Code and data for the paper "Visually grounded continual learning of compositional phrases, EMNLP 2020". Paper
Checkout our Project website for data explorers and the leaderboard!
conda create -n viscoll-env python==3.7.5
conda activate viscoll-env
pip install -r requirements.txt
VisCOLL proposes a problem setup and studies algorithms for continual learning and compositionality over visual-linguistic data. In VisCOLL, the model visits a stream of examples with an evolving data distribution over time and learn to perform masked phrases prediction. We create COCO-shift and Flickr-shift (based on COCO-captions and Flickr30k-entities) for study.
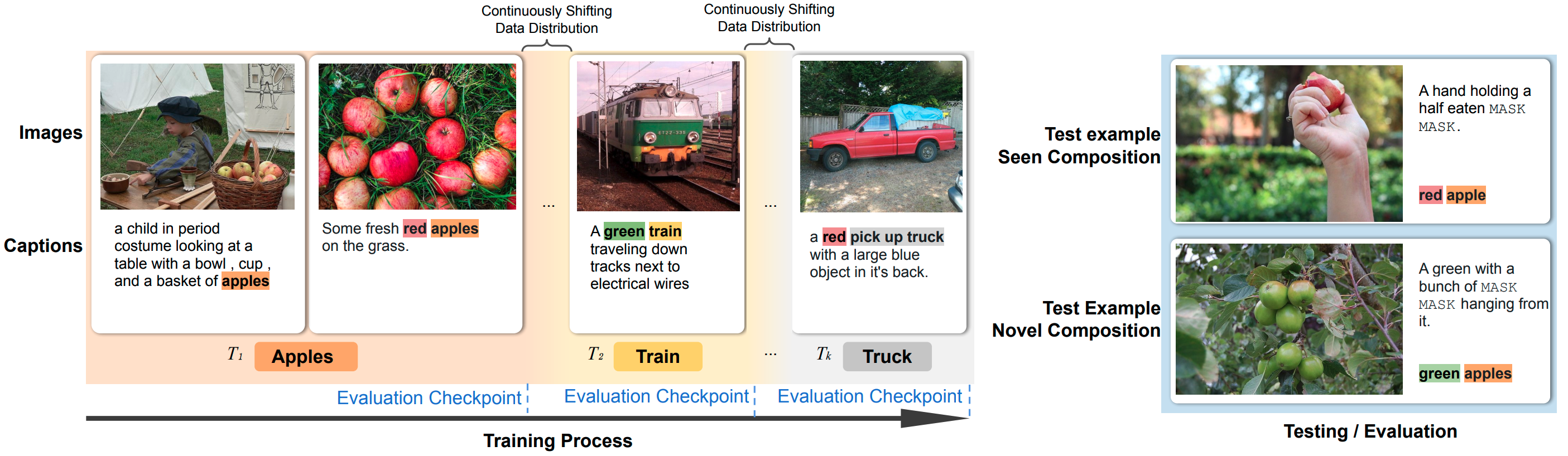
This repo include code for running and evaluating ER/MIR/AGEM continual learning algorithms on VisCOLL datasets (COCO-shift and Flickr-shift), with VLBERT or LXMERT models.
For example, to train a VLBERT model with a memory of 10,000 examples on coco using Experience Replay (ER) algorithm, run:
python train_mlm.py --name debug --config configs/mlmcaptioning/er.yaml --seed 0 --cfg MLMCAPTION.BASE=vlbert OUTPUT_DIR=runs/
You may check walkthrough.ipynb in this repo for a detailed walkthrough of training, inference, and evaluation.
We release the constructed data streams and scripts for visualization in the datasets folder.
COCO-shift is under datasets/coco/coco_buffer, with the name formats: task_buffer_real_split_{1}split{2}novel_comps{3}_task_partition_any_objects.pkl
- The official data split where examples are drawn from
- How the dataset is applied during training. We separate out 5,000 examples from original train split as the validation examples. The official val split is used as the test split
- Whether the data is the novel-composition split of 24 held-out concept pairs
The pickled file is python list where each item is a dict:
{'annotation': {'image_id': 374041, 'id': 31929, 'caption': 'Someone sitting on an elephant standing by a fence. '}, 'task': 'elephant', 'mask': (3, 5)}
The mask is the text span that should be masked for prediction. image_id can be used for locating the image in the dataset.
If you use the provided data stream above (i.e. do not create the non-stationary data stream itself, which requires additional extra steps such as phrase extraction), the only extra files required are,
-
Extracted image features for COCO under
datasets/coco-features. We use code from this repo to extract features. We will upload our extracted features soon; -
A json dictionary mapping of image id to image features in the file above. Included in this repo.
We use data from this repo to perform evaluation of compositional generalization. Please put compositional-image-captioning/data/dataset_splits/
under datasets/novel_comps and compositional-image-captioning/data/occurrences/ under datasets/occurrences.
Flickr-shift is under datasets/flickr/flickr_buffer.
We use official split for Flickr30k Entities. Below is an example from the Flickr shift dataset.
{'tokens': ['a', 'motorcyclist', '"', 'pops', 'a', 'wheelie', '"', 'in', 'a', 'grassy', 'field', 'framed', 'by', 'rolling', 'hills', '.'], 'task_id': 518, 'image_id': '3353962769', 'instance_id': 8714, 'phrase_offset': (0, 2)}
The phrase offset is the text span that should be masked for prediction. image_id can be used for retrieving the image in the dataset.
Similar to COCO, unless you want to create the datastream yourself, the only files required are,
-
Extracted image features for Flickr under
datasets/flickr-features. Simiarly, we use code from this repo to perfrom extraction. The extracted features will be uploaded soon. -
A json dictionary mapping of image id to image features in the file above. Included in this repo.
We provide visual_stream.ipynb to visualize task distributions over time in Flickr-shift dataset.
@inproceedings{Jin2020VisuallyGC,
title={Visually Grounded Continual Learning of Compositional Phrases},
author={Xisen Jin and Junyi Du and Arka Sadhu and R. Nevatia and X. Ren},
booktitle={EMNLP},
year={2020}
}

























 Yuchen Lin")