jetbrains-research / astminer Goto Github PK
View Code? Open in Web Editor NEWA library for mining of path-based representations of code (and more)
License: MIT License
A library for mining of path-based representations of code (and more)
License: MIT License

















































































































H:\jupyter>java -jar cli.jar pathContexts --lang c --project code+data_process --output code+data_paths --maxH 8 --maxW 2 --maxContexts 200 --maxTokens 1300000 --maxPaths 9000000
Exception in thread "main" java.lang.Exception: The first argument should be task's name: either 'preprocess' or 'parse'
at cli.MainKt.main(Main.kt:14)
Bintray is sunsetting and will no longer work starting on May 1st. It would be great to update the astminer version which is currently hosted on Maven Central, it appears the latest version was 0.2 and uses the io.github.vovak namespace. cc: @vovak
I generated code2vec data from a simple python file and noticed that there is no token for id 4:
id,token
4,
7,def
1,(
3,x
2,)
5,y
8,METHOD_NAME
9,:
6,=
From the path contexts it is clear that id 4 should be a comma.
Command:
./cli.sh code2vec --lang py --project C:\Workspace\astminer\test_project --output C:\Workspace\astminer\test_output --split-tokens --granularity method --hide-method-name
Python file:
def main():
x, y = (1, 2)
I used astminer to generate ASTs on a python repository dataset and was able to train the code2vec model on the path_contexts.csv. I have the model now and now I want to use it for inference on a new python file.
My doubt is that when I generate AST for the new python file, it outputs a path_contexts file with numbers specific to only that program. If i use this AST for inference, the model will end up doing a wrong embedding look-up since a token '2' in the new python file might be for example ')' where as in the trained model the '2' might have been something else.
How do I get about this? Should I substitute the numbers in the original dataset used for training with the node types and tokens?
Hi,
I'm using CLI to parse my python code.
I want to command "java -jar cli.jar code2vec --lang py,java,c,cpp --project path/to/project --output path/to/results --maxH H --maxW W --maxContexts C --maxTokens T --maxPaths P", but I cannot find the meaning of arguments maxH and maxW.
Best!
Xi
Create release job in Travis CI as described in #9
The Node Types in the AST Output for Java are not very specific. As can be seen below, "SimpleName" type is applicable for variables, methods as well as class names; which reduces its value.

Is there anything that can be done to improve upon this?
PFB the input source code I was using, for quick reference:
`public class sample_java_2{
public static void main(String[] args){
int x = 10;
int y = 15;
int z;
if (x < y) {
z = 2*x;
}
else {
z = 5*x;
}
}
}`
Support GumTree in astminer-cli
Travis integration has been broken by a rename. We have to fix it.
I get the following error on cli-javascript branch (code2vec with default parameters):
Exception in thread "main" kotlin.TypeCastException: null cannot be cast to non-null type astminer.parse.antlr.SimpleNode
at astminer.parse.antlr.javascript.JavaScriptElement.getElementInfo(JavaScriptMethodSplitter.kt:54)
at astminer.parse.antlr.javascript.JavaScriptMethodSplitter.splitIntoMethods(JavaScriptMethodSplitter.kt:29)
at astminer.cli.MethodLabelExtractor.toLabeledData(LabelExtractors.kt:82)
at astminer.cli.Code2VecExtractor.extractFromTree(Code2VecExtractor.kt:128)
at astminer.cli.Code2VecExtractor.access$extractFromTree(Code2VecExtractor.kt:18)
at astminer.cli.Code2VecExtractor$extract$1.invoke(Code2VecExtractor.kt:159)
at astminer.cli.Code2VecExtractor$extract$1.invoke(Code2VecExtractor.kt:18)
at astminer.common.model.Parser$DefaultImpls.parseFiles(ParsingModel.kt:55)
at astminer.parse.antlr.javascript.JavaScriptParser.parseFiles(JavaScriptParser.kt:13)
at astminer.cli.Code2VecExtractor.extract(Code2VecExtractor.kt:156)
at astminer.cli.Code2VecExtractor.run(Code2VecExtractor.kt:179)
at com.github.ajalt.clikt.parsers.Parser.parse(Parser.kt:136)
at com.github.ajalt.clikt.parsers.Parser.parse(Parser.kt:14)
at com.github.ajalt.clikt.core.CliktCommand.parse(CliktCommand.kt:216)
at com.github.ajalt.clikt.core.CliktCommand.parse$default(CliktCommand.kt:213)
at com.github.ajalt.clikt.core.CliktCommand.main(CliktCommand.kt:231)
at com.github.ajalt.clikt.core.CliktCommand.main(CliktCommand.kt:250)
at astminer.MainKt.main(Main.kt:16)
The first dozen methods or so seemed to parse fine. I get the same/similar error on master & master-dev.
The pathContexts option name is working fine.
Hello,
I am using astminer to extract path_contexts from some python file to use in the code2vec model.
I am particularly interested in making the the results easily interpretable, but I am having some troubles understanding how the node_types.csv file is generated.
For example what is the difference between these two node_types?
testlist_star_expr|test|or_test|and_test|not_test|comparison|expr|xor_expr|and_expr|shift_expr|arith_expr|term|factor|power|atom_expr|atom|NAME UP
and
expr|xor_expr|and_expr|shift_expr|arith_expr|term|factor|power|atom_expr|atom|NAME UP
Instead in the tokens.csv file, I have several tokens composed by one or more underscores ('_') and I don't understand what they represent, maybe the indentations?
Finally, is there a clever way to graphically represent the AST extracted with the parse comand?
I am trying to extend on this project by adding the ability to parse PHP ASTs, with the ultimate goal of using the output with Code2Vec. Eventually, I want to add PHP to the Code2VecExtractor in Astminer-cli, but right now, I want to focus on creating a working parser. I followed the steps listed here, and created the parser using the following PHP ANTLR Grammar files: PhpLexer.g4, PhpParser.g4, and PhpBaseLexer.
However, I am having some issues with the parser. When I parse files using the parseWithExtension() function to get a file's roots, and then try to split the methods using a PHPMethodSplitter.kt file I created, it seems like the methods are not being identified. It seems to be treating function names, comments, and data types all as NAME nodes. As an example, here is a simple piece of code.
<?php
function writeMsg() {
echo "Hello world!";
}
writeMsg(); // call the function
?>
In this example, the following nodes get identified as NAME nodes:
Ultimately, my questions are as follows:
package astminer.parse.antlr.php
import astminer.common.model.Parser
import astminer.parse.antlr.SimpleNode
import astminer.parse.antlr.convertAntlrTree
import org.antlr.v4.runtime.CommonTokenStream
import org.antlr.v4.runtime.CharStreams
import java.io.InputStream
import java.lang.Exception
import me.vovak.antlr.parser.PhpLexer
import me.vovak.antlr.parser.PhpParser
class PhpMainParser : Parser<SimpleNode> {
override fun parse(content: InputStream): SimpleNode? {
return try {
val lexer = PhpLexer(CharStreams.fromStream(content))
lexer.removeErrorListeners()
val tokens = CommonTokenStream(lexer)
val parser = PhpParser(tokens)
parser.removeErrorListeners()
val context = parser.phpBlock()
convertAntlrTree(context, PhpParser.ruleNames, PhpParser.VOCABULARY)
} catch (e: Exception) {
null
}
}
}
In order to make life of potential contributors and users of astminer easier, we should write extensive documentation.
Hi,
I am currently trying to use Astminer to extract paths for use with Code2Vec. I have roughly 9500 Python projects containing a total of about 220,000 code files that I want to extract paths from.
When running the command:
java -jar cli.jar code2vec --lang py --project <data location> --output <output location> --maxH 10 --maxW 6 --maxContexts 1000000 --maxTokens 100000 --maxPaths 100000
After about 15 minutes I get the error:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space: failed reallocation of scalar replaced objects.
When I reduce the number of projects from 9500 to 50 it works successfully. Is this likely to be an issue with system resources, or Astminer itself? Any help would be greatly appreciated, thanks!
Could astminer be used to extract metadata from Java methods?
For instance, using the following code snippet
/*
Checks if a target integer is present in the list of integers.
*/
public Boolean contains(Integer target, List<Integer> numbers) {
for(Integer number: numbers){
if(number.equals(target)){
return true;
}
}
return false;
}the metadata would be:
metadata = {
"comment": "Checks if a target integer is present in the list of integers.",
"identifier": "contains",
"parameters": "Integer target, List<Integer> numbers",
"return_statement": "false | true"
}Hi,
Thank you for this amazing project!
There is a description of the code2vec option in README:
split into methods, and store in form method|name triplesOfPathContexts
How the algorithm splits code files into methods? Is it necessary to wrap input code blocks with a function?
Thanks,
Ainur
The code below can not be parsed correctly using the code2vec option.
public static void main(String[] args) {
System.out.println("Hello world");
}
There are nothing in the output files.
I tried to add the ANTLR parser for clojure.
I am getting an error at this line. I think it's rather an issue from the ANTLR grammar as it seems to be quite a hack, but wanted to report anyway, as I am not absolutely sure what is going on at this point.
Here is the stacktrace: https://pastebin.com/mTfqDHN2
It only happens if I comment out the try case in the wrapper as otherwise it returns NULL.
EDIT: When looking at the generated ClojureParser there are quite a few null literal to symbolic mappings and vice versa. I am assuming this is a hole in the grammar file.
I can not split them when they are in camel case. Could you please add an option to keep upper case letters?
Hello @iromeo @egor-bogomolov ,
I was trying to use ASTMINER for extracting path step to feed it into code2vec.
with cli I ran this command
java -jar cli.jar code2vec --lang cpp --project ${VAL_PREPROCESSED_DIR} --output ${VAL_DATA_FILE} --maxH 10 --maxW 6 --maxContexts 1000000 --maxTokens 100000 --maxPaths 100000
But output of this is 4 csv files as mentioned in Readme but for passing it to code2vec preprocess.py we need single text file
How can we solve this issue?
I am guessing that PathMiner does only the step that is equivalent to JavaExtractor (i.e., only up to https://github.com/tech-srl/code2vec/blob/master/preprocess.sh#L49 line), but then I need to run the next preprocessing steps that begin here https://github.com/tech-srl/code2vec/blob/master/preprocess.sh#L51
But next steps are done by treating output as txt file
Can you please help me overcome this issue?
Hi, I run the pathContexts task with lang c, and I have got the vocabulary.
I try to parse a new c code by running the pathContexts task again, and map the new vocabulary into the old.
But I get the key error, seems like the old vocabulary didn't have the path.
Even if I pick a sub set from the old dataset, I still get the key error.
Thank you for your efforts.
I plan to use astminer to generate specific path_contexts. Specifically, I need to delete specific subtrees on the AST and replace them with specific nodes (such as "PRED").
I now have some questions about how to modify astminer:
Hope to get your reply.
Hi,
I tried to use astminer to preprocess my java data for path contexts. The result files seemed normal on paths.csv and tokens.csv. But in the path_contexts.csv, it got only one column of file_name without any extracted path.
Here's my data example:

I used the newest version of astminer and successfully extract another c dataset. I don't know why it cannot get the correct path_context file on the java dataset.
I appreciate your assistance sincerely.
Thanks!
Han
I am working with a Java dataset composed of pairs (code, comment), as shown below:
id | code | desc
-- | -- | --
321 | \tpublic int getPushesLowerbound() {\n\t\tretu... | returns the pushes lowerbound of this board po...
323 | \tpublic void setPushesLowerbound(int pushesLo... | sets the pushes lowerbound of this board position
324 | \t\tpublic void play() {\n\t\t\t\n\t\t\t// If ... | play a sound
343 | \tpublic int getInfluenceValue(int boxNo1, int... | returns the influence value between the positi...
351 | \tpublic void setPositions(int[] positions){\n... | sets the box positions and the player positionthen, is there an approach to extract the path context of each Java method creating new pairs (path_context, comment)?
Running utility I've got an error:
java.io.FileNotFoundException: /home/mikhail/Documents/Development/java_hw_au_hse_dataset/hse-19/babushkin/hw6.java (Is a directory)/home/mikhail/Documents/Development/java_hw_au_hse_dataset/hse-19/babushkin/hw5.java java.io.FileNotFoundException: /home/mikhail/Documents/Development/java_hw_au_hse_dataset/hse-19/babushkin/hw5.java (Is a directory)/home/mikhail/Documents/Development/java_hw_au_hse_dataset/hse-19/babushkin/hw3.java java.io.FileNotFoundException: /home/mikhail/Documents/Development/java_hw_au_hse_dataset/hse-19/babushkin/hw3.java (Is a directory)
Problem occurs because probably utility thinks it is source java file but in fact it is a directory.
From a quick glance, current implementation produces an "output format inspired by code2vec" and has a allJavaMethods example.
It would be very nice if there is also an option for producing the exact code2vec output format in a .csv, so it could replace existing *Extractors and be used as an input to preprocess.py.
What do you think?
I got this error. And can't got the processed_data.
My code is as follows:
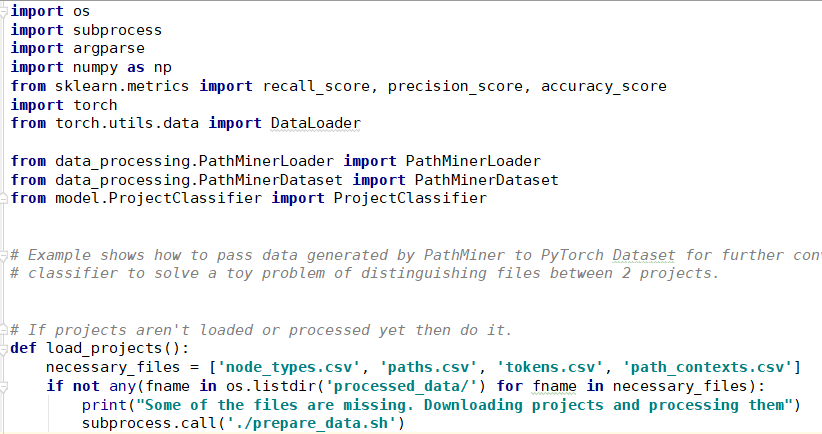
C:\Users\xingy\AppData\Local\Programs\Python\Python36\python.exe C:/Users/xingy/Desktop/py_example/run_example.py Traceback (most recent call last): File "C:/Users/xingy/Desktop/py_example/run_example.py", line 111, in <module> main(args) Checking if projects are loaded and processed File "C:/Users/xingy/Desktop/py_example/run_example.py", line 85, in main Some of the files are missing. Downloading projects and processing them load_projects() File "C:/Users/xingy/Desktop/py_example/run_example.py", line 23, in load_projects subprocess.call('./prepare_data.sh') File "C:\Users\xingy\AppData\Local\Programs\Python\Python36\lib\subprocess.py", line 267, in call with Popen(*popenargs, **kwargs) as p: File "C:\Users\xingy\AppData\Local\Programs\Python\Python36\lib\subprocess.py", line 709, in __init__ restore_signals, start_new_session) File "C:\Users\xingy\AppData\Local\Programs\Python\Python36\lib\subprocess.py", line 997, in _execute_child startupinfo) OSError: [WinError 193] %1
I am using CLI to generate the PathContexts of Java methods such as the one shown in the following code snippet:
class M{
public int sum (int a, int b){
return a + b
}
}which produces the following output:
in_path/teste.java 1,1,2 1,1,3 4,2,1 4,3,5 4,4,1 4,5,2 4,4,1 4,5,3 4,6,6 1,7,5
id,path
2,5 6 7 8
4,5 6 7 3 8
6,5 6 7 9
5,5 6 7 3 4
1,1 2 3 4
7,1 6 7 4
3,5 6 7 4
id,node_type
6,MethodDeclaration UP
1,PrimitiveType UP
9,Block DOWN
3,SingleVariableDeclaration DOWN
7,MethodDeclaration DOWN
5,Modifier UP
2,SingleVariableDeclaration UP
8,PrimitiveType DOWN
4,SimpleName DOWN
id,token
2,a
3,b
4,public
5,sum
6,EMPTY_TOKEN
1,int
In this context, shouldn't the start and end tokens be the leaf nodes (that is, the method variables like a and b)?
Hey, great progress on the project!
Could you please help me understand the current status of C support?
It seems like the Cpp lexer/parser from Joern should be able to handle it, but that is what happens when I try:
cat <<EOT >> testData/examples/cpp/realExamples/666.cpp
void main()
{
int n,a[100],i;
void fen(int a[],int x);
scanf("%d",&n);
for(i=0;i<n;i++)
{
scanf("%d",&a[i]);
}
fen(a,n);
}
void fen(int a[],int x){}
int look(int x,int y){ return 0;}
EOT
./gradlew runresults in
> Task :run
Exception in thread "main" java.lang.IllegalStateException: ruleContext.children must not be null
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:17)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:26)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:26)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:26)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:26)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:26)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:26)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:26)
at astminer.parse.antlr.AntlrUtilKt.convertAntlrTree(AntlrUtil.kt:9)
at astminer.parse.antlr.joern.CppParser.parse(CppParser.kt:20)
at astminer.examples.AllCppFilesKt.allCppFiles(AllCppFiles.kt:18)
at astminer.MainKt.runExamples(Main.kt:14)
at astminer.MainKt.main(Main.kt:6)
Please, let me know if I missed something here, and thanks in advance!
Hi all,
Do you know any workarounds to cope with such an error?
*_SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
java.lang.NoClassDefFoundError: jdk/nashorn/internal/runtime/ParserException_*
The command I ran is the following one: ./cli.sh code2vec --lang c --project results/prep --output results/ --maxL 8 --maxW 2 --maxContexts 500 --maxTokens 500 --maxPaths 500 --split-tokens --granularity method
it looks strange to me since I can see sl4j

Thank you all in advance :)
Hello,
I want to use Astminer to preprocess C/C++,
cli.sh preprocess --project MergeSort.c --output /home/harshit/Desktop/astminer/astminer/output
but I am getting following error.
Exception in thread "main" java.lang.IllegalStateException: relativeFilePath.parent must not be null
at astminer.parse.cpp.FuzzyCppParser.preprocessProject(FuzzyCppParser.kt:154)
at astminer.cli.ProjectPreprocessor.preprocessing(ProjectPreprocessor.kt:27)
at astminer.cli.ProjectPreprocessor.run(ProjectPreprocessor.kt:31)
at com.github.ajalt.clikt.parsers.Parser.parse(Parser.kt:136)
at com.github.ajalt.clikt.parsers.Parser.parse(Parser.kt:14)
at com.github.ajalt.clikt.core.CliktCommand.parse(CliktCommand.kt:216)
at com.github.ajalt.clikt.core.CliktCommand.parse$default(CliktCommand.kt:213)
at com.github.ajalt.clikt.core.CliktCommand.main(CliktCommand.kt:231)
at com.github.ajalt.clikt.core.CliktCommand.main(CliktCommand.kt:250)
at astminer.MainKt.main(Main.kt:13)
After cloning the repository, I run the following command.
./gradlew shadowJar
I am not getting what is going on, It will be great if anyone can help.
Hi,
I tried to use astminer to preprocess my python data for code2vec and it produced data in (Token, Path, Token) format, but the path were too long to implement the code2vec program because I substituted the id in path_contexts_x.csv by the corresponding node in node_types.csv.
The length of a path is lower than 20, which is suitable. However, a path id corresponds to a long node_type.
For example, this is part of my node_types.csv and id 734 has a very long node_type.

How can I compress the length of the paths into a suitable range? Or maybe I were not supposed to substitute the id in path_contexts_x.csv by the corresponding node_type in node_types.csv?
I appreciate your assistance sincerely.
Thanks!
Xi
Hello, the current format you gave returns the data in three files. However, when converting to Code2Vec (.c2v) it all compresses into a single file Code2Vec. The data came in this format:
set|work|unit|manager void,1726006538,METHOD_NAME void,1729349180,workunitmanager void,-233946901,workunitmanager METHOD_NAME,-1103308019,workunitmanager METHOD_NAME,1228363196,workunitmanager ...
Format Description
- A single text file, where each row is an example.
- Each example is a space-delimited list of fields, where:
- The first "word" is the target label, internally delimited by the "|" character.
- Each of the following words are contexts, where each context has three components separated by commas (","). Each of these components cannot include spaces nor commas. We refer to these three components as a token, a path, and another token, but in general other types of ternary contexts can be considered.
I am having trouble converting the path_contents.csv along with the other files to the .c2v format. What do I have to do to convert it to this format?
Files from output
path_contexts_0.csv
|node_types.csv
paths.csv
tokens.csv
I tried walking through their preprocessing stage however it looks like you already need the .c2v format in order to start preprocessing.
Thank you,
Kyle Dampier
We've had a bunch of tests failing in master-dev despite green builds on merge commits.
I've reverted master-dev to a stable state.
The current changes are in master-dev-current.
Before we merge it back into master-dev, we need to:
*.python.GumTreeJavaMethodSplitterTestThe python example takes most of the build time and is not relevant to most users. It should be extracted to a separate repository, and use astminer as a dependency.
Hi, first of all, huge 👍 for building this project! It is so handy, especially, when working with code2vec!
I tried to add Ruby support on my local fork using these instructions. But I'm getting the following error when I run ./gradlew run
➜ ./gradlew run
> Task :run
Reflections took 255 ms to scan 2 urls, producing 11 keys and 14 values
Reflections took 5 ms to scan 2 urls, producing 11 keys and 14 values
Reflections took 16 ms to scan 2 urls, producing 11 keys and 14 values
Reflections took 5 ms to scan 2 urls, producing 11 keys and 14 values
Reflections took 4 ms to scan 2 urls, producing 11 keys and 14 values
Reflections took 3 ms to scan 2 urls, producing 11 keys and 14 values
Reflections took 3 ms to scan 2 urls, producing 11 keys and 14 values
Reflections took 3 ms to scan 2 urls, producing 11 keys and 14 values
Reflections took 5 ms to scan 2 urls, producing 11 keys and 14 values
Exception in thread "main" java.lang.IllegalStateException: ruleContext.children must not be null
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:18)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:27)
at astminer.parse.antlr.AntlrUtilKt.convertRuleContext(AntlrUtil.kt:27)
at astminer.parse.antlr.AntlrUtilKt.convertAntlrTree(AntlrUtil.kt:10)
at astminer.parse.antlr.ruby.RubyParser.parse(RubyParser.kt:22)
at astminer.examples.AllRubyFilesKt$allRubyFiles$1.invoke(AllRubyFiles.kt:20)
at astminer.examples.AllRubyFilesKt$allRubyFiles$1.invoke(AllRubyFiles.kt)
at astminer.examples.CommonKt.iterateFiles(Common.kt:6)
at astminer.examples.CommonKt.forFilesWithSuffix(Common.kt:10)
at astminer.examples.AllRubyFilesKt.allRubyFiles(AllRubyFiles.kt:19)
at astminer.MainKt.runExamples(Main.kt:18)
at astminer.MainKt.main(Main.kt:7)
> Task :run FAILED
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':run'.
> Process 'command '/Library/Java/JavaVirtualMachines/jdk1.8.0_60.jdk/Contents/Home/bin/java'' finished with non-zero exit value 1
* Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.
* Get more help at https://help.gradle.org
BUILD FAILED in 13s
4 actionable tasks: 1 executed, 3 up-to-dateThis may be a problem with the Corundum.g4 parser file, but the example I'm using is supported by the grammar, so I'm kinda stuck. Any help would be wonderful, thanks!
This is the parser wrapper that I wrote after generating classes for Corundum.
I am trying to use astminer to convert a dataset of JavaScript files into AST format for code2vec. However, it is failing to parse certain JavaScript files at this step:
JavaScriptParser().parse(file.inputStream()) ?: return@forFilesWithSuffix
It does not throw any error so I am not sure what is exactly causing this failure. I have tried using astexplorer for those files and there doesn't seem to be an issue with the file itself. I have attached two files, one of which processes successfully while the other fails. Is there something I can do to make it work for failing files as well? Any help in this regard would be greatly appreciated. Thanks.
samples.zip
Hi,
I noticed that the parser for c/cpp is FuzzyCppParser, which is different from that for java/python (antlr4). The first question is why you choose a different parser? Does it outperform native antlr4? To my knowledge, the parser is written based on antlr4.
The second question is how to preprocess the whole project by considering complex dependencies, as I guess that the preprocessing module now only uses g++/gdb to preprocess files separately. Do you preprocess the files without the compiler?
Looking forward to your reply. Thanks!
Hi, while trying to run the example I am getting a FileNotFoundError, this is what I did:
(pathminer) user:~/astminer/py_example$ python run_example.py
Checking if projects are loaded and processed
Some of the files are missing. Downloading projects and processing them
FAILURE: Build failed with an exception.
* What went wrong:
Task 'processPyExample' not found in root project 'astminer'.
* Try:
Run gradlew tasks to get a list of available tasks. Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.
* Get more help at https://help.gradle.org
BUILD FAILED in 0s
Loading generated data
Traceback (most recent call last):
File "run_example.py", line 111, in <module>
main(args)
File "run_example.py", line 87, in main
loader = PathMinerLoader.from_folder(args.source_folder)
File "/home/user/astminer/py_example/data_processing/PathMinerLoader.py", line 22, in from_folder
path.join(dataset_folder, 'path_contexts.csv'))
File "/home/user/astminer/py_example/data_processing/PathMinerLoader.py", line 12, in __init__
self.tokens = self._load_tokens(tokens_file)
File "/home/user/astminer/py_example/data_processing/PathMinerLoader.py", line 28, in _load_tokens
with open(tokens_file, 'r') as f:
FileNotFoundError: [Errno 2] No such file or directory: 'processed_data/tokens.csv'
What is the correct way of generating tokens.csv file?
I have a specific JavaScript file I wish to extract path contexts from at function level to use with code2vec. This file only has one function: it starts at line 18 and ends at line 158. The parser seems to be unable to create an AST for the entire function, stopping at line 91. If I use esprima, the AST is properly extracted.
I'm using astminer as a library (master-dev branch), and this function node is obtained after passing the file node through JavaScriptMethodSplitter.splitIntoMethods().
Below is the result of executing methodRoot.prettyPrint() on the function node in question. You can see that the AST ends way before reaching the end of the function; it even complains of a missing closing brace.
expressionSequence|singleExpression : null
--Function : function
--Multiply : *
--OpenParen : (
--formalParameterList : null
----formalParameterArg|Identifier : req
----Comma : ,
----formalParameterArg|Identifier : res
----Comma : ,
----formalParameterArg|Identifier : flags
----Comma : ,
----formalParameterArg|Identifier : current
----Comma : ,
----formalParameterArg|Identifier : ignoredFiles
--CloseParen : )
--OpenBrace : {
--functionBody|sourceElements : null
----sourceElement|statement|variableStatement : null
------varModifier|Const : const
------variableDeclarationList|variableDeclaration : null
--------Identifier : headers
--------Assign : =
--------singleExpression|objectLiteral : null
----------OpenBrace : {
----------CloseBrace : }
------eos : null
----sourceElement|statement|ifStatement : null
------If : if
------OpenParen : (
------expressionSequence|singleExpression : null
--------singleExpression|Identifier : flags
--------Dot : .
--------identifierName|Identifier : cors
------CloseParen : )
------statement|block : null
--------OpenBrace : {
--------statementList : null
----------statement|expressionStatement : null
------------expressionSequence|singleExpression : null
--------------singleExpression : null
----------------singleExpression|Identifier : headers
----------------OpenBracket : [
----------------expressionSequence|singleExpression|literal|StringLiteral : 'Access-Control-Allow-Origin'
----------------CloseBracket : ]
--------------Assign : =
--------------singleExpression|literal|StringLiteral : '*'
------------eos : null
----------statement|expressionStatement : null
------------expressionSequence|singleExpression : null
--------------singleExpression : null
----------------singleExpression|Identifier : headers
----------------OpenBracket : [
----------------expressionSequence|singleExpression|literal|StringLiteral : 'Access-Control-Allow-Headers'
----------------CloseBracket : ]
--------------Assign : =
--------------singleExpression|literal|StringLiteral : 'Origin, X-Requested-With, Content-Type, Accept, Range'
------------eos : null
--------CloseBrace : }
----sourceElement|statement|iterationStatement : null
------For : for
------OpenParen : (
------varModifier|Const : const
------variableDeclaration|Identifier : header
------In : in
------expressionSequence|singleExpression|Identifier : headers
------CloseParen : )
------statement|block : null
--------OpenBrace : {
--------statementList : null
----------statement|ifStatement : null
------------If : if
------------OpenParen : (
------------expressionSequence|singleExpression : null
--------------Not : !
--------------singleExpression : null
----------------singleExpression : null
------------------singleExpression : null
--------------------singleExpression|objectLiteral : null
----------------------OpenBrace : {
----------------------CloseBrace : }
--------------------Dot : .
--------------------identifierName|Identifier : hasOwnProperty
------------------Dot : .
------------------identifierName|Identifier : call
----------------arguments : null
------------------OpenParen : (
------------------singleExpression|Identifier : headers
------------------Comma : ,
------------------singleExpression|Identifier : header
------------------CloseParen : )
------------CloseParen : )
------------statement|block : null
--------------OpenBrace : {
--------------statementList|statement|continueStatement : null
----------------Continue : continue
----------------eos : null
--------------CloseBrace : }
----------statement|expressionStatement : null
------------expressionSequence|singleExpression : null
--------------singleExpression : null
----------------singleExpression|Identifier : res
----------------Dot : .
----------------identifierName|Identifier : setHeader
--------------arguments : null
----------------OpenParen : (
----------------singleExpression|Identifier : header
----------------Comma : ,
----------------singleExpression : null
------------------singleExpression|Identifier : headers
------------------OpenBracket : [
------------------expressionSequence|singleExpression|Identifier : header
------------------CloseBracket : ]
----------------CloseParen : )
------------eos : null
--------CloseBrace : }
----sourceElement|statement|ifStatement : null
------If : if
------OpenParen : (
------expressionSequence|singleExpression : null
--------singleExpression|Identifier : flags
--------Dot : .
--------identifierName|Identifier : auth
------CloseParen : )
------statement|block : null
--------OpenBrace : {
--------statementList : null
----------statement|variableStatement : null
------------varModifier|Const : const
------------variableDeclarationList|variableDeclaration : null
--------------Identifier : credentials
--------------Assign : =
--------------singleExpression : null
----------------singleExpression|Identifier : auth
----------------arguments : null
------------------OpenParen : (
------------------singleExpression|Identifier : req
------------------CloseParen : )
------------eos : null
----------statement|ifStatement : null
------------If : if
------------OpenParen : (
------------expressionSequence|singleExpression : null
--------------singleExpression : null
----------------Not : !
----------------singleExpression : null
------------------singleExpression : null
--------------------singleExpression|Identifier : process
--------------------Dot : .
--------------------identifierName|Identifier : env
------------------Dot : .
------------------identifierName|Identifier : SERVE_USER
--------------Or : ||
--------------singleExpression : null
----------------Not : !
----------------singleExpression : null
------------------singleExpression : null
--------------------singleExpression|Identifier : process
--------------------Dot : .
--------------------identifierName|Identifier : env
------------------Dot : .
------------------identifierName|Identifier : SERVE_PASSWORD
------------CloseParen : )
------------statement|block : null
--------------OpenBrace : {
--------------statementList : null
----------------statement|expressionStatement : null
------------------expressionSequence|singleExpression : null
--------------------singleExpression : null
----------------------singleExpression|Identifier : console
----------------------Dot : .
----------------------identifierName|Identifier : error
--------------------arguments : null
----------------------OpenParen : (
----------------------singleExpression : null
------------------------singleExpression|Identifier : red
------------------------arguments : null
--------------------------OpenParen : (
--------------------------singleExpression|literal|StringLiteral : 'You are running serve with basic auth but did not set the SERVE_USER and SERVE_PASSWORD environment variables.'
--------------------------CloseParen : )
----------------------CloseParen : )
------------------eos : null
----------------statement|expressionStatement : null
------------------expressionSequence|singleExpression : null
--------------------singleExpression : null
----------------------singleExpression|Identifier : process
----------------------Dot : .
----------------------identifierName|Identifier : exit
--------------------arguments : null
----------------------OpenParen : (
----------------------singleExpression|literal|numericLiteral|DecimalLiteral : 1
----------------------CloseParen : )
------------------eos : null
--------------CloseBrace : }
----------statement|ifStatement : null
------------If : if
------------OpenParen : (
------------expressionSequence|singleExpression : null
--------------singleExpression : null
----------------singleExpression : null
------------------Not : !
------------------singleExpression|Identifier : credentials
----------------Or : ||
----------------singleExpression : null
------------------singleExpression : null
--------------------singleExpression|Identifier : credentials
--------------------Dot : .
--------------------identifierName|Identifier : name
------------------IdentityNotEquals : !==
------------------singleExpression : null
--------------------singleExpression : null
----------------------singleExpression|Identifier : process
----------------------Dot : .
----------------------identifierName|Identifier : env
--------------------Dot : .
--------------------identifierName|Identifier : SERVE_USER
--------------Or : ||
--------------singleExpression : null
----------------singleExpression : null
------------------singleExpression|Identifier : credentials
------------------Dot : .
------------------identifierName|Identifier : pass
----------------IdentityNotEquals : !==
----------------singleExpression : null
------------------singleExpression : null
--------------------singleExpression|Identifier : process
--------------------Dot : .
--------------------identifierName|Identifier : env
------------------Dot : .
------------------identifierName|Identifier : SERVE_PASSWORD
------------CloseParen : )
------------statement|block : null
--------------OpenBrace : {
--------------statementList : null
----------------statement|expressionStatement : null
------------------expressionSequence|singleExpression : null
--------------------singleExpression : null
----------------------singleExpression|Identifier : res
----------------------Dot : .
----------------------identifierName|Identifier : statusCode
--------------------Assign : =
--------------------singleExpression|literal|numericLiteral|DecimalLiteral : 401
------------------eos : null
----------------statement|expressionStatement : null
------------------expressionSequence|singleExpression : null
--------------------singleExpression : null
----------------------singleExpression|Identifier : res
----------------------Dot : .
----------------------identifierName|Identifier : setHeader
--------------------arguments : null
----------------------OpenParen : (
----------------------singleExpression|literal|StringLiteral : 'WWW-Authenticate'
----------------------Comma : ,
----------------------singleExpression|literal|StringLiteral : 'Basic realm="User Visible Realm"'
----------------------CloseParen : )
------------------eos : null
----------------statement|returnStatement : null
------------------Return : return
------------------expressionSequence|singleExpression : null
--------------------singleExpression : null
----------------------singleExpression|Identifier : micro
----------------------Dot : .
----------------------identifierName|Identifier : send
--------------------arguments : null
----------------------OpenParen : (
----------------------singleExpression|Identifier : res
----------------------Comma : ,
----------------------singleExpression|literal|numericLiteral|DecimalLiteral : 401
----------------------Comma : ,
----------------------singleExpression|literal|StringLiteral : 'Access Denied'
----------------------CloseParen : )
------------------eos : null
--------------CloseBrace : }
--------CloseBrace : }
----sourceElement|statement|variableStatement : null
------varModifier|Const : const
------variableDeclarationList|variableDeclaration : null
--------objectLiteral : null
----------OpenBrace : {
----------propertyAssignment|Identifier : pathname
----------CloseBrace : }
--------Assign : =
--------singleExpression : null
----------singleExpression|Identifier : parse
----------arguments : null
------------OpenParen : (
------------singleExpression : null
--------------singleExpression|Identifier : req
--------------Dot : .
--------------identifierName|Identifier : url
------------CloseParen : )
------eos : null
----sourceElement|statement|variableStatement : null
------varModifier|Const : const
------variableDeclarationList|variableDeclaration : null
--------Identifier : assetDir
--------Assign : =
--------singleExpression : null
----------singleExpression : null
------------singleExpression|Identifier : path
------------Dot : .
------------identifierName|Identifier : normalize
----------arguments : null
------------OpenParen : (
------------singleExpression : null
--------------singleExpression : null
----------------singleExpression|Identifier : process
----------------Dot : .
----------------identifierName|Identifier : env
--------------Dot : .
--------------identifierName|Identifier : ASSET_DIR
------------CloseParen : )
------eos : null
----sourceElement|statement|expressionStatement : null
------expressionSequence|singleExpression|Identifier : let
------eos : null
----sourceElement|statement|expressionStatement : null
------expressionSequence|singleExpression : null
--------singleExpression|Identifier : related
--------Assign : =
--------singleExpression : null
----------singleExpression : null
------------singleExpression|Identifier : path
------------Dot : .
------------identifierName|Identifier : parse
----------arguments : null
------------OpenParen : (
------------singleExpression : null
--------------singleExpression : null
----------------singleExpression|Identifier : path
----------------Dot : .
----------------identifierName|Identifier : join
--------------arguments : null
----------------OpenParen : (
----------------singleExpression|Identifier : current
----------------Comma : ,
----------------singleExpression|Identifier : pathname
----------------CloseParen : )
------------CloseParen : )
------eos : null
----sourceElement|statement|ifStatement : null
------If : if
------OpenParen : (
------expressionSequence|singleExpression : null
--------singleExpression : null
----------singleExpression : null
------------singleExpression : null
--------------singleExpression|Identifier : related
--------------Dot : .
--------------identifierName|Identifier : dir
------------Dot : .
------------identifierName|Identifier : indexOf
----------arguments : null
------------OpenParen : (
------------singleExpression|Identifier : assetDir
------------CloseParen : )
--------MoreThan : >
--------singleExpression : null
----------Minus : -
----------singleExpression|literal|numericLiteral|DecimalLiteral : 1
------CloseParen : )
------statement|block : null
--------OpenBrace : {
--------statementList : null
----------statement|variableStatement : null
------------varModifier|Const : const
------------variableDeclarationList|variableDeclaration : null
--------------Identifier : relative
--------------Assign : =
--------------singleExpression : null
----------------singleExpression : null
------------------singleExpression|Identifier : path
------------------Dot : .
------------------identifierName|Identifier : relative
----------------arguments : null
------------------OpenParen : (
------------------singleExpression|Identifier : assetDir
------------------Comma : ,
------------------singleExpression|Identifier : pathname
------------------CloseParen : )
------------eos : null
----------statement|expressionStatement : null
------------expressionSequence|singleExpression : null
--------------singleExpression|Identifier : related
--------------Assign : =
--------------singleExpression : null
----------------singleExpression : null
------------------singleExpression|Identifier : path
------------------Dot : .
------------------identifierName|Identifier : parse
----------------arguments : null
------------------OpenParen : (
------------------singleExpression : null
--------------------singleExpression : null
----------------------singleExpression|Identifier : path
----------------------Dot : .
----------------------identifierName|Identifier : join
--------------------arguments : null
----------------------OpenParen : (
----------------------singleExpression|Identifier : __dirname
----------------------Comma : ,
----------------------singleExpression|literal|StringLiteral : '/../assets'
----------------------Comma : ,
----------------------singleExpression|Identifier : relative
----------------------CloseParen : )
------------------CloseParen : )
------------eos : null
--------CloseBrace : }
----sourceElement|statement|expressionStatement : null
------expressionSequence|singleExpression : null
--------singleExpression|Identifier : related
--------Assign : =
--------singleExpression : null
----------singleExpression|Identifier : decodeURIComponent
----------arguments : null
------------OpenParen : (
------------singleExpression : null
--------------singleExpression : null
----------------singleExpression|Identifier : path
----------------Dot : .
----------------identifierName|Identifier : format
--------------arguments : null
----------------OpenParen : (
----------------singleExpression|Identifier : related
----------------CloseParen : )
------------CloseParen : )
------eos : null
----sourceElement|statement|variableStatement : null
------varModifier|Const : const
------variableDeclarationList|variableDeclaration : null
--------Identifier : relatedExists
--------Assign : =
--------singleExpression|Identifier : yield
------eos : null
----sourceElement|statement|expressionStatement : null
------expressionSequence|singleExpression : null
--------singleExpression : null
----------singleExpression|Identifier : fs
----------Dot : .
----------identifierName|Identifier : exists
--------arguments : null
----------OpenParen : (
----------singleExpression|Identifier : related
----------CloseParen : )
------eos : null
----sourceElement|statement|expressionStatement : null
------expressionSequence|singleExpression|Identifier : let
------eos : null
----sourceElement|statement|expressionStatement : null
------expressionSequence|singleExpression : null
--------singleExpression|Identifier : notFoundResponse
--------Assign : =
--------singleExpression|literal|StringLiteral : 'Not Found'
------eos : null
----sourceElement|statement|tryStatement : null
------Try : try
------block : null
--------OpenBrace : {
--------statementList : null
----------statement|variableStatement : null
------------varModifier|Const : const
------------variableDeclarationList|variableDeclaration : null
--------------Identifier : custom404Path
--------------Assign : =
--------------singleExpression : null
----------------singleExpression : null
------------------singleExpression|Identifier : path
------------------Dot : .
------------------identifierName|Identifier : join
----------------arguments : null
------------------OpenParen : (
------------------singleExpression|Identifier : current
------------------Comma : ,
------------------singleExpression|literal|StringLiteral : '/404.html'
------------------CloseParen : )
------------eos : null
----------statement|expressionStatement : null
------------expressionSequence|singleExpression : null
--------------singleExpression|Identifier : notFoundResponse
--------------Assign : =
--------------singleExpression|Identifier : yield
------------eos : null
----------statement|expressionStatement : null
------------expressionSequence|singleExpression : null
--------------singleExpression : null
----------------singleExpression|Identifier : fs
----------------Dot : .
----------------identifierName|Identifier : readFile
--------------arguments : null
----------------OpenParen : (
----------------singleExpression|Identifier : custom404Path
----------------Comma : ,
----------------singleExpression|literal|StringLiteral : 'utf-8'
----------------CloseParen : )
------------eos : null
--------CloseBrace : }
------catchProduction : null
--------Catch : catch
--------OpenParen : (
--------Identifier : err
--------CloseParen : )
--------block : null
----------OpenBrace : {
----------CloseBrace : }
----sourceElement|statement|ifStatement : null
------If : if
------OpenParen : (
------expressionSequence|singleExpression : null
--------singleExpression : null
----------Not : !
----------singleExpression|Identifier : relatedExists
--------And : &&
--------singleExpression : null
----------singleExpression : null
------------singleExpression|Identifier : flags
------------Dot : .
------------identifierName|Identifier : single
----------IdentityEquals : ===
----------singleExpression|Identifier : undefined
------CloseParen : )
------statement|block : null
--------OpenBrace : {
--------statementList|statement|returnStatement : null
----------Return : return
----------expressionSequence|singleExpression : null
------------singleExpression : null
--------------singleExpression|Identifier : micro
--------------Dot : .
--------------identifierName|Identifier : send
------------arguments : null
--------------OpenParen : (
--------------singleExpression|Identifier : res
--------------Comma : ,
--------------singleExpression|literal|numericLiteral|DecimalLiteral : 404
--------------Comma : ,
--------------singleExpression|Identifier : notFoundResponse
--------------CloseParen : )
----------eos : null
--------CloseBrace : }
----sourceElement|statement|variableStatement : null
------varModifier|Const : const
------variableDeclarationList|variableDeclaration : null
--------Identifier : streamOptions
--------Assign : =
--------singleExpression|objectLiteral : null
----------OpenBrace : {
----------CloseBrace : }
------eos : null
----sourceElement|statement|ifStatement : null
------If : if
------OpenParen : (
------expressionSequence|singleExpression : null
--------singleExpression|Identifier : flags
--------Dot : .
--------identifierName|Identifier : cache
------CloseParen : )
------statement|block : null
--------OpenBrace : {
--------statementList|statement|expressionStatement : null
----------expressionSequence|singleExpression : null
------------singleExpression : null
--------------singleExpression|Identifier : streamOptions
--------------Dot : .
--------------identifierName|Identifier : maxAge
------------Assign : =
------------singleExpression : null
--------------singleExpression|Identifier : flags
--------------Dot : .
--------------identifierName|Identifier : cache
----------eos : null
--------CloseBrace : }
----sourceElement|statement|ifStatement : null
------If : if
------OpenParen : (
------expressionSequence|singleExpression : null
--------singleExpression|Identifier : relatedExists
--------And : &&
--------singleExpression : null
------CloseParen : <missing ')'>
------statement|expressionStatement : null
--------expressionSequence : null
----------singleExpression|OpenParen : (
----------Identifier : yield
--------eos : null
----sourceElement|statement|expressionStatement : null
------expressionSequence|singleExpression : null
--------singleExpression : null
----------singleExpression|Identifier : pathType
----------Dot : .
----------identifierName|Identifier : dir
--------arguments : null
----------OpenParen : (
----------singleExpression|Identifier : related
----------CloseParen : )
------eos : null
--CloseBrace : <missing '}'>
Hello,
I've been testing the tool and i've seen that the cli gives inconsistent results for same files:
So I have one C file named cros_ec_dev_pre.c which i copied to have two files cros_ec_dev_pre.c and cros_ec_dev_pre1.c. I then run the command in the current directory where my two files are
java -jar cli.jar code2vec --lang c --maxH 10 --maxW 6 --maxContexts 1000000 --maxTokens 100000 --maxPaths 100000 --project . --output res
As the two files are identical, the path_contexts_0.csv should contain each of the methods and the contexts associated twice, and the contexts should be identical. However some methods have differents resulting contexts as for example:
ec|device|remove 57,2,58 8,155,7 7,4,8 58,4,57 36,13,9 58,6,36 58,5,9 57,8,36 57,7,9 59,607,58 59,608,57 59,608,36 59,607,9 7,201,59 7,609,58 7,610,57 7,610,36 7,609,9 8,206,59 8,611,58 8,612,57 8,612,36 8,611,9 8,13,7 60,13,9 8,8,60 8,7,9 7,6,60 7,5,9 61,608,8 61,607,7 61,608,60 61,607,9 7,4,8 62,13,9 7,6,62 7,5,9 8,8,62 8,7,9 63,607,7 63,608,8 63,608,62 63,607,9 8,85,7 8,86,8 8,613,59 8,614,58 8,615,57 7,81,7 7,82,8 7,616,59 7,617,58 7,618,57 7,618,36 8,619,61 59,620,61 59,621,8 58,622,61 58,623,8 58,624,7 57,625,61 57,626,8 57,627,7 57,626,60 36,625,61 36,626,8 36,627,7 36,626,60 36,627,9 9,622,61 9,623,8 9,624,7 9,623,60 9,624,9 9,622,63 61,628,63 61,629,7 8,630,63 8,631,7 8,632,8 7,633,63 7,634,7 7,635,8 7,635,62 60,630,63 60,631,7 60,632,8 60,632,62 60,631,9 9,633,63 9,634,7 9,635,8 9,635,62 9,634,9 9,636,33 63,637,33 7,636,33 8,638,33 62,638,33 9,636,33 64,135,20 64,137,57 64,136,58 64,639,8 64,328,7 64,640,7 20,139,57 20,138,58 20,330,8 20,329,7 20,641,7 20,642,8 57,146,8 57,145,7 57,147,7 57,152,8 57,643,59 58,148,8 58,142,7 58,149,7 58,150,8 58,644,59 58,645,58
ec|device|remove 57,2,58 7,3,8 7,4,8 57,13,58 9,4,36 57,7,9 57,8,36 58,5,9 58,6,36 59,608,57 59,607,58 59,607,9 59,608,36 7,201,59 7,610,57 7,609,58 7,609,9 7,610,36 8,206,59 8,612,57 8,611,58 8,611,9 8,612,36 7,4,8 60,13,9 7,6,60 7,5,9 8,8,60 8,7,9 61,607,7 61,608,8 61,608,60 61,607,9 7,4,8 62,13,9 7,6,62 7,5,9 8,8,62 8,7,9 63,607,7 63,608,8 63,608,62 63,607,9 7,81,7 7,82,8 7,616,59 7,618,57 7,617,58 8,85,7 8,86,8 8,613,59 8,615,57 8,614,58 8,614,9 8,619,61 59,620,61 59,1597,7 57,625,61 57,627,7 57,626,8 58,622,61 58,624,7 58,623,8 58,623,60 9,622,61 9,624,7 9,623,8 9,623,60 9,624,9 36,625,61 36,627,7 36,626,8 36,626,60 36,627,9 36,625,63 61,628,63 61,629,7 7,633,63 7,634,7 7,635,8 8,630,63 8,631,7 8,632,8 8,632,62 60,630,63 60,631,7 60,632,8 60,632,62 60,631,9 9,633,63 9,634,7 9,635,8 9,635,62 9,634,9 9,636,33 63,637,33 7,636,33 8,638,33 62,638,33 9,636,33 64,135,20 64,137,57 64,136,58 64,328,7 64,639,8 64,640,7 20,139,57 20,138,58 20,329,7 20,330,8 20,641,7 20,642,8 57,145,7 57,146,8 57,147,7 57,152,8 57,643,59 58,142,7 58,148,8 58,149,7 58,150,8 58,644,59 58,1598,57
I don't understand why the two identical methods give different results.
Please find attached the c file in question
Following a discussion in #57, we should provide instructions on how to locally update the library and use the updated version in CLI immediately, without releasing it anywhere.
We can improve memory usage by, for example, avoiding storing graphics in storage and immediately saving them to disk, this can fix #75. And many things can help to reduce the working time, such as using multiprocessing.
But before making any improvements, we need time and memory usage tests so that we can show progress and determine that any offer works in practice.
On the other hand, running benchmarks on a few examples will show the system requirements for using the tool, such as the minimum amount of RAM.
I received an error when trying to execute ./gradlew shadowJar. Information and solution below. Providing in case anyone else is having the same issue.
gradle -version
Build time: 2020-08-25 16:29:12 UTC
Revision: f2d1fb54a951d8b11d25748e4711bec8d128d7e3
Kotlin: 1.3.72
Groovy: 2.5.12
Ant: Apache Ant(TM) version 1.10.8 compiled on May 10 2020
JVM: 14.0.1 (Oracle Corporation 14.0.1+14)
OS: Mac OS X 10.15.5 x86_64
attempt: ./gradlew shadowJar
error:
FAILURE: Build failed with an exception.
* What went wrong:
Could not initialize class org.codehaus.groovy.runtime.InvokerHelper
solution:
source ([https://github.com/gradle/gradle/issues/10248])
distributionUrl=https\://services.gradle.org/distributions/gradle-6.3-bin.zip./gradlew shadowJarI am trying to generate the code2vec data using the cli.jar on a bunch of custom program files.
Running the cli.jar on several files C,CPP files in my dataset, it generates 10130 tokens, 64054 paths and 76050 path contexts.
Error: The path_contexts.csv file contains token ids which is greater than 10130 and path_ids greater than 64045 hence crashing my code2vec training (Using the pyexample code to train code2vec).
Note: I tried the same on two open source C,CPP repos (tensorflow and swift) and it worked without this problem.
I have added ANTLR grammer of COBOL to ASTMiner and implemented the wrapper. When I run the ASTMiner, it generates the below files:
node_types.csv
path_contexts.csv
paths.csv
tokens.csv
I know this ASTMiner output is compatible with code2vec. I need some help/pointers on how to use this output in code2vec to get predictions.
Thanks for this great tool! I'm trying to generate input files for code2vec model from python projects. I have a list of python projects (directories), and after I run astminer CLI, i got the node_types.csv, tokens.csv, paths.csv and the rest are path_contexts_*.csv. I wonder how can I possibly know which path_contexts_i.csv file come from which project?
for example, my list of python projects:
- PyProjectRepoA
-- folderA1
--- script.py
...
-- folderA2
...
other_script. py
- PyProjectRepoB
...
- PyProjectRepoX
then e.g. does path_contexts_10.csv come from PyProjectRepoB or PyProjectRepoX or else? so far to me there seems like no (easy) way to tell.
(The reason why I'd like to know which project it belong to is that, I need to split train, val and test file on project level not per path_context level, so there's no information leakage.
To do that 1) I either split all my projects to train/val/test first then run extract path_contexts separately
2) or, I run extraction overall then find out which project each path context belongs to, so I can do the split of train/val/test and also know their corresponding path_contexts.
the 1) is not possible since each integer representation in the path_context could actually represent different things for different project, so I'm trying to work out the 2) option)
Thanks!
Add JS support via
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.