item['data'].metadata
#{'href': 'https://grfn.asf.alaska.edu/door/download/S1-GUNW-A-R-087-tops-20141023_20141011-153856-27545N_25464N-PP-1a1a-v2_0_2.nc'}
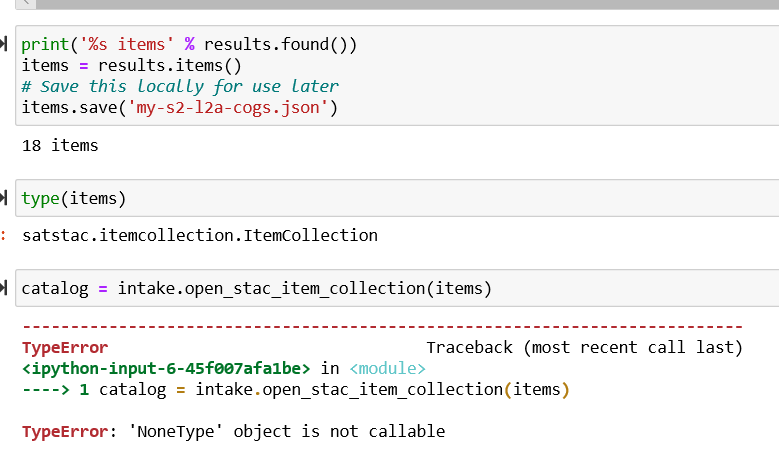
da = item['data'].to_dask()
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/file_manager.py in _acquire_with_cache_info(self, needs_lock)
197 try:
--> 198 file = self._cache[self._key]
199 except KeyError:
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/lru_cache.py in __getitem__(self, key)
52 with self._lock:
---> 53 value = self._cache[key]
54 self._cache.move_to_end(key)
KeyError: [<class 'netCDF4._netCDF4.Dataset'>, ('https://grfn.asf.alaska.edu/door/download/S1-GUNW-A-R-087-tops-20141023_20141011-153856-27545N_25464N-PP-1a1a-v2_0_2.nc',), 'r', (('clobber', True), ('diskless', False), ('format', 'NETCDF4'), ('persist', False))]
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
<ipython-input-15-90d7a2a112b8> in <module>
----> 1 da = item['data'].to_dask()
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/intake_xarray/base.py in to_dask(self)
67 def to_dask(self):
68 """Return xarray object where variables are dask arrays"""
---> 69 return self.read_chunked()
70
71 def close(self):
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/intake_xarray/base.py in read_chunked(self)
42 def read_chunked(self):
43 """Return xarray object (which will have chunks)"""
---> 44 self._load_metadata()
45 return self._ds
46
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/intake/source/base.py in _load_metadata(self)
124 """load metadata only if needed"""
125 if self._schema is None:
--> 126 self._schema = self._get_schema()
127 self.datashape = self._schema.datashape
128 self.dtype = self._schema.dtype
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/intake_xarray/base.py in _get_schema(self)
16
17 if self._ds is None:
---> 18 self._open_dataset()
19
20 metadata = {
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/intake_xarray/netcdf.py in _open_dataset(self)
56 _open_dataset = xr.open_dataset
57
---> 58 self._ds = _open_dataset(url, chunks=self.chunks, **kwargs)
59
60 def _add_path_to_ds(self, ds):
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/api.py in open_dataset(filename_or_obj, group, decode_cf, mask_and_scale, decode_times, autoclose, concat_characters, decode_coords, engine, chunks, lock, cache, drop_variables, backend_kwargs, use_cftime, decode_timedelta)
507 if engine == "netcdf4":
508 store = backends.NetCDF4DataStore.open(
--> 509 filename_or_obj, group=group, lock=lock, **backend_kwargs
510 )
511 elif engine == "scipy":
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/netCDF4_.py in open(cls, filename, mode, format, group, clobber, diskless, persist, lock, lock_maker, autoclose)
356 netCDF4.Dataset, filename, mode=mode, kwargs=kwargs
357 )
--> 358 return cls(manager, group=group, mode=mode, lock=lock, autoclose=autoclose)
359
360 def _acquire(self, needs_lock=True):
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/netCDF4_.py in __init__(self, manager, group, mode, lock, autoclose)
312 self._group = group
313 self._mode = mode
--> 314 self.format = self.ds.data_model
315 self._filename = self.ds.filepath()
316 self.is_remote = is_remote_uri(self._filename)
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/netCDF4_.py in ds(self)
365 @property
366 def ds(self):
--> 367 return self._acquire()
368
369 def open_store_variable(self, name, var):
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/netCDF4_.py in _acquire(self, needs_lock)
359
360 def _acquire(self, needs_lock=True):
--> 361 with self._manager.acquire_context(needs_lock) as root:
362 ds = _nc4_require_group(root, self._group, self._mode)
363 return ds
~/miniconda3/envs/intake-stac-gui/lib/python3.7/contextlib.py in __enter__(self)
110 del self.args, self.kwds, self.func
111 try:
--> 112 return next(self.gen)
113 except StopIteration:
114 raise RuntimeError("generator didn't yield") from None
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/file_manager.py in acquire_context(self, needs_lock)
184 def acquire_context(self, needs_lock=True):
185 """Context manager for acquiring a file."""
--> 186 file, cached = self._acquire_with_cache_info(needs_lock)
187 try:
188 yield file
~/miniconda3/envs/intake-stac-gui/lib/python3.7/site-packages/xarray/backends/file_manager.py in _acquire_with_cache_info(self, needs_lock)
202 kwargs = kwargs.copy()
203 kwargs["mode"] = self._mode
--> 204 file = self._opener(*self._args, **kwargs)
205 if self._mode == "w":
206 # ensure file doesn't get overriden when opened again
netCDF4/_netCDF4.pyx in netCDF4._netCDF4.Dataset.__init__()
netCDF4/_netCDF4.pyx in netCDF4._netCDF4._ensure_nc_success()
OSError: [Errno -78] NetCDF: Authorization failure: b'https://grfn.asf.alaska.edu/door/download/S1-GUNW-A-R-087-tops-20141023_20141011-153856-27545N_25464N-PP-1a1a-v2_0_2.nc'
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")





![pre-commit-ci[bot] avatar](https://avatars.githubusercontent.com/in/68672?v=4 "pre-commit-ci[bot]")