![]()
![]()
![]()
🤗 Optimum Graphcore is the interface between the 🤗 Transformers library and Graphcore IPUs. It provides a set of tools enabling model parallelization and loading on IPUs, training, fine-tuning and inference on all the tasks already supported by 🤗 Transformers while being compatible with the 🤗 Hub and every model available on it out of the box.
Quote from the Hugging Face blog post:
IPUs are the processors that power Graphcore’s IPU-POD datacenter compute systems. This new type of processor is designed to support the very specific computational requirements of AI and machine learning. Characteristics such as fine-grained parallelism, low precision arithmetic, and the ability to handle sparsity have been built into our silicon.
Instead of adopting a SIMD/SIMT architecture like GPUs, Graphcore’s IPU uses a massively parallel, MIMD architecture, with ultra-high bandwidth memory placed adjacent to the processor cores, right on the silicon die.
This design delivers high performance and new levels of efficiency, whether running today’s most popular models, such as BERT and EfficientNet, or exploring next-generation AI applications.
A Poplar SDK environment needs to be enabled to use this library. Please refer to Graphcore's Getting Started guides.
To install the latest release of this package:
pip install optimum-graphcore
Optimum Graphcore is a fast-moving project, and you may want to install from source.
pip install git+https://github.com/huggingface/optimum-graphcore.git
If you are working on the optimum-graphcore code then you should use an editable install
by cloning and installing optimum and optimum-graphcore:
git clone https://github.com/huggingface/optimum --branch v1.6.1-release
git clone https://github.com/huggingface/optimum-graphcore
pip install -e optimum -e optimum-graphcore
Now whenever you change the code, you'll be able to run with those changes instantly.
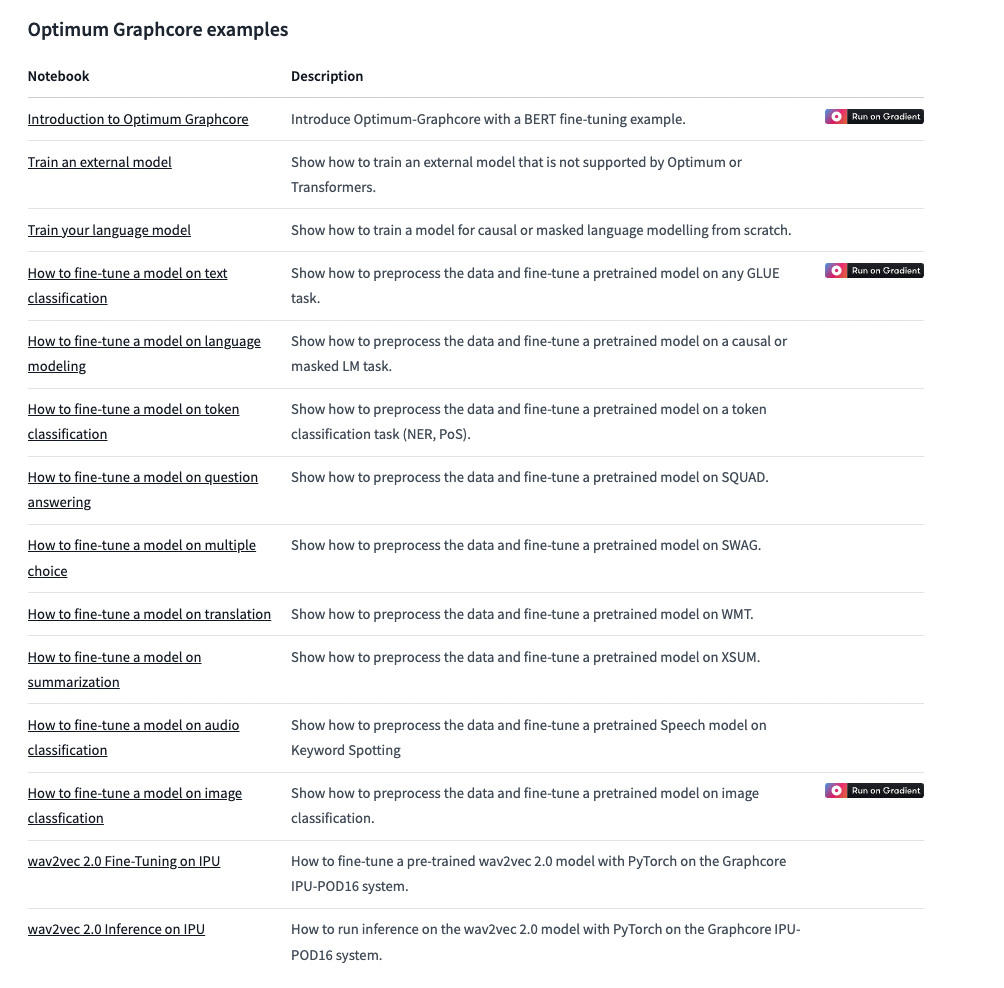
There are a number of examples provided in the examples directory. Each of these contains a README with command lines for running them on IPUs with Optimum Graphcore.
Please install the requirements for every example:
cd <example-folder>
pip install -r requirements.txt
🤗 Optimum Graphcore was designed with one goal in mind: make training and evaluation straightforward for any 🤗 Transformers user while leveraging the complete power of IPUs. It requires minimal changes if you are already using 🤗 Transformers.
To immediately use a model on a given input (text, image, audio, ...), we support the pipeline API:
->>> from transformers import pipeline
+>>> from optimum.graphcore import pipeline
# Allocate a pipeline for sentiment-analysis
->>> classifier = pipeline('sentiment-analysis', model="distilbert-base-uncased-finetuned-sst-2-english")
+>>> classifier = pipeline('sentiment-analysis', model="distilbert-base-uncased-finetuned-sst-2-english", ipu_config = "Graphcore/distilbert-base-ipu")
>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9996947050094604}]It is also super easy to use the Trainer API:
-from transformers import Trainer, TrainingArguments
+from optimum.graphcore import IPUConfig, IPUTrainer, IPUTrainingArguments
-training_args = TrainingArguments(
+training_args = IPUTrainingArguments(
per_device_train_batch_size=4,
learning_rate=1e-4,
+ # Any IPUConfig on the Hub or stored locally
+ ipu_config_name="Graphcore/bert-base-ipu",
+)
+
+# Loading the IPUConfig needed by the IPUTrainer to compile and train the model on IPUs
+ipu_config = IPUConfig.from_pretrained(
+ training_args.ipu_config_name,
)
# Initialize our Trainer
-trainer = Trainer(
+trainer = IPUTrainer(
model=model,
+ ipu_config=ipu_config,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
... # Other argumentsFor more information, refer to the full 🤗 Optimum Graphcore documentation.
The following model architectures and tasks are currently supported by 🤗 Optimum Graphcore:
| Pre-Training | Masked LM | Causal LM | Seq2Seq LM (Summarization, Translation, etc) | Sequence Classification | Token Classification | Question Answering | Multiple Choice | Image Classification | CTC | |
|---|---|---|---|---|---|---|---|---|---|---|
| BART | ✅ | ❌ | ✅ | ✅ | ❌ | |||||
| BERT | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | |||
| ConvNeXt | ✅ | ✅ | ||||||||
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| DistilBERT | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | ||||
| GPT-2 | ✅ | ✅ | ✅ | ✅ | ||||||
| GroupBERT | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | |||
| HuBERT | ❌ | ✅ | ✅ | |||||||
| LXMERT | ❌ | ✅ | ||||||||
| RoBERTa | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | |||
| T5 | ✅ | ✅ | ||||||||
| ViT | ❌ | ✅ | ||||||||
| Wav2Vec2 | ✅ | ✅ | ||||||||
| Whisper | ❌ | ✅ |
If you find any issue while using those, please open an issue or a pull request.