kailbin / blog Goto Github PK
View Code? Open in Web Editor NEWblog
License: MIT License
blog
License: MIT License





Java 里面的位运算操作符有 与& 、或|、非~、异或^、左移<<、右移>>、无符号右移>>>
&|~^<<>>>>>依次类推,左移2位乘4(*2*2)、左移3位乘8(*2*2*2)...
System.out.println(10 >> 1); // 5 (10 / 2 = 5)
System.out.println(10 << 1); // 20 (10 * 2 = 20)
System.out.println(-12 >> 2); // -3 (-12 / 4 = -3)
System.out.println(-13 << 3); // -52 (-13 * 4 = -52)
一个数的二进制位最低一位,如果是1则为奇数,如果是0则为偶数;数字1的二进制位,高位都是0,最低位是1;与1进行与运算&,结果高位都会变成0,最低位如果是奇数则1(同1得1),偶数则0(否则得0)
System.out.println((10 & 1) == 0); // true
System.out.println((11 & 1) == 0); // false
System.out.println((-10 & 1) == 0); // true
System.out.println((-11 & 1) == 0); // false
通过以上 右移除2 和 计算奇数偶数 的特性,可以使用以下方式算出一个整数的二进制形式:
public static String toBit(byte num) {
return toBit(num, 8);
}
public static String toBit(int num, int size) {
StringBuilder buf = new StringBuilder();
for (int length = size - 1; length >= 0; length--) {
buf.append((num >> length) & 1);
}
return buf.toString();
}
size的大小必须能够表示num的数字大小,例子:
System.out.println(toBit((byte) 1, 3)); // 001
System.out.println(toBit((byte) 2, 3)); // 010
a ^ 0 = a (任何数字和0异或 等于本身)a ^ a = 0 (自己和自己异或 等于0)a ^ b = b ^ a (满足交换律)a ^ b ^ a = b (根据1、2、3的特性,a^b^a=a^a^b=0^b=b)a ^ b ^ c = a ^ (b ^ c) = (a ^ b) ^ c (结合律,通过3和得出这条结论)d = a ^ b ^ c → a = d ^ b ^ ca ^ -1 = -a - 1根据 异或运算的一些特性,不引用第三个变量也可以交换两个变量
int a = 1; // 0001
int b = 2; // 0010
a = b ^ a; // 临时变量
b = b ^ a; // b ^ a = b ^ (b ^ a) = 0 ^ a = a
a = a ^ b; // a ^ b = (b^a) ^ (b^(b^a))=a^a^b^b^b=b
( x ^ y ) < 0 // 同号小于0,异号则大于0
负数最高位是1正数0,两个同类型的数字相比,实际上比的还是最高位,一正一负异或得1,还是负数,小于0
public static int abs(int x) {
return (x ^ (x >> 31)) - (x >> 31); //or: (x+y)^y
}
如果是正数,x >> 31 为 0,x ^ 0 还是x,则以上公式变为 x^0-0=x-0=x;
如果是负数,x >> 31 为 -1,x ^ -1为-x-1,则以上公式变为 (-x-1)-(-1)=-x;
题目是对数组中大于等于128的数字进行求和,大家发现,如果数组是有序的情况加,计算起来会比无序的情况下快很多,原因是分支带来了一定的性能损耗,原文 why is it faster to process a sorted array than an unsorted array
有人给出了以下解决方案,
int t = (data[index] - 128) >> 31; // s1
sum += ~t & data[index]; // s2
s1取遍历到的每个数据减128,如果比128大相减后为正数,否则为负数,正数右移31位为0,负数为-1,则 t如果是0则大于或等于128,-1则小于128;通过s1可判断出data[index]是否大于等于128
0 & x = 0、-1 & x = x,则data[index]如果大于128,t为0,~t为-1,-1 & data[index] = data[index]
当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会增加一倍,性能也将提升一倍。换言之,每一美元所能买到的电脑性能,将每隔18-24个月翻一倍以上。这一定律揭示了信息技术进步的速度
Google的前CEO 埃里克·施密特 提出的:如果一个IT公司如果今天和18个月前卖掉同样多的、同样的产品,它的营业额就要降一半
反摩尔定律逼着所有的硬件设备公司必须赶上摩尔定律所规定的更新速度,而所有的硬件和设备生产厂活得都是非常辛苦的
百度百科 反摩尔定律
TOC(Theory of constraints)其核心观点为:系统最终的产出将受到系统内最薄弱环节的限制。换言之,任何一个链条的牢固程度取决于它最薄弱的环节。
这是一对完全基于两种完全相反假设的理论,X理论认为人们有消极的工作源动力,而Y理论则认为人们有积极的工作源动力。即:麦格雷戈的人性假设与管理方式理论。
他把传统的管理观点叫做 X理论,其要点是:
他针对X理论的错误假设,提出了相反的Y理论。他把Y理论叫做个人目标与组织目标的结,其要点是:
其根本内容是:如果事情有变坏的可能,不管这种可能性有多小,它总会发生
主要内容是:
百度百科 墨菲定律
“墨菲定律”、“帕金森定理”和“彼德原理”并称为二十世纪西方文化三大发现
假如下图是个方桌,现在随机往桌子上抛个硬币,问:硬币落在黄色区域的概率是多少?

了解过概率统计的同学会瞬间给出答案:1/4 或者 25%
如何用数学公式描述呢?
假设把 “硬币落在黄色区域” 这个事件命名为A,则落在黄色区域的概率为 P(A)。
P 是 probability 的缩写。
先查看防火墙是否打开,是否去掉 “仅允许运行使用网络级别身份验证的远程计算机…”
如果还是不行的话。便需要开启组策略中远程桌面链接安全层:
gpedit.msc,进入组策略编辑器。原文链接:GC Tuning Confessions of a Performance Engineer by Monica Beckwith
很高兴再次为您提供最新的 Virtual JUG 大会概述。这次我们将讨论垃圾回收(GC)这个自动内存管理工具,它使我们和我们的应用相信,只要不一次性的消耗太多,就会有无限的内存。
本次会议由 Monica Beckwith 呈现。Monica是一个独立咨询顾问,她专门为企业应用 优化 Java 虚拟机和 垃圾回收器。她是各种会议的常客,还发表过 垃圾回收、Java内存模型等专题文章。Monica还曾引领 Oracle 的 G1GC 性能团队,被称为 JavaOne Rock Star。你可以在 Twitter 上关注 Monica @mon_beck。
下面是 Youtube 上的会议视频,点击查看:
以下附出一些相关资源(非原文内容)
垃圾回收是任何现代化应用平台的重点之一。JVM也不例外,Java代码访问内存是由平台自动管理。
你不需要为你的对象明确分配多少字节空间,而且也不需要手动释放内存。虽然有许多实现内存管理的方法,但是 JVM 的垃圾回收无疑的最高水准的。
简而言之,所有分配在内存中的对象都是在堆中分配的。堆代表你的代码可以访问的所有内存。当堆上没有多余的空间的时候,释放内存的算法会在堆上移除对象,为你提供更多的空间。
垃圾回收最重要地方在于 什么时候 如何运行。当然,抽象化的内存也会占用你的应用可用资源。
如果垃圾收集器和你的程序并行执行(部分GC被称为并发)。当GC使用很多线程并行的加速工作时,这时候被称为并行。目前在 JDK8 的实现中,默认的垃圾回收器是并行并发执行的,这使得垃圾回收真的很快。接下里让我们看一下 GC 会执行那些操作,讨论一下它们为什么那么重要,并且看一下它们是如何影响 GC 的性能的。
垃圾回收器主要就是为了处理垃圾。这就意味着如果你的对象正在被应用使用的时候,垃圾回收之后,这个对象仍然会存在。不可达的对象会被认定为死亡,之后会被删除并释放内存。
这就需要一些标记来区分对象是死了还是活着。最简单的做法是标记对象图,从根对象开始,查看哪些对象仍然在被访问并且应该被保留。需要注意的是,你不需要要每次都遍历所有的堆去寻找存活的对象,因为这个操作代价太大,平台更希望把这些资源让给那些对实际业务有用的操作。所以它会通过两个阶段来进行操作:标记和清除。在标记阶段会找到存活的对象。然后把这些活动的对象移动到连续的内存空间区域中,从而使空闲的空间也是连续的内存区域,以便使用。可以把这个过程理解为磁盘碎片整理。
虽然很容易实现一个只对单一内存块进行回收GC的算法,但是这并不是最优的。为了避免一次又一次的遍历所有的对象进行回收占用宝贵的资源,堆实际上是划分区域的,特定属性的对象会存放在特定的区域,这被称为分代(generations)。下图是 Oracle 垃圾回收基础教程(Oracle’s Garbage Collection Basics tutorial)阐述的分代图:
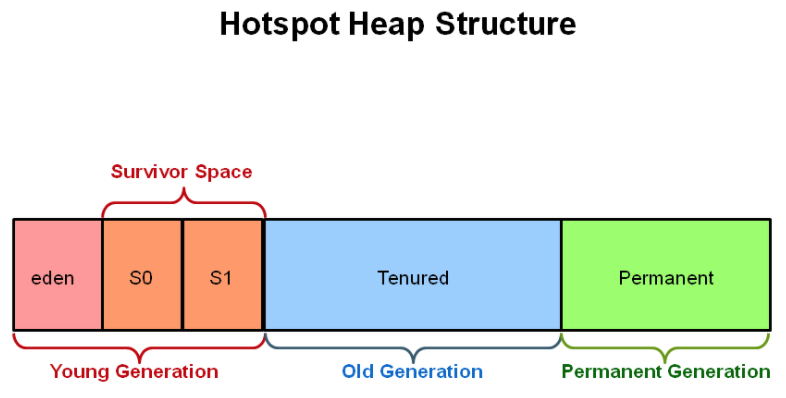
所有新创建的对象被放在新生代(Young generation)。实际上在大多数应用中,大部分的对象寿命并不长。如果对象在方法中创建,很可能在方法调用完毕之后就死了。
如果对象存活的时间足够长,那么他们将被移动到旧生代(Old generation),这里很少会执行GC。在新生代和旧生代发生的垃圾回收分别被称为 次要(Minor)和主要(major) 垃圾回收。
Minor垃圾回收 主要删除新生代的死对象。因为在这个回收发生的时候大多数对象是不可达的,所以速度会非常快。通常新生会还会有被划分出一个更小的区域,称为幸存者(Survivor)空间。在Minor垃圾回收之后仍然存活的对象会被移动到这个空间。如果经历和多次Minor垃圾回收仍然从幸存者空间幸存了下来,他们会继续变老,被移动到老年代(旧生代)。
Major 垃圾回收会在老年代运行。这个过程通过较慢,因为这里有更多的对象存活。毕竟他们已经存活了很长时间,才能升级到老年代。
虽然分代这种方式是有效的,但是这种方式与设置更大的堆是有冲突的。由于堆空间是按块划分的,堆越大块越大。Major GC 需要暂停虚拟机去分析老年代的整个内存,通常这个过程是很耗时的。而且对应用来说,这层抽象化的操作是不可见的。
G1GC 是一个区块化、并行、并发、增量的垃圾回收器,与HotSpot GC 相比,其暂停也是可预测的。分代垃圾回收的主要问题在于不够灵活。事实上,随着内存和硬件越来越便宜,应用程序也变的越来越饥渴。我们很自然的想要运行数百G内存的JVM。但是这么大的内存会让 GC 的暂停问题十分明显。想象一下,这么大的内存下有三分之一是老年代,可能会有 30G 的对象会被标记移动。JVM 的用户是不能容忍在一个较小的堆上有这么长时间的暂停的。这就是为什么我们不能在不牺牲性能或改变垃圾收集方式的情况下给予Java更多的内存。
给 Java 更多的内存就可能会带来性能消耗,这个性能消耗主要体现在垃圾回收上,内存越大,垃圾回收越慢,应用暂停的时间越长。
G1GC 对堆的划分不同于分代划分。事实上它将堆划分成数千个称之为区域(regions)的小空间。这样 GC 可以针对个别区域进行清理,并通过适当的措施,使每个 GC 事件尽可能的短。这就是 G1GC 的主要价值,在更大的堆上,实现可预测的 GC 暂停事件。
这个创举不是毫无副作用。G1GC 不得不需要记录 是否一个区域里的对象会引用另一个区域里的对象,类似于 GC 的根。并且这会和你的应用代码一块进行。这意味着着 GC 比以前更加占用 CPU,你的应用会得到更少的资源。
然而,基于区域粒度上增强了,这使得 GC 比以前更快了,而且 自适应性更强,可调整空间更大。
这里有一些 Monica 提到的命令用于调整 G1GC。
-XX:G1HeapRegionSize=n 值是 2 的幂,范围是 1 MB 到 32 MB 之间。目标是根据最小的 Java 堆大小划分出约 2048 个区域-XX:MaxGCPauseMillis=200 GC可以暂停多长时间。 这只是个建议值,G1GC 暂停的时间会尽可能比这个值短。默认值是 200 毫秒-XX:G1HeapWastePercent=10 设置您愿意浪费的堆百分比。 垃圾越大, GC 在新区域分配对象时越快,而不是试图将这些空间浪费掉你还可以在 Oracle 博客上找到更多的选项和GC的基本准则。
... 略
原子性(Atomicity):原子性是指事务包含的所有操作要么全部成功
一致性(Consistency):事务执行之前和执行之后都必须处于一致性状态
隔离性(Isolation): 多个并发事务之间要相互隔离,事务的隔离性数据库提供了多种隔离级别
持久性(Durability): 事务一旦被提交了,那么对数据库中的数据的改变就是永久性的
在分布式系统中**,一致性**、可用性和分区容错性,3 个要素最多只能同时满足两个,不可兼得。
放弃C并不是完全不需要数据的一致性(如果是这样,数据就没有了意义),实际上是放弃强一致性,保留最终一致性
放弃P意味着放弃了系统的可扩展性,实际上变成了单点应用
请求都需要在Server之间强一致,而分区会导致同步时间无限延长,如此CP也是可以保证的,但是导致系统可用性降低,性能急剧下降
分布式系统中,最重要的是满足业务需求,而不是追求抽象绝对的系统特性。
可以通过放弃系统在每个时刻的强一致性来换取系统的可扩展性。核心**:
ACID是传统数据库常用的设计理念,追求强一致性模型。BASE支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。ACID和BASE代表了两种截然相反的设计哲学。
在分布式系统设计的场景中,系统组件对一致性要求是不同的,因此ACID和BASE又会结合使用。
分布式系统的BASE理论 http://www.hollischuang.com/archives/672
XA 是 X/Open DTP组织(X/Open DTP Group)定义的两阶段提交协议。
X/Open DTP模型(1994)包括应用程序(AP)、事务管理器(TM)、资源管理器(RM)、通信资源管理器(CRM)四部分。
通常**事务管理器(TM)**是交易中间件,**资源管理器(RM)**是数据库,通信资源管理器(CRM)是消息中间件。
XA是一个协议,实现的关键是二阶段提交(2PC),其有个致命的缺点,那就是性能不理想,无法满足高并发场景。
2PC 主要保证了分布式事务的原子性:即所有结点要么全做要么全不做
事务协调者(事务管理器)给每个参与者(资源管理器)发送prepare消息,每个参与者要么直接返回失败,要么在本地执行事务但不提交,并将Undo信息和Redo信息写入日志,到达一种“万事俱备,只欠东风”的状态。
如果协调者收到了参与者的失败消息,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。
3PC 在 2PC 的基础增加以下两点:
协调者想参与者发送提交询问请求,如果可以提交就返回Yes,否者返回No,询问阶段。该阶段和 2PC的准备阶段(Prepare)很像但是不记录undo和redo日志。
可以提交的话记录 undo和redo日志。
通知各个参与者对事务进行提交。
在任意阶段如果请求超时,则发送回滚信号。
2PC和3PC的详细过程请参见:
关于分布式事务、两阶段提交协议、三阶提交协议
分布式协议之两阶段提交协议(2PC)和改进三阶段提交协议(3PC)
核心**是将需要分布式处理的任务通过消息或者日志的方式来异步执行,消息或日志可以存到本地文件、数据库或消息队列,再通过业务规则进行失败重试,它要求各服务的接口是幂等的。
假如有一个场景为:有用户表user 和交易表transaction,用户表存储用户信息、总销售额和总购买额,交易表存储每一笔交易的流水号、买家信息、卖家信息和交易金额。如果产生了一笔交易,需要在交易表增加记录,同时还要修改用户表的金额。
解决方法是将更新交易表记录和用户表更新消息放在一个本地事务来完成。这个方案的核心在于需要保证第二阶段(用户表更新)的重试是幂等执行
失败后重试,这是一种补偿机制,它是能保证系统最终一致的关键流程。
支付系统接收到会员的支付请求后,需要扣减会员账户余额、增加会员积分(暂时假设需要同步实现)增加商户账户余额。再假设:会员系统、商户系统、积分系统是独立的三个子系统,无法通过传统的事务方式进行处理。
以上所有的操作需要满足幂等性,幂等性的实现方式可以是:
一般通过定时任务跑批,查询出数据不一致的情况,进行修复
分布式事务的典型处理方式:2PC、TCC、异步确保和最大努力型
常用的分布式事务解决方案介绍有多少种?
分布式系统的一致性探讨
常用的分布式事务解决方案介绍
程立谈大规模SOA系统
欢迎来到 第十个 RebelLabs 备忘单!这次我们将专注于那些你想用但是忽略掉的 JVM 选项。在这篇文章中,我们将介绍每个重要选项的功能。但是首先,让我们回顾一下下面10份备忘录,就要追溯到2015年12月份了!
我艹,太吊了(Wow, what a colorful journey! Here’s an amazing fact for you)。如果打印出上面所有的备忘录放在手边,那么你将腾出很多时间去做你喜欢的事。废话少说,点击下面的图片,打印出来吧,这样你就不用把那些该死的选项记在脑子里了。
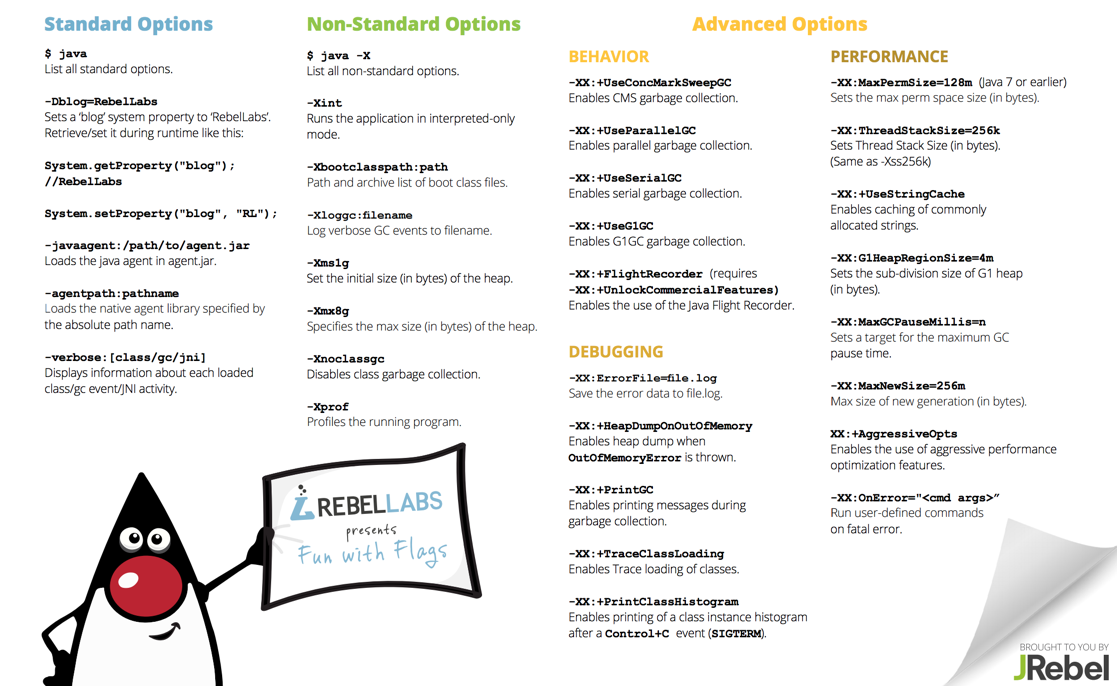
让我们从上往下看。有三种类型的选项可以传递给 JVM:标准、非标准和高级选项。
-XX:开头;-X;我这样来告诉你,是不是发现好记了很多呢!下面,我们就从标准选项开始吧。
如果你想获得所有的标准选项列表,只要在命令行输入 java 即可,不需要携带任何参数,你想看到大量的标准选型并且带有使用说明。在这份备忘单中,我们选了一些最有趣的选项。
这里附上我在执行 java 时的输出:
$ java
用法: java [-options] class [args...]
(执行类)
或 java [-options] -jar jarfile [args...]
(执行 jar 文件)
其中选项包括:
-d32 使用 32 位数据模型 (如果可用)
-d64 使用 64 位数据模型 (如果可用)
-server 选择 "server" VM
默认 VM 是 server,
因为您是在服务器类计算机上运行。
-cp <目录和 zip/jar 文件的类搜索路径>
-classpath <目录和 zip/jar 文件的类搜索路径>
用 : 分隔的目录, JAR 档案
和 ZIP 档案列表, 用于搜索类文件。
-D<名称>=<值>
设置系统属性
-verbose:[class|gc|jni]
启用详细输出
-version 输出产品版本并退出
-version:<值>
警告: 此功能已过时, 将在
未来发行版中删除。
需要指定的版本才能运行
-showversion 输出产品版本并继续
-jre-restrict-search | -no-jre-restrict-search
警告: 此功能已过时, 将在
未来发行版中删除。
在版本搜索中包括/排除用户专用 JRE
-? -help 输出此帮助消息
-X 输出非标准选项的帮助
-ea[:<packagename>...|:<classname>]
-enableassertions[:<packagename>...|:<classname>]
按指定的粒度启用断言
-da[:<packagename>...|:<classname>]
-disableassertions[:<packagename>...|:<classname>]
禁用具有指定粒度的断言
-esa | -enablesystemassertions
启用系统断言
-dsa | -disablesystemassertions
禁用系统断言
-agentlib:<libname>[=<选项>]
加载本机代理库 <libname>, 例如 -agentlib:hprof
另请参阅 -agentlib:jdwp=help 和 -agentlib:hprof=help
-agentpath:<pathname>[=<选项>]
按完整路径名加载本机代理库
-javaagent:<jarpath>[=<选项>]
加载 Java 编程语言代理, 请参阅 java.lang.instrument
-splash:<imagepath>
使用指定的图像显示启动屏幕
首先,我们从公共系统属性开始。这可以在 JVM 创建时传入,如下:
-Dblog=RebelLabs -D标志 表示后面的键值对将会作为JVM的系统属性,我们可以通过以下参数获取:
System.getProperty("blog"); //RebelLabs相同的系统属性,也可以在系统启动的时候通过程序创建,就像下面这样:
System.setProperty("blog", "RL");在 ZeroTurnaround,java agent 无非是我们的最爱!事实上,我们已经把它添加到了我们所有的产品中,从 JRebel 到 XRebel, 从 JRebel for Android 到 XRebel Hub!
java agent 非常像一个 JVM 插件,它使用了 Instrumentation API。通过它可以进行有趣的字节码操作,从而实现很多神奇的工具。要添加一个 java agent,只需指向一个包含 agent 代码和manifest 的jar包路径即可,如下:
-javaagent:/path/to/agent.jar如果想要的 JVM运行时获得更多其内部运行的信息,可以使用-verbose 选项。你可以使用多种风味来收集不同的信息。这些信息包括 加载类(class)、垃圾回收(gc)、JNI(jni)的活动信息。下面的例子中我们将获得 垃圾回收的详细信息。所有信息都将已日志的形式打印到标准输出中。
-verbose:gc像标准选项那样,你可以在命令行执行 java -X 召唤出完整的 非标准选项列表。下面附出我在本机执行的结果:
-Xmixed 混合模式执行 (默认)
-Xint 仅解释模式执行
-Xbootclasspath:<用 : 分隔的目录和 zip/jar 文件>
设置搜索路径以引导类和资源
-Xbootclasspath/a:<用 : 分隔的目录和 zip/jar 文件>
附加在引导类路径末尾
-Xbootclasspath/p:<用 : 分隔的目录和 zip/jar 文件>
置于引导类路径之前
-Xdiag 显示附加诊断消息
-Xnoclassgc 禁用类垃圾收集
-Xincgc 启用增量垃圾收集
-Xloggc:<file> 将 GC 状态记录在文件中 (带时间戳)
-Xbatch 禁用后台编译
-Xms<size> 设置初始 Java 堆大小
-Xmx<size> 设置最大 Java 堆大小
-Xss<size> 设置 Java 线程堆栈大小
-Xprof 输出 cpu 配置文件数据
-Xfuture 启用最严格的检查, 预期将来的默认值
-Xrs 减少 Java/VM 对操作系统信号的使用 (请参阅文档)
-Xcheck:jni 对 JNI 函数执行其他检查
-Xshare:off 不尝试使用共享类数据
-Xshare:auto 在可能的情况下使用共享类数据 (默认)
-Xshare:on 要求使用共享类数据, 否则将失败。
-XshowSettings 显示所有设置并继续
-XshowSettings:all
显示所有设置并继续
-XshowSettings:vm 显示所有与 vm 相关的设置并继续
-XshowSettings:properties
显示所有属性设置并继续
-XshowSettings:locale
显示所有与区域设置相关的设置并继续
-X 选项是非标准选项, 如有更改, 恕不另行通知。
以下选项为 Mac OS X 特定的选项:
-XstartOnFirstThread
在第一个 (AppKit) 线程上运行 main() 方法
-Xdock:name=<应用程序名称>"
覆盖停靠栏中显示的默认应用程序名称
-Xdock:icon=<图标文件的路径>
覆盖停靠栏中显示的默认图标当 JVM 启动的时候,它使用默认的 bootstrap 类路径来加载引导类和资源。要覆盖默认的启动类路径,可以通过以下选项把 路径 和/或 归档列表 提供给 JVM。
-Xbootclasspath:path你可以通过 -Xbootclasspath/a:path 和 -Xbootclasspath/p:path 分别追加或预加默认引导路径。
你是否厌烦了把 GC 事件作为日志输出到标准输出流?如果是,那么下面这个选项就是为你所准备!设置-Xloggc这个选项,并且提供一个你打算输出的目标文件路径!这个选项将会覆盖上节说到的-verbose:gc选项。
-Xloggc:filename避免 JVM 在堆中崩溃的最好做法 就是一开始就设置堆的大小。但问题是 堆应该设置为多大?这取决于你的应用程序和打算用JVM来做什么。在确定最终应该设置多大之前,你应该不断的改变你的堆大小然后进行测量评估。你可以设置堆的初始字节和最大字节数,单位可以使用常用的 k、m、g。下面的示例设置JVM的初始堆大小是 1GB,如果不够,最大能增长到 8GB。
-Xms1g -Xmx8g要禁用类的垃圾回收,可以用下面的选项。这样可以节省垃圾回收的时间,这时候只有对象才有资格被垃圾回收。当然,这样也增加了内存不足的风险,特别是在 使用了永久代空间的 Java 版本里。
-Xnoclassgc我们讨论的最后一个非标准选项,将允许你 profile 运行中的 JVM。当然,它没有那些具有 漂亮UI和丰富功能 的工具易于理解和使用,例如 XRebel (而且很便宜)。但是下面这个参数很容易启用。所有的信息都会在标准输出显示。
-Xprof这个备忘单由 XRebel 提供,它是一个在你工作中 提醒你的应用性能问题的工具,而不是让你的用户来发现这些问题。如果你正在开发 Java Web 程序,就应该尝试使用它。这个将会改变你对你程序表现的态度。
我们将围绕着垃圾回收这个主题开始。在 Java9 中,标准的垃圾回收器是 Garbage First Garbage Collector (G1GC),你也可以选择其它的垃圾回收器来执行垃圾回收策略。这些垃圾收集器包括 并发标记清除(Concurrent Mark Sweep (CMS))、并行扫描、串行 垃圾回收器,当然还包括G1GC。你可以通过下选项来启动它们。无需多说,请不要尝试同时使用多个选项来运行。
-XX:+UseConcMarkSweepGC
-XX:+UseParallelGC
-XX:+UseSerialGC
-XX:+UseG1GC飞行记录器这(Flight Recorder)个功能是 JDK 内置的。它允许你获得有关应用和JVM的详细信息。和你期望的分析器功能类似,它将收集事件信息供你检查。为了使用这个功能,你需要使用单独的选项来解锁JVM的这个商业功能。这两个选项如下所示:
-XX:+FlightRecorder -XX:+UnlockCommercialFeatures如果你希望用一个专门的文件来查看错误数据,可以使用下面的选项 外加一个日志文件名。现在你就可以看到一个漂亮干净的日志文件,里面只有那些令人惊讶的错误!
-XX:ErrorFile=file.log想调试一个错误,但是却没有错误信息,没有什么比这个更令人沮丧了。最好的例子例子就是 常见的OutOfMemory错误。这个事件会让你的JVM瘫痪却不告诉你原因。使用下面这个选项可以帮到你。HeapDumpOnOutOfMemory 会为你提供一个包含大量调试信息的 .hprof 文件。你可以使用 Eclipse MAT 或者其他你喜欢的工具打开,它可以找出是什么囤积在堆里面。里面内容非常详细,你可以拿到最原始的对象,诊断出可能的内存泄露问题。
-XX:+HeapDumpOnOutOfMemory如果你很想了解垃圾回收器如何工作,但是又不想使用-verbose:gc 打印沉长的完整详细信息,可以尝试 PrintGC 选项。每次执行垃圾回收时,它只简单的打印一条消息。
-XX:+PrintGC你对 什么时候 或 在什么条件下 你的类会被加载充满好奇吗?如果是,你可能需要看一下下面这个选项。这个选项可以追踪JVM加载的每个类。如果这种事情对你是有帮助的。
-XX:+TraceClassLoading在你打算发牢*之前声明一下,是的,我知道 永久代已经从 Java8 中移除了!但是,如果没有酷到使用最新版的版本,你会发现下面的这个参数很有用。如果你存在 PermGen 不够的问题,那么你会发现它很有用。你可以改变 PermGen 的最大大小,就像改变老年代堆大小一样。只需要提供你想要的最大字节数,如下:
-XX:MaxPermSize=512k你应该知道线程的栈内存空间并没有从堆中分配,因此当你使用 -Xms 和 -Xmx 选项的时候并不会对此产生影响。如果你想增加 甚至是减少线程栈空间大小,你可以像下面这样指定一定的字节数。
-XX:ThreadStackSize=256k在 Java8 之前提供了一个有趣的UseStringCache 选项。这允许JVM缓存字符串。然而不幸的是它从 Java8 中移除了,而且没有可替换的选项。所以如果你想用到这个选项必须使用较早的版本。
-XX:+UseStringCache如果你正在使用 G1GC,你应该非常熟悉这个区域的大小,并且了解什么是对你的应用有益。与所有的选项一样,你应该不断的尝试不同的值,然后进行评估。将来,G1GC 将成为 Java9 的标配,你需要和它成为最好的朋友。
-XX:G1HeapRegionSize=4m我们之前提到的-Xms 和 -Xmx选项只适用于老年代堆。在大多数JVM中,Java 的堆空间还包含一个 年轻代 或者 托儿所(nursery) 堆。要设置年轻代的最大大小,可以使用一下选项。
-XX:MaxNewSize=256m如果你想让你的 JVM 性能很激进(angry and thirsty)的战斗,你可以使用下面这个 积极的性能优化功能。
XX:+AggressiveOpts这篇文章文章中,我们涵盖了一些流行并且有趣的 Java 命令行选项。对于完整的 Java8选项列表,请查看 Oracle 官方文档。当你修改你的参数的时候,请务必记住,一定要不断的 测试、评估、迭代,以便正确的调优 JVM,尤其是在堆大小方面。
原文在讲到 -XX:MaxNewSize=256m 这个参数的时候,说 -Xms 和 -Xmx 修改的是老年代的堆空间大小,感觉不是太对,因为印象中,这两个参数设置的是整个堆空间的大小,包含 新生代(年轻代)和旧生代(老年代)。
后续查了一下Oracle Garbage Collection Tuning Guide 官方文档中Total Heap这一节,
文中提到
the total size is bounded below by
-Xms<min>and above by-Xmx<max>.
所以-Xms 和 -Xmx修改的是整个堆的大小,而不仅仅是老年代。
wget --no-check-certificate https://bootstrap.pypa.io/get-pip.py
python get-pip.py
pip Installation
pip install mysql-python
或
wget --no-check-certificate https://github.com/farcepest/MySQLdb1/archive/MySQLdb-1.2.5.tar.gz
# 解压 进入 执行
python setup.py install
# apt-get install libmysqlclient-dev
yum install mysql-devel
yum install gcc libffi-devel python-devel openssl-devel
MySQL-python 1.2.5
farcepest/MySQLdb1
pip install mysql-python fails with EnvironmentError: mysql_config not found
# 读写 Excel
pip install xlwt
# 输出 Hello Python!
print "Hello %s!" % "Python"
# 保留两位小数,输出 33.33%;
print "%.2f%%" % (float(1)/float(3)*100)
# 为真时的结果 if 判定条件 else 为假时的结果
print 1 if 5 > 3 else 0 # 输出 1
import datetime
# 当前时间
today = datetime.date.today()
# 获取一个时间的差值
between = datetime.timedelta(days=1)
# 明天
print today + between
# 昨天
print today - between
# 格式化输出 年-月-日 时:分:秒
print today.strftime("%Y-%m-%d %H:%M:%M")
# 或获取某一天是星期几(星期一是0,以此类推)
print datetime.datetime(2016,1,1).weekday()
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.utils import COMMASPACE, formatdate
def send_mail(subject, content):
msg = MIMEMultipart()
msg['From'] = sender # 显示是谁发送的
msg['Subject'] = subject.decode('utf8').encode('gbk') # 邮件主题
msg['To'] = COMMASPACE.join(receiver) # 显示发送给谁
msg['Cc'] = COMMASPACE.join(cc) # 显示抄送给谁
msg['Date'] = formatdate(localtime=True)
msg.attach(MIMEText(content.decode('utf8').encode('gbk'), 'html', 'gbk'))
smtp = smtplib.SMTP(smtpserver, 25)
smtp.login(username, password) # 用户名密码
smtp.sendmail(sender, receiver + cc, msg.as_string()) # 真正的发件人和收件人
smtp.quit()
import MySQLdb
def select_sql(dbinfo, sql):
conn = MySQLdb.connect(host="", user="", passwd="", db="", charset="")
cursor = conn.cursor()
cursor.execute(sql)
title = cursor.description
data = cursor.fetchall()
conn.close()
return title, data
同源策略(Same origin policy)是一种约定,它是浏览器最核心也最基本的安全功能。以下几点同时满足认为是同源:
同源策略限制:从一个域上加载的脚本不允许访问另外一个域的文档属性。
但是以下标签通过 src 加载资源(实际上是发起了一次GET请求),不受同源策略的限制,可以跨域访问资源:
<script><img><iframe><link>但浏览器限制了JavaScript的权限使其不能读、写加载的内容。
AJAX 受到同远策略的限制,无法跨域访问资源。
但是人们利用<script>标签的跨域能力实现了跨域数据的访问,产生了 JSONP。需要注意的是 JSONP 和 AJAX 并不是相同的技术概念,两者完全不同。
使用 JSOUP 实现跨域的原理与流程如下:
function,方法名随机,如:eval("function hello_1232412342(data){console.info('hello ' + data);}")
这时候浏览器端会存在一个方法,如下:
function hello_1232412342(data){
console.info('hello ' + data);
}
<script> 标签,加载服务端接口,可以非同源,需要附加参数,callback=hello_1232412342,callback 的参数值是上一步生成的方法名<script src="http://other.host.com/some/resource?callback=hello_1232412342"><script>
hello_1232412342("world")<script> 标签会执行里面的脚本整个过程实际上会简单的变成这样:
<script>
<!-- 定义一个名称随机的函数,该函数是通过eval() 生成的 -->
function hello_1232412342(data){
console.info('hello ' + data);
}
<!-- 执行这个函数,这个函数是服务端生成的 -->
<!-- 通过script标签加载进来: <script src="http://other.host.com/some/resource?callback=hello_1232412342"><script> -->
hello_1232412342("world");
<script>
Proxy 解决跨域问题是利用了服务端之间的资源请求不会有跨域限制的特点实现的,具体来说就是前端发起的请求被Nginx拦截,再由Nginx代由转发请求到资源服务器请求资源。
Nginx 配置如下:
# 拦截以 /cors/ 开头的链接
location ^~ /cors/ {
# 设置 proxy_hostname 变量,默认访问本机 55582 端口
set $proxy_hostname http://192.168.31.105:55582;
# 如果请求头中有 Target-Origin 且以 http 开头
# 则转发的指定的目标源
if ($http_target_origin ~ ^http ) {
set $proxy_hostname $http_target_origin;
# add_header 'Cors-Target' "${http_target_origin}";
}
proxy_pass $proxy_hostname;
}
前端(在http://192.168.31.105源下,调用 http://192.168.31.105:55581/cors/data)调用示例如下:
<script src="//cdn.bootcss.com/jquery/1.12.0/jquery.min.js"></script>
<script>
$(function () {
$.ajax({
type: "GET",
url: "http://192.168.31.105/cors/data",
success: function(data) {
$("body").append(data);
},
beforeSend: function(xhr) {
// 自定义的请求头
// 访问 http://192.168.31.105/cors/data 到Nginx之后,会转发到 http://192.168.31.105:55581/cors/data
xhr.setRequestHeader("Target-Origin", "http://192.168.31.105:55581");
}
});
})
</script>
CORS 全称是"跨域资源共享"(Cross-origin resource sharing),它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
浏览器通过读取 Response 的响应头来控制AJAX是否可以跨域。
// 简单请求 Response
Access-Control-Allow-Origin: * // 允许所有Origin
Access-Control-Allow-Credentials: true // true 表示可以发送Cookies
Access-Control-Expose-Headers: FooBar // 允许跨域读取FooBar扩展字段
// 预检请求 Request
Access-Control-Request-Method: PUT // 允许发送的请求类型
Access-Control-Request-Headers: X-Cus-H // 允许发送的自定义头
// 预检请求 Response
Access-Control-Allow-Methods: GET, POST, PUT
Access-Control-Allow-Headers: X-Cus-H // 允许发送的自定义头
Access-Control-Max-Age: 1728000 // 单位s,在此期间,不用发出另一条预检请求
location / {
#
# 对复杂请求,预检请求进行处理
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Origin' '*';
#
# 允许Cookie 和 允许的请求方式
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
#
# 允许发送的头
add_header 'Access-Control-Allow-Headers' 'DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type';
#
# 告诉客户端与检查有效期20天
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain charset=UTF-8';
add_header 'Content-Length' 0;
return 204;
}
if ($request_method = 'POST') {
# 允许所有(建议配置具体的域名)
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type';
}
if ($request_method = 'GET') {
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type';
}
}
Spring MVC 4.2 开始对 CORS 进行支持,最简单的方式就是使用注解@CrossOrigin,可以控制到可以一个请求 或 一个Controller。
以下注解里面的属性可以和W3C定义的头属性相对应:
// Access-Control-Allow-Origin
String[] origins() default {};
// Access-Control-Allow-Headers 允许发送的自定义头
String[] allowedHeaders() default {};
// Access-Control-Expose-Headers 允许跨域读取的扩展字段
String[] exposedHeaders() default {};
// Access-Control-Allow-Methods 允许的请求方式
RequestMethod[] methods() default {};
// Access-Control-Allow-Credentials
String allowCredentials() default "";
// Access-Control-Max-Age
long maxAge() default -1;
Enabling Cross Origin Requests for a RESTful Web Service
CORS support in Spring Framework
官方文档 CORS Support
跨域资源共享 CORS 详解
HTTP访问控制(CORS)
Cross-Origin Resource Sharing (CORS)
Same-origin policy
Nginx反向代理、CORS、JSONP等跨域请求解决方法总结
<!-- 拷贝配置文件到指定文件夹,例如:conf/ -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<executions>
<execution>
<!-- 绑定到生命周期的compile阶段,即执行compile的时候就执行该插件 -->
<phase>compile</phase>
<!-- 使用插件的copy-resources目标 -->
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<encoding>UTF-8</encoding>
<!--拷贝到构建目录conf文件夹下 -->
<outputDirectory>${project.build.directory}/conf</outputDirectory>
<resources>
<resource>
<!-- 需要拷贝的文件夹 -->
<directory>src/main/resources</directory>
<!-- 需要拷贝的文件 -->
<includes>
<include>*.properties</include>
<include>*.xml</include>
</includes>
<!-- 排除不用拷贝的文件 -->
<excludes>
<exclude>*.txt</exclude>
</excludes>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<!-- 拷贝依赖项到指定文件夹,例如:lib/ -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>
<!--拷贝到构建目录的lib文件夹下 -->
${project.build.directory}/lib
</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<!-- 设置主方法和classpath -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.6</version>
<executions>
<execution>
<goals>
<goal>jar</goal>
</goals>
<!-- 绑定到编译阶段 -->
<phase>compile</phase>
<configuration>
<!--排除某些配置文件,放在jar的外面,方面修改,-->
<!--【测试后发现这种写方法“src/main/resources/*”并不能排除文件,这里排除文件的根目录是classpath,不是项目根目录,】 -->
<excludes>
<exclude>**/*.xml</exclude>
<exclude>**/*.properties</exclude>
<exclude>**/*.txt</exclude>
</excludes>
<archive>
<!--自动添加META-INF/MANIFEST.MF -->
<manifest>
<addClasspath>true</addClasspath>
<!-- MANIFEST.MF文件里的classPath添加 lib/ 前缀,该插件并不会拷贝依赖jar包到lib文件夹下 -->
<classpathPrefix>lib/</classpathPrefix>
<mainClass>${main.class}</mainClass>
</manifest>
<manifestEntries>
<Class-Path>. conf/</Class-Path>
</manifestEntries>
</archive>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<mainClass>${main.class}</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>test.Main</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
Executable JAR
Resource Transformers
Selecting Contents for Uber JAR
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>1.5.8.RELEASE</version>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
<configuration>
<mainClass>test.Main</mainClass>
</configuration>
</plugin>
每个 Java 程序都有一个共同点,那就是它们都会用到集合。集合是编程根基,以至于我们不能从 RebelLabs 备忘清单中忽略掉它们。你必须要知道集合框架的实现细节、正确用法、如何选择正确的集合类型、它们可以做什么 以及什么时候应该使用第三方库 或者什么时候应该选择内置的 JDK 集合,这是个巨大的挑战。
但是,我们从来不走捷径,请记住下面这些我们已经处理过的话题:
无论如何,是无法在一张 A4 纸上充分的解释如此广泛的Java集合话题,但是我们一次又一次的尝试把最重要的信息囊括进去。在这篇博客中,我们会详细解释每一个决策背后的细节,Java 集合备忘清单如下:

我们还创建了一个交互式的问答流程,你可以回答这些问题来为你的数据选择合适的Java集合。点击 Enter 开始,Esc回到上一步:
Choosing the right Java collection
继续读下去以更好的了解 Java 集合类,以及何时该用它们。
你可能认为集合框架自始至终都是 JDK 的一部分。其实不是。集合是 JDK 最基础的一部分(任何编程语言都是这样的),但正确的使用它也是编程最难的地方之一。除此之外,使集合库变得简单、连贯、易于使用(我正在看 Scala)也是非常有挑战性的。所以 Java 集合库在 1998 年被 引入到 Java1.2 中,从那时起一直到现在。由于 Java 平台的核心价值是后向兼容,所以从那时起,集合就没有改变过。然而在最近的 Java8 中,语言已经发展到在不破坏后向兼容性的同时,也能增强集合接口了。
总而言之,Java 集合是一个非常全面的库,其包含的工具集类似于一个容器,几乎可以处理你可能需要的任何数据结构。让我们来看看有哪些集合可以使用,大致描述一下它们有什么特别之处,以及为什么要使用它们。
... 略 (XRebel 的广告部分)
在代码中选择需要的集合类型主要有两种方式。第一种最简单,但不总是有效的:
另一种方法需要你了解 你用到的集合的所有操作、你期望的性能、以及你打算保存的数据类型。虽然这样做需要下很大的功夫,但是了解这些可用的选项能帮助你做出更明智的选择。
有四种主要的 Java 集合类型。每种类型的实现都可以在相应的接口下找到。在开始深入研究之前,先了解一下两个 包装接口(umbrella interfaces):Iterable 和 Collection。你很少需要考虑这些,但是至少要知道它们是很重要的。Iterable 接口允许你获得一个迭代器(Iterator),并通过 next() 方法遍历获得元素序列。它可以用通过 for-each 这种循环语法糖来迭代元素:
for(E e: iterable) Collection 接口继承了 Iterable 接口,可以 添加、删除、检查元素是否存在等。然而,不同的实现往往会增加更具体的接口,这些接口是在不同的应用场景下设计出来的。下面是一些最常用的集合接口。
List 是一个有序集合。有些语言也称之为 序列(sequence),你可以认为这是一个可变长度的数组。可以在中间添加元素,使用索引访问或者替换元素。
毋庸置疑,List 是最常用的集合之一。然而,在只用过程中它几乎没有任何变化。是的,你在学校的时候肯定也学过那个可怕的链表,以及实现一个链表 和 如何访问它的头和尾。在实践中,在 99% 的情况下,你最好使用 ArrayList 就行了。
原因很简单,它消耗的内存很小,缓存也很友善,通常也比 JDK 中的 LinkedList 要快。其实你应该尽量不要使用 LinkedList。
如果需要创建并发访问列表,你就需要考虑 同步问题了。通常,这意味着你将会使用线程安全而且不可变的 CopyOnWriteArrayList。
如果你的数据会偶尔被其他线程修改但是对读的能要求很高 (读多写少的应用)。CopyOnWriteArrayList 就是你的不二之选。
常见方法有 引用计数法 和 可达性分析法。
每一个对象都维护一个引用计数器,当该对象被引用的时候,计数器加1,当失效时,计数器减1,当该对象没有被任何对象引用时,计数器为0,这时候认定为垃圾对象。
主流的Java虚拟机没有采用 引用计数法 来管理内存,其主要原因在于它很难解决对象之间相互循环引用的问题。
Java 判断对象是否存活使用的是 可达性分析法。
基本思路是通过一系列成为 “GC Root” 的对象作为起点,从这些起点开始向下搜索,搜索走过的路径称之为“引用链”,当一个对象到 GC Root 没有任何引用链相连时,即 GC Root 到该对象不可达,则认为该对象不可用。
- 虚拟机栈(栈用的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中 JNI 引用的对象
Eclipse documentation Garbage Collection Roots
如果一个对象被判定为不可达,这时候会再判断一下该对象是否有必要执行finalize()方法,如果没有该方法,或者方法已经被执行过,则没有必要被执行,直接标记为死亡,否则会把该对象放入 F-Queue 队列。如果该方法正常执行,则标记为死亡;如果在该方法内又重新把自己与引用链上的任何对象建立关联,则该对象会重新复活。
当判断出对象是否存活之后,接下来就开始进行垃圾回收(GC)。常见的 GC 算法有 拷贝 (copying)、标记-清除 (mark-sweep)、标记-整理 (mark-compact)。
拷贝算法的实现是将内存按块划分,进行一轮标记之后,会把存活的对象拷贝到另一块区域,原来的区域则一次性全部清除掉。
程序中大部分对象是“朝生夕死”的对象,大概有98%左右,复制的时候只用复制2%左右的对象到另一个空间,所以复制算法是一种效率很高的算法;复制的时候,对象新空间也是按照顺序排列的,没有内存碎片的问题。
HotSpot中,拷贝算法常用在 Eden→Survivor、Survivor1 ↔ Survivor2 之间相互拷贝、和 整个年轻代(Eden+Survivor)→ 老年代之间的复制。
该算法是把被标记为死亡的对象直接回收掉,导致结果就是会产生大量的内存缝隙。
如果新产生的对象大小小于缝隙的大小,则直接存放在缝隙空间中;如果新产生的对象大小很大,所有缝隙空间都不够分配,则该对象可能会创建失败,最常见的错误表现就是 OutOfMemory (OOM)。
复制算法的缺点是当对象存活率很高(例如老年代、持久代)的时候,该算法的效率就会变得很低,可以想象一下标记了一遍大部分对象都没有死亡,可能就需要复制大量的对象到新的空间;该算法还需要准备一份目标空间用于复制操作。
标记清除上面已经说过,会产生大量的内存缝隙,新产生的对象不好分配新的空间。
标记整理并不是直接直接清理掉死亡的对象,而是把存活的对象位置向前移动(相当于对缝隙进行压缩),最后把后面的大块空间一次性清理掉,避免缝隙的产生。其优点也是其缺点,移动对象进行空间压缩成本是很高的。
了解过上面几种常见 GC 算法之后,就会了解过,实际上每一种算法都有优点和缺点。分代实际上是根据对象存活周期的不同进行内存的划分,这样就可以根据不同年代的特点采用最适合的垃圾回收算法。
拓展阅读 Java虚拟机学习 - 垃圾收集算法
HotSpot 的垃圾收集器有 Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1。
启动参数指定 -server 或者 -client 即可,x64位虚拟机只支持 -server
新生代:Parallel Scavenge ,使用 复制算法
老年代:Serial Old,使用 标记整理算法
”=”表示参数的默认值,而”:=” 表明了参数被用户或者JVM赋值了。
$ java -XX:+PrintFlagsFinal -version | grep ":="
......
bool UseCompressedClassPointers := true {lp64_product}
bool UseCompressedOops := true {lp64_product}
bool UseParallelGC := true {product}
......
$ java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
吞吐量 = 运行用户代码时间/(运行用户代码时间 + GC时间)
虚拟机运行了100分钟,有一分钟在垃圾回收,那么 吞吐量为 99%
-XX:MaxGCPauseMillis=n
并行收集最大暂停时间
-XX:GCTimeRatio=n
GC时间占程序时间的百分比,公式为1/(1+n)
-XX:ParallelGCThreads=n
并行收集线程数
-XX:+UseAdaptiveSizePolicy
自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等;设置该选项之后,就不要再设置 -Xmn、-XX:SurvivorRatio、-XX:MaxTenuringThreshold 等选项了,但是可以设置 -Xms、-Xmx规定一下整个堆的大小
Parallel Scavenge没有使用原本HotSpot其它GC通用的那个GC框架,所以不能跟使用了那个框架的CMS搭配使用。就这么简单,不是什么算法/技术上的不兼容,纯粹是人为造成的
并发(concurrent)原指 同一段时间内交替执行,这里偏向于 用户线程和GC线程同时交替执行,或者并行运行在不同的CPU上;
并行(parallel)原指 同一时刻同时执行,这里偏向于 多个GC线程并行,用户线程等待。
基本上可以认为是的。
Major GC 主要描述的是在老年代的内存回收,触发老年代垃圾回收的其中一个原因是新生代在垃圾后将到达一定年龄的对象复制到老年代,实际上可以看出Major GC产生的之前多伴随着 Minor GC 的产生。
我们不应该去关心到底应该是叫 Major GC 还是 Full GC,这些术语无论是在 JVM 规范还是在垃圾收集研究论文中都没有正式的定义,大家应该关注当前的 GC 是否停止了所有应用程序的线程,还是能够并发的处理而不用停掉应用程序的线程。
-XX:ConcGCThreads=n
并发收集线程数,如果没有设置则为(ParallelGCThreads + 3)/4
-XX:CMSFullGCsBeforeCompaction
运行多少次CMS GC以后对内存空间进行压缩、整理
-XX:+UseCMSCompactAtFullCollection
可以对年老代的压缩,默认是打开的
-XX:CMSInitiatingOccupancyFraction
设置执行GC的阈值,如75,则占用空间到达75%的时候开始GC
这里有一些 Monica 提到的命令用于调整 G1GC。
-XX:G1HeapRegionSize=n 值是 2 的幂,范围是 1 MB 到 32 MB 之间。目标是根据最小的 Java 堆大小划分出约 2048 个区域-XX:MaxGCPauseMillis=200 GC可以暂停多长时间。 这只是个建议值,G1GC 暂停的时间会尽可能比这个值短。默认值是 200 毫秒-XX:G1HeapWastePercent=10 设置您愿意浪费的堆百分比。 垃圾越大, GC 在新区域分配对象时越快,而不是试图将这些空间浪费掉-XX:UseSerialGC = Serial + Serial Old
-XX:UseParNewGC = ParNew + Serial Old
-XX:UseConcMarkSweepGC = ParNew + CMS + Serial Old
-XX:UseParallelGC = Parallel Scavenge + Serial Old
-XX:UseParallelOldGC = Parallel Scavenge + Parallel Old
-XX:UseParallelOldGC = Parallel Scavenge + Parallel Old
-XX:UseConcMarkSweepGC = ParNew + CMS + Serial Old
-XX:+UseG1GC
Our Collectors
我们的垃圾收集器
虚拟机调优
JVM 垃圾回收算法
JVM实用参数(六) 吞吐量收集器
JVM实用参数(七)CMS收集器
《深入理解Java虚拟机:JVM高级特性与最佳实践》勘误
JVM之几种垃圾收集器简单介绍
本文主要是 深入理解Java虚拟机 第3章垃圾收集器与内存分配策略 的总结笔记
有人用 Github 的 Issues 作为博客,其满足一些需求
编写的时候也相对方便
缺点可能就是
总结来说,作为日常记录还是不错的。
为什么选择 Github 呢,实际上国内的 Coding、oscgit 等社区其实也都不错呀,可能只因为主观感受,这里感觉稍微纯净一点,不太喧嚣。
UML 是 Unified Modeling Language的缩写,又称统一建模语言。作为“语言”,其本质目的是为了便于交流,俗话说一图省胜千言。
以上分类摘录自 解析UML中五类UML模型图
个人感觉没必要把上面所有类型的图区分的特别明白,只要是在日常工作中(如 设计和分析阶段)能进行正常的交流,能理解别人所表达的意思,或者正确的表达自己的意思即可。
以下将主要介绍一些类图中相关的元素,因为里面的一些元素很相似,比较容易混淆。当看到别人的图的时候可能会出现理解上的偏差。打着好记性不如烂笔头的旗号,做了一下记录。以下截图中有些地方可能不符合标准,但是大体上应该不影响理解。

如上图,一个矩形分了三格:
属性和方法前民有三种符号对访问级别进行了描述:
+ 代表 public# 代表 protect- 代表 private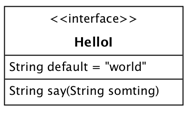
可以看出第一格多了一个 <<interface>>。在Java里,接口的定义只能是公共属性或者方法,所以这里省略了前面的描述符。
类图中类与类、接口 之间存在很多关系:
泛化即Java中的继承关系(类与类;接口与接口),在UML中用 空心三角 直线来表示:
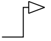
实现即 Java 中的 一个类实现一个接口,在UML中用 空心三角 虚线来表示:
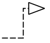
可以理解为在一个类中 import 了另一个类,该类不是作为一个属性存在,而是作为一个方法参数或者局部变量等,依赖是类与类之间最弱的关系。在UML中用 箭头 虚线来表示:
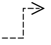
可以理解为一个类作为另一个类的属性,在UML中用 箭头 实线来表示,箭头可以是单向箭头 或者 双向箭头,箭头指向被包含的类:

可以在实线上加备注来描述数量上的关系
1..1:一对一
0..*:0对多
1..*:1对多
0..1:0对1
* :多对多
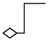
聚合与关联类似,语义上更强调可以分离,例如我有量车,我和车是可以分离的,在编码上可能表述为 Person 类里面有个 Car 的属性,在UML中用 箭头 实线 箭头的反方向是空心菱形来表示
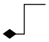
组合也与关联类似,语义上更强调不可分离,例如我有手有脚,我和我的身体是不可分离的,否则无法运行,在UML中用 箭头 实线 箭头的反方向是实心菱形来表示
除了以上几种常用的关系外,还有其他几种关系,这里不再说明,因为你可以通过在箭头上加描述信息来描述这种关系,随着技术的发展,你实际上也可以通过文字描述造出非 UML 标准外的关系,只要能达到便于沟通理解的目的即可。
个人感觉者三种关系在代码上基本上是一样,但是在语义上稍有不同:
快速浏览上面几个图,会发现一个规律
知乎讨论 UML 还有用吗?
文中截图使用 yEd 进行绘制
UML 软件工程组织 深入浅出UML类图
伯乐在线 Java利器之UML类图详解
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.