue) {
Vue.use(install)
}
})()由于微信浏览器只在onload 事件中通过 title 的值初始化标题,而后续的 title 修改,无法触发标题的修改。既然 onload 事件能够通过 title 修改标题,那么我创建一个空的 iframe 触发 onload 事件修改了标题后就移除它。这种方式根据 title 修改了标题,并且没有对页面造成额外的影响。
众所周知,vue-wechat-title 通过 v-wechat-title 指令来触发 title 的动态修改,每当指令的值修改后,触发 update 钩子中的回调函数——setWechatTitle。该函数通过前面提到的兼容性处理,实现了document.title 对标题的修改。
最近阅读《JavaScript忍者秘籍》看到了一种有趣的函数:自记忆函数。
何为自记忆函数?书中提到:
记忆化(memoization)是一种构建函数的处理过程,能够记住上次计算结果
通过这句话可以得出,自记忆函数其实就是能够记住上次计算结果的函数。在实现中,我们可以这样进行处理:当函数计算得到结果时,就将该结果按照参数存储起来。采取这种方式时,如果另外一个调用也使用相同的参数,我们则可以直接返回上次存储的结果而不是再计算一遍。
显而易见,像这样避免既重复又复杂的计算可以显著提高性能。对于动画中的计算、搜索不经常变化的数据或任何耗时的数学计算来说,记忆化这种方式是十分有用的。
下面这个例子展现自记忆函数的工作方式:
// 自记忆素数检测函数
function isPrime (value) {
// 创建缓存
if (!isPrime.answers) {
isPrime.answers = {};
}
// 检查缓存的值
if (isPrime.answers[value] !== undefined) {
return isPrime.answers[value];
}
// 0和1不是素数
var prime = value !== 0 && value !== 1;
// 检查是否为素数
for (var i = 2; i < value; i++) {
if (value % i === 0) {
prime = false;
break;
}
}
// 存储计算值
return isPrime.answers[value] = prime
}isPrime函数是一个自记忆素数检测函数,每当它被调用时:
首先,检查它的answers属性来确认是否已经有自记忆的缓存,如果没有,创建一个。
接下来,检查参数之前是否已经被缓存过,如果在缓存中找到该值,直接返回缓存的结果。
如果参数是一个全新的值,进行正常的素数检测。
最后,存储并返回计算值。
自记忆函数有两个优点:
但是,自记忆函数并不是完美的,它一样有着缺陷:
在 TypeScript 中使用联合类型时,往往会碰到这种尴尬的情况:
interface Bird {
// 独有方法
fly();
// 共有方法
layEggs();
}
interface Fish {
// 独有方法
swim();
// 共有方法
layEggs();
}
function getSmallPet(): Fish | Bird {
// ...
}
let pet = getSmallPet();
pet.layEggs(); // 正常
pet.swim(); // ts 报错如上所示,getSmallPet 函数中,既可以返回 Fish 类型的对象,又可以返回 Bird 类型的对象。由于返回的对象类型不确定,所以使用联合类型对象共有的方法时,一切正常,但是使用联合类型对象各自独有的方法时,ts 会报错。
那么如何解决这个问题呢?最粗暴的方法当然是将联合类型转换为 any,不过这种方法不值得提倡,毕竟我们写的是 TypeScript 而不是 AnyScript。
此时,我们使用今天的主角——类型保护,闪亮登场,它可以完美的解决这个问题。
孔乙己说过,茴香豆有四种写法,同理,实现类型保护,也有四种写法。
类型断言是最常用的一种类型保护方法,即直接指定类型。由于,TypeScript 中识别的类型大多是靠 TypeScript 的自动类型推算算出来的,所以会出现上面所说的那种问题,即 TypeScript 不知道具体对象类型是什么,所以不确定有没有联合类型各自独有的方法。
当使用类型断言直接指定类型时,相当于你让 TypeScript 开启了上帝模式,可以直接知道具体类型是联合类型中的那个,此时再使用对象的独有方法就符合 TypeScript 的推断了。
interface Bird {
// 独有方法
fly();
// 共有方法
layEggs();
}
interface Fish {
// 独有方法
swim();
// 共有方法
layEggs();
}
function getSmallPet(): Fish | Bird {
// ...
}
let pet = getSmallPet();
pet.layEggs(); // 正常
// 通过鸭子类型来进行判断
if ((pet as Bird).fly) {
// 类型断言
(pet as Bird).fly()
} else {
// 类型断言
(pet as Fish).swim()
}如果嫌弃通过 as 来进行类型断言不够上流,还可以使用类泛型的写法,即:
let pet = getSmallPet();
pet.layEggs(); // 正常
// 通过鸭子类型来进行判断
if ((<Bird>pet).fly) {
(<Bird>pet).fly()
} else {
(<Fish>pet).swim()
}tips:友情提示,虽然使用类泛型写法进行类型断言看起来高端一些,但是由于在 tsx 中语法存在歧义,所以为了统一起见,推荐使用 as 的方法进行类型断言。
在 JS 中,我们经常使用 in 语法来判断指定的属性是否在指定的对象或其原型链中。
同理,在 TypeScript 中,我们可以通过这种方法确认对象类型。
interface Bird {
// 独有方法
fly();
// 共有方法
layEggs();
}
interface Fish {
// 独有方法
swim();
// 共有方法
layEggs();
}
function getSmallPet(): Fish | Bird {
// ...
}
let pet = getSmallPet();
pet.layEggs(); // 正常
// 使用 in 语法进行类型保护
if ('fly' in pet) {
pet.fly()
} else {
pet.swim()
}原理同类型断言一样,都是引导 TypeScript 的类型推断,确定对象类型。
当联合类型中使用的是 class 而不是 interface 时,instanceof 语法就派上用场了,通过 instanceof 语法可以区分不同的 class 类型。
class Bird {
// 独有方法
fly() {};
// 共有方法
layEggs() {};
}
class Fish {
// 独有方法
swim() {};
// 共有方法
layEggs() {};
}
function getSmallPet(): Fish | Bird {
// ...
}
let pet = getSmallPet();
pet.layEggs(); // 正常
// 使用 in 语法进行
if (pet instanceof Bird) {
pet.fly()
} else {
pet.swim()
}typeof 语法不同于 in 语法以及 instanceof 语法,in 语法以及 instanceof 语法都是用来引导类型推断进行不同对象类型推断,而 typeof 语法常用于基本类型的推断(或者是联合使用基本类型和对象类型)。
简而言之,当使用 typeof 能够区分联合类型中的不同类型时,即可使用它。
function getSmallPet(): number | string {
// ...
}
let pet = getSmallPet();
if (typeof pet === 'number') {
pet++
} else {
pet = Number(pet) + 1
}就如茴香豆的四种写法的本质依然是茴香豆一样,类型保护的四种写法的本质也是一样的,即,引导 TypeScript 中的类型推断将类型推断的多选题变为单选题,这就是类型保护的本质。
CORS全称“跨站资源共享”(Cross-Origin Resource Sharing),它允许浏览器克服浏览器同源策略向跨域服务器发出请求。
说到CORS,那么就不得不提浏览器同源策略,所谓“同源”,是指服务器URL的三个相同:
1.协议相同
2.域名相同
3.端口相同
举个栗子:比如一个URL是http://www.example.com:80/a.html,那么:
http://www.example.com:80/b.html // 同源
https://www.example.com:80/a.html // 非同源(协议不同)
http://www.example1.com:80/a.html // 非同源(域名不同)
http://www.example.com:81/a.html // 非同源(端口不同)如果非同源,那么三种行为将受到限制:
1.非同源页面无法跨域读取浏览器本地数据存储(Cookie、LocalStorage和IndexDB)
2.非同源页面无法跨域获取DOM
3.非同源页面无法跨域发送AJAX请求
那么,为什么浏览器要使用同源策略?
同源策略的目的,是为了保证用户的信息安全,防止被不法分子窃取数据。而众所周知,Cookie包含大量的登录信息,如果一个网页可以跨域访问另一个网站的Cookie,那么不法分子可以通过使用跨域访问获取Cookie然后冒充用户,为所欲为。
由此可见,同源策略是极其有必要的。
但是,很多时候,我们需要跨域发送AJAX请求,此时我们就需要突破同源策略不允许发送跨域AJAX的规定。随着技术的发展,有很多技术可以实现跨域发送AJAX请求,常见的有以下三种:
1.JSONP
2.Websocket
3.CORS
JSONP是CORS技术出来之前最常用的跨域解决方案,最大的特定是兼容性好,简单,不需要进行大的服务器改动。它的基本思路是通过动态添加一个script标签,向服务器请求脚本,脚本中一般调用一个客户端定义的函数,将数据作为参数,调用客户端的函数,而客户端通过操作该函数,可以使用被当做参数传过来的数据。
因为服务器不限制script的跨域,所以不受跨域影响。
众所周知,Websocket是一个持久化协议,常用于解决服务器推送问题。但是,实际上Websocket其实支持跨域通信。通过设置Websocket的origin的字段,可以规定允许跨域的站点。
上面两种方法虽然可以解决跨域,但是,都有着各种问题。
庆幸的是,本文的主角:CORS的出现,彻底解决了跨域问题。
浏览器将跨域AJAX请求分为两类:简单请求和非简单请求,对应有两种不同的处理方式。
何为简单请求?
简单请求就是满足以下两个条件的请求:
1.请求方法为HEAD、GET和POST
2.HTTP请求头只包含:Accept、Accept-Language、Content-Language、Last-Event-ID以及值为application/x-www-form-urlencoded、multipart/form-data、text/plain三者之一的Content-Type
对于简单请求,浏览器可以直接发送请求到服务器,但是会在请求头中添加一个origin字段,该字段用来说明请求的来源。服务器会识别该字段,判断是否允许跨域。
如果允许跨域,服务器会返回结果并在响应头上添加三个字段:
1.Access-Control-Allow-Origin
该字段的值为Origin字段的值,或者是*,表示服务器接受任何源的跨域请求。
2.Access-Control-Allow-Credentials
可选字段,它表示是否允许发送Cookie,值为true时,表示发送请求的时候允许发送Cookie,如果不包含该字段,则表示不允许发送Cookie。
值得一提的是,如果服务器允许发送Cookie,那么不允许将Access-Control-Allow-Origin的值设为*。
3.Access-Control-Expose-Headers
可选字段,在没有该字段的情况下,针对跨域请求,XHR对象的getResponseHeader()方法只能拿到Cache-Control、Content-Language、Content-Type、Expire、Last-Modified、Pragma这六个字段,该字段可以设置额外可以拿到的字段。
不满足简单请求的跨域请求都是非简单请求,比如PUT或DELETE方法。
不同于简单请求的直接向服务器请求,非简单请求会在发送之前,先进行一次“预检”(preflight),即,向服务器发出一个OPTIONS请求,查询服务器是否允许它进行跨域请求。
如果服务器不通过“预检”,会返回一个error,客户端可以通过onerror事件进行捕获。
当服务器通过“预检”后,服务器会进行响应,响应头中含有CORS的相关字段,分别是:
1.Access-Control-Allow-Origin
该字段和简单请求中的同名字段一样。
2.Access-Control-Allow-Methods
该字段表示服务器支持跨域的所有方法,是一个逗号分隔的字符串,如:POST,DELETE。
3.Access-Control-Allow-Headers
该字段表示服务器支持的所有头信息,也是一个逗号分隔的字符串。
4.Access-Control-Allow-Credentials
可选字段,与简单请求中的同名字段一样。
5.Access-Control-Max-Age
可选字段,在一段时间内,浏览器对同一个域名进行非简单跨域请求,只对第一次进行“预检”,而这一次“预检”的结果将被缓存,接下来的请求都通过该结果进行判断。该字段就是用来设置“预检”结果缓存的时间长短,可以将其值设为-1来禁用“预检”缓存。
接收到服务器通过“预检”的响应后,客户端会正式发送真正的请求,接下来的处理方式和简单请求一致。
在当前开发中,当不需要兼容老式浏览器中,我们一般采用CORS的方式进行跨域请求,因为相比Websocket,CORS支持非长连接场景;相比JSONP,CORS支持所有HTTP请求,用法更加平滑。
当然,值得一提的是,当你需要兼容老式浏览器时,JSONP是你唯一的选择~
为什么要写博客?从一开始,这个问题就一直困扰着我。
最开始的时候,写博客的目的是紧跟潮流。毕竟,身为程序员,github 和博客基本是必备的,不论是面试还是吹水,都是一大利器。稀里糊涂的,在 2018 年 1 月 1 日,我在博客园写了第一篇文章。由于当时刚正式工作半年,也写不出什么源码解析、最佳实践之类的文章。所以,刚开始的时候,基本是在记录工作中遇到的 bug,并总结了一些解决这些 bug 的方案。在这一时期,写博客的意义在于总结工作中遇到的问题,方便下次碰到的问题时候快速解决问题。
之后的半年时间中,工作比较忙,再加上懒癌发作,而为了保住自己当时说好的一个月一篇的誓言,经常进行灌水,可以说,那段时间简直是黑历史[捂脸]。
时间到了 2018 年年底,认识了当时掘金的编辑——Linmi 大佬,在他言传身教之下,我系统性的学习了一些写文章的技巧,包括写作规范、标题的取法之类的(虽然我现在还是放不下身段去做一个标题党,哈哈哈)。
由于 2018 年看了 N 多书籍,系统性的巩固了自己的基础,再加上开始阅读一些源码,再再加上写作技巧的提升,当时写了不少自己如今看下来还不错、读者能学到一些东西的文章。
这一时期,我写博客的目的从记录转变成了交流,和各路大神探讨技术。最典型的是 浅谈 class 私有变量,在这篇文章中,轮番被各路大佬教育,更加加深了对文章中提到的知识点的理解。哪怕过了一年半,我依然记得那天晚上,Linmi 小心翼翼的告诉我,他在掘金后台上看到好多读者对我进行了质疑,让我不要生气。其实,互相交流,本来就是提升技术最好的手段,生气你就输了,不是吗?
再到后来,我一度沉迷于文章阅读量,写了几篇小白文,甚至都准备写自己之前最鄙视的 “面试” 系列文章,还好最后理智阻止了我[捂脸]。
之后的之后,由于没有明确写博客对于自己的意义,感到一阵空虚,再加上入职新公司工作繁忙,博客经历了半年的停更。
直到最近,和一些认识的大佬交流之后,我渐渐明确了写博客对于自己的意义:分享 & 交流。一方面分享自己的学习、总结的成果,回馈社区;另一方面,通过交流,提升自己的技术水平。两者结合,形成了一个完美的正反馈的闭环,perfect~
接下来,我会回归初心,以分享和交流的态度写文章,尽量多写一些有价值的文章,不求所谓的阅读量,只求读者能够有自己的收获。
众所周知,在 Vue 中,直接修改对象属性的值无法触发响应式。当你直接修改了对象属性的值,你会发现,只有数据改了,但是页面内容并没有改变。
这是什么原因?
原因在于: Vue 的响应式系统是基于Object.defineProperty这个方法的,该方法可以监听对象中某个元素的获取或修改,经过了该方法处理的数据,我们称其为响应式数据。但是,该方法有一个很大的缺点,新增属性或者删除属性不会触发监听,举个栗子:
var vm = new Vue({
data () {
return {
obj: {
a: 1
}
}
}
})
// `vm.obj.a` 现在是响应式的
vm.obj.b = 2
// `vm.obj.b` 不是响应式的原因在于,在 Vue 初始化的时候, Vue 内部会对 data 方法的返回值进行深度响应式处理,使其变为响应式数据,所以, vm.obj.a 是响应式的。但是,之后设置的 vm.obj.b 并没有经过 Vue 初始化时响应式的洗礼,所以,理所应当的不是响应式。
那么,vm.obj.b可以变成响应式吗?当然可以,通过 vm.$set 方法就可以完美地实现要求,在此不再赘述相关原理了,之后应该会写一篇文章讲述 vm.$set 背后的原理。
上面说了这么多,还没有提到本篇文章的主角——数组,现在该主角出场了。
比起对象,数组的境遇更加凄惨一些,看看官方文档:
由于 JavaScript 的限制,
Vue不能检测以下变动的数组:
- 当你利用索引直接设置一个项时,例如:
vm.items[indexOfItem] = newValue- 当你修改数组的长度时,例如:
vm.items.length = newLength
有可能官方文档不是很清晰,那我们继续举个栗子:
var vm = new Vue({
data () {
return {
items: ['a', 'b', 'c']
}
}
})
vm.items[1] = 'x' // 不是响应性的
vm.items.length = 2 // 不是响应性的也就是说,数组连自身元素的修改也无法监听,原因在于, Vue 对 data 方法返回的对象中的元素进行响应式处理时,如果元素是数组时,仅仅对数组本身进行响应式化,而不对数组内部元素进行响应式化。
这也就导致如官方文档所写的后果,无法直接修改数组内部元素来触发响应式。
那么,有没有破解方法呢?
当然有,官方规定了 7 个数组方法,通过这 7 个数组方法,可以很开心地触发数组的响应式,这 7 个数组方法分别是:
push()pop()shift()unshift()splice()sort()reverse()可以发现,这 7 个数组方法貌似就是原生的那些数组方法,为什么这 7 个数组方法可以触发应式,触发视图更新呢?
你是不是心里想着:数组方法了不起呀,数组方法就可以为所欲为啊?
*瑞啊,这 7 个数组方法是真的可以为所欲为的。
因为,它们是变异后的数组方法。
什么是变异数组方法?
变异数组方法即保持数组方法原有功能不变的前提下对其进行功能拓展,在 Vue 中这个所谓的功能拓展就是添加响应式功能。
将普通的数组变为变异数组的方法分为两步:
先来个思考题:
有这样一个需求,要求在不改变原有函数功能以及调用方式的情况下,使得每次调用该函数都能在控制台中打印出'HelloWorld'
其实思路很简单,分为三步:
看看具体的代码实现:
function A () {
console.log('调用了函数A')
}
const nativeA = A
A = function () {
console.log('HelloWorld')
nativeA()
}可以看到,通过这种方式,我们就保证了在不改变 A 函数行为的前提下对其进行了功能拓展。
接下来,我们使用这种方法对数组原本方法进行功能拓展:
// 变异方法名称
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
const arrayProto = Array.prototype
// 继承原有数组的方法
const arrayMethods = Object.create(arrayProto)
mutationMethods.forEach(method => {
// 缓存原生数组方法
const original = arrayProto[method]
arrayMethods[method] = function (...args) {
const result = original.apply(this, args)
console.log('执行响应式功能')
return result
}
})从代码中可以看出来,我们调用 arrayMethods 这个对象中的方法有两种情况:
arrayMethods 中的方法通过上述方法,我们实现了对数组原生方法进行功能的拓展,但是,有一个巨大的问题摆在面前:我们该如何让数组实例调用功能拓展后数组方法呢?
解决这一问题的方法就是:数组劫持。
数组劫持,顾名思义就是将原本数组实例要继承的方法替换成我们功能拓展后的方法。
想一想,我们在前面实现了一个功能拓展后的数组 arrayMethods ,这个自定义的数组继承自数组对象,我们只需要将其和普通数组实例连接起来,让普通数组继承于它即可。
而想实现上述操作,就是通过原型链。
实现方法如下代码所示:
let arr = []
// 通过隐式原型继承arrayMethods
arr.__proto__ = arrayMethods
// 执行变异后方法
arr.push(1)通过功能拓展和数组劫持,我们终于实现了变异数组,接下来让我们看看 Vue 源码是如何实现变异数组的。
我们来到 src/core/observer/index.js 中在 Observer 类中的 constructor 函数:
constructor (value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
// 检测是否是数组
if (Array.isArray(value)) {
// 能力检测
const augment = hasProto
? protoAugment
: copyAugment
// 通过能力检测的结果选择不同方式进行数组劫持
augment(value, arrayMethods, arrayKeys)
// 对数组的响应式处理
this.observeArray(value)
} else {
this.walk(value)
}
}Observer 这个类是 Vue 响应式系统的核心组成部分,在初始化阶段最主要的功能是将目标对象进行响应式化。在这里,我们主要关注其对数组的处理。
其对数组的处理主要是以下代码
// 能力检测
const augment = hasProto
? protoAugment
: copyAugment
// 通过能力检测的结果选择不同方式进行数组劫持
augment(value, arrayMethods, arrayKeys)
// 对数组的响应式处理,很本文关系不大,略过
this.observeArray(value)首先定义了 augment 常量,这个常量的值由 hasProto 决定。
我们来看看 hasProto:
export const hasProto = '__proto__' in {}可以发现, hasProto 其实就是一个布尔值常量,用来表示浏览器是否支持直接使用 __proto__ (隐式原型) 。
所以,第一段代码很好理解:根据根据能力检测结果选择不同的数组劫持方法,如果浏览器支持隐式原型,则调用 protoAugment 函数作为数组劫持的方法,反之则使用 copyAugment 。
现在我们来看看 protoAugment 以及 copyAugment 。
function protoAugment (target, src: Object, keys: any) {
/* eslint-disable no-proto */
target.__proto__ = src
/* eslint-enable no-proto */
}可以看到, protoAugment 函数极其简洁,和在数组变异思路中所说的方法一致:将数组实例直接通过隐式原型与变异数组连接起来,通过这种方式继承变异数组中的方法。
接下来我们再看看 copyAugment :
function copyAugment (target: Object, src: Object, keys: Array<string>) {
for (let i = 0, l = keys.length; i < l; i++) {
const key = keys[i]
// Object.defineProperty的封装
def(target, key, src[key])
}
}由于在这种情况下,浏览器不支持直接使用隐式原型,所以数组劫持方法要麻烦很多。我们知道该函数接收的第一个参数是数组实例,第二个参数是变异数组,那么第三个参数是什么?
// 获取变异数组中所有自身属性的属性名
const arrayKeys = Object.getOwnPropertyNames(arrayMethods)arrayKeys 在该文件的开头就定义了,即变异数组中的所有自身属性的属性名,是一个数组。
回头再看 copyAugment 函数就很清晰了,将所有变异数组中的方法,直接定义在数组实例本身,相当于变相的实现了数组的劫持。
实现了数组劫持后,我们再来看看 Vue 中是怎样实现数组的功能拓展的。
数组功能拓展的代码位于 src/core/observer/array.js ,代码如下:
import { def } from '../util/index'
// 缓存数组原型
const arrayProto = Array.prototype
// 实现 arrayMethods.__proto__ === Array.prototype
export const arrayMethods = Object.create(arrayProto)
// 需要进行功能拓展的方法
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
/**
* Intercept mutating methods and emit events
*/
methodsToPatch.forEach(function (method) {
// cache original method
// 缓存原生数组方法
const original = arrayProto[method]
// 在变异数组中定义功能拓展方法
def(arrayMethods, method, function mutator (...args) {
// 执行并缓存原生数组方法的执行结果
const result = original.apply(this, args)
// 响应式处理
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// notify change
ob.dep.notify()
// 返回原生数组方法的执行结果
return result
})
})可以发现,源码在实现的方式上,和我在数组变异思路中采用的方法一致,只不过在其中添加了响应式的处理。
Vue 的变异数组从本质上是来说是一种装饰器模式,通过学习它的原理,我们在实际工作中可以轻松处理这类保持原有功能不变的前提下对其进行功能拓展的需求。
ElementUI 作为当前运用的最广的 Vue PC 端组件库,很多 Vue 组件库的架构都是参照 ElementUI 做的。作为一个有梦想的前端(咸鱼),当然需要好好学习一番这套比较成熟的架构。
首先,我们先来看看 ElementUI 的目录结构,总体来说,ElementUI 的目录结构与 vue-cli2 相差不大:
package.json 中指定 typing 字段的值为 声明的入口文件才能生效。说完了文件夹目录,抛开那些常见的 .babelrc、.eslintc 等文件,我们来看看根目录下的几个看起来比较奇怪的文件:
make new 创建组件目录结构,包含测试代码、入口文件、文档。其中 make new 就是 make 命令中的一种。make 命令是一个工程化编译工具,而 Makefile 定义了一系列的规则来制定文件变异操作,常常使用 Linux 的同学应该不会对 Makefile 感到陌生。接下来,我们来看看项目的入口文件。正如前面所说的,入口文件就是 src/index.js :
/* Automatically generated by './build/bin/build-entry.js' */
import Pagination from '../packages/pagination/index.js';
// ...
// 引入组件
const components = [
Pagination,
Dialog,
// ...
// 组件名称
];
const install = function(Vue, opts = {}) {
// 国际化配置
locale.use(opts.locale);
locale.i18n(opts.i18n);
// 批量全局注册组件
components.forEach(component => {
Vue.component(component.name, component);
});
// 全局注册指令
Vue.use(InfiniteScroll);
Vue.use(Loading.directive);
// 全局设置尺寸
Vue.prototype.$ELEMENT = {
size: opts.size || '',
zIndex: opts.zIndex || 2000
};
// 在 Vue 原型上挂载方法
Vue.prototype.$loading = Loading.service;
Vue.prototype.$msgbox = MessageBox;
Vue.prototype.$alert = MessageBox.alert;
Vue.prototype.$confirm = MessageBox.confirm;
Vue.prototype.$prompt = MessageBox.prompt;
Vue.prototype.$notify = Notification;
Vue.prototype.$message = Message;
};
/* istanbul ignore if */
if (typeof window !== 'undefined' && window.Vue) {
install(window.Vue);
}
export default {
version: '2.9.1',
locale: locale.use,
i18n: locale.i18n,
install,
CollapseTransition,
// 导出组件
};总体来说,入口文件十分简单易懂。由于使用 Vue.use 方法调用插件时,会自动调用 install 函数,所以只需要在 install 函数中批量全局注册各种指令、组件,挂载全局方法即可。
ElementUI 的入口文件有两点十分值得我们学习:
下面我们来聊聊自动化生成入口文件,在此之前,有几位同学发现了入口文件是自动化生成的?说来羞愧,我也是在写这篇文章的时候才发现入口文件是自动化生成的。
我们先来看看入口文件的第一句话:
/* Automatically generated by './build/bin/build-entry.js' */
这句话告诉我们,该文件是由 build/bin/build-entry.js 生成的,所以我们来到该文件:
var Components = require('../../components.json');
var fs = require('fs');
var render = require('json-templater/string');
var uppercamelcase = require('uppercamelcase');
var path = require('path');
var endOfLine = require('os').EOL;
// 输出地址
var OUTPUT_PATH = path.join(__dirname, '../../src/index.js');
// 导入模板
var IMPORT_TEMPLATE = 'import {{name}} from \'../packages/{{package}}/index.js\';';
// 安装组件模板
var INSTALL_COMPONENT_TEMPLATE = ' {{name}}';
// 模板
var MAIN_TEMPLATE = `/* Automatically generated by './build/bin/build-entry.js' */
{{include}}
import locale from 'element-ui/src/locale';
import CollapseTransition from 'element-ui/src/transitions/collapse-transition';
const components = [
{{install}},
CollapseTransition
];
const install = function(Vue, opts = {}) {
locale.use(opts.locale);
locale.i18n(opts.i18n);
components.forEach(component => {
Vue.component(component.name, component);
});
Vue.use(InfiniteScroll);
Vue.use(Loading.directive);
Vue.prototype.$ELEMENT = {
size: opts.size || '',
zIndex: opts.zIndex || 2000
};
Vue.prototype.$loading = Loading.service;
Vue.prototype.$msgbox = MessageBox;
Vue.prototype.$alert = MessageBox.alert;
Vue.prototype.$confirm = MessageBox.confirm;
Vue.prototype.$prompt = MessageBox.prompt;
Vue.prototype.$notify = Notification;
Vue.prototype.$message = Message;
};
/* istanbul ignore if */
if (typeof window !== 'undefined' && window.Vue) {
install(window.Vue);
}
export default {
version: '{{version}}',
locale: locale.use,
i18n: locale.i18n,
install,
CollapseTransition,
Loading,
{{list}}
};
`;
delete Components.font;
var ComponentNames = Object.keys(Components);
var includeComponentTemplate = [];
var installTemplate = [];
var listTemplate = [];
// 根据 components.json 文件批量生成模板所需的参数
ComponentNames.forEach(name => {
var componentName = uppercamelcase(name);
includeComponentTemplate.push(render(IMPORT_TEMPLATE, {
name: componentName,
package: name
}));
if (['Loading', 'MessageBox', 'Notification', 'Message', 'InfiniteScroll'].indexOf(componentName) === -1) {
installTemplate.push(render(INSTALL_COMPONENT_TEMPLATE, {
name: componentName,
component: name
}));
}
if (componentName !== 'Loading') listTemplate.push(` ${componentName}`);
});
// 传入模板参数
var template = render(MAIN_TEMPLATE, {
include: includeComponentTemplate.join(endOfLine),
install: installTemplate.join(',' + endOfLine),
version: process.env.VERSION || require('../../package.json').version,
list: listTemplate.join(',' + endOfLine)
});
// 生成入口文件
fs.writeFileSync(OUTPUT_PATH, template);
console.log('[build entry] DONE:', OUTPUT_PATH);build-entry.js 使用了 json-templater 来生成了入口文件。在这里,我们不关注 json-templater 的用法,仅仅研究这个文件的**。
它通过引入 components.json 这个我们前面提到过的静态文件,批量生成了组件引入、注册的代码。这样做的好处是什么?我们不再需要每添加或删除一个组件,就在入口文件中进行多处修改,使用自动化生成入口文件之后,我们只需要修改一处即可。
另外,再说一个鬼故事:之前提到的 components.json 文件也是自动化生成的。由于本文篇幅有限,接下来就需要同学们自己去钻研啦。
坏的代码各有不同,但是好的代码**总是一致的,那就是高性能易维护,随着一个项目代码量越来越大,在很多时候,易维护的代码甚至比高性能但是难以维护的代码更受欢迎,高内聚低耦合的**无论在何时都不会过时。
我一直坚信,我们学习各种源码不是为了盲目模仿它们的写法,而是为了学习它们的**。毕竟,代码的写法很快就会被更多更优秀的写法替代,但是这些**将是最宝贵的财富。
众所周知,在组件式开发中,最大的痛点就在于组件之间的通信。在 Vue 中,Vue 提供了各种各样的组件通信方式,从基础的 props/$emit 到用于兄弟组件通信的 EventBus,再到用于全局数据管理的 Vuex。
在这么多的组件通信方式中,provide/inject 显得十分阿卡林(毫无存在感)。但是,其实 provide/inject 也有它们的用武之地。今天,我们就来聊聊 Vue 中 provide/inject 的应用。
provide/inject 是 Vue 在 2.2.0 版本新增的 API,官网介绍如下:
这对选项需要一起使用,以允许一个祖先组件向其所有子孙后代注入一个依赖,不论组件层次有多深,并在起上下游关系成立的时间里始终生效。如果你熟悉 React,这与 React 的上下文特性很相似。
官网的解释很让人疑惑,那我翻译下这几句话:
provide 可以在祖先组件中指定我们想要提供给后代组件的数据或方法,而在任何后代组件中,我们都可以使用 inject 来接收 provide 提供的数据或方法。
举个官网的🌰:
// 父级组件提供 'foo'
var Provider = {
provide: {
foo: 'bar'
},
// ...
}
// 子组件注入 'foo'
var Child = {
inject: ['foo'],
created () {
console.log(this.foo) // => "bar"
}
// ...
}可以看到,父组件提供的 foo 变量被子组件成功接收并使用。
了解了 provide/inject 是什么后,我们再来使用使用 provide/inject。
在日常开发中,我们经常会使用 Vuex 做状态管理,但是,我个人一直不喜欢使用 Vuex,原因在于 Vuex 为了保持状态可被回溯追踪,使用起来太过繁琐;而我之前参与的项目,较少多人合作,这个功能对于我来说,意义不大,我仅仅只需要 Vuex 中提供全局状态的功能。
那么,有没有方便快捷的实现全局状态的方法呢?当然有,这就是 provide/inject 这个黑科技 API 的一种使用方法。
很多人也许会想到一种方式:在根组件中,传入变量,然后在后代组件中使用即可。
// 根组件提供一个非响应式变量给后代组件
export default {
provide () {
return {
text: 'bar'
}
}
}
// 后代组件注入 'app'
<template>
<div>{{this.text}}</div>
</template>
<script>
export default {
inject: ['text'],
created() {
this.text = 'baz' // 在模板中,依然显示 'bar'
}
}
</script>这个想法,说对也对,说不对也不对,原因在于 provide 的特殊性。
在官网文档中关于 provide/inject 有这么一个提示:
提示:
provide和inject绑定并不是可响应的。这是刻意为之的。然而,如果你传入了一个可监听的对象,那么其对象的属性还是可响应的。
也就是说,Vue 不会对 provide 中的变量进行响应式处理。所以,要想 inject 接受的变量是响应式的,provide 提供的变量本身就需要是响应式的。
由于组件内部的各种状态就是可响应的,所以我们直接在根组件中将组件本身注入 provide,此时,我们可以在后代组件中任意访问根组件中的所有状态,根组件就成为了全局状态的容器,仔细想想,是不是很像 React 中的 context 呢?
代码如下:
// 根组件提供将自身提供给后代组件
export default {
provide () {
return {
app: this
}
},
data () {
return {
text: 'bar'
}
}
}
// 后代组件注入 'app'
<template>
<div>{{this.app.text}}</div>
</template>
<script>
export default {
inject: ['app'],
created() {
this.app.text = 'baz' // 在模板中,显示 'baz'
}
}
</script> 也许有的同学会问:使用 $root 依然能够取到根节点,那么我们何必使用 provide/inject 呢?
在实际开发中,一个项目常常有多人开发,每个人有可能需要不同的全局变量,如果所有人的全局变量都统一定义在根组件,势必会引起变量冲突等问题。
使用 provide/inject 不同模块的入口组件传给各自的后代组件可以完美的解决该问题。
既然 provide/inject 如此好用,那么,为什么 Vue 官方还要推荐我们使用 Vuex,而不是用原生的 API 呢?
我在前面提到过,Vuex 和 provide/inject 最大的区别在于,Vuex 中的全局状态的每次修改是可以追踪回溯的,而 provide/inject 中变量的修改是无法控制的,换句话说,你不知道是哪个组件修改了这个全局状态。
Vue 的设计理念借鉴了 React 中的单向数据流原则(虽然有 sync 这种破坏单向数据流的家伙),而 provide/inject 明显破坏了单向数据流原则。试想,如果有多个后代组件同时依赖于一个祖先组件提供的状态,那么只要有一个组件修改了该状态,那么所有组件都会受到影响。这一方面增加了耦合度,另一方面,使得数据变化不可控。如果在多人协作开发中,这将成为一个噩梦。
在这里,我总结了两条条使用 provide/inject 做全局状态管理的原则:
看起来,使用 provide/inject 做全局状态管理好像很危险,那么有没有 provide/inject 更好的使用方式呢?当然有,那就是使用 provide/inject 编写组件。
###使用 provide/inject 编写组件
使用 provide/inject 做组件开发,是 Vue 官方文档中提倡的一种做法。
以我比较熟悉的 elementUI 来举例:
在 elementUI 中有 Button(按钮)组件,当在 Form(表单)组件中使用时,它的尺寸会同时受到外层的 FormItem 组件以及更外层的 Form 组件中的 size 属性的影响。
如果是常规方案,我们可以通过 props 从 Form 开始,一层层往下传递属性值。看起来只需要传递传递两层即可,还可以接受。但是,Form 的下一层组件不一定是 FormItem,FormItem 的下一层组件不一定是 Button,它们之间还可以嵌套其他组件,也就是说,层级关系不确定。如果使用 props,我们写的组件会出现强耦合的情况。
provide/inject 可以完美的解决这个问题,只需要向后代注入组件本身(上下文),后代组件中可以无视层级任意访问祖先组件中的状态。
部分源码如下:
// Button 组件核心源码
export default {
name: 'ElButton',
// 通过 inject 获取 elForm 以及 elFormItem 这两个组件
inject: {
elForm: {
default: ''
},
elFormItem: {
default: ''
}
},
// ...
computed: {
_elFormItemSize() {
return (this.elFormItem || {}).elFormItemSize;
},
buttonSize() {
return this.size || this._elFormItemSize || (this.$ELEMENT || {}).size;
},
//...
},
// ...
};其实在 Vue 的学习中,遵循着二八法则,我们常用的 20% 的 API 就能解决大部分日常问题,剩余的 API 感觉用处不大。但是,抽点时间去了解那些冷门的 API,也许你能发现一些不一般的风景,令你在解决一些问题时,事半功倍。
在 es6 之前,虽然 JS 和 Java 同样都是 OOP (面向对象)语言,但是在 JS 中,只有对象而没有类的概念。
在 JS 中,生成实例对象的传统方法是通过构造函数,如下所示:
function A (x) {
this.x = x
}
// 在原型链上挂载原型方法
A.prototype.showX = function () {
return this.x
}
// 生成对象实例
let a = new A(1)
// 调用原型方法
a.showX() // 1对比传统 OOP 语言中的类写法,这种写法让许多学过其他 OOP 语言的 JS 初学者感到困惑。
为了实现在 JS 中写 Java 的心愿,当时有人将构造函数写法封装成了类似于 Java 中类的写法的 klass 语法糖 。
有人会问,为什么是 klass 而不是 class ?当然是因为 class 是 JS 中的保留关键字,直接用 class 会报错。
就这样凑合着过了好多年,直到 es6 发布,在 es6 中, klass 终于备胎转正,摇身一变变成了 class ,终于从官方角度实现了梦想。
之前的代码转换成 class 是这样的:
class A {
// 构造函数,相当于之前的函数A
constructor(x) {
this.x = x
}
// 相当于挂载在原型链上的原型方法
showX () {
return this.x
}
}
// 生成对象实例
let a = new A(1)
// 调用原型方法
a.showX() // 1可以发现, class 的写法更接近传统 OOP 语言。
看起来, es6 中 class 的出现拉近了 JS 和传统 OOP 语言的距离。但是,就如之前所说的 klass 一样,它仅仅是一个语法糖罢了,不能实现传统 OOP 语言一样的功能。在其中,比较大的一个痛点就是私有变量问题。
何为私有变量?私有变量就是只能在类内部访问的变量,外部无法访问的变量。在开发中,很多变量或方法你不想其他人访问,可以定义为私有变量,防止被其他人使用。在 Java 中,可以使用 private 实现私有变量,但是可惜的是, JS 中并没有该功能。
来看下下面这个代码:
class A {
constructor(x) {
this.x = x
}
// 想要通过该方法来暴露x
showX () {
return this.x
}
}
let a = new A(1)
// 直接访问x成功
a.x // 1可以看到,虽然本意是通过方法 showX 来暴露 x 的值,但是可以直接通过 a.x 来直接访问 x 的值。
很明显,这影响了代码的封装性。要知道,这些属性都是可以使用 for...in 来遍历出来的。
所以,实现 class 的私有变量功能是很有必要的。
虽然, class 本身没有提供私有变量的功能,但是,我们可以通过通过一些方式来实现类似于私有变量的功能。
首先,是目前使用最广的方式:约定命名,又称为:自己骗自己或者潜规则。
该方式很简单,就是团队自行约定一种代表着私有变量的命名方式,一般是在私有变量的名称前加上一个下划线。代码如下:
class A {
constructor(x) {
// _x 是一个私有变量
this._x = x
}
showX () {
return this._x
}
}
let a = new A(1)
// _x 依然可以被使用
a._x // 1
a.showX() //1可以发现,该方法最大的优点是简单、方便,所以很多团队都采用了这种方式。
但是,该方式并没有从本质上解决问题,如果使用 for...in 依然可以遍历出所谓的私有变量,可以说是治标不治本。
不过,该方式有一点值得肯定,那就是通过约定规范来方便他人阅读代码。
闭包在很多时候被拿来解决模块化问题,显而易见,私有变量本质上也是一种模块化问题,所以,我们也可以使用闭包来解决私有变量的问题。
我们在构造函数中定义一个局部变量,然后通过方法引用,该变量就成为了真正的私有变量。
class A {
constructor (x) {
let _x = x
this.showX = function () {
return _x
}
}
}
let a = new A(1)
// 无法访问
a._x // undefined
// 可以访问
a.showX() // 1该方法最大的优点就是从本质解决了私有变量的问题。
但是有个很大的问题,在这种情况下,引用私有变量的方法不能定义在原型链上,只能定义在构造函数中,也就是实例上。这导致了两个缺点:
进阶版闭包方式可以基本完美解决上面的那个问题:既然在构造函数内部定义闭包那么麻烦,那我放在 class 外面不就可以了吗?
我们可以通过 IIFE (立即执行函数表达式) 建立一个闭包,在其中建立一个变量以及 class ,通过 class 引用变量实现私有变量。
代码如下:
// 利用闭包生成IIFE,返回类A
const A = (function() {
// 定义私有变量_x
let _x
class A {
constructor (x) {
// 初始化私有变量_x
_x = x
}
showX () {
return _x
}
}
return A
})()
let a = new A(1)
// 无法访问
a._x // undefined
// 可以访问
a.showX() //1可以发现,该方法完美解决了之前闭包的问题,只不过写法相对复杂一些,另外,还需要额外创建 IIFE ,有一点额外的性能开销。
注1:该方式也可以不使用 IIFE ,可以直接将私有变量置于全局,但是这不利于封装性,所以,我在这里采用了 IIFE 的方式。
注2:对于 IIFE 是否是个闭包,在 You-Dont-Know-JS 这本书中有过争议,有兴趣的同学可以前去了解一下,在此不再赘述。
这种方式利用的是 Symbol 的唯一性—— 敌人最大的优势是知道我方key值,我把key值弄成唯一的,敌人不就无法访问了吗? (人质是这次任务的关键,当敌人不再拥有人质时,任务也就完成了)
代码如下:
// 定义symbol
const _x = Symbol('x')
class A {
constructor (x) {
// 利用symbol声明私有变量
this[_x] = x
}
showX () {
return this[_x]
}
}
let a = new A(1)
// 自行定义一个相同的Symbol
const x = Symbol('x')
// 无法访问
a[x] // undefined
// 可以访问
a.showX() //1从结果来看,完美地实现了 class 私有变量。
个人认为,这是目前最完美的实现私有变量的方式,唯一的缺点就是 Symbol 不太常用,很多同学不熟悉。
针对 es6 中的 class 没有私有属性的问题,产生了一个提案——在属性名之前加上 # ,用于表示私有属性。
class A {
#x = 0
constructor (x) {
#x = x
}
showX () {
return this.#x
}
}很多同学会有一个问题,私有属性提案为什么不使用 private 而使用 # ?是人性的扭曲还是道德的沦丧? 这一点和编译器性能有关(其实我个人认为还有一大原因是向 Python 靠拢,毕竟从 es6 以来, JS 一直向着 Python 发展),有兴趣的同学可以去了解了解。
不过该提案仅仅还是提案罢了,并没有进入标准,所以依然无法使用。
如果上述所有方法全都满足不了你,还有一个终极方法—— TypeScript 。使用 TS ,让你享受在 JS 中写 Java 的快感!区区私有变量,不在话下。
就今年的发展趋势来看, TS 已经成为前端必备的技能之一,连之前 diss 过 TS 的尤大都已经开始用 TS 重写 Vue 了(尤大:真香)。
每当有人问起:你们的公司的这款应用用户体验怎么样呀?访问量怎么样?此时,你该怎么回答呢?你会回答:UV、PV 巴拉巴拉,秒开率、FP、TTI 巴拉巴拉。
那么,这些数据是哪里来的呢?显而易见,这些数据都来自前端监控系统。
当今时代,是一个快节奏的时代,应用的性能极大影响着用户的留存率,没有用户会忍受一个卡到爆的应用。而监控应用性能的重担,就由前端监控系统肩负着。
其次,对于线上应用来说,故障是不可避免的,对于高日活的应用来说,每次故障都意味着大量的损失。试想,如果是淘宝挂了一天,那么损失是多么惨痛。所以,对于开发人员来说,必须要尽早发现线上故障,而不是等到客户打爆客服的电话才发现。线上错误监控,也是前端监控的任务之一。
最后,作为商业公司,需要根据用户行为和数据进行分析,进一步制定各种策略,如果没有各种数据,那么 BI 会热情的找你谈谈人生。而这些数据,也是前端监控系统获取的。
总而言之,前端监控肩负着:性能监控、错误监控以及数据上报等功能,无论对于大公司还是小公司,可以说是必不可缺的了。
今天,我们先来聊聊前端监控中的错误监控。
一般来说,按照错误监控错误监控可以分为:脚本错误监控、请求错误监控以及资源错误监控。
脚本错误大体可以分为两种:编译时错误以及运行时错误。其中,编译时错误一般在开发阶段就会发现,配合 lint 工具比如 eslint、tslint 等以及 git 提交插件比如 husky 等,基本可以保证线上代码不出现低级的编译时错误。大厂一般都有发布前置检测平台,能够在发布前提前发现编译时错误,当然,原理依然和之前所说的类似。
而发现并上报运行时错误就是前端检测平台的本质工作啦,一般来说,脚本错误监控指的就是运行时错误监控。
说到脚本错误监控,你想到的第一个是什么?对,就是 try catch !
在编写 JavaScript 时,我们为了防止出现错误阻塞程序,我们会通过 try catch 捕获错误,对于错误捕获,这是最简单也是最通用的方案。
但是,try catch 捕获错误是侵入式的,需要在开发代码时即提前进行处理,而作为一个监控系统,无法做到在所有可能产生错误的代码片段中都嵌入 try catch。所以,我们需要全局捕获脚本错误。
当页面出现脚本错误时,就会产生 onerror 事件,我们只需捕获该事件即可。
/**
* @description window.onerror 全局捕获错误
* @param event 错误信息,如果是
* @param source 错误源文件URL
* @param lineno 行号
* @param colno 列号
* @param error Error对象
*/
window.onerror = function (event, source, lineno, colno, error) {
// 上报错误
// 如果不想在控制台抛出错误,只需返回 true 即可
};可以发现,各种错误监控所需的信息,如错误信息、错误源文件的 URL、错误行号、错误列号都被回调函数所传入。
但是,window.onerror 有两个缺点:
window.onerror 显然无法完成;同时,不同回调函数直接容易造成互相覆盖。所以,一般情况下,我们使用 addEventListener 来代替。
/**
* @param event 事件名
* @param function 回调函数
* @param useCapture 回调函数是否在捕获阶段执行,默认是false,在冒泡阶段执行
*/
window.addEventListener('error', (event) => {
// addEventListener 回调函数的离散参数全部聚合在 error 对象中
// 上报错误
}, true)tips:在一些特殊情况下,我们依然需要使用 window.onerror。比如,不期望在控制台抛出错误时,因为只有 window.onerror 才能阻止抛出错误到控制台
使用了这两种方法,是不是可以捕获所有脚本错误了呢?这个问题再几年前其实是正确的,但是随着前端技术的发展,出现了 Promise 这项技术,而使用这两种常规方法无法捕获 Promise 错误。
和常规脚本错误的捕获一样,我们只需捕获 Promise 对应的错误事件即可。而 Promise 错误事件有两种,unhandledrejection 以及 rejectionhandled。
当 Promise 被 reject 且没有 reject 处理器的时候,会触发 unhandledrejection 事件。
当 Promise 被 reject 且有 reject 处理器的时候,会触发 rejectionhandled 事件。
// unhandledrejection 推荐处理方案
window.addEventListener('unhandledrejection', (event) => {
console.log(event)
}, true);
// unhandledrejection 备选处理方案
window.onunhandledrejection = function (error) {
console.log(error)
}
// rejectionhandled 推荐处理方案
window.addEventListener('rejectionhandled', (event) => {
console.log(event)
}, true);
// rejectionhandled 备选处理方案
window.onrejectionhandled = function (error) {
console.log(error)
}由于我 React 使用的不多,所以在此只讨论下 Vue 的框架错误处理,如果有大佬了解 React 的框架错误处理,欢迎补充~
在 Vue 中,框架提供了 errorHandler 这个 API 来捕获并处理错误。
Vue.config.errorHandler = function (err, vm, info) {
// handle error
// `info` 是 Vue 特定的错误信息,比如错误所在的生命周期钩子
// 只在 2.2.0+ 可用
}值得一提的是,框架错误指的不是框架层面的错误,而是指框架提供了 API 来捕获全局错误。
一般来说,前端请求有两种方案,使用 ajax 或者 fetch ,所以只需重写两种方法,进行代理,即可实现请求错误监控。
代理的核心在于使用 apply 重新执行原有方法,并且在执行原有方法之前进行监听操作。在请求错误监控中,我们关心三种错误事件:abort,error 以及 timeout,所以,只需在代理中对这三种事件进行统一处理即可。
tips:如果能够统一使用一种请求工具,如 axios 等,那么不需要重写 ajax 或者 fetch 只需在请求拦截器以及响应拦截器进行处理上报即可
资源错误监控本质上和常规脚本错误监控一样,都是监控错误事件实现错误捕获。
那么如果区分脚本错误还是资源错误呢?我们可以通过 instanceof 区分,脚本错误参数对象 instanceof ErrorEvent,而资源错误的参数对象 instanceof Event。
值得一提的是,由于 ErrorEvent 继承于 Event ,所以不管是脚本错误还是资源错误的参数对象,它们都 instanceof Event,所以,需要先判断脚本错误。
此外,两个参数对象之间有一些细微的不同,比如,脚本错误的参数对象中包含 message ,而资源错误没有,这些都可以作为判断资源错误或者脚本错误的依据。
/**
* @param event 事件名
* @param function 回调函数
* @param useCapture 回调函数是否在捕获阶段执行,默认是false,在冒泡阶段执行
*/
window.addEventListener('error', (event) => {
if (event instanceof ErrorEvent) {
console.log('脚本错误')
} else if (event instanceof Event) {
console.log('资源错误')
}
}, true);tips:使用 addEventListener 捕获资源错误时,一定要将 useCapture 即第三个选项设为 true,因为资源错误没有冒泡,所以只能在捕获阶段捕获。同理,由于 window.onerror 是通过在冒泡阶段捕获错误,所以无法捕获资源错误。
为了性能方面的考虑,我们一般会将脚本文件放到 CDN ,这种方法会大大加快首屏时间。但是,如果脚本报错,此时,浏览器出于于安全方面的考虑,对于不同源的脚本报错,无法捕获到详细错误信息,只会显示 Script Error。那么,有解决该问题的方案吗?
CDN ,降低性能。script 标签中,添加 crossorigin 属性(推荐使用 webpack 插件自动添加);同时,配置 CDN 服务器,为跨域脚本配上 CORS。可以发现,方案二基本可以完美解决跨域脚本错误捕获的问题。但是,其实该方案有一个隐藏的坑,即兼容性问题,crossorigin 属性对于 IE 以及 Safari 支持程度不高。
所以,该如何真正完美的解决跨域脚本错误捕获问题?
终极解决方案:对所有原生方法进行代理~
但是,一方面,很难覆盖所有的原生方法,另一方面,对原生方法进行代理容易出现无法预知的问题。
综合所有方案,看起来还是方案二最靠谱,至于低级浏览器,就让它们随风消逝吧~
如果有不同想法的同学,欢迎一起交流~
原文地址:https://medium.com/javascript-scene/rethinking-unit-test-assertions-55f59358253f
作者:Eric Elliott
「断言」是编程术语,表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真,可以在任何时候启用和禁用断言验证,因此可以在测试时启用断言而在部署时禁用断言。同样,程序投入运行后,最终用户在遇到问题时可以重新启用断言。
每当测试失败的时候,靠谱的自动化测试总能生成一份优秀的错误报告(bug report),但是很少有开发者花时间去思考一个好的错误报告需要哪些信息。
在此之前,我已经详细地叙述过 每个单元测试必须回答的 5 个问题 ,所以这次我们将它们一笔带过。
许多测试框架允许你忽略这些问题中的一个或者多个,这会导致错误报告并不实用。
让我们看一下使用一个虚拟测试框架的示例,该框架提供常用的 pass() 以及 fail() 断言。
describe('addEntity()', async ({ pass, fail }) => {
const myEntity = { id: 'baz', foo: 'bar' };
try {
const response = await addEntity(myEntity);
const storedEntity = await getEntity(response.id);
pass('should add the new entity');
} catch(err) {
fail('failed to add and read entity', { myEntity, error });
}
});我们走在正确的轨道上,但是我们遗漏了一些信息。让我们尝试使用此测试中提供的数据回答 5 个问题:
addEntity()should add the new entitypromise ,我们应该测试结果值。满分为 5 分的情况下,我的得分为 2.5 分。这项测试没有完成它应尽的职责。显然没有回答每个单元测试必须回答的 5 个问题。
大多数测试框架的问题在于它们的功能太过强大,你可以轻松地使用它们提供的各种 “方便(convenient)” 断言,以至于忘记了在测试失败时实现测试的最大价值。
在失败阶段,编写测试问题让我们更加容易弄清楚出了什么问题。
在 每个单元测试必须回答的 5 个问题 ,我这样写道:
equal() 是我最喜欢的断言。如果每个测试套件中唯一可用的断言是 equal(),那么世界上几乎所有的测试套件都会更好。
自从我写这篇文章以来的几年里,我一直坚持着我的这一信念。虽然测试框架忙于添加更多 “方便” 断言,但我却在 Tape(译者注:一个开源测试框架) 上进行了一层简单的封装,使它只暴露了一个深度的相等断言。换句话说,我最低程度地使用了 Tape 库,并删除了一些功能,以提高测试体验。
在 RITE Way 测试原则的影响下,我将封装库称为 RITEway。RITE Way 测试应该是这样的:
RITEway 强制你编写可读,隔离以及彻底的测试,因为这是你使用 API 唯一的方法。由于编写测试断言是如此简单,以至于你将沉迷于编写测试,这使得你更容易进行彻底的测试。
这是 RITEway 中 assert() 的 函数签名:
assert({
given: Any,
should: String,
actual: Any,
expected: Any
}) => Void断言必须位于一个 describe() 块中,它的第一个参数将作为单元测试的一个标签。完整的测试如下:
describe('sum()', async assert => {
assert({
given: 'no arguments',
should: 'return 0',
actual: sum(),
expected: 0
});
});它的运行结果如下所示:
TAP version 13
# sum()
ok 1 Given no arguments: should return 0让我们再看看上面的 2.5 分的测试,看看我们能否提高我们的分数:
describe('addEntity()', async assert => {
const myEntity = { id: 'baz', foo: 'bar' };
const given = 'an entity';
const should = 'read the same entity from the api';
try {
const response = await addEntity(myEntity);
const storedEntity = await getEntity(response.id);
assert({
given,
should,
actual: storedEntity,
expected: myEntity
});
} catch(error) {
assert({
given,
should,
actual: error,
expected: myEntity
});
}
});addEntity()given an entity: should read the same entity from the api{ id: 'baz', foo: 'bar' }{ id: 'baz', foo: 'bar' }given 以及描述。很好!现在我们通过了测试的测试。
在过去的一年半中的几个大型项目中,我几乎每天都使用 RITEway。通过界面的简单化,我们将其提升了一些,但是我从来没有想过另外的断言,我们的测试套件是我在整个职业生涯中见过的最简单,最易读的测试套件。
我认为是时候与世界其他地方分享这项创新了。如果你想开始使用 RITEway :
npm install --save-dev riteway它会改变你对测试软件的看法。
简而言之:
测试越简单越好(Simple tests are better tests)
附:我在本文中一直使用 “单元测试” 这个术语,这仅仅是因为它比 “自动化软件测试” 或 “单元测试、功能测试以及集成测试” 更容易写,但是我在本文中所说的关于单元测试的所有内容都适用于我能想到的每个自动化软件测试。我也喜欢这些比 Cucumber/Gherkin 更好的测试。
在vue文件中的style标签上,有一个特殊的属性:scoped。当一个style标签拥有scoped属性时,它的CSS样式就只能作用于当前的组件,也就是说,该样式只能适用于当前组件元素。通过该属性,可以使得组件之间的样式不互相污染。如果一个项目中的所有style标签全部加上了scoped,相当于实现了样式的模块化。
vue中的scoped属性的效果主要通过PostCSS转译实现,如下是转译前的vue代码:
<style scoped>
.example {
color: red;
}
</style>
<template>
<div class="example">hi</div>
</template>转译后:
<style>
.example[data-v-5558831a] {
color: red;
}
</style>
<template>
<div class="example" data-v-5558831a>hi</div>
</template>即:PostCSS给一个组件中的所有dom添加了一个独一无二的动态属性,然后,给CSS选择器额外添加一个对应的属性选择器来选择该组件中dom,这种做法使得样式只作用于含有该属性的dom——组件内部dom。
scoped看起来很美,但是,在很多项目中,会出现这么一种情况,即:引用了第三方组件,需要在组件中局部修改第三方组件的样式,而又不想去除scoped属性造成组件之间的样式污染。此时只能通过特殊的方式,穿透scoped。
<style scoped>
外层 >>> 第三方组件 {
样式
}
</style>通过 >>> 可以使得在使用scoped属性的情况下,穿透scoped,修改其他组件的值。
其实,还拥有一种曲线救国的方法,即在定义一个含有scoped属性的style标签之外,再定义一个不含有scoped属性的style标签,即在一个vue组件中定义一个全局的style标签,一个含有作用域的style标签:
<style>
/* global styles */
</style>
<style scoped>
/* local styles */
</style>此时,你只需要将修改第三方样式的css写在第一个style中即可。
以上两种方法,穿透方法实际上违反了scoped属性的意义,曲线救国的方法又使得代码太过于难看。
个人推荐第三种方法,即:由于scoped看起来很美好,但是含有很多的坑,所以,不推荐不使用scoped属性,而通过在外层dom上添加唯一的class来区分不同组件。这种方法既实现了类似于scoped的效果,又方便修改各种第三方组件的样式,代码看起来也相对舒适。
axios 是 Vue 官方推荐的一个 HTTP 库,用 axios 官方简介来介绍它,就是:
Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中。
作为一个优秀的 HTTP 库,axios 打败了曾经由 Vue 官方团队维护的 vue-resource,获得了 Vue 作者尤小右的大力推荐,成为了 Vue 项目中 HTTP 库的最佳选择。
虽然,axios 是个优秀的 HTTP 库,但是,直接在项目中使用并不是那么方便,所以,我们需要对其进行一定程度上的配置封装,减少重复代码,方便调用。下面,我们就来聊聊 Vue 中 axios 的封装。
其实,网上关于 axios 封装的代码不少,但是大部分都是在入口文件(main.js)中进行 axios 全局对象属性定义的形式进行配置,类似于如下代码:
axios.defaults.timeout = 10000该方案有两个不足,首先,axios 封装代码耦合进入入口文件,不方便后期维护;其次,使用 axios 全局对象属性定义的方式进行配置,代码过于零散。
针对问题一,我使用了 Vue 源码结构中的一大核心**——将功能拆分为文件,方便后期的维护。单独创建一个 http.js 或者 http.ts 文件,在文件中引入 axios 并对其进行封装配置,最后将其导出并挂载到 Vue 的原型上即可。此时,每次修改 axios 配置,只需要修改对应的文件即可,不会影响到不相关的功能。
针对问题二,采用 axios 官方推荐的,通过配置项创建 axios 实例的方式进行配置封装。
代码如下:
// http.js
import axios from 'axios'
// 创建 axios 实例
const service = axios.create({
// 配置项
})baseURL 属性是请求地址前缀,将自动加在 url 前面,除非 url 是个绝对地址。正常情况下,在开发环境下和生产模式下有着不同的 baseURL,所以,我们需要根据不同的环境切换不同的 baseURL。
在开发模式下,由于有着 devServer 的存在,需要根据固定的 url 前缀进行请求地址重写,所以,在开发环境下,将 baseURL 设为某个固定的值,比如:/apis。
在生产模式下,根据 Java 模块的请求前缀的不同,可以设置不同的 baseURL。
具体代码如下:
// 根据 process.env.NODE_ENV 区分状态,切换不同的 baseURL
const service = axios.create({
baseURL: process.env.NODE_ENV === 'production' ? `/java` : '/apis',
})在这里和大家聊一个问题,什么是封装?在我看来,封装是通过更少的调用代码覆盖更多的调用场景。
由于,大部分情况下,请求头都是固定的,只有少部分情况下,会需要一些特殊的请求头,所以,在这里,我采用的方案是,将普适性的请求头作为基础配置。当需要特殊请求头时,将特殊请求头作为参数传入,覆盖基础配置。
代码如下:
const service = axios.create({
...
headers: {
get: {
'Content-Type': 'application/x-www-form-urlencoded;charset=utf-8'
// 在开发中,一般还需要单点登录或者其他功能的通用请求头,可以一并配置进来
},
post: {
'Content-Type': 'application/json;charset=utf-8'
// 在开发中,一般还需要单点登录或者其他功能的通用请求头,可以一并配置进来
}
},
})axios 中,提供是否允许跨域的属性——withCredentials,以及配置超时时间的属性——timeout,通过这两个属性,可以轻松处理跨域和超时的问题。
下面,我们来说说响应码处理:
axios 提供了 validateStatus 属性,用于定义对于给定的HTTP 响应状态码是 resolve 或 reject promise。所以,正常设置的情况下,我们会将状态码为 2 系列或者 304 的请求设为 resolve 状态,其余为 reject 状态。结果就是,我们可以在业务代码里,使用 catch 统一捕获响应错误的请求,从而进行统一处理。
但是,由于我在代码里面使用了 async-await,而众所周知,async-await 捕获 catch 的方式极为麻烦,所以,在此处,我选择将所有响应都设为 resolve 状态,统一在 then 处理。
此部分代码如下:
const service = axios.create({
// 跨域请求时是否需要使用凭证
withCredentials: true,
// 请求 30s 超时
timeout: 30000,
validateStatus: function () {
// 使用async-await,处理reject情况较为繁琐,所以全部返回resolve,在业务代码中处理异常
return true
},
})在不使用 axios 的情况下,每次请求或者接受响应,都需要将请求或者响应序列化。
而在 axios 中, transformRequest 允许在向服务器发送请求前,修改请求数据;transformResponse 在传递给 then/catch 前,允许修改响应数据。
通过这两个钩子,可以省去大量重复的序列化代码。
代码如下:
const service = axios.create({
// 在向服务器发送请求前,序列化请求数据
transformRequest: [function (data) {
data = JSON.stringify(data)
return data
}],
// 在传递给 then/catch 前,修改响应数据
transformResponse: [function (data) {
if (typeof data === 'string' && data.startsWith('{')) {
data = JSON.parse(data)
}
return data
}]
})拦截器,分为请求拦截器以及响应拦截器,分别在请求或响应被 then 或 catch 处理前拦截它们。
之前提到过,由于 async-await 中 catch 难以处理的问题,所以将出错的情况也作为 resolve 状态进行处理。但这带来了一个问题,请求或响应出错的情况下,结果没有数据协议中定义的 msg 字段(消息)。所以,我们需要在出错的时候,手动生成一个符合返回格式的返回数据。
由于,在业务中,没有需要在请求拦截器中做额外处理的需求,所以,请求拦截器的 resolve 状态,只需直接返回就可以了。
请求拦截器代码如下:
// 请求拦截器
service.interceptors.request.use((config) => {
return config
}, (error) => {
// 错误抛到业务代码
error.data = {}
error.data.msg = '服务器异常,请联系管理员!'
return Promise.resolve(error)
})再来聊聊响应拦截器,还是之前的那个问题,除了请求或响应错误,还有一种情况也会导致返回的消息体不符合协议规范,那就是状态码不为 2 系列或 304 时。此时,我们还是需要做一样的处理——手动生成一个符合返回格式的返回数据。但是,有一点不一样,我们还需要根据不同的状态码生成不同的提示信息,以方便处理上线后的问题。
响应拦截器代码如下:
// 根据不同的状态码,生成不同的提示信息
const showStatus = (status) => {
let message = ''
// 这一坨代码可以使用策略模式进行优化
switch (status) {
case 400:
message = '请求错误(400)'
break
case 401:
message = '未授权,请重新登录(401)'
break
case 403:
message = '拒绝访问(403)'
break
case 404:
message = '请求出错(404)'
break
case 408:
message = '请求超时(408)'
break
case 500:
message = '服务器错误(500)'
break
case 501:
message = '服务未实现(501)'
break
case 502:
message = '网络错误(502)'
break
case 503:
message = '服务不可用(503)'
break
case 504:
message = '网络超时(504)'
break
case 505:
message = 'HTTP版本不受支持(505)'
break
default:
message = `连接出错(${status})!`
}
return `${message},请检查网络或联系管理员!`
}
// 响应拦截器
service.interceptors.response.use((response) => {
const status = response.status
let msg = ''
if (status < 200 || status >= 300) {
// 处理http错误,抛到业务代码
msg = showStatus(status)
if (typeof response.data === 'string') {
response.data = { msg }
} else {
response.data.msg = msg
}
}
return response
}, (error) => {
// 错误抛到业务代码
error.data = {}
error.data.msg = '请求超时或服务器异常,请检查网络或联系管理员!'
return Promise.resolve(error)
})tips:友情提示,上面那一坨 switch-case 代码,可以使用策略模式进行优化~
由于前段时间,我在部门内推了 TypeScript,为了满足自己的强迫症,将所有 js 文件改写为了 ts 文件。由于 axios 本身有 TypeScript 相关的支持,所以只需要把对应的类型导入,然后赋值即可。
// http.ts
import axios, { AxiosRequestConfig, AxiosResponse } from 'axios'
const showStatus = (status: number) => {
let message = ''
switch (status) {
case 400:
message = '请求错误(400)'
break
case 401:
message = '未授权,请重新登录(401)'
break
case 403:
message = '拒绝访问(403)'
break
case 404:
message = '请求出错(404)'
break
case 408:
message = '请求超时(408)'
break
case 500:
message = '服务器错误(500)'
break
case 501:
message = '服务未实现(501)'
break
case 502:
message = '网络错误(502)'
break
case 503:
message = '服务不可用(503)'
break
case 504:
message = '网络超时(504)'
break
case 505:
message = 'HTTP版本不受支持(505)'
break
default:
message = `连接出错(${status})!`
}
return `${message},请检查网络或联系管理员!`
}
const service = axios.create({
// 联调
baseURL: process.env.NODE_ENV === 'production' ? `/` : '/apis',
headers: {
get: {
'Content-Type': 'application/x-www-form-urlencoded;charset=utf-8'
},
post: {
'Content-Type': 'application/json;charset=utf-8'
}
},
// 是否跨站点访问控制请求
withCredentials: true,
timeout: 30000,
transformRequest: [(data) => {
data = JSON.stringify(data)
return data
}],
validateStatus () {
// 使用async-await,处理reject情况较为繁琐,所以全部返回resolve,在业务代码中处理异常
return true
},
transformResponse: [(data) => {
if (typeof data === 'string' && data.startsWith('{')) {
data = JSON.parse(data)
}
return data
}]
})
// 请求拦截器
service.interceptors.request.use((config: AxiosRequestConfig) => {
return config
}, (error) => {
// 错误抛到业务代码
error.data = {}
error.data.msg = '服务器异常,请联系管理员!'
return Promise.resolve(error)
})
// 响应拦截器
service.interceptors.response.use((response: AxiosResponse) => {
const status = response.status
let msg = ''
if (status < 200 || status >= 300) {
// 处理http错误,抛到业务代码
msg = showStatus(status)
if (typeof response.data === 'string') {
response.data = {msg}
} else {
response.data.msg = msg
}
}
return response
}, (error) => {
// 错误抛到业务代码
error.data = {}
error.data.msg = '请求超时或服务器异常,请检查网络或联系管理员!'
return Promise.resolve(error)
})
export default serviceHistory对象最初设计用来表示窗口的浏览历史,但是,出于隐私方面的原因,History对象不再允许脚本访问已经访问过的实际URL。虽然,我们不清楚历史URL,但是,我们可以通过History对象的内置属性方法进行跳转。
该属性代表着浏览器历史列表中的URL数量。初始值为1,如果当前窗口先后访问了两个网址,那该属性的值变为2。
history.length // 1
// 访问了一个新的URL
history.length // 2HTML5新增属性,返回一个表示历史堆栈顶部的状态的值,这是一种可以不必等待popstate 事件而查看状态的方式。
允许Web应用程序在历史导航上显式地设置默认滚动恢复行为。此属性可以是自动的(auto)或者手动的(manual)。
go方法是History对象三个方法中的核心方法,通过go方法可以完美替代其他的两个方法。该方法接收一个可选参数,这个参数可以是number也可以是URL。
ps:经过多次试验,传入URL参数貌似没有作用,有待后续研究
当使用number参数时,页面会跳转到History的URL列表的相对位置。比如当传入参数为-1,则相当于点击浏览器后退按钮的效果;当传入参数为1时,相当于点击浏览器前进按钮;当不传参数或者传入参数为0时,页面会刷新。
window.history.go(-1) // 后退
window.history.go(1) // 前进
window.history.go(0) // 刷新
window.history.go() // 刷新tips:当传入的number对应的位置没有URL,则该条语句会静默失败
forward方法可以加载历史列表中的下一个URL,类似于go(1),实现了点击浏览器前进按钮的效果。
window.history.forward() // 前进
window.history.go(1) // 前进back方法可以加载历史列表中的上一个URL,类似于go(-1),实现了点击浏览器后退按钮的效果。
window.history.back() // 后退
window.history.go(-1) // 后退tips:当URL队列中没有上一个URL时,back方法会失效;同理,当URL队列中没有下一个URL时,forward方法会失效。
HTML5为History对象添加了两个新方法,pushState和replaceState方法,用来在浏览历史中添加和修改记录。
pushState方法接收三个参数:
popstate事件触发时,该对象会传入回调函数。如果不需要这个对象(即不需要传参),可以设为nullnull比如当前的网址是localhost:63342/1.html,使用pushState方法在浏览记录中可以添加一条新的记录:
window.history.pushState({params: 'aaa'}, null, '2.html')输入这行语句后,浏览器地址栏中的URL变为了localhost:63342/2.html,但是无论这是不是一个真实网址,它都不会跳转,这只是一条历史记录。此时,可以通过state取到状态。
此时,如果你前往下个地址后点击后退按钮,页面将返回到localhost:63342/2.html,此时,也可以通过state属性取到状态。
window.history.state // {params: "aaa"}tips:如果pushState的第三个参数是一个跨域网址,控制台会报错,这主要是因为安全问题,防止不法分子伪装URL
window.history.pushState(null, null, 'www.baidu.com') // 报错该方法基本和pushState一致,但是不同的是,该方法会直接替换当前的历史记录。
传统的History用法是操纵浏览器进行前进或后退的跳转,用处不是很大。但是,HTML5新增的方法为其带来了脱胎换骨的变化。
众所周知,vue-router等一众路由插件实现的功能是更新页面的视图,但是却不重新请求页面,也就是说,其实,他们并没有实际进行了跳转,而是修改了页面的DOM并通过修改页面的URL来模拟跳转。
在HTML5之前,页面路由只有hash模式,而HTML5中History对象的新增方法,带来了另一种模式:history模式。
在HTML5之前,vue-router是通过修改URL的hash值(URL中#开始的字符串,不了解的同学可以看我的上一篇文章)来达到修改页面URL并生成历史记录,但却不会重新请求页面。所以,不使用vue-router中history模式的情况下,你会发现你的路径前总会有一个#。
比如,你在vue-router中设置的路径是/b,在你的想象中,路径应该是http://localhost:8080/b,但是,现实很骨感,实际路径是:http://localhost:8080/#/b,原因就是因为没开启history模式的情况下,vue-router是通过hashchange事件来监听URL中hash的改变并通过修改hash来模拟路径的变化。
由于通过window.location.hash修改hash是会有历史记录产生的,所以,在SPA中,依然可以通过后退、前进按钮来控制路由的跳转。
hash模式最大的优点是兼容性强,可以兼容一众老式浏览器。而它最大的缺点是,页面URL中一直挂着一个难看的#,这一点连vue-router的官网也对其进行了吐槽。
有需求就有功能,所以,当HTML5发布后,又有了history模式。
看到这里,如果认真看了pushState方法的同学应该已经差不多明白了,vue-router的history模式就是通过HTML5中History对象的pushState方法进行模拟的。
当vue-router每次需要跳转页面时,页面DOM的修改方式和时机并没有改变,和hash模式一样。但是,修改URL的方式改变了。此时,有了pushState方法,可以不用修改丑陋的hash模拟而是直接在历史记录中添加一条新的URL。
那么,没有了hash,如何监听URL的改变呢?HTML5还提供了一个popstate事件,当用户点击前进、后退按钮,或者调用back、forward、go方法时触发,可以监听URL的改变。
在这里提一句,使用history模式,就连路由传值都有更好的方式——使用pushState的第一个参数进行传值,使用History的state属性进行取值。
当使用了history模式时,使用vue-router跳入/b时,此时的页面URL不是丑陋的http://localhost:8080/#/b,而是预料之中的http://localhost:8080/b。
// hash模式
window.location.href // http://localhost:8080/#/b
// history
window.location.href // http://localhost:8080/b虽然,history模式提供了完美的URL显示,但是,正所谓鱼和熊掌不可兼得,兼容性和美观也不可兼得。只有兼容了HTML5的浏览器(IE10+)才能使用history模式,不然,就老实的继续使用hash模式吧。
所以,使用何种模式,还是取决于软件的兼容性,如果不需要兼容低级浏览器,那就放心大胆的使用history模式吧!
何为严格模式?严格模式(strict mode)即在严格的条件下运行,在严格模式下,很多正常情况下不会报错的问题语句,将会报错并阻止运行。
但是,严格模式可以显著提高代码的健壮性,比如JS经常被人诟病的隐式创建全局变量,在严格模式下就会阻止运行。
总的来说,引入严格模式虽然会导致一些代码不可运行,但是,严格模式使得一些JS广受诟病的问题无法运行,从长期角度上看,绝对是利大于弊。
进入严格模式的方法很简单,只需要在在需要进入严格模式的作用域开头输入"user strict"即可,值得一提的是,在无法执行严格模式的旧版浏览器中(IE10之前),该条指令会自动被忽略。
例1:
"user strict";
x = 1; // Uncaught ReferenceError: x is not defined如例1所示,在全局作用域的开头定义了严格模式,并隐式定义了全局变量x,x = 1 这条语句在严格模式下,抛出了异常,提示没有显式创建变量a。
例2:
"use strict";
fn();
function fn () {
x = 1; // Uncaught ReferenceError: x is not defined
}在例2中,由于严格模式定义在全局作用域中,而fn作用域被全局作用域所包含,所以fn作用域中同样执行了严格模式。
注:也可以通过执行上下文栈来解释。
例3:
x = 1;
fn();
function fn () {
"use strict"
y = 2; // Uncaught ReferenceError: y is not defined
}在例3中,由于严格模式只定义在fn函数的局部作用域中,在全局作用域中不起作用,所以全局作用域中,隐式定义全局变量x没有抛出异常,而在局部作用域中,隐式定义全局变量y抛出异常。
1.严格模式下无法隐式创建全局变量
2.严格模式会使引起静默失败(silently fail,注:不报错也没有任何效果)的赋值操做抛出异常
"use strict";
// 给不可写属性赋值
var obj1 = {};
Object.defineProperty(obj1, "x", { value: 42, writable: false });
obj1.x = 9; // 抛出TypeError错误
// 给只读属性赋值
var obj2 = { get x() { return 17; } };
obj2.x = 5; // 抛出TypeError错误
// 给不可扩展对象的新属性赋值
var fixed = {};
Object.preventExtensions(fixed);
fixed.newProp = "ohai"; // 抛出TypeError错误3.在严格模式下,试图删除不可删除的属性时,会抛出异常(之前这种操作不会产生任何效果)
"use strict";
delete Object.prototype; // 抛出TypeError错误4.在严格模式下,不允许重名属性
"use strict";
var o = { p: 1, p: 2 }; // 语法错误5.严格模式要求函数参数名唯一
function sum(a, a, c){ // 语法错误
"use strict";
return a + a + c; // 代码运行到这里会出错
}6.禁止八进制数字语法
"use strict";
var sum = 015 + // 语法错误
197 +
142;7.禁止设置原始类型(primitive)值的属性
(function() {
"use strict";
false.true = ""; //TypeError
(14).sailing = "home"; //TypeError
"with".you = "far away"; //TypeError
})();8.禁用with
9.严格模式下,eval()创建变量不能被调用
"use strict";
eval ("var x = 2");
alert (x); // Uncaught ReferenceError: x is not defined10.严格模式禁止删除声明变量
"use strict";
var x;
delete x; // 语法错误
eval("var y; delete y;"); // 语法错误11.不能使用eval 和 arguments字符串
"use strict";
var arguments = 1; // Uncaught SyntaxError: Unexpected eval or arguments in strict mode
var eval = 2; // Uncaught SyntaxError: Unexpected eval or arguments in strict mode12.严格模式下,函数的 arguments 对象会保存函数被调用时的原始参数。arguments[i] 的值不会随与之相应的参数的值的改变而变化,同名参数的值也不会随与之相应的 arguments[i] 的值的改变而变化。
13.不再支持arguments.callee
"use strict";
var f = function() { return arguments.callee; };
f(); // TypeError14.保留部分关键字,这些字符包括implements, interface, let, package, private, protected, public, static和yield。在严格模式下,你不能再用这些名字作为变量名或形参名。
15.禁止this指向全局对象,当this指向全局对象时,自动转为undefined
随着JS的飞速发展,出现了一大堆可以代替严格模式的工具,比如eslint等,但是,当你想要提升原生JS代码的健壮性和可读性,回避JS一些被人诟病的语法,严格模式是你不二的选择。
事件的起因在于老板最近的两次“故障”,一次去年的,一次最近。共同原因都是脚手架在发布平台发布打包时出错,导致线上应用白屏不可用。
最神奇的是,事后多次 Code Review,结果还是没有发现任何能够导致该问题的 bug,最后推测有可能是服务器在发布打包的时候出了问题。
当老板第 N + 1 次吐槽因为他写的工程化工具领来的天外飞锅,我突然思考起来,如何才能避免这种天外飞锅。
归根结底,导致这类线上故障的原因都是在于打包上线的代码没有经过验证。针对这个问题,有两种方法可以解决:
正如之前所说的,治本的方法实施难度较大,所以,我们重点关注治标的方法,即上线之后进行回归验证。
说到这里,问大家一个问题,需求上线之后,作为前端,大家会主动进行回归验证而不是等测试进行验证吗?
不管你们会不会,反正我是不会[doge]。
在这种情况下,前端 UI 自动化测试闪亮登场。
众所周知,测试是一个很重要的环节,由于它的重要性,甚至软件工程中出现了 TDD 这种说法。
在之前,所谓的前端测试,更多的是在页面上点点点,进行人肉测试,毫无疑问,效率低下。
所以,有了前端自动化测试,使用机器代替人工。一般来说,前端自动化测试分为两种:单元测试以及 e2e 测试(UI 自动化测试)。
单元测试本质上是一种白盒测试,是对程序中的最小可测试单元进行测试。
e2e 测试本质上是一种黑盒测试,相当于模拟用户访问应用程序,主要检查界面或功能是否正确。
相比于单元测试,UI 自动化测试更多的是站在用户角度,从用户的角度发现问题。但是,由于它其实是一种黑盒测试,所以效率相对于白盒测试要低一些。
Selenium:e2e 测试鼻祖级的框架,有多种编程语言的版本,如果你去问问你们公司的测试,那么你一定会发现,他们正在用 Python 版本的 Selenium 写自动化测试脚本。值得一提的是,它是基于 webdriver 而不是 webkit 内核实现的,所以,Selenium 的浏览器兼容性相对于其他浏览器要好很多。
PhantomJS:开创性的 headless(无头)测试框架,何为 headless?即没有 UI 界面的浏览器。headless 最大好处在于可以像单元测试一样,在命令行中跑 e2e 测试。
nightmare:一句话——加强版的 PhantomJS,相对于 PhantomJS,无论是开发还是运行效率都得到了很大的提升。
tips:nightmare 还有个优点——它提供了一个 Chrome 插件 daydream,该插件可以通过录制屏幕,自动化生成测试代码,懒人福音。
nightwatch:名字和 nightmare 很像,但是完全不一样的一个 e2e 框架,使用 Node 调用 webdriver 实现。相对于 Selenium,开发和运行效率更高,最重要的是,迭代很活跃,这点,用开源产品的用户懂得都懂。
cypress:我接触的第一个 e2e 测试框架,测试界面和文档做到极致的一个产品,推荐大家可以试一试。
puppeteer:e2e 测试框架的集大成者,默认以 headless 模式运行,但是也可以通过配置变为 Chromium 运行。开发效率以及运行效率一流,最重要的是,它像 nightmare 一样,提供了测试代码生成插件——puppeteer-recorder。
综上所述,如果考虑浏览器兼容性,使用 nightwatch,反之,选择 cypress 或者 puppeteer,如果需要 headless 或者自动化生成代码的功能,那就使用 puppeteer。
从自动化测试的收益来说,自动化测试有个公式:
自动化的收益 = 迭代次数 * 全手动执行成本 - 首次自动化成本 - 维护次数 * 维护成本
简而言之,迭代越频繁,维护成本越高的项目,添加自动化测试的价值越高。在基建项目或频繁迭代项目中引入前端 UI 自动化测试,可以大大减少每次迭代后手动测试的时间。比起手动测试,前端 UI 自动化测试测试的更快也更彻底。
另一个方面,随着前端技术的高速发展,各个公司的前端开发、监控体系已经很完善了,但是缺少前端在测试方向上的延伸。而前端 UI 自动化测试最大的价值,就是在前端部分,弥补开发和监控之间的空白区域,形成一个完整的闭环,三管齐下,极大地保障了项目的质量。
针对前端 UI 自动化测试,我思考了很久,个人认为主要有两大方向:
第二个方案,即通用化方案也是我最近开发的重点方向,接下来我应该会专门写一篇文章,大概介绍下该方案的设计以及具体实现(如果我没有懒癌发作的话[doge])。
如果有不同想法的同学,欢迎一起交流~
近两个月学习了小程序的开发,并且撸了一个不大不小的demo,算是正式入门了小程序,在此想分享下小程序的开发经验。
在小程序的开发中,或者说在整个前端开发中,请求都是绕不过去的一道坎。在Vue开发中,我们可以采用 axios 这个成熟的插件来进行HTTP请求。但是,遗憾的是,到目前为止,小程序没有一个比较好用的插件来进行HTTP请求。此时,我们需要对小程序的HTTP请求进行封装,以方便我们后续开发。
众所周知,在小程序中,我们通过 wx.request 方法来进行HTTP请求(或者说是HTTPS请求)。
通过 官方文档 我们可以知道, wx.request 方法接收一个对象,对象可以有9个属性:url,data,header,method,dataType,responseType,success,fail,complete。除了url是必填的以外,其余都是可选项。在这些属性里面,最常用的是 method,data,header,success以及fail这几个属性。毕竟我们总要设置请求方法、请求数据、请求头以及请求成功或失败的处理方法是不是?
所以接下来我们的目标我们已经明确,就是对这些常用属性进行封装。
对于HTTP请求的封装,有很多种方法,比如:axios 采用的是通过IIFE作为工厂函数处理并返回一个Axios的实例。在这里,我推荐使用类,因为类的封装形式,正是axios 的封装形式的加强版。
为了一致性,我也采用request作为请求的方法名,并且接受相同的对象作为参数。此时,我们已经可以实现出以下代码:
class HTTP {
request (params) {
wx.request({
url: params.url,
method: params.method,
data: params.data,
header: params.header,
success: (res) => {
params.success(res)
},
fail: (err) => {
params.fail(err)
}
})
}
}接下来,我们需要对各个属性进行处理。
由于除了url,其余的的属性皆为可选可选项,所以需要对可选属性进行缺省属性的处理。
在小程序官方文档中,当不传入method属性时,默认采用GET方法,所以我们需要将method的默认值设为GET,设置method的默认值的方式很简单:
if (!params.method) {
params.method = 'GET'
}但是,这种方式不够优雅,我们可以采用位运算符的方式进行默认复制:
...
method: params.method || 'GET'
...其余属性也采用类似方式进行缺省值处理,除了success和fail属性,这个我们后面说。
在正常情况下,REST风格的接口协议给的接口路径都是诸如/pathA/a,在此之前还有一个类似于www.baidu.com/root类似的base url,两者结合才是真正的请求路径。在Vue中,我们可以通过webpack中的proxyTable来解决这个问题,但是,小程序中没有webpack中的proxyTable,所以需要每次请求的时候,都输入完整请求路径。
在HTTP类中的request方法,我们可以实现路径的拼接。
...
url: 'www.baidu.com/root' + params.url,
...但是,这里有个问题,base url是写死的,也就是说,我们每做一个项目,都需要重新设置一次base url的值,这显然是有问题的。
为了处理该问题,我新建了一个config.js文件,作为该项目的配置文件,用来存储所有项目相关的配置,比如base url以及HTTP Header。
const config = {
api_base_url: 'www.baidu.com/root',
// 更多的配置项
}
export {config}拥有配置文件最大的好处就是,每次修改项目,只需要修改配置文件中的配置项的值即可,重复保证了组件的封闭性,减少了对项目的耦合。
最后,我们需要封装success以及fail。
显而易见,我们只有在HTTP状态码为2**或者304才调用success,所以我们需要对响应结果的状态码进行判断,根据判断结果决定是否执行params.success
...
success: (res) => {
let code = res.statusCode.toString()
// 状态码判断
if (code.startsWith('2') || code === '304') {
params.success && params.success(res.data)
} else {
// 失败
}
}tips:一般情况下,我们还可以对显示错误的方法进行一次封装,调用wx.showToast显示服务器返回的错误信息。
经过这么多步骤,封装结束后的代码是:
import {config} from '../config.js'
class HTTP {
request (params) {
wx.request({
url: config.api_base_url + params.url,
method: params.method || 'GET',
data: params.data || {},
header: params.header ? Object.asign(config.header, params.header):config.header
success: (res) => {
let code = res.statusCode.toString()
if (code.startsWith('2') || code === '304') {
params.success && params.success(res.data)
} else {
params.fail && params.fail(res.data)
let error_code = res.data.error_code
this._show_error(error_code)
}
},
fail: (err) => {
params.fail && params.fail(res.data)
this._show_error(1)
}
})
}
// 私有方法,显示请求错误信息
_show_error(error_code) {
if (!error_code) {
error_code = 1
}
const tip = config.tips[error_code]
wx.showToast({
title: tip ? tip : tips[1],
icon: 'none',
duration: 2000
})
}
}其实,HTTP类还可以进一步优化,比如,使用解构以及默认赋值,使用promise等等,篇幅有限,我就不一一细说了,详情可以查看我github上的代码。
代码路径:https://github.com/KarthusLorin/mini-program/blob/master/util/http.js
nextTick是Vue的一个核心功能,在Vue内部实现中也经常用到nextTick。但是,很多新手不理解nextTick的原理,甚至不清楚nextTick的作用。
那么,我们就先来看看nextTick是什么。
看看官方文档的描述:
在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。
再看看官方示例:
// 修改数据
vm.msg = 'Hello'
// DOM 还没有更新
Vue.nextTick(function () {
// DOM 更新了
})
// 作为一个 Promise 使用 (2.1.0 起新增,详见接下来的提示)
Vue.nextTick()
.then(function () {
// DOM 更新了
})
2.1.0 起新增:如果没有提供回调且在支持 Promise 的环境中,则返回一个 Promise。请注意 Vue 不自带 Promise 的 polyfill,所以如果你的目标浏览器不原生支持 Promise (IE:你们都看我干嘛),你得自己提供 polyfill。
可以看到,nextTick主要功能就是改变数据后让回调函数作用于dom更新后。很多人一看到这里就懵逼了,为什么需要在dom更新后再执行回调函数,我修改了数据后,不是dom自动就更新了吗?
这个和JS中的Event Loop有关,网上教程不计其数,在此就不再赘述了。建议明白Event Loop后再继续向下阅读本文。
举个实际的例子:
我们有个带有分页器的表格,每次翻页需要选中第一项。正常情况下,我们想的是点击翻页器,向后台获取数据,更新表格数据,操纵表格API选中第一项。
但是,你会发现,表格数据是更新了,但是并没有选中第一项。因为,你选中第一项时,虽然数据更新了,但是DOM并没有更新。此时,你可以使用nextTick,在DOM更新后再操纵表格第一项的选中。
那么,nextTick到底做了什么了才能实现在DOM更新后执行回调函数?
nextTick的源码位于src/core/util/next-tick.js,总计118行,十分的短小精悍,十分适合初次阅读源码的同学。
nextTick源码主要分为两块:
1.能力检测
2.根据能力检测以不同方式执行回调队列
这一块其实很简单,众所周知,Event Loop分为宏任务(macro task)以及微任务( micro task),不管执行宏任务还是微任务,完成后都会进入下一个tick,并在两个tick之间执行UI渲染。
但是,宏任务耗费的时间是大于微任务的,所以在浏览器支持的情况下,优先使用微任务。如果浏览器不支持微任务,使用宏任务;但是,各种宏任务之间也有效率的不同,需要根据浏览器的支持情况,使用不同的宏任务。
nextTick在能力检测这一块,就是遵循的这种**。
// Determine (macro) task defer implementation.
// Technically setImmediate should be the ideal choice, but it's only available
// in IE. The only polyfill that consistently queues the callback after all DOM
// events triggered in the same loop is by using MessageChannel.
/* istanbul ignore if */
// 如果浏览器不支持Promise,使用宏任务来执行nextTick回调函数队列
// 能力检测,测试浏览器是否支持原生的setImmediate(setImmediate只在IE中有效)
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
// 如果支持,宏任务( macro task)使用setImmediate
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
// 同上
} else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]'
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
/* istanbul ignore next */
// 都不支持的情况下,使用setTimeout
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
首先,检测浏览器是否支持setImmediate,不支持就使用MessageChannel,再不支持只能使用效率最差但是兼容性最好的setTimeout了。
之后,检测浏览器是否支持Promise,如果支持,则使用Promise来执行回调函数队列,毕竟微任务速度大于宏任务。如果不支持的话,就只能使用宏任务来执行回调函数队列。
执行回调函数队列的代码刚好在一头一尾
// 回调函数队列
const callbacks = []
// 异步锁
let pending = false
// 执行回调函数
function flushCallbacks () {
// 重置异步锁
pending = false
// 防止出现nextTick中包含nextTick时出现问题,在执行回调函数队列前,提前复制备份,清空回调函数队列
const copies = callbacks.slice(0)
callbacks.length = 0
// 执行回调函数队列
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
...
// 我们调用的nextTick函数
export function nextTick (cb?: Function, ctx?: Object) {
let _resolve
// 将回调函数推入回调队列
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
// 如果异步锁未锁上,锁上异步锁,调用异步函数,准备等同步函数执行完后,就开始执行回调函数队列
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// $flow-disable-line
// 2.1.0新增,如果没有提供回调,并且支持Promise,返回一个Promise
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}
总体流程就是,接收回调函数,将回调函数推入回调函数队列中。
同时,在接收第一个回调函数时,执行能力检测中对应的异步方法(异步方法中调用了回调函数队列)。
如何保证只在接收第一个回调函数时执行异步方法?
nextTick源码中使用了一个异步锁的概念,即接收第一个回调函数时,先关上锁,执行异步方法。此时,浏览器处于等待执行完同步代码就执行异步代码的情况。
打个比喻:相当于一群旅客准备上车,当第一个旅客上车的时候,车开始发动,准备出发,等到所有旅客都上车后,就可以正式开车了。
当然执行flushCallbacks函数时有个难以理解的点,即:为什么需要备份回调函数队列?执行的也是备份的回调函数队列?
因为,会出现这么一种情况:nextTick套用nextTick。如果flushCallbacks不做特殊处理,直接循环执行回调函数,会导致里面nextTick中的回调函数会进入回调队列。这就相当于,下一个班车的旅客上了上一个班车。
说了这么多,我们来实现一个简单的nextTick:
let callbacks = []
let pending = false
function nextTick (cb) {
callbacks.push(cb)
if (!pending) {
pending = true
setTimeout(flushCallback, 0)
}
}
function flushCallback () {
pending = false
let copies = callbacks.slice()
callbacks.length = 0
copies.forEach(copy => {
copy()
})
}
可以看到,在简易版的nextTick中,通过nextTick接收回调函数,通过setTimeout来异步执行回调函数。通过这种方式,可以实现在下一个tick中执行回调函数,即在UI重新渲染后执行回调函数。
布局组件中的父组件,用于控制子组件。很简单的一个布局标签,主要通过 justify 和 align 控制子元素的对齐方式,使用 render 函数通过传入的 tag 属性控制生成的标签。
在这里推荐学习下 render 函数和 JSX 的写法,因为之后比较复杂的组件都是通过 render函数 + JSX 的方式来写的。
// 核心代码
render(h) {
return h(this.tag, {
class: [
'el-row',
this.justify !== 'start' ? `is-justify-${this.justify}` : '',
this.align !== 'top' ? `is-align-${this.align}` : '',
{ 'el-row--flex': this.type === 'flex' }
],
style: this.style
}, this.$slots.default);
}布局组件中的子组件,通过传入的props控制占据的列数、偏移、大小等,通过 forEach 对每个属性进行处理,生成包含对应样式的 classList。
最后将 classList 传入 createElement 函数(h)中的第二个参数(标签选项)中,如此,就生成了所需要的布局。
// 核心代码
render (h) {
// 省略,通过props计算classList
return h(this.tag, {
class: ['el-col', classList],
style
}, this.$slots.default);
}父容器组件,根据传入的direction字段,决定样式是水平还是垂直。当没有传入direction字段时,根据插槽中子组件是否含有 header 或 footer组件,如果含有则为垂直,否则为水平。
// 核心代码
computed: {
isVertical() {
if (this.direction === 'vertical') {
return true;
} else if (this.direction === 'horizontal') {
return false;
}
return this.$slots && this.$slots.default
? this.$slots.default.some(vnode => {
const tag = vnode.componentOptions && vnode.componentOptions.tag;
return tag === 'el-header' || tag === 'el-footer';
})
: false;
}
}最简单的组件之一,通过传入的 height 参数定义 style 高度。
最简单的组件之一,通过传入的 width 参数控制 style 宽度。
真正意义上的最简单容器组件,包含插槽的纯容器。
最简单的组件之一,通过传入的 height 参数定义 style 高度。
何为容器?在我的理解中,容器就是一个限制大小的盒子。布局容器通过属性定义 header、aside、footer 的高宽的行内样式,接下来只需要定义 main 为 flex: 1 即可实现自适应布局。
感觉比较没有意义的一个组件,通过传入的 name 来组成类似于 el-icon-name 格式的类,然后将这个类定义在 i 标签内。不过大多数人都不会用这个组件,为什么?因为连官网推荐写法都是直接在 i 标签内添加对应图标的类。
Button 组件是 Basic 里面唯一一个稍微复杂一点的组件。它与其他 Basic 组件的最大区别在于,通过 provide/inject 获取了祖先组件,然后参照祖先组件的尺寸参数,将 Button 组件的尺寸参数设为一致。
Button 组件的尺寸由三个因素决定:
this.$ELEMENT 对象中的 size 属性决定。What? this.$ELEMENT 什么鬼?它是接收初始化 ElementUI 时传入的尺寸参数的对象,包含两个属性:size 以及 zIndex,方便全局定义各种组件的尺寸。类比于样式中的 body 样式继承。// 核心代码
export default {
name: 'ElButton',
// 通过 inject 获取 elForm 以及 elFormItem 这两个组件
inject: {
elForm: {
default: ''
},
elFormItem: {
default: ''
}
},
// ...
computed: {
_elFormItemSize() {
return (this.elFormItem || {}).elFormItemSize;
},
buttonSize() {
// 三种因素决定按钮的尺寸
return this.size || this._elFormItemSize || (this.$ELEMENT || {}).size;
},
//...
},
// ...
};和一般文字链接区别不大的一个组件,主要区别在于两点:
值得一提的是,该组件还使用了一个通用组件开发的小技巧:通过 v-bind="$attrs" 进行快速属性赋值。为什么要这样做?因为 a 标签可以含有各种 html 属性,而这些属性我们不可能一一通过 props 接收然后赋值到 a 标签的属性上。
因此,我们可以通过 v-bind="$attrs" 无视传入的属性是什么,一股脑将其赋值到 a 标签上。这相当于,开发者可以直接像操作 a 标签一样操作 Link 组件,大大方便了组件的使用。
<template>
<a
:class="[
'el-link',
type ? `el-link--${type}` : '',
disabled && 'is-disabled',
underline && !disabled && 'is-underline'
]"
:href="disabled ? null : href"
v-bind="$attrs"
@click="handleClick"
>
<i :class="icon" v-if="icon"></i>
<span v-if="$slots.default" class="el-link--inner">
<slot></slot>
</span>
<template v-if="$slots.icon"><slot v-if="$slots.icon" name="icon"></slot></template>
</a>
</template>通读了 Basic 系列的源码,可以发现,这一部分的源码其实相对比较简单,但是,却又很多的小细节点值得学习,比如:通过 v-bind=$attrs 定义标签属性、通过组合插槽方便组件使用、通过多种因素设定属性以及各种缺省设计等等。
在遥远的几个月前,还在上家公司的时候,老板突发奇想,想要搞个代码片段平台,类似于 snipit,实现代码片段的复用。本身这个需求并不难实现——简单的前端界面 + 简单的 node CURD,搞定收工,下班回家。
但是,在实际使用中,发现了一个使用痛点——没有在线调试功能,所有代码只能 copy 到本地,在本地进行调试。本着发现痛点就要解决痛点的指导**,我当时思考了一段时间,希望寻找一个合适的解决方案来完美的解决这个痛点。总体来说,分为两种方案:
相比于服务端构建方案,浏览器实时构建方案的优势在于:即时、高效以及最宝贵的——可离线运行(前提是做了合适的缓存方案)。
最终,出于各种因素,最终我选择了浏览器实时构建方案。
浏览器实时构建是最近两年前端的热门方向,所以也涌现了一大批成熟的解决方案。
个人总结为:bundle 方案以及 unbundle 方案两种。
大部分投入生产环境的浏览器实时构建方案都采用了该方案,该方案基本采用了 codesandbox-client 的方案,所以我一般称之为类 CodeSandBox 方案。
bundle 方案的核心在于在浏览器上实现一个打包工具,如 webpack,配合 indexDB 进行本地文件存储。当然,不仅仅是这么简单,由于在浏览器端做构建工作效率相对较低,所以需要大量的性能优化,比如 CodeSandBox 在浏览器端实现了一个线程池,当进行构建时,从线程池中取出线程,从而实现多线程打包。
总的来说,bundle 方案依然没有跳出构建的思路,当项目较为复杂时,依然会出现构建工具遇到的那个问题——慢。针对 bundle 方案的缺点,业界推出了 unbundle 方案(当然最主要还得感谢浏览器的支持)。
unbundle 方案的出现,需要感谢 ESM。啥是 ESM 呢?ESM 全称为 ECMAScript modules,即浏览器原生支持模块化规范。效果如下:
<script type="module">
// 引用别的模块
import { util } from './utils.js';
// 使用别的模块中的函数
util()
</script>当浏览器解析到 import 语句时,会像开发态一样自动引入对应模块。得益于 ESM,我们可以不经过构建即可直接在浏览器端运行模块化代码。
相比于 bundle 方案,unbundle 方案在各种意义上都快了许多,特别当项目复杂度上来以后,这个差异将会异常明显;另一方面,unbundle 不需要在浏览器端实现一个打包工具,对于快速实现浏览器实时构建也有着很大的意义。
由于 unbundle 的各种优点,最终我选择了使用 unbundle 方案来实现浏览器实时构建。
接下来,到了实战环节,我们来尝试实现一个单文件浏览器实时构建。
该系统分为两部分:
首先是 UI 部分,UI 简单的分成三部分:代码编辑器(如:monaco editor),按钮(用于执行实时构建函数)以及构建结果展示部分,主要负责调试代码并展示结果。
当点击按钮后,触发构建函数,开始执行构建逻辑,整个构建流程主要分为以下几步:
总体思路其实和 vite 非常像,也可以认为是在浏览器端实现了一个小 vite。详细的代码可以参考 vite 源码,在此不再赘述。
服务端的功能非常简单,即接收请求,返回对应的依赖打包文件。由于 ESM 只支持 ESM 规范,所以,需要将各种模块规范(主要指的是 commonjs)统一转为 ESM。
当依赖服务器接收到客户端的请求时,具体工作流程如下:
通过上面的思路,我们就可以实现一个最简单的单文件浏览器实时构建了,但是其实有非常多的问题,比如:
本来我很想直接来一句:这些问题留作课后思考[doge],但是怕被打,所以接下来就聊下我对这几个问题的看法吧。
以上就是我的思路,如果大佬们有不同的思路,欢迎一起探讨。
按照惯例,发个招聘帖:
字节跳动招人啦,HC 巨多,北上广深杭皆有坑位。
团队详情见:https://webinfra.org/about
提供内推及面试辅导服务,目前我内推的几个同学皆通过了面试,欢迎咨询~
暂时不看机会,之后有想法来字节试试的同学,也一样欢迎你加入 😁。
有意者可发送邮件到 [email protected]
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.