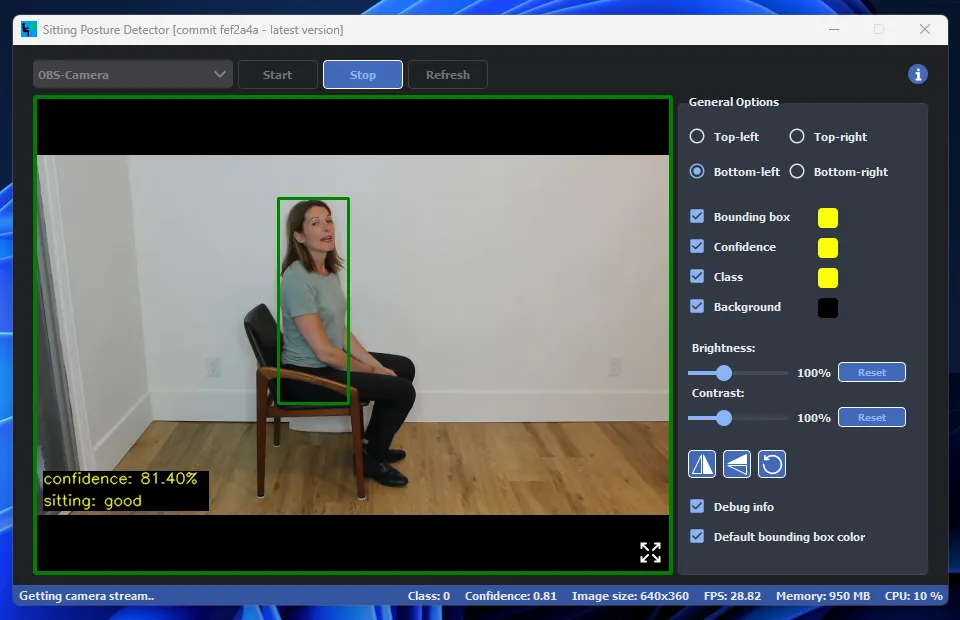
This GitHub repository contains a posture detection program that utilizes YOLOv5, an advanced object detection algorithm, to detect and predict lateral sitting postures. The program is designed to analyze the user's sitting posture in real-time and provide feedback on whether the posture is good or bad based on predefined criteria. The goal of this project is to promote healthy sitting habits and prevent potential health issues associated with poor posture.
Key Features:
- YOLOv5: The program leverages the power of YOLOv5, which is an object detection algorithm, to accurately detect the user's sitting posture from a webcam.
- Real-time Posture Detection: The program provides real-time feedback on the user's sitting posture, making it suitable for use in applications such as office ergonomics, fitness, and health monitoring.
- Good vs. Bad Posture Classification: The program uses a pre-trained model to classify the detected posture as good or bad, enabling users to improve their posture and prevent potential health issues associated with poor sitting habits.
- Open-source: The program is released under an open-source license, allowing users to access the source code, modify it, and contribute to the project.
- Python 3.9.x
If you have an NVIDIA graphics processor, you can activate GPU acceleration by installing the GPU requirements. Note that without GPU acceleration, the inference will run on the CPU, which can be very slow.
git clone https://github.com/itakurah/SittingPostureDetection.gitpython -m venv venv.\venv\scripts\activate.bat
pip install -r ./requirements_windows.txtORpip install -r ./requirements_windows_gpu.txt
git clone https://github.com/itakurah/SittingPostureDetection.gitpython3 -m venv venvsource venv/bin/activate
pip3 install -r requirements_linux.txtORpip3 install -r requirements_linux_gpu.txt
python application.py <optional: model_file.pt> OR python3 application.py <optional: model_file.pt>
The default model is loaded if no model file is specified.
The program uses a custom trained YOLOv5s model that is trained on about 160 images per class for 146 epochs. The model has two classes: sitting_good and sitting_bad to give feedback about the current sitting posture.
The architecture that is used for the model is the standard YOLOv5 architecture:

Fig. 1: The architecture of the YOLOv5 model, which consists of three parts: (i) Backbone: CSPDarknet, (ii) Neck: PANet, and (iii) Head: YOLO Layer. The data are initially input to CSPDarknet for feature extraction and subsequently fed to PANet for feature fusion. Lastly, the YOLO Layer outputs the object detection results (i.e., class, score, location, size)
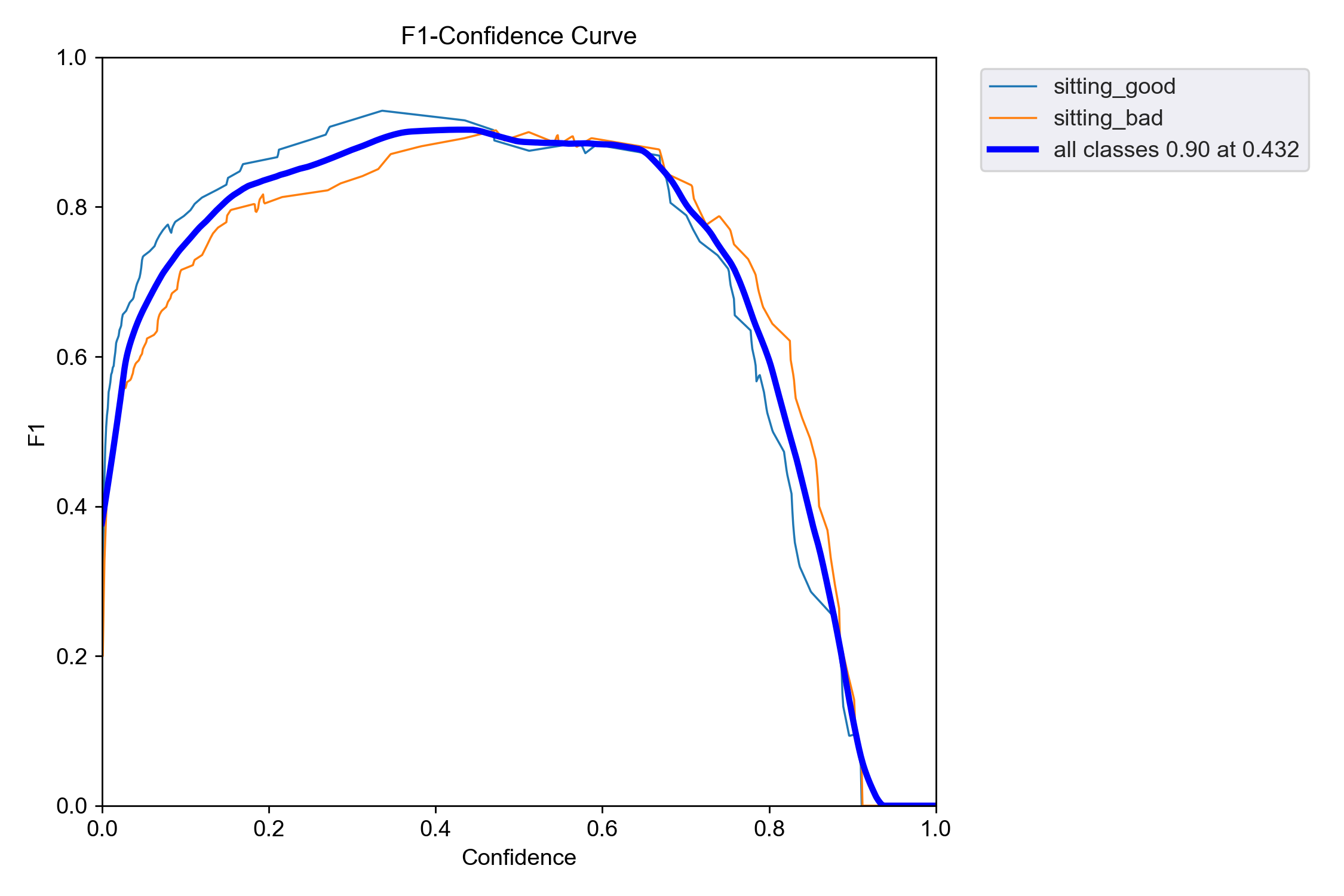
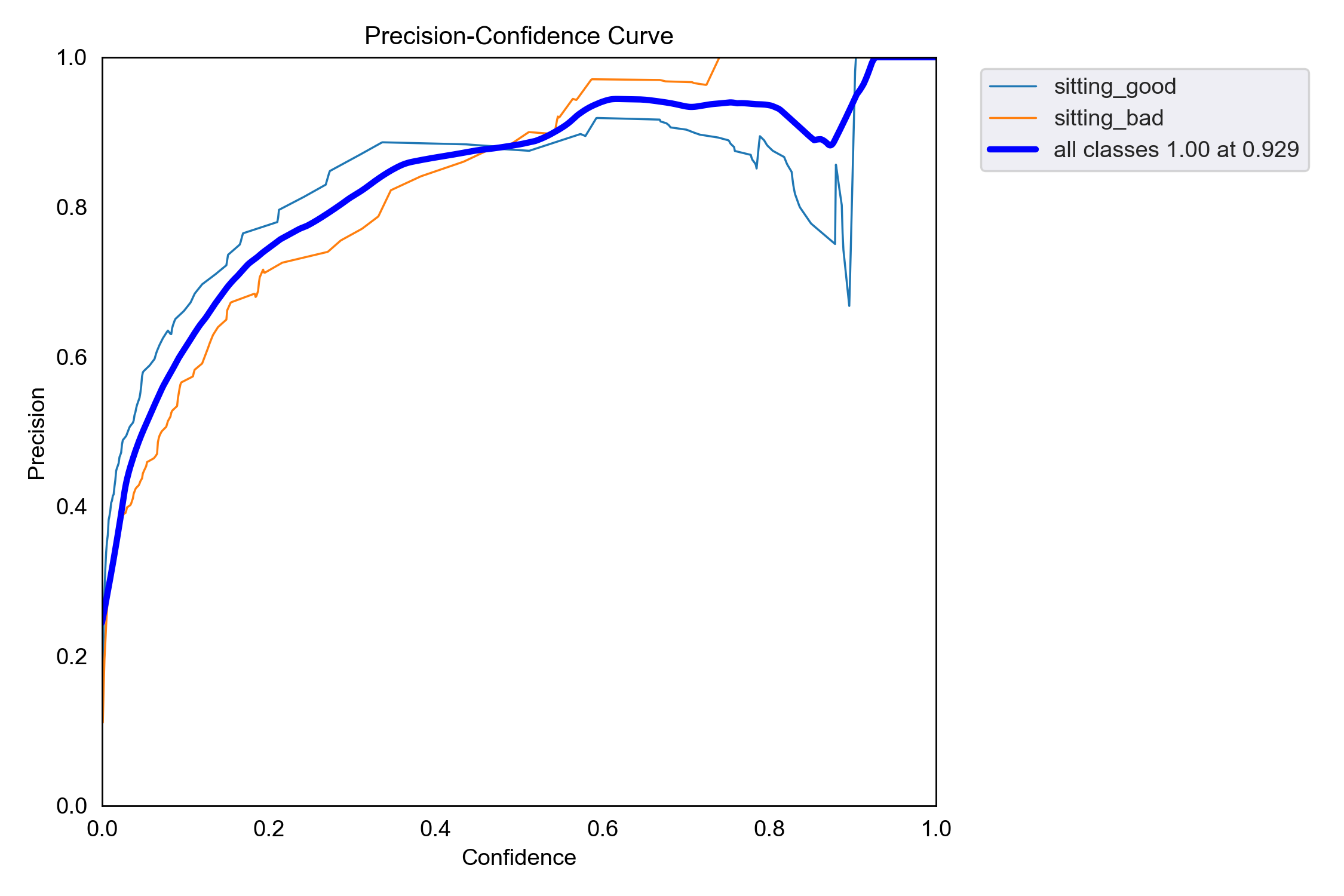
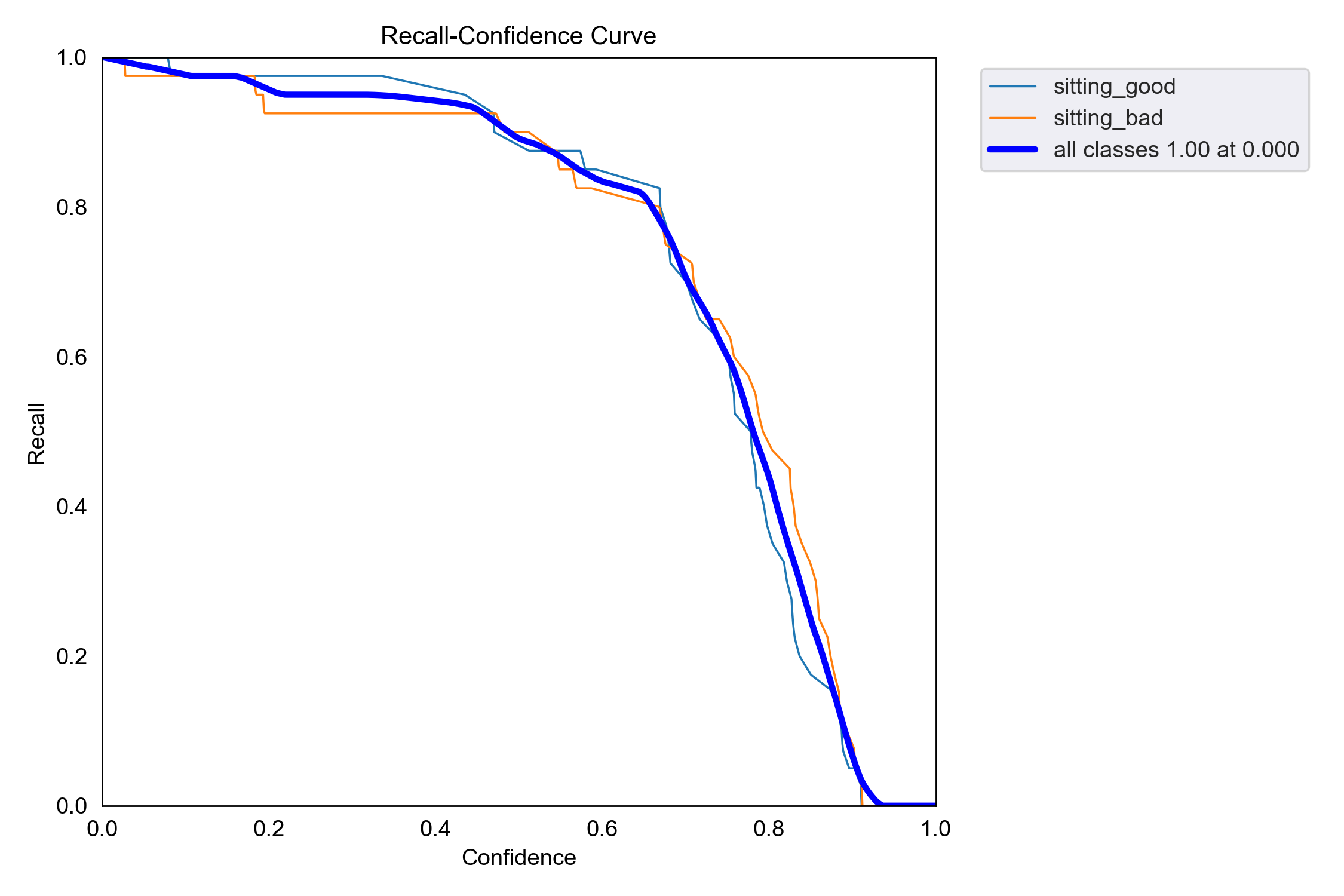
The validation set contains 80 images (40 sitting_good, 40 sitting_bad). The results are as follows:
| Class | Images | Instances | Precision | Recall | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|
| all | 80 | 80 | 0.87 | 0.939 | 0.931 | 0.734 |
| sitting_good | 40 | 40 | 0.884 | 0.954 | 0.908 | 0.744 |
| sitting_bad | 80 | 40 | 0.855 | 0.925 | 0.953 | 0.724 |
Detailed graphs:
F1-Confidence Curve:
Precision-Confidence Curve:
Recall-Confidence Curve:
Precision-Recall Curve:

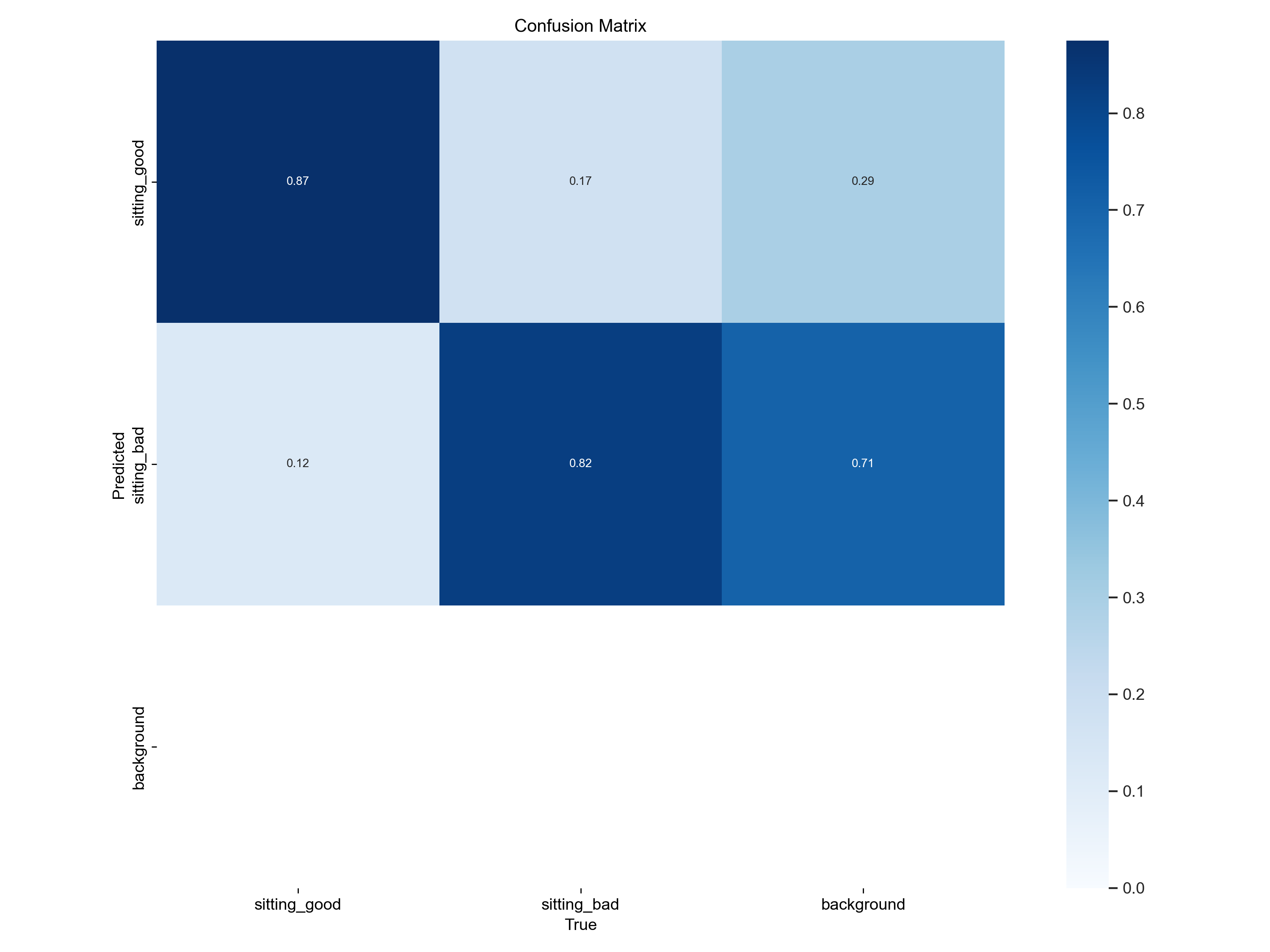
Confusion Matrix:
This project was developed by Niklas Hoefflin, Tim Spulak, Pascal Gerber & Jan Bösch and supervised by André Jeworutzki and Jan Schwarzer as part of the Train Like A Machine module.
- Jocher, G. (2020). YOLOv5 by Ultralytics (Version 7.0) [Computer software]. https://doi.org/10.5281/zenodo.3908559
- Fig. 1: TraCon: A novel dataset for real-time traffic cones detection using deep learning - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/The-architecture-of-the-YOLOv5-model-which-consists-of-three-parts-i-Backbone_fig1_360834230 [accessed 24 Jun, 2023]
This project is licensed under the MIT License. See the LICENSE file for details.
































