Table of Contents
In recent years, Reinforcement Learning (RL) has been used extensively in many real life problems. The application field varies from resource management, medical treatment design, tutoring systems robotics to several other fields. But in RL a problem occurs during selection of action (termed as exploration/exploitation dilemma). Bayesian Reinforcement Learning(BRL) provides an elegant solution to this dilemma. BRL algorithms incorporate prior knowledge into the algorithm. Regrettably, BRL is computationally very demanding and several scalability problems arise. Using a Finite State Controller (FSC) this scalability issue has been addressed. Previously boltzmann function have been used to parameterize the control parameters of the fsc. So, we used Maximum Entropy Mellowmax Policy. Also we propose a new algorithm named as The Monte Carlo gradient estimation algorithm with maximum Entropy mellowmax policy. The algorithm calculates the value gradient of the control parameters and updates the parameters in the direction of the gradient using the gradient ascent algorithm. We analyze this performance of the newly proposed algorithm with several hyper-parameters. We use two toy problem structures, chain problem and grid world, to investigate the result of these two policies. The empirical comparison between the boltzmann and the mellowmax policy suggests an improvement in the result.
This project was successfully built with the following libraries. To install the libraries and use the codebase, you should properly be aware of the version conflicts of tensorflow and numpy as well. But I strongly recommend to use Anaconda for that.
To get started with this project, the level of code interraction needed is intermediate level at least. Please follow the simple steps below to run the repo:
- Clone the repo
git clone https://github.com/intisarnaheen/Bayesian-Reinforcement-Learning-with-Maximum-Entropy.git
- Install numpy
pip install numpy
- Install Tensorflow
pip install tensorflow
- Install Gym
pip install gym
- Install Matplotlib
pip install matplotlib
- Install Scipy
pip install scipy
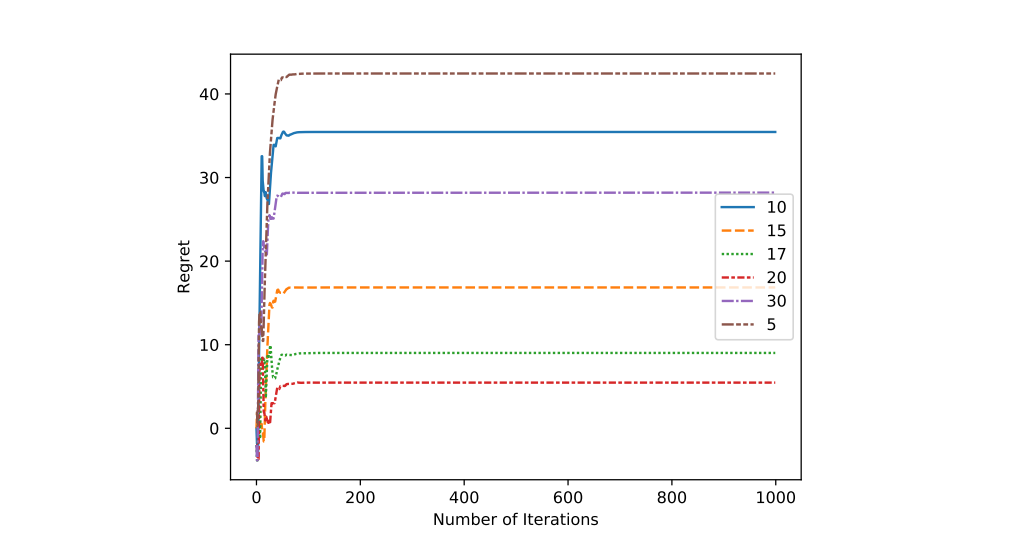
In this section we analyze the performance of our mellowmax policy. Here, we compare the influence of the number of memory states of the fsc. It is expected that as the number of memory states increases the performance of the finite state controller should improve.
In this section we make a comparative analysis the Monte- Carlo gradient estimation algorithm with mellowmax policy(Algorithm 7) and the Monte Carlo gradient estimation algorithm with boltzmann policy(Algorithm 6) First the results on the chain problem has been discussed. We compare our result both on cumulative reward and cumulative discounted reward.
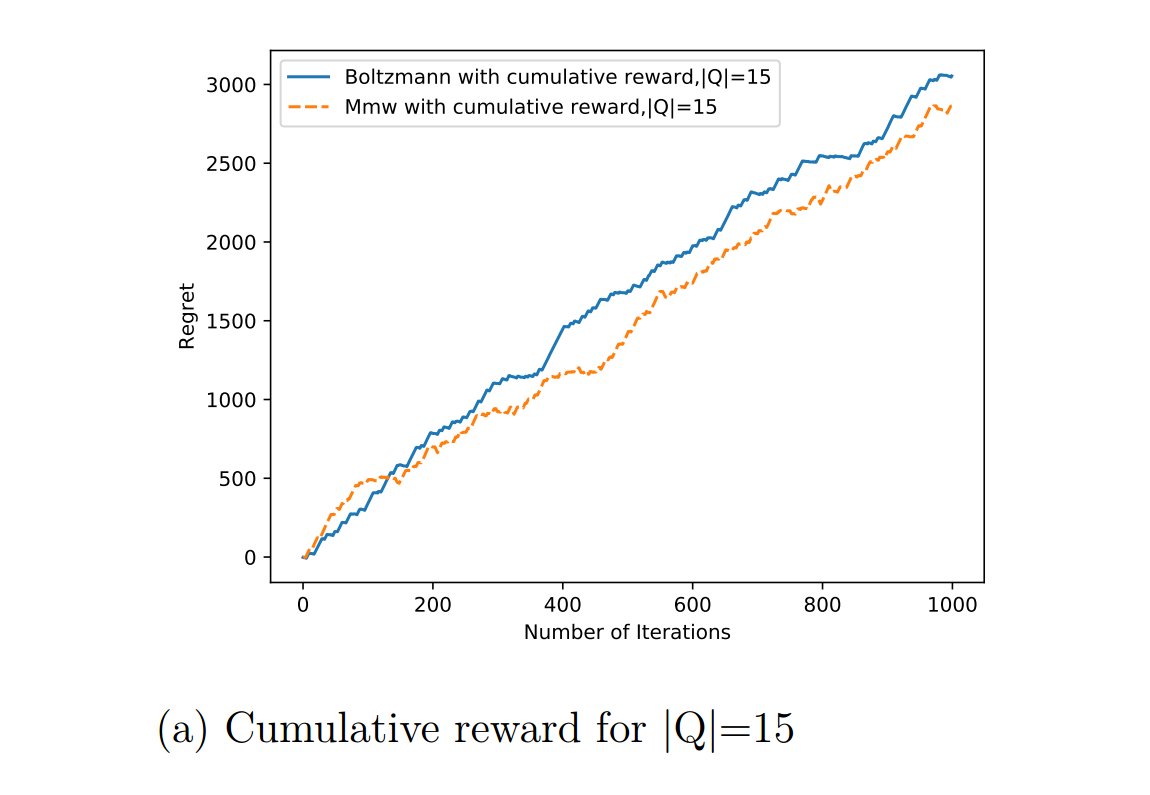
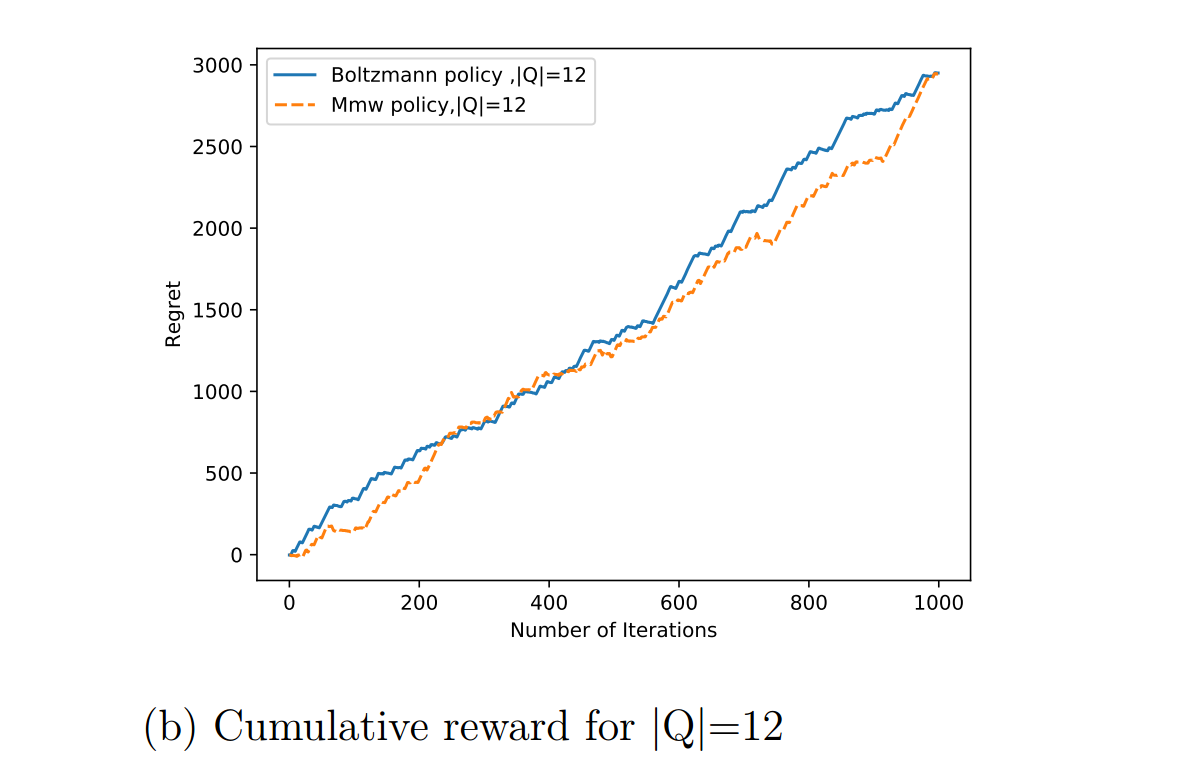
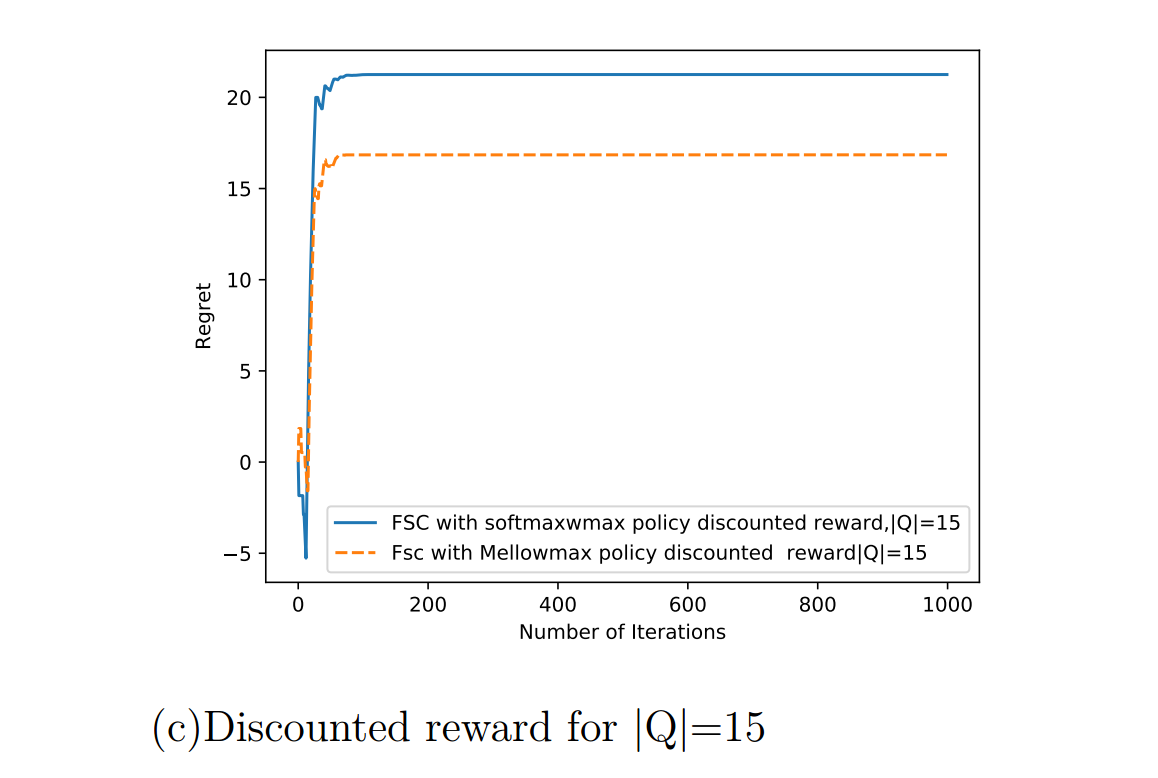
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are greatly appreciated.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement". Don't forget to give the project a star! Thanks again!
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/Bayesian-Reinforcement-Learning-with-Maximum-Entropy) - Commit your Changes (
git commit -m 'Add some Bayesian-Reinforcement-Learning-with-Maximum-Entropy') - Push to the Branch (
git push origin feature/Bayesian-Reinforcement-Learning-with-Maximum-Entropy) - Open a Pull Request
Distributed under the MIT License. See LICENSE.txt for more information.
@Follow me on twitter
Email me - [email protected]
Project Link: Bayesian Reinforcement Learning with Maximum Entropy Finite State Controllers.
Use this space to list resources you find helpful and would like to give credit to. I've included a few of my favorites to kick things off!