jingegebuguai / java-blog Goto Github PK
View Code? Open in Web Editor NEW关于Java学习的一些知识点
关于Java学习的一些知识点



网上有很多java源码的解读教程,我换一种方式以自己的认识来解读,不足之处还望见谅。
若是读者的java开发经验在一年以上,那么说明已经基本掌握了java源码的阅读条件。建议使用IDEA阅读源码,从JDK走起。也就是我们学的《数据结构和算法》Java版,如List接口和ArrayList、LinkedList实现,HashMap和TreeMap等。这些数据结构里也涉及到排序等算法,一举两得。
面试时,考官总喜欢问ArrayList和Vector的区别,你花10分钟读读源码,估计一辈子都忘不了。
读这些源码时,只需要读懂一些核心类即可,如和ArrayList类似的二三十个类,对于每一个类,也不一定要每个方法都读懂。像String有些方法已经到虚拟机层了(native方法),如hashCode方法。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
//这是一个字符数组,并且是 final 类型,用于存储字符串内容。从 fianl 关键字可以看出,String 的内容一旦被初始化后,其不能被修改的。
private final char value[];
//缓存字符串hash码
private int hash; // Default to 0
//Java 的序列化机制是通过在运行时判断类的 serialVersionUID 来验证版本一致性的。
private static final long serialVersionUID = -6849794470754667710L;
//字符串实例时被写入对象输出流的
private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0];
//构造函数若干
//具体实现方法若干
}
//该构造方法会创建空的字符序列,注意这个构造方法的使用
//因为创造不必要的字符串对象是不可变的。
public String() { this.value = "".value; }
//这里将直接将源 String 中的 value 和 hash 两个属性直接赋值给目标 String。
//因为 String 一旦定义之后是不可以改变的,所以也就不用担心改变源 String 的值会影响到目标 String 的值。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
//当我们使用字符数组创建 String 的时候,会用到 Arrays.copyOf 方法或 Arrays.copyOfRange方法。
//这两个方法是将原有的字符数组中的内容逐一的复制到 String 中的字符数组中。
//会创建一个新的字符串对象,随后修改的字符数组不影响新创建的字符串。
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
//在 Java 中,String 实例中保存有一个 char[] 字符数组,char[] 字符数组是以 unicode 码来存储的,String 和 char 为内存形式。
//分配包含数组参数的子数组中的字符的新的字符串。 参数offset是子数组的第一个代码点的索引,参数count指定子数组的长度。
//子数组的内容被转换为char; 随后修改数组不会影响新创建的字符串。
public String(char value[], int offset, int count) {
......
}
//分配由8位整数值数组的子数组构成的新的字符串
public String(byte ascii[], int hibyte, int offset, int count) {
......
}
public String(byte ascii[], int hibyte) { this(ascii, hibyte, 0, ascii.length); }
byte 是网络传输或存储的序列化形式,所以在很多传输和存储的过程中需要将 byte[] 数组和 String 进行相互转化。所以 String 提供了一系列重载的构造方法来将一个字符数组转化成 String,提到 byte[] 和 String 之间的相互转换就不得不关注编码问题。
//该构造方法是指通过 charset 来解码指定的 byte 数组,将其解码成 unicode 的 char[] 数组,构造成新的 String。
//这里的 bytes 字节流是使用 charset 进行编码的,想要将他转换成 unicode 的 char[] 数组,而又保证不出现乱码,那就要指定其解码方式
public String(byte bytes[], int offset, int length, String charsetName)
public String(byte bytes[], int offset, int length, Charset charset)
public String(byte bytes[], String charsetName)
public String(byte bytes[], Charset charset)
public String(byte bytes[], int offset, int length)
public String(byte bytes[])
StringBuffer 和 StringBuilder 也可以被当做构造 String 的参数。当然,这两个构造方法是很少用到的,因为当我们有了 StringBuffer 或者 StringBuilfer 对象之后可以直接使用他们的 toString 方法来得到 String。
关于效率问题,Java 的官方文档有提到说使用StringBuilder 的 toString 方法会更快一些,原因是 StringBuffer 的 toString 方法是 synchronized 的,在牺牲了效率的情况下保证了线程安全。
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
该方法和 String(char[] value) 有两点区别:
第一个区别:该方法多了一个参数:boolean share,其实这个参数在方法体中根本没被使用。注释说目前不支持 false,只使用 true。那可以断定,加入这个 share 的只是为了区分于 String(char[] value) 方法,不加这个参数就没办法定义这个函数,只有参数是不同才能进行重载。
第二个区别:具体的方法实现不同。我们前面提到过 String(char[] value) 方法在创建 String 的时候会用到 Arrays 的 copyOf 方法将 value 中的内容逐一复制到 String 当中,而这个 String(char[] value, boolean share) 方法则是直接将 value 的引用赋值给 String 的 value。那么也就是说,这个方法构造出来的 String 和参数传过来的 char[] value 共享同一个数组。
性能好:这个很简单,一个是直接给数组赋值(相当于直接将 String 的 value 的指针指向char[]数组),一个是逐一拷贝,当然是直接赋值快了。
节约内存:该方法之所以设置为 protected,是因为一旦该方法设置为公有,在外面可以访问的话,如果构造方法没有对 arr 进行拷贝,那么其他人就可以在字符串外部修改该数组,由于它们引用的是同一个数组,因此对 arr 的修改就相当于修改了字符串,那就破坏了字符串的不可变性。
安全的:对于调用他的方法来说,由于无论是原字符串还是新字符串,其 value 数组本身都是 String 对象的私有属性,从外部是无法访问的,因此对两个字符串来说都很安全。
//返回字符串长度
public int length() {
return value.length;
}
//判断字符串是否为空
public boolean isEmpty() {
return value.length == 0;
}
//返回字符串中第index+1个字符
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
//将字符串转换为字节数组
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, value, 0, value.length);
}
public boolean equals(Object anObject) {
//先判断是否为同一个对象,若是一个对象,直接返回true
if (this == anObject) {
return true;
}
//判断anObject是否属于String
if (anObject instanceof String) {
//转型
String anotherString = (String)anObject;
int n = value.length;
//比较两个数组的长度
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
//一一比较值是否相同
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
contentEquals((CharSequence) sb) 方法
contentEquals((CharSequence) sb) 分两种情况:
具体比较方式几乎和 equals 方法类似,先做“宏观”比较,在做“微观”比较。
public boolean equalsIgnoreCase(String anotherString) {
return (this == anotherString) ? true
: (anotherString != null)
&& (anotherString.value.length == value.length)
&& regionMatches(true, 0, anotherString, 0, value.length);
}
三目运算符加上&&替代if语句实现比较语句
package ThreadPool;
import com.sun.istack.internal.logging.Logger;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class ThreadPoolManage {
private static final Logger logger = Logger.getLogger(ThreadPoolManage.class);
private AtomicInteger threadId = new AtomicInteger(0);
private String prefix;
private int poolSiza;
private ThreadPoolExecutor threadPoolExecutor;
public ThreadPoolManage(int poolSiza, String prefix) {
this.poolSiza = poolSiza;
this.prefix = prefix;
}
/**
* 创建固定线程池
*/
public void buildThreadPool() {
logger.info("build threadPoll");
this.threadPoolExecutor = new ThreadPoolExecutor(poolSiza, poolSiza,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, prefix + threadId.getAndIncrement());
}
}
) {
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
printException(r, t);
}
private void printException(Runnable r, Throwable t) {
if (t == null && r instanceof Future<?>) {
try {
Future<?> future = (Future<?>) r;
if (future.isDone()) {
future.get();
}
} catch (CancellationException ce) {
t = ce;
} catch (ExecutionException ee) {
t = ee.getCause();
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
}
if (t != null) {
logger.warning(t.getMessage(), t);
}
}
};
}
public void closeThreadPool() {
logger.info("close thread pool");
threadPoolExecutor.shutdown();
try {
threadPoolExecutor.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
logger.warning(e.getMessage());
}
}
}
包含collection的构造函数ArrayList(Collection<? extends E> c);
ArrayList容量的设置,ensureCapacity(int minCapacity);
以及所以ArrayList函数。
最常用toArray()方法
// toArray(T[] contents)调用方式一
public static Integer[] vectorToArray1(ArrayList<Integer> v) {
Integer[] newText = new Integer[v.size()];
v.toArray(newText);
return newText;
}
// toArray(T[] contents)调用方式二。最常用!
public static Integer[] vectorToArray2(ArrayList<Integer> v) {
Integer[] newText = (Integer[])v.toArray(new Integer[0]);
return newText;
}
// toArray(T[] contents)调用方式三
public static Integer[] vectorToArray3(ArrayList<Integer> v) {
Integer[] newText = new Integer[v.size()];
Integer[] newStrings = (Integer[])v.toArray(newText);
return newStrings;
}
源码:
package java.util;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
// 序列版本号
private static final long serialVersionUID = 8683452581122892189L;
// 保存ArrayList中数据的数组
private transient Object[] elementData;
// ArrayList中实际数据的数量
private int size;
// ArrayList带容量大小的构造函数。
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
// 新建一个数组
this.elementData = new Object[initialCapacity];
}
// ArrayList构造函数。默认容量是10。
public ArrayList() {
this(10);
}
// 创建一个包含collection的ArrayList
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
// 将当前容量值设为 =实际元素个数
public void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (size < oldCapacity) {
elementData = Arrays.copyOf(elementData, size);
}
}
// 确定ArrarList的容量。
// 若ArrayList的容量不足以容纳当前的全部元素,设置 新的容量=“(原始容量x3)/2 + 1”
public void ensureCapacity(int minCapacity) {
// 将“修改统计数”+1
modCount++;
int oldCapacity = elementData.length;
// 若当前容量不足以容纳当前的元素个数,设置 新的容量=“(原始容量x3)/2 + 1”
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
// 添加元素e
public boolean add(E e) {
// 确定ArrayList的容量大小
ensureCapacity(size + 1); // Increments modCount!!
// 添加e到ArrayList中
elementData[size++] = e;
return true;
}
// 返回ArrayList的实际大小
public int size() {
return size;
}
// 返回ArrayList是否包含Object(o)
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
// 返回ArrayList是否为空
public boolean isEmpty() {
return size == 0;
}
// 正向查找,返回元素的索引值
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
// 反向查找,返回元素的索引值
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
// 反向查找(从数组末尾向开始查找),返回元素(o)的索引值
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
// 返回ArrayList的Object数组
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
// 返回ArrayList的模板数组。所谓模板数组,即可以将T设为任意的数据类型
public <T> T[] toArray(T[] a) {
// 若数组a的大小 < ArrayList的元素个数;
// 则新建一个T[]数组,数组大小是“ArrayList的元素个数”,并将“ArrayList”全部拷贝到新数组中
if (a.length < size)
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
// 若数组a的大小 >= ArrayList的元素个数;
// 则将ArrayList的全部元素都拷贝到数组a中。
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
// 获取index位置的元素值
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
}
// 设置index位置的值为element
public E set(int index, E element) {
RangeCheck(index);
E oldValue = (E) elementData[index];
elementData[index] = element;
return oldValue;
}
// 将e添加到ArrayList中
public boolean add(E e) {
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 将e添加到ArrayList的指定位置
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
ensureCapacity(size+1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
// 删除ArrayList指定位置的元素
public E remove(int index) {
RangeCheck(index);
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
// 删除ArrayList的指定元素
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
// 快速删除第index个元素
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
// 从"index+1"开始,用后面的元素替换前面的元素。
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 将最后一个元素设为null
elementData[--size] = null; // Let gc do its work
}
// 删除元素
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
// 便利ArrayList,找到“元素o”,则删除,并返回true。
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
// 清空ArrayList,将全部的元素设为null
public void clear() {
modCount++;
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
// 将集合c追加到ArrayList中
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacity(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
// 从index位置开始,将集合c添加到ArrayList
public boolean addAll(int index, Collection<? extends E> c) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: " + index + ", Size: " + size);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacity(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
// 删除fromIndex到toIndex之间的全部元素。
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// Let gc do its work
int newSize = size - (toIndex-fromIndex);
while (size != newSize)
elementData[--size] = null;
}
private void RangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
}
// 克隆函数
public Object clone() {
try {
ArrayList<E> v = (ArrayList<E>) super.clone();
// 将当前ArrayList的全部元素拷贝到v中
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}
// java.io.Serializable的写入函数
// 将ArrayList的“容量,所有的元素值”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// 写入“数组的容量”
s.writeInt(elementData.length);
// 写入“数组的每一个元素”
for (int i=0; i<size; i++)
s.writeObject(elementData[i]);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
// java.io.Serializable的读取函数:根据写入方式读出
// 先将ArrayList的“容量”读出,然后将“所有的元素值”读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject();
// 从输入流中读取ArrayList的“容量”
int arrayLength = s.readInt();
Object[] a = elementData = new Object[arrayLength];
// 从输入流中将“所有的元素值”读出
for (int i=0; i<size; i++)
a[i] = s.readObject();
}
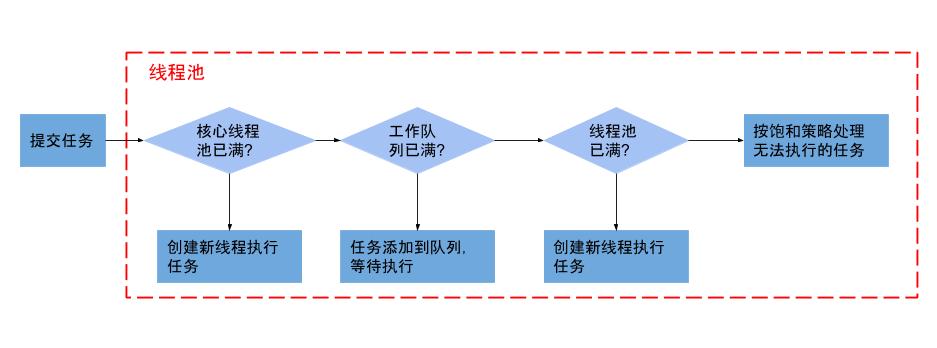
}如果不使用线程池,当并发的线程数量很多,并且每个线程执行很短时间就结束,这要频繁创建线程会造成大量资源消,降低系统效率。
合理利用线程池能够带来三个好处。第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。第二:提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。但是要做到合理的利用线程池,必须对其原理了如指掌。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
} public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
} public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
} public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}前三个线程池构造函数都使用的this()来调用其他构造函数,而真正初始化作用的构造函数是第四个,所以前三个构造函数是基于第四个构造器初始化的。
下面详细说明每个参数的含义:
corePollSize: 核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
maximumPoolSize: 线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
keepAliveTime: 线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。默认线程池的线程数大于线程池大小时起作用,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize,但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
workQueue: 一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响.
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
PriorityBlockingQueue:一个具有优先级得无限阻塞队列。
unit: 时间单位
threadFactory: 用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字
handler: 拒绝处理任务时的策略
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
再来看看以上的构造函数,可以发现四个构造函数在对threadFactory和handler的处理不同。
ExecutorService是JDK并发工具包提供的一个核心接口,相当于一个线程池,提供执行任务和管理生命周期的方法。AbstractExecutorService主要实现了这个接口。
处理后的源码如下:
public abstract class AbstractExecutorService implements ExecutorService {
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
//submit函数1
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
//submit函数2
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
//submit函数3
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,boolean timed, long nanos) throws InterruptedException, ExecutionException, TimeoutException {······}
public <T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)throws InterruptedException, ExecutionException, TimeoutException {······}
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)throws InterruptedException {
} 源码如下所示:
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
} public interface Executor {
void execute(Runnable command);
}
在分析之前先梳理一下各个类和接口的实现继承关系。
ThreadPoolExector——>(extends)AbstractExecutorService——>(implement)ExectorService——>(implement)Executor
现在我们来依次分析:
先看这个类的相关方法的使用与源码
volatile int runState;
static final int RUNNING = 0;
static final int SHUTDOWN = 1;
static final int STOP = 2;
static final int TERMINATED = 3; private final BlockingQueue<Runnable> workQueue; //任务缓存队列,用来存放等待执行的任务
private final ReentrantLock mainLock = new ReentrantLock(); //线程池的主要状态锁,对线程池状态(runState等)的改变都要使用这个锁
private final HashSet<Worker> workers = new HashSet<Worker>(); //用来存放工作集
private volatile long keepAliveTime; //线程存货时间
private volatile boolean allowCoreThreadTimeOut; //是否允许为核心线程设置存活时间
private volatile int corePoolSize; //核心池的大小(即线程池中的线程数目大于这个参数时,提交的任务会被放进任务缓存队列)
private volatile int maximumPoolSize; //线程池最大能容忍的线程数
private volatile int poolSize; //线程池中当前的线程数
private volatile RejectedExecutionHandler handler; //任务拒绝策略
private volatile ThreadFactory threadFactory; //线程工厂,用来创建线程
private int largestPoolSize; //用来记录线程池中曾经出现过的最大线程数
private long completedTaskCount; //用来记录已经执行完毕的任务个数 //初始化核心线程池一个线程
public boolean prestartCoreThread() {
return addIfUnderCorePoolSize(null); //注意传进去的参数是null
}
//初始化核心线程池所有线程
public int prestartAllCoreThreads() {
int n = 0;
while (addIfUnderCorePoolSize(null))//注意传进去的参数是null
++n;
return n;
}首先是Executor接口中的execute的方法,为核心方法。这个方法主要在ThreadPoolExecutor中实现,这个方法可以向线程池提交一个任务,交由线程池去执行。源码如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//获取ctl,主线程控制状态ctl是包装两个概念的原子整数,其中workerCount指代有效线程数,runState指代线程是运行还是停止等。
int c = ctl.get();
//保证增加工作线程时,ctl可以实时更新。
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//保证任务可以在新线程或合并线程中运行
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
} 从传入的参数可知它是执行的实现Runnable接口的线程。
这个方法主要是有序关闭线程,先前提交的任务将会执行,但不会再接受新任务。一般执行关闭线程池任务主要使用shutdown()方法。
public void shutdown() {
//声明一个重入锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
//关闭线程
try {
//确保有权限关闭线程
checkShutdownAccess();
//将运行状态转化为跟定目标
advanceRunState(SHUTDOWN);
//中断线程,等待未执行的任务
interruptIdleWorkers();
onShutdown();
} finally {
mainLock.unlock();
}
tryTerminate();
}中断所有已经执行的任务,并且不接受新的任务,源码与方法shutdown()类似。不同点是ShutdownNow()遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。shutdownNow会首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
只要调用了这两个关闭方法的其中一个,isShutdown方法就会返回true。判断是否在关闭线程池。
public boolean isShutdown() {
return ! isRunning(ctl.get());
}
```java
#### isTerminated()方法分析
当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。
```java
public boolean isTerminated() {
return runStateAtLeast(ctl.get(), TERMINATED);
}移除线程池中正在执行的任务,线程未执行的话则不执行该方法。
public boolean remove(Runnable task) {
boolean removed = workQueue.remove(task);
tryTerminate();
return removed;
}删除线程池中所有已经被取消的任务,用于回收存储回收操作。
public void purge() {
final BlockingQueue<Runnable> q = workQueue;
try {
Iterator<Runnable> it = q.iterator();
while (it.hasNext()) {
Runnable r = it.next();
if (r instanceof Future<?> && ((Future<?>)r).isCancelled())
it.remove();
}
} catch (ConcurrentModificationException fallThrough) {
for (Object r : q.toArray())
if (r instanceof Future<?> && ((Future<?>)r).isCancelled())
q.remove(r);
}
tryTerminate();
}用于返回当前线程池存在的线程数量
public int getPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
return runStateAtLeast(ctl.get(), TIDYING) ? 0
: workers.size();
} finally {
mainLock.unlock();
}
}返回正在执行任务的线程数量
public int getActiveCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int n = 0;
for (Worker w : workers)
if (w.isLocked())
++n;
return n;
} finally {
mainLock.unlock();
}
}返回线程池中曾经创建过的线程最大数量。通过这个数据可以知道线程池是否满过。如等于线程池的最大大小,则表示线程池曾经满了。
public int getLargestPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
return largestPoolSize;
} finally {
mainLock.unlock();
}
}返回计划任务数量的估计值(已经执行完的任务数+正在执行的任务数+工作队列等待的线程数)。
public long getTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//已经完成的任务数
long n = completedTaskCount;
//加上正在线程池执行的任务数
for (Worker w : workers) {
n += w.completedTasks;
if (w.isLocked())
++n;
}
//再加上工作队列中等待的任务数
return n + workQueue.size();
} finally {
mainLock.unlock();
}
}返回已经完成的任务数,其实是已完成的加上正执行的任务数。源码和getTaskCount()基本类似。
返回线程池的相关信息
public String toString() {
long ncompleted;
int nworkers, nactive;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
ncompleted = completedTaskCount;
nactive = 0;
nworkers = workers.size();
for (Worker w : workers) {
ncompleted += w.completedTasks;
if (w.isLocked())
++nactive;
}
} finally {
mainLock.unlock();
}
int c = ctl.get();
String rs = (runStateLessThan(c, SHUTDOWN) ? "Running" :
(runStateAtLeast(c, TERMINATED) ? "Terminated" :
"Shutting down"));
return super.toString() +
"[" + rs +
", pool size = " + nworkers +
", active threads = " + nactive +
", queued tasks = " + workQueue.size() +
", completed tasks = " + ncompleted +
"]";
} public class Test {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(5));
for(int i=0;i<15;i++){
MyTask myTask = new MyTask(i);
executor.execute(myTask);
System.out.println("线程池中线程数目:"+executor.getPoolSize()+",队列中等待执行的任务数目:"+
executor.getQueue().size()+",已执行玩别的任务数目:"+executor.getCompletedTaskCount());
}
executor.shutdown();
}
}
class MyTask implements Runnable {
private int taskNum;
public MyTask(int num) {
this.taskNum = num;
}
@Override
public void run() {
System.out.println("正在执行task "+taskNum);
try {
Thread.currentThread().sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("task "+taskNum+"执行完毕");
}
}在java doc中,并不提倡我们直接使用ThreadPoolExecutor,而是使用Executors类中提供的几个静态方法来创建线程池:
Executors.newCachedThreadPool(); //创建一个缓冲池,缓冲池容量大小为Integer.MAX_VALUE
Executors.newSingleThreadExecutor(); //创建容量为1的缓冲池
Executors.newFixedThreadPool(int); //创建固定容量大小的缓冲池
具体实现如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}newFixedThreadPool创建的线程池corePoolSize和maximumPoolSize值是相等的,它使用的LinkedBlockingQueue;
newSingleThreadExecutor将corePoolSize和maximumPoolSize都设置为1,也使用的LinkedBlockingQueue;
newCachedThreadPool将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,使用的SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。
如果线程池过大,那么大量的线程将在相对很少的CPU和内存资源上发生竞争,如果线程池过小,那么会导致许多空闲的处理器无法执行工作,从而降低吞吐率。
NCPU是系统处理器的数量
如果是CPU密集型任务,就需要尽量压榨CPU,参考值可以设为 NCPU+1
如果是IO密集型任务,参考值可以设置为2*NCPU
当然,这只是一个参考值,具体的设置还需要根据实际情况进行调整,比如可以先将线程池大小设置为参考值,再观察任务运行情况和系统负载、资源利用率来进行适当调整。
可以说并发是Java开发工程师面试时最常见的面试题了,关于并发的书籍也有很多,比如Java并发编程实战,Java并发编程艺术等。下面的几篇文章目的用最浅显的内容来解释并发的基础内容、并发的三大特性、线程池、并发容器、锁机制、相关源码分析等内容。并且会在每一篇章最后总结出常见的面试题。
这可以说是操作系统中的一块问题,也是Java并发编程的开始。首先来看看基本概念:
如果实在无法理解,可以去看看阮一峰老师的解释:
一个比较有趣的进程,线程的解释
二者区别:
二者相同点:
执行阶段:创建,就绪,运行,阻塞,终止。
通常运行一个java程序,就会有一个线程立即运行,这个线程就是主线程。
尽管主线程在程序启动时自动创建,但它可以由一个Thread对象控制。为此,你必须调用方法currentThread()获得它的一个引用,currentThread()是Thread类的公有的静态成员。它的通常形式如下:
static Thread currentThread( )
该方法返回一个调用它的线程的引用。一旦你获得主线程的引用,你就可以像控制其他线程那样控制主线程。
class CurrentThreadDemo {
public static void main(String args[]) {
Thread t = Thread.currentThread();
System.out.println("Current thread: " + t);
// change the name of the thread
t.setName("My Thread");
System.out.println("After name change: " + t);
try {
for(int n = 5; n > 0; n--) {
System.out.println(n);
Thread.sleep(1000);
}
} catch (InterruptedException e) {
System.out.println("Main thread interrupted");
}
}
}输出如下:
Current thread: Thread[main,5,main]
After name change: Thread[My Thread,5,main]
5
4
3
2
1
我们输出的线程显示顺序依次是[线程名称,优先级,组的名称]。主线程名称默认为main,优先级为5,main为组的名称。
我们可以用setName()设置线程的名称,用getName()获取线程的名称。
final void setName(String threadName)
final String getName()
## Thread类
class testThread extend Thread{
private String name;
public testThread(){
this.name = name;
}
public void run(){
for(int i=0;i<5;i++){
System.out.println(name+"running: "+i);
}try{
sleep((int) Math.random()*10);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
public class Main{
public static void main(String[] args){
testThread thread_1 = new testThread("A");
testThread thread_2 = new testThread("B");
thread_1.start();
thread_2.start();
}
}运行结果如下:
B running: 0
A running: 0
B running: 1
B running: 2
A running: 1
B running: 3
A running: 2
A running: 3
A running: 4
B running: 4
在start()方法后,并不是立即执行多线程代码,而是使线程进入可运行状态(Runnable),何时运行由操作系统决定。由于代码执行时乱序的,所以我们要加上线程机制。
import static java.lang.Thread.sleep;
class testThread implements Runnable{
private String name;
public testThread(String name){
this.name = name;
}
public void run(){
for (int i=0;i<5;i++){
System.out.println(name+" running: "+i);
}try{
Thread.sleep((int)Math.random()*10);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
public class Main{
public static void main(String[] args) {
testThread thread_1 = new testThread("C");
testThread thread_2 = new testThread("D");
new Thread(thread_1).start();
new Thread(thread_2).start();
}
}运行结果:
C running: 0
C running: 1
C running: 2
C running: 3
C running: 4
D running: 0
D running: 1
D running: 2
D running: 3
D running: 4
在启动线程时,需要先通过Thread类的构造方法Thread类的构造方法Thread构造出对象,然后调用Thread对象的start()方法来运行多线程代码。
注意Thread和Runnable之间代码具有细微的差别,但是二者背后的差距很大。
实现Runnable接口比继承Thread类所具有的优势:
1):适合多个相同的程序代码的线程去处理同一个资源
2):可以避免java中的单继承的限制
3):增加程序的健壮性,代码可以被多个线程共享,代码和数据独立
4):线程池只能放入实现Runable或callable类线程,不能直接放入继承Thread的类
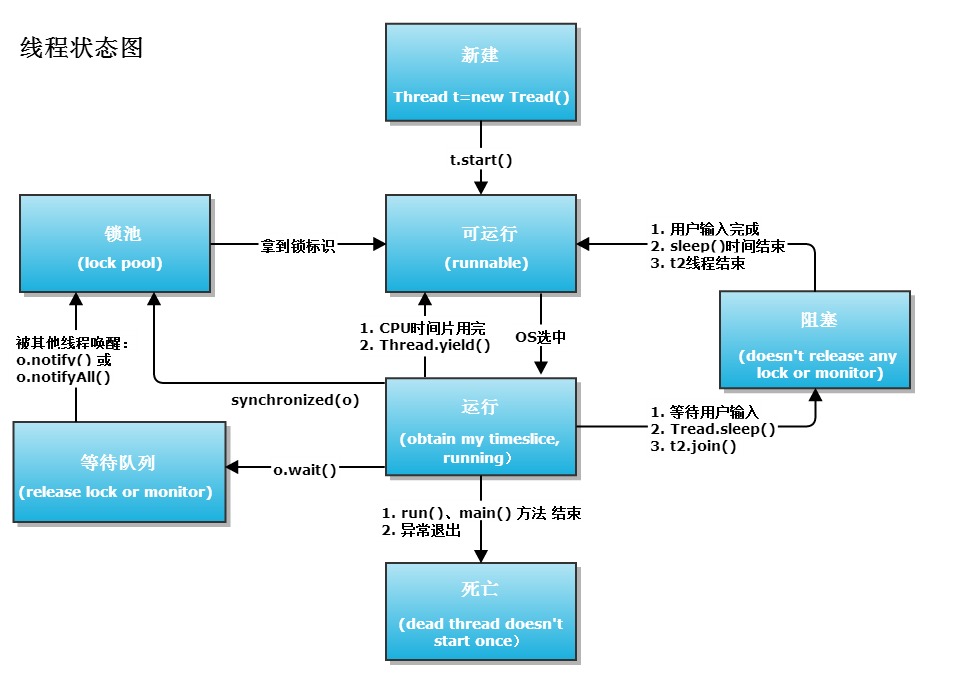
新建(new):新创建了一个线程对象。
可运行(runnable):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取cpu 的使用权 。
运行(running):可运行状态(runnable)的线程获得了cpu 时间片(timeslice) ,执行程序代码。
阻塞(block):阻塞状态是指线程因为某种原因放弃了cpu 使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有机会再次获得cpu timeslice 转到运行(running)状态。阻塞的情况分三种:
(一). 等待阻塞:运行(running)的线程执行o.wait()方法,JVM会把该线程放入等待队列(waitting queue)中。
(二). 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
(三). 其他阻塞:运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
最简单的一个函数,作用是在指定的毫秒数内瓤当前正在执行的线程进入休眠,也就是进入阻塞状态。另外它没有对象锁这个概念。
join是Thread类的一个方法,启动线程后直接调用,即join()的作用是:“等待该线程终止”,这里需要理解的就是该线程是指的主线程等待子线程的终止。也就是在子线程调用了join()方法后面的代码,只有等到子线程结束了才能执行。
在很多情况下,主线程生成并起动了子线程,如果子线程里要进行大量的耗时的运算,主线程往往将于子线程之前结束,但是如果主线程处理完其他的事务后,需要用到子线程的处理结果,也就是主线程需要等待子线程执行完成之后再结束,这个时候就要用到join()方法了。
不加join。
看如下示例(不加join函数的情况):
import static java.lang.Thread.sleep;
class testThread implements Runnable{
private String name;
public testThread(String name){
this.name = name;
}
public void run(){
System.out.println(Thread.currentThread().getName()+" 线程开始运行");
for(int i=0;i<5;i++) {
System.out.println(name + " running " + i);
try {
sleep((int) Math.random() * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName()+" 线程运行结束");
}
}
public class Main{
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName()+ " 主线程开始运行");
new Thread(new testThread("E")).start();
new Thread(new testThread("F")).start();
System.out.println(Thread.currentThread().getName()+ " 主线程运行结束");
}
}运行结果如下:
main 主线程开始运行
main 主线程运行结束
Thread-0 线程开始运行
Thread-1 线程开始运行
E running 0
F running 0
E running 1
F running 1
E running 2
F running 2
E running 3
F running 3
E running 4
F running 4
Thread-0 线程运行结束
Thread-1 线程运行结束
我们想让主线程最后执行完,下面再看看加上join()的情况:
import static java.lang.Thread.sleep;
class testThread implements Runnable{
private String name;
public testThread(String name){
this.name = name;
}
public void run(){
System.out.println(Thread.currentThread().getName()+" 线程开始运行");
for(int i=0;i<5;i++) {
System.out.println(name + " running " + i);
try {
sleep((int) Math.random() * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName()+" 线程运行结束");
}
}
public class Main{
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName()+ " 主线程开始运行");
Thread thread_1 = new Thread(new testThread("E"));
Thread thread_2 = new Thread(new testThread("F"));
thread_1.start();
thread_2.start();
try{
thread_1.join();
}catch (InterruptedException e){
e.printStackTrace();
}
try{
thread_2.join();
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+ " 主线程运行结束");
}
}运行结果如下:
main 主线程开始运行
Thread-0 线程开始运行
E running 0
Thread-1 线程开始运行
F running 0
E running 1
F running 1
E running 2
F running 2
E running 3
F running 3
E running 4
F running 4
Thread-0 线程运行结束
Thread-1 线程运行结束
main 主线程运行结束
作用是暂停当前的执行的线程对象,开始执行其他线程。
需要注意的是yield()是让当前运行状态进入到可运行状态,而非阻塞状态,实际情况下,我们并无法保证yield()完美的完成让步目的,即使当前线程让步了,根据优先级,该线程还可能继续被选中,继续执行该线程。由于可控性差的原因,建议尽量少用yield()函数。
sleep()和yield()的区别:
sleep()和yield()的区别):sleep()使当前线程进入停滞状态,所以执行sleep()的线程在指定的时间内肯定不会被执行;yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
sleep 方法使当前运行中的线程睡眼一段时间,进入不可运行状态,这段时间的长短是由程序设定的,yield 方法使当前线程让出 CPU 占有权,但让出的时间是不可设定的。实际上,yield()方法对应了如下操作:先检测当前是否有相同优先级的线程处于同可运行状态,如有,则把 CPU 的占有权交给此线程,否则,继续运行原来的线程。所以yield()方法称为“退让”,它把运行机会让给了同等优先级的其他线程
另外,sleep 方法允许较低优先级的线程获得运行机会,但 yield() 方法执行时,当前线程仍处在可运行状态,所以,不可能让出较低优先级的线程些时获得 CPU 占有权。在一个运行系统中,如果较高优先级的线程没有调用 sleep 方法,又没有受到 I\O 阻塞,那么,较低优先级线程只能等待所有较高优先级的线程运行结束,才有机会运行。
wait()和notify()必须和synchronized一起使用,二者针对对象进行操作。wait()必须在同步代码块中调用,调用wait()的线程会等待,知道其他线程调用了notify()方法之后,该线程才会被唤醒。被唤醒并不意味着立即获得对象锁,需要等待两件事的发生:
import java.util.concurrent.TimeUnit;
public class Main{
public static Object object = new Object();
static class testThread_1 implements Runnable{
@Override
public void run()
{
synchronized(object)
{
System.out.println(Thread.currentThread().getName()+" running.");
try
{
object.wait();
}
catch (InterruptedException e)
{
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+" get the lock.");
}
}
}
static class testThread_2 implements Runnable{
@Override
public void run() {
synchronized (object){
System.out.println(Thread.currentThread().getName()+ " running");
object.notify();
System.out.println(Thread.currentThread().getName()+ " is invoked");
System.out.println(Thread.currentThread().getName()+ "release the lock");
}
}
}
public static void main(String[] args)throws InterruptedException {
new Thread(new testThread_1()).start();
TimeUnit.SECONDS.sleep(1);
new Thread(new testThread_2()).start();
}
}运行结果如下:
Thread-0 running.
Thread-1 running
Thread-1 is invoked
Thread-1release the lock
Thread-0 get the lock.
这一块基本都是Java入门书籍中都会出现的知识点,当然真的是入门。其中,Thread类和Runnable接口之间的区别是面试最常见的题目。线程同步部分在后面的章节结合synchronized一起叙述。下面一个章节将结合Java并发编程实战这本书来谈谈并发三大特性的相关机制和volatile的相关基础。
在面向对象领域由于抽象的概念在问题领域没有对应的具体概念,所以用以表征抽象概念的抽象类是不能实例化的。
同时,抽象类体现了数据抽象的**,是实现多态的一种机制。它定义了一组抽象的方法,至于这组抽象方法的具体表现形式有派生类来实现。同时抽象类提供了继承的概念,它的出发点就是为了继承,否则它没有存在的任何意义。所以说定义的抽象类一定是用来继承的,同时在一个以抽象类为节点的继承关系等级链中,叶子节点一定是具体的实现类。(不知这样理解是否有错!!!高手指点….)
在使用抽象类时需要注意几点:
抽象类
public abstract class bird{
//定义抽象方法
public void abstract fly();
//定义普通方法
public void method(){
//实现
}
}
接口
interface bird{
public void fly();
//默认为public
void method();
//默认为public static final
name = "xiaoniao";
}
上面只是从语法层次和编程角度来区分它们之间的关系,这些都是低层次的,要真正使用好抽象类和接口,我们就必须要从较高层次来区分了。只有从设计理念的角度才能看出它们的本质所在。一般来说他们存在如下三个不同点:
1、 抽象层次不同。抽象类是对类抽象,而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
2、 跨域不同。抽象类所跨域的是具有相似特点的类,而接口却可以跨域不同的类。我们知道抽象类是从子类中发现公共部分,然后泛化成抽象类,子类继承该父类即可,但是接口不同。实现它的子类可以不存在任何关系,共同之处。例如猫、狗可以抽象成一个动物类抽象类,具备叫的方法。鸟、飞机可以实现飞Fly接口,具备飞的行为,这里我们总不能将鸟、飞机共用一个父类吧!所以说抽象类所体现的是一种继承关系,要想使得继承关系合理,父类和派生类之间必须存在"is-a" 关系,即父类和派生类在概念本质上应该是相同的。对于接口则不然,并不要求接口的实现者和接口定义在概念本质上是一致的, 仅仅是实现了接口定义的契约而已。
3、 设计层次不同。对于抽象类而言,它是自下而上来设计的,我们要先知道子类才能抽象出父类,而接口则不同,它根本就不需要知道子类的存在,只需要定义一个规则即可,至于什么子类、什么时候怎么实现它一概不知。比如我们只有一个猫类在这里,如果你这是就抽象成一个动物类,是不是设计有点儿过度?我们起码要有两个动物类,猫、狗在这里,我们在抽象他们的共同点形成动物抽象类吧!所以说抽象类往往都是通过重构而来的!但是接口就不同,比如说飞,我们根本就不知道会有什么东西来实现这个飞接口,怎么实现也不得而知,我们要做的就是事前定义好飞的行为接口。所以说抽象类是自底向上抽象而来的,接口是自顶向下设计出来的。
该章节需首先掌握hash表的数据结构相关知识。
HashMap的底层主要是基于数组和链表来实现的,它之所以有相当快的查询速度主要是因为它是通过计算散列码来决定存储的位置。HashMap中主要是通过key的hashCode来计算hash值的,只要hashCode相同,计算出来的hash值就一样。如果存储的对象对多了,就有可能不同的对象所算出来的hash值是相同的,这就出现了所谓的hash冲突。学过数据结构的同学都知道,解决hash冲突的方法有很多,HashMap底层是通过链表来解决hash冲突的。
下面一幅图,形象的反映出HashMap的数据结构:数组加链表实现
//默认的初始容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
//存储数据的Node数组,长度是2的幂。
transient Node<K,V>[] table;
//keyset 方法要返回的结果
transient Set<Map.Entry<K,V>> entrySet;
//map中保存的键值对的数量
transient int size;
//hashmap 对象被修改的次数
transient int modCount;
// 容量乘以装载因子所得结果,如果key-value的 数量等于该值,则调用resize方法,扩大容量,同时修改threshold的值。
int threshold;
//装载因子
final float loadFactor; 使用指定的初始容量和默认装载因子初始化HashMap,其中初始容量只能是2的次方数。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}HashMap 内部的 Node 数组默认的大小是16,假设有100万个元素,那么最好的情况下每个 hash 桶里都有62500个元素,这时get(),put(),remove()等方法效率都会降低。为了解决这个问题,HashMap 提供了自动扩容机制,当元素个数达到数组大小 loadFactor 后会扩大数组的大小,在默认情况下,数组大小为16,loadFactor 为0.75,也就是说当 HashMap 中的元素超过16乘以0.75=12时,会把数组大小扩展为2*16=32,并且重新计算每个元素在新数组中的位置。
HashMap存储结构
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
} //计算出hash值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
} public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* key的hash值
* key
* value
* onlyIfAbsent如果是true,则不修改已存在的value值
* true
* return value值,if none ->null
**/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断table是否初始化,若未初始化,使用resize()初始化table容量,并设置threshold值
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据hash值定位数组索引,如果对应的数组索引无值,调用newNode()方法,创建Node结点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//若是hash值和key值都相等,则更新相应结点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//添加treeNode结点类型的键值对
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
创建新Node,并添加到链表尾部
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//更新容量和threshold
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}Hashtable,ConcurrentHashMap
,Synchronized Map
//Hashtable
Map<String, String> hashtable = new Hashtable<>();
//synchronizedMap
Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>());
//ConcurrentHashMap
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
HashTable 源码中是使用 synchronized 来保证线程安全的,比如下面的 get 方法和 put 方法:
public synchronized V get(Object key) {
···
}
public synchronized V put(K key, V value) {
···
}
http://www.cnblogs.com/dolphin0520/p/3932905.html
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
// 省略其他方法
}其中ConcurrentHashMap性能最高
使用非阻塞队列的时候有一个很大问题就是:它不会对当前线程产生阻塞,那么在面对类似消费者-生产者的模型时,就必须额外地实现同步策略以及线程间唤醒策略,这个实现起来就非常麻烦。但是有了阻塞队列就不一样了,它会对当前线程产生阻塞,比如一个线程从一个空的阻塞队列中取元素,此时线程会被阻塞直到阻塞队列中有了元素。当队列中有元素后,被阻塞的线程会自动被唤醒(不需要我们编写代码去唤醒)。这样提供了极大的方便性。
自从Java 1.5之后,在java.util.concurrent包下提供了若干个阻塞队列,主要有以下几个:
ArrayBlockingQueue:基于数组实现的一个阻塞队列,在创建ArrayBlockingQueue对象时必须制定容量大小。并且可以指定公平性与非公平性,默认情况下为非公平的,即不保证等待时间最长的队列最优先能够访问队列。
LinkedBlockingQueue:基于链表实现的一个阻塞队列,在创建LinkedBlockingQueue对象时如果不指定容量大小,则默认大小为Integer.MAX_VALUE。
PriorityBlockingQueue:以上2种队列都是先进先出队列,而PriorityBlockingQueue却不是,它会按照元素的优先级对元素进行排序,按照优先级顺序出队,每次出队的元素都是优先级最高的元素。注意,此阻塞队列为无界阻塞队列,即容量没有上限(通过源码就可以知道,它没有容器满的信号标志),前面2种都是有界队列。
DelayQueue:基于PriorityQueue,一种延时阻塞队列,DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue也是一个无界队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
1.非阻塞队列中的几个主要方法:
add(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则会抛出异常;
remove():移除队首元素,若移除成功,则返回true;如果移除失败(队列为空),则会抛出异常;
offer(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则返回false;
poll():移除并获取队首元素,若成功,则返回队首元素;否则返回null;
peek():获取队首元素,若成功,则返回队首元素;否则返回null
对于非阻塞队列,一般情况下建议使用offer、poll和peek三个方法,不建议使用add和remove方法。因为使用offer、poll和peek三个方法可以通过返回值判断操作成功与否,而使用add和remove方法却不能达到这样的效果。注意,非阻塞队列中的方法都没有进行同步措施。
2.阻塞队列中的几个主要方法:
阻塞队列包括了非阻塞队列中的大部分方法,上面列举的5个方法在阻塞队列中都存在,但是要注意这5个方法在阻塞队列中都进行了同步措施。除此之外,阻塞队列提供了另外4个非常有用的方法:
put(E e)
take()
offer(E e,long timeout, TimeUnit unit)
poll(long timeout, TimeUnit unit)
put方法用来向队尾存入元素,如果队列满,则等待;
take方法用来从队首取元素,如果队列为空,则等待;
offer方法用来向队尾存入元素,如果队列满,则等待一定的时间,当时间期限达到时,如果还没有插入成功,则返回false;否则返回true;
poll方法用来从队首取元素,如果队列空,则等待一定的时间,当时间期限达到时,如果取到,则返回null;否则返回取得的元素;
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
private static final long serialVersionUID = -817911632652898426L;
/** The queued items */
private final E[] items;
/** items index for next take, poll or remove */
private int takeIndex;
/** items index for next put, offer, or add. */
private int putIndex;
/** Number of items in the queue */
private int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
*/
/** Main lock guarding all access */
private final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
}
```
可以看出,ArrayBlockingQueue中用来存储元素的实际上是一个数组,takeIndex和putIndex分别表示队首元素和队尾元素的下标,count表示队列中元素的个数。
lock是一个可重入锁,notEmpty和notFull是等待条件。
下面看一下ArrayBlockingQueue的构造器,构造器有三个重载版本:
public ArrayBlockingQueue(int capacity) {
}
public ArrayBlockingQueue(int capacity, boolean fair) {
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
}
第一个构造器只有一个参数用来指定容量,第二个构造器可以指定容量和公平性,第三个构造器可以指定容量、公平性以及用另外一个集合进行初始化。
然后看它的两个关键方法的实现:put()和take():
```java
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
final E[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
try {
while (count == items.length)
notFull.await();
} catch (InterruptedException ie) {
notFull.signal(); // propagate to non-interrupted thread
throw ie;
}
insert(e);
} finally {
lock.unlock();
}
}从put方法的实现可以看出,它先获取了锁,并且获取的是可中断锁,然后判断当前元素个数是否等于数组的长度,如果相等,则调用notFull.await()进行等待,如果捕获到中断异常,则唤醒线程并抛出异常。
当被其他线程唤醒时,通过insert(e)方法插入元素,最后解锁。
我们看一下insert方法的实现:
java private void insert(E x) { items[putIndex] = x; putIndex = inc(putIndex); ++count; notEmpty.signal(); }
它是一个private方法,插入成功后,通过notEmpty唤醒正在等待取元素的线程。
下面是take()方法的实现:
java public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { try { while (count == 0) notEmpty.await(); } catch (InterruptedException ie) { notEmpty.signal(); // propagate to non-interrupted thread throw ie; } E x = extract(); return x; } finally { lock.unlock(); } }
跟put方法实现很类似,只不过put方法等待的是notFull信号,而take方法等待的是notEmpty信号。在take方法中,如果可以取元素,则通过extract方法取得元素,下面是extract方法的实现:
private E extract() {
final E[] items = this.items;
E x = items[takeIndex];
items[takeIndex] = null;
takeIndex = inc(takeIndex);
--count;
notFull.signal();
return x;
}跟insert方法也很类似。
其实从这里大家应该明白了阻塞队列的实现原理,事实它和我们用Object.wait()、Object.notify()和非阻塞队列实现生产者-消费者的思路类似,只不过它把这些工作一起集成到了阻塞队列中实现。
HashMap和HashTable都是通过数组和链表实现的。
增删改查操作都需要先计算hash值,根据hash和table.length计算出index的具体位置(table的下标),然后再进行相关操作。
HashMap初始化变量如下
//默认初始容量为16
static final int DEFAULT_INITIAL_CAPACITY = 16;
//HashMap最大容量
static final int MAXIMUM_CAPACITY = 1<<30;
//默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75;
//默认存储数据的数组
transient Entry[] table;
构造函数
HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
//设置临界阙值
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
put和get方法原理:
HashMap先对为null值得key进行特殊处理,放到table[0]的位置。put是先计算hash值,再和table.length进行取模计算得到index,将key放到table[index]的位置。当table[index]已存在其它元素时,会在table[index]位置形成一个链表,将新添加的元素放在table[index],原来的元素通过Entry的next进行链接,这样以链表形式解决hash冲突问题,当元素数量达到临界值(capactiyfactor)时,则进行扩容,是table数组长度变为table.length2。
两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全
Hashtable的实现方法里面都添加了synchronized关键字来确保线程同步,因此相对而言HashMap性能会高一些,我们平时使用时若无特殊需求建议使用HashMap,在多线程环境下若使用HashMap需要使用Collections.synchronizedMap()方法来获取一个线程安全的集合(Collections.synchronizedMap()实现原理是Collections定义了一个SynchronizedMap的内部类,这个类实现了Map接口,在调用方法时使用synchronized来保证线程同步,当然了实际上操作的还是我们传入的HashMap实例,简单的说就是Collections.synchronizedMap()方法帮我们在操作HashMap时自动添加了synchronized来实现线程同步,类似的其它Collections.synchronizedXX方法也是类似原理)
HashMap可以使用null作为key,HashTable不可以使用null作为key值。
实现接口不同
默认容量不同,HashMap为16,HashTable为11,默认因子相同,为0。75
在Java SE 1.5之前,没有泛型的情况的下,通过对类型Object的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是一个安全隐患。
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
泛型在使用中还有一些规则和限制:
泛型的类型参数只能是类类型(包括自定义类),不能是简单类型。
同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
泛型的类型参数可以有多个。
泛型的参数类型可以使用extends语句,例如。习惯上成为“有界类型”。
泛型的参数类型还可以是通配符类型。
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
如在代码中定义的List和List等类型,在编译后都会编程List。JVM看到的只是List,而由泛型附加的类型信息对JVM来说是不可见的。Java编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法避免在运行时刻出现类型转换异常的情况。类型擦除也是Java的泛型实现方法与C++模版机制实现方式(后面介绍)之间的重要区别。
在上面,两次提到了原始类型,什么是原始类型?原始类型(raw type)就是擦除去了泛型信息,最后在字节码中的类型变量的真正类型。无论何时定义一个泛型类型,相应的原始类型都会被自动地提供。类型变量被擦除(crased),并使用其限定类型(无限定的变量用Object)替换。
例3:
class Pair<T> {
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
} Pair的原始类型为:
class Pair {
private Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
} 因为在Pair中,T是一个无限定的类型变量,所以用Object替换。其结果就是一个普通的类,如同泛型加入java变成语言之前已经实现的那样。在程序中可以包含不同类型的Pair,如Pair或Pair,但是,擦除类型后它们就成为原始的Pair类型了,原始类型都是Object。
从上面的那个例2中,我们也可以明白ArrayList被擦除类型后,原始类型也变成了Object,所以通过反射我们就可以存储字符串了。
如果类型变量有限定,那么原始类型就用第一个边界的类型变量来替换。
比如Pair这样声明
public class Pair<T extends Comparable& Serializable>
那么原始类型就是Comparable
注意:
如果Pair这样声明public class Pair<T extends Serializable&Comparable> ,那么原始类型就用Serializable替换,而编译器在必要的时要向Comparable插入强制类型转换。为了提高效率,应该将标签(tagging)接口(即没有方法的接口)放在边界限定列表的末尾。
由于泛型类型擦除的问题,JVM无法访问到泛型的类型信息,所以Java会在编译器通过先检查代码中泛型的信息,然后再进行类型擦除,再进行编译。
先看看参数化类型与原始类型的兼容
以ArrayList举例子,以前的写法:
ArrayList arrayList=new ArrayList();
现在的写法:
ArrayList<String> arrayList=new ArrayList<String>();
如果是与以前的代码兼容,各种引用传值之间,必然会出现如下的情况:
ArrayList<String> arrayList1=new ArrayList(); //第一种 情况
ArrayList arrayList2=new ArrayList<String>();//第二种 情况
这样是没有错误的,不过会有个编译时警告。
不过在第一种情况,可以实现与 完全使用泛型参数一样的效果,第二种则完全没效果。
因为,本来类型检查就是编译时完成的。new ArrayList()只是在内存中开辟一个存储空间,可以存储任何的类型对象。而真正涉及类型检查的是它的引用,因为我们是使用它引用arrayList1 来调用它的方法,比如说调用add()方法。所以arrayList1引用能完成泛型类型的检查。
而引用arrayList2没有使用泛型,所以不行。
举例子:
public class Test10 {
public static void main(String[] args) {
//
ArrayList<String> arrayList1=new ArrayList();
arrayList1.add("1");//编译通过
arrayList1.add(1);//编译错误
String str1=arrayList1.get(0);//返回类型就是String
ArrayList arrayList2=new ArrayList<String>();
arrayList2.add("1");//编译通过
arrayList2.add(1);//编译通过
Object object=arrayList2.get(0);//返回类型就是Object
new ArrayList<String>().add("11");//编译通过
new ArrayList<String>().add(22);//编译错误
String string=new ArrayList<String>().get(0);//返回类型就是String
}
} 通过上面的例子,我们可以明白,类型检查就是针对引用的,谁是一个引用,用这个引用调用泛型方法,就会对这个引用调用的方法进行类型检测,而无关它真正引用的对象。
从这里,我们可以再讨论下 泛型中参数化类型为什么不考虑继承关系
在Java中,像下面形式的引用传递是不允许的:
ArrayList<String> arrayList1=new ArrayList<Object>();//编译错误
ArrayList<Object> arrayList1=new ArrayList<String>();//编译错误
我们先看第一种情况,将第一种情况拓展成下面的形式:
ArrayList<Object> arrayList1=new ArrayList<Object>();
arrayList1.add(new Object());
arrayList1.add(new Object());
ArrayList<String> arrayList2=arrayList1;//编译错误
实际上,在第4行代码的时候,就会有编译错误。那么,我们先假设它编译没错。那么当我们使用arrayList2引用用get()方法取值的时候,返回的都是String类型的对象(上面提到了,类型检测是根据引用来决定的。),可是它里面实际上已经被我们存放了Object类型的对象,这样,就会有ClassCastException了。所以为了避免这种极易出现的错误,Java不允许进行这样的引用传递。(这也是泛型出现的原因,就是为了解决类型转换的问题,我们不能违背它的初衷)。
在看第二种情况,将第二种情况拓展成下面的形式:
ArrayList<String> arrayList1=new ArrayList<String>();
arrayList1.add(new String());
arrayList1.add(new String());
ArrayList<Object> arrayList2=arrayList1;//编译错误
没错,这样的情况比第一种情况好的多,最起码,在我们用arrayList2取值的时候不会出现ClassCastException,因为是从String转换为Object。可是,这样做有什么意义呢,泛型出现的原因,就是为了解决类型转换的问题。我们使用了泛型,到头来,还是要自己强转,违背了泛型设计的初衷。所以java不允许这么干。再说,你如果又用arrayList2往里面add()新的对象,那么到时候取得时候,我怎么知道我取出来的到底是String类型的,还是Object类型的呢?
所以,要格外注意,泛型中的引用传递的问题。
因为类型擦除的问题,所以所有的泛型类型变量最后都会被替换为原始类型。这样就引起了一个问题,既然都被替换为原始类型,那么为什么我们在获取的时候,不需要进行强制类型转换呢?看下ArrayList和get方法:
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
}
看以看到,在return之前,会根据泛型变量进行强转。
写了个简单的测试代码:
public class Test {
public static void main(String[] args) {
ArrayList<Date> list=new ArrayList<Date>();
list.add(new Date());
Date myDate=list.get(0);
}
然后反编了下字节码,如下
public static void main(java.lang.String[]);
Code:
0: new #16 // class java/util/ArrayList
3: dup
4: invokespecial #18 // Method java/util/ArrayList."<init
:()V
7: astore_1
8: aload_1
9: new #19 // class java/util/Date
12: dup
13: invokespecial #21 // Method java/util/Date."<init>":()
16: invokevirtual #22 // Method java/util/ArrayList.add:(L
va/lang/Object;)Z
19: pop
20: aload_1
21: iconst_0
22: invokevirtual #26 // Method java/util/ArrayList.get:(I
java/lang/Object;
25: checkcast #19 // class java/util/Date
28: astore_2
29: return
看第22 ,它调用的是ArrayList.get()方法,方法返回值是Object,说明类型擦除了。然后第25,它做了一个checkcast操作,即检查类型#19, 在在上面找#19引用的类型,他是
9: new #19 // class java/util/Date
是一个Date类型,即做Date类型的强转。
所以不是在get方法里强转的,是在你调用的地方强转的。
附关于checkcast的解释:
checkcast checks that the top item on the operand stack (a reference to an object or array) can be cast to a given type. For example, if you write in Java:
return ((String)obj);
then the Java compiler will generate something like:
aload_1 ; push -obj- onto the stack
checkcast java/lang/String ; check its a String
areturn ; return it
checkcast is actually a shortand for writing Java code like:
if (! (obj == null || obj instanceof <class>)) {
throw new ClassCastException();
}
// if this point is reached, then object is either null, or an instance of
// <class> or one of its superclasses.
现在有这样一个泛型类:
class Pair<T> {
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
然后我们想要一个子类继承它
class DateInter extends Pair<Date> {
@Override
public void setValue(Date value) {
super.setValue(value);
}
@Override
public Date getValue() {
return super.getValue();
}
}
在这个子类中,我们设定父类的泛型类型为Pair,在子类中,我们覆盖了父类的两个方法,我们的原意是这样的:
将父类的泛型类型限定为Date,那么父类里面的两个方法的参数都为Date类型:“
public Date getValue() {
return value;
}
public void setValue(Date value) {
this.value = value;
}
所以,我们在子类中重写这两个方法一点问题也没有,实际上,从他们的@OverRide标签中也可以看到,一点问题也没有,实际上是这样的吗?
分析:
实际上,类型擦除后,父类的的泛型类型全部变为了原始类型Object,所以父类编译之后会变成下面的样子:
[java] view plain copy
class Pair {
private Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
再看子类的两个重写的方法的类型:
[java] view plain copy
@OverRide
public void setValue(Date value) {
super.setValue(value);
}
@OverRide
public Date getValue() {
return super.getValue();
}
先来分析setValue方法,父类的类型是Object,而子类的类型是Date,参数类型不一样,这如果实在普通的继承关系中,根本就不会是重写,而是重载。
我们在一个main方法测试一下:
[java] view plain copy
public static void main(String[] args) throws ClassNotFoundException {
DateInter dateInter=new DateInter();
dateInter.setValue(new Date());
dateInter.setValue(new Object());//编译错误
}
如果是重载,那么子类中两个setValue方法,一个是参数Object类型,一个是Date类型,可是我们发现,根本就没有这样的一个子类继承自父类的Object类型参数的方法。所以说,却是是重写了,而不是重载了。
为什么会这样呢?
原因是这样的,我们传入父类的泛型类型是Date,Pair,我们的本意是将泛型类变为如下:
[java] view plain copy
class Pair {
private Date value;
public Date getValue() {
return value;
}
public void setValue(Date value) {
this.value = value;
}
}
然后再子类中重写参数类型为Date的那两个方法,实现继承中的多态。
可是由于种种原因,虚拟机并不能将泛型类型变为Date,只能将类型擦除掉,变为原始类型Object。这样,我们的本意是进行重写,实现多态。可是类型擦除后,只能变为了重载。这样,类型擦除就和多态有了冲突。JVM知道你的本意吗?知道!!!可是它能直接实现吗,不能!!!如果真的不能的话,那我们怎么去重写我们想要的Date类型参数的方法啊。
于是JVM采用了一个特殊的方法,来完成这项功能,那就是桥方法。
首先,我们用javap -c className的方式反编译下DateInter子类的字节码,结果如下:
[java] view plain copy
class com.tao.test.DateInter extends com.tao.test.Pair<java.util.Date> {
com.tao.test.DateInter();
Code:
0: aload_0
1: invokespecial #8 // Method com/tao/test/Pair.""
:()V
4: return
public void setValue(java.util.Date); //我们重写的setValue方法
Code:
0: aload_0
1: aload_1
2: invokespecial #16 // Method com/tao/test/Pair.setValue
:(Ljava/lang/Object;)V
5: return
public java.util.Date getValue(); //我们重写的getValue方法
Code:
0: aload_0
1: invokespecial #23 // Method com/tao/test/Pair.getValue
:()Ljava/lang/Object;
4: checkcast #26 // class java/util/Date
7: areturn
public java.lang.Object getValue(); //编译时由编译器生成的巧方法
Code:
0: aload_0
1: invokevirtual #28 // Method getValue:()Ljava/util/Date 去调用我们重写的getValue方法
;
4: areturn
public void setValue(java.lang.Object); //编译时由编译器生成的巧方法
Code:
0: aload_0
1: aload_1
2: checkcast #26 // class java/util/Date
5: invokevirtual #30 // Method setValue:(Ljava/util/Date; 去调用我们重写的setValue方法
)V
8: return
}
从编译的结果来看,我们本意重写setValue和getValue方法的子类,竟然有4个方法,其实不用惊奇,最后的两个方法,就是编译器自己生成的桥方法。可以看到桥方法的参数类型都是Object,也就是说,子类中真正覆盖父类两个方法的就是这两个我们看不到的桥方法。而打在我们自己定义的setvalue和getValue方法上面的@Oveerride只不过是假象。而桥方法的内部实现,就只是去调用我们自己重写的那两个方法。
所以,虚拟机巧妙的使用了巧方法,来解决了类型擦除和多态的冲突。
不过,要提到一点,这里面的setValue和getValue这两个桥方法的意义又有不同。
setValue方法是为了解决类型擦除与多态之间的冲突。
而getValue却有普遍的意义,怎么说呢,如果这是一个普通的继承关系:
那么父类的setValue方法如下:
[java] view plain copy
public ObjectgetValue() {
return super.getValue();
}
而子类重写的方法是:
[java] view plain copy
public Date getValue() {
return super.getValue();
}
其实这在普通的类继承中也是普遍存在的重写,这就是协变。
关于协变:。。。。。。
并且,还有一点也许会有疑问,子类中的巧方法 Object getValue()和Date getValue()是同 时存在的,可是如果是常规的两个方法,他们的方法签名是一样的,也就是说虚拟机根本不能分别这两个方法。如果是我们自己编写Java代码,这样的代码是无法通过编译器的检查的,但是虚拟机却是允许这样做的,因为虚拟机通过参数类型和返回类型来确定一个方法,所以编译器为了实现泛型的多态允许自己做这个看起来“不合法”的事情,然后交给虚拟器去区别。
4、泛型类型变量不能是基本数据类型
不能用类型参数替换基本类型。就比如,没有ArrayList,只有ArrayList。因为当类型擦除后,ArrayList的原始类型变为Object,但是Object类型不能存储double值,只能引用Double的值。
5、运行时类型查询
举个例子:
[java] view plain copy
ArrayList arrayList=new ArrayList();
因为类型擦除之后,ArrayList只剩下原始类型,泛型信息String不存在了。
那么,运行时进行类型查询的时候使用下面的方法是错误的
[java] view plain copy
if( arrayList instanceof ArrayList)
java限定了这种类型查询的方式
[java] view plain copy
if( arrayList instanceof ArrayList<?>)
? 是通配符的形式 ,将在后面一篇中介绍。
6、异常中使用泛型的问题
1、不能抛出也不能捕获泛型类的对象。事实上,泛型类扩展Throwable都不合法。例如:下面的定义将不会通过编译:
[java] view plain copy
public class Problem extends Exception{......}
为什么不能扩展Throwable,因为异常都是在运行时捕获和抛出的,而在编译的时候,泛型信息全都会被擦除掉,那么,假设上面的编译可行,那么,在看下面的定义:
[java] view plain copy
try{
}catch(Problem e1){
。。
}catch(Problem e2){
...
}
类型信息被擦除后,那么两个地方的catch都变为原始类型Object,那么也就是说,这两个地方的catch变的一模一样,就相当于下面的这样
[java] view plain copy
try{
}catch(Problem e1){
。。
}catch(Problem e2){
...
这个当然就是不行的。就好比,catch两个一模一样的普通异常,不能通过编译一样:
[java] view plain copy
try{
}catch(Exception e1){
。。
}catch(Exception e2){//编译错误
...
2、不能再catch子句中使用泛型变量
[java] view plain copy
public static void doWork(Class t){
try{
...
}catch(T e){ //编译错误
...
}
}
因为泛型信息在编译的时候已经变味原始类型,也就是说上面的T会变为原始类型Throwable,那么如果可以再catch子句中使用泛型变量,那么,下面的定义呢:
[java] view plain copy
public static void doWork(Class t){
try{
...
}catch(T e){ //编译错误
...
}catch(IndexOutOfBounds e){
}
}
根据异常捕获的原则,一定是子类在前面,父类在后面,那么上面就违背了这个原则。即使你在使用该静态方法的使用T是ArrayIndexOutofBounds,在编译之后还是会变成Throwable,ArrayIndexOutofBounds是IndexOutofBounds的子类,违背了异常捕获的原则。所以java为了避免这样的情况,禁止在catch子句中使用泛型变量。
但是在异常声明中可以使用类型变量。下面方法是合法的。
[java] view plain copy
public static void doWork(T t) throws T{
try{
...
}catch(Throwable realCause){
t.initCause(realCause);
throw t;
}
上面的这样使用是没问题的。
7、数组(这个不属于类型擦除引起的问题)
不能声明参数化类型的数组。如:
[java] view plain copy
Pair[] table = newPair(10); //ERROR
这是因为擦除后,table的类型变为Pair[],可以转化成一个Object[]。
[java] view plain copy
Object[] objarray =table;
数组可以记住自己的元素类型,下面的赋值会抛出一个ArrayStoreException异常。
[java] view plain copy
objarray ="Hello"; //ERROR
对于泛型而言,擦除降低了这个机制的效率。下面的赋值可以通过数组存储的检测,但仍然会导致类型错误。
[java] view plain copy
objarray =new Pair();
提示:如果需要收集参数化类型对象,直接使用ArrayList:ArrayList<Pair>最安全且有效。
8、泛型类型的实例化
不能实例化泛型类型。如,
[java] view plain copy
first = new T(); //ERROR
是错误的,类型擦除会使这个操作做成new Object()。
不能建立一个泛型数组。
[java] view plain copy
public T[] minMax(T[] a){
T[] mm = new T[2]; //ERROR
...
}
类似的,擦除会使这个方法总是构靠一个Object[2]数组。但是,可以用反射构造泛型对象和数组。
利用反射,调用Array.newInstance:
[java] view plain copy
publicstatic T[]minmax(T[] a)
{
T[] mm == (T[])Array.newInstance(a.getClass().getComponentType(),2);
...
// 以替换掉以下代码
// Obeject[] mm = new Object[2];
// return (T[]) mm;
}
9、类型擦除后的冲突
1、
当泛型类型被擦除后,创建条件不能产生冲突。如果在Pair类中添加下面的equals方法:
[java] view plain copy
class Pair {
public boolean equals(T value) {
return null;
}
}
考虑一个Pair。从概念上,它有两个equals方法:
booleanequals(String); //在Pair中定义
boolean equals(Object); //从object中继承
但是,这只是一种错觉。实际上,擦除后方法
boolean equals(T)
变成了方法 boolean equals(Object)
这与Object.equals方法是冲突的!当然,补救的办法是重新命名引发错误的方法。
2、
泛型规范说明提及另一个原则“要支持擦除的转换,需要强行制一个类或者类型变量不能同时成为两个接口的子类,而这两个子类是同一接品的不同参数化。”
下面的代码是非法的:
[java] view plain copy
class Calendar implements Comparable{ ... }
[java] view plain copy
class GregorianCalendar extends Calendar implements Comparable{...} //ERROR
GregorianCalendar会实现Comparable和Compable,这是同一个接口的不同参数化实现。
这一限制与类型擦除的关系并不很明确。非泛型版本:
[java] view plain copy
class Calendar implements Comparable{ ... }
[java] view plain copy
class GregorianCalendar extends Calendar implements Comparable{...} //ERROR
是合法的。
10、泛型在静态方法和静态类中的问题
泛型类中的静态方法和静态变量不可以使用泛型类所声明的泛型类型参数
举例说明:
[java] view plain copy
public class Test2 {
public static T one; //编译错误
public static T show(T one){ //编译错误
return null;
}
}
因为泛型类中的泛型参数的实例化是在定义对象的时候指定的,而静态变量和静态方法不需要使用对象来调用。对象都没有创建,如何确定这个泛型参数是何种类型,所以当然是错误的。
但是要注意区分下面的一种情况:
[java] view plain copy
public class Test2 {
public static <T >T show(T one){//这是正确的
return null;
}
}
因为这是一个泛型方法,在泛型方法中使用的T是自己在方法中定义的T,而不是泛型类中的T。
public interface lock {
void lock();
void lockInterruptibly() throws InterruptException;
boolean trylock();
boolean trylock(long time, TimeUnit unit) throws InterruptException;
void unlock();
Condition newCondition();
}unlock()作用是释放锁。最常用获取锁的方法是lock(),lock必须被显式的被创建,锁定和释放。一般使用ReentrantLock实例化,为了保证锁最后一定释放,要把互斥区放到try块中,并在finally语句中释放锁。当有return语句时,把return语句放到try子句中,确保unlock()不会过早执行。
//默认为非公平锁,若使用公平所,需要传入参数true
Lock lock = new ReentrantLock();
···
lock.lock();
try{
//执行任务,更新状态
} catch(Exception e){
...
} finally{
lock.unlock();
}tryLock()返回值是布尔型,trylock(long time, TimeUnit unit)方法和tryLock()类似,区别就是这个方法拿不到锁会等待一段时间,如果在时间期限内还拿不到锁就返回false。
Lock lock = new ReentrantLock();
···
if(lock.tryLock()){
try{
//执行任务,更新状态
}catch(Exception e){
···
} finally{
lock.unlock();
}
}else{
···
}lockInterruptibly()与以上方法不同,这个方法获取锁时,如果线程正在等待获取锁,则这个线程能够响应中断,即中断线程等待状态。例如:线程A,线程B都想获取到锁,此时A获取到锁,B只能等待,但是B也可以调用threadB.interrupt()中断等待状态。
public void method() throws InterruptedException(){
lock.interruptibly();
try{
//执行任务,更新状态
}catch(Exception e){
···
} finally{
lock.unlock();
}
}已获取到锁的线程无法interrupt()中断,interrupt()只能中断阻塞状态的线程。
以上是简略的用法,完整的使用方法如下:
对lock()方法执行代码如下:
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.stream.Stream;
public class Main{
private List<Integer> list = new ArrayList<>();
(1)//private Lock lock = new ReentrantLock();
public void method(Thread thread){
(2)//Lock lock = new ReentrantLock();
lock.lock();
try{
System.out.println(thread.getName()+"获取线程");
Stream.of(1,2,3,4,5).forEach(e -> list.add(e));
System.out.println(list);
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println(thread.getName()+"释放线程");
lock.unlock();
}
}
public static void main(String[] args) {
Main test = new Main();
new Thread(){
@Override
public void run(){
super.run();
test.method(Thread.currentThread());
}
}.start();
new Thread(){
@Override
public void run() {
super.run();
test.method(Thread.currentThread());
}
}.start();
}
}若是去掉(2)处注释,执行代码,执行结果如下:
Thread-0获取线程
Thread-1获取线程
[null, 1, 2, 2, 3, 3, 4, 5, 5]
[null, 1, 2, 2, 3, 3, 4, 5, 5]
Thread-1释放线程
Thread-0释放线程
为何Thread-0还未释放,Thread-1就获取到锁了呢?因为注释(2)处的lock是局部变量,我们两个线程执行时获取到的lock锁不是同一个锁,所以没有冲突。而(1)处的lock是仅此一家啊!
所以去掉(1)处的注释获取到的结果如下:
Thread-0获取线程
[1, 2, 3, 4, 5]
Thread-0释放线程
Thread-1获取线程
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
Thread-1释放线程
下面对tryLock()方法执行代码如下:
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.stream.Stream;
public class Main{
private List<Integer> list = new ArrayList<Integer>();
private Lock lock = new ReentrantLock();
public void method(Thread thread){
if(lock.tryLock()){
try{
System.out.println(thread.getName()+"获取线程");
Stream.of(1,2,3,4,5).forEach(e -> list.add(e));
System.out.println(list);
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println(thread.getName()+"释放线程");
lock.unlock();
}
}else{
System.out.println(thread.getName()+"获取线程失败");
}
}
public static void main(String[] args) {
Main test = new Main();
new Thread(){
@Override
public void run(){
super.run();
test.method(Thread.currentThread());
}
}.start();
new Thread(){
@Override
public void run() {
super.run();
test.method(Thread.currentThread());
}
}.start();
}
}tryLock()执行结果如下:
Thread-1获取线程
Thread-0获取线程失败
[1, 2, 3, 4, 5]
Thread-1释放线程
对lockInterruptibly执行测试代码如下:
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.stream.Stream;
class thread1 implements Runnable{
private Main test = null;
public thread1(Main test){
this.test = test;
}
@Override
public void run() {
try{
test.method(Thread.currentThread());
}catch(Exception e){
System.out.println(Thread.currentThread()+"线程被中断");
}
}
}
public class Main{
Lock lock = new ReentrantLock();
public void method(Thread thread) throws InterruptedException{
lock.lockInterruptibly();
try{
System.out.println(thread.getName()+"得到了锁");
long startTime = System.currentTimeMillis();
for( ; ;) {
if(System.currentTimeMillis() - startTime >= Integer.MAX_VALUE)
break;
}
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println(thread.getName()+"释放线程");
lock.unlock();
}
}
public static void main(String[] args) {
Main test = new Main();
Thread thread_1 = new Thread(new thread1(test));
Thread thread_2 = new Thread(new thread1(test));
thread_1.start();
thread_2.start();
try{
Thread.sleep(2000);
}catch (Exception e){
e.printStackTrace();
}
thread_2.interrupt();
}
}执行结果如下所示:
Thread-0得到了锁
Thread[Thread-1,5,main]线程被中断
public interface ReadWriteLock{
//return the lock of userd for reading
Lock readLock();
//return the lock of userd for writing
Lock writeLock();
}这个接口的两个方法主要用来获取读锁和获取写锁。ReentrantReadWriteLock实现这个接口,并且包含其他很多方法,最主要的还是readLock()和writeLock().这样的用意还是让多个线程可以同时进行读操作.
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class test {
private ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
public static void main(String[] args) {
test _test = new test();
new Thread(){
@Override
public void run() {
super.run();
_test.method(Thread.currentThread());
}
}.start();
new Thread(){
@Override
public void run() {
super.run();
_test.method(Thread.currentThread());
}
}.start();
}
public void method(Thread thread){
reentrantReadWriteLock.readLock().lock();
long start = System.currentTimeMillis();
try{
while(System.currentTimeMillis()-start<1){
System.out.println(thread.getName()+"正在读操作");
}
System.out.println(thread.getName()+"都操作完成");
}catch(Exception e){
e.printStackTrace();
}finally {
reentrantReadWriteLock.readLock().unlock();
}
}
}总结来说,Lock和synchronized有以下几点不同:
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
数据库连接步骤如下:
下载mysql-connector-java的jar包,并导入
加载注册驱动程序,Class.forName("com.mysql.jdbc.Driver")
连接数据库
conn = DriverManager.getCOnnection(DB_URL,USER,PASS)
执行sql语句
//创建用于执行sql语句的Statement对象
stmt = (Stattement)conn.createStatement();
//执行查询语句,返回查询结果
ResultSet rs = stmt.executeQuery("SELECT id,name FROM test");
while(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
out.println("..."+id+"..."+name);
out.println("<br />")
}
//执行插入语句,返回插入行数
String sql = “INSERT INTO test ...VALUES(...)”
stmt = (Statement)conn.createStatement();
int count = stmt.executeUpdate(sql);
//数据库更新(删除)和插入相似关闭数据库连接
rs.close();
stmt.close();
conn.close();
PrepareStatement
是Statement的子接口,可以传入带占位符的sqlyuju,提供补充占位符变量的方法
String sql = "insert into mysql_test values(?,?,?)"
PrepareStatement ps = conn.preprareStatement(sql);
ps.setString(1, '');
ps.setString(2, '');
ps.setString(3, '');
ps.execteUpdate();
何为事物: 所有的操作要么同时完成,要么同时失败。在mysql中提供Commit和Rollback命令进行事务的提交与回滚。
java的事务处理类型有三种,JDBC、JTA(Java Transaction API)事务、容器事务。容器事务多用于Spring中。
JDBC一切行为包括事务是基于一个connection的.
JDBC事务处理步骤:
取消JDBC的自动提交
void setAutoCommit(bollean autoCommit)=>setAutoCommit(false)
执行各个sql语句,加入到批处理之中
如若所有语句都执行成功,则提交事务commit(),如果出现错误,则回滚:roolback()
基本核心如下:
//取消自动提交
conn.setAutoCommit(false)
//将sql加入到批处理
stmt.addBatch();
stmt.addBatch();
//执行批处理操作
stmt.execteBatch();
//提交事务
commit();
//发生错误
try{
rollback();
}
优缺点:
实例如下所示:
public static void example(){
Connection conn = null;
}try{
Class.forName("com.mysql.jdbc.Driver");
conn = DreiverManager.getConnection("jdbc:ysql://localhost:3306/mysqltest", USSR, PASS);
conn.setAutoCommit(false);//取消自动提交,改为手动提交
String sql_1 = "update test_table set name='...' where name='...'";
String sql_2 = "insert test_table (name,url) values('...',''),('','')";
stmt = (Statement)conn.create.Statement();
int count = stmt.executeUpdate(sql_1);
//若所有结果执行完成,则执行提交事务
stmt.execteUpdate(sql_2);
conn.commit();
ps.close();
conn.close()
catch(ClassNotFoundException e){
e.printStackTrace();
}catch(SQLException e){
e.printStackTrace();
try{
//只要有一个sql语句错误,则事务回滚
conn.rollback();
}catch(SQLException e){
e.printStackTrace();
}
}
} JDBC事务无法满足分布式数据库的处理,所以使用JTA,JTA是一个java企业版的应用程序接口,在java中,允许完成跨越多个XA资源的分布式事务
XA(数据库与事务管理器的接口标准,Oracle,DB2,Sybase提供XA支持)
JTA提供了java.transaction.UserTansaction,主要方法为:
要想使用用 JTA 事务,那么就需要有一个实现 javax.sql.XADataSource 、 javax.sql.XAConnection 和 javax.sql.XAResource 接口的 JDBC 驱动程序。一个实现了这些接口的驱动程序将可以参与 JTA 事务。一个 XADataSource 对象就是一个 XAConnection 对象的工厂。XAConnection 是参与 JTA 事务的 JDBC 连接。
要使用JTA事务,必须使用XADataSource来产生数据库连接,产生的连接为一个XA连接。
XA连接(javax.sql.XAConnection)和非XA(java.sql.Connection)连接的区别在于:XA可以参与JTA的事务,而且不支持自动提交。
public void JtaTransfer() {
javax.transaction.UserTransaction tx = null;
java.sql.Connection conn = null;
try{
tx = (javax.transaction.UserTransaction) context.lookup("java:comp/UserTransaction"); //取得JTA事务,本例中是由Jboss容器管理
javax.sql.DataSource ds = (javax.sql.DataSource) context.lookup("java:/XAOracleDS"); //取得数据库连接池,必须有支持XA的数据库、驱动程序
tx.begin();
conn = ds.getConnection();
// 将自动提交设置为 false,
//若设置为 true 则数据库将会把每一次数据更新认定为一个事务并自动提交
conn.setAutoCommit(false);
stmt = conn.createStatement();
// 将 A 账户中的金额减少 500
stmt.execute("\
update t_account set amount = amount - 500 where account_id = 'A'");
// 将 B 账户中的金额增加 500
stmt.execute("\
update t_account set amount = amount + 500 where account_id = 'B'");
// 提交事务
tx.commit();
// 事务提交:转账的两步操作同时成功
} catch(SQLException sqle){
try{
// 发生异常,回滚在本事务中的操做
tx.rollback();
// 事务回滚:转账的两步操作完全撤销
stmt.close();
conn.close();
}catch(Exception ignore){
}
sqle.printStackTrace();
}
}这个类包含了所有的线程池静态工厂方法,我们一般使用工厂方法之一来创建一个线程池。
接口 java.util.concurrent.ExecutorService 表述了异步执行的机制,并且可以让任务在后台执行。一个 ExecutorService 实例因此特别像一个线程池。事实上,在 java.util.concurrent 包中的 ExecutorService 的实现就是一个线程池的实现。
一旦线程把任务委托给 ExecutorService,该线程就会继续执行与运行任务无关的其它任务。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}newFixedThreadPool创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到线程池的最大数量,这时线程池规模将不再变化(如果某个线程发生了未预期的Exception而结束,那么线程池会补充一个新的线程)
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}newSingleThreadExecutor是一个单线程的Executor,它创建单个工作者线程来执行任务,如果这个县城异常结束,会创建另一个线程来代替。能确保依照任务在队列中的顺序来执行任务。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}newCachedThreadPool将创建一个可缓存的线程池,这个工厂方法很重要,是个无界线程池,我们将会专门在另一篇文章讲这个方法。
如果线程池当前规模超过了处理需求时,将回收空闲的线程,当需求增加时,则可以添加新的线程,规模不u你在任何限制。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}创建一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
主要是几个方法的使用,具体看我线程池的第一篇文章
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
submit();
invokeAny();
invokeAll();
execute(); ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.execute(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
executorService.shutdown();使用这种方式没有办法获取执行 Runnable 之后的结果,如果你希望获取运行之后的返回值,就必须使用 接收 Callable 参数的 execute() 方法,后者将会在下文中提到。
Future future = executorService.submit(new Runnable() {
public void run() {
System.out.println("Asynchronous task");
}
});
//如果任务结束执行则返回 null
System.out.println("future.get()=" + future.get());方法 submit(Callable) 和方法 submit(Runnable) 比较类似,但是区别则在于它们接收不同的参数类型。Callable 的实例与 Runnable 的实例很类似,但是 Callable 的 call() 方法可以返回壹個结果。方法 Runnable.run() 则不能返回结果。
Callable 的返回值可以从方法 submit(Callable) 返回的 Future 对象中获取。如下是一个 ExecutorService Callable 的样例:
Future future = executorService.submit(new Callable(){
public Object call() throws Exception {
System.out.println("Asynchronous Callable");
return "Callable Result";
}
});
System.out.println("future.get() = " + future.get());上述样例代码会输出如下结果:
Asynchronous Callable
future.get() = Callable Result
当使用 ExecutorService 完毕之后,我们应该关闭它,这样才能保证线程不会继续保持运行状态。
举例来说,如果你的程序通过 main() 方法启动,并且主线程退出了你的程序,如果你还有一个活动的 ExecutorService 存在于你的程序中,那么程序将会继续保持运行状态。存在于 ExecutorService 中的活动线程会阻止Java虚拟机关闭。
为了关闭在 ExecutorService 中的线程,你需要调用 shutdown() 方法。ExecutorService 并不会马上关闭,而是不再接收新的任务,一旦所有的线程结束执行当前任务,ExecutorServie 才会真的关闭。所有在调用 shutdown() 方法之前提交到 ExecutorService 的任务都会执行。
如果你希望立即关闭 ExecutorService,你可以调用 shutdownNow() 方法。这个方法会尝试马上关闭所有正在执行的任务,并且跳过所有已经提交但是还没有运行的任务。但是对于正在执行的任务,是否能够成功关闭它是无法保证的,有可能他们真的被关闭掉了,也有可能它会一直执行到任务结束。这是一个最好的尝试。
结论:java中静态属性和静态方法可以被继承,但是没有被重写(overwrite)而是被隐藏.
原因:
1). 静态方法和属性是属于类的,调用的时候直接通过类名.方法名完成对,不需要继承机制及可以调用。如果子类里面定义了静态方法和属性,那么这时候父类的静态方法或属性称之为"隐藏"。如果你想要调用父类的静态方法和属性,直接通过父类名.方法或变量名完成,至于是否继承一说,子类是有继承静态方法和属性,但是跟实例方法和属性不太一样,存在"隐藏"的这种情况。
2). 多态之所以能够实现依赖于继承、接口和重写、重载(继承和重写最为关键)。有了继承和重写就可以实现父类的引用指向不同子类的对象。重写的功能是:"重写"后子类的优先级要高于父类的优先级,但是“隐藏”是没有这个优先级之分的。
3). 静态属性、静态方法和非静态的属性都可以被继承和隐藏而不能被重写,因此不能实现多态,不能实现父类的引用可以指向不同子类的对象。非静态方法可以被继承和重写,因此可以实现多态。
例子:
package com.study.test;
public class A { //父类
public static String staticStr = "A静态属性";
public String nonStaticStr = "A非静态属性";
public static void staticMethod(){
System.out.println("A静态方法");
}
public void nonStaticMethod(){
System.out.println("A非静态方法");
}
}
package com.study.test;
public class B extends A{//子类B
public static String staticStr = "B改写后的静态属性";
public String nonStaticStr = "B改写后的非静态属性";
public static void staticMethod(){
System.out.println("B改写后的静态方法");
}
}
package com.study.test;
public class C extends A{//子类C继承A中的所有属性和方法
}
package com.study.test;
public class StaticExtendsTest {
public static void main(String[] args) {
C c = new C();
System.out.println(c.nonStaticStr);
System.out.println(c.staticStr);
c.staticMethod();//输出的结果都是父类中的非静态属性、静态属性和静态方法,推出静态属性和静态方法可以被继承
System.out.println("-------------------------------");
A c1 = new C();
System.out.println(c1.nonStaticStr);
System.out.println(c1.staticStr);
c1.staticMethod();//结果同上,输出的结果都是父类中的非静态属性、静态属性和静态方法,推出静态属性和静态方法可以被继承
System.out.println("-------------------------------");
B b = new B();
System.out.println(b.nonStaticStr);
System.out.println(b.staticStr);
b.staticMethod();
System.out.println("-------------------------------");
A b1 = new B();
System.out.println(b1.nonStaticStr);
System.out.println(b1.staticStr);
b1.staticMethod();//结果都是父类的静态方法,说明静态方法不可以被重写,不能实现多态
}
} 如下图:
为解决数组固定尺寸的限制,java类库提供容器类来解决这问题。其中包括List,Set,Map,Queue,也称集合类。编程时可以将任意数量的对象置于容器,不用在意容器大小。
容器类库可以划分为:
java.util包中的Arrays和Collections类的Arrays.asList()方法和Collections.addAll()方法可以在Collection对象中添加一组元素。
如下:
public class addGroups(){
public static void main(String[] args){
Conllection<Integer> conllection = new ArrayList<Integer>(Arrays.asList(1,2,3));
Integer[] moreInts = {4,5,6};
collection.addAll(Arrays.asList(moreInts));
Collections.addAlls(conllection, 7,8,9);
Collections.addAlls(conllection, moreInts);
}
}可以直接使用Arrays.asList()的输出,将其作为List,此时,底层表示为数组,无法调整尺寸,若用add(),delete()添加或删除元素,会引发改变数组尺寸,产生错误。
List<Integer> list = Arrays.asList(10,11,12);
list.set(1,99); //可以修改元素值
list.add(13); //产生错误,尝试改变数组尺寸
List可以将元素维护在特定的序列中,有两种类型List:
具体方法操作如下例所示:
import java.util.*;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<String>(Arrays.asList("red","blue","white","grey"));
//add(int index,String value)向List中添加插入元素
list.add("yellow");
out.println(list);
//contains(String value)判断List中是否包含该元素
out.println(list.contains("yellow"));
//indexOf(String value)查询元素的位置
out.println(list.indexOf("blue"));
//remove(String value)删除元素
out.println(list.remove("blue"));
out.println(list);
//subList(int index,int _index)截取片断,返回一个新的List对象
List<String> _list = list.subList(1,4);
out.println(_list);
//containAll(List object)判断一个List中是否包含另一个List中的所有值
out.println(list.containsAll(_list));
//Collections.sort(List object)对List进行排序
Collections.sort(_list);
out.println(_list);
List<String> copy_list = new ArrayList<>(list);
_list = Arrays.asList(list.get(1),list.get(3));
out.println(_list);
out.println(copy_list);
//retainAll()取交集
copy_list.retainAll(_list);
out.println(copy_list);
//removeALl()从List中移除参数List中所有元素
copy_list.removeAll(_list);
out.println(copy_list);
//set()设值,在指定索引处,替换位置上的元素
list.set(1,"green");
out.println(list);
//addAll()在List中插入新的列表
list.addAll(1,_list);
out.println(list);
//isEmpty()判断List是否为空
out.println(list.isEmpty());
//clear()清除所有元素
list.clear();
out.println(list);
//toArray()将Collection转换为一个数组,为重载方法,无参版本返回的是Object数组
Object[] array = _list.toArray();
out.println(array[0]);
}
}迭代器(设计模式)是一个对象,用来遍历并选择序列中的对象,通常被称为轻量级对象,创建代价小。Java的Iterator只能单向移动。
如下示例:
import java.util.*;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<String>(Arrays.asList("red","blue","white","grey"));
Iterator<String> iter = list.iterator();
while(iter.hasNext()){
String s = iter.next();
out.println(s);
}
for(String _s : list)
out.println(_s);
iter = list.iterator();
for(int i = 0;i < 2;i++){
iter.next();
iter.remove();
}
out.println(list);
}
}若是所创建的List能把相同的代码应用于Set,将显得很方便,代码重组显然不适合,所以我们使用迭代器。创建一个display()方法:
import java.util.*;
import static java.lang.System.out;
public class Main {
public static void display(Iterator<String> iter){
while(iter.hasNext()){
String s = iter.next();
out.println(s);
}
}
public static void main(String[] args) {
List<String> list = new ArrayList<String>(Arrays.asList("red", "blue", "white", "grey"));
LinkedList<String> L_list = new LinkedList<String>(list);
HashSet<String> H_list = new HashSet<String>(list);
TreeSet<String> T_list = new TreeSet<String>(list);
display(list.iterator());
display(L_list.iterator());
display(H_list.iterator());
display(T_list.iterator());
}
}ListIterator是Iterator的子类型,用于LIst的访问。Iterator只能单向移动,但是ListIterator可以双向移动。
其中的previousIndex()和nextIndex()可以获取到当前位置的前一个和后一个元素索引,hasPrevious()判断一个元素是否存在,set()用于替换元素。
import java.util.*;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<String>(Arrays.asList("red", "blue", "white", "grey"));
ListIterator<String> iter = list.listIterator();
while(iter.hasNext()){
System.out.print(iter.next()+","+iter.nextIndex()+","+iter.previousIndex()+" ");
}
System.out.println();
while(iter.hasPrevious())
out.print(iter.previous()+" ");
out.println();
iter = list.listIterator(2);
while(iter.hasNext()){
iter.next();
iter.set("girl");
}
out.println(list);
}
}LinkedList随机访问比ArrayList逊色,但是元素的插入删除比ArrayList迅速的多。LinkedList添加了栈,队列,双端队列的方法。
import java.util.*;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<String>(Arrays.asList("red","blue","green","yellow"));
out.println(list);
out.println("getFirst():"+list.getFirst());
out.println("element():"+list.element());
out.println("peek():"+list.peek());
out.println("remove():"+list.remove());
out.println("removeFirst():"+list.removeFirst());
out.println("poll():"+list.poll());
list.addFirst("red");
list.addLast("blue");
out.println(list);
out.println("removeLast():"+list.removeLast());
}
}
[red, blue, green, yellow]
getFirst():red
element():red
peek():red
remove():red
removeFirst():blue
poll():green
[red, yellow, blue]
removeLast():blue“栈”称为“先进后出”(LIFO)容器。有时也称作叠加栈。最后压入的元素,最后一个弹出。LinkedList可以实现Java中的栈。
使用LInkedList定义一个Stack类:
import java.util.LinkedList;
public class Stack<T>{
private LinkedList<T> Storage = new LinkedList<T>();
public void push(T v) {
storage.addFirst(v);
}
public T peek(){
return storage.getFirst();
}
public T pop(){
return storage.removeFirst();
}
public boolean empty(){
return storage.isEmpty();
}
public String toString(){
return storage.toString();
}
}Set不保存重复元素,常用作测试归属性可以很容易判断对象是否在Set中,加快了对快速查询的优化。
Set有着与Collection完全一样的接口,没有任何额外功能,只是行为不同而已。如下为Set示例:
import java.util.*;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) {
Random rand = new Random(47);
//Set<Integer> set = new HashSet<Integer>();
//Set<Integer> set = new TreeSet<Integer>();
Set<Integer> set = new LinkedHashSet<Integer>();
for(int i = 0;i<1000;i++){
set.add(rand.nextInt(30));
}
out.println(set);
}
}运行结果:
HashSet:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
TreeSet:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
LinkedHashSet
[8, 5, 13, 11, 1, 29, 28, 20, 12, 7, 18, 21, 19, 16, 0, 14, 3, 26, 25, 10, 2, 24, 4, 6, 22, 27, 17, 9, 23, 15]
由运行结果可知,HashSet和TreeSet按顺序输出,以往的HashSet使用的是散列,现在或许已经改变了元素存储方式,TreeSet存储在红黑树中,LinkedHashSet使用了散列存储,看起来更是使用了链表维护元素插入顺序。
若是想要列出一个文件上所有的单词时,可以使用net.mindview.TextFile工具,并将其写入Set中。
new TextFile("Exzample.hava", "\\W+");
其中“\W+”表示正则表达式“一个或多个字母”。
队列是“先进先出”容器,容器一段放入元素,另一端取出。LinkedList支持队列的行为,实现了Queue接口,可以通过LinkedList向上转型为Queue。
Queue<String> queue = new LinkedList<String>();
其中Queue的offer()方法可以将一个元素插入到队尾,或返回false。peek()和element()在不移除的情况返回队头。poll()和remove()移除并返回队头。
Map是一种将对象与对象相关联的设计,HashMap设计用来快速访问,而TreeMap保持“键”始终处于排序状态,所以没有HashMap快,LInkedHashMap保持元素插入的顺序,但也通过散列提供快速访问的能力。
Map可以将对象映射到其他对象。例如,对Random产生的数字进行计数,键位Random产生的数字,值是数字出现的次数。
import java.util.*;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) {
Random rand = new Random(47);
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for(int i =0; i<1000;i++){
int r= rand.nextInt(30);
Integer num = map.get(r);
map.put(r, num==null?1:num+1);
}
out.println(map);
}
}此外,可以通过containsKey()和containsValue()测试一个Map,判断是否包含某个键或某个值。
import java.util.*;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<Integer, String>();
map.put(0, "red");
map.put(1, "blue");
map.put(2, "yellow");
out.println(map);
out.println(map.containsKey(1));
out.println(map.containsValue("blue"));
}
}方法一
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
} 方法二
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
//遍历map中的键
for (Integer key : map.keySet()) {
System.out.println("Key = " + key);
}
//遍历map中的值
for (Integer value : map.values()) {
System.out.println("Value = " + value);
}方法三
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<Integer, Integer> entry = entries.next();
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
} 线程池ThreadPoolExecutor继承于AbstractorExecutorService类,所以分析该类的构成很有必要。
上一篇博文提到ExecutorService是JDK并发工具包提供的一个核心接口,相当于一个线程池,提供执行任务和管理生命周期的方法。AbstractExecutorService主要实现了这个接口。 处理后的源码如下:
public abstract class AbstractExecutorService implements ExecutorService {
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
//submit函数1
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
//submit函数2
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
//submit函数3
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,boolean timed, long nanos) throws InterruptedException, ExecutionException, TimeoutException {······}
public <T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)throws InterruptedException, ExecutionException, TimeoutException {······}
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)throws InterruptedException {
}下面三个submit()方法是ExecutorService接口中的,并且由AbstructExecutorService类具体实现。
public Future<?> submit(Runnable task) {···}
public <T> Future<T> submit(Runnable task, T result) {···}
public <T> Future<T> submit(Callable<T> task) {···} @FunctionalInterface
public interface Callable<V> {
//计算结果
V call() throws Exception;
}
#### newTaskFor()方法源码
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
#### FutureTask类部分源码
public class FutureTask<V> implements RunnableFuture<V> {
···
public FutureTask(Callable<V> callable) {···}
public FutureTask(Runnable runnable, V result) {···}
···
} public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
} @FunctionalInterface
public interface Runnable {
public abstract void run();
} public interface Future<V> {
//试图取消对任务的执行,参数为true表示可以取消正在执行的任务
boolean cancel(boolean mayInterruptIfRunning);
//任务是否取消成功
boolean isCancelled();
//任务是否已经完成
boolean isDone();
//获取执行结果,会产生阻塞,等到任务执行完再返回结果
V get() throws InterruptedException, ExecutionException;
//在指定时间内未返回结果,则返回null
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
}从上述源码可知,想要分析submit()方法,转接这需要分析很多FutureTask类和若干接口。梳理一下如下所示
ThreadPoolExecutor-->(extends)AbstractExecutorService
AbstractExecutorService-->具有三个submit()方法,参数类型包括Runnable,Callable
submit()-->返回FutureTask类对象-->(implements)RunnableFuture-->(extends)Runnable,Future
我们来看Callable接口,从源码可知,这个接口只有一个call()方法,用以调用并返回结果,和Runnable相似,用以返回一个对象或异常。
Call接口使用泛型定义返回类型,Executors类提供了一些有用的方法在线程池中执行Callable内的任务。由于Callable任务是并行的(并行就是整体看上去是并行的,其实在某个时间点只有一个线程在执行),我们必须等待它返回的结果。
java.util.concurrent.Future对象为我们解决了这个问题。在线程池提交Callable任务后返回了一个Future对象,使用它可以知道Callable任务的状态和得到Callable返回的执行结果。Future提供了get()方法让我们可以等待Callable结束并获取它的执行结果。
可以用ExecutorService接口中的submit()方法实现这个功能,submit()负责向线程池提交Callable任务,然后返回Future对象,我们在借助Future对象的get()方法获取Callable接口中call()方法的结果:
<T> Future<T> submit(Callable<T> task);
public <T> Future<T> submit(Callable<T> task) {
//Callable任务为空,抛出无参异常
if (task == null) throw new NullPointerException();
//返回FutureTask类对象,
RunnableFuture<T> ftask = newTaskFor(task);
//向线程池提交一个任务
execute(ftask);
//返回处理后的任务
return ftask;
}我们分析的是传入Callable类型参数的submit方法,其实其他两个源码都类似, 注解基本都已经备注好,第一步判断参数的有无,我们来看看第二步返回是FutureTask类的对象,注意这个类实现的是RunnableFuture接口,而这个接口继承的又是Runnable和Future接口(接口也是可以extends接口的哦!)。所以它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。来看第二步代码FutureTask类的构造函数源码:
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW;
}FutureTask类实现了Future接口的一系列方法,如get()。第三步是向线程池提交任务,最后返回这个任务,下面看一个实例:
public class Test {
public static void main(String[] args) {
//建议使用Executors类中的方法构建线程池,具体使用方法和源码分析看我关于线程池本主题的其他博文
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
Future<Integer> result = executor.submit(task);
executor.shutdown();
try {
Thread.sleep(1000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
System.out.println("主线程在执行任务");
try {
System.out.println("task运行结果"+result.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println("所有任务执行完毕");
}
}
class Task implements Callable<Integer>{
@Override
public Integer call() throws Exception {
System.out.println("子线程在进行计算");
Thread.sleep(3000);
int sum = 0;
for(int i=0;i<100;i++)
sum += i;
return sum;
}
}执行结果如下:
子线程在进行计算
主线程在执行任务
task运行结果4950
所有任务执行完毕
public class Test {
public static void main(String[] args) {
//第一种方式,线程池方式
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
executor.submit(futureTask);
executor.shutdown();
//第二种方式,注意这种方式和第一种方式效果是类似的,只不过一个使用的是ExecutorService,一个使用的是Thread
/*Task task = new Task();
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
Thread thread = new Thread(futureTask);
thread.start();*/
try {
Thread.sleep(1000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
System.out.println("主线程在执行任务");
try {
System.out.println("task运行结果"+futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println("所有任务执行完毕");
}
}
class Task implements Callable<Integer>{
@Override
public Integer call() throws Exception {
System.out.println("子线程在进行计算");
Thread.sleep(3000);
int sum = 0;
for(int i=0;i<100;i++)
sum += i;
return sum;
}
}上面一段代码是对Callable+FutureTask方法的演示,若是Runnable+FutureTask也可以用此调用方式,只是task类中的不是call方法,而是实现run方法。
如果为了可取消性而使用 Future 但又不提供可用的结果,则可以声明 Future<?> 形式类型、并返回 null 作为底层任务的结果。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.