Interpret-Community is an experimental repository extending Interpret, with additional interpretability techniques and utility functions to handle real-world datasets and workflows for explaining models trained on tabular data. This repository contains the Interpret-Community SDK and Jupyter notebooks with examples to showcase its use.
- Overview of Interpret-Community
- Installation
- Documentation
- Supported Models
- Supported Interpretability Techniques
- Use Interpret-Community
- Visualizations
- Contributing
- Code of Conduct
Interpret-Community extends the Interpret repository and incorporates further community developed and experimental interpretability techniques and functionalities that are designed to enable interpretability for real world scenarios. Interpret-Community enables adding new experimental techniques (or functionalities) and performing comparative analysis to evaluate them.
Interpret-Community
- Actively incorporates innovative experimental interpretability techniques and allows for further expansion by researchers and data scientists
- Applies optimizations to make it possible to run interpretability techniques on real-world datasets at scale
- Provides improvements such as the capability to "reverse the feature engineering pipeline" to provide model insights in terms of the original raw features rather than engineered features
- Provides interactive and exploratory visualizations to empower data scientists to gain meaningful insight into their data
The package can be installed from pypi with:
pip install interpret-community
For more installation information, please see the website documentation at https://interpret-community.readthedocs.io/en/latest/overview.html#getting-started
For more information, please visit the documentation website, which also includes detailed API documentation generated by sphinx: https://interpret-community.readthedocs.io/en/latest/index.html
This API supports models that are trained on datasets in Python numpy.ndarray, pandas.DataFrame, or scipy.sparse.csr_matrix format.
The explanation functions accept both models and pipelines as input as long as the model or pipeline implements a predict or predict_proba function that conforms to the Scikit convention. If not compatible, you can wrap your model's prediction function into a wrapper function that transforms the output into the format that is supported (predict or predict_proba of Scikit), and pass that wrapper function to your selected interpretability techniques.
If a pipeline script is provided, the explanation function assumes that the running pipeline script returns a prediction. The repository also supports models trained via PyTorch, TensorFlow, and Keras deep learning frameworks.
The following are a list of the explainers available in the community repository:
| Interpretability Technique | Description | Type |
|---|---|---|
| SHAP Kernel Explainer | SHAP's Kernel explainer uses a specially weighted local linear regression to estimate SHAP values for any model. | Model-agnostic |
| GPU SHAP Kernel Explainer | GPU Kernel explainer uses cuML's GPU accelerated version of SHAP's Kernel Explainer to estimate SHAP values for any model. It's main advantage is to provide acceleration to fast GPU models, like those in cuML. But it can also be used with CPU-based models, where speedups can still be achieved but they might be limited due to data transfers and speed of models themselves. | Model-agnostic |
| SHAP Tree Explainer | SHAP’s Tree explainer, which focuses on the polynomial time fast SHAP value estimation algorithm specific to trees and ensembles of trees. | Model-specific |
| SHAP Deep Explainer | Based on the explanation from SHAP, Deep Explainer "is a high-speed approximation algorithm for SHAP values in deep learning models that builds on a connection with DeepLIFT described in the SHAP NIPS paper. TensorFlow models and Keras models using the TensorFlow backend are supported (there is also preliminary support for PyTorch)". | Model-specific |
| SHAP Linear Explainer | SHAP's Linear explainer computes SHAP values for a linear model, optionally accounting for inter-feature correlations. | Model-specific |
| Mimic Explainer (Global Surrogate) | Mimic explainer is based on the idea of training global surrogate models to mimic blackbox models. A global surrogate model is an intrinsically interpretable model that is trained to approximate the predictions of any black box model as accurately as possible. Data scientists can interpret the surrogate model to draw conclusions about the black box model. You can use one of the following interpretable models as your surrogate model: LightGBM (LGBMExplainableModel), Linear Regression (LinearExplainableModel), Stochastic Gradient Descent explainable model (SGDExplainableModel), and Decision Tree (DecisionTreeExplainableModel). | Model-agnostic |
| Permutation Feature Importance Explainer (PFI) | Permutation Feature Importance is a technique used to explain classification and regression models that is inspired by Breiman's Random Forests paper (see section 10). At a high level, the way it works is by randomly shuffling data one feature at a time for the entire dataset and calculating how much the performance metric of interest changes. The larger the change, the more important that feature is. PFI can explain the overall behavior of any underlying model but does not explain individual predictions. | Model-agnostic |
| LIME Explainer | Local Interpretable Model-agnostic Explanations (LIME) is a local linear approximation of the model's behavior. The explainer wraps the LIME tabular explainer with a uniform API and additional functionality. | Model-agnostic |
Besides the interpretability techniques described above, Interpret-Community supports another SHAP-based explainer, called TabularExplainer. Depending on the model, TabularExplainer uses one of the supported SHAP explainers:
| Original Model | Invoked Explainer |
|---|---|
| Tree-based models | SHAP TreeExplainer |
| Deep Neural Network models | SHAP DeepExplainer |
| Linear models | SHAP LinearExplainer |
| None of the above | SHAP KernelExplainer or GPUKernelExplainer |
The explainers in interpret-community have one common API, where you first construct the explainer from the model or prediction function:
from interpret.ext.blackbox import TabularExplainer
# "features" and "classes" fields are optional
explainer = TabularExplainer(model,
x_train,
features=breast_cancer_data.feature_names,
classes=classes)Explanations can then be computed on the evaluation examples:
# you can use the training data or the test data here
global_explanation = explainer.explain_global(x_train)
# explain the first five data points in the test set
local_explanation = explainer.explain_local(x_test[0:5])For more usage information, please see Use Interpret-Community
Install the raiwidgets package, the ExplanationDashboard has moved to the responsible-ai-toolbox repo:
pip install raiwidgets
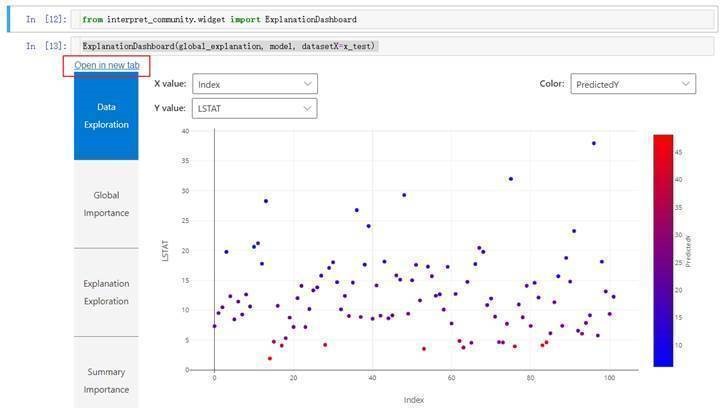
Load the visualization dashboard in your notebook to understand and interpret your model:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, dataset=x_test, trueY=y_test)Once you load the visualization dashboard, you can investigate different aspects of your dataset and trained model via four tab views:
- Model Performance
- Data Explorer
- Aggregate Feature Importance
- Individual Feature Importance and What-If
For more information about the visualizations, please see Visualizations
This project welcomes contributions and suggestions. Most contributions require you to agree to the Github Developer Certificate of Origin, DCO. For details, please visit https://probot.github.io/apps/dco/.
The Developer Certificate of Origin (DCO) is a lightweight way for contributors to certify that they wrote or otherwise have the right to submit the code they are contributing to the project. Here is the full text of the DCO, reformatted for readability:
By making a contribution to this project, I certify that:
(a) The contribution was created in whole or in part by me and I have the right to submit it under the open source license indicated in the file; or
(b) The contribution is based upon previous work that, to the best of my knowledge, is covered under an appropriate open source license and I have the right under that license to submit that work with modifications, whether created in whole or in part by me, under the same open source license (unless I am permitted to submit under a different license), as indicated in the file; or
(c) The contribution was provided directly to me by some other person who certified (a), (b) or (c) and I have not modified it.
(d) I understand and agree that this project and the contribution are public and that a record of the contribution (including all personal information I submit with it, including my sign-off) is maintained indefinitely and may be redistributed consistent with this project or the open source license(s) involved.
Contributors sign-off that they adhere to these requirements by adding a Signed-off-by line to commit messages.
This is my commit message
Signed-off-by: Random J Developer <[email protected]>
Git even has a -s command line option to append this automatically to your commit message:
$ git commit -s -m 'This is my commit message'
When you submit a pull request, a DCO bot will automatically determine whether you need to certify. Simply follow the instructions provided by the bot.
This project has adopted the his project has adopted the GitHub Community Guidelines.
Security issues and bugs should be reported privately, via email, to the Microsoft Security Response Center (MSRC) at [email protected]. You should receive a response within 24 hours. If for some reason you do not, please follow up via email to ensure we received your original message. Further information, including the MSRC PGP key, can be found in the Security TechCenter.

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")