This project explores the concept of amortized variational inference (A-VI) within the realm of Bayesian probabilistic modeling, particularly focusing on its application in Variational Autoencoders (VAEs). The project aims to bridge the gap between theoretical insights and practical applications, demonstrating how A-VI can enhance inference efficiency in deep generative models.
Bayesian inference provides a principled approach for understanding uncertainty in machine learning models. However, classical methods like Markov Chain Monte Carlo (MCMC) are computationally expensive, especially for complex models or large datasets. Variational Inference (VI) offers a more scalable alternative by turning the inference problem into an optimization problem. This project delves into amortized variational inference, a technique that leverages deep neural networks to efficiently approximate posterior distributions.
- Variational Inference (VI): A method that approximates the intractable posterior distribution in Bayesian inference by optimizing a simpler, parameterized distribution.
- Amortization Gap: The discrepancy between the true posterior distribution and its approximation via variational inference. This gap arises from the use of a fixed function (e.g., a neural network) to approximate the posterior across all observations.
- Reparameterization Trick: A technique that allows gradients to be backpropagated through stochastic nodes, facilitating the optimization of variational objectives.
- Background: Introduction to Bayesian inference, the challenges with classical methods, and the basics of Variational Inference and the amortization gap.
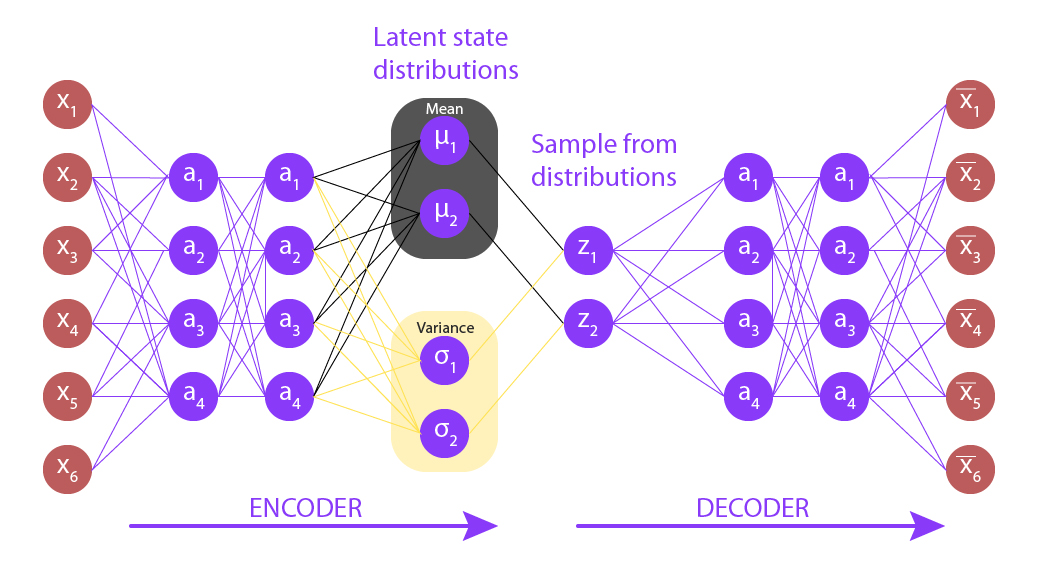
- Model Setup: Implementation details of the encoder and decoder components of a Variational Autoencoder (VAE), focusing on the neural network architectures used.
- Experiments: Description of the experimental setup, including data preprocessing, model training, and evaluation metrics.
- Results: Analysis of the model's performance, with a focus on the reconstruction accuracy and the computational efficiency of amortized inference.
- Conclusion: Summary of key findings, implications for the field of machine learning, and potential directions for future research.
- Amortized variational inference significantly reduces the computational burden associated with estimating posterior distributions, making it a viable option for complex models and large datasets.
- The architecture of the neural network (e.g., the width of layers) plays a crucial role in the model's ability to approximate the true posterior distribution.
- There is a trade-off between model complexity and computational efficiency, highlighting the importance of choosing the right model architecture for the task at hand.
This project opens up several avenues for future research, including exploring different neural network architectures for the encoder and decoder, investigating the impact of the amortization gap on model performance, and applying amortized variational inference to other types of generative models.
This project was created by Jordan Deklerk. Visit my website to see a full walk-through of this project.
For more details on the implementation and results, please refer to the Jupyter Notebook included in this repository.

